LINEヤフーの技術カンファレンス「Tech-Verse 2026」の公式記事です。
大規模言語モデル(LLM)が入力トークンの物理的しきい値を百万規模へと拡張するにつれ、ソフトウェア工学の現場は「シリコンの誤謬(silicon fallacy)」という誤ったパラダイムに直面しています。大きなコンテキストウィンドウが自動的に高度な運用知能に等しい、という前提は広く信じられていますが、実運用レベルのエージェントワークフロー(自動コードファクタリング、継続的なコードレビュー、長期的な開発ループなど)では、受動的な「トークン詰め込み」に依存すると重大な失敗状態を引き起こします。能動的なランタイムガバナンスが欠けていると、マルチヘッドアテンションは情報エントロピーを蓄積し、推論の劣化、コンテキストの腐敗(context rot)、そして重要データの漏洩といった脆弱性を招きます。
本稿では、コンテキストウィンドウを未管理のテキストストリームから決定論的なシステム資源へと変換するために設計された、ローカライズされた高スループット認知ランタイム基盤であるSemantic Context OSのアーキテクチャを紹介します。自律エージェントのアプリケーションロジックと外部のファウンデーションAPIの間に位置する傍受ループバックプロキシ(localhost:8080)として機能するSemantic Context OSは、専用のAIカーネルを実装します。このカーネルはPOSIX風の仮想ファイルシステム(VFS)を介して状態トポロジを管理し、PathAlignステージによる抽象構文木(AST)のトリミングを適用し、非同期のsawtoothメモリモデルを用いたインフライトのトークン最適化を実行します。
量的なハードウェアレベルのトークン制限と質的なセマンティックガバナンスの明確な責務分離を確立することで、Semantic Context OSは下流の推論エンジンを構造的ノイズから保護し、企業の知的財産を守ります。最終的に、このフレームワークはエンタープライズ規模で堅牢かつ安全、かつコスト効率の高い自律的ソフトウェアエンジニアリングエージェントを設計するための成熟した再現可能な標準を確立します。
(免責事項:本記事で導入する「Semantic Context OS」という用語は、本稿の著者がエージェントワークフロー内でのLLM注意機構のガバナンスおよびトークンライフサイクル管理のために設計した社内専用のランタイム基盤を指すものであり、ElixirData Context OS など、類似した名称を持つ商用データ統合プラットフォームとは、関係性・アーキテクチャ・商標のいずれの面においても一切の関連を有しません。)
「RAM危機」と長文コンテキストの逆説
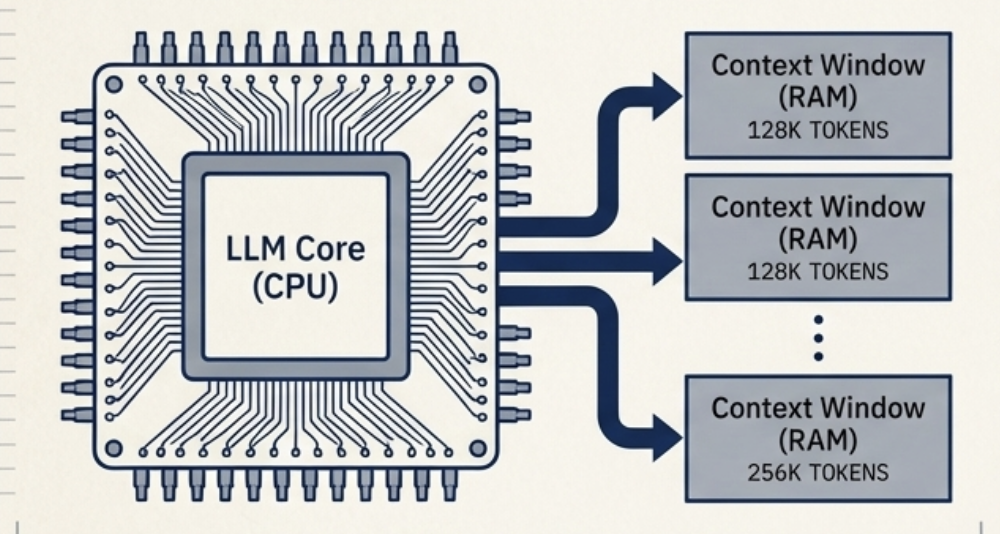
Karpathyの比喩:LLMメモリ動態の解明
現代のソフトウェアおよび分散システ��ムアーキテクチャにおいて、類推的思考は複雑で非決定論的な計算パラダイムを理解するための強力な概念的架け橋になります。最も基礎的な枠組みの一つがKarpathyの比喩であり、これは従来のフォン・ノイマン型コンピューティングアーキテクチャとLLMの実行ループとの間に明確な構造的一致があると仮定します:
-
LLMはCPUのように振る舞います:本質的にステートレスで非決定論的な推論エンジンであり、事前学習されたパラメータ重みに埋め込まれた構造的な意味パターンに基づいて、複雑な数学的命令セットを実行するよう設計されています。
-
コンテキストウィンドウはRAMとして機能します:現在の実行状態、過去のテレメトリ、動的な指示、実行時の運用データを格納する揮発性の作業メモリ空間であり、コアプロセッサが論理フローと状態の連続性を維持するために必要です。
 |  |
| 生成型AIを使用して作成された画像 | |
しかしソフトウェアエンジニアとして、我々はこの比喩が根本的に破綻する厳密な境界を認識しなければなりません。従来のコンピュ��ーティング工学において、物理的なシリコンRAMは厳密で決定論的な線形アドレッシングを前提としています。低レベルのポインタが0x7FFFのような特定のメモリアドレスを参照すると、基盤となるオペレーティングシステムはその正確な座標に格納されたバイトをO(1)の時間計算量かつ100%の精度で取得します。この操作は、システムが8GB、64GB、あるいは128GBのハードウェアメモリ上で動作しているかに関わらず完璧に機能します。
