Generated by Microsoft Designer
TL;DR
- 在LINE Taiwan,我們決定使用金絲雀部署進行Loki升級
- 使用Vector取代Promtail協助我們處理log並送往Loki
- 使用Vector去複製真實流量到新版Loki,幫助我們調整Loki config
- 使用Vector改善Loki labels,大幅度增進Loki效能
- 最終省下近70%的機器成本,將後端儲存的負擔降到最低
背景
Observability Platform
LINE Taiwan的observability platform主要使用Grafana提供的生態系,利用Grafana當作dashboard以及搜尋log、metrics以及trace的媒介。在metrics部分,我們使用公司提供相容於Prometheus API的系統,Log部分使用自建的Loki cluster,Trace部分則是使用自建的Tempo cluster。
當時我們的Loki cluster版本是2.8,並使用grafana/loki-distributed helm chart部署,後端儲存使用公司提供的相容於S3 API的Object Storage系統,比較特別的是,我們按照Loki config的說明,設定10個sharding buckets,嘗試分散bucket流量。cache部分則是使用公司提供的Redis Service。因應多的專�案及團隊,我們有開啟multi-tenant設定。
Loki升級
在去年底時,SRE計劃將Loki cluster升級到3.3,那時的Loki已經有官方維護的grafana/loki helm chart,並且在安裝文件直接使用這個helm chart進行安裝,不再仰賴於靠社群維護的grafana/loki-distributed helm chart。Loki官方文件也有提到如何從grafana/loki-distributed migrate到grafana/loki helm chart的方法,因此推斷這個舊的helm chart將會被deprecate,另外在稍微看過官方migration流程後,覺得不太方便實施。在綜合因素下,同時部署Loki的observability cluster資源還算充足,最後決定部建第二套新的Loki cluster,直接採用grafana/loki helm chart部署,希望能透過設計出新的架構、流程及config,去解決當時Loki的各項問題。
