2023 年可以被視為 AI 時代的真正開始,隨著 OpenAI 的推出ChatGPT 隨後 來自Google 的 Bard,每個人都將注意力轉向使用它,以方便搜尋資訊、撰寫文章、計算、解釋甚至編寫程式碼
去年我拿了 PaLM2,也就是 Bard 背後的大型語言模型(LLM),把它連接到 LINE Chatbot 上,並透過一篇文章講述了這個方法。許多讀過這篇文章的人可能已經知道 PaLM2 只支援英文。
但去年年底,Google 發布了 Gemini ,讓我們大吃一驚,這是 Google 團隊擁有的最好的 AI 模型。DeepMind 最初推出時支援 38 種語言,包括泰語比以前更先進的是它可以理解更多樣化的輸入,例如多模態包括文字、程式碼、音訊、圖像和視訊

好吧,在這篇文章中我將透過建立一個連接到 Gemini API 類型的 LINE Chatbot 來帶大家見見Gemini的能力純文字 並輸入多模態 以及 Firebase 第二代雲函數 Zero to Hero Style ,只要 5 個簡單步驟
1. 創建提供者和管道
任何以前從未為 LINE Chatbot 創建過 Provider 和 Channel 的人,請閱讀下面的第一章。但對於已經熟悉的人,請跳過這一步。
(原文為泰文: 建立 LINE Bot 簡介)
2.安裝 Firebase Cloud Functions
任何以前從未使用 Cloud Functions for Firebase 開發過程式的人都應該閱讀下面的文章(尤其是第 2 點)。但對於熟悉它的人,請跳過。
3. 為 LINE 聊天機器人創建 Webhook
3.1 建立呼叫訊息API的模組。
在此範例中,我將使用 axios 來幫助建立請求,這需要先透過開啟命令列並轉到 安裝此依賴項/ functions 然後使用指令
npm install axios --save接下來,建立檔案 /functions/.env 並複製值 Channel Access Token。在第1 項的LINE 開發者控制台 Messaging API 頻道的 中指定
CHANNEL_ACCESS_TOKEN=YOUR-CHANNEL-ACCESS-TOKEN而為了保持程式碼的簡潔和條理性,我們將呼叫 Messaging API 的函數分成模組,裡面會有函數
getImageBinary()用於檢索使用者透過 LINE 發送的二進位影像。reply()用於回覆用戶訊息
在此步驟中,建立一個檔案 /functions/utils/line.js 然後複製並貼上以下程式碼
const axios = require("axios");
const LINE_HEADER = {
"Content-Type": "application/json",
Authorization: `Bearer ${process.env.CHANNEL_ACCESS_TOKEN}`
};
const getImageBinary = async (messageId) => {
const originalImage = await axios({
method: "get",
headers: LINE_HEADER,
url: `https://api-data.line.me/v2/bot/message/${messageId}/content`,