これに対して、LLMのコンテキストRAMは本質的に確率的で非線形です。LLMはAttentionメカニズム(Q、K、V行列)に完全に依存しており、到着する各トークンはシーケンス内の他のすべてのトークンに対して密なアテンションスコアを計算する必要があります。LLMにおけるメモリ取得はアドレス参照ではなく、相対的重みの動的な確率分布です。したがって、コンテキストウィンドウの物理的容量を(例えば32Kトークンから1Mや2Mに)拡張しても線形的にアクセス精度が保証されるわけではありません。むしろ計算表面積が指数的に拡大し、システム的ノイズ、構造的劣化、深刻なアーキテクチャ上の脆弱性を生み出します。
注意散逸の罠:大規模コンテキストの構造的失敗
人工知能業界は現在、我々が「シリコンの誤謬」と定義する状況に陥っています — 入力容量を拡大すれば実行上の知能が向上すると仮定して生のコンテキストウィンドウを拡張する力任せの工学競争です。このアプローチはTransformerアーキテクチャの深層に埋め込まれた重要な数学的現実を無視しています:注意散逸の罠。��この失敗状態を明らかにするために、多頭注意機構のコアとなる計算を評価する必要があります。クエリ(Q)、キー(K)、値(V)が与えられたとき、スケール済みドット積注意スコアは次のように定式化されます:
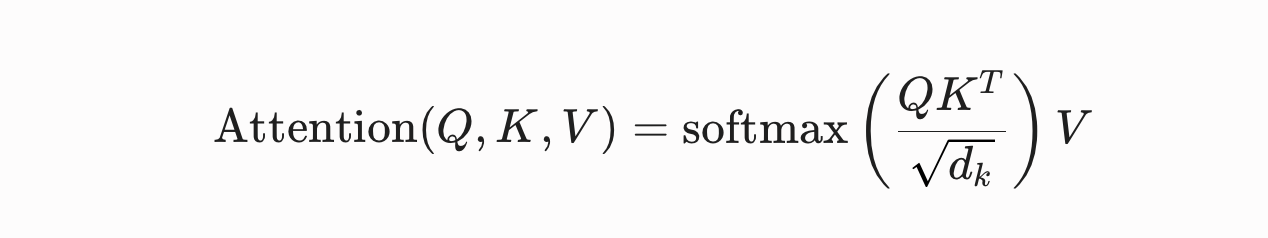
長大コンテキストのスケーリングにおける数学的脆弱性は、ソフトマックスの分母を単純に線形に平坦化することから生じるのではありません。むしろ、ドット積行列(QKT)内に情報エントロピーが蓄積することの直接的な帰結です。企業コードベースや大規模なシステムログでは、シーケンス長(N)が増大するにつれて、ペイロードはボイラープレート定義、参照されないインポート、冗長な構文トークンなど大量の構造的ノイズを導入します。その結果、キー行列(K)はクエリ(Q)に対して低振幅で均一な意味的類似性を示すバックグラウンドベクトルで満たされます。QKTを計算すると、この高次元ノイズは分散が小さい注意ロジットスコアのほぼ均一な分布を生成します。これをソフトマックス指数関数に通すと、エネルギー分布は巨大なシーケンス領域にわたって数学的に拡散されます。この構造的分散が注意散逸を引き起こします:正確な事実取得に必要な鋭い注意スパイク(シャープなデルタ分布)が高エントロピーの均一分布へと鈍化してしまうのです。
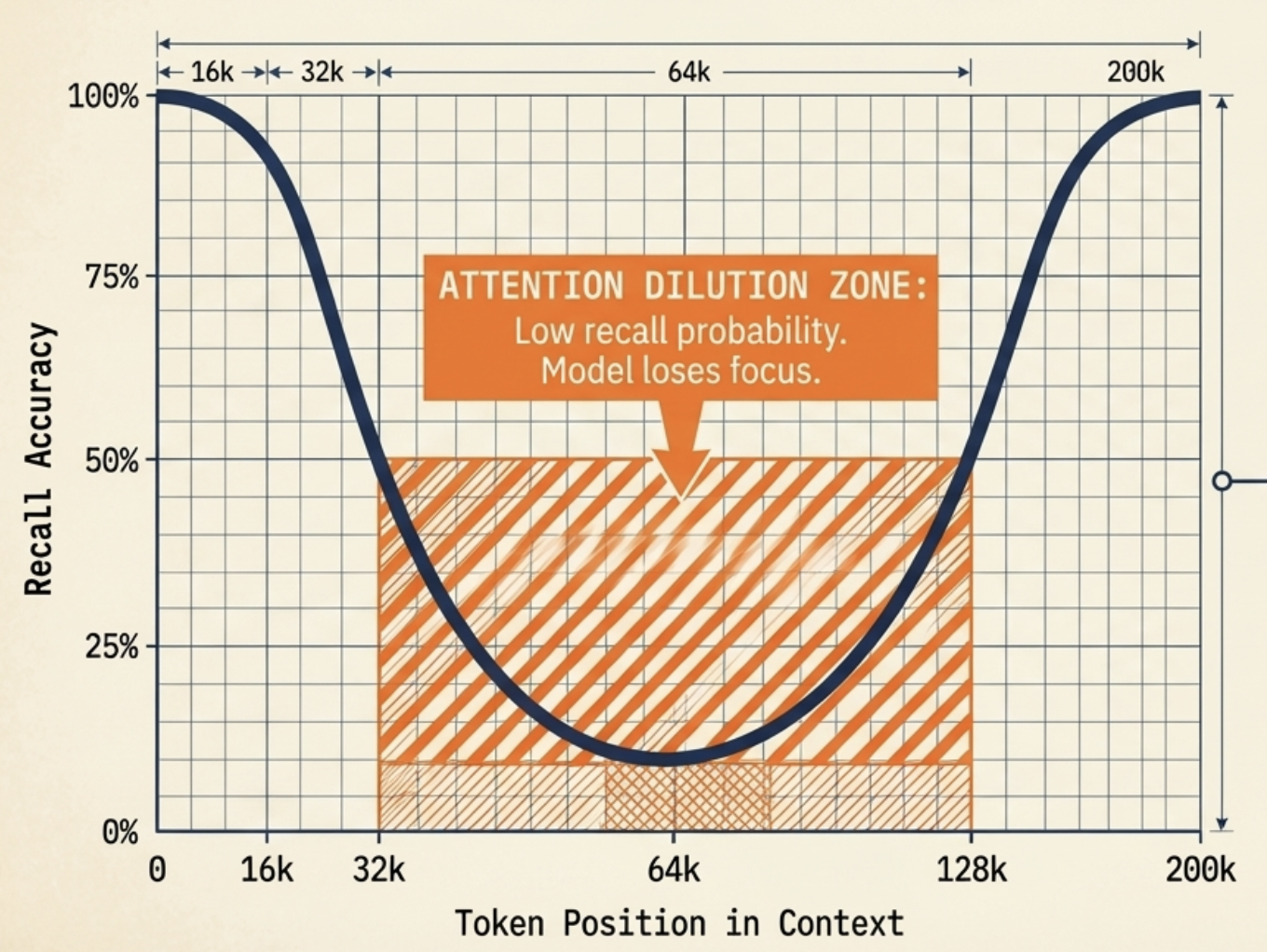
この数学的な希薄化は、本番環境でよく文書化された「lost in the middle(中ほどで失われる)」現象として現れます(U字型の検索精度曲線としてスタンフォード大学の Liu et al., 2023 により実証)。LLMはペイロードの先頭(初頭効果)や末尾(終末効果)にある情報を確実に取得できますが、コンテキストウィンドウの中央70%領域では構造的な検索精度が劇的に低下します。
何万行ものコードレビューやサービス間の依存関係トレースなど、複雑なソフトウェア開発ライフサイクルの自動化を任されるエンタープライズ向けAIエージェントにとって、これは容認できない誤差です。能動的なオーケストレーション層なしに巨大なコンテキストウィンドウに頼ることは、推論の劣化や重大な論理的失敗に直結するアーキテクチャ上のアンチパターンです。
長期タスクにおける「コンテキスト腐敗(context rot)」の病理
自律エージェントが自動化された企業向けコードファクタリング、レガシーマイグレーション、またはサービス間API契約の検証のような複雑で長期にわたるタスクに投入されると、コンテキストウィンドウの状態は時間の経過とともに不可避的に劣化します。この体系的な劣化を我々はコンテキスト腐敗(context rot)と定義します。ランタイムの可観測性トレースを用いた実証的観察により、コンテキスト腐敗を構成する3つの明確なアーキテクチャ��的病理を特定しました:

-
コンテキスト汚染(Context poisoning): マルチターンの自律実行ループ中に、エージェントが履歴の生データ、システム実行ログ、古いターミナルのエラーメッセージを継続的にコンテキストウィンドウへ追記すると、その蓄積がアテンション行列を歪めます。モデルは一時的な過去の失敗を現在の構造的制約として扱い始め、現在のタスクに対して有効な次トークン分布を生成する能力が損なわれます。
-
コンテキスト分散(Context distraction): 大規模なエンタープライズモノレポでは、同名の命名規約、オーバーロードされたメソッド、重複する補助ユーティリティが別のモジュールにまたがって頻繁に出現します。標準的な検索メカニズムがこれら無関係なコード断片をコンテキストウィンドウに流し込むと、アテンションは構造的に散漫になり、エージェントは主要な実行パスを見失い、主要なターゲットロジックと構造的に類似するが論理的には無関係なコードブロックを区別できなくなります。