在設計migration流程時,我們希望能讓這個新版Loki cluster直接承擔production流量,方便在過程中能針對Loki的config做一些tuning,等到性能調校差不多後,就能逐步開放beta以及production使用。所以如何設計一個平滑的搬遷流程是我們的首要目標,這也是本文的著重重點,Loki細項的config調整將會在下一篇提及。
方法
從 Promtail 遷移到 Vector
如前面提到的,我們希望能在migration期間,並存兩套Loki cluster,並且都收同樣的log,這需要在log collector那邊下功夫,我們當時是使用Grafana出的Promtail,雖然說Promtail可以設定第二個Loki endpoint,不過Promtail config不好維護而且官方也說明Promtail已經不再接受更新,他們改專注在Alloy的開發。
在衡量該替換成哪個log collector時,我們考量目前的幾點需求:
-
能正常收kubernetes logs,並有基本的k8s metadata資訊
-
允許送log到Loki去
-
能夠將log內容做些基本的處理,例如masking敏感資料或是調整Loki label
Alloy雖然皆滿足以上需求,我們也曾在其他場景中使用,不過這時想起主管曾提到Vector現正流行,在評估它的功能以後,發現都可以滿足目前需求,也有以下優勢:
-
使用Rust開發,在執行上所需的資源遠小於使用Golang開發的Promtail或是Alloy
-
生態系豐富的Vector Components,能依照環境及情境選擇合適的元件
-
提供了稱作Vector Remap Language (VRL)的語法,並支持眾多的functions,能根據需求輕易處理log
-
提供了非常方便的Unit Tests功能,能夠驗證你寫的VRL沒有問題
我們最後決定將Promtail替換成Vector,流程如下:
