
KDD (Knowledge Data Science and Data Mining) 為 ACM (Association for Computing Machinery) 主辦的頂級資料挖掘論壇;
2023 在美國加州洛杉磯郡的長堤會議娛樂中心 (Long Beach Convention & Entertainment Center) 展開連續 5 天的綜合型會議 (08/06-08/10) ,
其中包含 conference、workshop、tutorial 和國內外頂尖大學電資學院熱愛組隊參加的 KDD cup,
這次我參加的是 08/06-08/08 的 workshop 和 tutorial。

KDD workshop 和 tutorial 遍及資料科學各項領域,學界業界高手雲集,除了 FAAMG 外也有不少灣區或美國知名企業派員參加,
例如 NVIDIA、Uber、Airbnb、eBay 和 Walmart,企業攤位也是滿滿人潮。
由於每場 workshop/tutorial 為期半天,權衡之下只好挑出與 LINE 台灣 EC 資料工程團隊在資料科學與機器學習業務相關場次,
主要環繞在用戶歷程建置與分析、深度學習推薦系統與搜尋引擎延伸服務。

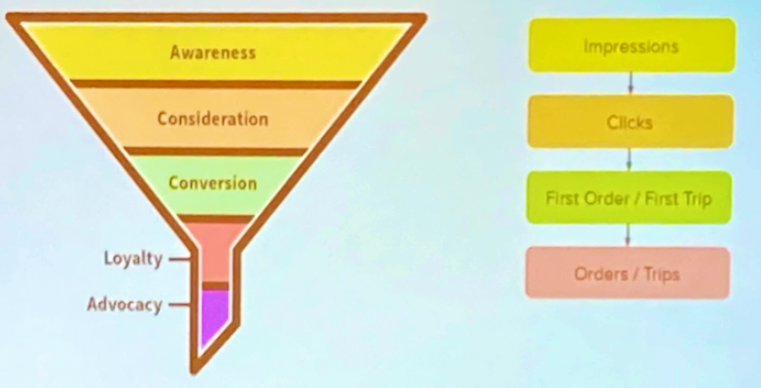
首先第一場為用戶歷程 workshop, End-End Customer Journey

Unveiling the Guest & Host Journey: Session-Based Instrumentation on Airbnb Platform
講者: Shant Torosean (Airbnb)
我們在收集用戶歷程時常會遇到該如何將用戶在 UI 元件上的操作 (e.g. 拖拉、點擊等 ) 轉換成可以使用的資料。
在這個主題中講者提到不要單一去觀察用戶的單點行為,而是該將一系列的活動轉變成一組 session,
以 Airbnb 訂房服務為例,即是把 search page, listing page 和 checkout page 串為 session 用來代表用戶的 booking journey。

有向路徑屬性圖 (Directed Path-based attribution)
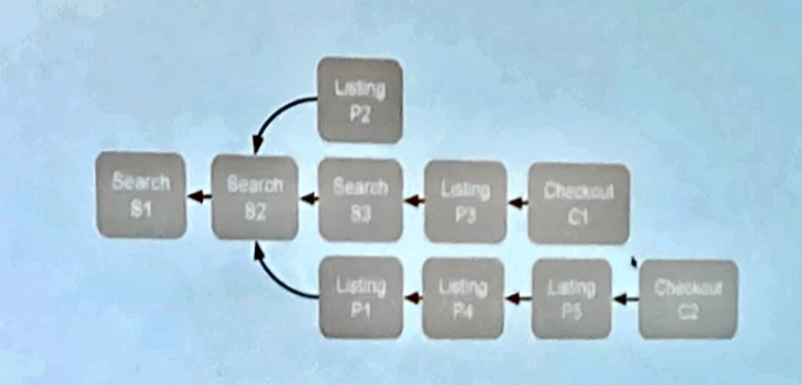
本講次關鍵分享為
-
用��心設計如何取得關鍵資料是最有效的解決方案
-
相較於採購外部解決方案並在後續規劃如何教育團隊使用, 自行開發實作相對實惠
-
維護 session 的生命週期是很耗團隊時間的, 記得依照商業價值排好各類 session 建制的優先順序
Devoted to Long-Term Adventure: Growing Airbnb Through Measuring Customer Lifetime Value
講者: Sean O’Donnell & Jason Cai & Linsha Chen (Airbnb)
CLV (Customer Lifetime Value) 現今趨勢為 Machine Learning。
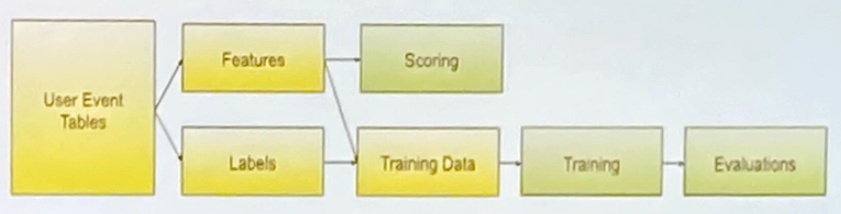
- 在用戶事件上通常專注於處理兩種面向的資料, feature 和 label。
- 在系統設計上以追求預測精準度 (precision) 為主要考量,
工程上利用模型迭代運算 (Logistic Regression/SparkGBT/XGBoost)。
- 但缺點是相當顯著的,需要帶入市場銷售上的 domain knowledge。
Airbnb 資料科學團隊希望導入 HMM (Hidden Markov Model) 來解決需要人為帶入 domain knowledge 的困擾。
在 CLV 的案例中將以 booking 和 search 等 "Active" 狀態來預測 "Inactive" 狀態 (該用戶/其他用戶 booking 的機��率)。
系統設計如下
- 用戶互動: MTA (Multi-Touch-Attribute) 系統
- 資料區間: 80 天
- ML 模型: LSTM
- 模型評估指標: SHAP (SHapley Additive exPlanations)
定義: Future Incremental Value (FIV) 計算 Markerting (AD)和用戶 Booking 資料未來所能帶來的價值,
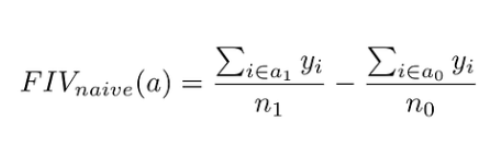
n1 數量的用戶於這個月 booking
n0 數量的用戶在這段時間沒有 booking
接下來的一年中用戶產生的 revenue 定義為 y
這個 naive approach 可以很簡單的計算固定期間用戶 booking 和沒有 booking 帶來的效益
Multi-objective Online Advertisement Budget Allocation
講者: Yang Cao & Shiyao Guan (Uber); Tushar Shanker (NA); Mert Bay (Noom)
當新用戶加入時公司需要花很多費用在數位行銷平台,行銷團隊無法很精確的將行銷活動預算效用最大化。
- Uber 行銷活動層級
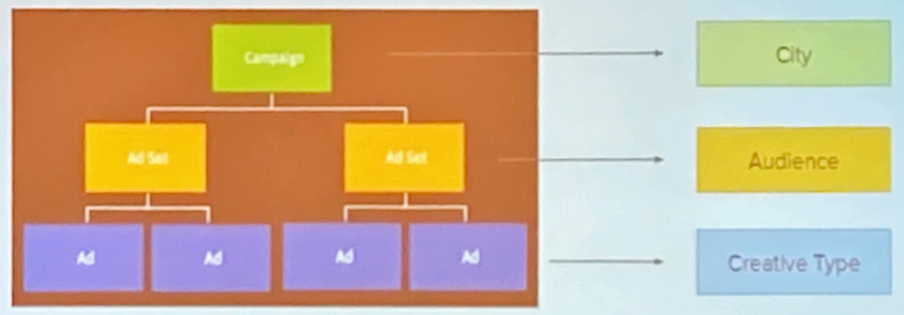
- 事件位階
傳統的行銷做法將會帶來下述的許多困境
- 手動配置
- 很難因應不同的行銷目標 (impression/click/first conversion/long-term value 都可能是最大化的方向)
- 不是 data-driven
- 可能會產生 suboptimal 的結果
- 無法 scalable
- 第三方解決方案
- 無法為了公司的方向做客製化
- 個資還有資安等議題
- 整合有額外開銷 (e.g. 串接 API 需要開發人員與溝通成本)
- 沒辦法 in-house 支援
這裡團隊提出了多目標貝葉斯 Bandits (Multi-Objective Bayesian Bandits) 演算法
- Multi-Objective
- 支持多種目標最佳化
- 流量指標 - Impression, Click, First Conversion, Total Sales
- 效率指標 - Cost per impression, Cost per click, Cost per First Conversion, Total Sales per Conversion
- 支持多種目標最佳化
- Bayesian
- 調整風險
- 提升學習提升學習效率
- Bandits
- 探索和再利用
至於 Bandits 如何該最佳化呢?
- 利用指標來抽樣資料分布
- 計算並標準化每項指標的信賴區間
- 計算並標準化每場行銷活動的 weighted reward
- 計算最後的分配比例
Q&A
- Q: Reward 怎麼計算比較合適? (Reinforcement Learning 中很關鍵的問題)
- A: 團隊建議依照擁有資料型態選擇其中一種方式
- Sliding window
- Cumulative
Unlocking Sales Growth: Account Prioritization Engine with Explainable AI
講者: Suvendu K Jena & Jilei Yang & Fangfang Tan (LinkedIn Corporation)
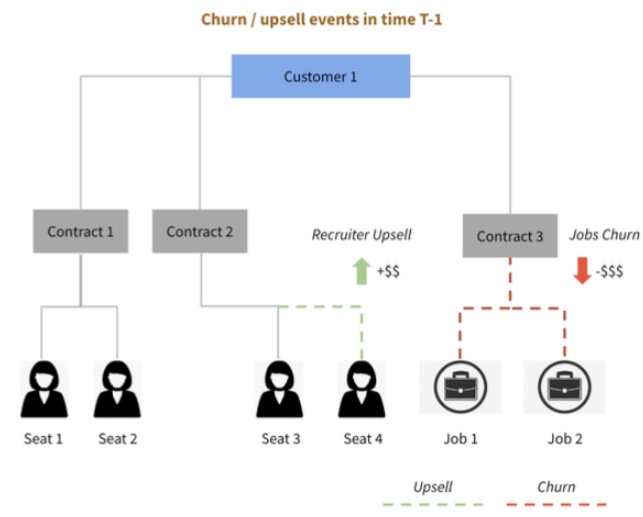

