A/B tests play a crucial role in decision-making at LINE NEWS as they help determine what modifications to make and what experimental features to release. This is especially important given the high stakes involved: over three-fifths (*1) of the population of Japan regularly visit LINE NEWS, a web application seamlessly encapsulated inside the LINE messenger native app.
The previous architecture of our A/B testing system had its purpose, but it was far from efficient. It required frequent and sometimes verbose code deployment, especially at the frontend. This inability to change the behavior and appearance of the product until the next deployment date was slowing down the lead time from feature conceptualization to release.
To make our A/B testing operation more flexible, fast, and efficient, we redesigned our system and employed several software operation concepts and strategies. In this article, I will share how we incorporated these concepts, including decoupling releases from deployment, into our source code. The strategies I will discuss today are feature flags, remote configuration, and canary releases.
How we typically use an A/B test
Before discussing those strategies, let me explain how we typically use an A/B test for a new feature. Suppose we have a hypothesis that this new feature will improve user experience. To test this hypothesis, we allocate users to the control group (without the feature) and the treatment groups (which may include variations of the feature). We then collect user behavior data from each group. After analyzing the data statistically, we draw conclusions and gradually release the best variation of the feature.
The issues with the existing system
At LINE, some of our products, including LINE NEWS, use an internal A/B testing tool called Libra. Its role is to help us create an experiment instance with a name and to allocate users to experiment groups. Values created in this tool get sent and stored in our separate configuration server.
The previous A/B testing code base for LINE NEWS had experiment names and groups, created with the internal A/B testing tool, redundantly hard-coded on the frontend. The specifications of all feature variations were individually mapped to the A/B testing names and groups by developers in the TypeScript code base. The conditionals became complex when multiple A/B tests were running.
On the operational side, the issue was that the A/B testing procedures were both inflexible and repetitive. Even the slightest change to an existing A/B test required deploying new code. Because we deploy every two weeks, testing and releasing a new feature could sometimes take months. Frequent changes to source code also required more QA resources.
Taking full control of experimental features
What we needed was an approach that would enable us to release updates to the behavior and appearance of the experimental features outside of our scheduled deployment dates. Before delving into the details of our solution implementation, let's discuss a few strategies for software development and management.
Feature flagging allows you to activate or deactivate features without changing the source code or requiring a deployment. In other words, they are conditionals such as if-statements in the source code with boolean (true/false or on/off) values that are dynamically and remotely inserted. Historically, the terms "release" and "deploy" have been used interchangeably, but feature flagging separates feature releases from code deployment.
Feature flags alone could bring us great value (*2), but we wanted to go beyond just turning features on and off. We aimed to add other parameters to control the behavior and appearance of the feature. That's when we explored the concept of remote configuration.
Remote configuration is a more complex and capable version of feature flagging. Typically, software configurations are written either in the deployed source code or environment files. However, services like Firebase from Google have popularized remote management of configurations. Remote configuration comes in handy, especially in mobile native app development where they cannot easily modify production source code once it has been shipped as they must go through a review before they make an update.
Building on internal technologies instead of relying on third-party tools
A popular way to implement these techniques is to use third-party A/B testing suites, such as LaunchDarkly or Optimizely that come with user allocation, data tracking, and data analyzation capabilities. However, these options were not feasible for LINE NEWS as we send user behavior data to LINE’s internal data tracking and management systems so that business functions at LINE can utilize the data with appropriate authorization. Pairing only part of a third-party suite with our internal tools would require some unwanted hacks and/or unnecessary redundancy. Instead, we used LINE's open-source configuration server, Central Dogma, to store our feature flags and configurations, which provided the necessary functionality. At LINE NEWS, we call this set of data (the flag and configuration) feature configuration.
