들어가며
안녕하세요. LINE Plus에서 태국 LINE BK 채널 서버 개발 및 운영 업무를 맡고 있는 이석재입니다. LINE BK에서는 지난 9월에 LINE BK 보험 중개 서비스를 출시했습니다. 이 서비스는 Spring Boot 2를 기반으로 개발하기 시작해서 올해 초에 Spring Boot 3로 마이그레이션했는데요. 서비스를 정식 오픈한 후에는 현실적으로 대규모 변경 작업이 어렵다는 점과, Spring Boot 2의 OSS 지원이 올해 11월 24일에 EOL(end of life)을 맞이한다는 점(참고)을 고려해 마이그레이션을 결정하고 진행했습니다. 현재 안정적으로 운영되고 있으며, 이 프로젝트에서 쌓은 경험을 바탕으로 최근에는 여신(lending) 서비스를 위한 API 서버를 Spring Boot 3 환경으로 이관하는 작업을 진행하고 있습니다.
본 글에서는 저희가 Spring Boot 2 환경에서 Spring Boot 3 환경으로 이관하는 과정에서 경험한 내용을 공유하려고 합니다. 작년 11월에 출시된 Spring Boot 3는 내부적으로 상당한 변화가 있었습니다(참고). 이에 따라 Spring Boot와 함께 사용하는 다른 Spring 프로젝트들도 버전 업그레이드를 진행하면서 다양한 신규 기능이 추가되는 등의 크고 작은 변화가 있었는데요. 모든 변경 사항을 다루는 것은 어렵겠지만, 팀에서 운영하는 7개의 모듈을 업그레이드하는 과정에서 중요하다고 판단한 내용을 중점으로 다뤄보려고 합니다. 이 글이 마이그레이션을 계획하고 계신 분들에게 참고할 만한 가이드가 되길 바라며 시작하겠습니다.
이 글은 Spring Boot 2.7 버전에서 3.1 버전으로 업그레이드하는 과정을 기반으로 작성했습니다. 빌드 도구는 Gradle을 기준으로 삼았으며, 예제 코드는 Java를 기본으로 Kotlin과 함께 제공합니다.
Spring Boot 마이그레이션
Spring Boot는 다음과 같은 순서로 마이그레이션을 진행했습니다.
- 사전 준비
- Java 버전을 최소 17 이상으로 업데이트
- Spring Boot 버전을 3으로 업데이트
- Java EE를 Jakarta EE로 변경
application.yml혹은application.properties수정- 지원이 중단된(deprecated) API 수정
사전 준비
마이그레이션을 준비할 때 관련 공식 문서는 꼭 읽어보는 게 좋습니다. Spring Boot 3가 릴리스된 지 1년이 되어가는 시점에서 가장 신뢰할 수 있는 참고 자료인데요. 프로젝트에서 사용하고 있는 Spring과 Spring Boot의 버전을 확인하고 Spring Boot 3.0 문서부터 릴리스 노트와 마이그레이션 가이드를 최소 한 번 이상 꼼꼼히 읽어보시기를 권장합니다. 읽으면서 담당하는 프로젝트에 해당하는 내용을 Spring 프로젝트별로 정리해 놓는 것도 좋은 방법입니다.
만약 Spring Boot 버전이 최신 버전과 비교해 많이 낮은 상태라면, 업데이트할 때 바로 3 버전으로 업데이트하기보다는 마이너 버전부터 한 단계씩 순차적으로 진행하는 것을 것을 추천합니다. 또는 공식 문서인 Spring Boot Config Data Migration Guide를 참고해서 Spring Boot 2.4 버전으로 먼저 업데이트한 후 Spring Boot Config Data(application.yml, application.properties) 관련 변경 사항을 확인한 뒤 2.7 버전을 거쳐 3 버전으로 업데이트하는 것도 좋을 것 같습니다.

Spring 프로젝트는 시맨틱 버저닝(semantic versioning) 방식으로 운영되고 있어서 마이너 버전마다 크고 작은 신규 기능이 추가되거나 변경됩니다. 이와 같은 이전 릴리스의 변경 사항을 최신 버전의 릴리스 노트에서 한꺼번에 확인하는 것은 쉽지 않습니다. 따라서 버전 업데이트 작업은 물론 이후 프로젝트를 안정적으로 운영하려면 Spring Boot 2의 최신 버전인 2.7 버전 릴리스 노트는 물론 그 이하 마이너 버전의 릴리스 노트도 꼭 한 번쯤은 읽어보는 것을 권장합니다.
Java 버전을 최소 17 이상으로 업데이트
마이그레이션 작업을 시작하면 가장 먼저 해야 할 일은 프로젝트에서 사용하는 Java의 버전을 최소 17 이상으로 올리는 것입니다. Spring Boot 3과, Spring Boot 3에서 사용하는 Spring 프레임워크 6에서 지원하는 최소 Java 버전이 17입니다. 따라서 프로젝트에서 Java 버전을 명시적으로 사용하고 있는 부분이 있다면 수정합니다.
- Kotlin 예제
java.sourceCompatibility = JavaVersion.VERSION_17 java.targetCompatibility = JavaVersion.VERSION_17 java { sourceCompatibility = '17' targetCompatibility = '17' }Groovy 예제
Spring Boot 버전을 3으로 업데이트
다음으로 Spring Boot 버전을 3으로 올립니다. 아래 예시에서는 Gradle 프로젝트에서 사용하는 Spring Boot 관련 플러그인 버전을 23년 10월 25일 기준 최신 GA(General Availability) 버전인 3.1.5로 업데이트했습니다. 이외에도 Java 버전과 Spring Boot 버전을 설정하는 부분이 있다면 프로젝트에서 사용하는 빌드 도구와 환경에 맞춰 적절하게 수정합니다.
- Kotlin 예제
plugins { id("org.springframework.boot") version "3.1.5" id("io.spring.dependency-management") version "1.1.3" } plugins { id 'org.springframework.boot' version '3.1.5' id 'io.spring.dependency-management' version '1.1.3' }Groovy 예제
Java EE를 Jakarta EE로 변경
코드 레벨에서의 큰 변화는 javax 패키지가 jakarta 패키지로 변경된 것입니다. Java의 표준 사양을 관리하는 주체가 Java Community Process(JCP)에서 Eclipse Foundation으로 바뀌면서, Oracle과의 라이선스 이슈 때문에 javax 패키지가 jakarta 패키지로 변경됐습니다. 이에 따라 코드 내 import 문에서, javax.sql, javax.crypto 등 JDK에 포함돼 있는 일부 패키지를 제외한 대부분의 javax 패키지를 jakarta 패키지로 변경해야 합니다.
이 작업은 수기로 하는 것보다는 IDE의 기능을 이용해 일괄 변경하거나 공식 문서에서 제안하는 몇 가지 방법 중 하나를 선택하는 게 좋습니다. 예를 들어 IntelliJ에서 지원하는 Java EE에서 Jakarta EE로 리팩토링하는 기능을 이용하면 변경해야 하는 코드를 쉽게 수정할 수 있습니다. 작업이 끝나면 IDE의 전체 검색 기능으로 javax.*를 검색해서 한 번 더 확인하는 것을 추천합니다.
- Java 예제
// As-Is import javax.validation.Valid; // To-Be import jakarta.validation.Valid; // As-Is import javax.validation.Valid // To-Be import jakarta.validation.ValidKotlin 예제
application.yml 혹은 application.properties 수정
application.yml 혹은 application.properties 등에서 Spring Boot Config Data의 일부 프로퍼티의 이름이나 뎁스(depth)를 수정해야 합니다. 예를 들어 아래와 같이 spring.redis.port가 spring.data.redis.port로 수정됐습니다.
application.yml
# As-Is spring: redis: port: 6379 # To-Be spring: data: redis: port: 6379# As-Is spring.redis.port=6379 # To-Be spring.data.redis.port=6379application.properties
Spring Boot 2.7 버전에서 3.0 버전으로 업데이트될 때 변경된 프로퍼티와, 3.0 버전에서 3.1 버전으로 업데이트될 때 변경된 프로퍼티는 다음과 같습니다.