業務代表通常是依賴 「直覺」 和片段的資料訊息去評估客戶價值,但這其實是很吃重經驗傳承與個人特質。
為了解決自動評估客戶價值,團隊以建造 Account Prioritizer 為目標,希望用 AI 改善這個問題。
- A/B test 增加 8.08% Avg RIG
- MAU 增加 20.4 Avg RIG
Account Prioritizer
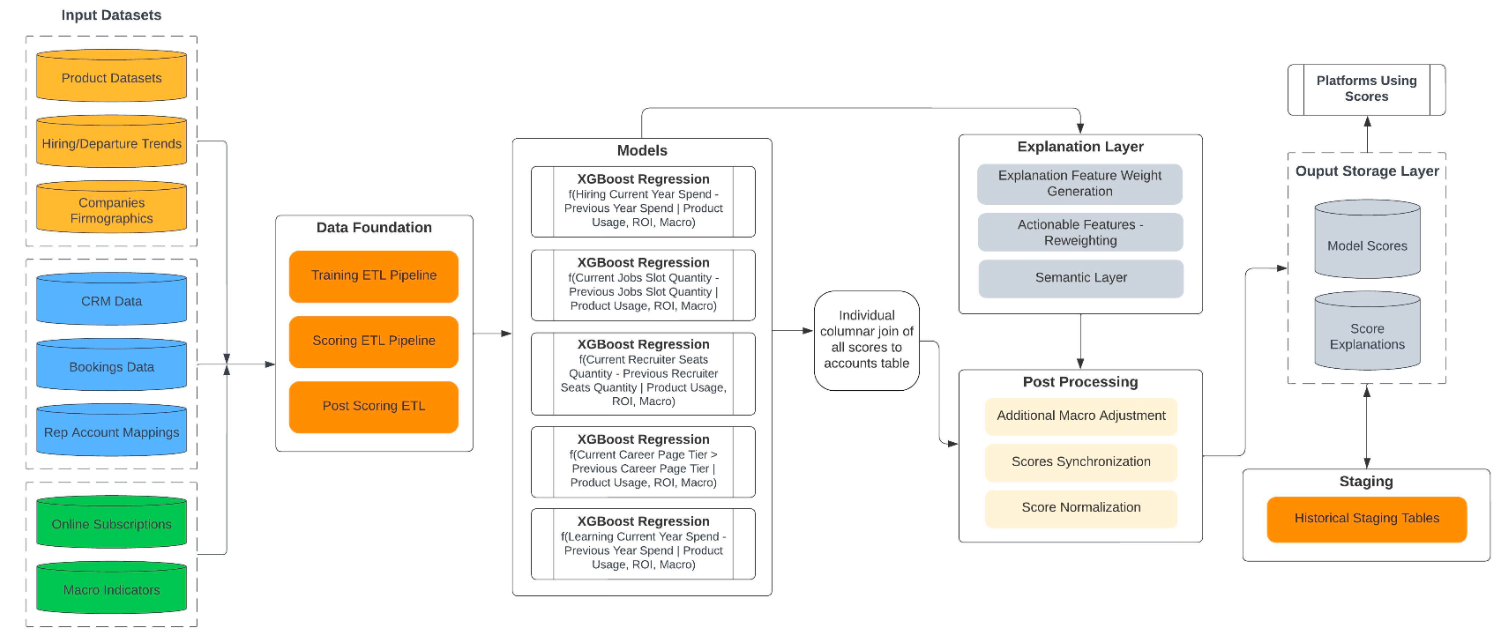
Account prioritizer engine 架構設計大體上跟一般 ML 解決方案類似,其中最關鍵的為 Explanation Layer;
在 Explanation Layer 會在 Spark 平台上進行多項 document representation
(這個 user-facing model explainer 團隊命名為 CrystalCandle)
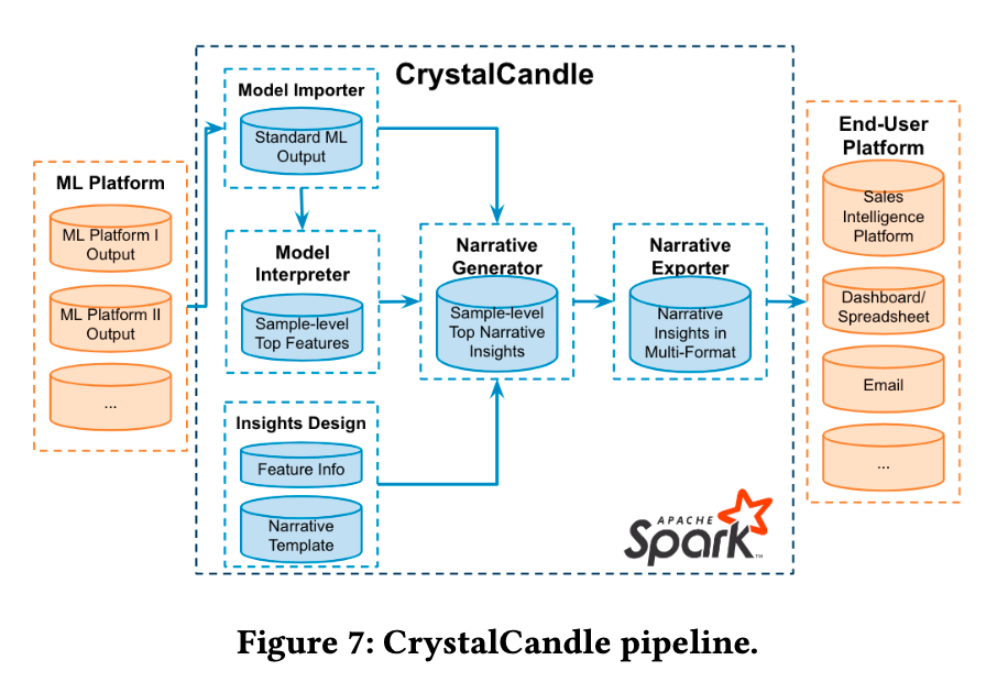
CrystalCandle 會採取進行以下幾個處理
- Aggregate contacts to company level
- misspelling
- word clustering
- build dictionary
- Narrow imputation
團隊在驗證階段採用指標 Renewal Incremental Growth (RIG)
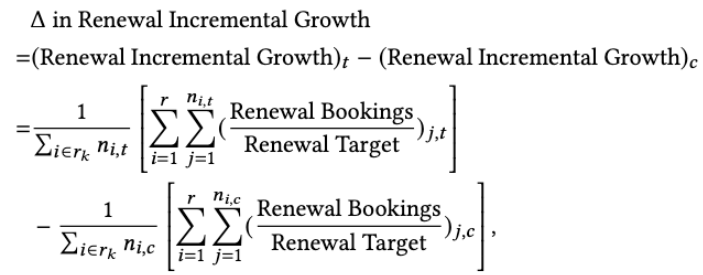
t: 實驗組 (treatment)
c: 控制組 (control)
最終得到很好的成效
- A/B test 增加 8.08% Avg RIG
- MAU 增加 20.4 Avg RIG
現在 Account Prioritizer 已經應用在 Linkedin engineering blog 等 3 個服務中
接著筆者參加的第二場 workshop 為 ECNLP workshop
Weakly Supervised E-Commerce Vernacular Search in low resource setting
講者: Vishal Kakkar & Aakarshan Gupta & Surender Kumar (Microsoft)
Microsoft 這場電子商務使用方言搜尋的講題十分有趣,可以說是殿堂級的分享,
現場滿滿的人潮,因為資源稀缺語言在自然語言 (NLP) 領域都還是極待有效的解決方案。
方言 (Vernacular) 通常會遭遇到三個問題
- 成熟度 (Maturity)
- 印度是個擁有眾多方言的國家
- 雞生蛋,蛋生雞的問題
- 用戶使用方言搜尋的紀錄太少
- 方言資料的收集生態還不完備
- 稀疏性 (Sparsity)
- 大部分的詞庫都有資料稀疏的問題,方言更為嚴重
- 電子商務領域資料不足 e.g. 搜尋記錄、品牌或型號音譯 (Transliteration) 問題
圖表: Web 資料訓練模型產生的 NLP 錯誤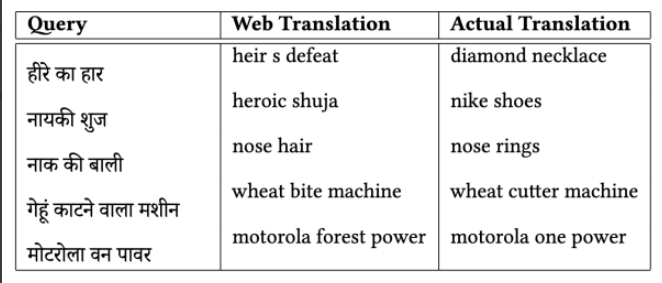
圖表: 印地語 (Hindi) 搜尋紀錄的文字長度分佈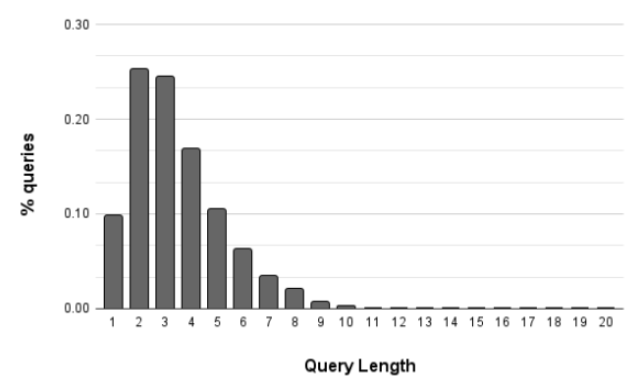
- 程式碼混用 (Coding mixed)
- 使用英文拼寫出印地語 (Hindi) 或其他印度方言
- 方言和英文同時出現的情況很常見
- 英文搜尋關鍵字拼寫錯誤
團隊提出複合型的解決方案
- 將方言翻譯 (Translation) /音譯 (Transliteration)成英文
- 開發英文查詢理解系統 (拼字校正、NER、資訊提取與相關排序)
- 提取索引使用單一語種 (e.g. 使用英文,比方言更能節省空間)
為了解決模型翻譯方言的準確度不是很好的問題,
團隊以拼字/拼音雜訊擴增 (noisy spelling/phonetics data augmentation) 手法生成詞庫。
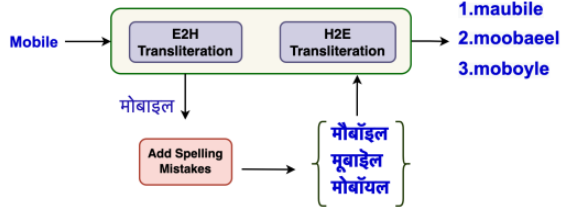
在語言模型使用上團隊發現 mBART(Multilingual Bidirectional and Auto - Regressive Transformers) 在電子商務領域斷詞效果表現不佳,
因此運用電子商務領域資料微調 (fine-tune) mBART,並以統計語言模型融合 (statistical LM fusion) 產生最終模型。
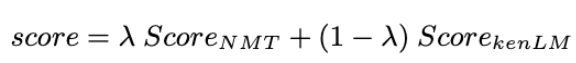
註:最終,翻譯分數 (translation score) 成為線性插值 (linearly interpolated) 統計語言模型
接續,團隊探討到多語言模型 (Multilingual Model) 在處理方言上的優缺點
- 缺點: 多語言模型比單語言模型 (Monolingual Model) 維護成本大 (可能會因為調優語言A間接影響到語言B)
- 優點: 印地語和南印語有共同的起源,多語言模型訓練後的優化效果會比單語與模型好
最後提到一種可能的兩階段解法,也就是先把文字送入泛化模型(general model),
得到基礎解再進而送入專一領域模型 (specific model),如此就可以同時獲得兩類模型的優點。
Semantic Equivalence of e-Commerce Queries
講者: arimandal, dtunkelang, zwu1 (eBay)
在電子商務中,搜尋引擎的查詢內容變化性是一個挑戰,因為同樣的查詢意圖會因為查詢表達方式不同帶來不一樣的查詢結果。
換句話說,查詢內容並不直接等同查詢意圖,兩者的關聯性其實是很模糊。

