모바일 앱을 성공적으로 운영하려면 장애 모니터링은 필수입니다. 회원 가입이나 결제 과정에서 오류가 발생했을 때 이를 즉시 파악하고 대응하지 못하면 사용자 이탈로 이어지기 때문입니다. 한 번 떠난 사용자를 다시 돌아오게 하는 일은 생각보다 어렵고 비용도 많이 듭니다. 사전 테스트를 아무리 철저히 해도 운영 환경에서는 예기치 못한 장애가 언제든 발생할 수 있으며 이런 장애를 빠르게 포착해 즉시 대응하는 체계가 없다면 품질은 금세 무너질 수 있습니다. 문제를 사용자 신고로 처음 인지한다면 대개 이미 늦은 것입니다.
장애를 모니터링하는 방법으로는 아래와 같은 것들이 있습니다.
- 이벤트 수집과 분석: Sentry나 Firebase, New Relic 등을 활용해 앱 크래시, 로그인 성공/실패, 구매 성공/실패와 같은 핵심 이벤트를 실시간으로 수집/집계/분석해서 사용자 영향도를 파악합니다. 수집된 데이터를 바탕으로 대시보드를 구성하고, 긴급 이슈는 즉시 대응할 수 있도록 이메일과 Slack 알림을 설정합니다.
- 성능 모니터링: API 응답 시간이나 화면 로딩 완료까지 걸린 시간 등을 측정합니다. Sentry Performance Monitoring이나 Firebase Performance Monitoring을 사용하면 병목 구간을 빠르게 식별할 수 있습니다.
- 사용자 피드백 수집: 앱 내 피드백 버튼이나 설문, 스토어 리뷰 등을 통해 사용자 의견을 수집해서 반복적으로 언급되는 이슈를 파악��합니다.
- 실시간 알림: 장애가 발생하면 즉시 대응할 수 있도록 Slack이나 이메일로 통지합니다. 일반적으로 알림은 꼭 필요할 때 최소한의 인원에게만 통지되도록 운영하며, 장애가 장기화되면 수신 대상을 단계적으로 확대합니다.
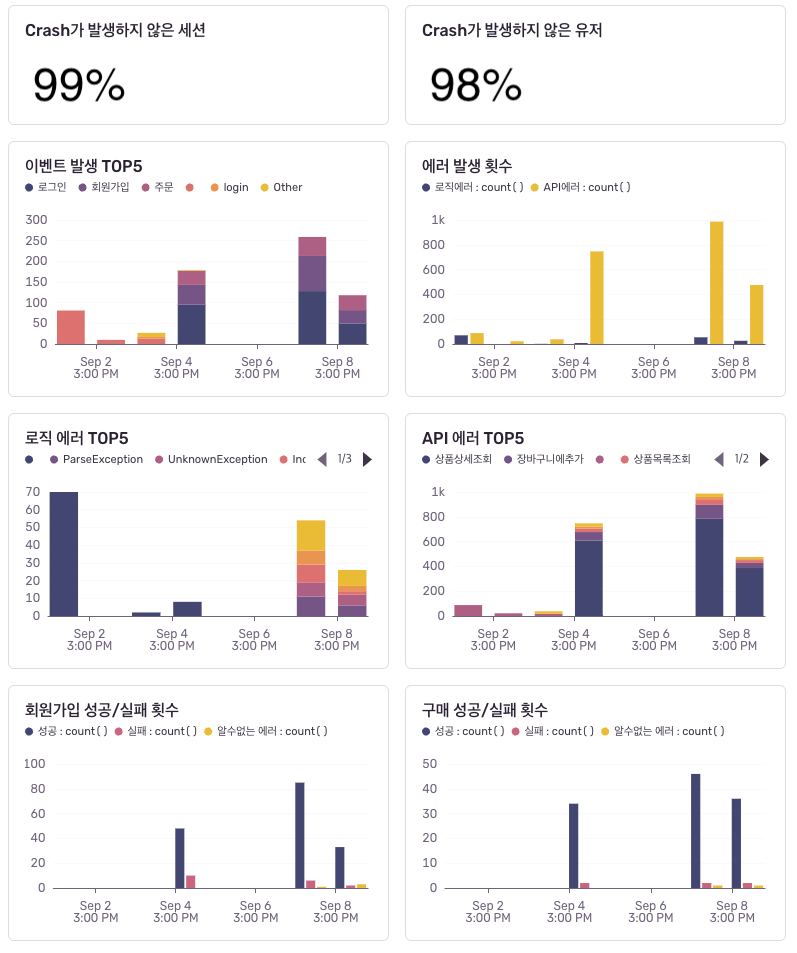
- 지표와 대시보드 구성: 주요 성능 지표를 시각화해 한눈에 모니터링할 수 있는 대시보드를 구성합니다. 일반적으로 새 릴리스의 안정성은 비정상 종료가 발생하지 않은 사용자(crash-free users) 비율로 확인하고, API 오류율과 로그인, 회원 가입, 구매 등 주요 이벤트의 실패율도 함께 추적합니다.