-
コンテキスト衝突(Context clash): 自律エージェントがマルチステップの実行計画を反復するにつれて、内部のプロンプト状態は進化する必要があります。システムが前のステップからの古い指示をクリアまたは更新できない場合、コンテキストウィンドウは同時に矛盾する指示(例: "Step 1: Isolate the core database interface" と "Step 5: Merge the concrete implementation")を保持してしまいます。この状態は論理的麻痺や無限推論ループを引き起こし、エージェントが停止、タイムアウト、あるいは幻覚を起こす原因となります。
統計的テレメトリは、能動的な管理層がない場合、自律エージェントの失敗率がコンテキストの深さとともに非線形的に増加し、深くネストされたコードベース構造に直面した際には推定で約40%の失敗率に達することを示しています。この現実は、受動的なプロンプト詰め込みを超えて、コンテキスト環境を統治する専用のオペレーティングシステムを構築するという緊急のエンジニアリング上の必要性を強調しています。
アーキテクチャへの橋渡し:コンテキスト腐敗がもたらす体系的な劣化と、注意散逸(attention dilution)の数学的現実は、受動的なコンテキスト蓄積が自律エージェントにとって構造的な行き止まりであることを明らかにします。これらの非決定的な失敗状態を解決するためには、根本的なアーキテクチャのパラダイムシフトを実行する必要があります。すなわち、受動的なプロンプトエンジニアリングから、能動的で境界が明確なガバナンス層への移行です。次のセクションでは、この規律を強制するために設計されたコアエンジン、Semantic Context OS の AI カーネルを分解して説明します。
AIカーネルの設計(VFS と MVC)
パラダイムシフト:受動的プロンプトから能動的ガバナンスへ
堅牢なエンタープライズ向けのエージェントワークフローを構築するには、システ�ムエンジニアは根本的なパラダイムシフトを実行する必要があります。コンテキストを静的なテキストペイロードとして扱うのをやめ、動的で境界が定められた構造化されたシステム資源として管理し始めなければなりません。
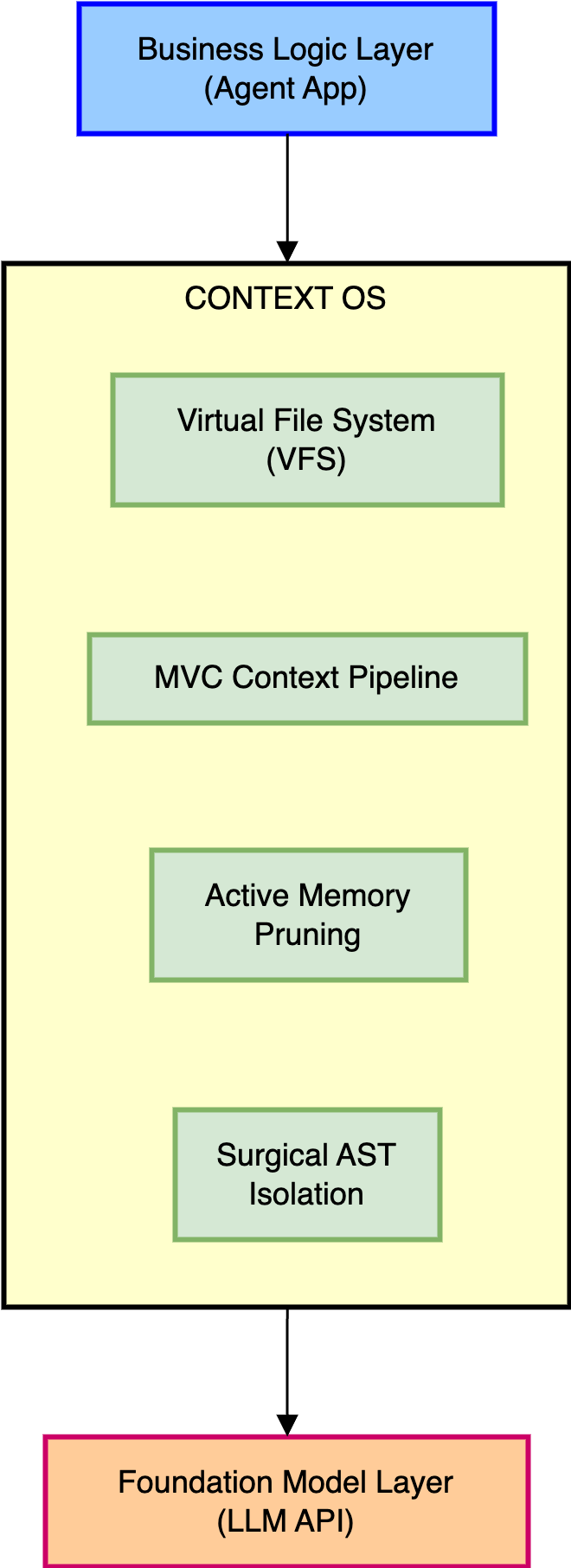
従来の実装パターンは受動的なプロンプトエンジニアリングに依存しており、コンテキストを文字列連結で段階的に構築した後、それを次のAPI呼び出しに盲目的に詰め込むという方法を取ります。このアプローチは下流の基盤モデル(LLM)にメモリ管理、トークン最適化、ノイズフィルタリングをその内部のアテンション層で暗黙的に処理させることを強いており、モデルが本来アーキテクチャ的に最適化されていないタスクを負わせることになります。
我々の解決策であるSemantic Context OSは、アプリケーションレベルのビジネスロジックと基盤モデル層の間に直接位置する専用のAIカーネルを導入します。Semantic Context OSはメモリ管理の責任を明示的に引き受け、コンテキストウィンドウを有限のハードウェア制約として扱い、トークンのライフサイクルを能動的に監視し、状態アクセスを統制し、単一のトークンがネットワークに送信される前に厳格な隔離ポリシーを適用します。
最小実行コンテキスト(MVC)パイプライン
Semantic Context OS のアーキテクチャの中核は MVC パイプラインです。大量のテキストを無差別に投入する「食べ放題」的な哲学を否定し、MVC パイプラインは厳格な技術方針を適用します。すなわち、エージェントが直近の推論ステップを確実に実行するために必要な、極めて純度の高く密度のある最小限の情報のみを提供することです。
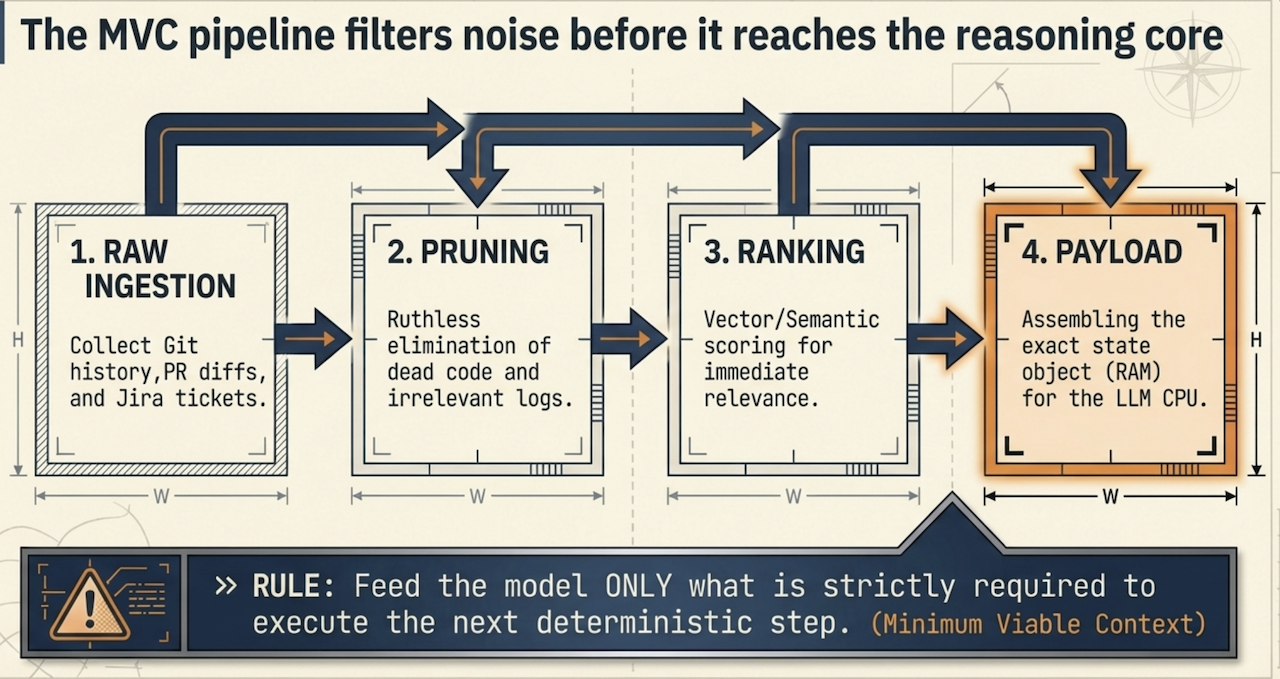
MVC パイプラインは、入ってくるすべてのコンテキストデータを次の4つの独立した高スループットステージで処理します:
-
取り込みとトークンマッピング(Ingestion & token mapping): ソースファイル、依存ツリー、ランタイムログなどの生データをキャプチャし、正確なモデルトークナイザ(例:
cl100k_base、o200k_base)を用いて絶対的なトークン重みに直接マッピングします。 -