語言上相同意義的查詢內容應該要產生同樣的結果
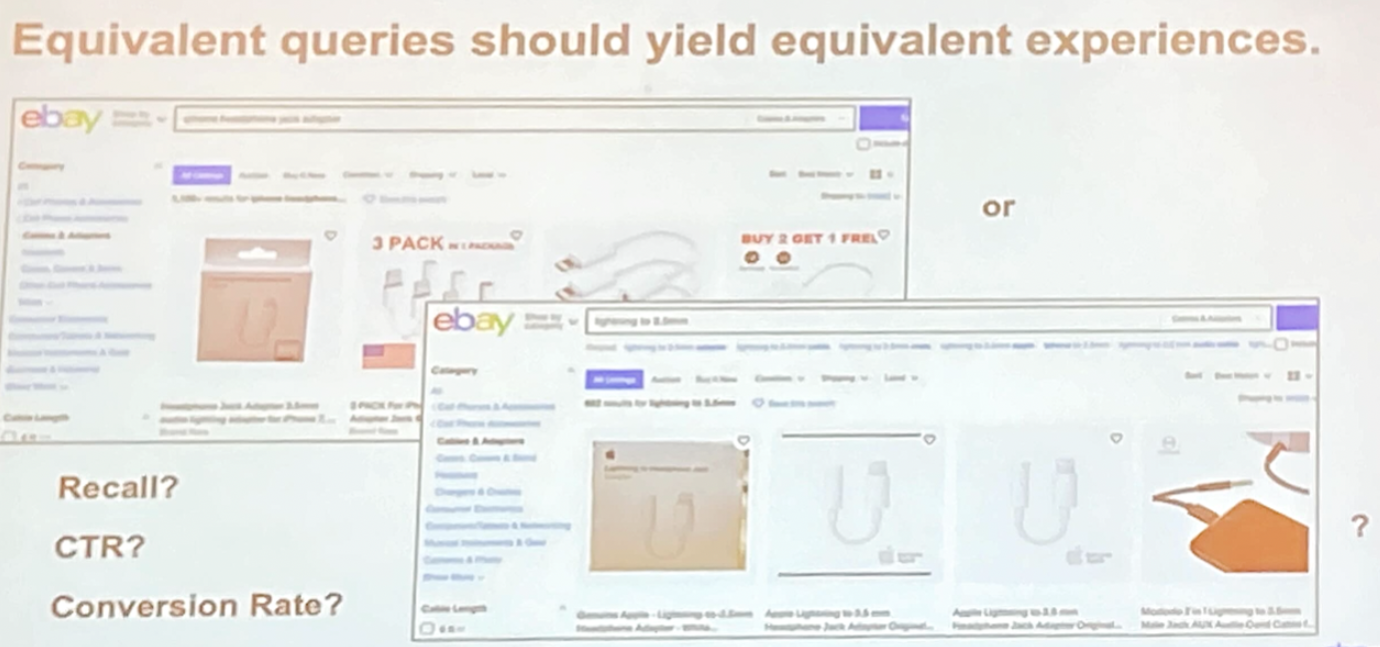
在此,團隊指出 2 種辨認同意義查詢內容的方式
- 表面相似度 (Surface Similarity): 主要在於字序、組成、噪聲詞上的變化
- 行為相似度 (Behavioral Similarity): 查詢意圖是一樣的,但用詞上有所變化

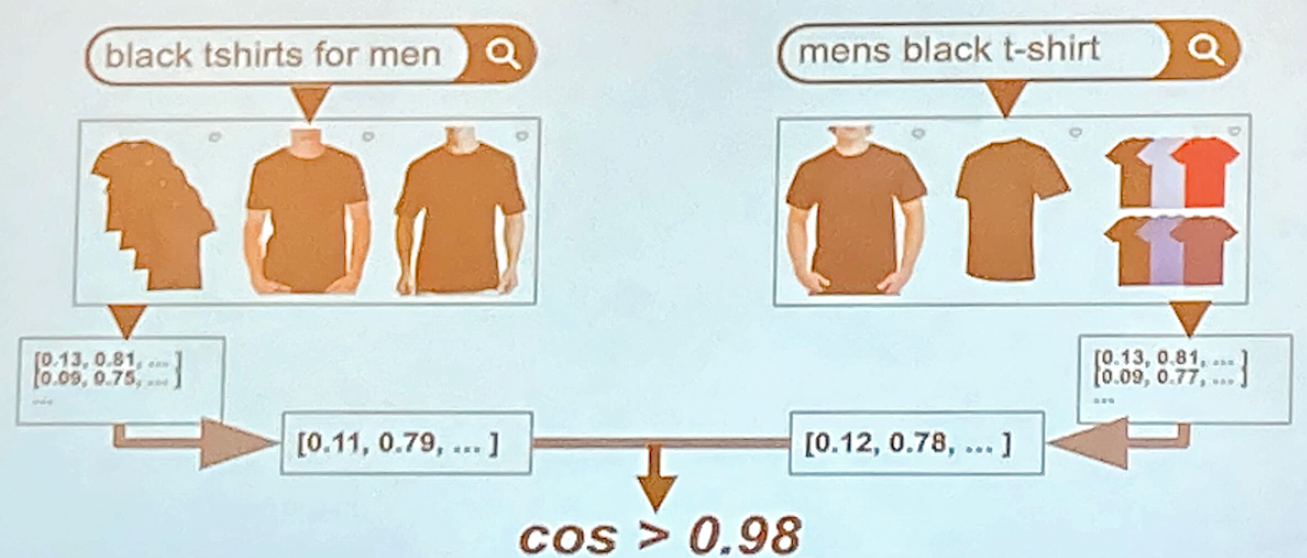
那團隊是如何去計算相似度呢?
這裡以兩組商品向量 (product vector) 為質心 (centroid) 一起計算 Cosine Similarity,
假如 cos > 0.98 認定為帶有相似搜尋目的
團隊提出 Online Query Similarity Model Architecture
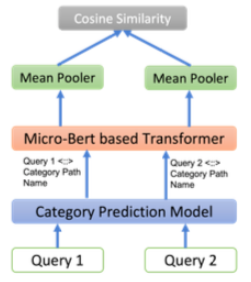
為了解決電子商務領域常見的長尾效益,
團隊使用 query1 + query + similarity 三重組合來訓練模型
為了處理三重組合在計算上的效能問題團隊在這裡採用最鄰近 (nearest neighbor) 資料庫, FAISS

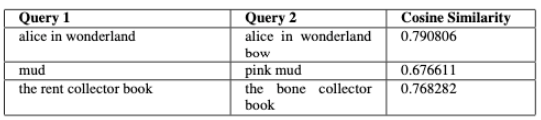
圖表: 低度表面相似但 cosine 相似度極高範例
從表中我們可以觀察到雖然 query 1 和 query 2 屬於低度表面相似,
但模型中得到的 cosine 相似度極高,代表著兩者擁有相同的查詢意義

圖表:高度表面相似但 cosine 相似度偏低的範例
中我們可以觀察到即便查詢內容有高度表面相似,但在模型中得到的 cosine 相似度是偏低
最後幾題 Q&A 分享給大家
Q1. 在 Online Query Similarity Model Architecture 中什麼元件最影響準確性 (accuracy) 呢?
A1. 類別預測模型 (category prediction model)
Q2. 請問你們有嘗試過其它語言嗎?
A2. 也有嘗試過德語,結果是很類似的
Q3. 為什麼你們選擇最鄰近 (neareast neighbors) 演算法來處理三重組合 ?
A3. 不需要額外做降維就可以使用原始維度 (好處就是可以用較小的維度做運算)
Seasonality Based Reranking of E-commerce Autocomplete Using Natural Language Queries
講者: prateek.verma, shan.zhong, xiaoyu.liu, adithya.rajan (Walmart)
搜尋自動完成 (Query autocomplete, QAC) 是現代化電子商務搜尋引擎的關鍵功能,QAC 主要任務是幫助用戶公式化查詢內容或預測用戶意圖。
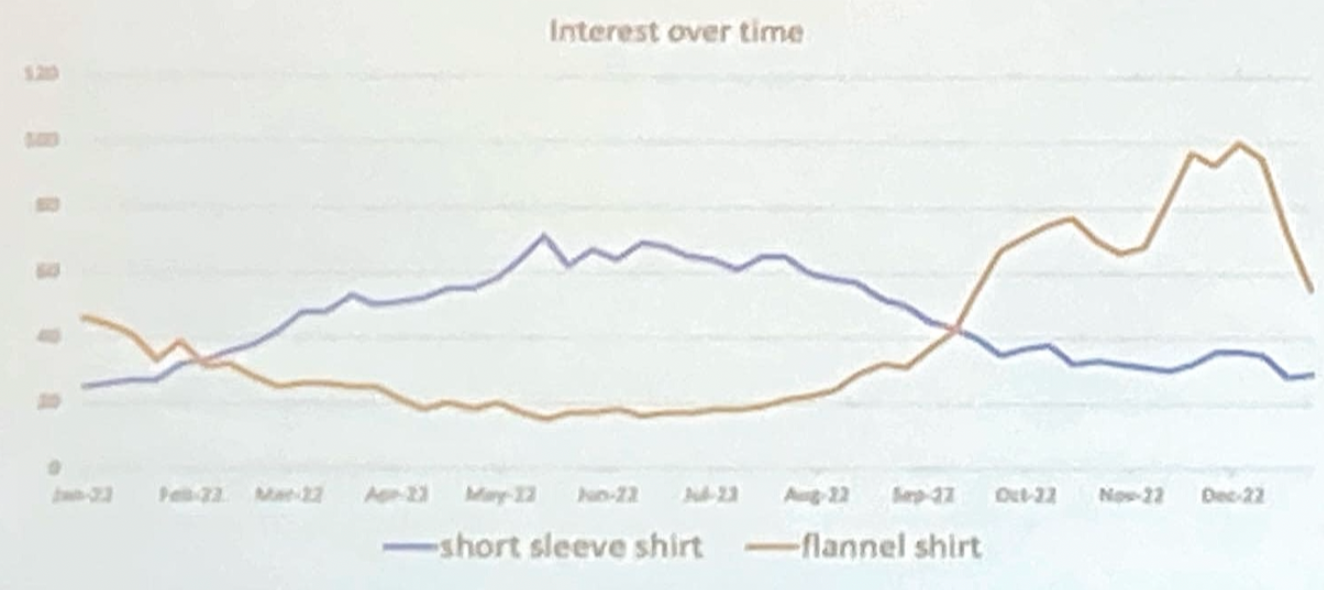
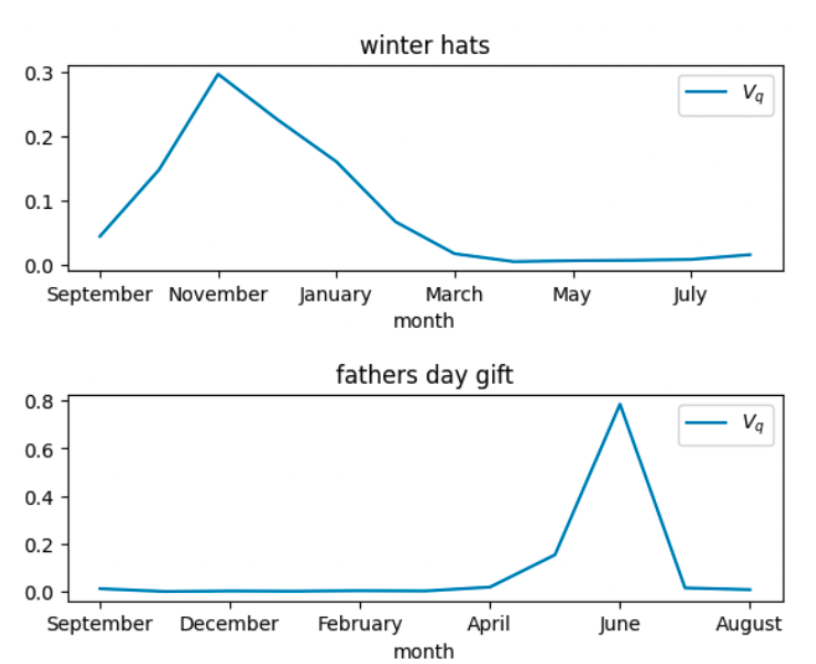
時節在電子商務搜尋中往往強烈影響用戶搜尋內容,例如在冬天用戶會特別喜歡搜尋手套、帽子和外套。
圖表: 12個月中的搜尋趨勢