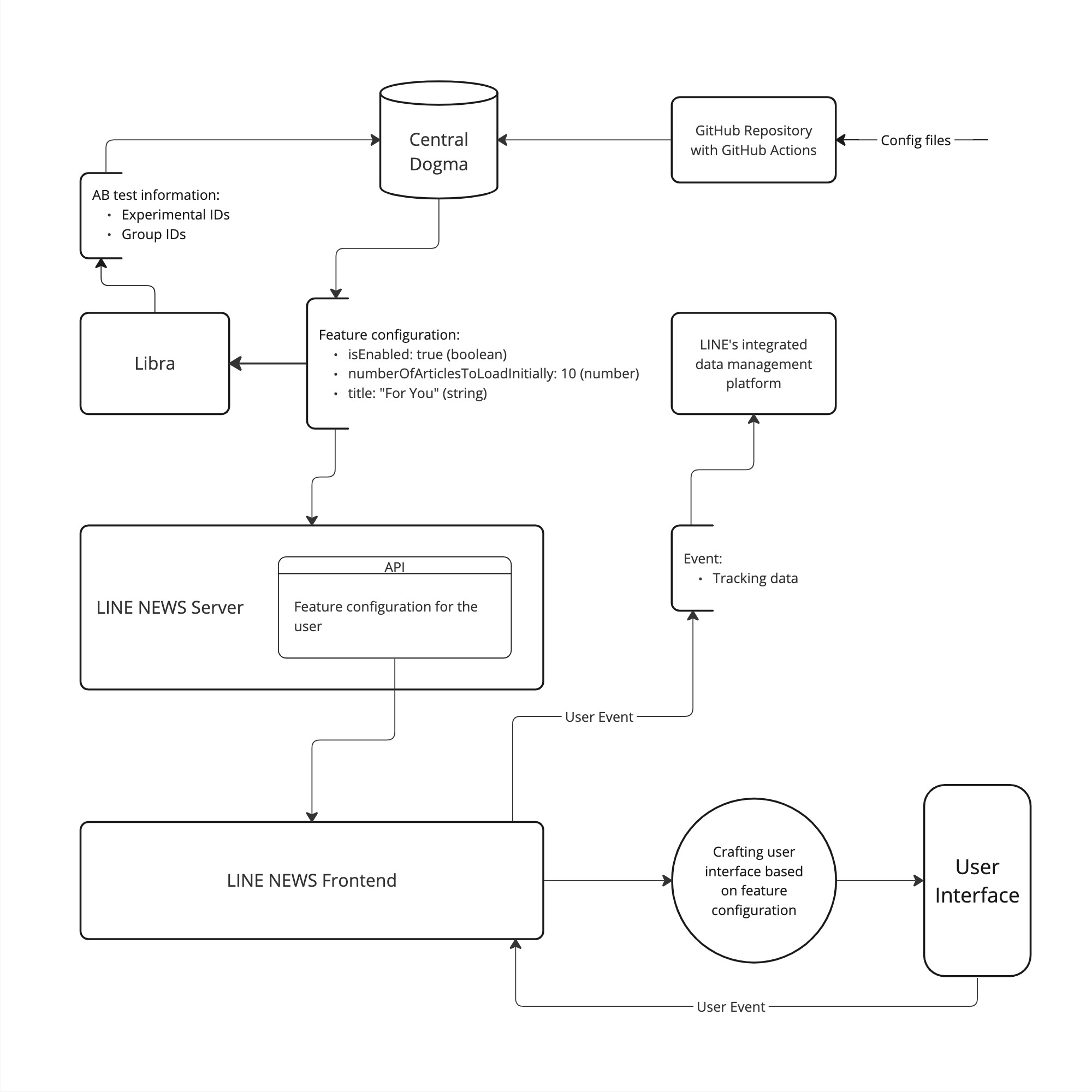
Using feature configuration
For our new system, we decided to store flags and configurations in the same location. For instance, for a specific feature, the flag would be the parameter isEnabled while other parameters could control the behavior and appearance of the same feature.
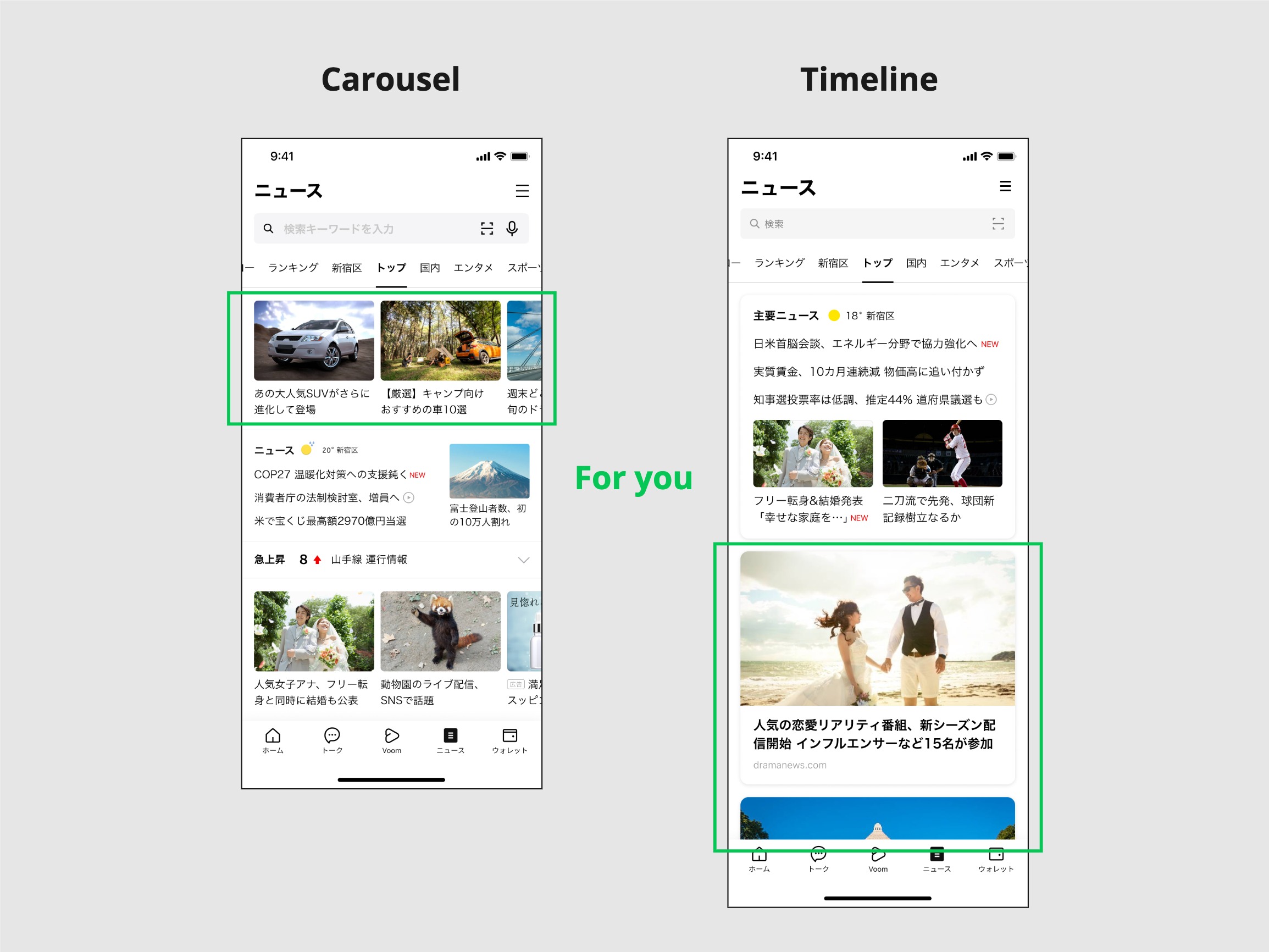
Instead of building a whole new CMS, we opted to take advantage of the JSON format that is designed for simplicity. Suppose the personalized articles are displayed in a carousel, which is a horizontally-scrollable user interface, and we were testing the new UI that displays the same articles vertically. We call it the timeline UI. On the configuration server, the data will look like this:
{
"timelineForyou": {
"isEnabled": true,
"numberOfArticlesToLoadInitially": 30,
"title": "Recommended based on your interests"
}
}The client-side code will simply look like this:
if (timelineForyou.isEnabled) {
// ...
}Assuming we have decided to rollout the timeline UI, the next step is to determine how many articles to load initially. Loading too many articles will slow down the initial page loading. Loading too few articles could decrease user experience as articles get "lazy-loaded" more often. In our previous system, we had to modify the source code and deploy it. With this new system, we can easily adjust the value of numberOfArticlesToLoadInitially from the remote repository. We can also change the title from "Recommended based on your interests" to something like "For You".
The image below describes how our "For You" section changed. In the left example, personalized articles are displayed in a carousel. In the right example (the current UI), the same content is displayed vertically. Note that it shows only the beginning and the end of our experiment. The actual process involved many trial and errors. For instance, how people perceive and interact with the "For You" section could be influenced by the appearance of other parts of the top page. To control these influencing factors, we ran multiple isolated A/B tests.
Conventions to make setting configs easier
There are a limited number of straightforward conventions. These are all the things the developers need to know to set configurations. Those conventions are:
- To tie the appropriate configuration to the specific experiment, the name of the JSON file must be the name of the experiment. For example, for the experiment named exp0001, the JSON file is named exp0001.json.
- Each level of the JSON object has a dedicated role: the experiment group (1st), the functionality (2nd), and (3rd) the configuration.
