들어가며
안녕하세요. LINE Plus에서 통합 커머스 개발을 맡고 있는 김성도, 고상일입니다.
통합 커머스에서는 HBase 스냅숏과 Hive를 사용해 ETL(Extract-Transform-Load, 원본 데이터를 추출·변환해 분석이나 처리에 적합한 형태로 적재하는 파이프라인)을 구축해서 사용하고 있었습니다(참고). 수많은 상품 데이터 속에서 특정 조건을 만족하는 상품을 찾거나, 상태가 변경돼 일괄 처리해야 하는 상품들을 추출한 후 Kafka에 전송하는 등 요구 사항에 맞게 여러 방식으로 활용해 왔습니다.
하지만 이 ETL 방식에는 근본적인 문제가 있었습니다. 변경 사항을 반영하려면 매번 수억 건의 전체 데이터를 다시 써야(rewrite) 하는 구조였기 때문에 데이터 규모가 커질수록 반영에 드는 비용과 시간이 함께 증가했습니다. 여기에 사내 공용 Hadoop 리소스가 부족한 상황까지 겹치면서 업데이트 주기가 지연돼 데이터의 최신성을 보장하기 어려운 상황이 반복됐습니다.
저희에게 필요한 것은 전체 데이터를 매번 덮어쓰는 방식이 아니라 실제로 변경된 데이터만 빠르게 반영할 수 있는 증분(incremental) 처리 구조로 전환하는 것이었는데요. 이번 글에서는 어떻게 이 과제를 해결해 기존에 1시간(60분) 주기였던 데이터 반영 작업을 5분으로 단축해 속도를 약 12배 높일 수 있었는지 소개하려고 합니다.
기존 ETL 구조의 한계
기존의 '전체 데이터 복제(full dump)' 방식이 안고 있는 문제는 우리에게 친숙한 MySQL(InnoDB) 환경을 떠올려 보면 쉽게 이해할 수 있습니다. 대용량 테이블의 데이터를 외부로 추출할 때에는 정합성(consistency)을 어떻게 보장하느냐에 따라 크게 두 가지 접근 방식을 고려하게 됩니다.
첫 번째는 정합성을 포기한 단순 추출(SELECT *)입니다. 이 방법은 추출 중에도 데이터가 계속 변경되므로 결과물에 서로 다른 시점의 데이터가 뒤섞이며, 막대한 디스크 I/O가 발생해 운영 DB에 큰 부하를 줍니다.
두 번째는 실무에서 주로 쓰는 스냅숏(snapshot) 기반 추출입니다. MVCC(multiversion concurrency control)를 활용해 특정 시점을 고정하므로 정합성은 보장되지만 대용량 데이터에서는 치명적인 딜레마가 발생합니다. 예를 들어 추출에 1시간이 걸린다면 DB는 그 사이 수많은 트랜잭션이 발생해도 1시간 전의 과거 상태를 유지해야 합니다. 이는 Undo 세그먼트의 팽창을 유발해 라이브 서비스의 성능을 떨어뜨리고, 힘들게 작업을 끝내더라도 확보한 데이터는 이미 '1시간 전의 과거'에 머물러 있게 됩니다.
저희 팀의 HBase와 Hive 기반 ETL도 본질적으로 같은 구조적 한계를 안고 있었습니다. 상품 데이터의 실시간 변경분을 HDFS에 지속적으로 수집하고 있었지만, 이를 실제 조회 가능한 테이블에 반영하려면 기존 데이터와 새로운 변경분을 병합해 수억 건의 전체 데이터를 새로 써야 했습니다. 결과적으로 RDBMS의 전체 덤프 상황처럼 업데이트마다 막대한 컴퓨팅 비용이 소모되었고, 사내 공용 Hadoop 리소스가 부족한 상황까지 겹쳐 데이터의 최신성을 보장하지 못하고 업데이트가 지연되는 일이 빈번했습니다.
기존 구조에서 여러 개선 작업을 진행해 ETL 주기를 하루에서 1시간까지 단축하기는 했지만, 상시로 수신되고 업데이트가 발생하는 상품 데이터의 특성을 고려할 때 여전히 충분하지 않았습니다. 1시간 주기로 테이블을 갱신하더라도 그 사이 상품 정보가 변경되면 시스템이 과거 데이터를 기반으로 처리 작업을 수�행하게 되는 위험이 남아 있었기 때문입니다.
만약 수억 건의 데이터 중 실제로 변경된 수만 건만 골라 반영할 수 있다면, 처리해야 할 데이터 규모 자체가 수천 분의 일로 줄어듭니다. 컴퓨팅 비용은 변경분의 크기에 비례하므로 데이터 총량이 아무리 늘어나도 업데이트 비용을 일정하게 유지할 수 있고, 그만큼 반영 주기도 대폭 단축할 수 있습니다. 즉, 전체를 매번 다시 쓰는 구조에서는 불가능했던 '데이터 규모와 업데이트 비용의 분리'가 가능해지는 것입니다.
Iceberg 테이블 형식 도입과 요구 사항
다행히 이 시기부터 사내 Hadoop 환경에서 Apache Iceberg(이하 Iceberg) 테이블 형식을 지원하기 시작했습니다.
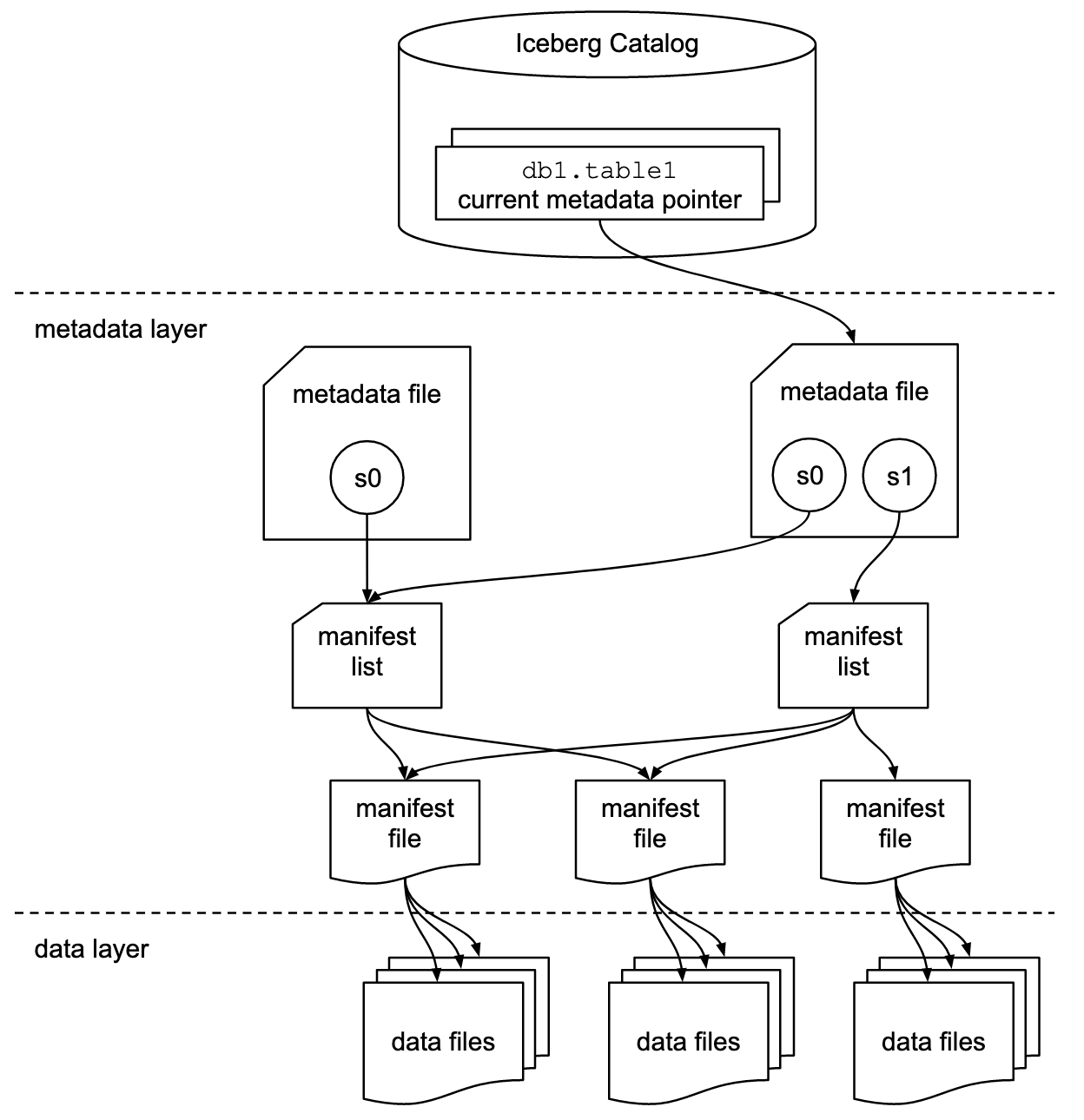
Iceberg는 대규모 데이터셋을 위한 오픈소스 테이블 형식입니다. 가장 큰 특징은 기존 Hive처럼 디렉터리 기반으로 파일을 관리하는 것이 아니라, 메타데이터를 이용해 테이블의 스냅숏 단위로 파일을 추적하고 관리한다는 점입니다.