이 글에서는 위 방법 중 첫 번째 방법인 '이벤트 수집과 분석' 방법을 고도화해 아래와 같은 대시보드를 만드는 과정을 공유하겠습니다. Flutter와 Sentry를 예시로 설명하지만 로그 레벨 설계와 메시지 형식 및 대시보드 구성 원칙 정하기, 알람 설정 등의 내용은 어떤 도구를 사용하든 거의 동일하게 적용할 수 있을 것이라고 생각합니다.
Flutter에서 Sentry 사용 설정하기
��먼저 Flutter에서 Sentry를 빠르게 사용할 수 있도록 설정 및 사용 방법의 핵심을 추려 정리해 봤습니다. 다른 도구를 사용하거나 이미 사용법을 알고 계신다면 이 섹션은 넘어가셔도 좋습니다.
디펜던시 추가
dependencies:
sentry_flutter: ^9.6.0
sentry_dio: ^9.6.0 # Dio 사용 시 네트워크 관련 로그를 자동으로 보고합니다.기본 초기화
void main() {
SentryFlutter.init((options) {
// Sentry에서 발급받은 클라이언트 키를 입력합니다.
options.dsn = const String.fromEnvironment('SENTRY_DSN');
// 현재 환경(운영/스테이징/개발)을 태깅합니다.
options.environment = const String.fromEnvironment('APP_ENV', defaultValue: 'production');
// 릴리스/빌드 번호를 태깅합니다.
options.release = 'com.example.app@1.2.3+42';
// 비용 문제가 걱정된다면 샘플링 비율을 적정한 비율로 설정해 트래픽·비용을 조절하세요.
options.tracesSampleRate = 0.1;
options.profilesSampleRate = 0.1;
// 서버로 전송하기 전에 민감한 정보를 마스킹합니다.
options.beforeSend = (event, hint) {
// event.request?.headers?.remove('Authorization');
// event.user = event.user?.copyWith(ipAddress: null);
return event;
};
}, appRunner: () => runApp(SentryWidget(child: MyApp())));
}사용자 설정 및 컨텍스트
// 로그인 성공 후 사용자 아이디를 설정합니다.
void onLoginSuccess(String userId) {
Sentry.configureScope((scope) {
scope.setUser(SentryUser(id: userId));
});
}사용자 동작 이벤트 기록
사용자의 클릭 및 화면 이동 이벤트를 기록으로 남기면 에러 발생 직전의 행동 맥락을 복원할 수 있습니다. 단, 과도하게 많은 기록을 남기면 노이즈가 발생하므로 핵심 행동(결제 버튼 등) 위주로만 남기는 게 좋습니다.
void trackTap(String label) {
Sentry.addBreadcrumb(Breadcrumb(message: 'tap: $label', category: 'ui'));
}화면·네비게이션 자동 태깅
로그가 전송되는 시점에 어떤 화면을 보고 있었는지 알 수 있도록 SentryNavigatorObserver를 연결합니다.
return MaterialApp(
navigatorObservers: [SentryNavigatorObserver()],
home: const MyHomePage(),
);HTTP 클라이언트 성능 측정
HTTP 호출을 추적하면 속도가 느린 API를 대시보드에서 바로 확인할 수 있습니다. 다음은 dio 라이브러를 사용하는 경우의 예시입니다.
final dio = Dio();
dio.interceptors.add(SentryInterceptor());커스텀 이벤트 로깅(성공 여부와 이유)
로그인이나 구매 성공 여부와 같은 주요 이벤트에 대해 명명 규칙을 정하고 �태그로 모듈·이유를 명확히 남깁니다. 전송된 로그는 쿼리문으로 검색하거나, 대시보드 구성에 사용할 수 잇습니다.