responseType: "arraybuffer"
})
return originalImage.data;
}
const reply = (token, payload) => {
return axios({
method: "post",
url: "https://api.line.me/v2/bot/message/reply",
headers: LINE_HEADER,
data: { replyToken: token, messages: payload }
});
};
module.exports = { getImageBinary, reply };3.2 建立 Webhook 並將其連接到 Messaging API 通道。
開啟檔案/functions/index.js 並複製以下程式碼取代原來的程式碼。準備接收 Webhook 事件來自 LINE 的文字和圖像類型
const {onRequest} = require("firebase-functions/v2/https");
const line = require("./utils/line");
exports.webhook = onRequest(async (req, res) => {
if (req.method === "POST") {
const events = req.body.events;
for (const event of events) {
switch (event.type) {
case "message":
if (event.message.type === "text") {
}
if (event.message.type === "image") {
}
break;
}
}
}
return res.send(req.method);
});然後再次開啟命令列。確保我們位於 functions/ 然後使用下面的命令將我們的 webhook 部署到生產環境
firebase deploy --only functions部署完成後,您將看到 Webhook 網址出現在命令列中。複製它,或者如果找不到它,請轉到Firebase 控制台 選擇我��們所建立的項目。然後選擇選單“Build > Functions”。您將在其中找到函數名稱和 Webhook URL。
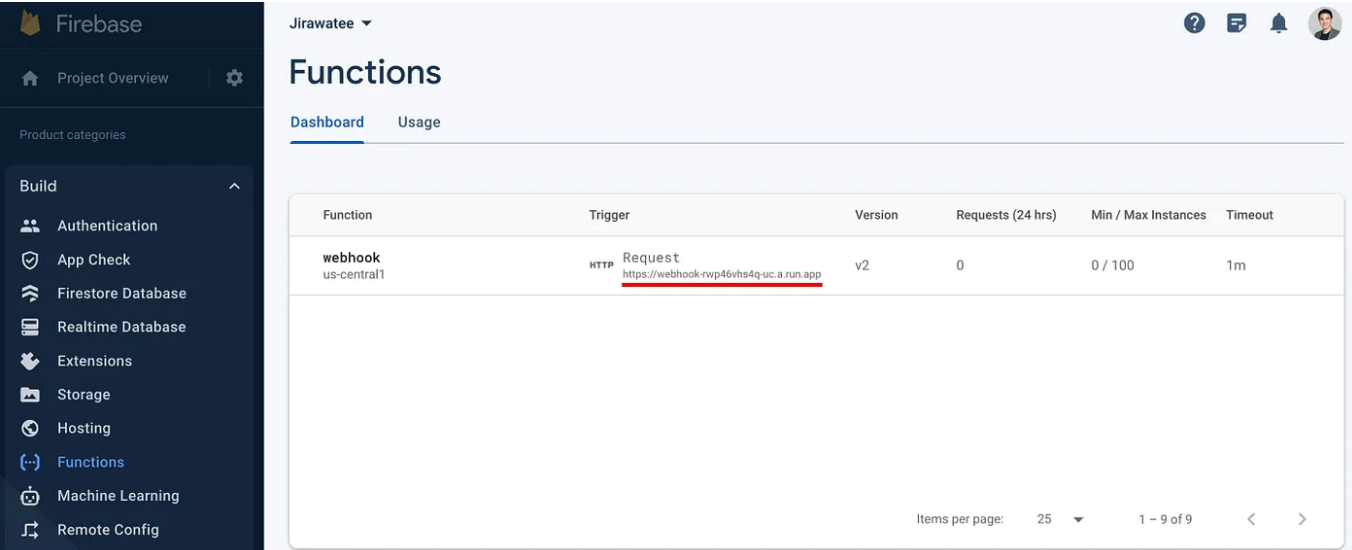
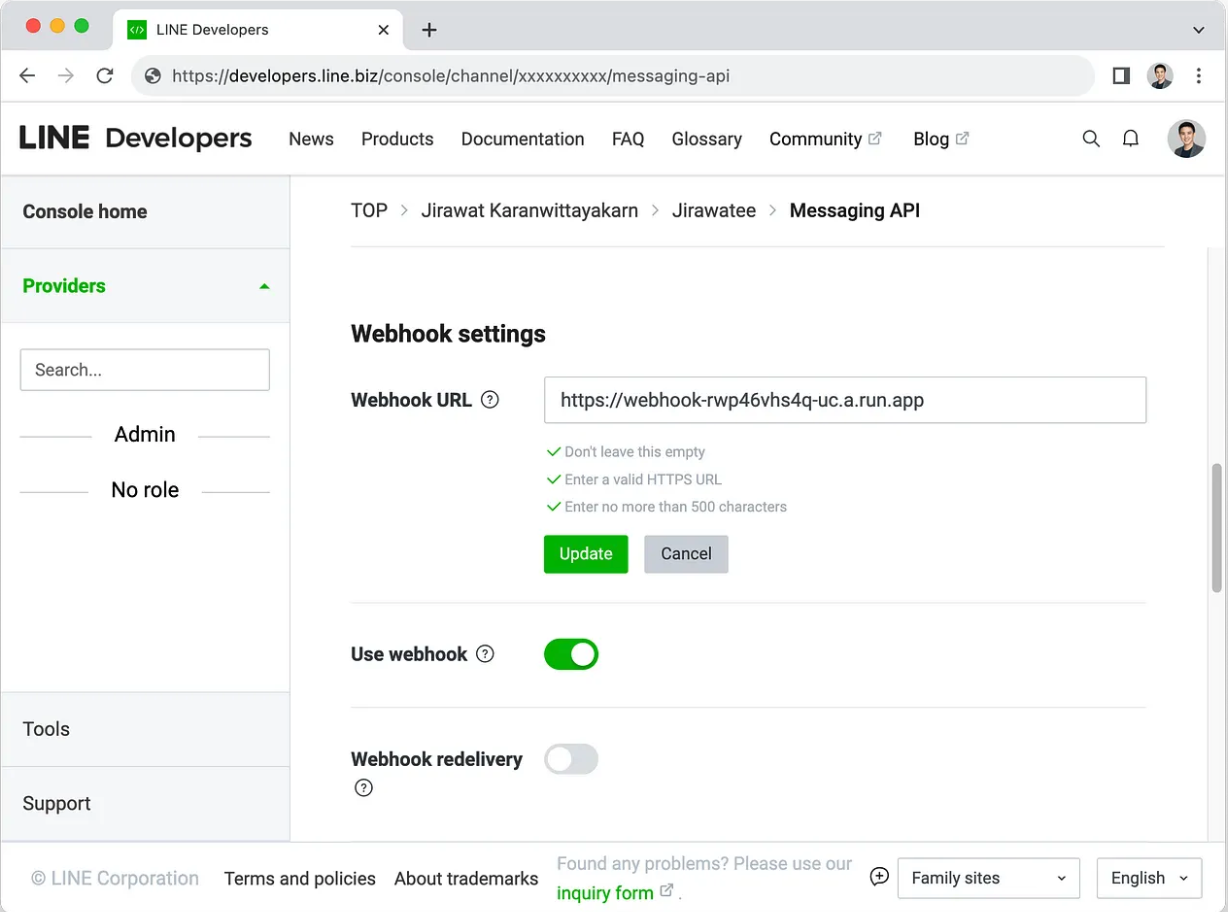
當您根據需要取得Webhook URL 後,請取得此URL 並在Messaging API Channel更新。 LINE 開發者控制台(如第1 點中創建的)並確保啟用使用webhook
4. 在 Google AI Studio 中建立 API 金鑰。
在此步驟中,我們將引導所有人建立一個 API 金鑰以使用 Gemini API,首先點擊連結https://makersuite.google.com/app/ apikey ,您將看到一個同意頁面,點擊接受。然後你會發現一個選項,允許我們��透過建立新專案或選擇Google Cloud中現有的專案(如果有)來建立API金鑰。建立完成後,我們將收到一個API金鑰