構造的プルーニング(Structural pruning): システムは静的コード解析と構造ルールを用いて、コンパイラコメント、未参照のボイラープレートインポート、無関係なユーティリティコードなどのマクロレベルのノイズを即座に破棄します。
-
セマンティック&依存関係ランキング(Semantic & dependency ranking): 残存する情報は、セマンティックベクトル類似度と決定論的なAST依存スコアリングを組み合わせた二重スコアリングメカニズムに通され、文脈の整合性を確保します。
-
ペイロードの安定化とフォーマット(Payload stabilization & formatting): 最終的に最適化されたコンテキストは、構造化された予測可能なJSONまたはXMLのエンベロー��プに整形され、一貫したスキーマによってモデル境界での構造的幻覚を緩和します。
このようにコンテキストウィンドウを高密度で低ノイズの領域に維持することで、下流のLLMのアテンションヘッドは重要なタスクパラメータに集中でき、注意散逸の罠を回避できます。
エージェント状態管理のためのVFSの実装
MVCパイプラインを効果的に実装するため、AIカーネルはエージェント内部状態の複数のコンポーネントを追跡、分離、操作する高度に構造化された仕組みを必要とします。Semantic Context OS はコンテキストウィンドウをVFSとして抽象化し、LinuxのようなPOSIX準拠OSの標準的なディレクトリ構造を模倣することでこれを実現します。
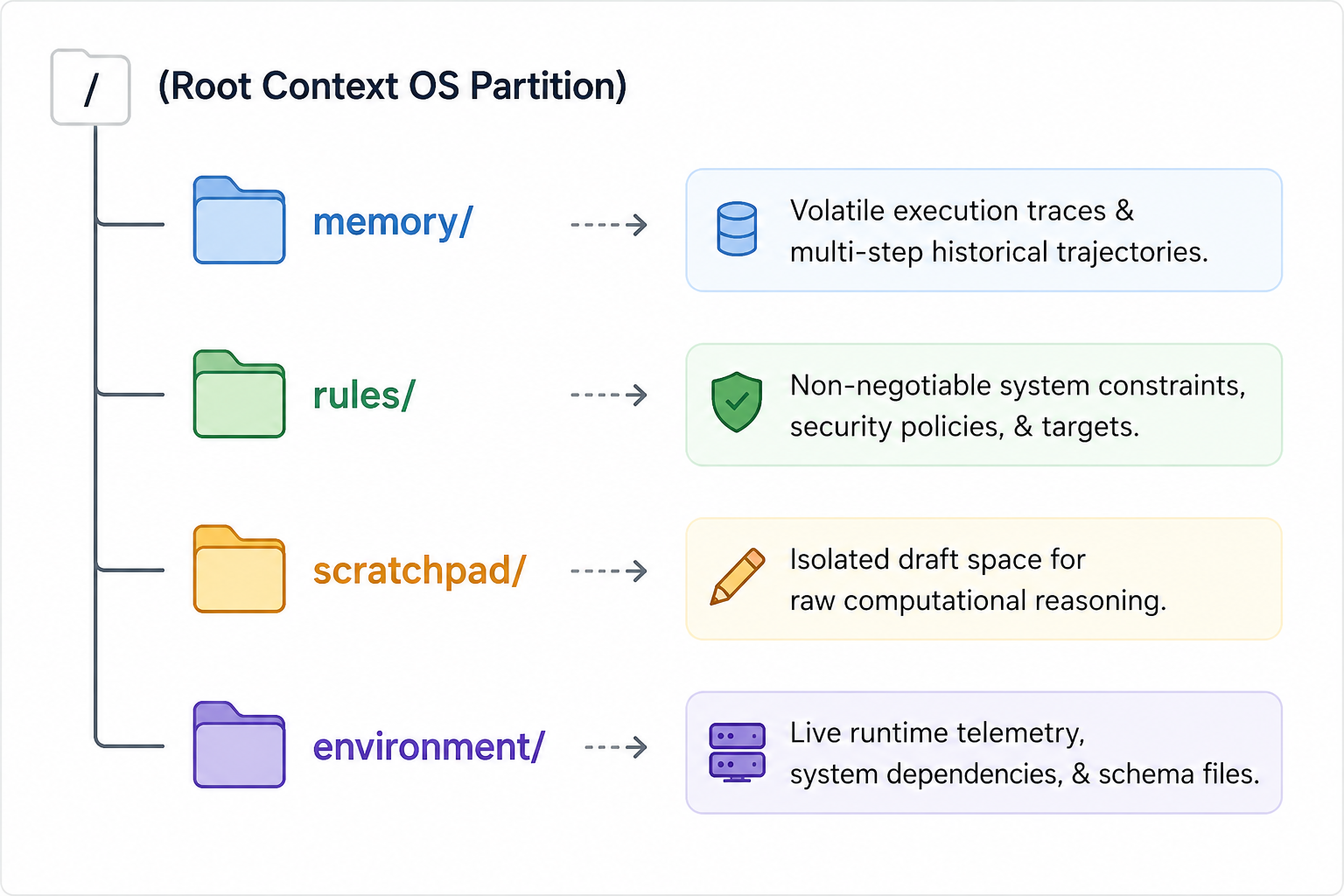
フラットな連続テキストブロックの代わりに、エージェントの作業メモリは異なる仮想論理ドライブに分割されています:
-
`/memory` パーティション:このパーティションはアクティブな実行ループの短期的かつ揮発性の履歴を管理します。エージェントが実行したステップ、返されたログ、完了したサブタスクを正確に追跡します。高度に動的で、厳格なプルーニングポリシーが適用されます。
-
`/rules` パーティション:このパーティションには譲れないアーキテクチャ制約、目標とするコーディング規約、企業セキュリティポリシー、および厳格な完了定義が格納されます。このドライブは最大の注意重みで保護され�、サブタスクのスタックがどれだけ深くなってもエージェントがコアのガードレールを見失わないようにします。
-
`/scratchpad` パーティション:専用の隔離されたサンドボックス作業領域です。エージェントがマルチステップの計画、数学的計算、またはコード構造の下書きを行う必要がある場合、これらの操作は`/scratchpad`内で実行されます。このパーティション内のデータは一時的であり、論理的な結論に達したら生の下書きは破棄され、最終的に最適化された結果のみが恒久的なコアメモリドライブへ昇格されます。
- `/environment` パーティション:このパーティションはランタイムのコンテキストアンカーとして機能します。外部環境メタデータ、スキーマ定義、ライブAPI仕様、およびサービス間のアクティブな境界を分離して管理します。揮発性の環境条件をエージェントのコア指示から分離することで、AIカーネルはランタイム依存関係が変化した際にサードパーティのサービススキーマを即座に差し替え、更新でき、`/memory`や`/rules`の基盤的な論理状態を汚染したりリセットしたりすることなく対応できます。
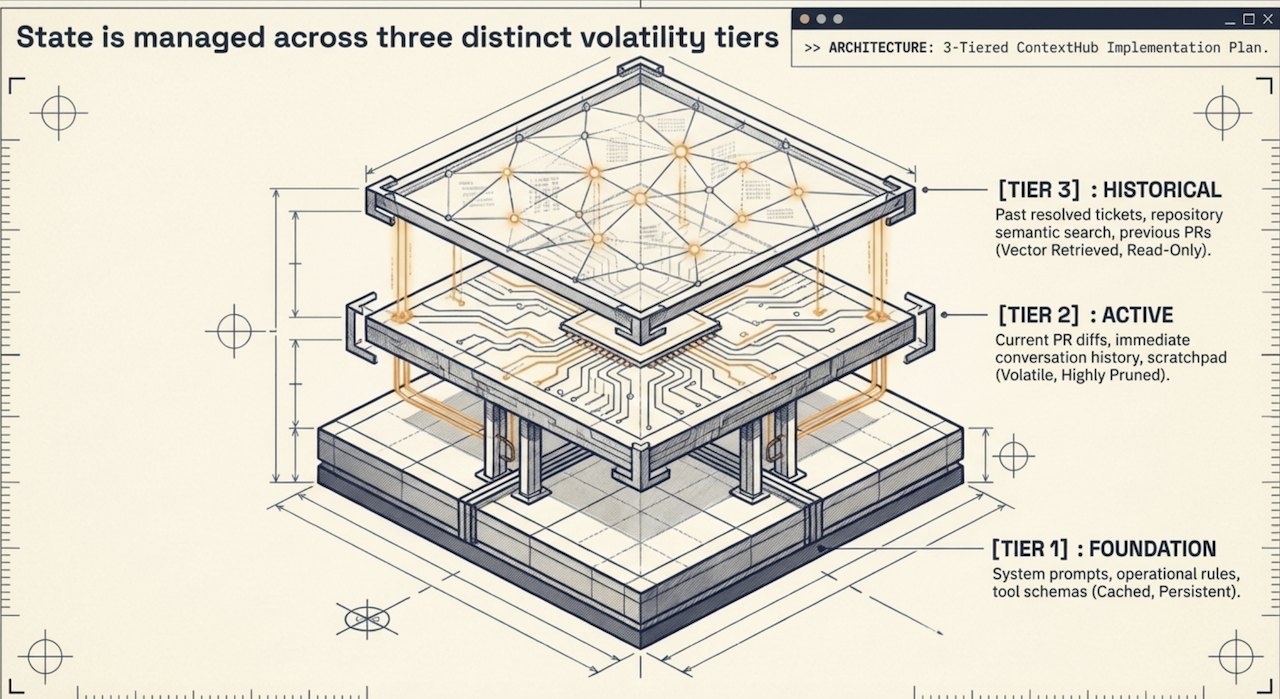
このVFS抽象化を通じて、Semantic Context OSは実行コンテキストの他部分を変更・汚染することなく、特定のメモリセグメントに対して外科的かつ粒度の細かい更新を実行できます。例えば、/memory/logs内の揮発的なランタイムログを消去しつつ、/rules/securityにあるシステム規則を完全に保護したままにすることで、LLMの状態追跡に伴う混沌に決定論的な秩序をもたらします。
アーキテクチャ的区別:素朴なトークン管理を超えてSemantic Context OSへ
Semantic Context OSインフラを導入する際に基本的な疑問が生じます:Claude Code、GitHub Copilot、Codexのような現代のエージェントエコシステムが既に組み込みのトークン管理やプロンプトキャッシュ機能を備えている場合、専用のSemantic Context OSを実装することは冗長なエンジニアリングオーバーヘッドを生むのではないでしょうか?
