들어가며
안녕하세요. VOOM Server Unit에서 LINE VOOM의 서버 개발을 맡고 있는 신홍중입니다. LINE VOOM 서비스는 포스트와 코멘트, 좋아요(like)와 같은 메인 콘텐츠 저장소로 Cassandra를 사용하고 있습니다. Cassandra는 멀티 데이터 센터를 구축해서 각 데이터 센터에 데이터를 복제한 뒤 서비스를 제공할 수 있습니다. 이를 통해 특정 데이터 센터가 다운되더라도 데이터 손실을 방지할 수 있으며, 사용자가 지역적으로 근접한 데이터 센터에서 데이터를 읽고 쓸 수 있게 함으로써 응답 시간을 단축시킬 수 있는데요. 최근 서버랙 공간 부족과 장비 노후화를 해결하기 위해 신규 클러스터를 구축한 뒤 이 기능을 이용해서 데이터를 복제하는 방식으로 데이터 센터를 이전하는 작업을 진행했습니다.
데이터 센터 간 복제를 이용해 데이터 센터를 이전하기 위해서는 다음과 같은 매우 복잡한 과정이 필요했습니다.
- 설치 파일 배포 및 설정 적용
- 신규 IDC에 독립적인(standalone) 클러스터 기동 후 구성 확인
- 기존 IDC와 신규 IDC 연동
- 신규 IDC의 개별 노드에서 순서대로 rebuild 명령어를 수행해 데이터 복제
- 기존 IDC의 개별 노드에서 순서대로 decomission 명령어를 수행해 연결 해제
- 기존 IDC의 장비 제거
각 과정은 다양한 테스트를 통해 철저히 검증할 필요가 있었습니다. 데이터 이전의 안전성과 정확성을 확보하기 위한 필수 단계였는데요. 이번 글에서는 멀티 데이터 센터를 구축해 데이터를 복제한 방법과, 각 단계에서 진행한 테스트 및 검증 방법을 살펴보겠습니다.
Cassandra 이전 작업과 함께 진행하려고 했던 과제들
본격적으로 이야기를 시작하기 전에, Cassandra 이전과 함께 ��진행하려고 했던 여러 과제와 그중 실제로 어떤 과제를 진행했는지 말씀드리겠습니다.
이번 작업이 결정된 시점에 저희는 Cassandra를 2.0.x 버전으로 운영하고 있었습니다. 당시 DBA 조직의 지원을 받고 있던 다른 데이터베이스와는 달리 Cassandra는 서버 개발자들이 직접 구축한 뒤 유지 보수하고 있었으며, 여러 서비스가 한 클러스터를 공유하며 각 서비스가 자체적인 키 스페이스를 사용하고 있었습니다. 또한 서버 자원의 확보 시기에 따라 SSD와 PCIe-SSD를 혼용하는 등 다양한 장비가 통합된 이질적인 구성이었는데요. 이로 인해 환경이 복잡해지면서 성능과 안정성이 영향을 받고 있었습니다.
저희는 이번 작업이 기존 시스템을 개선할 수 있는 적기라고 판단하고 키 스페이스 분리 및 Cassandra의 버전 업그레이드를 함께 진행하려고 했는데요. 결과적으로 키 스페이스 분리는 진행할 수 있었지만, 버전 업그레이드는 뒤로 미룰 수 밖에 없었습니다. 테스트 과정에서 버전 간 호환성 문제 때문에 버전을 간단히 업그레이드하는 것이 어렵다는 것이 밝혀졌기 때문인데요. 버전 업그레이드를 시도했던 과정은 이후 테스트 이력을 공유하는 과정에서 보다 자세히 소개하겠습니다.
멀티 데이터 센터 구축 후 데이터를 복제하는 방법
이제 멀티 데이터 센터를 구축하고 데이터 센터 간 데이터를 복제한 방법을 살펴보겠습니다.
데이터 복제에 사용할 복구 명령어 선정 및 테스트
Cassandra는 nodetool이라는 유틸리티를 통해서 �클러스터를 관리할 수 있는 여러 명령어를 제공합니다. 이 명령어 중에 rebuild와 repair라는 두 가지 복구 명령어가 존재하는 것을 확인한 뒤 테스트를 통해 두 기능의 실제 작동 과정과 결과를 살펴봤습니다.