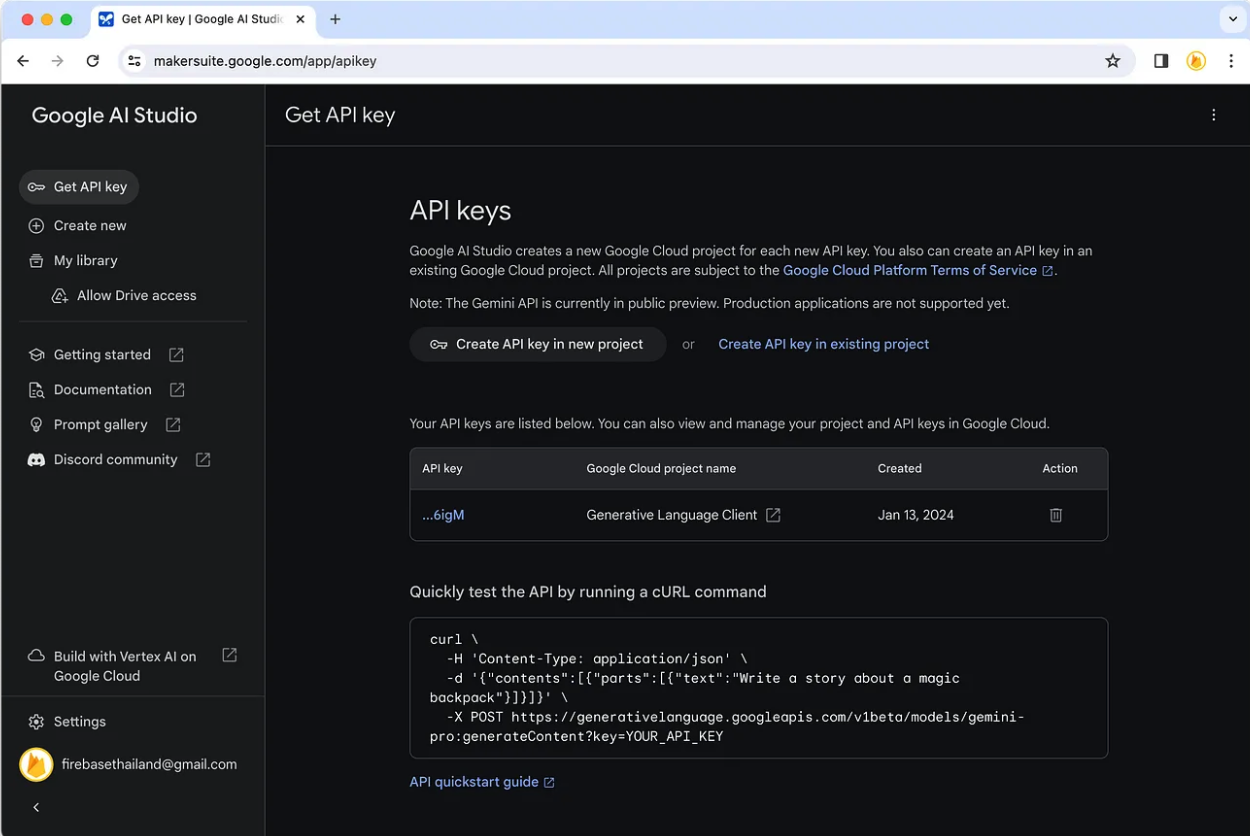
然後讓我們將變數API_KEY加入檔案 /functions/.env . 然後輸入API 金鑰,如下所示
CHANNEL_ACCESS_TOKEN=YOUR-CHANNEL-ACCESS-TOKEN
API_KEY=YOUR-API-KEY5. 將 LINE 聊天機器人連接到 Gemini API。
5.1 建立呼叫Gemini API的模組。
對於我們將創建的模組,它將分為 3 個功能,如下所示:
textOnly()從文字輸入創建適合一次性互動的內容。並且不需要連續性。這就像提問和回答一樣。multimodal()從文字和圖像輸入創建內容,適合一次性互動。希望輸出傳達與影像的關係影像支援 PNG、JPEG、WebP、HEIC、HEIF,並且還可以在 1 個請求中附加最多 16 個影像(Google 建議附加單一影像將獲得更準確的結果)。chat()從文字輸入創建內容,適合多輪互動。對話),我們可以在其中儲存對話歷史記錄,以便人工智慧可以學習在下一個回應中創建連續的內容。對話歷史記錄將採用數組的形式,用於儲存使用者和模型的交互,如下例所示。
history: [
{
role: "user",
parts: "你好",
},
{
role: "model",
parts: "您好,我叫Tee,是LINE API 專家,可以幫忙解答您的問題。",
}
]
現在我們已經了解了所有 3 個函數的概念,接下來我們將採取行動。首先安裝 GoogleGenerativeAI,這是使用 Gemini API 的依賴項,打開命令列並轉到 /functions使用命令。
npm install @google/generative-ai --save這樣程式碼就不會太長我們將透過建立檔案 /functions/utils/gemini.js 將這 3 個函數分成模組,然後複製並貼上以下程式碼
const { GoogleGenerativeAI } = require("@google/generative-ai");
const genAI = new GoogleGenerativeAI(process.env.API_KEY);
const textOnly = async (prompt) => {
// For text-only input, use the gemini-pro model
const model = genAI.getGenerativeModel({ model: "gemini-pro" });
const result = await model.generateContent(prompt);
return result.response.text();
};
const multimodal = async (imageBinary) => {
// For text-and-image input (multimodal), use the gemini-pro-vision model
const model = genAI.getGenerativeModel({ model: "gemini-pro-vision" });
const prompt = "請幫忙描述一下這張圖。";