이 구조 덕분에 데이터가 변경될 때마다 테이블 전체를 다시 쓸 필요 없이, 증분된 데이터를 행(row) 단위로 업데이트(upsert)하거나 삭제(delete)하면서 적재할 수 있습니다. 즉 전체 덮어쓰기라는 큰 장벽이 사라지면서 ETL 주기를 극적으로 단축할 수 있는 기술 기반이 마련된 것입니다.
스트리밍 엔진과 운영 방식 선택
Iceberg 공식 문서를 보면 여러 프레임워크와 연동할 수 있다고 나오는데요. 저희는 그중에서 사내 환경에서 사용할 수 있고 스트리밍 처리에 적합하다고 판단한 Apache Spark(이하 Spark)와 Apache Flink(이하 Flink)를 놓고 고민했습니다.
Flink vs. Spark 스트리밍
둘 중 어떤 엔진을 사용할지 결정하기 위해 두 엔진이 저희에게 꼭 필요한 다음 세 가지 필수 요소를 충족하는지 확인했습니다.
- 데이터 최신성 보장
- ‘종단 간 정확히 한 번(end-to-end exactly-once)’ 처리 지원
- 장애 허용(fault tolerance) 및 상태 관리
1. 데이터 최신성 보장
실시간 CDC(change data capture) 데이터만 처리하는 상황이라면 Kafka 파티션을 분배해 순서를 보장할 수 있습니다. 하지만 데이터 유실이나 오적재가 발생했을 때 혹은 전체 데이터셋을 일괄 재처리해야 할 때는 과거 시점의 데이터를 다시 흘려보내는 보정(compensation) 작업이 필요합니다. 이때 컨슈머 랙(consumer lag)이 발생하면 이미 처리된 최신 CDC 데이터 위로 뒤늦게 도착한 과거의 보정 데이터를 덮어써 버리는 문제가 발생할 수 있습니다. 시스템은 이를 사전에 인지하고 방어할 수 있어야 합니다.
2. 종단 간 정확히 한 번 처리 지원
데이터 추출 시점과 CDC 반영 시점이 일치하지 않아 데이터가 누락되는 현상을 완벽히 방지해야 했습니다.
예를 들어 특정 판매자(merchant)의 메타데이터가 변경돼 해당 판매자의 모든 상품 데이터를 추출해 일괄 업데이트해야 하는 상황을 가정해 보겠습니다. 상품 데이터는 CDC를 통해 파이프라인으로 끊임없이 들어오고 있습니다. 따라서 무턱대고 상품 테이블에서 추출하면 최신 CDC 변경분이 아직 테이블에 반영(commit)되지 않아 과거 데이터를 추출해 버리면서 치명적인 정합성 문제가 발생할 수 있습니다.
이를 방지하기 위해 저희는 ‘현재 상품 테이블에 몇 시 몇 분(예: 13:03)까지의 CDC 데이터가 모두 반영되었다’는 상태 정보를 Kafka 메시지로 전송해서 데이터 추출 가능 여부를 판단하는 기준으로 설정했습니다. 추출 파이프라인은 이 메시지를 확인해 상품 테이블의 반영 시점이 추출 기준 시간 이전이라면 아직 변경 사항이 다 들어오지 않았다고 판단해 대기합니다. 이후 기준 시간 이후까지 모두 반영됐다는 메시지를 확인하면 비로소 안전하게 추출 작업을 수행합니다.
이 판단 로직이 완벽하게 작동하려면 Kafka 메시지에 담긴 시간까지의 데이터가 Iceberg 테이블에 '단 한 건의 누락도 없이 완벽하게 반영되었다'고 100% 신뢰할 수 있어야 합니다.
만약 Iceberg에는 데이터가 정상적으로 쓰였지만 네트워크 오류로 Kafka 메시지 전송에는 실패하거나, 반대로 Kafka 메시지는 전송됐는데 Iceberg에는 반영되지 못한 '부분 성공(partial success)' 상태가 발생한다면 어떻게 될까요? 추출 파이프라인이 실제 테이블 상태와 어긋난 정보를 기반으로 작동하면서 치명적인 데이터 누락으로 이어질 것입니다.
이와 같은 분산 환경에 발생할 수 있는 정합성 문제를 원천적으로 해결하기 위해 반드시 필요한 기술 스펙이 바로 2단계 커밋(two-phase commit, 이하 2PC) 기반의 종단 간 정확히 한 번 처리 방식입니다.
- 2PC: '전부 아니�면 전무(all or nothing)' 보장
- 2PC는 두 개 이상의 독립적인 시스템에 데이터를 반영할 때 이를 두 단계로 나눠 처리합니다. 1단계(prepare)에서는 Iceberg와 Kafka 양쪽 모두 반영 준비를 완료했는지 확인하고, 모두 준비됐을 때에만 2단계(commit)로 넘어가 동시에 확정합니다. 만약 둘 중 하나라도 준비에 실패하면 전체 작업을 롤백합니다. 이를 통해 '부분 성공' 상태가 발생하는 것을 원천 차단할 수 있습니다.
- 정확히 한 번 처리(exactly-once): 중복과 유실 원천 차단
- 스트리밍 처리 중에는 네트워크 지연이나 노드 장애로 파이프라인이 재시작되는 일이 빈번합니다. 이때 동일한 데이터가 중복 반영되거나, 일부 데이터가 유실될 수 있습니다. 정확히 한 번 처리Exactly-Once는 이러한 예외 상황에서도 데이터와 상태 메시지가 '정확히 한 번만' 처리됨을 보장합니다.
그렇다면, 이 두 스펙이 적용된 파이프라인은 어떻게 달라질까요?