定義:搜尋流量
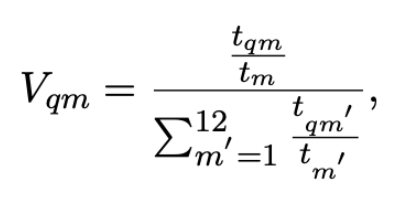
<nobr>𝑡𝑞𝑚:月份𝑚搜尋(𝑞𝑢𝑒𝑟𝑦)流量</nobr>
<nobr>𝑡𝑚:綜觀搜尋(𝑞𝑢𝑒𝑟𝑦)流量</nobr>
圖表:12個月中搜尋流量 (Vq) 與時節的關係
Walmart 將 QAC 系統分成兩個階段: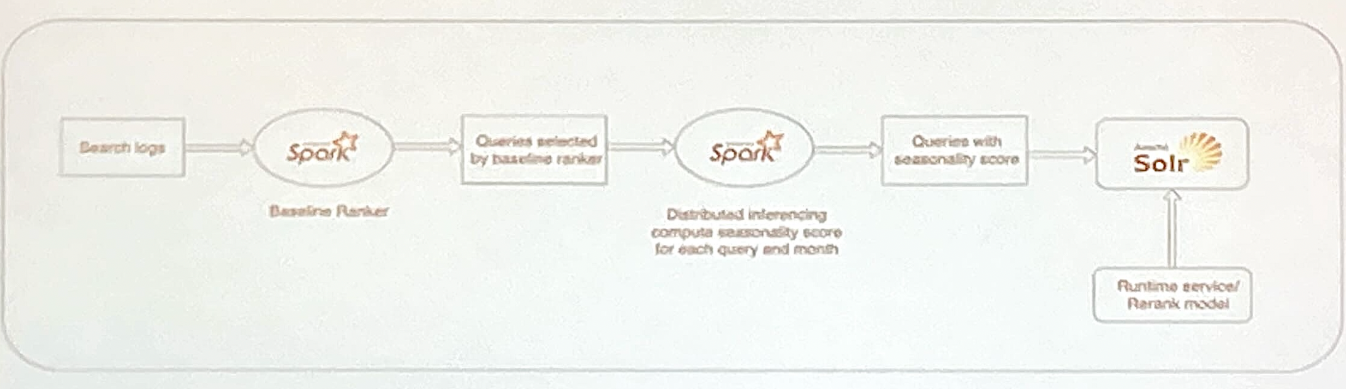
- Baseline ranker: 使用歷史互動資料 (e.g. click) 預測出 baseline score,目的是 maching/retrievel。
- Re-rank ranker: baseline score 搭配時節分數 (seasonality score) 並加上 session level feature 重排出 top K 的自動完成建議清單
訓練資料為33萬筆不重複搜尋內容,模型將通過最小化均方誤差 (mean square error) 進行學習。
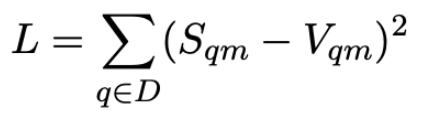 <nobr>𝑠𝑞𝑚:由模型預測月份𝑚的搜尋流量</nobr>
<nobr>𝑠𝑞𝑚:由模型預測月份𝑚的搜尋流量</nobr>
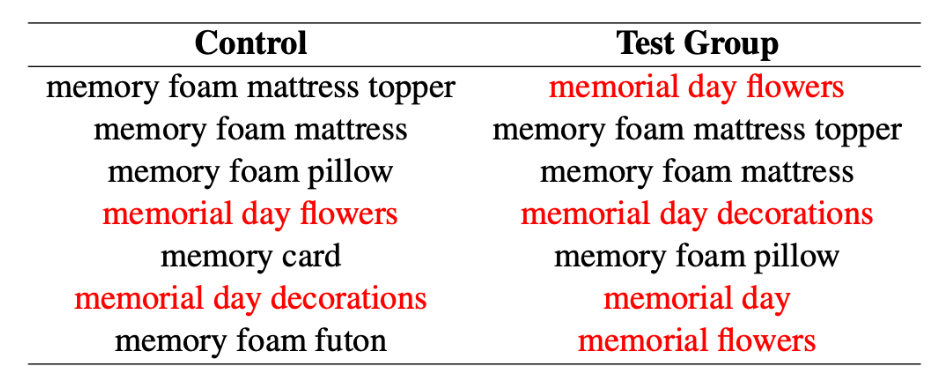
圖表:在紀念日前一週使用前綴為 memo 得到的自動完成建議
圖表: 四種不同用戶平台的 Offline Evaluation,驗證指標 MRR (Mean Reciprocal Rank)
排序模型搭配時節訊號在各平台都能有一定程度的成效提升

Explicit Attribute Extraction in e-Commerce Search
講者: Robyn Loughnane, Jiaxin Liu, Zhilin Chen, Zhiqi Wang,
Joseph Giroux, Tianchuan Du, Benjamin Schroeder, Weiyi Sun (Wayfair)
Wayfair 美國知名電子商務平台,主力銷售家俱和家飾用品。電子商務平台通常設計結構化資訊來描述商品的類別或屬性,方便用戶可以快速瀏覽或縮小商品的搜尋範圍。
用戶為了增加搜尋結果的精準度往往會想已商品屬性(例如:規格、顏色、風格、品牌等)協助搜尋,
因此 Wayfair 希望以機器學習方式自動萃取出商品屬性 (Attribute value extraction, AVE),減少人工定義帶來的成本。
圖表: 用戶搜尋時夾帶商品屬性的範例
AVE (Attribute value extraction) 在電子商務領域最主要的困難點在於資料的稀疏性,
Wayfrair 團隊提出的以弱標籤 (weak label) 搭配人工註釋 (human annotation)
訓練 DistilBERT (Distillation BERT) 的 NER (named-entity recognition) 任務。
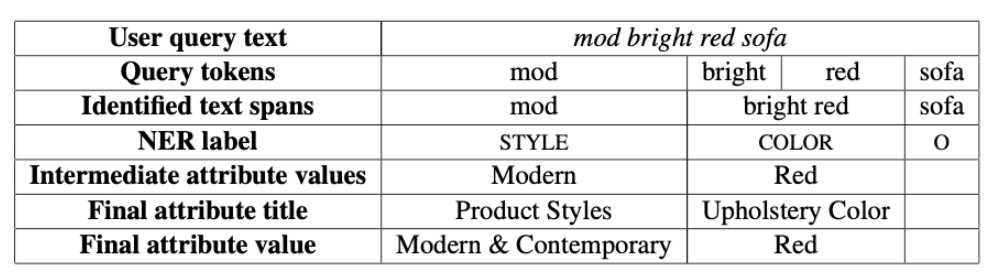
弱標籤 (weak label) 指的是如果被用戶加入購物車的商品與用戶搜尋內容可比對成功,系統就對搜尋內容執行斷詞產生 token 和 NER 標籤。
另外人工標註訓練資料會轉換成 BIO (beginning-inside-outside) 標籤。
附註:商品屬性的實體為以下幾類:
BRAND, MATERIAL, COLOR, DIMENSION, SUBJECT, LIFE_STAGE, FEATURE, LOCATION, SIZE,
FINISH, PRICE, STYLE, SHAPE, PATTERN, NUMBER_ITEMS, NUMBER_COMPONENTS。
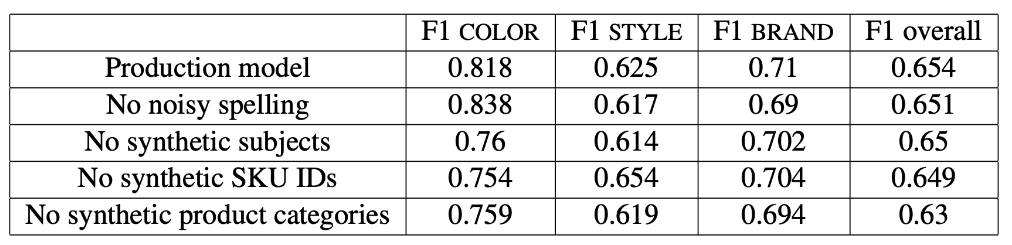
圖表: 優化 O 標籤的消融 (ablation) 研究
將商品 ID (SKU ID)、分類與拼錯字等加入 O 標籤對模型表現有很強的正向提升
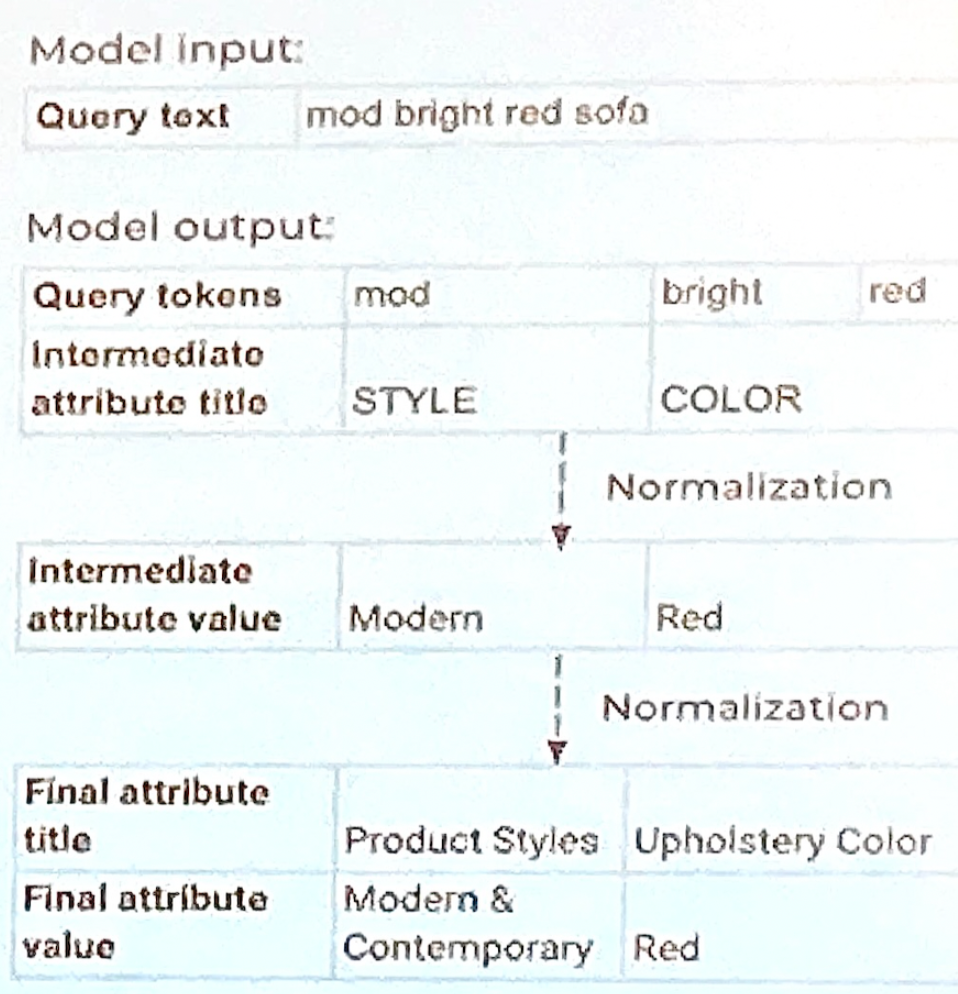
為了將由 NER 標籤產出的屬性比對回商品屬性,這裡會再加做兩階段正規化(two-steps normalization);
第一階段為 NER 標籤配對回用戶們的高頻率搜尋屬性 (frequency search attribute),
第二階段則是將高頻率搜尋屬性比對到結構化的商品屬性 (structured product attributes)。
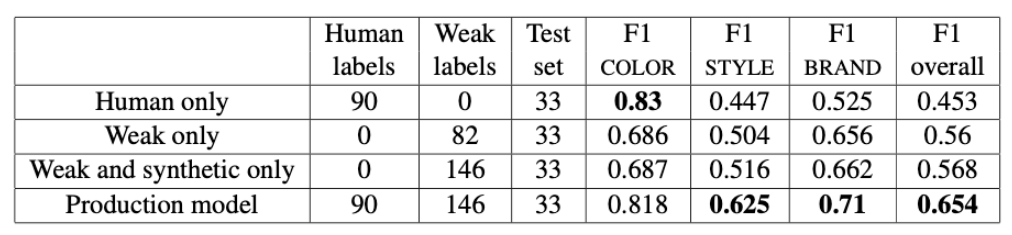
圖表: 人工標注、弱標註、合成資料與最終模型的成效指標
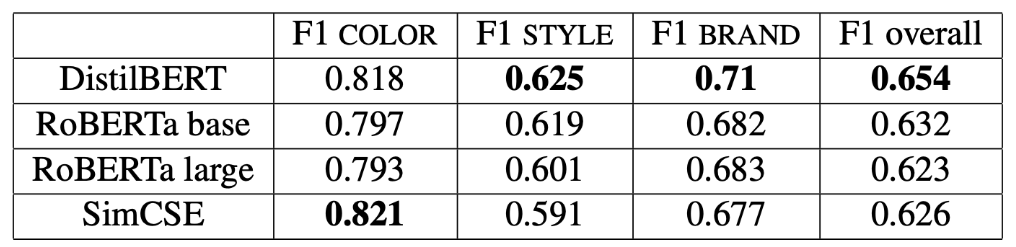
圖表: 不同語言模型的成效比對
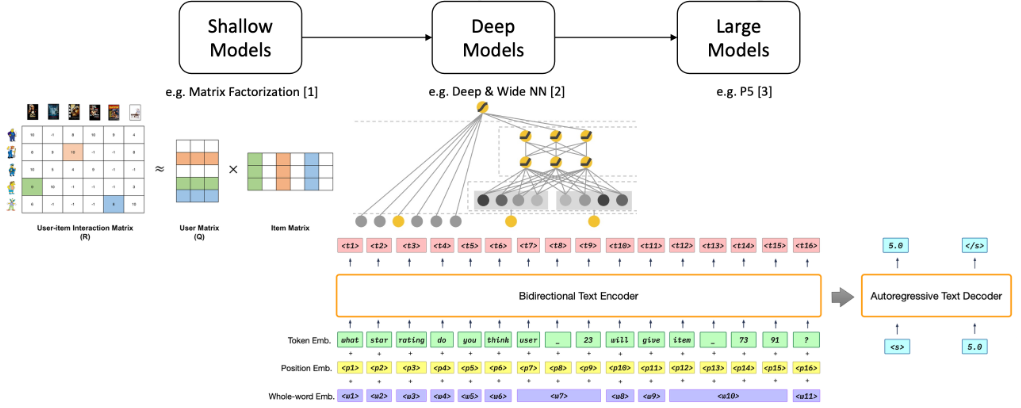
筆者的第三場 OARS workshop (Online and Adaptive Recommender Systems)
Large Language Models for Generative Recommendation
講者: Yongfeng Zhang (Rutgers University)
圖表: 我們的生活中各種個人化的服務