- 將現有的Promtail config移植成Vector config:這包含Kubernetes logs source、Loki sink以及客製化的Remap transform等等元件,也撰寫了多個Unit Tests,這能讓我們有更高的信心,確保Vector config能正常運作。
sources:
kubernetes_logs:
type: kubernetes_logs
transforms:
add_metadata:
type: "remap"
inputs:
- kubernetes_logs
source: |
# custom transformation by VRL
sinks:
loki:
type: loki
inputs: [ add_metadata ]
endpoint: "${LOKI_ENDPOINT}"
tenant_id: "{{ .tenant_id }}"
encoding:
codec: raw_message
labels:
"*": "{{ .loki_labels }}"
- 使用Vector取代Promtail:我們替換的過程如下:
- 先同步Vector,這時舊的Loki會短暫地直接承擔兩倍流量(Promtail+Vector)
- 下掉Promtail避免Loki的rate limit錯誤影響Vector
- 藉由Vector自己的retry機制,正常送log到Loki去
我們觀察到在替換後,不僅Loki運作正常,同時帶來的效益是Vector所需的記憶體使用是原先Promtail的30%以下,驗證了Vector的高效能表現。
逐步增加sample log流量
Vector提供了Sample transform功能,可以設定sample rate,進而針對收進來的log進行抽樣,一般應該是用在log量超級大的情境,設定少量但足夠進行排障的sample rate,減少log系統以及後端儲存的負擔。不過我們決定活用這個功能,幫助我們順利地進行Loki migration,具體流程如下。
- 定義Sample transform,輸入剛使用VRL轉換後的
add_metadata元件。以下範例是採用10%(1/10)的sample rate。
transforms:
add_metadata:
type: "remap"
inputs:
- kubernetes_logs
source: |