Future<void> logOrderResult({
required bool success,
required String orderId,
String? reason, // ex) 'payment_declined', 'stock_unavailable'
}) async {
await Sentry.captureEvent(SentryEvent(
level: success ? SentryLevel.info : SentryLevel.warning,
message: SentryMessage(success ? 'order_success' : 'order_failed'),
tags: {
'module': 'API',
'eventName': 'putOrder',
if (reason != null) 'reason': reason,
},
));
}Sentry로 로그 전송하기
Flutter에서 Sentry를 사용할 준비가 완료됐다면 이제 이벤트 발생 시 관련 로그를 생성해 Sentry 로그 서버로 전송해 기록할 수 있습니다. 아래는 각 이벤트가 발생했을 때 로그를 전송하는 예제 코드입니다.
// 로그인 성공
await Sentry.captureEvent(
SentryEvent(
level: SentryLevel.info,
message: const SentryMessage('[API] [postLogin] success'),
tags: {
'module': 'API',
'eventName': 'postLogin',
},
),
);
// 주문 실패
await Sentry.captureEvent(
SentryEvent(
level: SentryLevel.warning,
message: const SentryMessage('[API] [putOrder] failed'),
tags: {
'module': 'API',
'eventName': 'putOrder',
},
extra: {
'endpoint': 'POST /v1/orders',
'request': {
'body': {'orderId': 'ord_***'}, // 결제 정보 마스킹
},
'response': {
'status': 402,
},
},
),
);
// null 객체가 오면 안 됨
await Sentry.captureEvent(
SentryEvent(
level: SentryLevel.error,
message: const SentryMessage('[Logic] [nullObj] failed'),
tags: {
'module': 'Logic',
'eventName': 'nullObj',
},
),
);위 예제에서 각 항목(level, message, tags, extra 등)을 어떻게 설정하는지 설정 방법과 설정하는 이유를 하나씩 살펴보겠습니다.
로그 레벨 설계하기
너무 많은 로그를 기록하고 쌓으면 그 트래픽과 비용을 감당하기 어렵기 때문에 로그를 그 특성에 따라 분류해 꼭 필요한 로그만 쌓아야 합니다. 저는 아래와 같이 5단계로 로그 레벨을 나눠 각 레벨에 맞춰 로그를 관리하고 있습니다. 아직 규칙을 정하지 않았다면 제 방법을 한 번 따라해 보셔도 좋고, 여러분만의 규칙을 정해서 사용하셔도 좋습니다.
- debug
- info
- warning
- error
- fatal
debug
개발 단계에서만 사용합니다. 로그는 터미널 창으로만 출력하며, 로그 서버로 전송해 기록하지는 않습니다.
info
사용자의 행동으로 데이터가 변경되는 행위를 로그 서버로 전송해 기록합니다. info 레벨의 로그는 실시간으로 모니터링하지는 않지만 에러 발생 후 사용자의 행동을 추적할 때 도움이 되는 데이터입니다. 다음은 info 레벨로 설정하는 로그의 예시입니다.
- 회원 가입 호출: 로그 서버로 전송합니다.
- 데이터가 변경되는 행위이므로 기록합니다.
- 상품 구입 호출: 로그 서버로 전송해 기록합니다.
- 상품 목록 조회: 로그 서버로 전송하지 않습니다.
- 이 요청은 서버의 데이터를 변경하지 않습니다. 또한 굉장히 자주 발생하는 행위이기 때문에 로그 서버로 전송해 기록하면 과도한 트래픽을 유발하고 로그 저장 비용이 늘어날 수 있습니다.
warning
외부 시스템과의 연동 실패는 warning 레벨로 기록합니다. 예를 들어 다음과 같은 사례 발생 시 warning 레벨 로그로 기록합니다.