- 2.7 → 3.0: Spring Boot 3.0 Configuration Changelog
- 3.0 → 3.1: Spring Boot 3.1.0 Configuration Changelog
위 문서와 공식 문서를 참고하면서 IDE의 자동 완성 기능 등을 이용해 기존에 사용하던 설정을 수정하거나 spring-boot-properties-migrator를 사용하는 등 기존에 사용하던 설정을 Spring Boot 3에서 사용할 수 있도록 수정합니다.
지원이 중단된 API 수정
마지막으로 IDE의 자동 완성 기능을 이용하거나 Javadoc을 확인해서 지원이 중단된 API를 사용하고 있는 코드를 최신 버전에서 권장하는 방식으로 수정합니다.
기타 Spring 프로젝트 마이그레이션
앞서 말씀드린 것처럼 Spring Boot가 2에서 3으로 업그레이드되면서 Spring Boot와 함께 사용하는 다른 Spring 프로젝트들도 버전이 업데이트됐습니다. 기타 Spring 프로젝트 마이그레이션은 어떻게 진행하는지 다음과 같은 순서로 살펴보겠습니다(꼭 이 순서대로 작업해야 하는 것은 아닙니다).
- Spring Cloud
- Spring Data JPA
- Spring Batch
- Spring Security
- 기타(Flyway, Mockito 등)
Spring Cloud
Spring Cloud 프로젝트는 다음과 같은 순서로 마이그레이션을 진행했습니다.
- Spring Cloud Bom 업데이트
application.yml혹은application.properties수정- Spring Cloud Sleuth를 Micrometer Tracing으로 이관
Spring Cloud Bom
프로젝트에서 Spring Cloud를 사용하고 있다면 Spring Cloud BOM 의존성 버전을 최신 버전으로 올려야 합니다. 프로젝트 설정에 따라 Gradle 스크립트 혹은 Spring Dependency Management 플러그인에 설정된 BOM 의존성 버전을 수정합니다.
- Kotlin 예제
// 1, 직접 선언 dependencies { implementation(platform("org.springframework.cloud:spring-cloud-dependencies:2022.0.4")) } // 2, Dependency Management 플러그인에 선언 configure<DependencyManagementExtension> { imports { mavenBom("org.springframework.cloud:spring-cloud-dependencies:2022.0.4") } } // 1, Dependency Management 플러그인에 선언 dependencyManagement { imports { mavenBom 'org.springframework.cloud:spring-cloud-dependencies:2022.0.4' } }Groovy 예제
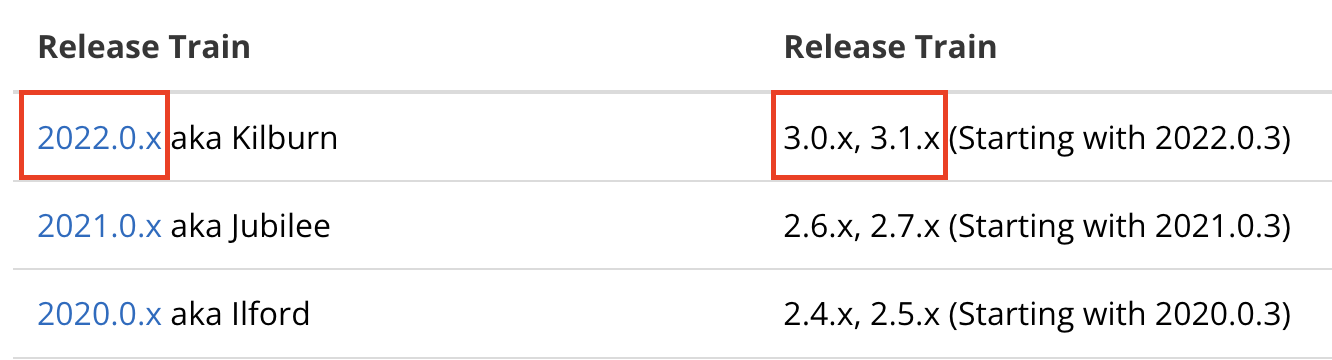
위 예시는 Spring Boot 3.1.5 버전과 호환되는 Spring Cloud 2022.0.4 버전으로 설정한 모습입니다. 변경 내용과 관련해서는 Spring Cloud 2022.0 릴리스 노트를 참고하시기 �바랍니다.
application.yml 혹은 application.properties 수정
Spring Boot와 마찬가지로 application.yml 혹은 application.properties 등에서 Spring Cloud 프로젝트에서 사용하던 일부 프로퍼티의 이름이나 뎁스(depth)를 수정해야 합니다.
application.yml
# As-Is feign: client: config: default: connect-timeout: 5000 # To-Be spring: cloud: openfeign: client: config: default: connect-timeout: 5000# As-Is feign.client.config.default.connect-timeout=5000 # To-Be spring.cloud.openfeign.client.config.default.connect-timeout=5000application.properties
Spring Cloud 버전을 업데이트하면서 변경해야 하는 프로퍼티는 각 하위 프로젝트의 공식 문서에서 확인할 수 있습니다. 각 공식 문서를 참고해서 IDE의 자동 완성 기능 등을 이용해 기존에 사용하던 설정을 신규 버전의 Spring Cloud에서 사용할 수 있도록 수정합니다. 저희 팀에서는 사용하고 있는 하위 프로젝트와 참고한 문서는 다음과 같습니다.
- Spring Cloud Gateway: Spring Cloud Gateway - Appendix A: Common application properties
- Spring Cloud OpenFeign: Spring Cloud OpenFeign - Appendix A: Common application properties
- Spring Cloud Vault: Spring Cloud Vault - Appendix A: Common application properties
Spring Cloud Sleuth를 Micrometer Tracing으로 이관
프로젝트에서 Spring Cloud Sleuth를 사용해 분산 환경에서 트레이싱(tracing) 기능을 사용하고 있다면 변경해야 할 부분이 많습니다.
분산 환경에서의 트레이싱에 대해선 김용훈 님이 작성하신 LINE 광고 플랫폼의 MSA 환경에서 Zipkin을 활용해 로그 트레이싱하기 포스트를 참고하시기 바랍니다.