2PC와 정확히 한 번 처리 방식을 함께 적용하면, Iceberg 테이블에 데이터가 누락 없이 완벽하게 커밋된 바로 그 순간에만 단 한 번, Kafka로 상태 메시지가 발행됩니다. 둘 중 하나만 성공하는 일은 결코 발생하지 않습니다. 이를 통해 Kafka 메시지는 단순한 알림을 넘어 Iceberg 테이블의 상태를 100% 대변하는 보증수표가 됩니다. 추출 파이프라인이 이 메시지만 믿고 작업을 수행해도 정합성이 어긋나지 않는 것입니다. 저희는 이런 방식으로 강력하게 데이터 무결성을 보장해 줄 수 있는 스트리밍 엔진이 필요했습니다.
3. 장애 허용 및 상태 관리
앞선 두 가지 스펙(데이터 최신성 판별, 종단 간 정확히 한 번 처리)을 구현하려면 스트림 처리 엔진 내부�에서 이전 데이터의 정보를 '상태값(state)'으로 유지해야 합니다. 예기치 않은 시스템 장애가 발생하거나 시스템이 재시작하더라도 이 상태를 유실하지 않고 안전하게 백업하고 복구할 수 있는 기능이 필요했습니다.
결론: Apache Flink 도입
널리 쓰이는 Spark Streaming(Structured Streaming)은 마이크로 배치(micro-batch) 방식으로 작동합니다. 데이터를 짧은 시간 동안 모아 한 번씩 처리하는 이 방식은, 이벤트가 발생한 시각(event-time)을 기준으로 상태를 세밀하게 제어하기 어렵다는 구조적인 한계가 있습니다. 이 한계 때문에 앞서 정의한 세 가지 요구 사항 중 특히 데이터 최신성 판별과 정확히 한 번 처리 보장을 동시에 만족하기 어려웠습니다.
반면 Apache Flink는 이벤트 하나하나를 발생 즉시 처리하는 네이티브 스트리밍(native streaming) 엔진이며, 이 특성은 위 세 가지 요구 사항을 모두 충족할 수 있는 토대가 됩니다.
1. 데이터 최신성 보장 → 스테이트풀(stateful) 처리
Flink의 DataStream API는 이벤트를 처리하는 과정에서 특정 값을 상태(state)로 유지할 수 있습니다. 저희는 Kafka 메시지 내의 updatedate 필드를 상태로 관리해 뒤늦게 도착한 이벤트의 updatedate가 현재 상태로 유지하고 있는 값보다 과거인 경우 해당 이벤트를 무시하도록 구현했습니다. 이를 통해 컨슈머 랙이 발생해 과거 보정 데이터가 뒤늦게 도착하더라도 최신 데이터를 덮어쓰는 문제를 방지할 수 있습니다.
2. 종단 간 정확히 한 번 처리 보장 → 체크포인트와 2PC 연동
Flink의 체크포인트(Checkpoints)는 파이프라인 내부의 모든 상태 스냅숏을 주기적으로 외부 저장소에 저장하는 메커니즘입니다. 장애 발생 후 재시작하더라도 마지막 체크포인트 시점으로 정확히 복구하기 때문에 중복 처리나 유실이 발생하지 않습니다.
여기서 중요한 것은 Flink의 Kafka Sink가 이 체크포인트와 연동해 2PC를 구현한다는 점입니다. 체크포인트가 완료되기 전까지는 Kafka로 메시지 전송하는 작업을 프리 커밋(pre-commit) 상태로 유지하다가 Iceberg 쓰기와 체크포인트가 모두 성공한 시점에 비로소 최종 커밋합 니다. 둘 중 하나라도 실패하면 전체를 롤백합니다. 앞서 요구 사항에서 설명한 ‘부분 성공 상태 원천 차단’을 엔진 수준에서 보장하는 것입니다.
3. 장애 허용 및 상태 관리 → 체크포인트의 내결함성
체크포인트는 정확히 한 번 처리를 보장하는 데에만 쓰이는 것이 아닙니다. 데이터 최신성을 판별하기 위해 DataStream에서 유지하는 updatedate 상태 역시 체크포인트를 통해 안전하게 백업됩니다. 상태는 예기치 않은 장애로 파이프라인이 재시작되더라도 유실되지 않습니다. 파이프라인은 정확히 중단 시점부터 이어서 작동합니다.
위와 같은 이유로 저희는 Flink를 도입했습니다. Flink가 Spark 대비 운영 복잡도가 높고 러닝 커브가 있다는 점도 사실입니다. 그럼에도 세 가지 요구 사항을 모두 엔진 수준에서 충족할 수 있는 선택지는 Flink가 유일했기에 Flink를 선택했습니다.
네이티브 쿠버네티스 vs. Flink 쿠버네티스 오퍼레이터
요구 사항을 만족하는 최적의 엔진으로 Flink를 선택한 후 다음 과제는 ‘이 클러스터를 어떻게 안정적으로 배포하고 운영할 것인가’였습니다. Flink는 다양한 배포(deployment) 방법을 제공합니다. 여러 대의 VM에서 직접 실행해 클러스터를 구성하는 방법부터 쿠버네티스에서 손쉽게 운영할 수 있도록 Helm 차트로 배포해 구성하는 방법까지 제공합니다.
저희 팀은 이미 모든 서비스를 쿠버네티스에서 운영하고 있었기 때문에 자연스럽게 쿠버네티스 기반의 여러 운영 방식을 검토했고, 그중 대표적인 두 가지 방식인 네이티브 쿠버네티스와 Flink 쿠버네티스 오퍼레이터를 비교해 봤습니다.
네이티브 쿠버네티스 방식
쿠버네티스의 기본 리소스를 직접 활용하는 방식입니다. 이 방식은 역할(role)과 서비스 어카운트(ServiceAccount)를 만들어 권한을 설정하고, 서비스를 추가해 트래픽 라우팅을 구성해야 합니다. 또한, 쿠버네티스 디플로이먼트(deployment)를 통해 Flink를 배포하고 사전에 정의한 슬롯에 맞춰 Flink 잡을 구동하는 등의 모든 설정 작업을 수동으로 해야 하는 번거로움이 있습니다.
Flink 쿠버네티스 오퍼레이터 방식
반면, 오퍼레이터 방식은 Flink 운영에 필요한 모든 요소가 커스텀 리소스로 추상화돼 있습니다. Helm 차트의 설정값(value)만 지정하면 라우팅과 웹 UI 구성 등을 자동으로 처리합니다.
Flink는 잡을 실행하는 방식으로 애플리케이션 모드와 세션 모드를 지원합니다. 애플리케이션 모드는 잡마다 클러스터를 별도로 생성해 격리 수준을 높이는 방식이고, 세션 모드는 하나의 클러스터에서 여러 잡을 실행해 리소스를 공유하는 방식입니다. 오퍼레이터에서는 각각 FlinkDeployment와 FlinkSessionJob이라는 CRD(CustomResourceDefinition)로 선언할 수 있어서 요구 사항에 따라 유연하게 선택할 수 있습니다.
또한 스케일 아웃도 편합니다. Flink는 실제 연산을 수행하는 프로세�스인 TaskManager를 파드 형태로 실행하는데요. 저희 팀은 TaskManager당 태스크 슬롯을 1로 설정해 운영하고 있어서 지정한 병렬성(parallelism)값만큼 TaskManager 파드가 1:1로 자동 생성됩니다. 덕분에 별도 인프라 조작 없이 선언적으로 처리량을 조절할 수 있습니다.