먼저 repair는 멀티 데이터 센터의 데이터 센터 간 데이터 불일치를 해소하는 명령어이기 때문에 클러스터 복제에는 맞지 않았습니다. 반면 rebuild는 추가된 신규 노드에 적재해야 하는 데이터를 다른 데이터 센터의 전체 노드에서 받아오는 기능을 수행하는 명령어여서 저희 목적에 부합했기에 rebuild 명령어를 선택했습니다.
멀티 데이터 센터를 구축하기 위한 클러스터 구성 후 클라이언트 설정 및 테이블 스키마 수정
Cassandra는 cassandra.yaml 설정 파일로 클러스터 구성을 포함한 대부분의 설정을 관리하고 있습니다.
# Cassandra storage config YAML
# NOTE:
# See https://cassandra.apache.org/doc/latest/configuration/ for
# full explanations of configuration directives
# /NOTE
# The name of the cluster. This is mainly used to prevent machines in
# one logical cluster from joining another.
cluster_name: 'Test Cluster'
# any class that implements the SeedProvider interface and has a
# constructor that takes a Map<String, String> of parameters will do.
seed_provider:
# Addresses of hosts that are deemed contact points.
# Cassandra nodes use this list of hosts to find each other and learn
# the topology of the ring. You must change this if you are running
# multiple nodes!
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
# seeds is actually a comma-delimited list of addresses.
# Ex: "<ip1>,<ip2>,<ip3>"
- seeds: "127.0.0.1:7000"
# endpoint_snitch -- Set this to a class that implements
# IEndpointSnitch. The snitch has two functions:
#
# - it teaches Cassandra enough about your network topology to route
# requests efficiently
# - it allows Cassandra to spread replicas around your cluster to avoid
# correlated failures. It does this by grouping machines into
# "datacenters" and "racks." Cassandra will do its best not to have
# more than one replica on the same "rack" (which may not actually
# be a physical location)
# SimpleSnitch:
# Treats Strategy order as proximity. This can improve cache
# locality when disabling read repair. Only appropriate for
# single-datacenter deployments.
# PropertyFileSnitch:
# Proximity is determined by rack and data center, which are
# explicitly configured in cassandra-topology.properties.
# You can use a custom Snitch by setting this to the full class name
# of the snitch, which will be assumed to be on your classpath.
endpoint_snitch: SimpleSnitch이 중 멀티 데이터 센터를 구축하는 데 사용한 값은 크게 세 가지입니다.
cluster_name: Cassandra 클러스터를 구별하는 데 사용하는 중요한 식별자입니다. 클러스터 내의 모든 노드는 동일한cluster_name값을 사용해야 하며, 이 값이 다른 노드는 다른 클러스터로 간주됩니다. 이에 따라 신규 IDC에 새로 클러스터를 구축할 때 기존 IDC의 클러스터와 동일한cluster_name을 설정함으로써 일관된 클러스터 구성을 유지했습니다.seeds: Cassandra 클러스터 내에서 다른 노드가 초기 구성 정보를 얻기 위해 참조하는 노드의 목록입니다. 특별한 데이터베이스 처리를 담당하는 마스터 노드와는 달리, 시드(seed) 노드들은 클러스터의 구성 정보를 제공하는 역할을 담당하며, 새 노드가 클러스터에 참여할 때 필요한 정보를 제공합니다. 시드 노드는 장애가 발생하더라도 클러스터 내 다른 노드의 작업에 영향을 주지 않으며, 따라서 클러스터는 계속 운영될 수 있습니다.endpoint_snitch: Cassandra가 네트워크 토폴로지를 인식하고 효율적으로 데이터를 분배하도록 도와주는 구성 요소입니다. 기존에는 단일 데이터 센터 환경에서SimpleSnitch를 사용했지만, 다중 데이터센터 환경을 지원하기 위해PropertyFileSnitch로 전환했습니다. AWS EC2와 같은 클라우드 환경에 배포한다면,EC2Snitch나EC2MultiRegionSnitch등을 사용해 클러스터를 구성할 수 있습니다.PropertyFileSnitch를 사용할 경우, cassandra-topology.properties 파일에서 네트워크 토폴로지 정보를 읽어 클러스터를 구성합니다.- 설정 예시는 다음과 같습니다. DC1은 데이터 센터 1을, RAC1은 랙 1을 의미합니�다. 클러스터에 추가로 정의되지 않은 IP의 노드가 참여할 때에는 디폴트 값으로 설정돼 있는 데이터 센터와 랙에 자동으로 할당됩니다.
