들어가며: 늘어나는 서비스, 새로운 인프라, 끝없는 문의
여러분의 팀은 하루에 몇 번이나 같은 질문�에 답하고, 같은 작업을 반복하고 계신가요?
LINE Home DevOps 팀은 최근 팀원이 늘어났지만, VOOM 서비스를 안정적으로 운영하는 업무와 새로운 HomeTab 서비스 준비, 새로운 클라우드 인프라 플랫폼인 Flava로 전환하는 일이 겹치면서 오히려 더욱 바빠졌습니다. 어느 하나 포기할 수 없었기에 저희는 이 상황을 개선하기 위한 방법을 찾았고, 문득 팀의 에너지가 중요한 일이 아니라 반복적이고 수동적인 작업에 조금씩 새어 나가고 있다는 것을 발견했습니다. 그렇게 SRE 봇 프로젝트를 시작했습니다.
SRE 팀이 마주한 문제
먼저 저희가 겪은 문제를 조금 더 자세히 살펴보겠습니다.
비효율적인 요청 및 문의 대응 워크플로
새로운 클라우드 인프라 플랫폼 Flava 도입 후 낯선 환경을 마주한 개발자들이 매일같이 수많은 문의와 요청을 쏟아냈고, 여기에 대응하는 일이 저희 하루 업무 시간의 많은 부분을 잠식하고 있었습니다.
- "Flava에서 파드(pod) 로그는 어떻게 확인하나요?"
- "배포 파이프라인 권한 요청은 어디서 하나요?"
- "이 에러 메시지는 무슨 의미인가요?"
- "스테이징 환경 접속이 안 되는데 확인 부탁드립니다"
그중에서도 배포 요청 처리가 가장 많은 시간을 빼앗아 갔습니다. 배포 요청은 요청 하나를 처리하기 위해 Slack → Confluence → Jira를 순서대로 오가며 정보를 복사-붙여넣기해야 했고, 그 과정에서 상당한 컨텍스트 스위칭 비용도 발생했기 때문입니다. 다음은 저희가 배포 요청을 처리하는 과정입니다.
- Slack에서 개발자의 배포 요청 확인
- Confluence에서 릴리스 체크리스트 페이지를 찾아 열기
- 체크리스트 내용을 하나하나 Jira 티켓에 옮기기
- Jira 티켓의 Fix Version 속성이 없으면 먼저 생성하기
- 생성된 티켓을 Epic 링크를 연결하고 스프린트에 추가하기
- Slack 스레드에 Jira 링크 공유하기
- 배포 준비 진행 및 배포 매뉴얼 작성 요청
위 절차를 따라 요청 한 건을 처리하는 데 평균 1시간 가량 소요됐습니다, 각 과정을 처리하기 위한 명확한 기준과 규칙은 있었으나 이를 자동화하지는 않았기에 매번 사람이 하나하나 직접 수행해야 했습니다.
실수를 유발하는 반복 작업의 늪
사람이 직접 하다 보니 실수도 잦았습니다. Fix Version을 잘못 설정하거나, Jira 티켓을 처리하면서 Epic 링크 연결 등 필수 정보 입력을 빠뜨리거나, 릴리스 시 꼭 확인해야 할 체크리스트 항목 중 일부를 누락하는 일이 반복됐습니다. 긴급 상황일수록 실수는 더 잦아졌고, 이 실수를 메꾸기 위해 더 큰 공수가 필요해지기도 했습니다.
진행 상황을 파악하기 어려운 처리 방식
Flava 전환 이후에는 배포 요청 외 일반 문의(기본 사용법, 마이그레이션, 권한 요청 등)도 폭증했습니다. 이런 요청은 Slack 멘션 속에 묻혀 추적하기 어려웠고, 누가 처리 중인지, 완료는 되었는지 파악하기 어려웠습니다. 어떻게 진행되고 있는지 알아보기 위해 개발자와 SRE가 각자 Slack 히스토리를 뒤지며 확인하는 비효율적인 모습이 일상이 되었습니다.