- 회원 가입 실패
- 상품 목록 조회 실패(성공 시에는 기록하지 않았지만 실패 시에는 기록)
- 푸시 알림 유실
- 원격 설정(remote config) 연동 실패
단, 위와 같은 이벤트가 발생하더라도 그 실패 사유가 사용자 측 네트워크 오류라면 로그 서버로 전송하지 않습니다. 사용자의 일시적 네트워크 상태 이상(오프라인, 타임아웃 등)은 앱이나 서버 결함이 아니어서 서비스 팀에서 대응 가능한 조치가 없고, 사용자가 재시도하면 자연 복구되는 경우가 대부분입니다. 따라서 수집할 경우 불필요하게 트래픽과 비용만 늘어나며, 실제 장애 신호를 포착하기 어렵게 만듭니다.
warning 레벨의 로그는 실시간 알림 대상입니다. '10분 동안 100회 이상 발생 시 알람 전송'과 같은 규칙을 정해 알람을 설정합니다. 이때 '100회' 같은 수치들은 처음에는 안전하게 넉넉히 설정한 뒤 이후 알림이 불필요하게 잦다고 판단되면 적절히 조절해 주세요.
error
API 실패와 같은 일반적인 에러 상황에 대해서는 대부분 방어 코드를 작성합니다. error 레벨 로그는 이 방어 코드로도 통제할 수 없는 상황에 발생한 이벤트에 대한 로그입니다. 대부분 내부 로직 오류에 해당하며, 발생 시 즉시 알림을 받아 바로 대응할 수 있도록 설정합니다. 주로 다음과 같은 사례 발생 시 이 유형의 로그로 기록합니다.
null객체가 오면 안 되는 상황에null객체를 받음- 전달 받은 파라미터가 유효하지 않음
if-else나switch구문에서 도달하면 안 되는 분기에 진입enum과 JSON 간 파싱 오류- 배열 인덱스 범위를 벗어난 접근
- DB 읽기/저장 실패
- 한 번만 호출돼야 하는 초기화가 여러 번 호출됨
- 타입 변환 실패
- 비즈니스 로직상 불가능한 상태 발생(예: 결제 버튼을 눌렀는데 장바구니가 비어있음)
간단한 예로, 쇼핑 앱에 새 품목 코드를 추가했다고 가정해 봅시다. 서버의 enum에 새 값이 들어왔는데 앱은 그걸 모른 채 배포됐고, 그 결과 JSON에서 enum으로 변환에 실패해 앱 에러가 발생했습니다. 이런 경우에 error 레벨 로그가 기록됩니다. 이 유형의 로그는 즉시 인지해 빠르게 핫픽스할 수 있도록 알림 체계를 갖춰 놓아야 합니다.
fatal
앱 크래시나 처리되지 않은 예외 발생 시 fatal 레벨 로그로 기록합니다. 만약 앞서 'Flutter에서 Sentry 사용하기' 섹션에서 말씀드린 것처럼 설정했다면 앱 시작 시 SentryFlutter으로 감쌌기 때문에 Sentry에서 이를 감지해 자동으로 전송해 주며, 여러분이 직접 코드를 작성해야 할 부분은 없습니다. 만약 Sentry 대신 다른 로그 라이브러리를 사용하신다면 각 라이브러리에서 제공하는 fatal 로그 전송 방법을 참고해 설정해 주세요.
tags, message, extra 작성하기
Sentry로 로그 전송 시 tags, message, extra 정보를 작성해야 합니다. 처음엔 어떻게 구성할지 막막하실 텐데요. 아래 예시대로 시작한 뒤 운영하면서 프로젝트 상황에 맞게 조정하시면 됩니다. 그럼 현재 제가 사용하고 있는 설정을 공유하겠습니다.
tags
tags는 검색, 필터, 그룹화가 잘 되도록 자유 입력을 금지하고 미리 정한 키-값만 쓰고 있습니다.
tags.module: 큰 분류를 나타냅니다.API,Logic,UI등을 사용합니다.tags.eventName: 큰 분류 안에서 어떤 이벤트에 대한 로그인지를 나타냅니다.postLogin,putOrder,getProducts,multipleInit,nullObj등을 사용합니다.
message
사람이 보고 바로 이해할 수 있도록 아래와 같은 간단한 형식으로 사용하고 있습니다.