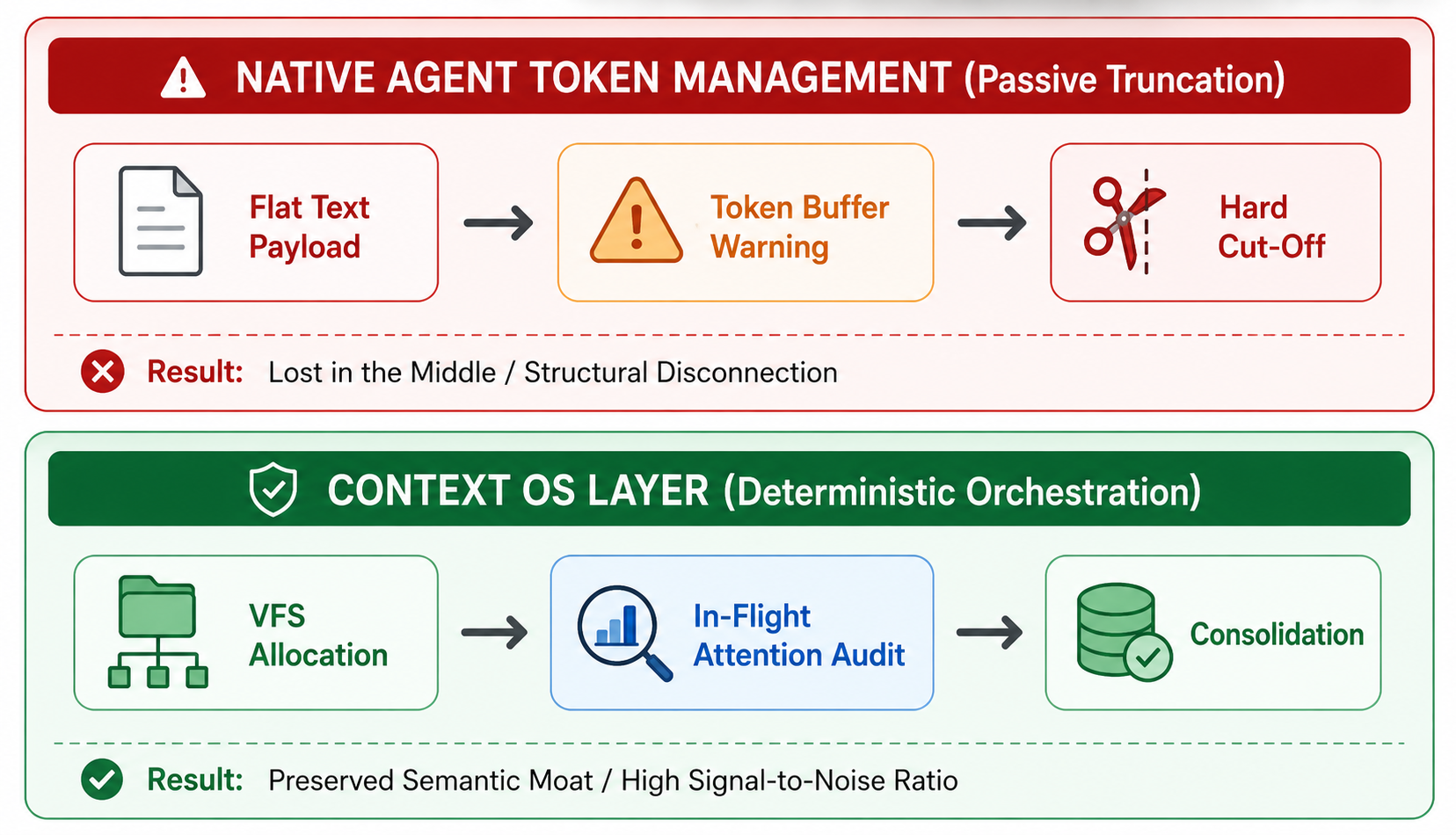
この明らかな逆説を解消するには、ハードウェアレベルのコンプライアンスと認知ランタイムのガバナンスの間に厳格な責務分離を確立する必要があります。ネイティブなクライアント側のトークン管理は本質的に定量的なインフラのガードレールである。その役割は境界を盲目的に強制することであり、文字列割当を監視して、下流のパイプラインが400 Bad Requestや429 Rate Limitのような致命的なHTTPエラーを返さないように反応的な切り捨て(FIFO)を実行することです。これは意味的推論の密度ではなく、APIの安定性を最適化するためのものです。
これに対してSemantic Context OSは、定性的なセマンティックルーター兼ロジックエンジンとして動作する。単にワイヤ上を流れるバイト量を測るだけでなく、ドメインに依拠したセマンティックな実行経路に基づいて、内部の情報トポロジーを能動的に構造化・監査・変容させる。
| 評価ベクトル | ネイティブトークン管理(インフラ層) | Semantic Context OS アーキテクチャ(セマンティック層) |
|---|---|---|
| 運用の性質 | 量的でセマンティクスに無関心(防御的) | 定性的でドメイン認識(オーケストレーション) |
| 主目的 | API枯渇や障害を防ぐための厳格な境界強制 | 推論のドリフトとコンテキスト腐敗を排除する注目度最大化 |
| メカニズム | トークンカウント、スライディングウィンドウ退避、静的プロンプトキャッシュ | ASTツリーのトリミング、アクティブメモリ圧縮、動的スコープオーバーライド |
| データトポロジー | フラットなテキストペイロード(全生テキストを連続文字列で含む) | 境界化されたVFSパーティション(/rules、/memory、/scratchpad、/environment) |
本番環境における実行の逆説:ルール衝突のケーススタディ
ネイ�ティブなトークン管理だけに依存することによる体系的な失敗を理解するために、自律エージェントが既存のコードベース全体に渡る大規模なアーキテクチャリファクタリングを実行する現実的な企業シナリオを考えてみましょう。
パイプラインがネイティブトークン管理のみに頼る場合:システムはすべての企業スタイルガイド、地域ごとのリポジトリ規約、ワークスペースのドキュメントを巨大なコンテキストウィンドウペイロードに集約します。基盤となるトークン層はデータ間の関係性を意識しないため、すべてのファイルを等しく扱ってしまいます。
たとえば、グローバルファイル(/global_rules.md)がインターフェイスメソッドはすべてsnake_caseに従うと規定している一方で、局所的なファイル(/src/modules/billing/rules.md)が具体的なAPIシリアライズにはcamelCaseを強制しているとします。これら相反する指示が同時にモデルのコンテキストRAMに詰め込まれると、多頭注意機構は即座に数学的な希薄化を受け、エージェントは停滞したり、挙動が揺らいだり、不正なコードインターフェイスを幻覚したりします。
Semantic Context OSアーキテクチャによってシステムが管理されている場合:単一のトークンがシリアライズされて送信される前に、AIカーネルは相互作用ループを横取りしてアクティブなディレクトリコンテキストをVFSに登録します。PathAlignエンジンがルールファイルの構造的階層を解析し、課題となっている請求モジュールのルールブロックがグローバル設定よりも深い高優先度のネームスペースに位置していることを認識すると、カーネルは動的なルール衝突のオーバーライドを実行します。
衝突するグローバル指示は運用スコープから外科的に除去され、統一された高密度のターゲット指示ペイロードのみが読み取り専用の/rulesドライブへ昇格されます。ワイヤ上に送信されるトークントークンエンベロープには、正しい実行に必要な本質的情報のみが抽出・凝縮された形で含まれています。
実行への橋渡し:VFS内でデータパーティションを局所化し、企業水準のセキュリティ境界を確立することは、安全なランタイム基盤の構造設計図を提供します。しかし、この境界化されたコンテキストをマルチターンの自律ループに渡って維持するには、能動的でリアルタイムな計算実行が必要です。次のセクションでは、Semantic Context OSアーキテクチャ下で本番環境における最小実行コンテキスト制約を能動的に強制するために設計された低レベルの数学的およびプログラム的ルーチン――sawtoothメモリモデルとPathAlignステージ――を詳述します。
アクティブアルゴリズム(sawtoothモデル & PathAlignステージ)
sawtoothメモリモデル:ランタイムの能動的プルーニング実行アルゴリズム
MVCパイプラインの制約をマルチターンの自律運用全体で強制し、突然のメモリ不足やコンテキスト切り捨てを回避するために、Semantic Context OSはsawtoothメモリモデルを実装しています。これは、トークン消費を動的にスケールおよび最適化する能動的なランタイム管理アルゴリズムです。
受動的なデータ配信フレームワークとは異なり、sawtoothアルゴリズムはVFSパーティション内のアクティブトークン数を継続的に追跡します。エージェントが外部環境と相互作用するにつれてトークン数は線形に増加し、あらかじめ定義された飽和閾値へと近づきます。
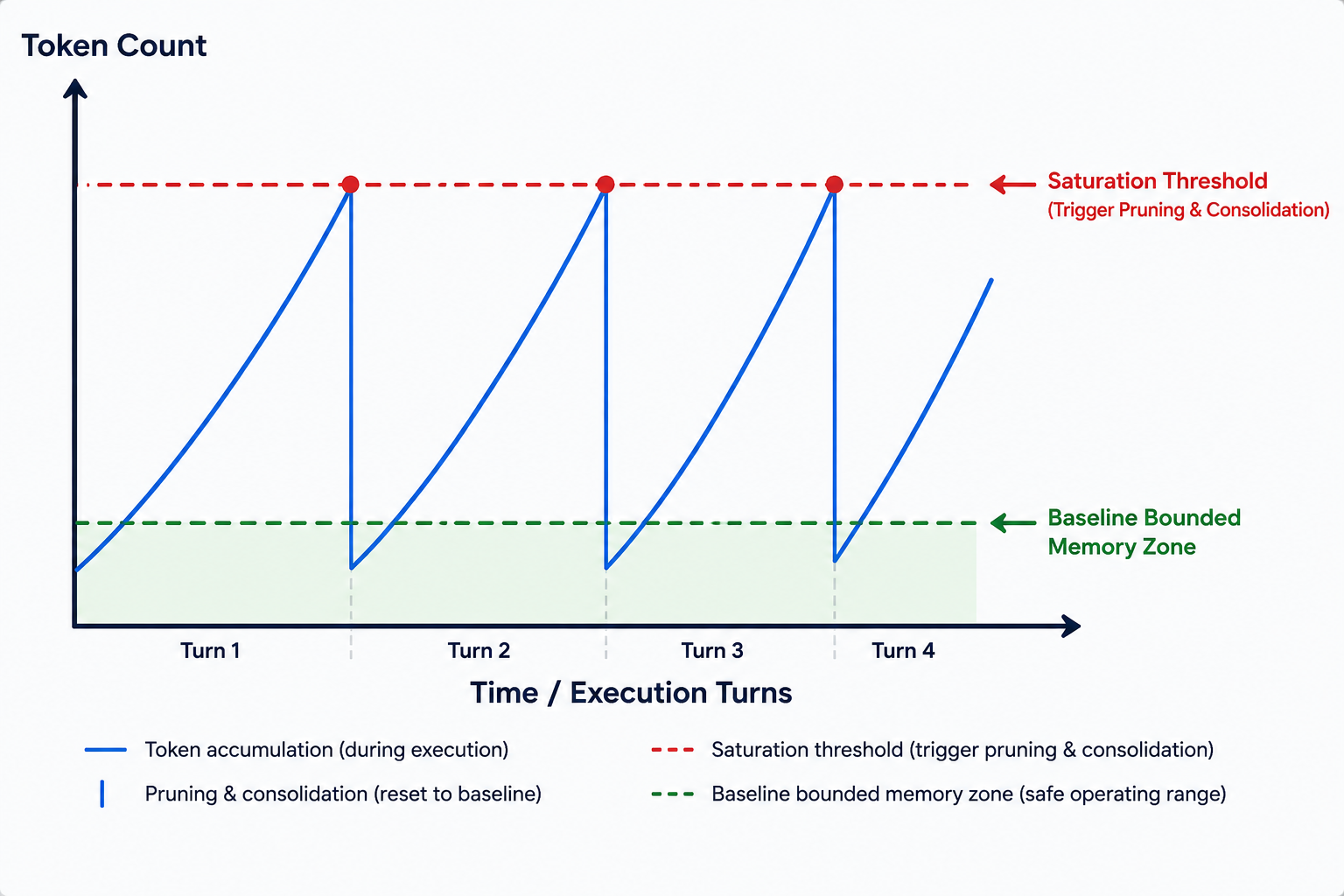