결론: Flink 쿠버네티스 오퍼레이터 도입
결과적으로 Flink 쿠버네티스 오퍼레이터가 네이티브 방식에 비해 설정 및 운영이 훨씬 수월했습니다. 무엇보다 GitOps 기반으로 운영할 수 있어서 현재 실행 중인 Flink 잡 상태와 Git에 정의된 설정 파일(manifest)이 완벽하게 일치(consistency)한다는 것을 보장할 수 있다는 점이 저희 팀의 운영 방향과 잘 맞아 도입하기로 결정했습니다.
스트리밍 ETL 구성
앞서 정의한 세 가지 핵심 요구 사항(데이터 최신성 보장, 종단 간 정확히 한 번 처리, 장애 허용 및 상태 관리)을 Flink가 모두 만족 구현 가능하다는 것을 확인하였고, 배포 방식 역시 팀 환경에 맞게 Flink 쿠버네티스 Operator를 채택하여 운영 편의성까지 확보했습니다.
이제 앞서 정의한 핵심 요구 사항을 Flink 아키텍처에서 어떻게 실제 로직으로 구현해 나갔는지 자세히 말씀드리겠습니다.
아키텍처 소개
스트리밍 ETL의 아키텍처는 다음과 같습니다.
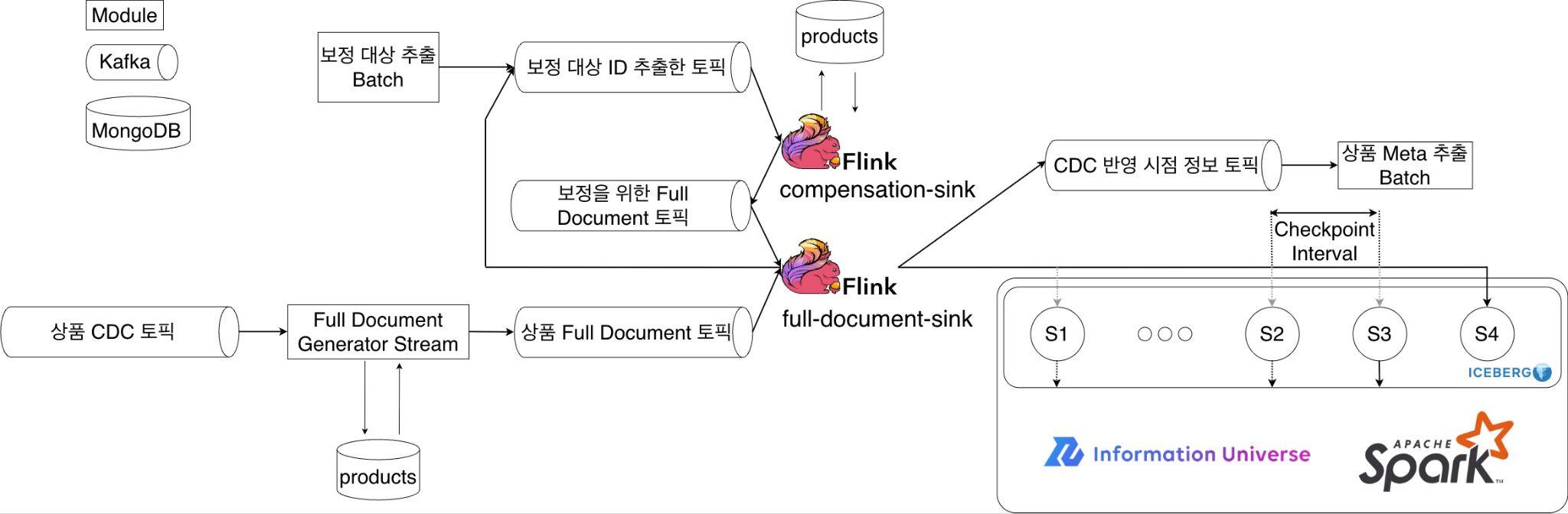
위 아키텍처는 두 가지 파이프라인으로 구성됩니다. 첫 번째는 보정 데이터 ��생성 파이프라인(compensation-sink)으로, 보정이 필요한 상품 ID를 받아 MongoDB에서 해당 상품의 도큐먼트 전체(fullDocument)를 조회한 뒤, CDC 파이프라인이 처리할 수 있는 형태로 변환해 전송합니다.
두 번째는 Iceberg 반영 파이프라인(full-document-sink)으로, MongoDB에서 발생하는 실시간 CDC 데이터와 보정 데이터 생성 파이프라인에서 전송된 데이터를 함께 수신하여 최신성을 보장하면서 Iceberg 테이블에 적재합니다.
그럼 두 파이프라인을 어떻게 구현했는지 핵심 구현 과정을 하나씩 살펴보겠습니다.
CDC와 보정 스트림을 함께 처리하는 파이프라인
저희는 데이터 최신성 문제를 해결하기 위해 첫 번째 파이프라인을 아래와 같이 CDC 데이터와 보정 데이터를 각각 별도의 Kafka 토픽으로 분리해 수신하는 구조로 설계했습니다.
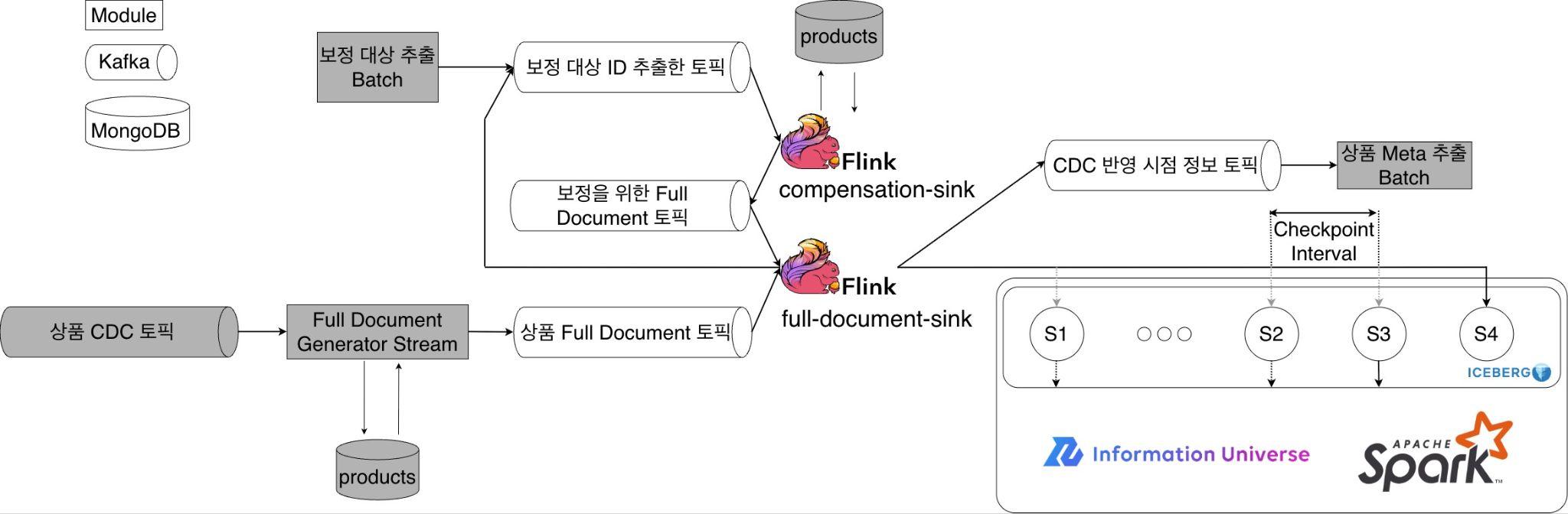
보정 데이터 생성 과정은 뒤에서 상세히 다루겠지만, Iceberg 테이블의 데이터가 최신 상태와 어긋났을 때 해당 상품의 fullDocument를 MongoDB에서 다시 조회해 보내는 데이터를 의미합니다. 파이프라인은 이 두 개의 토픽에서 메시지를 구독하는 것으로 시작하며, 유입된 데이터는 상품 ID를 키로 삼아 하나의 KeyedStream으로 모입니다. 이곳에서 데이터의 최신성을 엄격하게 보장하기 위해 다음과 같은 로직을 수행합니다.