정량화해 살펴본 문제의 규모
저희 팀은 일주일간 이 업무에 얼마나 많은 시간을 투입하고 있는지 측정해 봤고 그 결과 이 문제가 얼마나 큰지 그 규모가 수면 위로 드러났습니다.
| 요청 유형 | 주간 건수 | 건당 소요 시간 | 주간 합계 |
|---|---|---|---|
| 배포 요청 | 약 10건 | 평균 1시간 | 약 10시간 |
| 일반 요청 | 약 40건 | 평균 20분 | 약 14시간 |
| 종합 | 약 50건 | 평균 30분 | 약 15시간 |
전체 업무를 팀원 수로 나눴을 때 SRE 팀원 한 명당 매주 거의 반나절을 단순 반복 작업에 쓰고 있었던 셈입니다. 게다가 이런 처리 방식은 가시성이 부족해 현재 처리 중인 요청 건수조차 제대로 파악하기 어려워 성과로 인정받기도 쉽지 않은 구조였습니다. 이에 저희는 다음과 같은 결론을 내렸습니다.
"인원이 늘었는데도 시간이 부족하다. 이 반복 작업과 간단한 문의 대응을 자동화하지 않으면, 우리는 영원히 소방수 모드에서 벗어날 수 없다."
해결 과정 및 결과
이제 이 문제를 어떻게 해결했는지 설계 방향부터 결과까지 하나씩 자세히 살펴보겠습니다.
자동화 설계 방향: Slack 기반 통합 자동화
문제를 제대로 분석하니 명확한 해결책이 도출됐습니다. 저희는 다음과 같은 세상을 만들어야 했습니다.
"개발자는 Slack만 보면 되고, SRE는 버튼만 클릭하면 되는 세상"
이와 같은 모토 아래 다음과 같은 설계 철학을 세웠습니다.
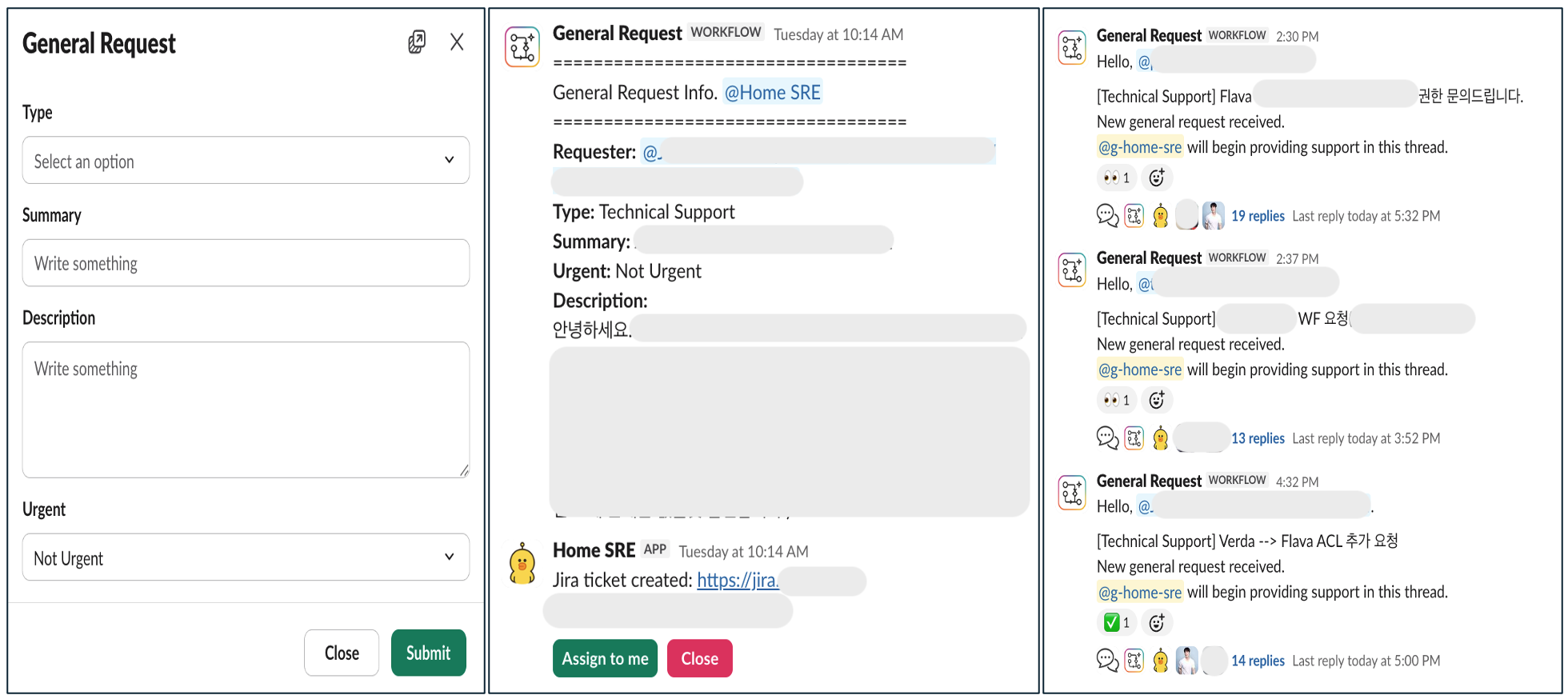
- Single Point of Truth: Slack을 모든 요청의 시작점이자 추적 지점으로 만듭니다.