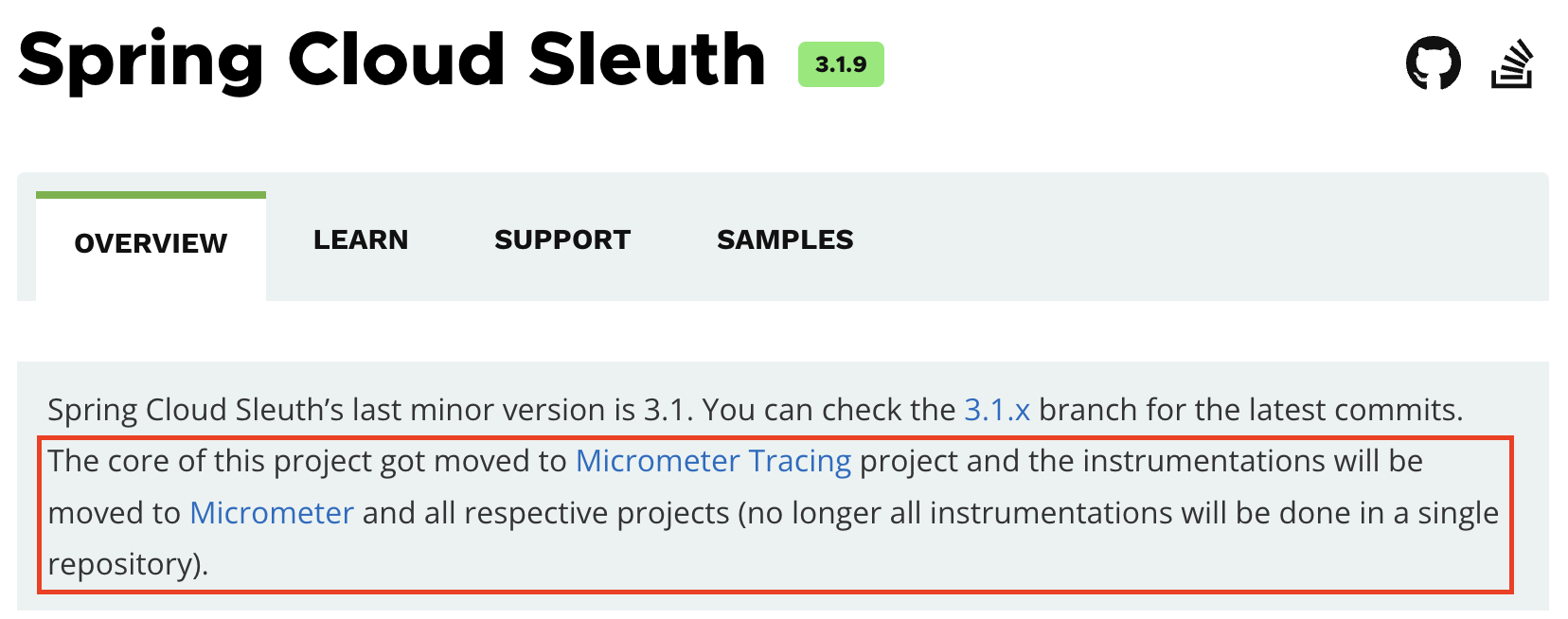
저희 팀 역시 Spring Cloud Sleuth를 통해 트레이싱 기능을 사용하고 있었는데요. 이 프로젝트의 핵심 기능이 Micrometer Tracing 프로젝트로 이관되면서(참고) Spring Cloud Sleuth가 Spring Cloud Release Train에서 제거됐습니다(참고).
위와 같은 변화가 발생한 히스토리를 간단하게 설명하겠습니다.
기존 Spring 프로젝트에서는 분산 환경에서의 트레이싱 기능을 사용할 때 아래 왼쪽 그림과 같은 의존성 구조가 형성됐습니다. 그림에서 상위에 위치한 모듈이 하위에 위치한 모듈에 의존하는 형태인데요. Spring Boot는 아래에 위치한 Spring Framework에 의존하고, Spring Framework는 다시 지표(metric)를 수집하기 위해 Micrometer 모듈에 의존하는 구조입니다.
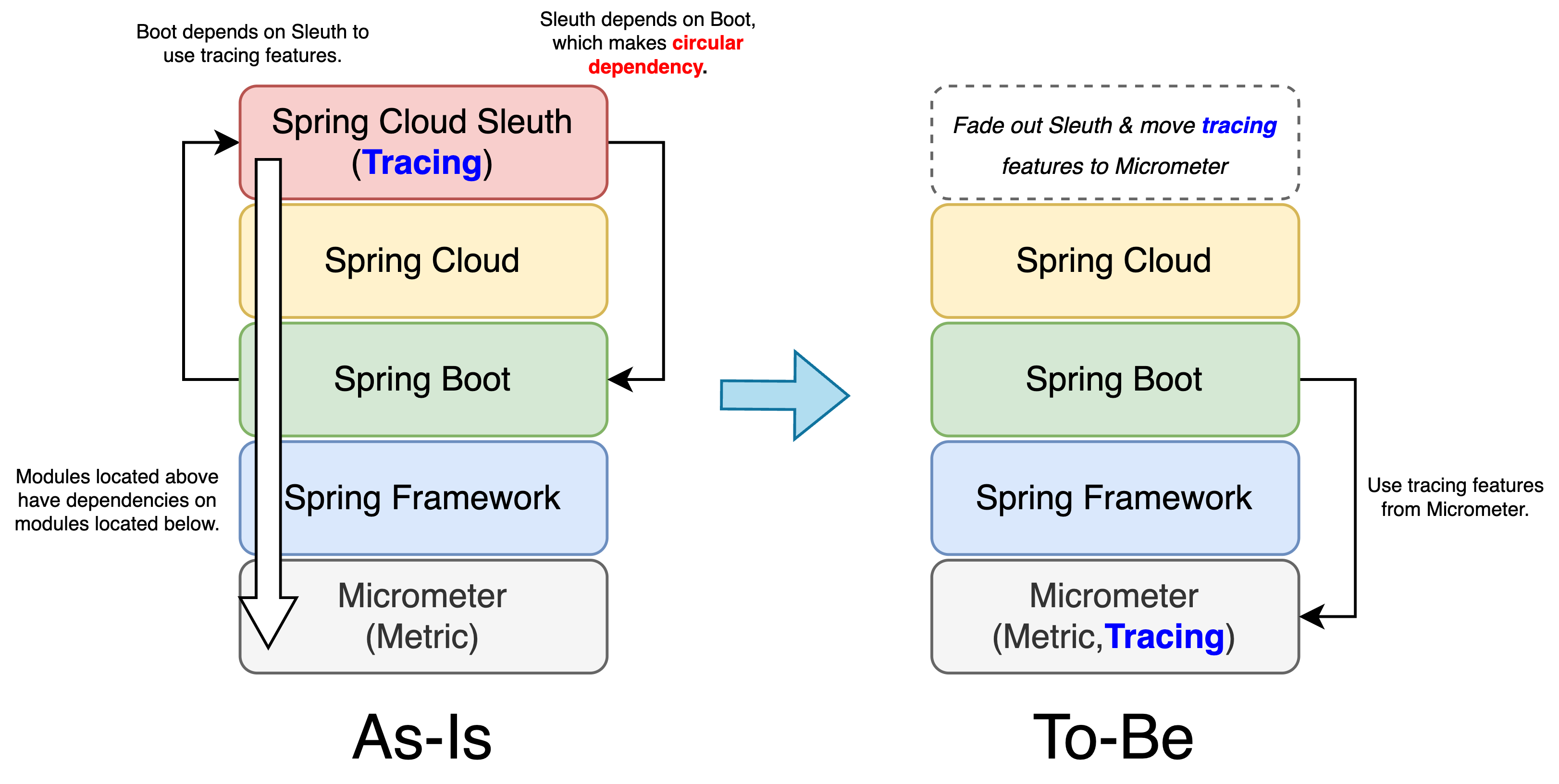
그동안 Spring 프로젝트에서는 Spring Cloud Sleuth로 트레이싱 기능을 지원하고 있었습니다. 다시 왼쪽 그림을 살펴보면 이는 차례대로 Spring Cloud와 Boot, Framework에 의존하는 구조라는 것을 알 수 있는데요. 이때 순환 의존성(circular dependency)이 발생합니다. Spring Cloud Sleuth는 기본적으로 Spring Boot 위에서 작동하도록 설계돼 있습니다. 이런 구조로 인해 Spring Cloud Sleuth는 Spring Boot에 의존하고 반대로 Spring Boot도 트레이싱 기능을 위해 Spring Cloud Sleuth에 의존하는 상호 의존적인 관계가 형성됩니다.
또한 기존 구조에서는 Spring Framework나 Spring Boot 레벨에서 트레이싱 기능을 지원하지 않아 Spring Cloud와 Spring Cloud Sleuth를 추가해야 한다는 점도 아쉬웠는데요. 순환 의존성 문제를 해결하고 Spring Framework나 Spring Boot 레벨에서 트레이싱 기능을 사용할 수 있도록 Micrometer에서 Spring Cloud Sleuth가 담당하고 있던 Spring 프로젝트의 트레이싱 기능을 지원하도록 바꾸는 것이 이번 변경의 히스토리라고 볼 수 있습니다.