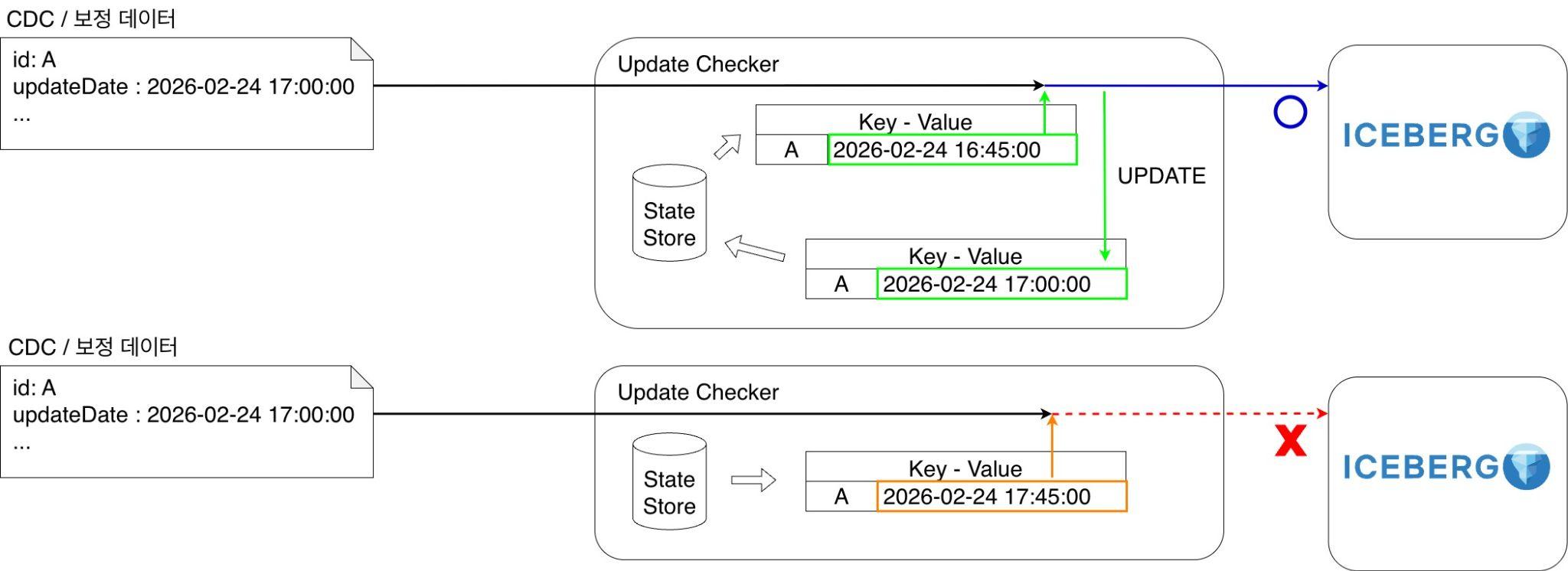
- 상태 저장: Flink의
KeyedStreamAPI 안에서 스테이트풀 오퍼레이터를 활용해 상품 ID별로 이전에 처리했던 데이터의updateDate를 상태값(state)으로 저장해 둡니다. - 과거 데이터 무시(drop): 현재 스트림으로 들어온 메시지의
updateDate와 상태에 저장된 최신 정보를 비교합니다. 만약 유입된 데이터가 더 오래된 데이터라면 해당 메시지는 무시하고 상태를 갱신하지 않습니다. - 최신 데이터 통과 및 갱신: 2번과 다르게 들어온 메시지가 상태 정보와 동일하거나 최신 데이터라면 파이프라인의 다음 단계로 통과시키고, 상태를 현재 메시지의 정보로 갱신합니다.
이 방식을 통해 컨슈머 랙 등의 이유로 과거 보정 데이터가 최신 CDC 데이터보다 늦게 도착하더라도 과거 정보가 최신 정보를 덮어써 버리는 위험을 원천 차단합니다. 이 스테이트풀 파이프라인을 무사히 통과한 '가장 최신' 데이터만 Iceberg 테이블에 병합(merge)합니다. 이 방식이 바로 앞서 저희가 Flink를 선택한 핵심 이유였던 ‘데이터 최신성 보장’을 완벽히 충족하는 구현 방식입니다.
보정 데이터 생성 파이프라인
다음은 보정 데이터를 생성하는 파이프라인을 살펴보겠습니다.
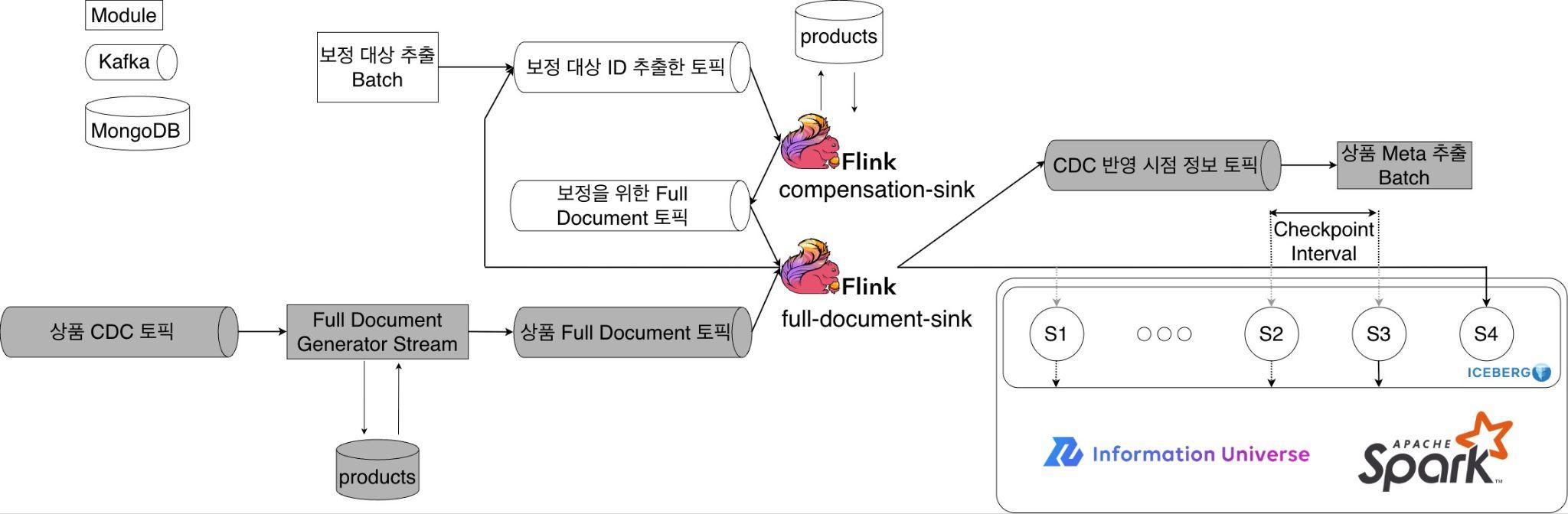
Iceberg 반영 파이프라인에는 실시간 CDC 데이터 외에 보정(compensation) 데이터도 함께 유입됩니��다. 보정 데이터는 어떤 이유로든 Iceberg 테이블의 데이터가 최신 상태와 어긋났을 때 해당 상품의 최신 fullDocument를 MongoDB에서 다시 조회해 Iceberg에 반영하는 것이 목적입니다.