# Datacenter 1 10.1.1.1=DC1:RAC1 10.1.1.2=DC1:RAC1 10.1.1.3=DC1:RAC1 # Datacenter 2 10.2.1.1=DC2:RAC1 10.2.1.2=DC2:RAC1 10.2.1.3=DC2:RAC1 # default for unknown nodes default=DC1:RAC1
- 설정 예시는 다음과 같습니다. DC1은 데이터 센터 1을, RAC1은 랙 1을 의미합니�다. 클러스터에 추가로 정의되지 않은 IP의 노드가 참여할 때에는 디폴트 값으로 설정돼 있는 데이터 센터와 랙에 자동으로 할당됩니다.
Cassandra 클러스터를 구성한 뒤에는 테이블 스키마를 수정하고 클러스터에 연동하는 클라이언트 설정을 진행했습니다.
Cassandra에서는 일관성 수준(consistency level)을 정의해 읽기와 쓰기의 일관성을 보장하는 수준을 정의할 수 있습니다. 예를 들어 만약 Replica Factor가 3이라면, Cassandra는 클러스터 내에 세 개의 복제본을 생성합니다. 이때 일관성 수준이 READ = 1, WRITE = 3이라면, 쓰기 요청이 들어오면 항상 세 개의 복제본에 모두 쓰기가 완료돼야 성공 응답을 반환하고, 읽기는 세 개의 복제본에 모두 요청을 보낸 뒤 그중 하나만 응답하면 성공 응답을 반환합니다. 물론 위 사례는 하나의 예시로, 실제로 이렇게 설정하면 쓰기가 너무 느려질 수 있기 때문에 보통 일관성 수준으로 QUORUM(과반수)을 지정해 사용합니다. 이 경우 복제본이 세 개라면 쓰기도 두 개, 읽기도 두 개 성공하면 요청이 성공한 것으로 처리합니다.
여기에 멀티 데이터 센터 구성이 들어가면 클라이언트에 설정을 추가해야 합니다. LINE VOOM에서는 Cassandra 클라이언트 라이브러리로 Datastax Cassandra Driver를 사용하고 있으며, 아래 코드와 같이 LoadBalancingPolicy를 DCAwareRoundRobinPolicy로 설정해서 클라이언트가 여러 데이터 센터 중에서 특정 데이터 센터를 로컬(local)로 설정하도록 ��합니다. 또한 일관성 수준으로 QUORUM 대신 LOCAL_QUORUM을 설정해 삽입/조회/수정/삭제를 실행할 때 로컬로 설정된 데이터 센터 내 클러스터에서만 과반수를 판단하도록 정의합니다. 만약 기존 IDC와 신규 IDC, 두 곳 모두에서 요청을 처리하고 싶으면 EACH_QUORUM을 설정할 수도 있습니다.
@Configuration
public class CassandraConfiguration {
@Autowired
private CassandraEnvironmentIF cassandraEnvironment;
private static final String DATA_CENTER_1 = "DC1";
private static final String DATA_CENTER_2 = "DC2";
@Bean
public com.datastax.driver.core.Cluster cluster() {
// balancing policy
LoadBalancingPolicy loadBalancingPolicy = new TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().withLocalDc(DATA_CENTER_KR).build(), false);
...클라이언트 설정까지 마친 뒤 마지막으로 테이블 스키마를 업데이트해 기존 IDC와 신규 IDC에 있는 모든 클러스터에 데이터 복제가 위치하도록 설정합니다.
[account@cassandra001.line:~]$ apps/cassandra/bin/cqlsh cassandra001.line
Connected to Test Cluster at cassandra001.line:9160.