아래 내용은 Spring Cloud Sleuth 3.1 마이그레이션 가이드를 참고해 Spring Cloud Sleuth에서 기본 구현체인 Brave를 사용하고 있는 프로젝트를 이관하는 절차입니다.
Micrometer Tracing 의존성 추가
우선 Spring Cloud Sleuth 관련 의존성은 더 이상 사용하지 않으니 제거하고, Micrometer Tracing 관련 의존성을 추가합니다. 아래 예시에선 기존에 Brave 구현체를 사용하고 있던 것에 맞춰 Brave가 포함된 micrometer-tracing-bridge-brave 의존성을 추가했습니다. 만일 프로젝트에서 OpenTelemetry를 사용하고 계신다면 micrometer-tracing-bridge-otel 의존성을 추가합니다.
또한 아래 예시에서 추가한 micrometer-tracing-bridge-brave 의존성에는 기본적으로 Zipkin 관련 의존성이 포함돼 있는데요. 만약 프로젝트에서 Zipkin을 사용하지 않는다면 아래 예시처럼 exclude 문법으로 Zipkin 관련 라이브러리를 제외합니다. 다음으로 Prometheus로 Micrometer 관련 지표를 수집하기 위해 micrometer-registry-prometheus 의존성도 추가했습니다.
- Kotlin 예제
dependencies { // Sleuth 의존성 제거 // implementation("org.springframework.cloud:spring-cloud-starter-sleuth") implementation("io.micrometer:micrometer-tracing-bridge-brave") { // 프로젝트에서 Zipkin을 사용하지 않는 경우 exclude(group = "io.zipkin.reporter2") } implementation("io.micrometer:micrometer-registry-prometheus") // 프로젝트에서 Spring Cloud OpenFeign의 FeignClient를 사용하고 있다면 아래 의존성도 추가 implementation("io.github.openfeign:feign-micrometer") } dependencies { // Sleuth 의존성 제거 // implementation 'org.springframework.cloud:spring-cloud-starter-sleuth' implementation('io.micrometer:micrometer-tracing-bridge-brave') { // 프로젝트에서 Zipkin을 사용하지 않는 경우 exclude group: 'io.zipkin.reporter2' } implementation 'io.micrometer:micrometer-registry-prometheus' // 프로젝트에서 Spring Cloud OpenFeign의 FeignClient를 사용하고 있다면 아래 의존성도 추가 implementation 'io.github.openfeign:feign-micrometer' }Groovy 예제
만일 프로젝트에서 Spring Cloud OpenFeign의 FeignClient를 사용한다면 feign-micrometer 의존성과 설정을 추가해야 하는데요. 이와 관련해서는 아래에서 다시 설명하겠습니다. 참고로 예시에서 사용한 모든 의존성 버전은 Spring Dependency Management 플러그인으로 관리되며 별도의 버전 정보 없이 현재 Spring Boot 버전과 호환되는 버전으로 추가됩니다.
import 문 수정
Spring Boot 프로젝트에서 Spring Cloud Sleuth를 사용할 때 기본적인 기능은 별다른 설정 없이 의존성을 추가하는 것만으로 사용할 수 있습니다. 다만 설정을 커스터마이징할 때에는 Spring Cloud Sleuth에서 제공하는 코드를 명시적으로 작성하게 되는데요. 예를 들어 아래 예시처럼 코�드에서 직접 트레이싱 관련 클래스와 코드를 사용하고 있다면 패키지 이름을 확인하고 필요하면 micrometer.tracing으로 변경해야 합니다.
- Java 예제
// As-Is import brave.Tracer; // To-Be import io.micrometer.tracing.Tracer; // As-Is import brave.Tracer // To-Be import io.micrometer.tracing.TracerKotlin 예제
지원이 중단된 API 및 컴파일 에러 수정
일부 Tracer 관련 메서드 이름도 변경됐습니다. 아래 예시처럼 소소한 변경이 대부분인데요. Javadoc을 확인하면서 기존과 동일하게 작동하는 메서드나 변수를 사용하도록 코드를 수정합니다.
- Java 예제
// Given Tracer tracer; // As-Is tracer.currentSpan().context().traceIdString(); // To-Be tracer.currentSpan().context().traceId(); // Given val tracer:Tracer // As-Is tracer.currentSpan()?.context()?.traceIdString() // To-Be tracer.currentSpan()?.context()?.traceId()Kotlin 예제
application.yml 혹은 application.properties 수정
마지막으로 아래와 같이 Spring Boot 설정 파일에서 management.tracing.propagation.type을 b3로 설정합니다.
application.yml
# Tracing propagation type을 수정 management: tracing: propagation: type: b3 # Logging 패턴 설정 logging: pattern: level: "%5p [${spring.application.name:},%X{traceId:-},%X{spanId:-}]" # Spring Cloud OpenFeign의 FeignClient의 트레��이싱 기능 활성화 spring: cloud: openfeign: micrometer: enabled: true# Tracing propagation type을 수정 management.tracing.propagation.type=b3 # Logging 패턴 설정 logging.pattern.level=%5p [${spring.application.name:},%X{traceId:-},%X{spanId:-}] # Spring Cloud OpenFeign의 FeignClient에 대한 Micrometer 기능 활성화 spring.cloud.openfeign.micrometer.enabled=trueapplication.properties
분산 트레이싱 시스템에서 사용하는 트레이스 컨텍스트 전파 방식으론 크게 'B3'와 'W3C' 두 종류가 있습니다.
Tracer 구현체와 프로젝트 설정 등에 따라 달라질 수 있지만, Spring Cloud Sleuth에서는 기본적으로 Brave를 Tracer 구현체로 사용한다고 앞서 말씀드렸습니다. 이 Brave는 정확히 말하자면 OpenZipkin 프로젝트의 Brave입니다. 따라서 Spring Cloud Sleuth에서는 전파 방식으로 Zipkin 시스템의 표준인 B3를 사용하고 있습니다. 하지만 Spring Boot 3에서의 디폴트 설정은 W3C입니다(참고). 따라서 기존과 동일하게 작동하기 위해서는 별도로 설정해야 합니다. 위 예시에서는 기존 Spring Boot 2 기반 모듈과의 호환성을 위해 B3로 설정했습니다.
이어서 애플리캐이션 이름과 traceId, spanId 로깅 패턴 설정(참고)도 위 예시와 같이 하면 됩니다. 또한 프로젝트에서 Spring Cloud OpenFeign의 FeignClient를 사용하고 있다면 위 예시처럼 micrometer.enabled=true 옵션을 설정해야 FeignClient를 통해 API 통신할 때 트레이싱 정보가 HTTP 헤더에 정상적으로 들어갑니다.
위 마이그레이션을 통해 기존에 사용하던 트레이싱 기능의 대부분을 기존과 동일하게 사용할 수 있습니다. 대부분이라고 말씀드리는 이유는, 기존에 Spring Cloud Sleuth에서 지원하던 기능 중 일부는 다음과 같이 별도로 설정해야 하거나 아직 지원하지 않기 때문입니다.
- Spring Cloud Gateway 등 Reactor를 사용하는 모듈의 경우 별도로 트레이싱 정보를 전파하기 위한 설정이 필요합니다(참고).
@Async로 선언한 작업을 트레이싱하려면TaskExecutor를 커스터마이징해야 합니다(참고).- 예외가 발생하면 트레이싱 정보가
@ExceptionHandler등으로 예외를 처리하는 로직까지 전파되지 않습니다(참고 1, 참고 2).
프로젝트마다 환경이 모두 다르다 보니 이를 전부 다루기는 어려울 것 같습니다. 위 내용을 포함해서 현재 GitHub 이슈로 활발하게 대화가 오가고 있으며, 그중 일부는 신규 버전에서 개선하는 것을 목표로 작업 중이라고 하니 참고하시면 좋을 것 같습니다.