- Zero Manual Work: 복사-붙여넣기, 버전 생성 등 규칙 기반 작업은 100% 자동화합니다.
- Instant Visibility: 요청 상태를 Slack에서 실시간으로 확인 가능하게 합니다.
- Permission Control: SRE 팀원만 작업 수행 가능하도록 권한을 제어합니다.
이 철학에 기반해 각 단계별로 다음과 같이 핵심 기능을 정의했습니다.
| 단계 | 목표 | 주요 기능 |
|---|---|---|
| 1단계: 기본 자동화 | 요청 접수 및 티켓 생성 자동화 | Slack 워크플로로 요청 받기(배포/일반) Jira 티켓 자동 생성 후 Fix Version 및 스프린트 자동 추가 |
| 2단계: 인텔리전스 추가 | 워크플로 내 정보 자동 연결 | Confluence 릴리스 체크 리스트 자동 반영 서비스별 배포 매뉴얼 자동 검색 및 연결 관련된 이전 배포 티켓 자동 링크 |
| 3단계: 상호작용 | Slack 기반 간편한 상태 관리 | Slack 버튼으로 티켓 할당/완료/재오픈 이모지 반응(👀, ✅, 🔄)으로 빠른 작업 SRE 그룹 멤버만 작업 가능하도록 권한 체크 |
설계 과정에서의 기술적 의사 결정과 그 이유
설계 과정에서 내린 기술적 의사 결정과 그런 결정을 내린 이유를 하나씩 살펴보겠습니다.
결정 1: Slack 워크플로 vs. 슬래시(/) 명령어
사용자가 요청하는 방식을 결정하는 것은 SRE 봇의 성패를 좌우하는 첫 번째 선택이었습니다. 슬래시 명령어는 구현하기는 쉽지만 사용자가 직접 형식에 맞게 텍스트를 입력해야 한다는 단점이 있습니다. 입력 과정에서 필수 항목을 빠뜨려도 즉시 알 수 없고, 만약 형식에 맞지 않게 입력할 경우 봇이 이를 처리하는 데 실패할 수도 있었습니다.
반면 Slack 워크플로는 사용자가 양식을 훨씬 직관적으로 채울 수 있습니다. 필수 항목을 Slack UI 단에서 검증하기 때문에 애초에 빈 값이 들어올 수 없고, Slack 네이티브 기능이기 때문에 UI를 별도로 개발할 필요도 없습니다. 저희는 사용 장벽을 낮추는 것이 자동화의 핵심이라고 판단해 Slack 워크플로를 선택했습니다.
결정 2: 동기 vs. 비동기
Jira 티켓 생성, Confluence 검색, 스프린트 추가 등의 외부 API 호출을 어떻게 처리할지도 중요한 결정이었습니다. Slack은 이벤트 응답을 3초 이내에 받아야 하는데 여러 외부 API를 순차적으로 호출하면 이 시간을 쉽게 초과합니다. 따라서 동기 처리 방식을 고집하면 Slack에서 타임아웃 에러가 발생하며, 사용자는 외부 API 호출이 어떻게 처리됐는지 알 수 없습니다.