この閾値を超えた瞬間、AIカーネルは実行を一時停止し、バックグラウンドでコンパクション処理を起動して以下の2つの主要操作を実行します:
-
外科的トークンプルーニング:
/memory内のトークンのクロスアテンション重み履歴を評価します。ある標準偏差以下に落ちた重みを持つトークンは直ちにシステムから削除されます。 -
セマンティック統合:アクティブなテキストチェーンやマルチターンの会話ログは、高効率なユーティリティモデルに渡され、生の履歴スレッドを高密度なセマンティック状態ベクトルへ圧縮されます。
この圧縮によりアクティブトークン数は安全な基準レベルまで低下し、テレメトリ上に特徴的な「sawtooth(ノコギリ歯)」パターンを作り出します。このサイクルは無限に繰り返され、エージェントを最適な推論ゾーン内に留めます。
以下はsawtoothメカニズムの概念的なアルゴリズム構成です:
# 疑似コード: Semantic Context OS インフライトメモリ圧縮カーネルデーモン
# 非同期かつノンブロッキングのインターセプトミドルウェアとして動作します
class ContextOSKernel:
def __init__(self, vfs_driver, token_encoder, saturation_threshold=0.70):
self.vfs = vfs_driver
self.encoder = token_encoder
self.threshold = saturation_threshold
self.is_compacting = False
def on_agent_request_intercepted(self, request_payload):
"""
Claude Code / Codex がAPIペイロードをディスパッチした際に即時にトリガーされます。
送信前にコンテキストウィンドウが最適なセマンティックゾーン内に収まることを保証します。
"""
# ステップ1: VFSパーティション全体のリアルタイム入力トークン配分を計算
active_tokens = self.encoder.count_allocated_tokens(self.vfs.read_partition('/memory'))
max_capacity = system_hardware_constraints.get_max_context_window()
current_usage_ratio = active_tokens / max_capacity
# ステップ2: 飽和閾値の評価(Sawtoothトリガーポイント)
if current_usage_ratio >= self.threshold and not self.is_compacting:
# アクティブなクライアントのストリーミングIOループをブロックしないよう非同期ワーカーを起動
asynchronous_worker_pool.dispatch(self.execute_sawtooth_compaction)
# ステップ3: PathAlignエンジンから外科的に分離されたコードベースグラフを注入
purified_code_subgraph = PathAlignEngine.extract_syntax_subgraph(request_payload.target_files)
self.vfs.write_partition('/environment/codebase', purified_code_subgraph)
# ステップ4: 局所化されたVFS状態を再シリアライズして高密度トークン封筒へ変換
return self.vfs.consolidate_to_raw_json_payload()
def execute_sawtooth_compaction(self):
"""
インフライトでプルーニングとセマンティック統合を実行する非同期カーネルルーチン
"""
self.is_compacting = True
try:
# メモリ破損を防ぐためにシステムガードレールに対して不変の排他ロックを適用
self.vfs.acquire_write_lock('/rules')
# 診断用テレメトリを取得(例: Langfuse やローカルランタイムトレース)
attention_metrics = telemetry_engine.get_active_attention_logs()
# 廃棄対象ノード(古い実行出力、陳腐化したエラー、重複トレース)を特定
stale_nodes = self.filter_low_weight_tokens(
target_partition=self.vfs.read_partition('/memory/history'),
weights=attention_metrics
)
# 外科的プルーニングを実行
for node in stale_nodes:
self.vfs.delete_node(node)
# 長期の会話ターンに対してロスレスなセマンティック統合を実行
raw_history_chain = self.vfs.read_partition('/memory/history')
# 重要エンティティを厳格に保護しつつ生ログを構造化された状態ベクトルへ圧縮
consolidated_state_vector = state_summarizer_utility.compress(
payload=raw_history_chain,