[cqlsh 4.1.1 | Cassandra 2.0.17 | CQL spec 3.1.1 | Thrift protocol 19.39.0]
Use HELP for help.
cqlsh>
ALTER KEYSPACE table_1 WITH replication = {
'class': 'NetworkTopologyStrategy',
'DC1': '3',
'DC2': '3'
};
cqlsh>
ALTER KEYSPACE table_2 WITH replication = {
'class': 'NetworkTopologyStrategy',
'DC1': '3',
'DC2': '3'
};위와 같이 설정을 마치면 기존 IDC에 있던 기존 Cassandra 클러스터에 신규 IDC 클러스터가 정상적으로 연결되는데요. Cassandra는 데이터 복제가 설정되더라도 repair 혹은 rebuild 명령어로 데이터 재구성을 통한 복제를 수행하기 전까지는 추가된 데이터 센터의 클러스터로 데이터 복제가 이뤄지지 않습니다. 연결된 후 기존 IDC로 들어오는 쓰기 요청은 모두 신규 IDC로 복제되지만, 복제되지 않은 데이터는 쓰기 요청이 들어오거나 신규 IDC에서 해당 데이터를 읽기 요청하기 전까지는 복제되지 않습니다.
이때 Cassandra는 조회가 발생한 데이터가 자신에게 존재하지 않는 경우 'Read Repair'라는 메커니즘을 통해 해당 데이터를 가지고 있는 노드를 찾아서 복제를 수행하는 기능이 있습니다. 즉, 신규 IDC에서 첫 조회가 실패하면 Cassandra에서 Read Repair를 통해 데이터를 복제해서 다음 요청부터는 정상 조회가 가능한데요. 이 방법으로 데이터를 복제하려면 전체 키 조회를 신규 IDC의 클러스터에 요청해야 하기 때문에 실제 복제 작업은 데이터 재구성(repair/rebuild 명령어 사용)을 수행해 진행하는 것으로 결정했습니다.
데이터 복제 및 검증 과정에서 수행한 테스트 이력
앞서 말씀드린 사안을 포함해 데이터 복제를 이용해 데이터 센터를 이전하기 위한 최적의 방법을 찾기 위해서는 다양한 테스트를 수행해야 했습니다. 어떤 테스트를 진행했는지 각 테스트를 수행한 순서대로 하나씩 살펴보겠습니다.
테스트 1: Repair 명령어 테스트
기존 IDC에 신규 IDC를 연동하고 repair 명령어를 수행했습니다. repair를 실행하면 기존 IDC의 모든 노드가 데이터를 전송하고, 신규 IDC의 모든 노드가 데이터를 받아 데이터 복구를 진행했는데요. 모든 노드에서 동시에 데이터 전송이 이뤄지다 보니 네트워크 사용량이 너무 높아지는 문제가 발생했습니다.
테스트 2: Repair 스트림 임곗값 설정 적용 테스트
테스트 1에서 발견된 문제를 해결하기 위해서 inter_dc_stream_throughput_outbound_megabits_per_sec 설정을 적용해 봤습니다. 하지만 이 설정은 Cassandra 내부 작동에서는 적용되지만 외부 작동인 nodetool의 repair 명령어를 사용할 때에는 적용되지 않아 네트워크 사용량은 그대로였습니다(이후 Cassandra 4.0.0 버전에서는 repair 명령어에도 해당 설정이 적용된다는 것이 확인됐습니다).
테스트 3: Rebuild 명령어 테스트
테스트 1과 테스트 2를 통해서 repair 명령어를 이용한 데이터 센터 복제는 불가능한 것으로 확인했습니다. 다음으로 rebuild 명령어를 테스트했습니다.
테스트는 기존 IDC에 신규 IDC를 연동한 뒤 신규 IDC의 노드마다 순서대로 rebuild 명령어를 수행하는 방식으로 진행했습니다. 테스트 결과 기존 IDC의 모든 노드에서 각각 100~200Mb/s의 전송량으로 신규 IDC rebuild 실행 노드로 데이터가 전송돼 repair 명령어보다 안정적으로 수행됐습니다. 이때 rebuild 명령어를 여러 노드에서 동시에 수행하면 작업 시간을 단축시킬 수는 있겠지만 전체 노드에 과부하를 발생시킬 수 있다고 판단해 동시 수행은 하지 않기로 결정했습니다.
테스트 4: 키 스페이스 분리 테스트
IDC 이전 작업에 맞춰, 서비스 운영 과정에서 한 클러스터에 여러 서비스 데이터가 혼재돼 있는 상황도 해소하고 싶었습니다. 과거에는 조직의 규모가 작고 한 담당자가 여러 서비스를 맡았기 때문에 하나의 스토리지에 여러 서비스 데이터를 저장하는 형태로 운영했습니다. 이후 조직의 규모가 커지면서 다른 시스템은 이와 같은 현상이 많이 개선됐지만, Cassandra는 담당이 명확하지 않다 보니 오랜 시간 방치되고 있었습니다.