推薦系統從簡單的淺層模型 (shallow model) 發跡,
漸漸進展為深層模型 (deep model),
近期已經走向大型模型 (large model)
推薦是 AI 家族中相當獨特的一項領域,
相對於電腦視覺偏重客觀性,推薦系統屬於偏重主觀性,
也可以說是最靠近人性的領域,也就是沒有絕對的答案,結果好壞會因人而異。
圖表: 電腦視覺 (Computer Vision) 著重客觀性

圖表: 自然語言處理 (NLP) 部分客觀,部分主觀
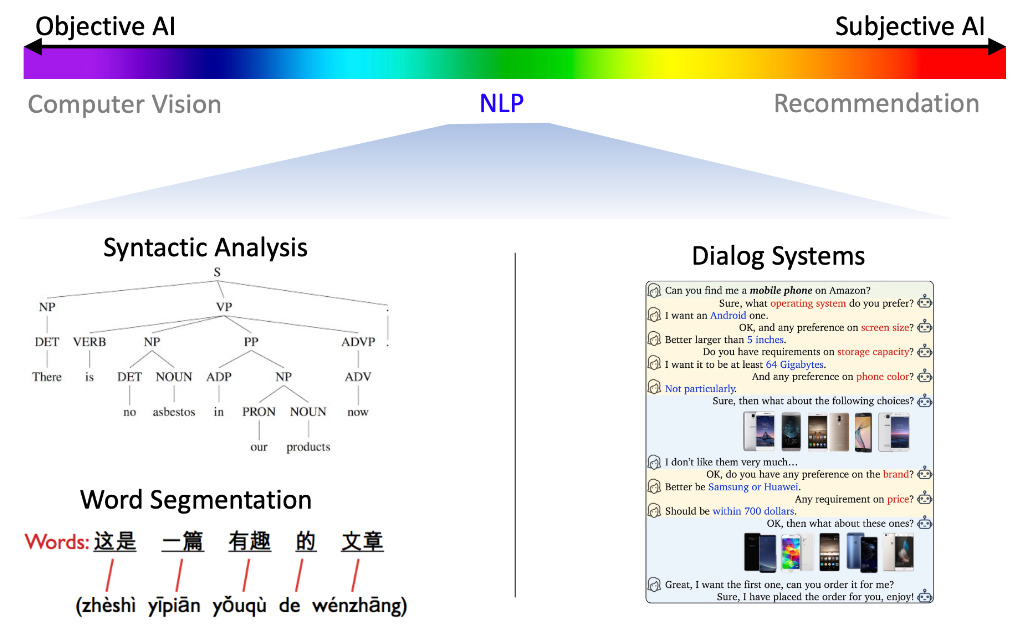
圖表: 推薦系統 (Recommender System) 著重主觀性
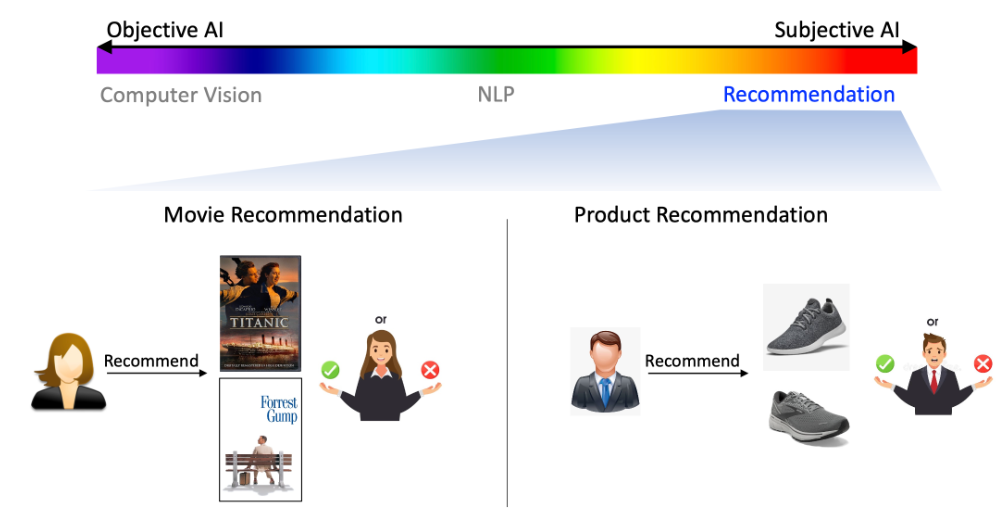
偏重主觀性的 AI 需要有可解釋性 (Explainability)

目前物品推薦的熱門為多階段資訊萃取推薦系統 (Multi-Stage Information Retrievel RecSys)
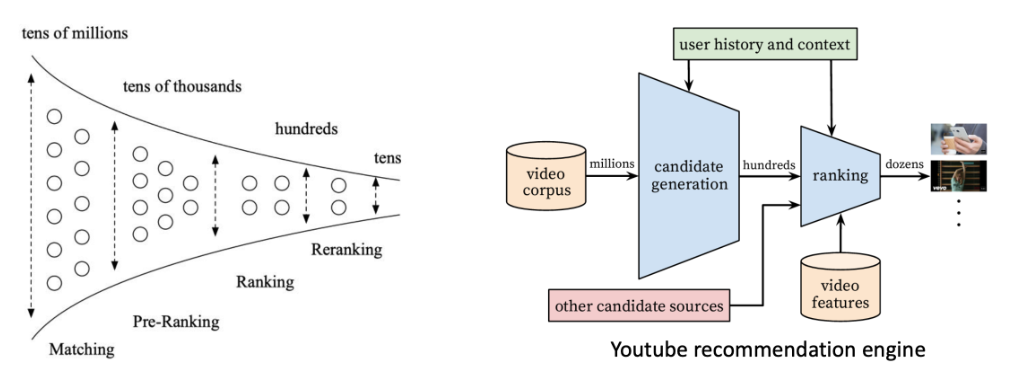
在大型科技公司中推薦系統需要有專家才能克服這些巨量資料運算瓶頸
• Amazon: 3 億用戶 x 3.5 億產品
• YouTube: 2.6 億的月活躍用戶 (monthly active users, MAU) x 5億影片
因此有許多研究型的論文會採用抽樣驗證, 例如抽樣比例為 1/100、1/1000 等等
事實上推薦不單只有排序 (Ranking) 一件事,現階段我們有辦法同時處理這些任務嗎?
- 評分預測 (rating prediction)
- 商品排序 (item ranking)
- 序列推薦 (sequential recommendation)
- 使用者資訊建置 (user profile construction)
- 評論總結 (review summarization)
- 解釋生成 (explanation generation)
-
公平性考慮 (fairness consideration)
從判別推薦 (discriminative recommendation) 改使用生成式推薦 (Generative Recommendation)
在此講者主軸為 P5 生成式模型,其命名是來自該模型能處理 5 種不同面向的任務 (請參考下面圖表)
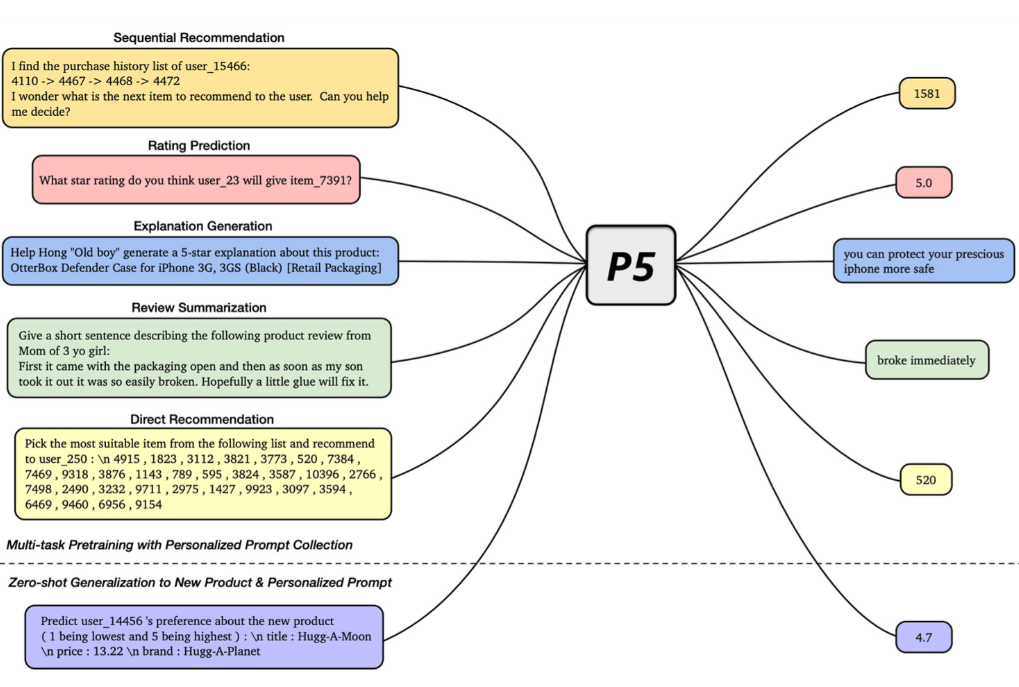
P5 模型搭配提示工程 (prompt engineering) 在不同類型推薦上都有不錯的表現
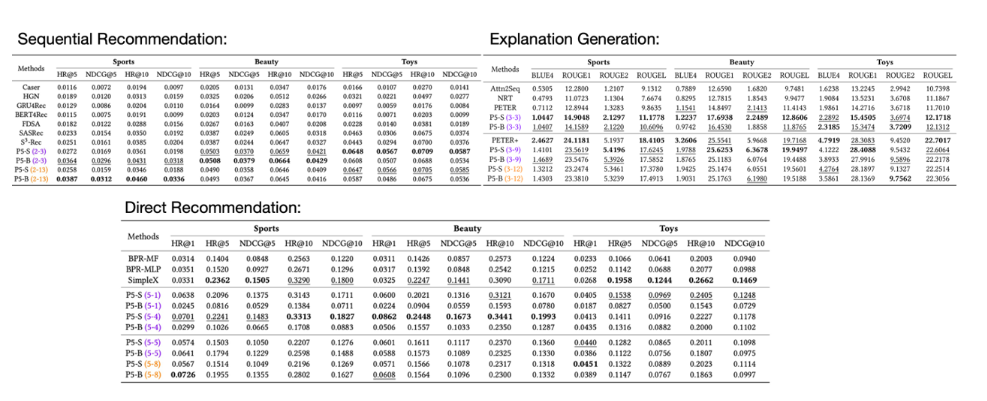
使用生成式推薦可以得到以下優點
- 多階段排序 (multi-stage ranking) 簡化為單階段排序 (single-stage ranking)
- 可以使用同一個基礎模型進行多任務學習 (multi-task learning)
- 容易處理多模態 (multi-modality) 資料
Incremental Training, Session-based Recommendation, and System Level Approaches to Online Recommender Systems
講者:Even Oldridge (NVIDIA)
首先講者提到許多推薦演算法都是基於用戶擁有固定喜好,
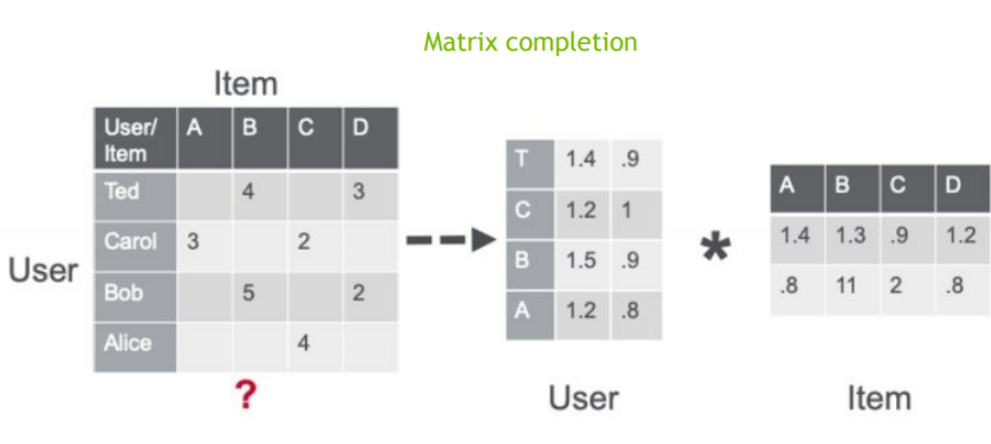
但事實上人的喜好和興趣會隨著時間持續改變 (序列模式很重要)