- [module].[eventName].[성공/실패 여부]
extra
세부 진단용 메시지를 적습니다. 예를 들어 API 관련 이슈라면 이해에 필요한 최소한의 요청(request)/응답(response) 정보를 적어주면 오류 추적에 큰 도움이 됩니다.
- 주의: 개인 정보나 보안 토큰 등의 민감 정보가 전송 정보에 포함되지 않도록 반드시 마스킹하거나 제거하세요.
그 외 항목
아래 항목들은 Sentry 라이브러리에서 자동으로 채워 전송하니 신경쓰지 않으셔도 됩니다.
- 사용자가 클릭한 버튼과 이벤트가 작동한 화면('Flutter에서 Sentry 사용하기' 섹션에서 소개한
addBreadcrumb,SentryNavigatorObserver설정 필요) - 사용자의 단말기 하드웨어 및 OS 정보
- 앱 버전과 앱의 라이프사이클 상태
대시보드 구성 가이드
대시보드를 잘 구성해 놓으면 한�눈에 상태를 파악해 바로 결정을 내리는 데 도움을 받을 수 있습니다. 이 섹션에서는 Sentry에서 제공하는 대시보드를 예시로 장애 모니터링 대시보드를 어떤 항목들로 구성하면 좋을지 소개하겠습니다.
대시보드를 구성한 뒤에는 운영 시 매일 아침 업무 시작 전에 대시보드를 확인하도록 루틴으로 정해 두거나, 신규 버전이 배포된 며칠 간은 시간 단위로 자주 확인하도록(예: 배포 후 3일간은 3시간마다 확인) 규칙을 정해두면 많은 도움을 받을 수 있습니다.
참고로 본 섹션의 대시보드 예시는 앞서 설명한 로그 분류를 그대로 적용했다는 가정 하에 작성했습니다. 다른 방식으로 분류하셨다면 해당 환경에 맞게 지표와 필터를 조정하세요.
비정상 종료가 발생하지 않은 세션/사용자 지표 설정
새 버전을 배포한 뒤에는 비정상 종료가 발생하지 않은 사용자 비율(crash-free)을 먼저 확인해야 합니다. 예를 들어 97% 이상으로 안정적이었던 지표가 90%로 떨어졌다면 롤백을 검토해야 할 수도 있습니다. 이 항목은 Sentry에서 기본 제공하는 컬럼 유형을 설정하시면 됩니다.
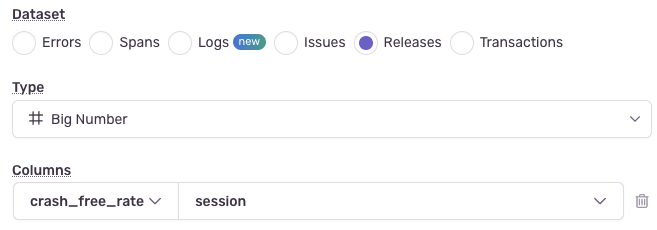
위와 같이 입력하면 아래와 같이 출력됩니다.

에러 발생 횟수 및 에러가 가장 많이 발생한 API 탑 5 지표 설정
이 지표는 앞서 제가 정의했던 로그 분류 체계를 이용해 대응 우선순위를 정하기 위해 아래와 같이 커스터마이징해서 대시보드에 추가한 항목입니다. 아래 입력 항목 중 GroupBy에 필드명(예: eventName, module)을 지정하면 해당 필드명을 기준으로 합산한 결과를 볼 수 있습니다. 예를 들어 eventName을 입력하면 eventName을 기준으로 로그를 묶어 어떤 이벤트가 가장 많이 발생했는지 볼 수 있으며, 이를 이용해 '가장 많이 에러가 발생한 API 탑 5' 같은 지표를 구현할 수 있습니다.