이를 개선하기 위해, 예를 들어 기존 IDC에서 한꺼번에 서비스 A와 B가 운영되고 있었다면 이를 DC2(service A)와 DC3(service B)로 분리했습니다. 분리 설정은, ALTER KEYSPACE를 설정할 때 Service A는 기존 IDC에서 DC2로 복제하고, Service B는 기존 IDC에서 DC3로 복제되도록 설정하는 방식을 사용했습니다.
테스트 5: 버전 업그레이드 테스트
신규 IDC에서 Cassandra의 버전 업그레이드를 진행했습니다. Cassandra는 여러 차례의 브레이킹 체인지가 있어서 구 버전을 한 번에 최신 버전으로 올릴 수 없습니다. 브레이킹 체인지가 발생했던 각 버전을 한 번씩 거쳐야 최신 버전으로 업그레이드할 수 있는데요. 이에 2.0.17에서 시작해 2.1.22, 3.0.24, 3.11.10 순으로 업그레이드한 후 마지막으로 4.0.0으로 업그레이드했습니다.
버전 업그레이드는 업그레이드한 버전의 Cassandra 바이너리 설치 후 클러스터 노드 전체를 재기동하고 nodetool의 upgradesstable 명령어를 수행해 상위 버전용으로 데이터를 전부 다시 쓰는 순서로 진행했습니다. 2.0.17과 2.1.22를 연동하는 것은 큰 문제가 없었는데요. 3.0.24를 연동하고 기동하려고 했을 때 cassandra.yaml 설정 파일의 사용법이 달라지면서 rpc_address, listen_address에 localhost가 들어있는 경우 정상적으로 기동하지 않는 이슈가 발생했습니다. 다행히 ��해당 이슈는 localhost를 제거하고 디폴트 값을 사용하게 함으로써 해결할 수 있었습니다. 이후 3.11.10으로 업그레이드하는 것도 문제없이 수행됐는데요. 마지막으로 4.0.0 업그레이드를 실행했을 때 기존 IDC의 2.0.17과 신규 IDC의 4.0.0이 서로 호환되지 않는 버전이어서 연동되지 않았습니다. 원인을 파악하기 위해 Cassandra 코드를 확인해 본 결과, 4.0.0 버전부터는 2.x 버전과는 통신되지 않고 실패하도록 코딩돼 있었습니다.
테스트 6: Decommission 명령어 테스트
작업을 모두 완료한 후 사용하지 않는 클러스터 노드를 제거하는 방법으로 nodetool의 decommission 명령어를 테스트했습니다. 노드를 제거하는 명령어로 removenode와 assassinate 명령어가 있는데요. removenode는 중지된 노드를 클러스터에서 제거하는 명령어이고, assassinate는 2.2.0 버전 이후로만 사용할 수 있는 명렁어여서 테스트 대상에서 제외했습니다.
decommission 명령어의 원래 목적은, 예를 들어 5대로 구성된 클러스터가 있을 때 클러스터의 용량을 줄이기 위해 한 대를 빼는 상황에서 사용하기 위한 명령어입니다. 노드에 decommission 명령어를 수행하면 해당 노드에 있던 모든 데이터가 클러스터의 다른 노드로 재분배되고, 해당 작업이 완료된 후 클러스터에서 제거됩니다.
명령어를 테스트한 결과 기존 IDC의 노드를 제거하더라도 신규 IDC의 클러스터에는 아무런 영향을 주지 않는 것을 확인했습니다.
테스트 7: 이중 쓰기(dual write) 테스트
서비스가 기존 IDC와 신규 IDC에 각각 연결돼 있더라도 문제없이 작동하는지 확인한 테스트입니다. Cassandra는 저장된 모든 데이터에 타임스탬프가 있어서 마지막에 저장된 값만 볼 수 있는데요. Cassandra를 이용하는 LINE VOOM 서비스에서는 단일 키에 대한 삽입/수정/삭제가 발생하고, 조회는 대부분 캐시를 이용해 처리하기 때문에 기존 IDC과 신규 IDC로 요청이 섞여서 들어오더라도 데이터의 일관성에는 문제가 없음을 확인했습니다.