時序相關的推薦
1. 序列推薦 - 利用用戶過去的互動(通常是長序列)
例如:用戶提醒或是重複性購買 (典型網路購物中重複性購買約提供了43%營收)

2. 基於會話的推薦 - 僅利用當前會話中的用戶互動(通常是短序列)
附註: 不同會話的用戶行為可能非常不同

NLP X 序列推薦系統
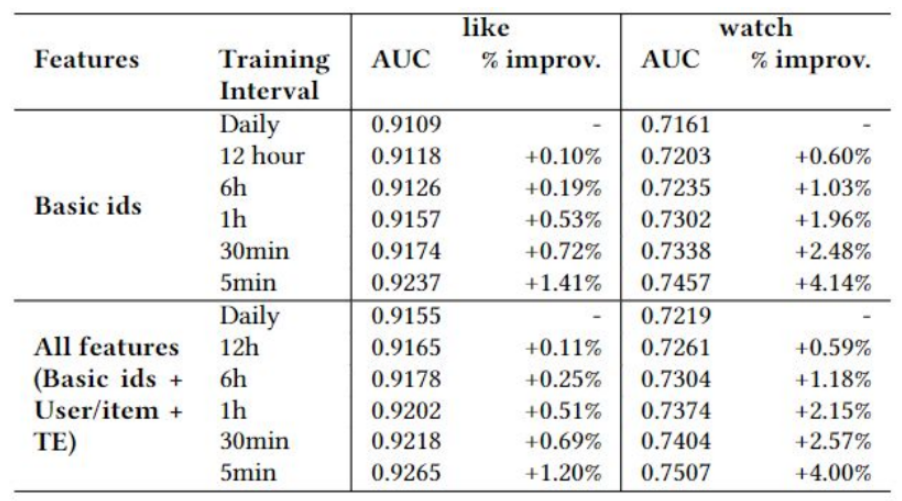
接著講者提到增量訓練 (incremental Training),是否訓練越頻繁就能提升模型成效?

圖表: 增量學習帶來較佳的成效
- 這裡切分出不同的時間窗格 (time window) 做實驗 (daily, 12 hr, 6hr, 1hr, etc.)
- 全部 feature (basic id + user/item+TE) 的效果又比單純 basic ids 來得好
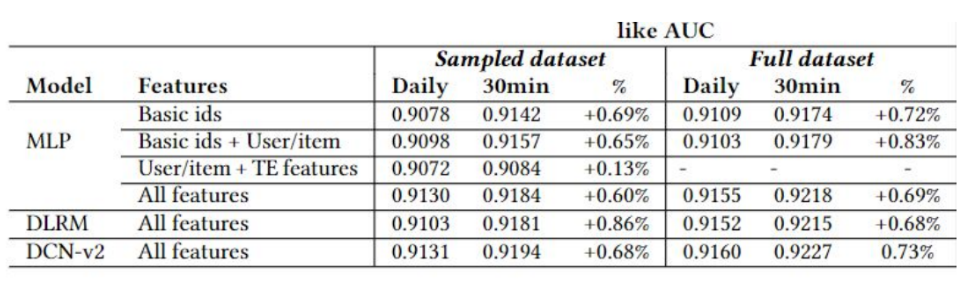
這具有普遍性嗎?
圖表: 是的,以不同特徵表示和模型做搭配訓練都可以看到進步
哪些物品影響最為顯著呢?
圖表: 新進物品和不常訪問的物品影響最顯著
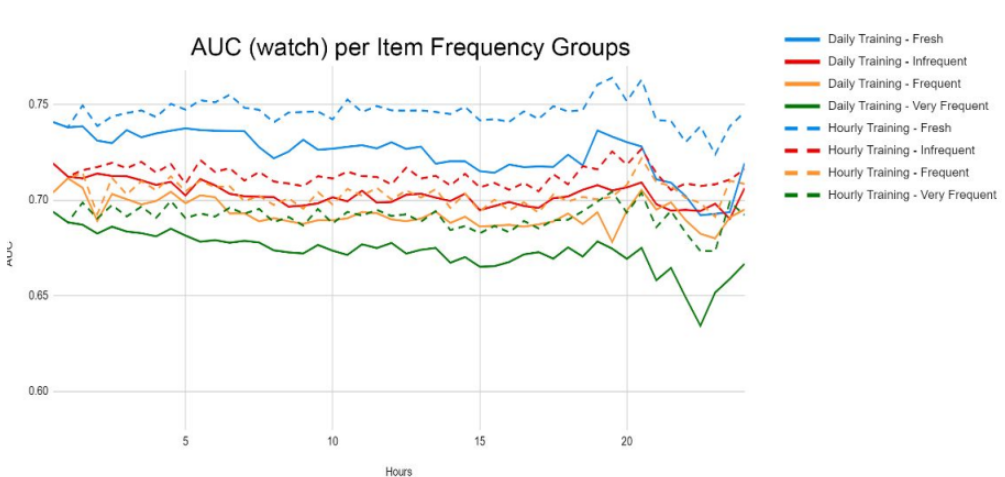
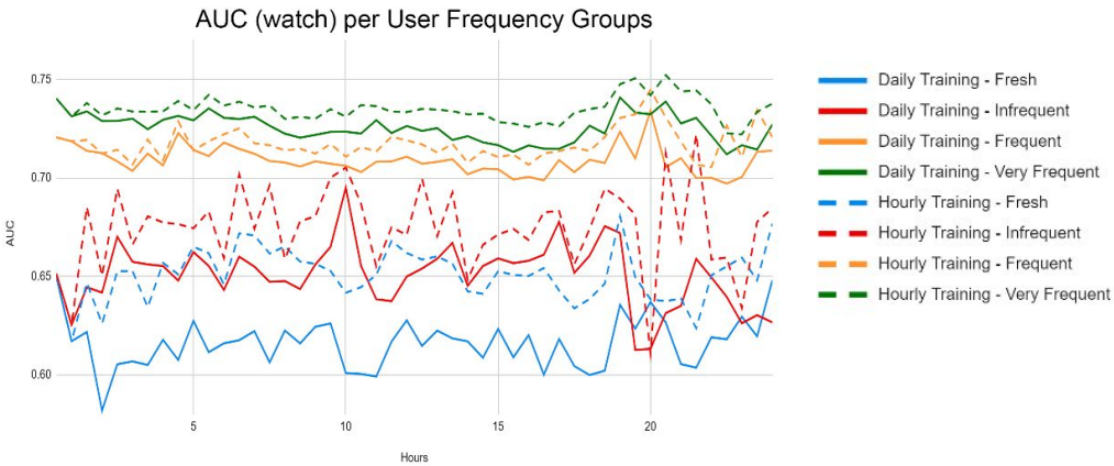
哪些用戶群體影響最顯著?
圖表:所有的特徵表現和模型搭配可以有進步
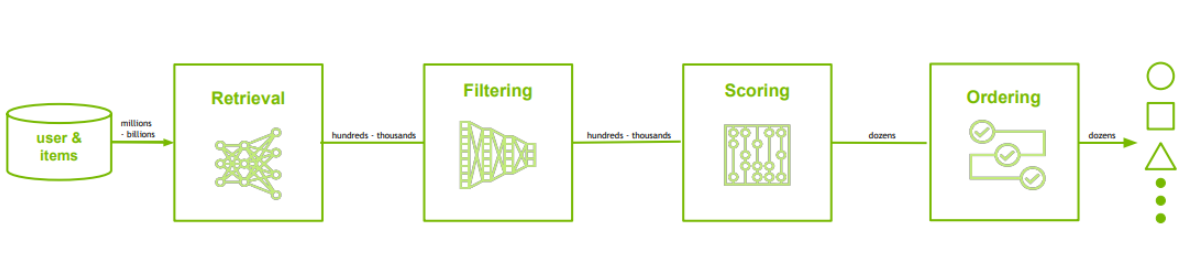
多階段推薦系統 (Multi-stage Recsys)
通常由四個元件組成
1. 取出 (Retrieval):從龐大的商品目錄中獲取一小部分與當前用戶相關的候選商品
2. 過濾 (Filtering):移除不適當或不可用的候選商品
3. 評分 (Scoring):給每個剩餘的商品分配一個相關性分數
4. 排序 (Ordering):選擇將哪些候選商品包含在最終推薦列表中,並以最佳順序排列
每個階段都有眾多的模型和工具,由不同的團隊維護,並有各自的關鍵績效指標(KPIs)。
不同的階段隨後通過複雜的系統工程和機器學習運營(MLOps)“串聯”在一起。讓一個端到端的系統順利運行需要整個團隊的努力!
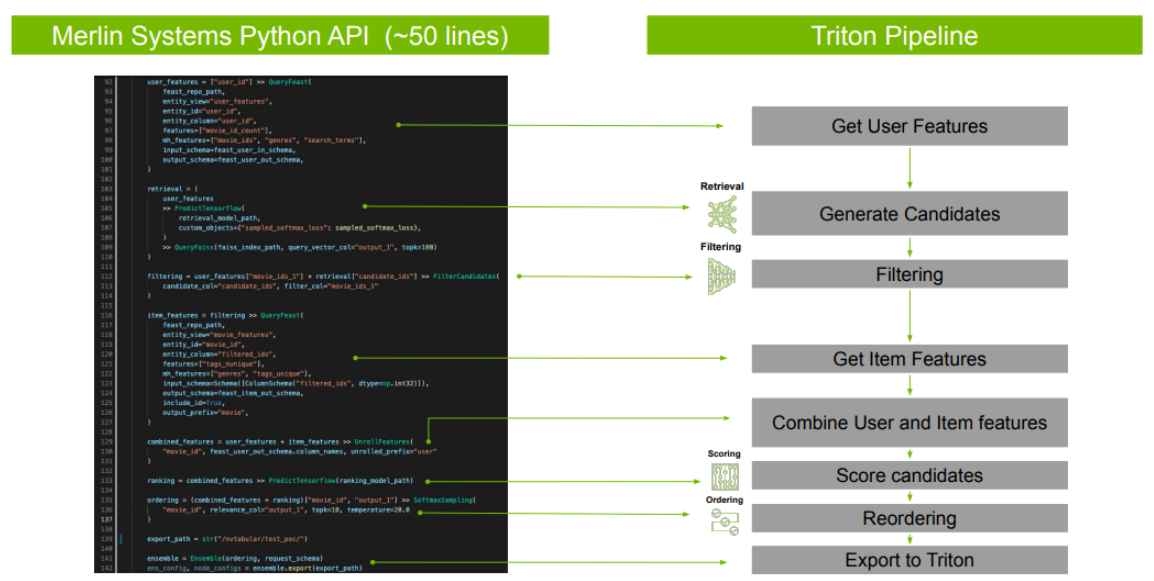
Merline 模型建立
提供可重複使用的建構模塊 (building block) 與模型訓練函式庫與預定義 (pre-defined) 模型
- 可在預處理 (pre-processing) 期間從 NVTabular 進行結構 (schema) 匯出
- 高階模型構建模塊 (High level model building block APIs) API只需用10行代碼構建和訓練ML/DL模型
- 可跨框架 (TF/XGBoost/Implicit/LightFM) 近模型評估
Merlin 系統
Triton 集成配置,將不同階段連接在一起進行本地/雲端部署,只需用 50行 Python 程式碼就能創建一個流程管線。
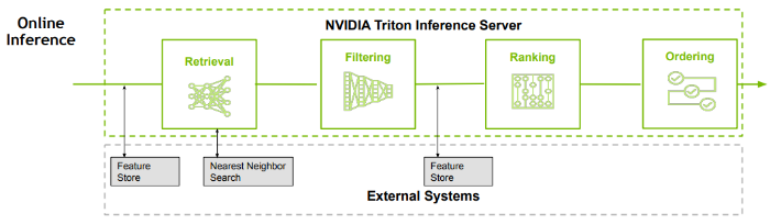
Merline 核心設計概念
- 易於添加:我們所有的函式庫都設計成可以讓用戶增加自己的元件
- 採用業界標準設計模式:落實最佳實踐,更容易快速迭代
- 可組合性:元件易於組合成更複雜的系統
快速 Python API 程式碼範例
最後一場 DCAI (Data-Centric AI) 筆者我覺得非常精彩
講者: Daochen Zha, Kwei-Herng Lai, Fan Yang, Sirui Ding, Na Zou, Huiji Gao, Xia Hu
(Airbnb, Rice University, Wake Forest University, Texas A&M University)
本場由萊斯大學的胡老師開場,以綜觀的方式分享 data-centric AI 的核心精神。
通常我們想要把合適的模型使用在我們的應用/服務上面
→ 步驟1: 選擇某個模型
→ 步驟2: 拿真實世界資料來檢驗成效
→ 步驟3: 返回模型中心並選擇另一個模型或者微調超參數
→ 反覆上面三個步驟
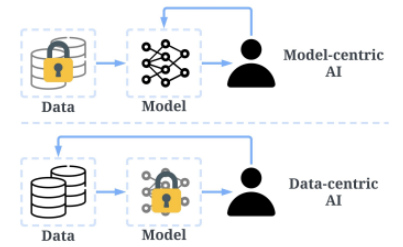
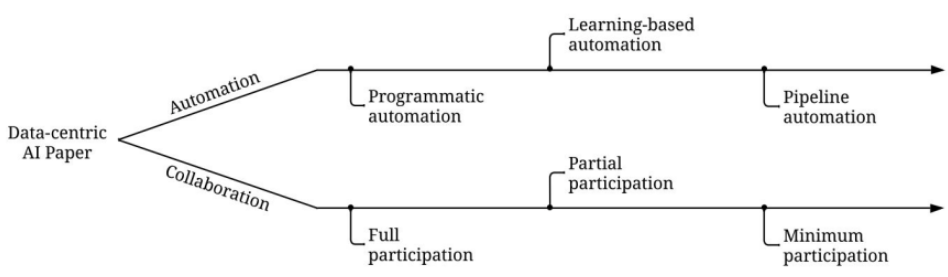
往往大家其實踩到誤區:資料驅動 (data-driven) 與 以資料為中心 (data-centric) 的概念有根本的區別。
資料驅動 (data-driven) 只強調使用資料來指導 AI 的開發,這通常還是環繞著模型開發,而不是工程化資料。
近年來運算能力大幅提昇突破了當年模型訓練的許多瓶頸,
因此訓練資料量也能隨之提升,進而讓模型往更成熟的方向前進
當我們模型已經足夠強大,我們可能只需要在做提示工程 (prompting engineering),
也就是推論資料 (inference data), 就能達到我們的目標,模型可以是固定的,
因此我們應該花心力關注資料層面。