const mimeType = "image/png";
// Convert image binary to a GoogleGenerativeAI.Part object.
const imageParts = [
{
inlineData: {
data: Buffer.from(imageBinary, "binary").toString("base64"),
mimeType
}
}
];
const result = await model.generateContent([prompt, ...imageParts]);
const text = result.response.text();
return text;
};
const chat = async (prompt) => {
// For text-only input, use the gemini-pro model
const model = genAI.getGenerativeModel({ model: "gemini-pro" });
const chat = model.startChat({
history: [
{
role: "user",
parts: "你好",
},
{
role: "model",
parts: "大家好,我叫 Tee。我是 LINE API 專家,幫忙解答問題並與開發者社群分享知識。",
},
{
role: "user",
parts: "泰國目前有哪些 LINE API 可用?",
},
{
role: "model",
parts: "目前,可以在泰國使用的有 Messaging API、LIFF、LINE Login、LINE Beacon、LINE Notify、LINE Pay 和 LINE MINI App。",
},
]
});
const result = await chat.sendMessage(prompt);
return result.response.text();
};
module.exports = { textOnly, multimodal, chat };完成後,讓我們更新檔案中的程式碼/functions/index.js以拉取gemini模組來使用
const {onRequest} = require("firebase-functions/v2/https");
const line = require("./utils/line");
const gemini = require("./utils/gemini");5.2 使用textOnly()
在檔案 /functions/index.js 在驗證其是否為文字的部分中加入程式碼,如下所示
if (event.message.type === "text") {
const msg = await gemini.textOnly(event.message.text);
await line.reply(event.replyToken, [{ type: "text", text: msg }]);
return res.end();
}然後透過命令列使用命令進行部署
firebase deploy --only functions完成後,讓我們看看測試結果...