위와 같은 테스트를 통해 데이터 센터 간 복제 작업이 얼마나 견고한지 확인할 수 있었고, 이를 바탕으로 IDC 이전 작업을 더욱 안정적으로 진행할 수 있었습니다.
이전 환경 구축 및 이전 작업 진행
이전 환경 구축
앞서 말씀드린 것처럼 다양한 테스트를 통해 얻은 결과를 바탕으로 2.0.17 버전을 유지하면서 신규 IDC로 이전하는 것으로 결정했습니다. 테스트 결과 버전 업그레이드 작업을 제외하고 rebuild 명령어를 이용해 데이터 복제만 처리하는 데에도 최소 2~3개월이 소요되는 것으로 예측됐기 때문에, 작업 종료 시점을 맞추기 위해 버전 업그레이드는 포기했습니다.
신규 IDC에 장비를 설치한 후 Shell 스크립트와 AWX를 활용해 개별 장비 OS 설치, 커널 파라미터 수정, Cassandra 설치 작업을 수행해 환경 구축을 완료했습니다.
이전 작업
이전 환경을 구축한 뒤 전체 이전 작업은 다음과 같은 순서로 진행했습니다.
- 서버 클러스터의 이름은 동일하지만 시드(seed) 정보는 교환하지 않은 채 신규 IDC에 독립적인(standalone) 클러스터를 구성합니다.
- 기존 IDC와 신규 IDC에 있는 클러스터끼리 시드 정보를 일치시켜 양쪽을 모두 바라볼 수 있게 설정합니다.
- 앞서 설명��한 것처럼
ALTER KEYSPACE를 이용해서 기존 IDC와 신규 IDC 간 서로 복제되도록 복제 설정을 추가합니다. - 기존 IDC에서 쓰기가 발생하면 신규 IDC에서 정상적으로 조회되는지 확인합니다.
- 신규 IDC의 클러스터 노드에서 한 대씩 순서대로
rebuild명령어를 수행합니다.rebuild명령어는 기존 IDC의 모든 노드로부터 데이터를 받아온 뒤 모두 파일로 저장하고 압축(compaction) 과정을 거쳐 데이터를 정리하는 순서로 작동합니다.
- 5번 작업이 마무리되면 샘플링한 키를 조회해 기존 IDC와 신규 IDC의 데이터가 일치하는지 확인하고, nodetool에서 조회되는 데이터 크기와 키 범위 등이 동일한지 확인합니다.
- 아직 기존 IDC에 위치해 있는 WAS가 기존 IDC 대신 신규 IDC를 바라보고 요청을 수행하도록 변경합니다.
- 장애 발생 시 롤백을 진행하기 위해 신규 IDC에서 기존 IDC로 정상적으로 복제되는지 확인합니다.
- 기존 IDC에 있는 노드를 순차적으로
decommission명령어를 수행해 제거합니다. - Cassandra 클러스터에서 제거된 물리 장비를 모두 반납합니다.
위 순서로 진행된 작업 중 5번 rebuild 명령어 수행 작업에서 가장 오랜 시간이 소요됐습니다. 한 노드가 데이터를 받아오는 데 2~3시간이 소요됐고, 이후 압축 작업을 통해 데이터를 정리하는 데 며칠씩 걸렸기 때문입니다. 압축 작업은 아직 서비스 요청을 받고 있지 않은 노드에서 진행되는 작업이어서 큰 문제가 없었지만, rebuild 명령어는 시작 시 모든 노드로부터 데이터를 받아오기 위해 상당 기간 네트워크 I/O와 CPU 자원을 사용하기 때문에 서비스에 영향을 주지 않을까 걱정됐습니다.
다음은 rebuild 명령어를 수행할 때 기존 IDC의 노드들에서 네트워크로 전송된 데이터량을 보여주는 그래프입니다.