이 문제를 해결하기 위해 백그라운드에서 작업하는 비동기 처리 방식을 선택했습니다. 봇은 이벤트를 받는 즉시 "요청이 접수되었습니다"라는 메시지를 반환한 뒤 실제 처리는 백그라운드에서 완료합니다. 이렇게 처리하면 에러가 발생하더라도 Slack 스레드에 별도 알림을 보낼 수 있어 처리 과정 또한 투명하게 만들 수 있습니다.
결정 3: 상태 저장 전략
Slack 스레드와 Jira 티켓의 매핑 정보를 어디에 저장할지도 고민해야 했습니다. 봇 메모리에 저장하면 재시작 시 모든 정보가 사라지고, Slack 메타데이터 API는 조회 성능이 느려 이모지 클릭 같은 실시간 상호작용에 적합하지 ��않습니다.
저희는 고민 끝에 Redis에 TTL(time to live) 30일을 조합하는 선택을 했습니다. Redis는 100ms 미만의 빠른 조회를 제공하면서도 영구 저장이 가능합니다. 여기에 더해 Redis Transaction(WATCH/MULTI/EXEC)을 활용해 동시성 문제도 해결했습니다. 여러 SRE 팀원이 동시에 버튼을 클릭하더라도 원자적 업데이트로 데이터 일관성을 보장합니다.
결정 4: 아키텍처 패턴
코드베이스가 커질 것을 대비해 헥사고날 아키텍처(포트 & 어댑터) 패턴을 선택했습니다. SRE 봇은 Slack, Jira, Confluence, Redis 등 여러 외부 시스템과 통합하는 것이 핵심입니다. 따라서 각 시스템과의 결합도를 낮추는 것이 장기적으로 중요하다고 판단했습니다.
저희는 단순히 코드를 계층으로 분리한 것이 아니라, '인터페이스를 통한 외부 환경과의 격리'를 설계 원칙으로 삼았습니다. 이렇게 하면 추상화된 포트(프로토콜 인터페이스) 덕분에 외부 서비스(예: Jira API 버전 업그레이드, Slack SDK 변경)가 바뀌더라도 내부 비즈니스 로직은 단 한 줄도 수정할 필요가 없습니다. 실제로 이 구조는 기능을 추가할 때마다 그 가치를 발휘했고, 테스트 작성도 훨씬 수월해졌습니다.
최종 구조는 다음과 같습니다.
- 인바운드 어댑터(Slack 이벤트) → 비즈니스 로직(유스케이스) → 아웃바운드 어댑터(Jira, Confluence, Redis)
시나리오별 SRE 봇 도입 전후 비교
그럼 SRE 봇 도입 전후로 사용 시나리오가 어떻게 변화했는지 살펴보겠습니다.
시나리오 1: 배포 요청 처리
SRE 봇 도입 전(수동 처리)
- 시나리오: 개발자가 Slack에 "배포 요청합니다"라는 메시지를 남기면, SRE가 확인 후 Confluence에서 릴리스 체크리스트 페이지를 열어 내용을 복사합니다. 그런 다음 Jira에서 티켓을 만들며 Summary와 Description 필드를 채워넣고, Fix Version이 없으면 먼저 생성한 뒤 Epic 링크를 연결하고 스프린트를 찾아 추가합니다. 이어서 배포 매뉴얼을 검색해서 링크를 첨부한 뒤 마지막으로 Slack 스레드에 Jira 링크를 공유합니다.