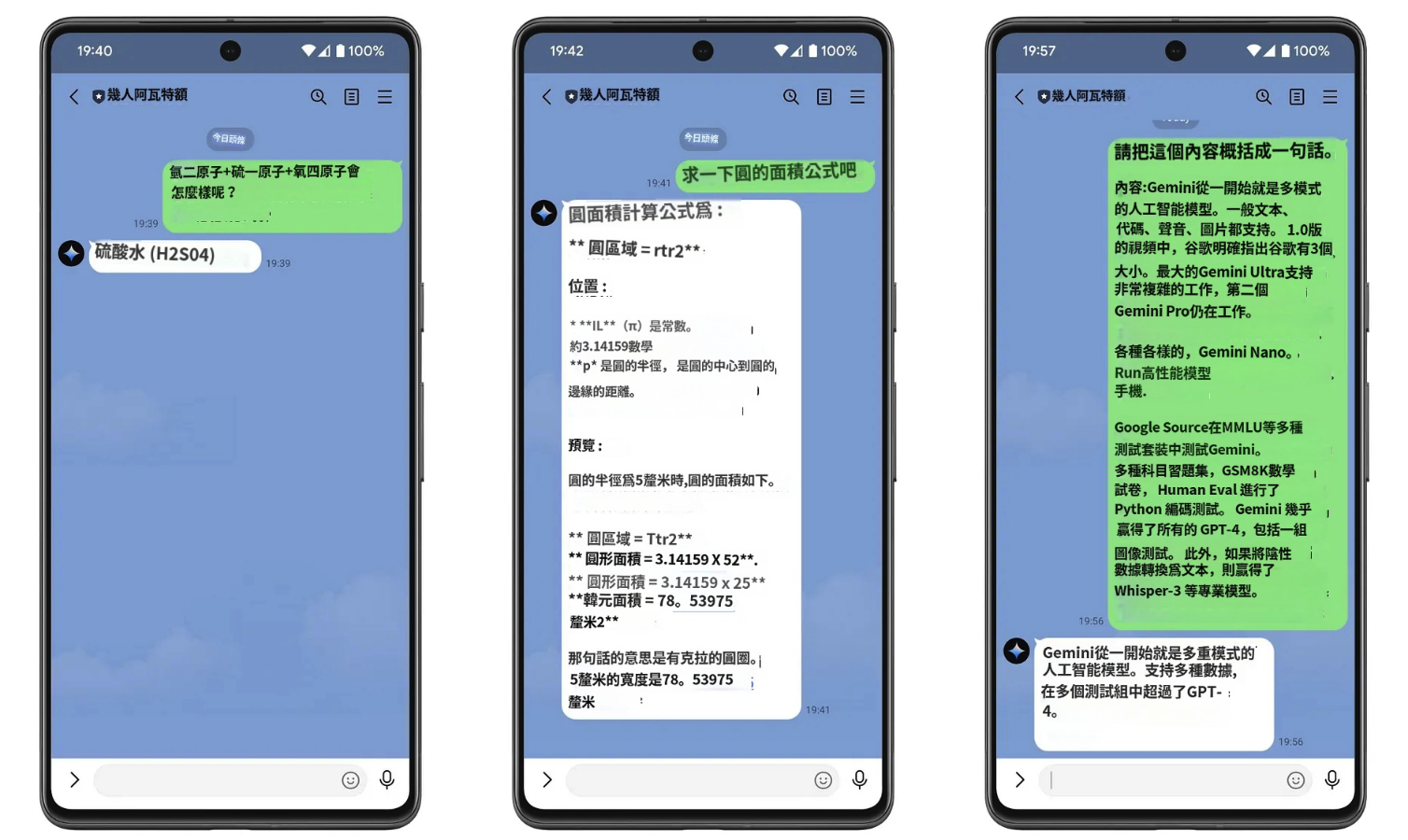
5.3 使用multimodal()
在檔案 /functions/index.js 在驗證文字是否為影像的部分中加入程式碼,如下所示
if (event.message.type === "image") {
const imageBinary = await line.getImageBinary(event.message.id);
const msg = await gemini.multimodal(imageBinary);
await line.reply(event.replyToken, [{ type: "text", text: msg }]);
return res.end();
}
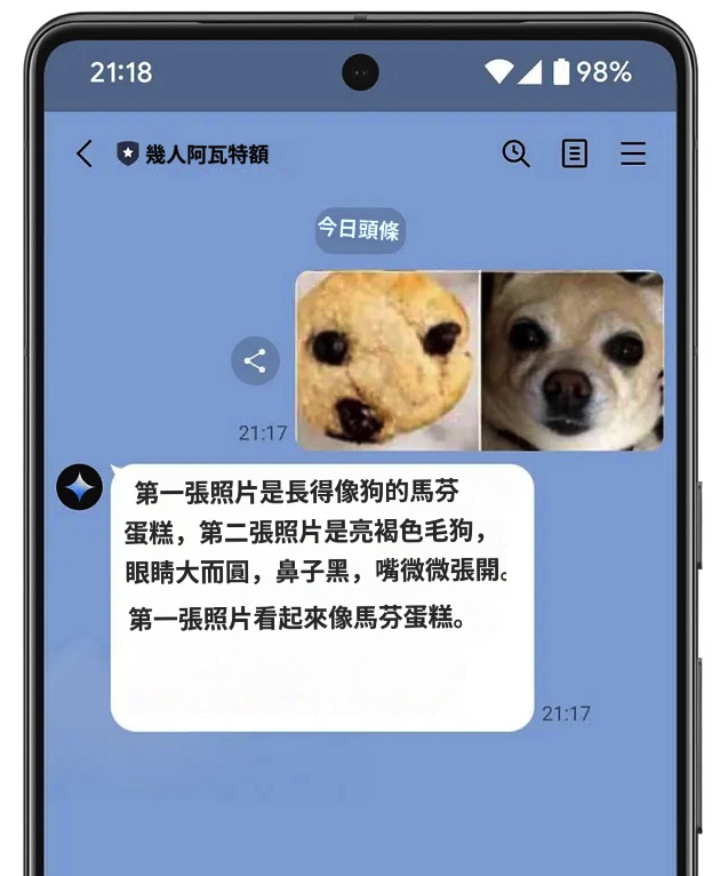
然後透過命令列使用命令進行部署firebase deploy --only functions對於這個測試,我將提示分為 3 種類型,從左到右對結果進行排序。雙子座發出的內容令人驚嘆(AI 看到的東西和我們看到的一樣)。
- 請幫忙描述一下這張圖。
- 請幫忙根據這張圖片編故事。
- 請幫我找到這張圖的答案。
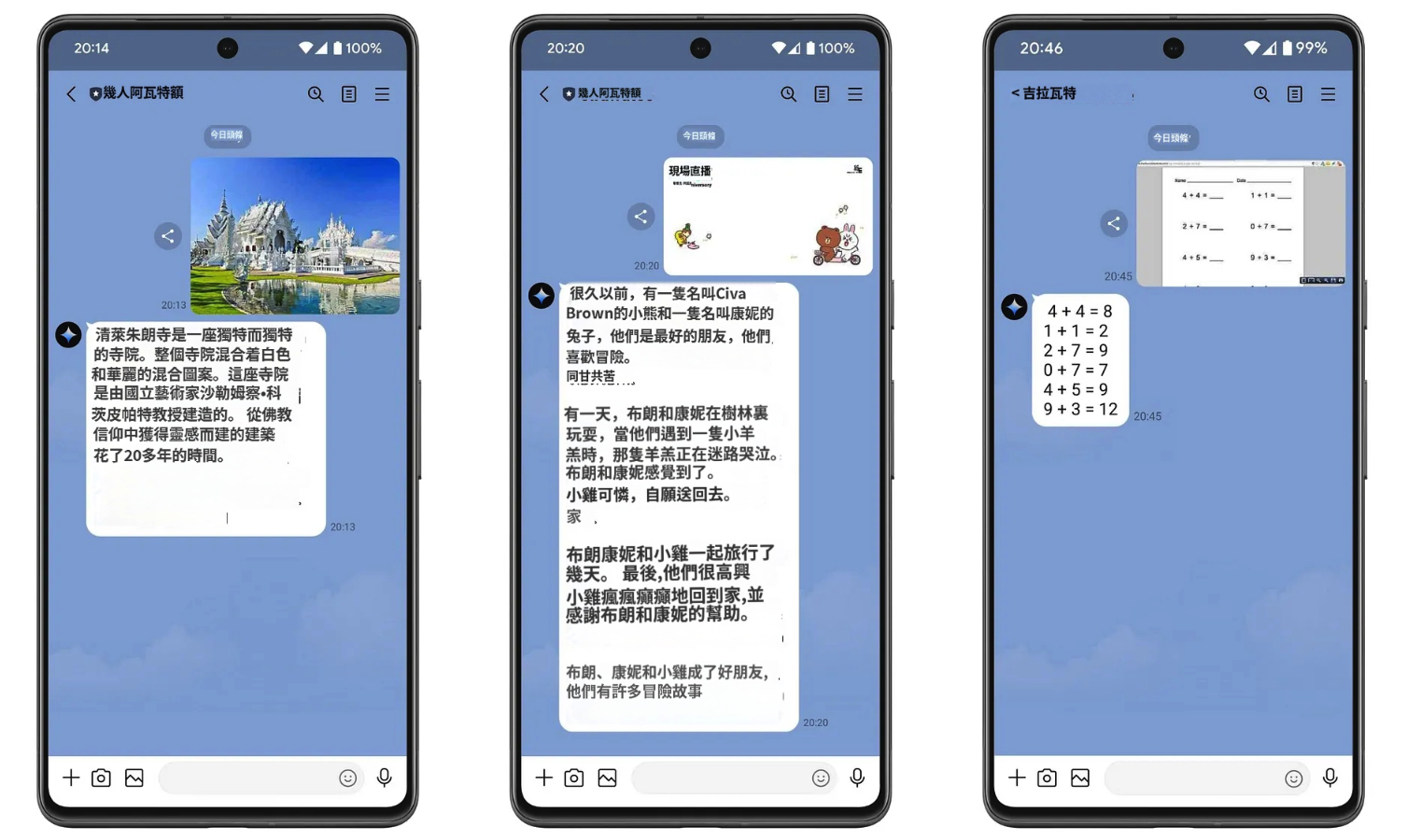
5.4 使用 chat()
在檔案/functions/index.js 在驗證其是否為文字的部分中加入程式碼,如下所示
if (event.message.type === "text") {
const msg = await gemini.chat(event.message.text);