Spring Data JPA
Spring Data JPA 프로젝트에서는 All-open 플러그인과 Hibernate를 살펴보겠습니다.
All-open 설정 수정
프로젝트에서 Kotlin을 사용하고 있다면 All-open 플러그인을 이용해 Entity, Embeddable, MappedSuperclass의 세 어노테이션을 사용하는 클래스를 상속할 수 있도록 설정하셨을 텐데요. 앞서 말씀드렸듯 javax.persistence 패키지가 jakarta.persistence 패키지로 변경됐으니 이에 맞게 수정합니다.
- Kotlin 예제
allOpen { // As-Is // annotation("javax.persistence.Entity") // annotation("javax.persistence.Embeddable") // annotation("javax.persistence.MappedSuperclass") // To-Be annotation("jakarta.persistence.Entity") annotation("jakarta.persistence.Embeddable") annotation("jakarta.persistence.MappedSuperclass") } allOpen { // As-Is // annotation 'javax.persistence.Entity' // annotation 'javax.persistence.Embeddable' // annotation 'javax.persistence.MappedSuperclass' // To-Be annotation 'jakarta.persistence.Entity' annotation 'jakarta.persistence.Embeddable' annotation 'jakarta.persistence.MappedSuperclass' }Groovy 예제
Hibernate 6.2 변경 사항 파악 및 적용
Spring Boot 3.1 버전부터 기본적으로 Hibernate 6.2를 사용합니다(참고). Hibernate는 JPA의 구현체로 이번에 마이너 버전이 올라갔고, 관련해서 아래와 같이 몇 가지 눈에 띄는 변경 사항이 있습니다. 자세한 내용은 Hibernate 6.2 릴리스 노트를 읽어보시길 바랍니다.

가장 큰 변경점 중 하나는 Hibernate에서 시간대(time zone) 정보를 다루는 방식이 달라진 것입니다. Hibernate 6.2부터 시간대 관련 정보는 hibernate.timezone.default_storage 옵션으로 다룹니다. 이 옵션은 내부적으로 TimeZoneStorageType 값과 매핑되고, 이를 통해 Hibernate가 시간 관련 정보를 실제 DB 테이블에 저장하고 데이터를 읽을 때 시간 데이터를 어떤 식으로 보간하는지 조정할 수 있습니다.
만일 별다른 옵션을 주지 않았다면 hibernate.timezone.default_storage=DEFAULT로 설정되고 다음과 같이 작동합니다.
- DB 레벨에서 시간대 정보를 관리할 수 있도록 지원하는 경우 절대 시간과 시간대 정보가 DB 테이블에 함께 저장됩니다(
TimeZoneStorageType.NATIVE와 동일). - DB 레벨에서 시간대 정보를 관리하지 않는 경우 UTC 시간대로 보간해서 시간 정보가 저장됩니다(
TimeZoneStorageType.NORMALIZE_UTC와 동일).
예를 들어 MySQL 타임스탬프 칼럼과 같이 시간대 정보를 저장하지 않는 칼럼의 경우 JPA 엔티티를 실제 DB 테이블에 저장할 때 시간 관련 정보를 UTC 시간으로 보간해서 저장합니다. 만일 이를 확인하지 않은 상태에서 운영 환경으로 내보낼 경우 기존 데이터와 정합성이 맞지 않는 것은 물론이고 애플리케이션 로직에도 큰 영향을 줄 수 있습니다. 그래서 Hibernate에서는 기존에 저장된 데이터와의 정합성을 보장하고 애플리케이션 로직의 하위 호환성을 고려해 NORMALIZE 옵션을 제공하고 있습니다.
application.yml
spring: jpa: properties: hibernate: timezone.default_storage: NORMALIZEspring.jpa.properties.hibernate.timezone.default_storage=NORMALIZEapplication.properties
NORMALIZE 옵션은 시간대 정보를 6.2 이전 버전과 동일한 방식으로 설정하는 옵션으로, 데이터소스 연결 정보에 설정한 시간대 또는 JVM 기본 시간대 정보를 사용합니다. 만일 JPA와 Hibernate를 사용하고 있는 모듈이라면 hibernate.timezone.default_storage=NORMALIZE 옵션을 꼭 설정해 놓아야 기존 데이터와의 정합성을 보장하면서 이전과 동일한 방식으로 DB 테이블에 데이터를 저장할 수 있습니다.
Spring Batch
Spring Boot 3부터 Spring Batch의 신규 메이저 버전인 Spring Batch 5를 사용합니다. 이 글에선 여러 가지 변경점 중 Spring Batch에서 가장 많이 사용하는 다음 두 가지 기능을 중심으로 살펴보겠습니다.
- 배치 잡 생성
- 배치 잡 파라미터(
jobParamter) 전달
배치 잡 정의 코드 변경
Spring Batch 5에서 배치 잡을 정의하는 코드가 변경됐습니다(참고). 간단한 예시 코드와 함께 변경된 부분을 살펴보겠습니다. 아래 코드는 Spring Batch 4 환경에서 작성한 simpleJob이라는 배치 잡을 만드는 코드로, 다음 두 개의 스텝으로 구성돼 있습니다.
taskletStep→Tasklet을 이용해 만든 스텝으로 콘솔에 지정한 문자열을 출력합니다.chunkStep→Reader,Processor,Writer를 이용해 만든 스텝으로count라는 정수 형태의 잡 파라미터를 전달받아 지정한 문자열을count값만큼 반복해서 콘솔에 출력합니다.
- Java 예제
@Slf4j @Configuration @EnableBatchProcessing @RequiredArgsConstructor public class SimpleJobBatch4 { private final JobBuilderFactory jobBuilderFactory; private final StepBuilderFactory stepBuilderFactory; @Bean public Job job() { return jobBuilderFactory.get("simpleJob") .incrementer(new RunIdIncrementer()) .start(taskletStep()) .next(chunkStep()) .build(); } @Bean public Step taskletStep() { return stepBuilderFactory.get("taskletStep") .tasklet(tasklet()) .build(); } @Bean public Tasklet tasklet() { return (contribution, chunkContext) -> { log.info("Running tasklet step"); return RepeatStatus.FINISHED; }; } @Bean public Step chunkStep() { return stepBuilderFactory.get("chunkStep") .<String, String>chunk(1) .reader(reader(null)) .processor(processor()) .writer(writer()) .build(); } @Bean @StepScope public ItemReader<String> reader(@Value("#{jobParameters['count']}") Integer count) { return new ItemReader<>() { private int alreadyRead = 0; @Override public String read() { if (alreadyRead < (count != null ? count : 0)) { alreadyRead++; return "Hello, Spring Batch!"; } else { return null; } } }; } @Bean public ItemProcessor<String, String> processor() { return String::toUpperCase; } @Bean public ItemWriter<String> writer() { return item -> item.forEach(log::info); } } @EnableBatchProcessing @Configuration class SimpleJobBatch4( private val jobBuilderFactory: JobBuilderFactory, private val stepBuilderFactory: StepBuilderFactory, ) { private val log = LoggerFactory.getLogger(this.javaClass) @Bean fun job(): Job = jobBuilderFactory["simpleJob"] .incrementer(RunIdIncrementer()) .start(taskletStep()) .next(chunkStep()) .build() @Bean fun taskletStep(): Step { return stepBuilderFactory["taskletStep"] .tasklet(tasklet()) .build() } @Bean fun tasklet(): Tasklet = Tasklet { _, _ -> log.info("Running tasklet step") RepeatStatus.FINISHED } @Bean fun chunkStep(): Step = stepBuilderFactory["chunkStep"] .chunk<String, String>(1) .reader(reader(null)) .processor(processor()) .writer(writer()) .build() @Bean @StepScope fun reader(@Value("#{jobParameters['count']}") count: Int?): ItemReader<String> { var alreadyRead = 0 return ItemReader { if (alreadyRead < (count ?: 0)) { alreadyRead++ "Hello, Spring Batch!" } else { null } } } @Bean fun processor(): ItemProcessor<String, String> = ItemProcessor { it.uppercase() } @Bean fun writer(): ItemWriter<String> = ItemWriter { it.forEach(log::info) } }Kotlin 예제
아래 코드는 Spring Batch 5 환경에서 동일한 기능을 하는 코드입니다.