- 총 SRE 작업 시간: 약 30분
- 실수 가능성: 높음(버전 누락, Epic 미연결, 체크리스트 일부 누락 등)
SRE 봇 도입 후
- 시나리오
- [5분] 개발자가 아래 필수 정보 입력 후 Slack 워크플로 ‘배포 요청’ 실행
- 프로젝트 이름: my-service
- 릴리스 버전: v1.2.3
- Confluence 체크리스트: https://wiki.../pages/12345
- 기타 필수 정보 입력
- [자동 10초] SRE 봇이 백그라운드에서 다음 작업 수행
- Fix Version v1.2.3이 없으면 자동 생성
- Jira 티켓 생성(HENG-1234)
- Epic 링크 연결
- 활성 스프린트에 자동 추가
- my-service 배포 매뉴얼 자동 검색 및 링크
- Slack 스레드에 결과 알림
- 👀 이모지 클릭한 SRE에게 자동으로 할당
- 배포 일정 수립 및 작업 수행
- ✅ 이모지 클릭 → 티켓 자동 완료 + Slack 알림
- [5분] 개발자가 아래 필수 정보 입력 후 Slack 워크플로 ‘배포 요청’ 실행
- 총 SRE 작업 시간: 1분 이내
- 실수 가능성: 거의 없음(SRE 봇으로 모든 규칙 자동 적용)
시나리오 2: 긴급 요청 처리
SRE 봇 도입 전
- 시나리오: 개발자가 "긴급입니다! 프로덕션 이슈로 핫픽스 배포 필요합니다"라고 Slack에 남겼지만, 다른 업무 중이던 SRE는 이를 바로 확인하지 못합니다. 30분이 지나서야 개발자가 다시 멘션을 보내고, SRE는 급하게 10분 만에 티켓을 생성하지만 Priority를 ‘Highest’로 설정하는 것과 스프린트 추가를 누락합니다. 결국 나중에 리포트를 작성할 때 이 티켓을 찾지 못하는 상황까지 벌어집니다.
- 총 지연 시간: 30~40분
- 업무 혼선 가능성: 높음
SRE 봇 도입 후(SRE 봇과 Slack 이모지를 이용한 워크플로우)
- 시나리오
- 개발자가 워크플로 '긴급 배포 요청' 실행(긴급 선택 시 자동으로 Priority를 ‘Highest’로 설정)(소요 시간: 1분)
- SRE 봇이 Slack 채널에 "🚨 긴급 배포 요청이 등록되었습니다! HENG-1234"라고 알림(소요 시간: 없음(즉시 실행))
- SRE가 알림을 보고 👀 이모지 클릭해 즉시 본인에게 할당(Jira에는 이미 앞서 Priority와 스프린트가 자동 설정된 상태)(소요 시간: 5초)
- 핫픽스 배포 완료
- SRE가 ✅ 이모지 클릭하면 티켓이 자동으로 완료되고 Slack에 알림 메시지도 자동 발송
- 총 지연 시간: 1분
- 업무 혼선 가능성: 없음(모든 정보가 Slack과 Jira에 기록됨)
시나리오 3: 일반 SRE 요청 처리
SRE 봇 도입 전(Slack 멘션으로 요청)
- 시나리오: 개발자가 "@SRE Flava 프로덕션 환경 접근 권한 필요합니다"라고 멘션을 걸어 메시지를 보내면, SRE는 다른 업무 탓에 늦게 확인하고 권한 부여 작업을 수행합니다. 나중에 추적하기 위해 Jira에 수동으로 티켓을 만드는데, Summary와 Description을 직접 작성하고 Epic 연결에 스프린트 추가까지 마쳐야 합니다. 한 주가 지나 개발자가 "그때 권한 요청 티켓 번호가 뭐였죠?"라고 다시 묻고, SRE는 Slack과 Jira를 뒤지며 3분을 더 씁니다.