policy="Preserve entity names, function signatures, error codes, and compliance constraints"
)
# 圧縮ベクトルをコミットしてパイプラインを解放
self.vfs.write_partition('/memory/consolidated_state', consolidated_state_vector)
self.vfs.clear_partition('/memory/history')
finally:
self.vfs.release_write_lock('/rules')
self.is_compacting = False
logger.info("Sawtooth memory compaction cycle executed successfully. Optimal context restored.")一方、sawtoothメモリモデルは自律的なアルゴリズムカーネルルーチンです。失敗が発生するのを待つのではなく、注意の減衰を能動的に監視し、実行中にメモリパターンを再構築してシステムの安定性を維持します。
外科的コンテキスト取得:PathAlignステージ
自動コードレビュー、脆弱性検出、自動リファクタリングなどのソフトウェアインテリジェンスタスクにLLMエージェントを適用する際、従来のセマンティックベクトル検索(標準的なRAG)は完全に機能不全に陥ります。コードは自然言語ではありません。固定文字数制限に基づいてコードベースをフラットなテキストブロックに分割(チャンク化)すると、セマンティックな構文木が破壊され、重要なインポートグラフや親子依存関係が切断されてしまいます。
大規模リポジトリ内の針の山から針を探す罠を解決するために、我々の提案アーキテクチャである Semantic Context OS はPathAlignステージを導入します。PathAlignはベクトル距離検索を置き換え、ASTベースの分離を用います。
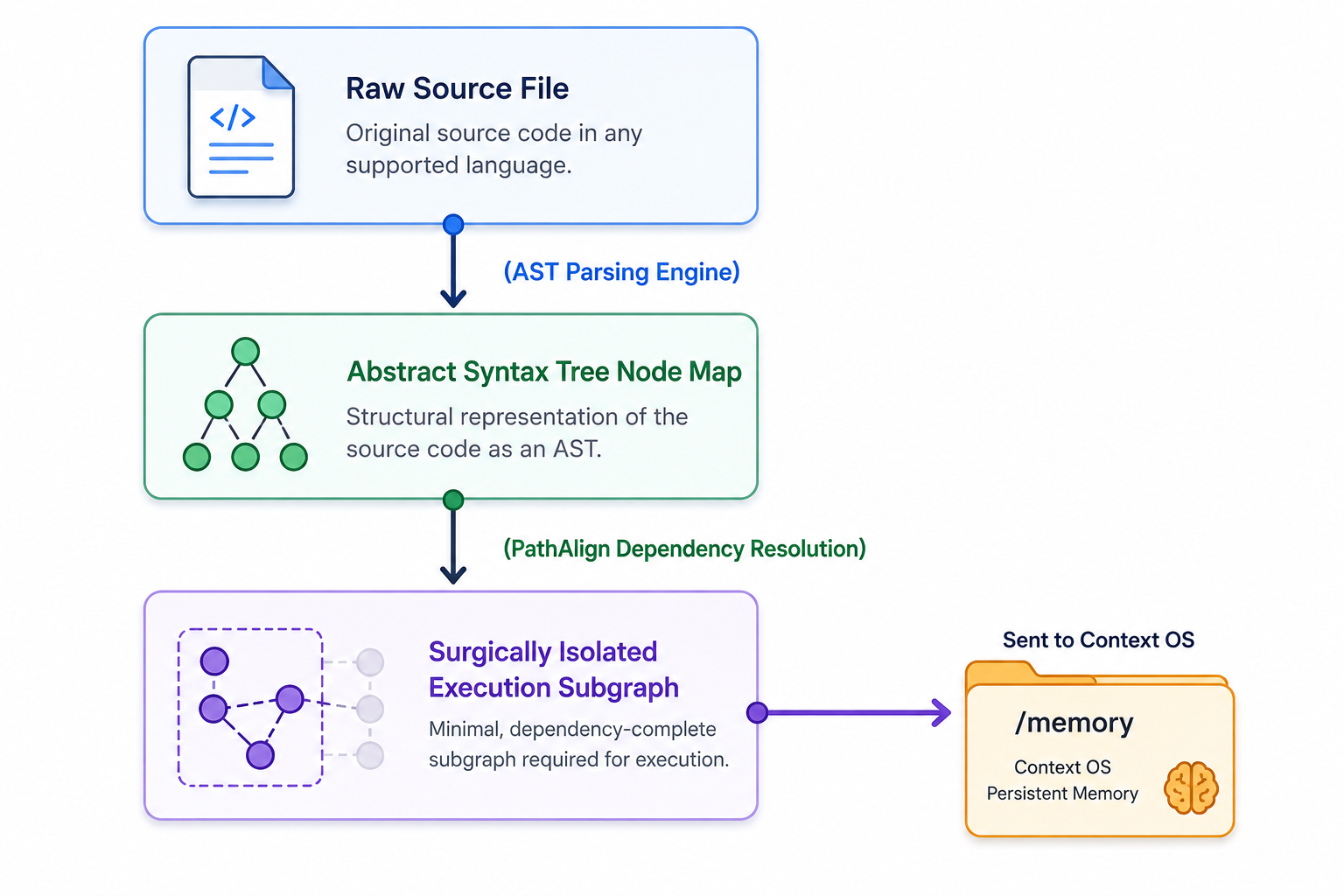
エージェントが特定のビジネス関数を調査したり、広大なシステム上でエラートレースを追跡したりする必要がある場合、PathAlignは以下の低レベルのシーケンスを実行します:
-
静的AST解析:ターゲットとなるソースファイルを階層的な構文木としてメモリにコンパイルし、すべてのクラス定義、イン�ターフェイス実装、関数呼び出し、変数参照を特定します。
-
制御フロー&依存関係解決:ターゲット関数ノードから外向きに明示的な実行経路をトレースし、正確な依存関係と下流の呼び出し元をマッピングします。
-
コンテキストグラフの分離:コードパスを理解するために必要な明示的な実行サブグラフのみを分離し、無関係なコメント、二次的なヘルパー関数、切り離されたコード行を完全に切り捨てます。
このように外科的に分離された実行グラフは高密度な構造化ペイロードに整形され、直接VFSに配置されます。これにより、エージェントは注意散逸に苦しむことなく、大規模リポジトリ内で複雑なエラーを特定できます。
評価への橋渡し:SawtoothデーモンとPathAlignパーサのアルゴリズム的な仕組みはSemantic Context OS内のトークンガバナンスに決定論的な秩序をもたらしますが、そのシステムとしての妥当性は実証的な枠組みによって監査される必要があります。主観的な「雰囲気ベース」の検証を超えて、次のセクションでは我々が提案するエンジニアリング用テレメトリと、システムを数学的に検証するために設計された目標となる性能軌道の詳細を示します。
性能評価フレームワークと設計目標
提案する可観測性手法と検証戦略
近年、企業プラットフォームにおけるAIエージェントの評価は、俗に「雰囲気ベースのエンジニアリング」と呼ばれる主観的な視覚的分析に依存することが多く、重大な工学的厳密性を欠いてい��ます。絶対的な技術的規律を確立するため、本節ではコンテキストのライフサイクルを数学的に監査することを目的とした我々の提案アーキテクチャ評価フレームワークを概説します。
-
Langfuseトレースを想定したテレメトリ:ターゲットアーキテクチャは、各VFSパーティションのスワップ境界にライブトラッキングIDを統合します。本フレームワークは注意分布マップをキャプチャし、ランタイムのメモリ圧縮ループ中に個々のヘッドがどのように反応するかを正確に記録するよう設計されています。
-
ゴールデンデータセット設計図:推論の一貫性をストレステストするために、我々は30件の複雑なエンジニアリングPull Requestで構成された専用のリポジトリベースラインを設計しました。このスイートは複数ファイルの相互依存や複雑なコードブランチを取り入れ、客観的な評価ベースラインとして機能します。
推定性能軌道と実証的目標
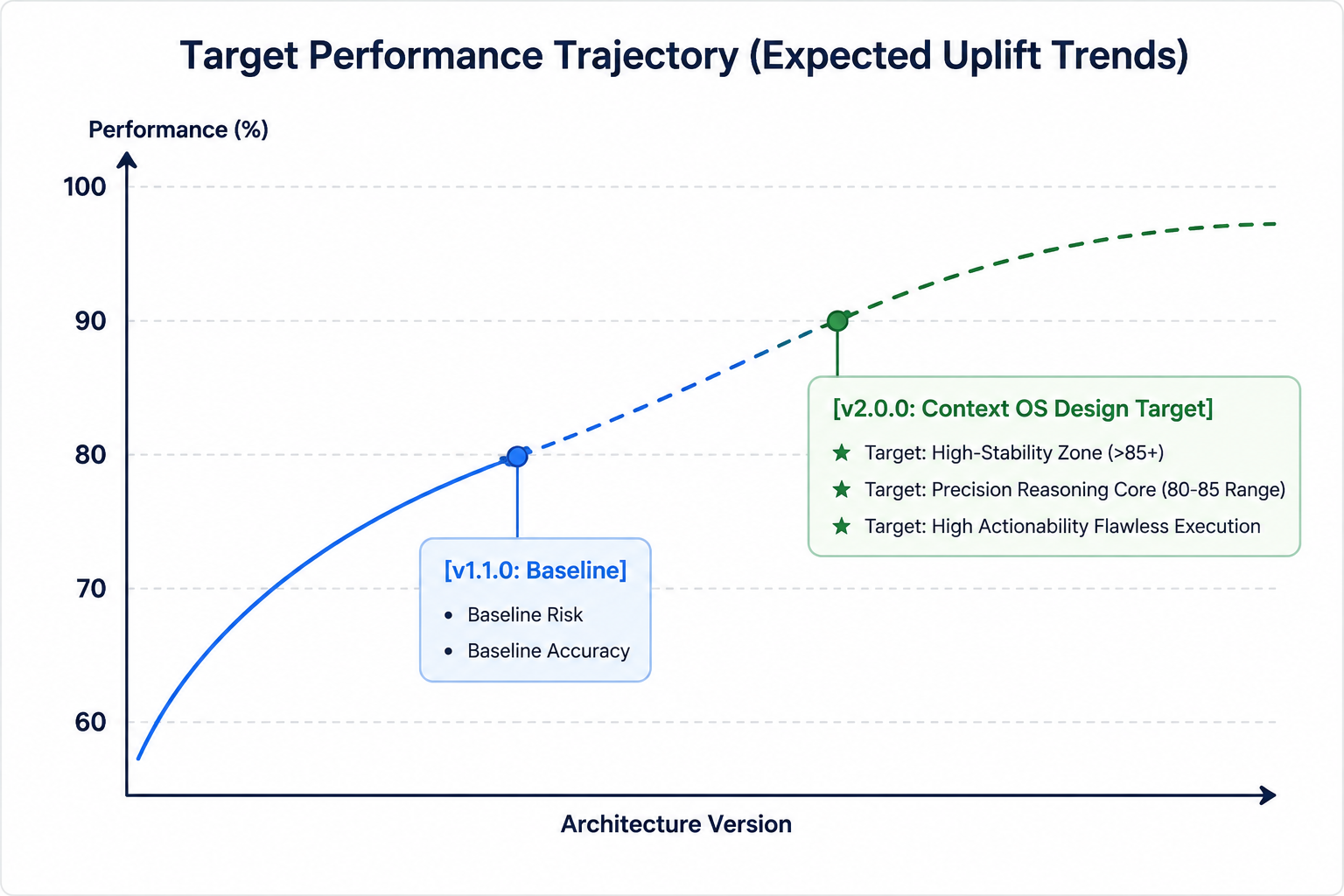
プロトタイプ段階で実施した初期の小規模実行では、従来のベースラインモデル(v1.1.0 - 標準的な文字列集約)とv2.0.0 Context OSアクティブメモリアーキテクチャを比較した際に、良好な性能軌道が示されました。
-
方法論整合性に関する免責事項:以下に示す指標は、コアとなるアーキテクチャ設計目標および期待される最適化傾向を表すものです。評価ハーネスは、フルスケールの企業生産ワークロードへ展開する前に絶対的な統計的再現性を確保するため、手法の継続的な較正を行っています。
軌道1:リソース最適化とトークン消費制限