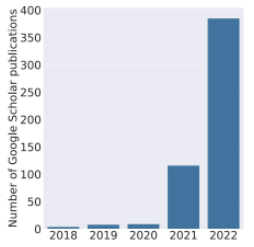
圖表:近年來 DCAI (data-centric AI) 的研究文獻飛速成長
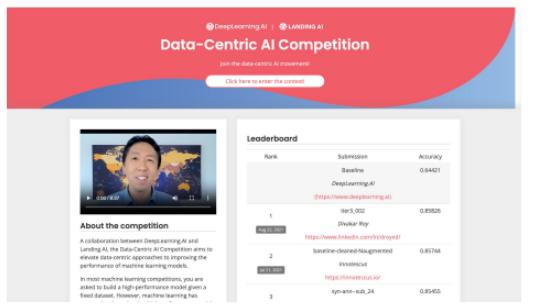
DCAI 競賽:它要求參賽者只對資料集進行迭代以提高性能。該比賽吸引了486份提交。
https://https-deeplearning-ai.github.io/data-centric-comp/
MIT 課程 : Introduction to Data-Centric AI
Website: https://dcai.csail.mit.edu/

環繞 DCAI 的新創公司不段崛起
舉幾個例子
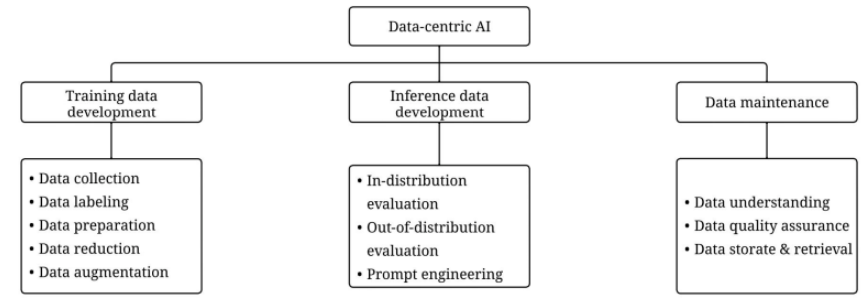
DCAI 技術架構
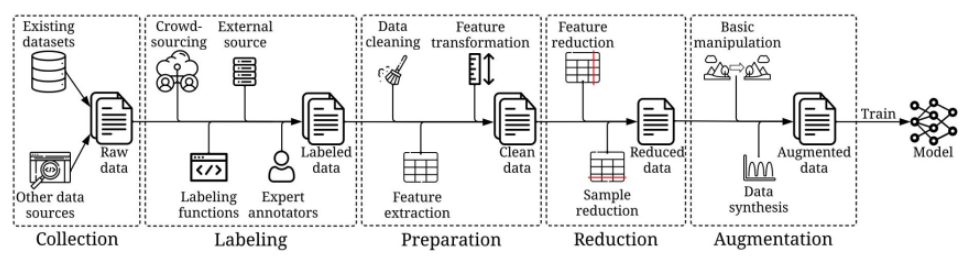
雖然 DCAI 是一個新概念,但它並不是全新的。
許多任務,例如:資料擴增 (data augmentation) 和資料減少 (data reduction)
幾十年前就已經被研究過。與此同時,許多新的任務和想法也正在出現。
我們如何建立正確的訓練資料以提高成效?
我們如何構建正確的推理資料 (inference data) 來評估模型或從模型中探索知識?
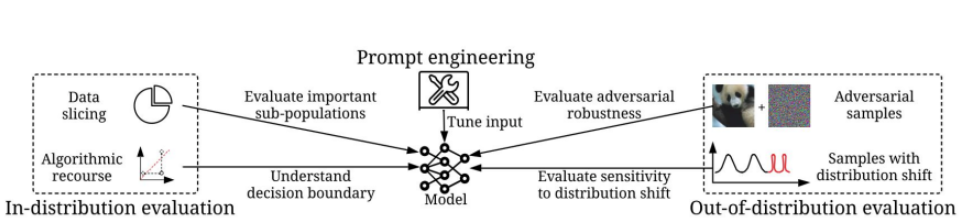
我們如何在動態生產環境中確保資料是正確的?
自動化與協同合作:為了跟資料不斷增長的規模,我們需要更高效的算法來自動化這個過程或者結合人類知識。
DCAI 趨勢:模糊的資料模型邊界
基礎模型 (foundation model) 可以變成一種資料形式 (data format) 或資料容器 (data container)
當模型變得足夠強大時,我們可以使用模型來生成資料
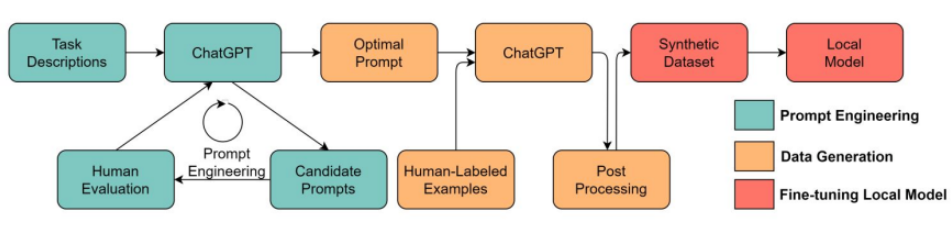