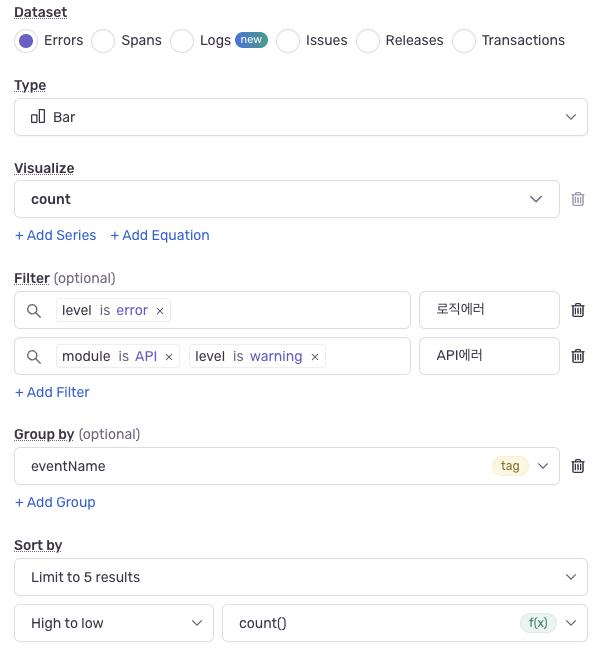
위와 같이 입력하면 아래와 같이 출력됩니다.
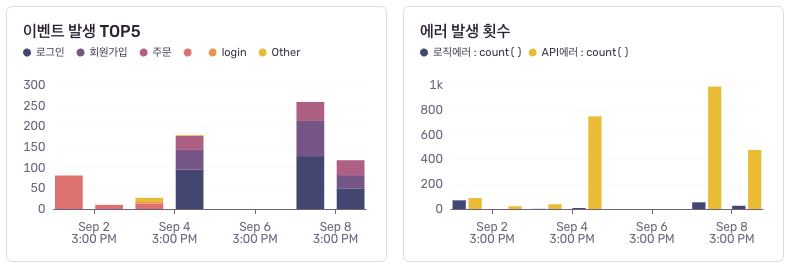
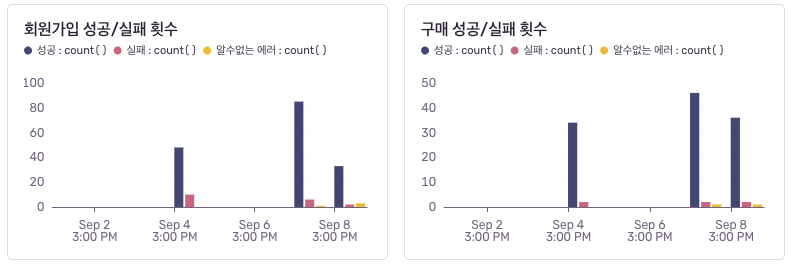
주요 이벤트에 대한 에러 추적 지표 설정
이 지표 역시 앞서 제가 정의한 로그 분류 체계를 기반으로 아래와 같이 커스터마이징해 대시보드에 추가한 항목입니다. 회원 가입과 구매 등 핵심 이벤트의 성공/실패 비율을 시각화�해 볼 수 있도록 구성했으며, 이벤트별 커스텀 필터를 적용해 성공과 실패를 나눠 확인할 수 있습니다.

위와 같이 입력하면 아래와 같이 출력됩니다.
그 외 항목
그 외 Sentry에서는 아래와 같은 항목들을 제공하고 있습니다. 필요에 따라 추가로 설정하면 됩니다.
- 각 화면 진입 후 첫 렌더링까지 걸리는 시간
- 이미지 로딩 요청에 대한 성공/실패 횟수
- 앱 응답 없음(application not responding, ANR)
알림과 대응 루틴 설정
알림은 급할 때만 울려야 하고, 울리면 누가 무엇을 할지 바로 보여야 합니다. 이를 위해 어떤 알림을 설정하고 알림 발생 시 어떻게 대응해야 하는지 간략히 공유하겠습니다.
알림을 설정할 항목 선정
아래는 저희가 설정한 예시입니다. 그대로 가져다 사용하셔도 좋고, 각자의 상황에 맞춰 구체적인 수치를 수정해 사용하셔도 좋습니다. 앞서 말씀드렸듯 수치는 최초 설정 후 한두 주 정도 지켜보면서 적절히 조정합니다.
- API 오류가 5분 동안 100회 이상 발생
- 로그인 실패율 3% 이상 상태가 5분 동안 지속
- 구매 성공률이 최근 15분 기준 전주 같은 시간대 대비 20% 이상 하락
- 비정상 종료가 발생하지 않은 사용자 비율이 95% 이하로 떨어짐
- 참고로 이 항목의 경우 처음에는 98% 정도로 설정했다가 수정할 수 없는 오류(라이브러리 자체에서 발생하는 비정상 종료)로 인해 너무 많은 알림이 발생해 95%로 조정했습니다.