- 총 소요 시간: 10분 이상
- 추적 어려움(Slack 메시지 속에 묻힘)
SRE 봇 도입 후(SRE 봇 일반 요청 워크플로)
- 시나리오
- 개발자가 Slack 워크플로 '일반 SRE 요청' 실행(소요 시간: 1분)
- 요청 유형: 인프라 권한
- 상세 내용: Flava 프로덕션 환경 접근 권한
- 긴급 여부: 아니오
- SRE 봇이 백그라운드에서 다음 작업 수행(소요 시간: 자동 5초)
- Jira 티켓 자동 생성 (HENG-2345)
- Epic 링크 연결
- 활성 스프린트에 자동 추가
- Priority 자동 설정(긴급이 아니기 때문에 ‘Medium’으로 설정)
- Slack 스레드에 티켓 링크 알림
- SRE가 👀 이모지 클릭해 본��인에게 할당
- 권한 부여 작업 수행
- ✅ 이모지 클릭하면 티켓 자동 완료 + Slack 알림
- 개발자: Slack 스레드에서 바로 HENG-2345 확인
- 개발자가 Slack 워크플로 '일반 SRE 요청' 실행(소요 시간: 1분)
- 총 소요 시간: 5분 이내(SRE 실제 작업 시간만)
- 추적 쉬움(Slack 스레드에서 티켓 링크 상시 확인 가능)
- 활용 사례
- Flava 사용법 문의: '파드 로그 확인 방법' → 배포 매뉴얼 링크 자동 첨부
- 네트워크 이슈 조사: '스테이징 DB 접속 불가' → 티켓으로 이슈 추적, 해결 과정 기록
- 모니터링 구축 요청: '신규 서비스 대시보드' → Epic에 자동 연결, 스프린트에서 우선순위 관리
시나리오 4: 이전 배포 참고
SRE 봇 도입 전
- 시나리오: 개발자가 "지난 v1.1.0 배포 때 뭐 했었죠?"라고 물으면, SRE가 Jira에서 직접
project = HENG AND summary ~ 'my-service v1.1.0'을 실행해 검색합니다. 검색 결과로 나온 티켓 세 개 중 어느 게 맞는지 확인하기 위해 하나씩 열어보다 보면 5분이 지나 있습니다. - 총 소요 시간: 5분 이상
SRE 봇 도입 후
- 시나리오: SRE 봇이 새 배포 티켓을 생성할 때 관련 이전 배포 티켓 링크를 아래와 같이 자동으로 추가합니다. 개발자는 Jira 티켓에서 링크를 클릭하기만 하면 됩니다. 5분 걸리던 작업이 10초로 줄었습니다.
- 'Related Deployments: HENG-1123 (v1.1.0), HENG-1045 (v1.0.5)'
- �총 소요 시간: 10초
예상치 못한 도전과 해결
자동화 과정 중 예상치 못한 난관에 부딪치기도 했습니다. 어떤 난관이 있었고 어떻게 해결했는지 하나씩 살펴보겠습니다.
도전 1: Central Dogma 설정 핫 리로드
SRE 봇은 설정 저장소로 Central Dogma(참고)를 사용합니다. 이 Central Dogma에서 Epic 키나 라벨 같은 설정을 변경하면 봇에 자동으로 반영돼야 하는데 새로 생성되는 Jira 티켓에 변경 사항이 적용되지 않는 버그가 발생했습니다.
원인을 추적해 보니 구조적인 문제였습니다. ConfigWatcher가 Central Dogma 변경을 감지하고 Settings 객체를 업데이트하는 것까지는 정상이었지만, 의존성 주입 컨테이너는 초기화 시점의 설정 값을 캡처해 두기 때문에 Settings를 업데이트해도 컨테이너는 여전히 옛날 값을 사용하고 있었던 것입니다.
해결 방법은 비교적 명확했습니다. 먼저 Settings는 업데이트되지만 실제 티켓 생성 시 이전 값이 사용된다는 것을 로그를 추가해 확인한 후, Settings 업데이트와 동시에 컨테이너 설정도 함께 업데이트하도록 수정했습니다. 이후 Central Dogma에서 Epic을 변경하고 5분 뒤 새 티켓이 변경된 Epic으로 생성되는 것을 확인해 검증했습니다.
이 경험에서 배운 교훈은 두 가지입니다. 의존성 주입 컨테이너를 사용할 때는 설정 변경이 실제로 전파되는 경로를 명확히 이해해야 한다는 것과, Factory Provider는 매번 설정을 다시 평가하므로 컨테이너 설정만 올바르게 업데이트하면 자동으로 반영된다는 것입니다.
�도전 2: 동시 요청 처리 시 Redis 데이터 불일치
SRE 봇을 여러 인스턴스로 운영하는 환경에서 같은 Slack 스레드에서 여러 SRE 팀원이 거의 동시에 버튼을 클릭하면 Redis 데이터가 꼬이는 문제가 발생했습니다. SRE A가 할당 버튼을 클릭해 상태를 ‘assigned’로 변경하는 순간 SRE B도 같은 버튼을 클릭하면 Redis에 저장된 SRE A로 할당된 데이터가 SRE B로 덮어씌워지는 것입니다.