- Java 예제
@Slf4j @Configuration // 1 public class SimpleJobBatch5 { @Bean public Job simpleJob(JobRepository jobRepository, PlatformTransactionManager transactionManager) { // 2 return new JobBuilder("simpleJob", jobRepository) // 3 .incrementer(new RunIdIncrementer()) .start(taskletStep(jobRepository, transactionManager)) .next(chunkStep(jobRepository, transactionManager)) .build(); } @Bean public Step taskletStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) { // 2 return new StepBuilder("taskletStep", jobRepository) // 3 .tasklet(tasklet(), transactionManager) .build(); } @Bean public Tasklet tasklet() { return (contribution, chunkContext) -> { log.info("Running tasklet step"); return RepeatStatus.FINISHED; }; } @Bean public Step chunkStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) { return new StepBuilder("chunkStep", jobRepository) .<String, String>chunk(1, transactionManager) .reader(reader(null)) .processor(processor()) .writer(writer()) .build(); } @Bean @StepScope public ItemReader<String> reader(@Value("#{jobParameters['count']}") Integer count) { return new ItemReader<>() { private int alreadyRead = 0; @Override public String read() { if (alreadyRead < (count != null ? count : 0)) { alreadyRead++; return "Hello, Spring Batch!"; } else { return null; } } }; } @Bean public ItemProcessor<String, String> processor() { return String::toUpperCase; } @Bean public ItemWriter<String> writer() { return item -> item.forEach(log::info); } } @Configuration // 1 class SimpleJobBatch5 { private val log = LoggerFactory.getLogger(this.javaClass) @Bean fun simpleJob(jobRepository: JobRepository, transactionManager: PlatformTransactionManager): Job { // 2 return JobBuilder("simpleJob", jobRepository) // 3 .incrementer(RunIdIncrementer()) .start(taskletStep(jobRepository, transactionManager)) .next(chunkStep(jobRepository, transactionManager)) .build() } @Bean fun taskletStep(jobRepository: JobRepository, transactionManager: PlatformTransactionManager): Step { // 2 return StepBuilder("taskletStep", jobRepository) // 3 .tasklet(tasklet(), transactionManager) .build() } @Bean fun tasklet(): Tasklet = Tasklet { _, _ -> log.info("Running tasklet step") RepeatStatus.FINISHED } @Bean fun chunkStep(jobRepository: JobRepository, transactionManager: PlatformTransactionManager): Step { return StepBuilder("chunkStep", jobRepository) .chunk<String, String>(1, transactionManager) .reader(reader(null)) .processor(processor()) .writer(writer()) .build() } @Bean @StepScope fun reader(@Value("#{jobParameters['count']}") count: Int?): ItemReader<String> { var alreadyRead = 0 return ItemReader { if (alreadyRead < (count ?: 0)) { alreadyRead++ "Hello, Spring Batch!" } else { null } } } @Bean fun processor(): ItemProcessor<String, String> = ItemProcessor { it.uppercase() } @Bean fun writer(): ItemWriter<String> = ItemWriter { it.forEach(log::info) } }Kotlin 예제
변경 포인트를 몇 가지 짚어보면 다음과 같습니다.
- Spring Boot 환경에서 Spring Batch를 사용할 때 더 이상
@EnableBatchProcessing어노테이션이 필요하지 않습니다(참고).@EnableBatchProcessing어노테이션을 사용하면 오히려 의도한 것과 다르게 작동합니다.- 만일 Spring Boot 없이 Spring Batch만 사용하는 프로젝트라면 기존과 동일하게
@EnaleBatchProcessing어노테이션을 사용합니다.
- 잡과 스텝을 만들 때 JobRepository와 PlatformTransactionManager 파라미터가 필요합니다.
JobBuilderFactory와StepBuilderFactory가 지원이 중단됐고,JobBuilder와StepBuilder를 사용합니다(참고).
배치 잡 파라미터 전달 방식 개선
Spring Batch 5에서 배치 잡 파라미터(jobParamter)를 전달하는 방식이 개선됐습니다(참고). 배치 잡 파라미터를 전달하는 방식에는 여러 가지가 있는데요. 저희 팀에선 배치 잡 실행 시 외부 인자(program argument) 형태로 파라미터를 전달하는 방식을 사용하고 있습니다.
아래는 배치 잡을 실행할 때 사용하는 예시 스크립트입니다. simpleJob이라는 이름의 배치 잡을 count라는 잡 파라미터에 10을 넣어 실행합니다. Spring Boot 3부터 두 개 이상의 배치 잡을 실행하는 것이 불가능해졌고(참고), 실행할 배치 잡 이름을 설정하는 프로퍼티가 spring.batch.job.names에서 spring.batch.job.name으로 변경됐습니다. 전달한 count 값은 simpleJob에서 @Value 어노테이션을 선언해 count라는 이름을 가진 변수에 넣고 배치 잡 로직을 실행합니다.
java -jar \
-Dspring.batch.job.name=simpleJob \
app.jar \
count=10 \위 예시에서 count와 같이 기존에는 잡 파라미터 값을 넣을 때 다음과 같은 문법을 사용했습니다.
[+|-]parameterName(parameterType)=valueSpring Batch 5로 넘어오면서 잡 파라미터 값을 넣는 방법으로 다음 두 가지 개선된 방법이 추가됐습니다.
parameterName=parameterValue,parameterType,identificationFlag
parameterName='{"value": "parameterValue", "type":"parameterType", "identifying": "booleanValue"}'
# value: string literal representing the value
# type (optional): fully qualified name of the type of the value. Defaults to String.
# identifying (optional): boolean to flag the job parameter as identifying or not. Defaults to true.count 값을 예시로 하면 다음과 같습니다. 기존에는 잡 파라미터로 String, Long, Double, Date 타입만을 지원했지만 Spring Batch 5에서는 위와 같은 문법으로 다양한 타입의 잡 파라미터를 전달받아 사용할 수 있습니다.
count=10 # 1
count=10,java.lang.Integer # 2
count={\"value\":\"10\",\"type\":\"java.lang.Integer\"} # 3첫 번째 방법은 위 예시처럼 파라미터 값이 단순한 형식일 때 사용하면 좋습니다.
두 번째 방법은 배치 잡 파라미터 타입을 함께 명시하는 방식으로 기존에 지원하는 네 가지 타입 외에 다른 타입도 사용할 수 있습니다.
세 번째 방법은 JSON 형식으로 파라미터 값을 전달하는 방식입니다. 예를 들어 Hello, world!라는 문자열은 쉼표(,) 때문에 기존 배치잡 파라미터 문법으로는 다루기 어려운데요. 이처럼 기존 문법으로 전달하기 어려운 복잡한 값을 다룰 때 사용하면 좋습니다. 이 방법은 아래 예시처럼 JsonJobParametersConverter Bean을 등록한 후 사용할 수 있습니다.
- Java 예제
@Configuration public class BatchConfiguration { @Bean public JobParametersConverter jsonJobParametersConverter() { return new JsonJobParametersConverter(); } } @Configuration class BatchCommonConfiguration { @Bean fun jsonJobParametersConverter(): JobParametersConverter { return JsonJobParametersConverter() } }Kotlin 예제
그 이외에 주목할 만한 변경점은 다음과 같습니�다. 자세한 내용은 Spring Batch 5.0 마이그레이션 가이드를 참고하시기 바랍니다.