# custom transformation by VRL
sample_log:
type: sample
inputs:
- add_metadata
rate: 10- 定義新的Loki sink,
endpoint改成新的Loki,輸入改成剛才的Sample transform元件名稱。以下範例的loki-v3即為新的Loki sink,注意他的輸入是sample_log而不是add_metadata。
sinks:
loki:
type: loki
inputs: [ add_metadata ]
endpoint: "${LOKI_ENDPOINT}"
tenant_id: "{{ .tenant_id }}"
encoding:
codec: raw_message
labels:
"*": "{{ .loki_labels }}"
loki-v3:
type: loki
inputs: [ sample_log ]
endpoint: "${LOKI_V3_ENDPOINT}"
tenant_id: "{{ .tenant_id }}"
encoding:
codec: raw_message
labels:
"*": "{{ .loki_labels }}"-
同步Vector config到cluster上,確認新的Loki已經有接收少量,但來自真實環境的log。這時就可以專注在Loki的tuning。
-
隨著Loki的tuning,可以逐步將sample rate拉高,我們一路從10%、33%、50%調整到最終的100%,證明新版Loki可以強健地承擔production環境上的log流量。
改善Loki labels
我們在log collector還在使用Promtail時,訂了以下的label
-
cluster:k8s cluster名稱
-
namespace: k8s namespace
-
container:定義在
spec.containers.name的pod container名稱 -
app:
app.kubernetes.io/name、apppod labels,或是pod名稱 -
component:
app.kubernetes.io/component或componentpod labels -