원인은 경쟁 상태(race condition)였습니다. 저희는 Redis에서 ‘GET → 수정 → SET’ 패턴을 사용했는데요. 두 요청이 거의 동시에 GET을 하면 둘 다 같은 값을 읽고 각자 SET을 해버렸습니다. 서비스 가용성을 높이기 위해 여러 인스턴스를 운영하면 필연적으로 발생하는 문제라고 할 수 있습니다.
해결책은 Redis Transaction(WATCH, MULTI, EXEC)을 사용한 ‘낙관적 락(optimistic locking)’이었습니다. 특정 키를 WATCH로 감시하다가, 트랜잭션(MULTI)을 실행하기 전에 다른 프로세스가 값을 변경했다면 실행을 취소하고 재시도(max_retries)하는 방식입니다. 단순히 락을 걸어 대기시키는 것이 아니라 실패 시 즉시 재시도하는 방식이기 때문에 사용자 경험을 해치지 않으면서도 데이터 정합성을 완전히 보장할 수 있었습니다.
자동화 결과 얻은 부수적 장점
SRE 봇을 이용한 자동화는 의도치 않은 장점도 안겨줬습니다.
장점 1: 데이터 축적 및 분석 가능
모든 요청이 구조화된 형태로 기록되면서 다음과 같은 인사이트 도출이 가능해졌습니다.
- '가장 많이 배포하는 서비스는?' → 리소스 우선순위 결정
- '평균 배포 소요 시간은?' → SLA(service level agreement) ��설정 근거
- '어느 시간대에 요청이 집중되나?' → 온콜 일정 최적화
- '한 달에 어느 정도 요청을 처리하는가?' → 업무 가시화 및 성과 기록 가능
장점 2: 온보딩 시간 단축
신규 SRE 팀원이 배포 프로세스를 익히는 시간이 크게 줄었습니다.
- SRE 봇 도입 전: 기존 동료가 1:1로 2~3일 교육 및 직접 Slack에서 업무 기록을 하나씩 찾아가면 공부
- SRE 봇 도입 후: #help-sre 채널에서 Slack 워크플로를 통해 처리한 업무 기록을 보며 학습
향후 계획
SRE 봇의 1단계 자동화로 반복 작업의 부담을 크게 줄였지만, 이것은 시작에 불과합니다. 다음 단계에서는 단순 자동화를 넘어 '지능형 자동화'로 나아가는 것이 목표입니다.
노드 기반 업무 자동화 플랫폼과 통합 워크플로 플랫폼 통합
현재 SRE 봇은 Python 코드로 워크플로를 직접 구현하고 있습니다. 이에 따라 새로운 자동화를 추가할 때마다 코드를 변경하고 배포해야 하는데요. n8n이나 make와 같은 플랫폼과 통합하면 로우 코드(low-code) 방식으로 복잡한 워크플로를 구성할 수 있어 개발 속도를 크게 높일 수 있습니다. 예를 들어 ‘배포 승인 후 자동으로 CD 파이프라인 트리거’처럼 여러 시스템을 연결하는 복잡한 흐름도 코드 없이 구성할 수 있게 됩니다.
쿠버네티스 MCP 서버 통합
현재 클러스터 관리 작업(파드 재시작, 스케일 아웃 등)은 여전히 터미널에서 직접 수행해야 하는데요. 쿠버네티스 MCP 서버를 통합하면 이런 작업을 Slack 내 명령어로 트리거할 수 있습니다. 따라서 SRE가 터미널과 Slack 사이를 오가지 않아도 되므로 사고 대응 속도가 더욱 빨라질 것으로 기대합니다.
Github과 Confluence, Jira MCP 통합
자연어로 "지난주 배포된 서비스들"이나 "내가 담당한 긴급 티켓 중 미완료 건"을 바로 조회할 수 있다면 얼마나 편할까요? MCP를 통해 Confluence, Jira, Github를 자연어 인터페이스로 연결하는 것이 다음 목표입니다. 특히 Github MCP를 활용하면 FKE(Flava Kubernetes Engine, 사내용 쿠버네티스 클러스터 서비스)에서 발생하는 파드 생성이나 이미지 업데이트 변경 사항도 자동으로 추적할 수 있습니다.