BatchConfigurer클래스 삭제- 배치 잡 메타 테이블 스키마 변경
Spring Security
Spring Boot 3부터 Spring Security의 신규 메이저 버전인 Spring Security 6를 사용합니다. 이번 글에선 여러 가지 변경점 중 HttpSecurity와 WebSecurity 설정 방식이 어떻게 변경됐는지 살펴보겠습니다.
Security 설정 방식 변경
다음은 Spring 공식 블로그의 포스트에서 가져온 문장입니다.
In Spring Security 5.7.0-M2 we deprecated the WebSecurityConfigurerAdapter, as we encourage users to move towards a component-based security configuration.
위와 같이 Spring Security 메인테이너는 개발자가 특정 클래스를 상속하는 것이 아니라 컴포넌트 기반으로 보안 설정을 하도록 권장하고 있습니다. 여기서 컴포넌트 기반의 보안 설정이라는 것은, 대부분의 Spring 프로젝트에서 사용하고 있는 '내가 필요한 기능을 담당하는 클래스를 커스터마이징하는 Bean을 등록하는 방식'이라고 아래와 같이 말하고 있습니다.
The first is that rather than exposing Beans, it silently creates objects that cannot be used by the underlying application or by Spring Boot for auto configuration.
Spring Security GitHub 이슈를 보면 클래스를 상속하는 방식은 일부 자동 설정을 감춰서 Spring Boot가 특정 스프링 Bean이 필요한지 알기 어렵게 하는 것과 같은 몇 가지 문제가 있다고 합니다. 이에 Spring Security 6에서는 보안 설정 방식이 변경됐습니다.
간단한 예시 코드와 함께 어떻게 변경됐는지 설명하겠습니다. 아래 코드는 Spring Security 6 이전 버전 기준으로 작성한 보안 설정 코드입니다. 특정 경로에 인가(authorization)받은 사용자만 접근할 수 있게 설정하고, 인증(authentication) 방식은 Basic Authentication를 사용하며, 특정 정적 자원에 접근하는 것을 막는(ignore) 간단한 코드입니다.
- Java 예제
@EnableWebSecurity public class SecurityConfigSecurity5 extends WebSecurityConfigurerAdapter { // HttpSecurity 설정 @Override protected void configure(HttpSecurity http) throws Exception { http.authorizeRequests() .antMatchers("/api/admin/**").hasRole("ADMIN") .antMatchers("/api/user/**").hasRole("USER") .anyRequest().authenticated(); http.httpBasic(Customizer.withDefaults()); } // WebSecurity 설정 @Override public void configure(WebSecurity web) { web.ignoring().antMatchers("/ignore1", "/ignore2"); } // UserDetailsService 설정 @Override protected void configure(AuthenticationManagerBuilder auth) throws Exception { UserDetails user = User.withDefaultPasswordEncoder() .username("user") .password("password") .roles("USER") .build(); UserDetails admin = User.withDefaultPasswordEncoder() .username("admin") .password("password") .roles("ADMIN") .build(); auth.inMemoryAuthentication() .withUser(user) .withUser(admin); } } @EnableWebSecurity class SecurityConfigSecurity5 : WebSecurityConfigurerAdapter() { // HttpSecurity 설정 override fun configure(http: HttpSecurity) { http.authorizeRequests { authorize -> authorize .antMatchers("/api/admin/**").hasRole("ADMIN") .antMatchers("/api/user/**").hasRole("USER") .anyRequest().authenticated() } http.httpBasic(Customizer.withDefaults()) } // WebSecurity 설정 override fun configure(web: WebSecurity) { web.ignoring().antMatchers("/ignore1", "/ignore2") } // UserDetailsService 설정 override fun configure(auth: AuthenticationManagerBuilder) { val user = User.withDefaultPasswordEncoder() .username("user") .password("password") .roles("USER") .build() val admin = User.withDefaultPasswordEncoder() .username("admin") .password("password") .roles("ADMIN") .build() auth.inMemoryAuthentication() .withUser(user) .withUser(admin) } }Kotlin 예제
아래 코드는 Spring Security 6 환경에서 동일한 기능을 하는 코드입니다.
- Java 예제
@Configuration // 1 @EnableWebSecurity public class SecurityConfigSecurity6 { // 2 // HttpSecurity 설정 @Bean public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception { // 3 http.authorizeHttpRequests(authorize -> authorize .requestMatchers("/api/admin/**").hasRole("ADMIN") .requestMatchers("/api/user/**").hasRole("USER") .requestMatchers("/login").permitAll() .anyRequest().authenticated()); http.httpBasic(Customizer.withDefaults()); return http.build(); } // WebSecurity 설정 @Bean public WebSecurityCustomizer webSecurityCustomizer() { // 4 return web -> web.ignoring().requestMatchers("/ignore1", "/ignore2"); } // UserDetailsService 설정 @Bean public InMemoryUserDetailsManager userDetailsService() { // 5 UserDetails user = User.withDefaultPasswordEncoder() .username("user") .password("password") .roles("USER") .build(); UserDetails admin = User.withDefaultPasswordEncoder() .username("admin") .password("password") .roles("ADMIN") .build(); return new InMemoryUserDetailsManager(user, admin); } } @Configuration // 1 @EnableWebSecurity class SecurityConfigSecurity6 { // 2 // HttpSecurity 설정 @Bean fun securityFilterChain(http: HttpSecurity): SecurityFilterChain { // 3 http.authorizeHttpRequests { authorize -> authorize .requestMatchers("/api/admin/**").hasRole("ADMIN") .requestMatchers("/api/user/**").hasRole("USER") .requestMatchers("/login").permitAll() .anyRequest().authenticated() } http.httpBasic(Customizer.withDefaults()) return http.build() } // WebSecurity 설정 @Bean fun webSecurityCustomizer(): WebSecurityCustomizer { // 4 return WebSecurityCustomizer { web -> web.ignoring().requestMatchers("/ignore1", "/ignore2") } } // UserDetailsService 설정 @Bean fun userDetailsService(): InMemoryUserDetailsManager { // 5 val user = User.withDefaultPasswordEncoder() .username("user") .password("password") .roles("USER") .build() val admin = User.withDefaultPasswordEncoder() .username("admin") .password("password") .roles("ADMIN") .build() return InMemoryUserDetailsManager(user, admin) } }Kotlin 예제
변경된 포인트를 몇 가지 짚어보면 다음과 같습니다.
@EnableWebSecurity어노테이션에서@Configuration어노테이션이 제거돼 이를 별도로 선언해야 합니다(참고).- 기존 Spring 프로젝트에서 사용하는
@EnableXXX형식의 어노테이션과 일관성을 맞추기 위해서라고 합니다. - WebFlux 애플리케이션에서 사용하는
@EnableWebFluxSecurity어노테이션도 동일합니다.
- 기존 Spring 프로젝트에서 사용하는
WebSecurityConfigurerAdapter클래스가 제거됐습니다(참고). 6.0 버전부터 해당 클래스가 완전히 제거됐기 때문에 위 예시처럼 관련 설정을 하는 클래스를 직접 Spring Bean으로 설정해야 합니다.- 2번의 영향으로
HttpSecurity설정 시SecurityFilterChainBean을 직접 선언하는 식으로 변경됐습니다. - 2번의 영향으로
WebSecurity설정 시WebSecurityCustomizerBean을 직접 선언하는 식으로 변경됐습니다. UserDetailsManager설정 시UserDetailsManagerBean을 직접 선언하는 식으로 변경됐습니다.AuthenticationManager도 마찬가지로 커스터마이징한 클래스를 직접 Spring Bean으로 등록하는 방식으로 변경됐습니다.