Here is an example of what’s inside exp0001.json:
{
"control": {
"timelineForyou": {
"isEnabled": true,
"numberOfArticlesToLoadInitially": 30,
"title": "For You"
}
},
"treatment": {
"timelineForyou": {
"isEnabled": true,
"numberOfArticlesToLoadInitially": 10,
"title": "For You"
}
}
}Ensuring safety with automation
To eliminate human errors and reduce bugs, we automated some processes:
- We could write feature configuration directly to the configuration server, but we created a GitHub repository with GitHub Actions as an extra layer of ensuring safety. The changes to configurations are reviewed by other developers in pull requests and are version-controlled.
- When developers push changes to a pull request in the Feature Config GitHub repository, GitHub Actions run the tests we wrote to check if the JSON format is complete to avoid errors. It also checks the functionality names (the second-level keys) are mutually exclusive among all files in the repository to avoid naming conflicts.
- When a pull request is merged into the main branch in the Feature Config GitHub repository, the configurations are updated in the configuration server automatically.
- When frontend code sends a request with the encrypted unique LINE user ID, the LINE NEWS server accesses the configuration server to retrieve data about experiments and determine which experiment group the user belongs to. It then provides only the necessary configuration for that user, enabling the frontend TypeScript code to build the UI with the specific configuration.
Minimizing cognitive load by hiding information
Our previous system had the LINE NEWS server provide data for all experiments after the frontend code made a request. This required the frontend code to perform the same task that the backend handles automatically in the new system as I mentioned in the previous section of this article. In other words, in the new architecture, experiment information, such as arbitrary experiment names, is not visible from the frontend. The frontend developers only need to mind which types of variables are in the configuration.
Additionally, storing the information about the configurations for variations of the experiment groups in a dedicated repository can also reduce cognitive load because the developers can separate implementing the UI and managing the configs in two different settings.
Maintaining reliability
Freedom and flexibility can often introduce complexity to software. To minimize risks, we do the following:
- Fallbacks are written in a dedicated module in the frontend code. It’s usually just the value
isEnabled: falsefor each functionality but even in the configuration server’s downtime, the application will still be live with the default behavior. - By turning on the feature only for QA devices, QA in production can be done.
- Because conditionals left in the source code even after tests are done become technical debt, we delete conditionals as quickly as possible and minimize the number of flags (with configuration or not).
With the new system, we have achieved the following:
- QA costs are where changes occur. By reducing code changes, we can use QA resources more efficiently.
- Another significant advantage of feature flags and remote configuration is avoiding big bang releases. This might be a good topic for the next post.
Implementation details with React
We use the React context to provide feature configuration so it can be used directly from anywhere in the UI component tree. We decided not to use a complex state management system. Configurations do not change over user actions during the session, so the simpler React context came in handy. Avoiding prop-drilling also minimizes code changes, too.
Below is a simplified example of our code. First, we create context with the default values written in the frontend code as the initial values. Setting the initial values is optional but recommended.
featureConfigurationContext.ts:
import { createContext } from 'react';
import { defaultFeatureConfiguration } from '../defaultFeatureConfiguration';
export const FeatureConfigurationContext = createContext({
...defaultFeatureConfiguration,
});Next, we overwrite the default values with the values sent from the remote repository and provide them.
App.tsx:
import { FeatureConfigurationContext } from './FeatureConfigurationContext';
const featureConfiguration = {
...defaultFeatureConfiguration,
...featureConfigurationData,
};
function App() {
return (
<FeatureConfigurationContext.Provider value="featureConfiguration">
...
</FeatureConfigurationContext.Provider>
);
}Using it is a breeze.
Feature.tsx:
import { FeatureConfigurationContext } from '../../FeatureConfigurationContext';
const { numberOfArticlesToLoadInitially } = useContext(
FeatureConfigurationContext
);
function Feature() {
return (
<SomeJsxElement>
// Here you can use numberOfArticlesToLoadInitially
</SomeJsxElement>
);
}Canary releases
Finally, canary releasing is a strategy that allows teams to rollout a feature to a small subset of users in order to reduce risks. LINE NEWS has been using this method for years. With the new architecture, we now have better control of the features as we can target which features to enable for which experiment groups. If something goes wrong, we can simply turn off the feature to avoid further damage.
1. 77 million monthly active users/15.4 billion pageviews per month (Our research, as of August 2021)
2. LINE's A/B testing tool Libra can turn an experiment on and off. When the experiment is set inactive, the feature's default behavior is usually the same as the behavior when the feature receives the flag value that is off. This means that we could achieve something similar to feature flagging by coupling an experiment and a feature. We had run projects in this way for a while before. However, using an experiment's active/inactive status to toggle a feature on and off was not a proper usage of Libra and required careful planning each time. With the new architecture, we solved this issue, too.