後續也分篇章由各專家分享 DCAI 技術架構中四大領域的研究發展
- Training data development
- Inference data development
- Data maintenance and DCAI benchmark
- Data bias and fairness
但由於篇幅過長接續我分享實際案例,
(算是筆者的私心,因為我主攻電子商務尤其是推薦系統)
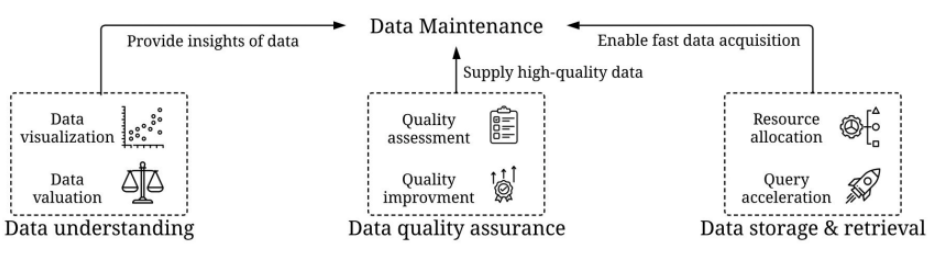
DCAI 現階段已在產業上的實際應用
主要環繞在3大領域
- 網路搜尋 (web search)
- 社交網絡 (social network)
- 電子商務 (E-commerce)
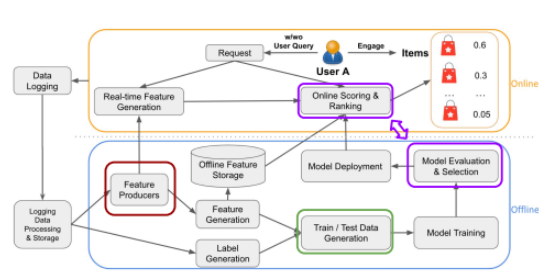
搜尋與推薦系統常見資料系統
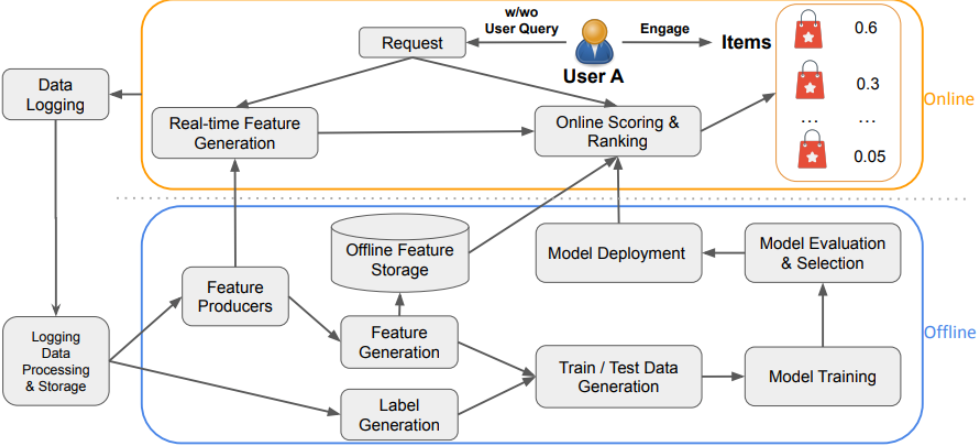
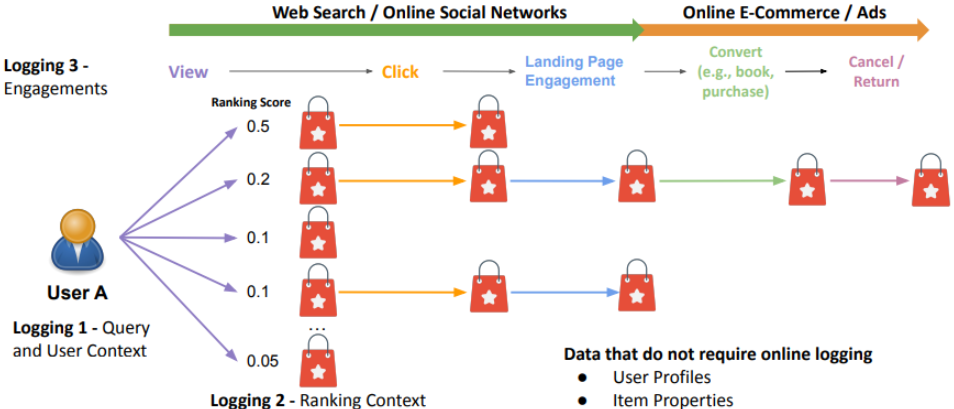
資料紀錄 (Data Logging)
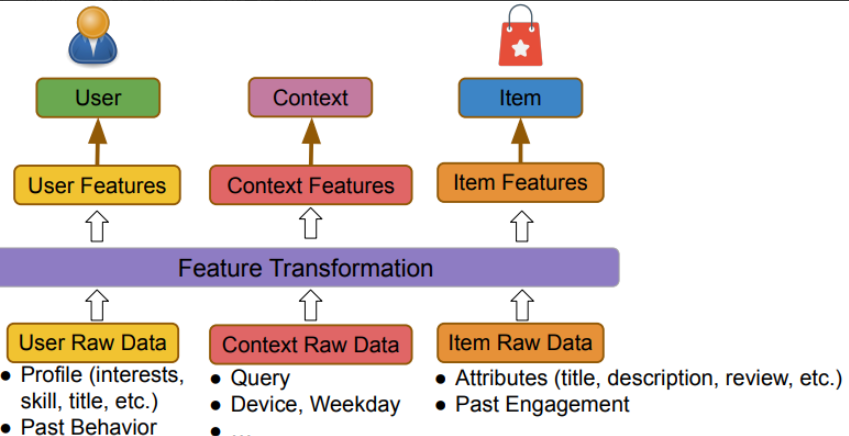
訓練資料生成 - 特徵 (Feature)
我們如何會為推薦系統注入以下3個面向的資料
- 用戶 (例如:興趣)
- 內容 (例如:搜尋)
- 物品 (例如:商品名稱)
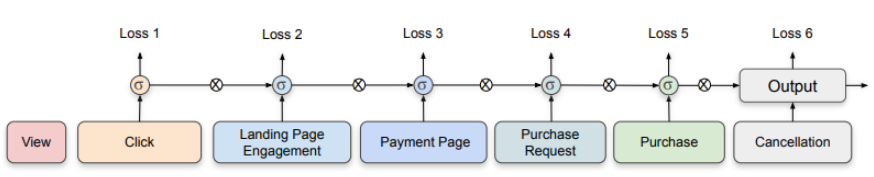
訓練資料生成 - 標籤 (Label)
- 單一任務
- P(Purchase | View)
- 多重任務
- P(Click | View)
- P(Purchase | Click)
- P(Cancellation| Purchase)
離線與線上的差異
- 測試資料
-
- 好的訓練資料和真實流量
- 工作日/週末效益
- 時節
- 大事件
- 避免資訊遺漏
- 好的訓練資料和真實流量
- 特徵生成
- 同步特徵生成器 (Synced Feature Producers)
- 模型評分
- 模型版控
- 模型偏差
- 下一個模型的訓練/測試資料是從前一個模型的服務資料中生成的
- 富者愈富:如果一個�項目從未有機會為用戶服務,我們如何知道它是否好用
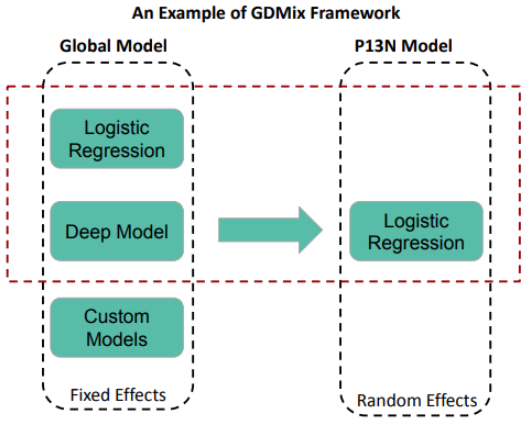
排序 (Ranking) 的預訓練:基礎模型 (Foundation Model) + 任務特定模型 (Task-Specific Model)
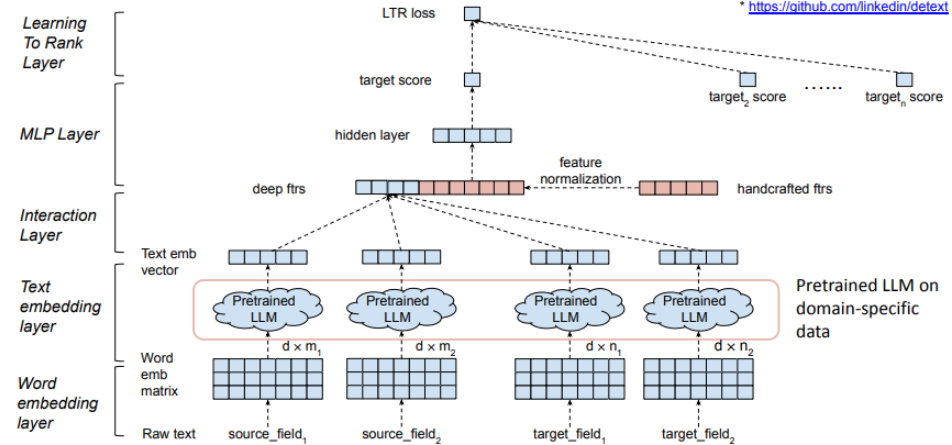
效果與效率的取捨
- 多媒體(文件、圖像等等)資料量和計算量通常很大
- 預訓練的基礎模型 v.s. 任務特定模型
- 用不同的資料重點進行訓練
- 在任務特定模型中對預訓練的模型進行微調
- 需要在模型成效和服務延遲之間取得平衡
- 使用特定領域的資料和靈活的結構對 LLM 進行預訓練
使用多模態序列資料 (Multi-modal sequential data) 預訓練模型
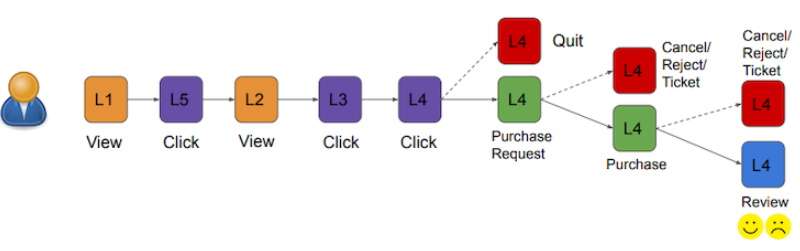
挑戰:用戶參與序列資料 (engagement sequence) v.s. 單詞/圖像序列資料 (word/image sequence)
- 語意平滑性 (semantic smoothness)
- 雜訊 (noise) 與隨機性 (randomness)
- 資料清理 (data cleaning) 和去除雜訊 (denoising)
資料模型架構圖
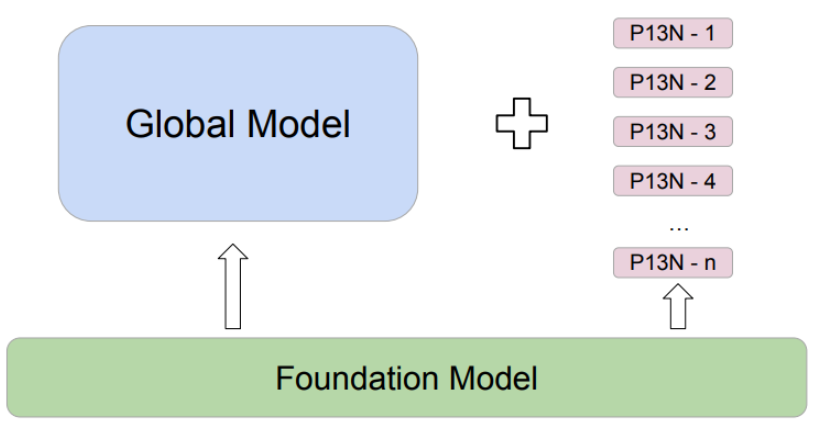
基礎模型 (Foundation Model)
- 非特定任務
- 處理大規模複雜/非結構化資料(文本,圖像,視頻,參與序列)
- 低頻率更新(例如:每季度或每年一次)
全域模型 (Global Model)
- 特定任務
- 處理具有穩定樣板 (stable pattern) 的結構化資料,從基礎模型中微調預訓練的資料樣式 (data pattern)
- 中頻率更新(例如:每月或每兩週一次)
個人化模型 (P13N Model)
- 特定任務
- 處理具有動態樣板 (dynamic pattern) 的結構化資料,從基礎模型中微調預訓練的資料樣板 (data pattern)
- 高頻率更新(例如:每小時或每天一次)
公平 (Fairness) 與穩定性 (Stability)
- 公平性
- 兩個資格相等的實體應該有平等的機會
- 用戶方面:工作推薦機會
- 物品方面:主持人/產品能見度
- 兩個資格相等的實體應該有平等的機會
- 穩定性
- 微小的隨機性可能就會影響潛在的公平性
- 排序模型 (raking model) 可以會一個物品排名高於另一個,雖然可能差距非常的小
- 排序策略也可能導致富者愈富,窮者愈窮
- 探索 (explore) /利用 (exploit) 可以提供更多機會給代表性不足的群體
- 排序集成 (ensemble) 可以用來減低偏見
- 微小的隨機性可能就會影響潛在的公平性
結語
KDD 2023 收穫滿滿,論壇形式與內容均十分豐富,有論文發表的 conference 場次、著重於分享與討論的 workshop、也有小班制課講式的 tutorial (能最貼近地與導師級人物對話),
大家論壇休息時間也不忘到知名企業攤位聊聊。幾天的時間能同時與學界業界高手交流,讓我對資料科學/機器學習領域更為了解,我也會將這些經驗和知識分享給 LINE 資料相關團隊成員,
讓 LINE 能為用戶帶來優質的服務。

![[I/O Extended Taipei] 在 Gemini API 家族中建構應用程式:從呼叫 API,到架構一個會自己完成工作的系統](/static/adae21cfc0c573393d486386200ed4cd/d990e/9d4ba616811b4f9e9be4ff927f65090e.png)