RAG(retrieval-augmented generation)와 LLM을 이용한 자동 응답
현재 일반 문의는 SRE가 직접 답변하거나 처리하고 있지만, 잘 정리된 Confluence 문서와 Flava 문서를 RAG에 저장하고 LLM과 연결한다면 반복적인 일반 문의에는 봇이 1차로 자동 응답할 수 있습니다. SRE는 봇이 해결하지 못한 복잡한 문의에만 집중할 수 있어, 팀의 시간과 에너지를 더 중요한 곳에 사용할 수 있게 됩니다.
마치며: 작은 자동화가 만든 큰 변화
SRE 봇 프로젝트를 시작할 때만 해도 ‘그냥 Slack으로 티켓 생성하는 봇’ 정도로 생각했습니다. 하지만 실제로 만들고 운영해 보니 반복 작업을 없애면 단순히 시간만 절약되는 것이 아니라 팀의 집중력과 사기까지 높아진다는 것을 깨달았습니다. 숫자만 보면 ‘주당 6시간 이상 절약’에서 그칠 것입니다. 하지만 더 중요한 변화는 수치로 잡히지 않는 곳에서 일어났습니다. SRE 팀원들은 소방수 역할에서 벗어나 New HomeTab 인프라 아키텍처 설계와 VOOM 성능 최적화, Flava 플랫폼 안정화처럼 정말 중요한 일에 집중할 수 있게 되었습니다. 개발자들이 SRE 팀에 요청하는 심리적 장벽도 낮아졌습니다. 간단한 권한 요청도 부담 없이 워크플로로 보낼 수 있게 되었고, 모든 요청이 투명하게 기록되면서 팀 간 신뢰도 높아졌습니다.
SRE 팀은 이 경험을 통해 얻은 다음 네 가지 기술적 교훈을 얻었습니다.
첫째는 ‘사용자 중심으로 설계하라’입니다. SRE 봇 성공의 핵심은 슬래시 명령어 대신 워크플로를 선택한 것입니다. 저희는 더 간단한 방법으로 개발할 수 있었지만 조금 더 어려운 대신 사용자가 더 편하게 쓸 수 있는 방법을 선택했습니다. 그 결과 아무리 뛰어난 자동화도 사용자가 쓰지 않으면 의미가 없다는 사실을 다시 한번 확인했습니다.
둘째는 ‘점진적으로 개선하라’입니다. 저희는 처음부터 완벽한 봇을 만들려고 하지 않았습니다. 기본 자동화로 시작해서 이모지 워크플로를 추가하고, 단계적으로 기능을 쌓아갔습니다. 완성된 그림을 미리 그리는 것보다 작동하는 것을 빠르게 내보내고 개선하는 것이 훨씬 효과적이었습니다.
셋째는 ‘측정 가능한 목표를 세워라’입니다. ‘편하게 만들자’가 아니라 ‘30분을 5분으로 줄이자’처럼 구체적인 목표를 세우는 것이 중요합니다. 수치로 나와야 얼마나 개선됐는지 확인할 수 있고, 팀과 조직의 지지를 얻을 수도 있습니다.
넷째는 ‘확장 가능한 아키텍처로 설계하라’입니다. 헥사고날 아키텍처를 선택한 덕분에 새로운 기능(MCP, 노드 기반 업무 자동화 플랫폼)을 추가하기가 쉬워졌습니다. 단기적으로는 복잡해 보이는 설계가 장기적으로는 유지 보수 비용을 크게 낮춰준다는 것을 몸소 경험했습니다.
만약 여러분의 팀에도 반복적인 수작업이 있다면 먼저 1주일간 해당 업무에 투입되는 시간을 측정해 보세요. 얼마나 많은 시간이 새어 나가는지 정량화하는 것이 첫걸음��입니다. 그 다음 가장 자주 하는 세 가지 작업부터 자동화한 뒤 사용자 피드백을 받아 적극 반영하는 방법으로 작게 시작해 보세요. SRE 봇도 처음에는 단순히 ‘Slack → Jira 티켓 생성’만 했습니다. 그리고 그 작은 시작이 지금의 변화를 만들었습니다.
자동화는 단순히 코드를 작성하는 것이 아니라, 팀이 일하는 방식을 바꾸는 것입니다. 여러분의 팀에도 이런 변화가 일어나기를 응원합니다!