보정이 필요한 상품 ID는 크게 네 가지 경로로 발생합니다.
- CDC 파이프라인에서 특정 상품 ID를 처음 처리하는 상황인데
opType이UPDATE인 경우- Flink 재기동 등으로 상태가 초기화된 상태에서는 과거 데이터가 최신 데이터를 덮어쓸 위험이 있어 해당 ID를 보정 대상으로 처리합니다.
- 이미 처리한 적 있는 ID인데
opType이CREATE로 다시 들어오는 경우- 논리적으로 모순된 상황이므로 현실에서는 거의 발생하지 않지만 방어 로직 차원에서 보정 대상에 포함시켰습니다.
- 하루 한 번 수행하는 정합성 검증에서 불일치가 감지된 경우
- 운영자가 필요에 따라 직접 대상 ID를 전송하는 경우
위 네 가지 경로 모두 보정이 필요한 상품 ID를 ‘보정 대상 ID 토픽’에 전송합니다. 보정 데이터 생성 파이프라인은 이 토픽을 구독해 해당 ID를 MongoDB에서 조회한 뒤 opType=READ 형태의 fullDocument 메시지를 생성해 ‘보정용 fullDocument 토픽’으로 전송합니다. 이렇게 생성된 메시지는 Iceberg 반영 파이프라인으로 합류해 CDC 데이터와 동일한 방식으로 처리됩니다.
윈도 연산을 활용한 보정 데이터 생성 파이프라인 최적화
앞서 Iceberg 반영 파이프라인에서 최신 데이터의 정합성을 확보하는 방법을 살펴봤다면, 이번에는 별도 Flink 잡으로 구성된 보정 데이터 생성 파이프라인에서 대량의 보정 요청을 효율적으로 처리하기 위해 다음과 같��은 순서로 윈도(window) 연산을 최적화한 과정을 소개합니다.
- 성능 병목을 해결하기 위한 키 기반 윈도(keyed window)
- 키 분산을 최적화해 병렬 처리 극대화
- MongoDB 부하를 방지하기 위한 커스텀 트리거 구현
1. 성능 병목 해결을 위한 키 기반 윈도(keyed window) 채택
보정 모듈은 데이터 순서를 엄격히 보장할 필요가 없었으므로 초기에는 키를 사용하지 않는 윈도(non-keyed window) 방식을 사용했습니다. 하지만 처리량이 늘어날수록 이 방식이 단일 태스크(single task)로 작동해 성능을 심각하게 저하시켰습니다. 이를 해결하고 Flink의 분산 처리 능력을 극대화하기 위해 키를 기준으로 데이터를 분산해 병렬 처리가 가능한 키 기반 윈도 방식으로 구조를 전환했습니다.
2. 키 분산을 최적화해 통한 병렬 처리 극대화
키 기반 윈도로 구조를 변경했음에도 처음에는 기대만큼 처리 속도가 올라가지 않았습니다. 원인은 KeyedStream의 데이터 분산 방식에 있었습니다.
KeyedStream은 KeyGroupStreamPartitioner를 통해 들어온 메시지의 키를 해시 함수(MurmurHash3)로 변환해 키 그룹 ID를 계산하고, 이 ID를 기반으로 메시지를 처리할 오퍼레이터 인덱스를 결정합니다.
문제는 KeyedStream의 윈도도 키별로 생성되는데 만약 키가 고르지 않게 분산될 경우 특정 오퍼레이터(태스크 슬롯)에 부하가 집중돼 병렬 처리의 이점을 얻지 못하고 성능이 저하되는 것이었습니다.
이를 해결하기 위해서는 KeyedStream에 주입하는 키값 자체가 오퍼레이터 인덱스에 최대한 고르게 분산되도록 조정해야 했습니다. 저희는 상품 ID를 병렬화(parallelism)값으로 모듈러 연산한 뒤 임의의 수를 곱한 결과를 키로 사용해 특정 오퍼레이터 인덱스에 부하가 집중되는 문제를 해소했습니다. 이를 통해 키 기반 윈도를 사용한 병렬 처리 효율을 극대화할 수 있었습니다.
3. MongoDB에 과부하가 걸리는 것을 방지하기 위한 커스텀 트리거 구현
키 분산을 최적화해 처리량이 비약적으로 늘어나자 이번에는 외부 데이터베이스 쪽에 문제가 발생했습니다. 윈도 함수가 5초 동안 수집한 수만 건의 메시지를 한 번에 조회하도록 MongoDB에 요청하면서 심각한 과부하를 준 것입니다.
이를 방지하려면 윈도 내 처리량(count)을 제한해야 했지만 Flink의 기본 윈도에는 개수를 기준으로 작동을 제어하는 기능이 없었습니다. 이에 저희는 데이터가 쌓이는 시점이나 시간을 기준으로 윈도를 다음 스트림으로 방출할지(fire) 결정하는 커스텀 트리거(CountWithTimeoutTrigger)를 직접 구현했습니다.
- 시간 제한: 처리 시간 기준으로 5초 경과
- 개수 제한: 윈도 내 데이터 개수가 1,000개 초과
위 두 조건 중 하나에 해당하면 다음 스트림으로 방출하도록 만든 커스텀 트리거 덕분에 데이터가 적을 때에도 무한정 대기하지 않으며 데이터가 폭증할 때는 MongoDB에 과부하를 주지 않도록 안정적인 단위로 배치 처리할 수 있게 되었습니다.
트러블슈팅
Flink라는 낯선 프레임워크를 사용할 뿐 아니라 Iceberg라는 새로운 테이블 형식을 사용하다 보니 이중으로 어려움을 겪었습니다. 저희가 겪었던 여러 문제 중 기억에 남는 몇 가지 사례와 해결 과정을 소개하겠습니다.
위임 토큰 프레임워크 인증
처음에 로컬에서 Flink를 테스트하며 Iceberg 테이블을 업데이트하기 위해 권한을 설정하는 과정에서 겪었던 문제입니다.
보안을 설정한 HDFS 환경에서 Flink 애플리케이션이 접근하기 위해서는 Kerberos 인증이 필수입니다. 처음에는 애플리케이션 코드 내에서 직접 인증(kinit 등)을 시도했으나 분산 환경인 Flink 특성상 다수의 TaskManager가 각각 인증을 시도하면 사내 인증 시스템(KDC(key distribution center))에 불필요한 부하를 유발할 수 있었습니다.
이에 저희는 인증을 수행하는 주체를 JobManager로 일원화하고 생성된 토큰을 공유하는 '위임 토큰 프레임워크(delegation token framework)'를 도입하기로 결정했습니다. 이는 JobManager가 대표로 Kerberos 인증을 한 번 수행한 뒤 발급받은 위임 토큰(delegation token)을 각 TaskManager에 배포해 개별 인증 없이 보안 자원에 접근할 수 있게 하는 메커니즘입니다.