아래 사항에 대한 알림은 경험상 무시해도 되는 알림입니다. 저희도 처음에는 필요할 것 같아서 설정했다가 불필요한 알림으로 판단돼 추후 삭제했습니다.
- 네트워크 일시 불안정으로 인한 단발성 실패
- 사용자 재시도 시 복구되는 오류입니다. 알림이 온다고 해도 딱히 대응할 일이 없기 때문에 알림에서 제외했고, 나중에는 로그 자체를 전송하지 않도록 변경했습니다.
- 특정 기기 혹은 OS 버전에서만 재현되는 미미한 버그
알림 설정 시 주의 사항
알림 설정 시 중복 알림을 막기 위해 10~15분 간의 대기 시간을 설정하고 해당 기간 동안 같은 알림은 한 번만 보내도록 설정합니다. 또한 꼭 필요한 알림을 놓치는 일이 없도록 Slack이나 이메일 등으로 알림을 전달할 때 일반 알림 채널과 긴급 알림 채널을 구분해 놓습니다.
알림 발생 시 대응 루틴
에러가 발생하면 아래와 같이 대응합니다.
- Sentry에서 해당 로그의 세부 내용 확인
- 이때 해당 로그를 남긴 개발자가 직접 바로 문제를 확인하는 것이 제일 좋습니다.
- 어떤 에러가 얼마나 많이 발생했는지, ��어떤 사용자가 영향을 받고 있는지 확인합니다.
- 이슈 발생 원인 분석(최근 릴리스에 문제가 있는지 혹은 서버 측 문제인지 등)
- Sentry 내용과 해당 시기에 배포된 코드 및 변경 사항을 함께 살펴보며 발생한 이슈가 최근 코드 변경 때문인지 혹은 서버나 인프라의 설정 문제인지 등 무엇이 문제인지 파악합니다.
- 긴급 공지나 긴급 패치 준비 및 실행
- 이슈의 심각도에 따라 내부 공지/사용자 공지 등 공지 범위와 방법, 내용을 결정해 공지하고, 롤백 혹은 핫픽스 준비 및 배포 등 조치 사항을 결정해 실행합니다.
- 발생한 이슈를 테스트 케이스로 추가해 재발 방지
마치며
장애를 완전히 없앨 수는 없지만 장애 발생 시 늦지 않게 알아차리고 바로 대응할 수 있도록 준비할 수는 있습니다. 장애 모니터링 시스템을 잘 준비해 놓으면 장애 발생 시 소방벨처럼 빠르게 알려 주고, 나침반처럼 어디를 개선해야 할지 방향을 보여줍니다.
만약 장애 모니터링 시스템을 처음 구축하신다면 처음에는 작게 한두 가지 이벤트를 수집하는 것부터 시작해서 운영하면서 점점 수집 항목을 늘려 가는 게 좋습니다. 예를 들어 처음에는 앱 크래시 발생과 핵심 기능(로그인, 회원 가입, 구매 등)의 성공/실패 이벤트만 수집하고, 대시보드도 간단히 만들어 알림은 하나만 붙이는 것으로 시작합니다. 그다음에 성능 측정(화면, API 속도 등)을 추가하고, 알림 올리기 순서(문제 지속 시 누구에게 차례로 알릴지 정한 규칙)를 정하고, 사후 점검 절차(문제 해결 후 발생 원인 기록 및 재발 방지 체크리스트 작성 등)를 추가하는 등 필요한 것들을 하나씩 추가해 나가면 됩니다.
구축 후 ��운영할 때에는 노이즈를 줄여 정확한 신호만 전달하는 것과 개인 정보는 안전하게 취급한다는 원칙을 지키는 것이 중요합니다. 또한 주기적으로 대시보드를 들여다 보는 습관을 들이는 것도 필요합니다.
이 글이 장애 모니터링 시스템을 이용해 더 안정적이고 신뢰받는 앱을 운영하고자 하는 분들에게 도움이 되길 바라며 이만 마치겠습니다.