그 이외에 주요 변경점은 다음과 같습니다.
requestMatchers()와securityMatchers()메서드 추가(참고)antMatchers(),mvcMatchers(),regexMatchers()메서드 지원 중단
.and()등 일부 메서드 지원 중단
Spring Security 6로 조금 더 부드럽게 업데이트하는 방법
위 변경 사항이 파격적인 변화라는 것을 Spring 진영에서도 인지한 것인지 공식 블로그 등을 통해 이관하는 데 도움이 되는 코드 스니펫을 많이 제공하고 있는데요(참고). 사실 WebSecurityConfigurerAdapter 없이 HttpSecurity, WebSecurity을 설정하는 방식은 Spring Security 5.6 버전부터 가능했습니다. 그리고 이를 포함한 주요 변경 사항은 Spring Boot 2.7 버전과 매핑되는 Spring Security 5.8 버전부터 적용돼 있었습니다.
따라서 프로젝트에서 사용하는 보안 설정의 양이 많아 한 번에 처리해야 할 일이 너무 많다고 판단되면 다음과 같이 한 단계씩 준비하는 것도 좋은 방법입니다.
- Spring Boot를 2.7 버전으로 업데이트하고 Spring Security를 5.8 버전으로 업데이트
- Spring Security 5.8 버전을 기준으로 6.0 버전으로 업데이트하기 위한 공식 가이드(Preparing for 6.0)를 참고해서 준비
- Spring Boot 3으로 업데이트한 뒤 공식 가이드(Migrating to 6.0)를 참고해 Spring Security 6.0 버전으로 업데이트
기타
그외 Spring Boot 3으로 업데이트할 때 함께 작업해야 할 사항을 살펴보겠습니다.
Flyway
Spring Boot 3.1.5 버전 기준으로 org.flywaydb:flyway-core를 비롯한 Flyway 관련 의존성 버전은 9.22.3입니다(참고). Flyway는 무료 버전과 유료 버전으로 나뉘어 있는데요. 일반적으로 사용하는 무료 버전은 7.16.0 버전부터 MySQL 5.7 지원이 종료됐습니다. 따라서 비교적 최신 버전의 Spring Boot 2 혹은 Spring Boot 3 애플리케이션과 MySQL 5.7과의 Flyway 연동은 불가능합니다.
저희 팀에선 일부 모듈에서 MySQL 5.7을 사용하고 있어서 Spring Boot 2에서는 Flyway 버전을 7.15.0으로 고정해서 사용하고 있었습니다. 하지만 Spring Boot 3부터 MySQL 5.7 버전에 대한 FlywayAutoConfiguration이 지원되지 않기 때문에 Flyway 버전을 고정해도 Spring Boot 자동 설정을 통한 Flyway는 사용할 수 없습니다(참고). 이에 따라 MySQL 5.7을 그대로 사용해야 하는 경우에는 아래와 같은 방법으로 설정해야 합니다.
- Spring Boot의
FlywayAutoConfiguration비활성화-
application.ymlspring: flyway: enabled: false spring.flyway.enabled=falseapplication.properties
-
- Flyway 설정을 위한 Spring Bean 클래스 직접 정의
-
Java 예제
@Configuration @RequiredArgsConstructor public class FlywayConfiguration { private final DataSource dataSource; @Bean(initMethod = "migrate") public Flyway flyway() { return Flyway.configure() .dataSource(dataSource) .locations("classpath:db/migration") .load(); } } @Configuration class FlywayConfiguration(private val dataSource: DataSource) { @Bean(initMethod = "migrate") fun flyway(): Flyway = Flyway.configure() .dataSource(dataSource) .locations("classpath:db/migration") // migration 파일 위치 .load() }Kotlin 예제
-
FlywayAutoConfiguration을 비활성화하더라도 이와 별개로 DB 스키마 변경 히스토리는 기존과 동일하게 Flyway 스크립트로 갱신하면서 관리하는 것을 권장합니다. FlywayConfiguration을 직접 정의하는 과정에서 개발자의 실수로 프로덕션 환경에서 애플리케이션이 실행될 때 Flyway가 활성화될 가능성이 있기 때문인데요. 이런 가능성을 막기 위해 아예 프로젝트에서 Flyway를 페이드아웃하거나 만일의 사태를 대비해 기존과 동일하게 변경된 DB 스키마에 대한 내역을 Flyway 스크립트로 관리하는 것이 좋을 것 같습니다.
Mockito
Spring Boot 3.1부터 Mockito 5를 사용합니다(참고). 이에 따른 큰 변화 중 하나는 Mockito의 ArgumentMatcher 인터페이스에 새로운 type() 메서드가 도입된 것입니다. 이전에는 ArgumentMatcher가 varargs를 지원하지 않았는데요. Mockito 5부터는 type() 메서드를 통해 원하는 만큼의 인자를 정확히 매칭할 수 있습니다.
또한 ArgumentCaptor의 작동 방식도 변경됐습니다. 모든 인자를 캡처하려면 String[]을 위한 ArgumentCaptor를 사용하고, 특정 수의 인자만 캡처하려면 String을 위한 ArgumentCaptor를 사용해야 합니다. 아래는 공식 문서에서 가져온 예시입니다. 기존에 varargs를 파라미터로 사용하고 있던 메서드를 스터빙(stubbing)하고 있는 테스트 코드가 실패할 수 있으니, 아래 예시처럼 사용하려는 아규먼트를 명확하게 선언하도록 수정해야 합니다.
- Java 예제
// 아래와 같은 메서드가 있다면, long call(String... args); // 0 ~ N개의 argument로 호출하는 것을 stubbing할 때 when(mock.call(any(String[].class))).thenReturn(1L); // 0개의 argument로 호출하는 것을 stubbing할 때 when(mock.call()).thenReturn(1L); // 1개의 argument로 호출하는 것을 stubbing할 때, 방법 1 when(mock.call(any())).thenReturn(1L); // 1개의 argument로 호출하는 것을 stubbing할 때, 방법 2 when(mock.call(any(String.class))).thenReturn(1L); // 2개의 argument로 호출하는 것을 stubbing할 때 when(mock.call(any(), any())).thenReturn(1L);
그 외 자세한 내용은 공식 문서를 참고하시기 바랍니다.
의존성 버전 업그레이드
Gradle과 springdoc-openapi 의존성 버전이 업데이트됐습니다.
- Gradle 8.4: Java 21 지원 및 여러 가지 성능 개선, 보안 취약점 수정
- springdoc-openapi: Spring Boot 3을 지원하�기 위한 아티팩트 ID
- 기존 아티팩트 ID: springdoc-openapi-ui
- 새 아티팩트 ID: springdoc-openapi-starter-webmvc-ui, springdoc-openapi-starter-webflux-ui
마치며
글을 시작하면서 말씀드렸듯이 올해 11월 24일에 Spring Boot 2의 OSS 지원이 EOL(End Of Life)을 맞이하면서 지원이 중단될 예정입니다. 또한 11월에는 Spring Boot 3.2 버전 릴리스도 예정돼 있습니다. Spring Boot 3.2 버전에서는 Java 21의 새로운 기능 중 하나인 가상 스레드(virtual thread) 관련 지원(참고)을 비롯해 여러 가지 유용한 신규 기능이 추가될 예정이라고 합니다. Spring Boot 3는 정식 출시 후 1년 정도 지났기에 이제 상당히 안정화됐다고 볼 수 있습니다. 아직 일부 파격적인 변화들은 완벽하게 자리 잡지 못했지만, 오픈소스 커뮤니티의 지속적인 노력으로 점차 성숙해질 것이라고 기대하고 있습니다.
글을 마무리하는 시점에서 돌아보니 프로젝트마다 사용하는 환경이 달라 모든 변경 사항을 다루지 못한 점과, Spring Boot 3에서 신규로 적용해 볼 만한 기능들을 다루지 못한 점이 아쉽습니다. 기회가 된다면 이후 다른 글에서 이에 대한 내용도 다뤄보려고 합니다. 이 글이 Spring Boot 3 환경으로 전환하는 것을 고려하고 계신 개발자분들에게 조금이나마 도움이 되기를 바라며 이만 마치겠습니다.