instance:
app.kubernetes.io/instance或instancepod labels -
nodename:當時pod部署的node名稱
-
pod:pod名稱
-
stream:log是
stderr或stdout
在詳細閱讀The concise guide to Grafana Loki: Everything you need to know about labels這篇官方blog後,深深體悟到目前的label設計對Loki儲存以及搜尋上是非常沒有效率的,因此我們決定針對label進行大幅度的改善。
我們決定移除pod以及nodename這些high cardinality的label,改放在structured metadata,雖然他的檢索速度不及label,但是這更符合官方建議,而且也能透過引進Bloom Filters,帶來潛在的搜尋加速。我們也另外放入對搜尋log有幫助的availability_zone, nodepool以及trace_id。
我們還針對app這個label做特別處理,除了前述app相關的pod label之外,如果pod有parent resource,例如他是daemonset、statefulset或是deployment,我們會將pod owner的欄位取出,處理後寫入到app label中。
我們也另外針對k8s client library或是controller生成的pod做處理。因為它們通常會是一次性任務的job,或是沒有parent resource但是suffix複雜的pod名稱,這樣就不能用前面的方式處理,這時必須更積極地看目前還有哪些app label沒有被處理,這時可以使用下方的logcli指令協助看不同的Loki tenant的stream有哪些,針對常見而且量大的stream中的label作處理。
export LOKI_ADDR=<loki-gateway>
export LOKI_ORG_ID=<tenant-id>
logcli series '{}'這些操作完成之後,預期在Loki Operational Dashboard將會看到兩個顯著的變化。
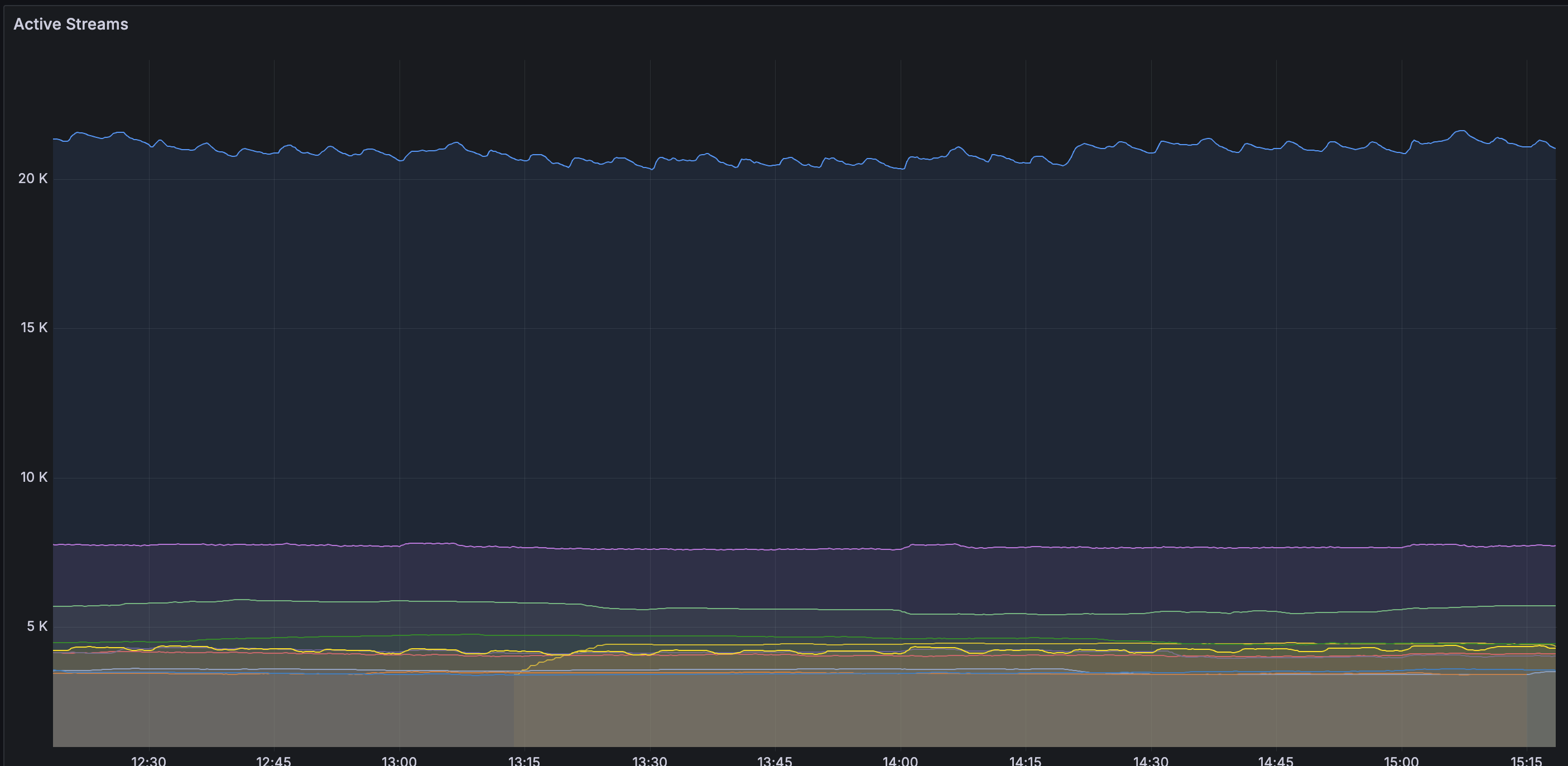