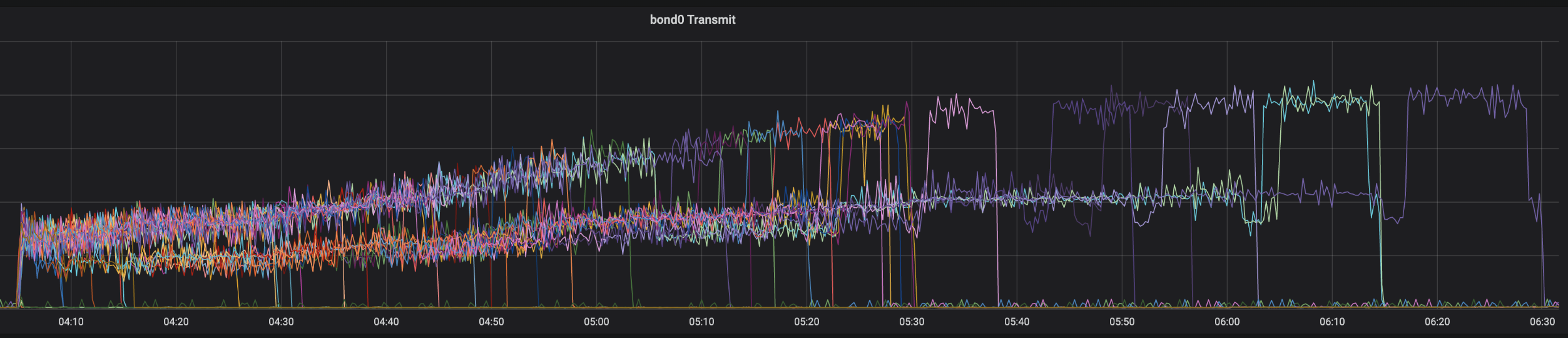
LINE VOOM 서비스의 메인 스토리지 중 하나인 Cassandra 클러스터에 문제가 생기면 서비스 전면 장애로 확산되기 때문에 최대한 위험을 피해야 했습니다. 특정 노드의 하드웨어에 이슈가 발생해 디스크 쓰기가 지연되거나 네트워크 패킷이 유실되는 등의 사소한 이슈에도 전체 노드가 서로를 찾고 문제점을 확인하기 위해 비정상적으로 부하가 높아지는 사례를 몇 차례 겪어왔기 때문에 조심할 수밖에 없는 상황이었습니다. 이에 하루에 한 대씩 서비스 사용량이 가장 적은 00~06시 사이에 작업을 진행했으며, 서버 대수가 많았기에 매일 2~3명씩 새벽에 작업을 수행해야 했습니다.
마치며
데이터 센터 이전은 단순히 노드를 한 위치에서 다른 위치로 이동시키는 것 이상으로 복잡한 작업입니다. 데이터의 안전을 보장하면서 새로운 환경으로 원활하게 이전해야 하기 때문입니다. 이전 작업은 다른 업무와 병행하면서 진행했는데요. 데이터 센터 이전 테스트에 약 5개월, rebuild 명령어 수행 작업에 약 2개월, 그 외 준비 작업 및 기타 업무에 또다시 추가로 시간이 소요돼 수개월에 걸친 긴 기간 동안 수행했습니다.
2013년에 MySQL에서 대용량 스토리지로 전환을 검토할 당시에는 Cassandra가 가장 효율적인 분산 스토리지 솔루션이었습니다. Cassandra는 아주 잘 만든 분산 스토리지였기에 10년이라는 기간 동안 큰 유지 보수 작업을 하지 않고도 과거 버전으로 큰 이슈 없이 잘 운영해 올 수 있었습니다. 이는 Cassandra를 그 목적에 맞게 아주 잘 사용하고 있었다는 것을 의미합니다. 그러나 서비스가 성장하고 회사 규모가 커지는 과정에서 Cassandra는 회사의 선택을 받지 못했습니다. 이로 인해 DBA를 포함한 지원을 받을 수 없게 됐고, 이는 백엔드 서버 개발 팀에게 큰 부담이 되었습니다. 조금만 더 여유가 있었다면 버전까지 업그레이드해 더 안정적인 Cassandra 운영 환경을 구축할 수 있었을 텐데요. 이 점이 약간의 아쉬움으로 남아 있습니다.
하지만 이와 같은 시행착오는 저와 저희 팀에게 소중한 경험을 제공했습니다. 여러 동료의 도움을 받고 여러 조직의 지원을 받은 덕분에 수십 대의 Cassandra 클러스터를 성공적으로 이전할 수 있었습니다. 그 과정에서 단순히 구전으로 전달되던 운영 지식을 실제로 체험하며 이해하는 기회를 얻었고, 이를 통해 개발 팀 전체가 성장할 수 있었습니다. 이 경험은 앞으로의 운영 업무에서 큰 자산이 될 것입니다.