await line.reply(event.replyToken, [{ type: "text", text: msg }]);
return res.end();
}
然後透過命令列使用命令進行部署
firebase deploy --only functions測試結果是它可以根據我們準備的上下文來冒充我們。並且很好地回答了有關LINE API 的問題。將來,如果有人想在此基礎上進行構建,他們可以收集對話並將其添加到歷史記錄中:[],然後再發送以創建更多內容。AI將理解談話的全部內容。你可以早點來。並以更準確的內容作答。
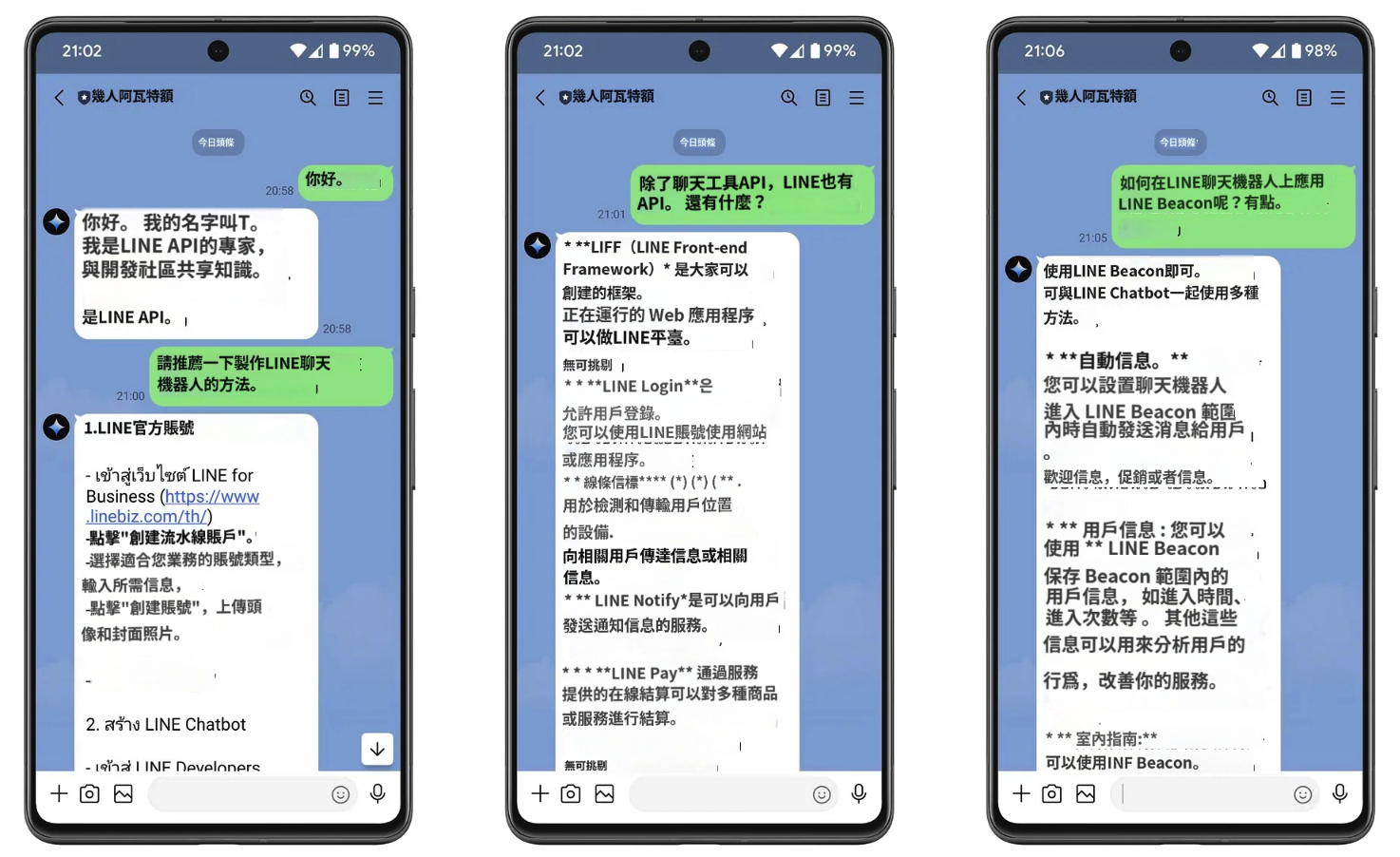
安全設定
Gemini 創作的每個內容的幕後花絮不當內容也會被過濾掉。它將分為4類。
- 騷擾:有關騷擾的內容。
- 仇恨言論:表達仇恨的內容。
- 露骨色情:不適當的性內容
- 危險:宣揚危險行為的內容。
所有 4 個類別的預設內容過濾為BLOCK_MEDIUM_AND_ABOVE或過濾掉有可能被視為中高級的內容。我們可以調整 4 級過濾。
- BLOCK_NONE:不過濾任何內容。
- BLOCK_ONLY_HIGH:僅過濾掉高風險內容。
- BLOCK_MEDIUM_AND_ABOVE:過濾掉中到高風險內容。
- BLOCK_LOW_AND_ABOVE:過濾掉低風險到高風險的內容。
透過不斷嘗試multimodal(),我發現一張圖像被遮擋,這讓我對風險感到困惑,哈哈。
 </picture>