初期の実行ループにおいて、sawtoothメモリモデル内のアクティブなコンパクション機構は、合計トークン割当の明確な下降軌道を示しました。生のトークンオーバーヘッドはベースライン(v1.1.0)と比較して約20%〜25%の削減を目標としています。/memoryから低重みの履歴ノードを体系的に削除することで、システムは非常に最適化されたランタイムフットプリントを目指します。
軌道2:精度の向上と信号対雑音の配分
従来のv1.1.0ベースラインでは、エージェントの技術的精度スコアは「lost in the middle」領域内での注意の減衰によって構造的に制約されていました。v2.0フレームワークでは、初期のトラッキングで最適な80以上の精度ゾーンへの改善が見込まれています。この軌道はPathAlignステージによって推進され、コンパイル済みの構文グラフのみがモデル境界に到達するようにすることで、信号対雑音比を約15%〜20%改善すると推定されます。
軌道3:ガバナンス継続性とリスク評価の境界
最も重要な軌道の変化はリスクおよび影響評価指標に現れ、85〜90以上の高い耐性ターゲットゾーンへ向かって上昇しています。読み取り専用の/rules VFSパーティション内に基盤となるポリシー��をロックすることで、長期のマルチターン推論ワークフロー中にエージェントが企業のコンプライアンスガイドラインを忘れたり逸脱したりすることを構造的に防ぎます。
結論:エンタープライズ市場における競争優位性
モデルはコモディティ、コンテキストアーキテクチャは知的財産である
人工知能エコシステムが急速に進化する中、最先端のファウンデーションモデルの基礎的能力は急速に集約されています。生の推論能力、ネイティブのコンテキストウィンドウサイズ、価格体系は主要クラウドプロバイダ間でコモディティ化しつつあります。この状況では、単にAPIを呼び出したりプロンプトに文字列を追加したりするだけでは持続可能な技術的優位性とはならず、基本的なインフラ作業に過ぎません。
2026年のエンタープライズAIシステムにとって決定的な競争上の優位性は、ファウンデーションモデルの重みにあるのではなく、それらのモデルの入力環境を統御するオーケストレーション層に完全に存在します。
Semantic Context OSは、アクティブなAIカーネルの導入、厳格な最小実行コンテキスト(MVC)パイプラインの適用、構造化されたVFSによるメモリ抽象化、そしてsawtoothモデルのような高度なランタイム圧縮アルゴリズムの適用により、LLMの注意の混沌と非決定性を高い規律を備えたエンタープライズ向けランタイム資産へと変換します。
最終的に、コンテキストレイヤの習熟こそが、単にテキストを生成するだけでなく、大規模で信頼性の高い複雑なソフトウェア工学タスクを確実に実行するAIエージェントを構築するための最後の工学的障壁です。
出典と参考文献の設計
厳格な工学的整合性と専門的な透明性を維持するため、本節では業界で確立された手法と、Context OSフレームワーク内で我々のチームが導入した固有の技術的発明との境界を明確にします。
業界標準の基盤
本研究の理論的な基盤は、国際的な人工知能コミュニティによって発展してきた基本的なパラダイムに基づいています:
- CPU–RAM比喩(Karpathyのメタファー):LLMの推論ループと現代のコンピューティングアーキテクチャとの概念的な整合性を説明するためにAndrej Karpathyが提唱したもの。
- “Lost in the Middle”の病理:Stanford University(Liu et al., 2023)による構造的評価論文 Lost in the Middle: How Language Models Use Long Context に記載されています。
- スケールド・ドットプロダクト注意:多頭注意メカニズム(Q、K、V行列)の数学的定式化であり、Googleの基礎論文 Attention Is All You Need(Vaswani et al., 2017)に由来します。
著者による主要な技術的発明
以下のコンポーネントは、企業規模のスケーリングボトルネックを解決するために著者らがスクラッチで設計・実装した独自のシステムアーキテクチャ、アルゴリズム、および実装を示します:
- Semantic Context OSフレームワーク:決定論的なメモリ配分を管理するために、独立したAIカーネルをローカルのインターセプトループバックプロキシ(
localhost:8080)として組み込むパラダイムシフト。 - VFSステートエンジン:フラットなトークンスペースをPOSIX風の別個のディレクトリパーティション(
/rules、/memory、/scratchpad、/environment)に抽象化し、厳格な振る舞いの分離ガードレールを実現する仕組み。 - sawtoothメモリモデル:「sawtoothメモリモデル」節で詳述した、動的なインフライトのランタイム圧縮アルゴリズムおよび非同期イベント駆動のトークン最適化デーモン。
- PathAlignステージ:ネットワーク境界でのASTツリーのトリミングを活用し、コンパイラの実行サブグラフを分離する特定の静的解析手法。
Tech-Verse 2026 を開催します(6月29日)

この記事は、イベントの公式記事として公開されました。
Tech-Verse 2026は、LINEヤフーが開催する技術カンファレンスです。
最先端の挑戦や積み重ねてきた知識を共有します。
YouTube LIVEでの配信をぜひご覧ください。
https://tech-verse.lycorp.co.jp/2026/ja/