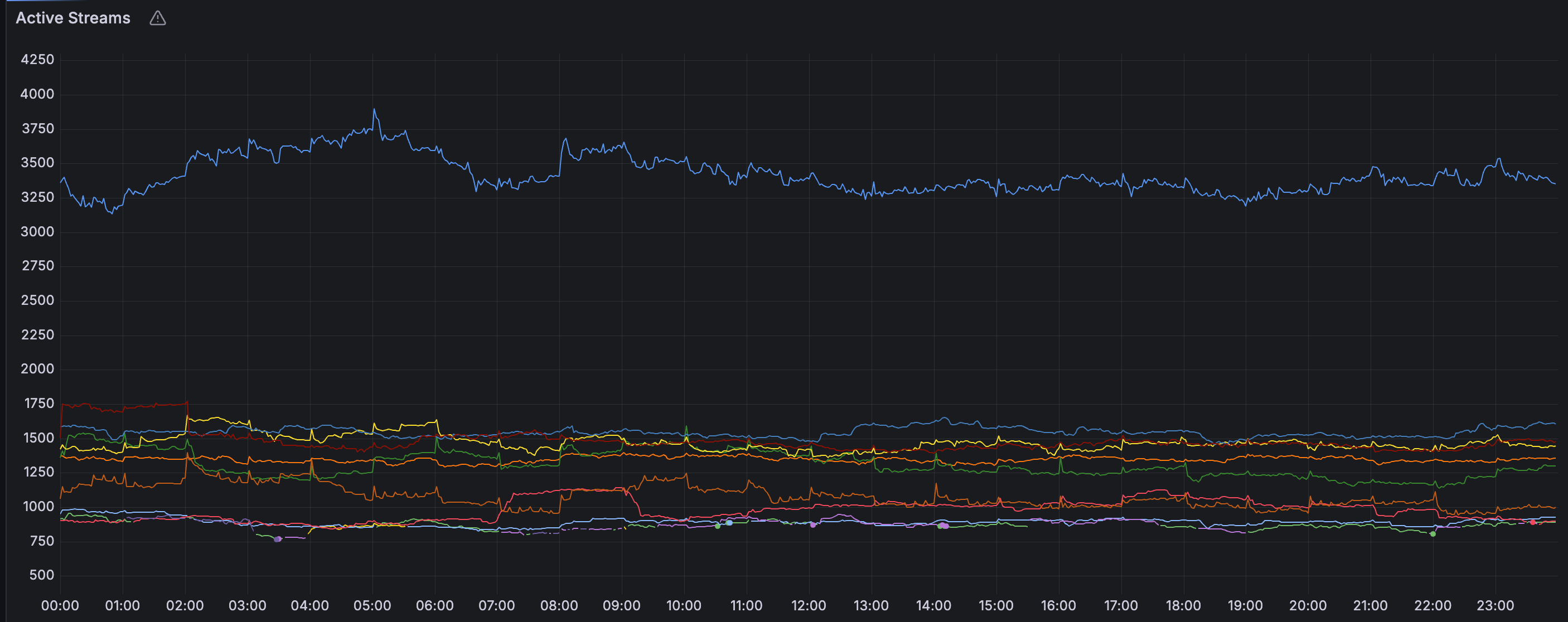
Streams
由以下結果可以看出,stream的寫入數量從最高的20K,大幅減少至3K。stream數量的改變將會改善chunk的使用率,在之後會說明。
| Before | After |
|---|---|
 |  |
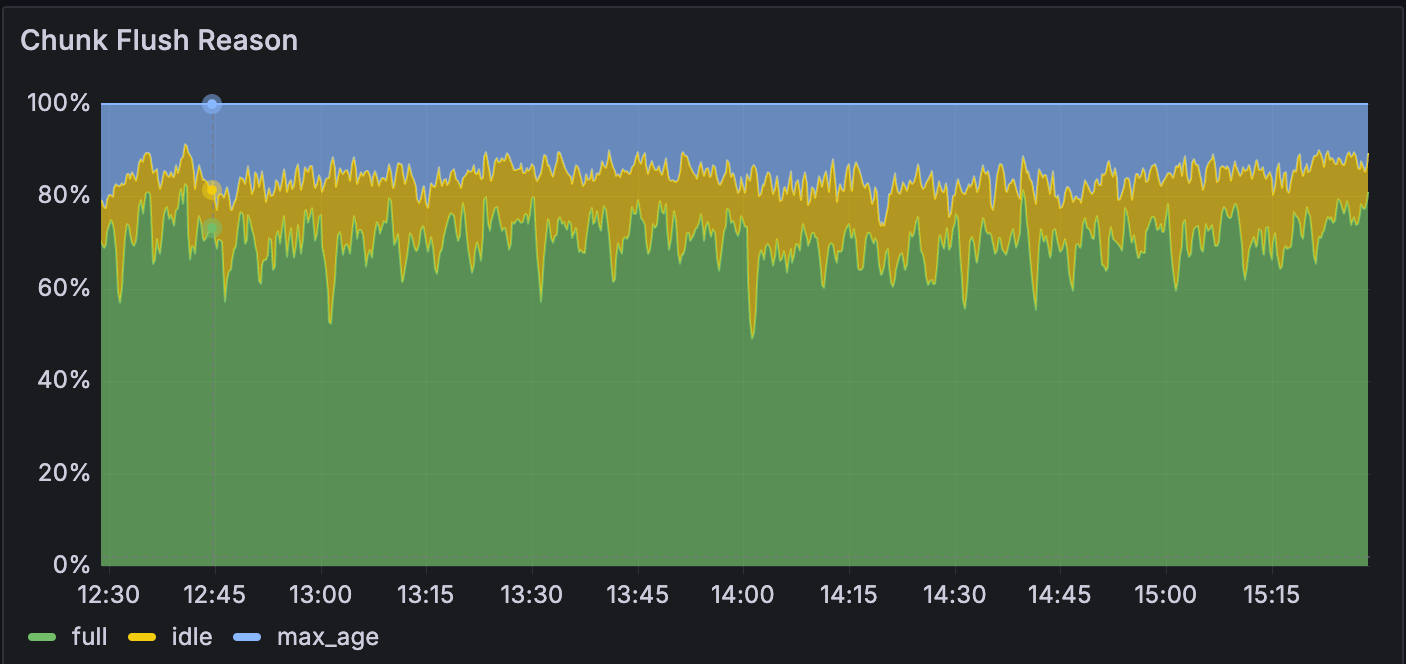
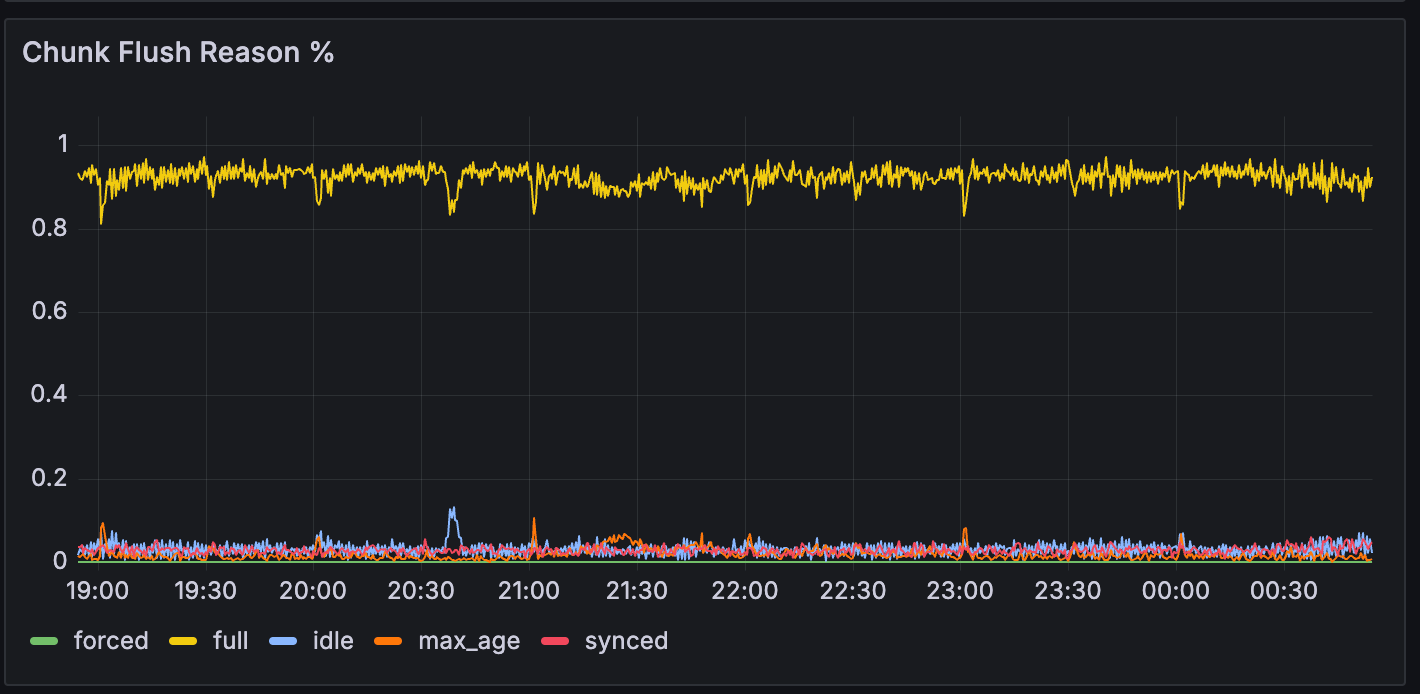
Chunk Flush Reason
從下圖可以看出,full Chunk Flush Reason從原先的70%增加到90%以上。理論上總體log量不會變,但因為stream數量變少,使得每一條stream需要消化的log量將會增大,這將會加速該條stream的chunk寫入,使得chunk更快被填滿,最終導致full Chunk Flush Reason比率的增加。
| Before | After |
|---|---|
 |  |
成效
除了前面提到的full Chunk Flush Reason比率提高以及Stream數量的減少之外,針對Loki labels的改善還帶來以下好處。
更高的Ingester寫入效能
在改善Loki labels的前後,所需的Ingester資源差異列在下表,可以看到Ingester需要的replica減少到原先的30%左右,需要的memory更減少到25%以下。在worker node部分因為我們有特別為Ingester設定pod anti-affinity,所以node數量會跟ingester一樣,每個月省下的成本估計為7萬日幣。
| Ingester’s #replicas | CPU core | memory usage in GB | dedicated worker node | |
|---|---|---|---|---|
| Before | 30 | 10 | 90 | 30 |
| After | 12 | 7.5 | 21 | 12 |
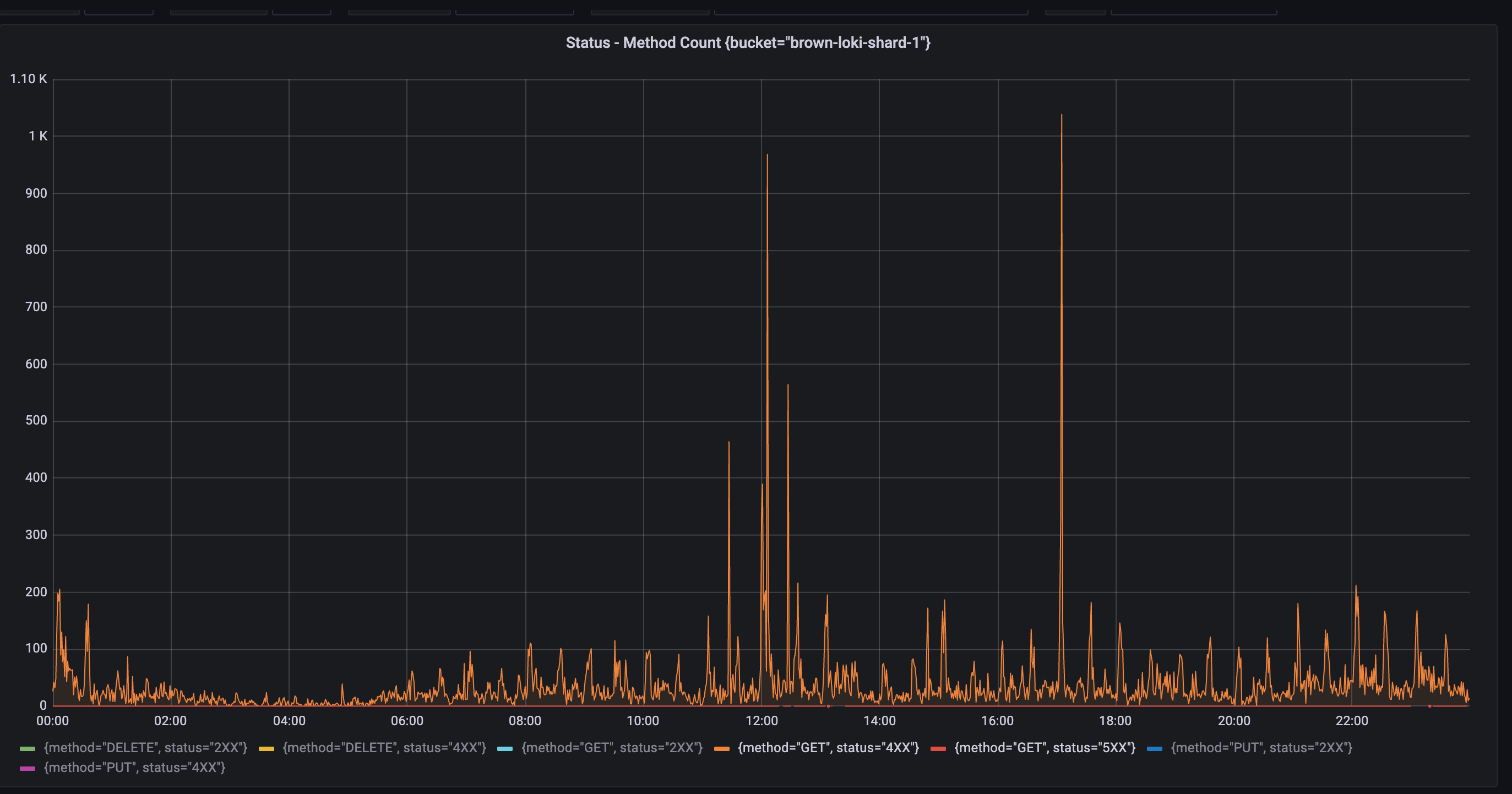
完全消除Object Storage發生rate limit機會