이 프레임워크를 적용하는 과정에서 예상치 못한 두 가지 기술적 난관을 만났는데요. 이를 해결한 과정을 공유하겠습니다.
HadoopSecurity 모듈 누락과 의존성 경량화
가장 먼저 발생한 문제는 JobManager가 HadoopSecurity 모듈을 찾지 못해 인증 자체를 시작하지 못하는 현상이었습니다. Flink 이미지에 Hadoop 에코시스템 전체를 설치하거나 수많은 JAR 파일을 일일이 추가할 수도 있었지만, 이는 Docker 이미지 크기를 키우고 유지 보수를 어렵게 만듭니다.
이에 저희는 관련 의존성을 하나로 묶은 flink-shaded-hadoop-3-uber 라이브러리를 추가하는 방법을 선택했습니다. 이때 최신 버전 사용 시 CLI 관련 클래스 충돌(NoSuchMethodError)이 발생했는데요. 여러 버전을 테스트한 끝에 충돌 없이 작동하는 특정 버전(3.1.1.7.2.8.0-224-9.0)을 찾아 적용했습니다. 이를 통해 Flink 이미지 크기를 유지하면서 HadoopSecurity 모듈을 무사히 로드할 수 있었습니다.
Kafka Kerberos 인증 간섭 방지
의존성 문제를 해결하고 HDFS 연동을 마친 후 예상치 못한 부작용이 발생했습니다. 위임 토큰 프레임워크를 활성화하니 파이프라인에 연결된 Kafka Sink에도 의도치 않게 Kerberos 인증을 시도하는 것이었습니다. 저희 환경의 Kafka는 Kerberos를 사용하지 않으므로 이를 명확히 차단해야 했습니다.
관련 설정을 파악한 결과 특정 서비스에 대한 토큰 프로바이더만 선택적으로 비활성화할 수 있는 옵션이 있었습니다. 이에 security.delegation.token.provider.kafka.enabled: false 설정을 추가해 이 문제를 깔끔하게 해결했습니다.
위 과정을 거쳐 어떠한 수동 개입이나 인증 서버 과부하 우려 없이 Flink 클러스터에서 Kerberos를 가장 안정적으로 사용할 수 있는 환경을 구축할 수 있었습니다.
중복 적재 발생 및 읽기 성능 저하 문제
9억 건에 달하는 상품 테이블을 Flink CDC를 통해 Iceberg 테이블로 실시간 업데이트하며 정상 작동 여부를 테스트했는데요. 초당 약 1만 건의 CDC 데이터를 처리한 지 1시간 만에 데이터 읽기 성능이 급격히 저하되고 동일한 ID를 가진 행(row)이 중복 적재되는 현상이 발생했습니다.
원인을 분석해 본 결과 Iceberg와 Flink의 특정 식별자 설정을 누락한 것이 문제였습니다. Iceberg는 일반적인 데이터베이스의 기본키(프라이머리 키)와 유사한 역할을 하는 identifier-field-ids 설정을 통해 동일한 엔티티를 식별합니다. Flink 역시 이와 연동되는 equalityFieldColumn이라는 설정을 제공합니다. 이 두 가지 설정을 명시하지 않아 다음과 같은 두 가지 문제가 연쇄적으로 발생했습니다.
데이터 유일성(uniqueness) 보장 실패
Iceberg 테이블에 identifier-field-ids가 정의돼 있지 않으면, 레코드의 모든 칼럼 값이 완벽히 일치해야만 동일한 행으로 판단합니다. 이에 따라 데이터가 변경돼 Upsert(Delete 후 Insert) 연산을 수행할 때 기존 행을 식별해 삭제하지 못하고 삭제되지 않은 기존 레코드 위에 새로운 행을 중첩 적재하는 결과를 초래했습니다.
급격한 읽기 성능 저하
Iceberg는 데이터 쓰기 및 업데이트 방식으로 CoW(copy-on-write)와 MoR(merge-on-read) 두 가지를 지원합니다.
- CoW는 데이터가 변경될 때 아예 새로운 데이터 파일을 작성해 읽기 성능을 최적화하는 방식입니다.
- MoR은 변경된 내역(추가/삭제)만 별도 파일에 빠르게 기록해 두고, 데이터를 읽는 시점에 원본 파일과 변경 내역을 병합해 보여주는 방식입니다.
실시간 스트리밍 환경인 Flink에서는 쓰기 지연을 최소화하기 위해 MoR 방식만 지원하고 있습니다.
또한 Iceberg는 데이터를 삭제할 때 두 가지 방식을 사용합니다. 위치 삭제(position-delete)는 데이터 파일 경로와 파일 내 행 위치(offset)로 삭제 대상을 정확히 특정하므로 읽기 시 부담이 적습니다. 반면 동등 삭제(equality-delete)는 식별자 칼럼값을 기준으로 삭제 대상을 찾는 방식이므로, 식별자가 정의되지 않으면 모든 칼럼 값을 삭제 파일에 기록해야 합니다. Flink Iceberg Sink는 기동 후 한 번이라도 처리한 적이 있어 기존 데이터 파일 내 위치를 알고 있는 행 업데이트는 위치 �삭제 파일로, 위치를 알 수 없는 행 업데이트는 동등 삭제 파일로 기록합니다.
여기서 문제는 앞서 언급한 식별자 칼럼(identifier-field-ids, equalityFieldColumn)을 정의하지 않았다는 점이었습니다. 식별자가 없으니 처음 유입된 데이터를 동등 삭제 파일에 기록할 때 모든 칼럼값을 작성하게 됐는데요. 테스트 극초기에는 문제가 드러나지 않았지만 CDC로 처리한 데이터가 누적될수록 동등 삭제 파일의 크기가 기하급수적으로 팽창하고 있었습니다.
결국 읽을 때마다 원본과 변경 내역을 병합해야 하는 MoR 방식의 특성 때문에 데이터를 조회할 때 이 거대해진 삭제 파일들을 매번 병합해야 했고, 이에 따라 많은 부하가 발생해 읽기 성능이 심각하게 저하됐습니다.
아래는 동등 삭제 파일을 통해 행을 삭제하는 작업을 간략히 도식화한 그림입니다. identifier-field-ids와 equalityFieldColumn을 정의하면 동등 삭제 파일에 작성되는 내용이 어떻게 달라지는지 확인할 수 있습니다.
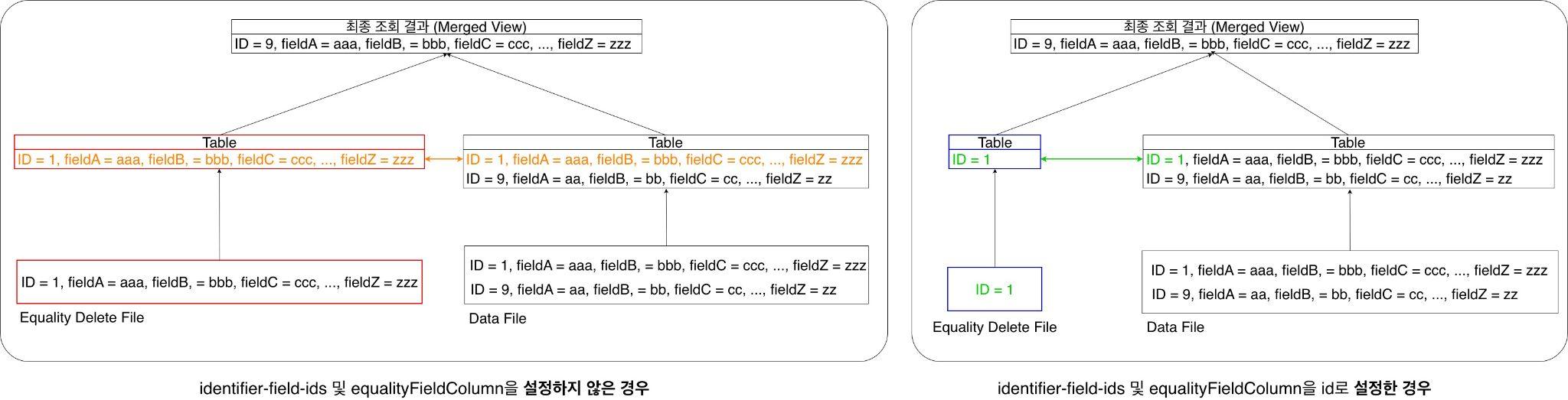
위와 같이identifier-field-ids와 equalityFieldColumn를 정의하는 것으로 읽기 성능을 어느 정도 끌어올릴 수 있었으나 아직 충분하지 않았습니다. 이에 저희는 추가 조치를 취했습니다.