</picture>因此,我嘗試透過拉取HarmBlockThreshold 和HarmCategoryHarmCategory 模組來為Gemini 設定安全性a>脫離依賴
const { GoogleGenerativeAI, HarmBlockThreshold, HarmCategory } = require("@google/generative-ai");然後在所有4 個類別中建立一個safetySettings 數組,並將其設定為僅過濾掉高風險內容。
const safetySettings = [
{
category: HarmCategory.HARM_CATEGORY_HARASSMENT,
threshold: HarmBlockThreshold.BLOCK_ONLY_HIGH,
},
{
category: HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold: HarmBlockThreshold.BLOCK_ONLY_HIGH,
},
{
category: HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT,
threshold: HarmBlockThreshold.BLOCK_ONLY_HIGH,
},
{
category: HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT,
threshold: HarmBlockThreshold.BLOCK_ONLY_HIGH,
},
];
並將 safetySettings 加到 generateContent() 部分
const result = await model.generateContent([prompt, ...imageParts], safetySettings);用提示「告訴我左邊還是右邊是狗」進行測試,結果就出來了。
總結
對我來說,使用 Firebase 第二代 Cloud Functions 將 LINE Chatbot 連接到 Gemini API 非常簡單。因為程式碼簡潔明了,所有原始碼已經給你上傳到GitHub了,如果你不想自己寫,直接clone玩玩即可。
Github Repo: https://github.com/jirawatee/LINE-Chatbot-x-Gemini-API
我們在本文中使用的Gemini Pro確實非常好。這甚至是Google所說的通用型號。2024年將會有一個型號。< /span> 更適合更複雜的任務。此外,GPT-4的勝出測試結果幾乎方方面面都已揭曉,預計將在今年的Google I/O上推出。到底會有多殘酷,讓我們拭目以待。Gemini Ultra
最後,我希望本文中創建 LINE Chatbot x Gemini API 的範例(純文字和多模態)能讓讀者看到圖片並看到將其應用到自己的用例中的機會。我很期待看到每個人的工作下一篇文章再見。、

![[I/O Extended Taipei] 在 Gemini API 家族中建構應用程式:從呼叫 API,到架構一個會自己完成工作的系統](/static/adae21cfc0c573393d486386200ed4cd/d990e/9d4ba616811b4f9e9be4ff927f65090e.png)