另一個改善Loki labels帶來的效益是,過去在Object Storage頻繁發生的rate limit錯誤(429)已經不再出現。以下的圖表顯示4xx HTTP status code錯誤的前後差異,能看出在新版Loki所使用的bucket沒有任何錯誤發生。我們判斷是因為新版Loki的full Chunk Flush Reason高達九成,再加上Compactor幫忙壓縮剩餘沒有滿的chunk,造成幾乎所有的chunk都是資料密集。比起過去需要使用多個稀疏的chunk,現在可以用更少數量的密集chunk就可以存放相同的log量。這使得Loki在查詢時,需要的Object Storage API請求次數也跟著變少,也就導致rate limit不再發生。另外,我們推斷sharding buckets數量從10增加到20也有幫助。
| Before | After |
|---|---|
 |  |
結論
在本文中,介紹了我們如何平滑地migrate Loki cluster,特別是使用Vector去取代Promtail,大量地運用Vector提供的功能強大Vector Remap Language以及生態系豐富的Vector Components,幫助我們在migrate過程中,除了能不影響現有使用者的操作,更能透過sample技巧,讓新版Loki能接收來自production環境的log。
在有了實際的log流量之後,我們也才能針對新版Loki的config進行重點調校。我們還按照官方建議,針對Loki labels進行特別處理,大幅提升Loki寫入效能,以及完全消弭查詢log帶來的潛在Object Storage負擔。
此外,Vector也提供了Log to Metric Transform功能,能夠將log中紀錄的數值直接轉換成Prometheus metrics,我們使用這功能改進先前Alloy使用經驗,取代掉Loki Ruler進而降低Loki負擔。值得一題的是我在使用Vector上碰到一些可以改進的地方,我也嘗試做些Vector貢獻,希望Vector能發展的更好。
最後,在前面提及的Loki labels改善,事實上會對Loki的Distributor造成潛在負擔,還有其他的Loki component需要做些特別的tuning,更多的Loki config調整細節,將會在下一篇文章中提到,敬請期待!