데이터 파일 최적화
Iceberg 테이블은 데이터 수정 시 기존 데이터를 직접 수정하지 않고 삭제 파일과 새 데이터 파일을 생성하는 불변(immutable) 특성이 있습니다. 이 특성 때문에 Flink의 Upsert 연산으로 실시간 반영을 진행하다 보면 변경 파일이 누적되는데요. 쿼리 엔진은 최신 상태를 보여주기 위해 런타임에 이를 병합하는 MoR 방식을 수행하므로 필연적으로 읽기 성능이 저하됩니다.
이를 해결하기 위해 Iceberg가 제공하는 rewrite_data_files 프로시저(optimization)를 주기적으로 실행해 파일들을 정리해야 합니다. 1억 건 내외의 카탈로그 테이블에서는 문제가 없었으나, 9억 건 이상의 운영 상품 테이블에서는 이 rewrite_data_files 프로시저가 심각하게 지연되거나 OOM(out of memory)가 발생해 실패하는 현상을 겪었습니다. 이 문제를 해결하기 위해 시도했던 최적화 과정은 다음과 같습니다.
1. Spark 메모리 할당 전략 수정(오프힙 메모리 활용)
처음에는 익스큐터의 메모리가 부족하다고 판단해 병렬 처리를 위한 코어 수를 줄이고 Spark 온힙(on-heap) 메모리(spark.executor.memory)를 늘려봤지만 그래도 여전히 메모리 압박이 심했습니다. 살펴본 결과 원인은 압축 방식에 있었습니다.
저희는 Iceberg 테이블의 압축 코덱으로 ZSTD를 선택했습니다. ZSTD는 데이터를 읽는 과정에서 압축 해제를 Java 영역이 아닌 JNI를 통해 C/C++ 레벨에서 수행합니다. 또한 복사 과정을 생략하는 제로 카피(zero-copy) 전략을 취하기 때문에 GC(garbage collector)가 관리하는 온힙이 아닌 오프힙(off-heap) 영역을 주로 사용합니다. 따라서 온힙에 치우쳐 있던 메모리를 재분배해 spark.executor.memoryOverhead값을 크게 늘려 오프힙 메모리를 넉넉하게 확보함으로써 OOM 문제를 완화할 수 있었습니다.
2. CPU 기아(starvation) 현상 방지와 타임아웃 연장
메모리 문제를 해결한 뒤 Heartbeat Timeout이라는 복병을 만났습니다. 수억 건의 데이터를 압축 해제하는 작업은 엄청나게 많은 CPU 연산이 필요합니다. 압축 해제 단일 태스크가 거대한 파일 그룹을 처리하느라 CPU를 100% 점유해 버리면 Spark 익스큐터가 주기적으로 드라이버에게 생존 신호(heartbeat)를 전송하기 위한 스레드조차 실행 기회를 얻지 못합니다. 이 때문에 네트워크에 문제가 없는데도 노드가 비정상 종료(terminated)될 수 있는데요. 이를 방지하고자 spark.network.timeout 값을 기본 120초에서 대폭 늘려 애플리케이션 레벨에서 강제 종료되는 것을 막았습니다.
3. HDFS I/O 부하를 방지하기위한 압축 타깃 기준 완화
초기에는 최상의 읽기 성능을 유지하기 위해 파일이 조금만 쌓여도 즉시 병합하도록 min-input-files, delete-file-threshold 등을 공격적으로 설정했습니다. 하지만 이로 인해 대규모 테이블에서 발생하는 잦은 병합 작업은 HDFS의 NameNode와 DataNode에 과도하게 I/O 부하를 일으키는 원인이 되었습니다. 수많은 태스크가 동시에 메타데이터와 파일 입출력을 요청하며 클러스터 전체 성능을 저하시켰는데요. 이를 해결하기 위해 해당 파라미터들의 최소 기준치를 상향 조정해 압축이 불필요하게 자주 발생하며 HDFS 전체에 과부하를 주지 않도록 타협점을 찾았습니다.
이와 같은 최적화 작업으로 지연을 상당히 줄일 수 있었지만 아직도 피크 시간대에는 HDFS I/O가 한계에 도달하는 물리적 병목 지점이 남아있었습니다. 9억 건이라는 거대한 단일 데이터를 매번 전체 스캔해 병합 대상을 찾는 구조적 한계를 극복하기 위해 저희는 ID 기반 파티셔닝을 도입해 아키텍처를 개선했습니다.
최종 아키텍처 개선 - ID 기반 파티셔닝 도입
앞서 언급한 HDFS I/O 병목과 과부하 문제를 근본적으로 해결하기 위해 저희는 마지막으로 단일 테이블 구조에서 파티션 테이블 구조로 전환하는 아키텍처 개선을 단행했습니다. 파티셔닝은 Iceberg에서 제공하는 bucket 함수를 활용해 상품 ID값을 기준으로 진행했습니다. bucket(N, column)은 지정된 칼럼값을 해시해 N개의 버킷으로 균등 분배하는 히든 파티셔닝 전략으로, 상품 ID처럼 카디널리티(cardinality)가 높고 균등하게 분포하는 칼럼에 적합합니다.
Iceberg에서 MoR 방식을 사용할 때, 비파티션 테이블 환경에서는 동등 삭제(equality delete) 파일이 글로벌 삭제로 적용됩니다. 이는 해당 작업을 파티션 범위로 한정할 수 없어 테이블 내 모든 데이터 파일에 대해 삭제 조건 매칭을 수행해야 한다는 의미입니다. Iceberg는 각 커밋에 증가하는 일련 번호를 부여해 삭제 파일의 적용 범위를 결정합니다. 따라서 업데이트가 누적될수록 해당 삭제 파일의 일련 번호 이전에 생성된 모든 데이터 파일에 대해 삭제 조건 매칭을 수행해야 하므로 읽기 비용이 급증합니다. 하지만 ID를 기준으로 파티셔닝을 적용하자 데이터를 조회하거나 병합할 때 읽어야 하는 데이터 파일과 삭제 파일의 범위가 해당 파티션 내로 대폭 축소되었습니다.
그 결과 가장 큰 골칫거리였던 rewrite_data_files 프로시저를 HDFS 부하 없이 안정적으로 수행할 수 있게 되었고, 조회 대상 데이터에 대한 읽기 성능 또한 지연 없이 안정적으로 유지할 수 있었습니다.
데이터 반영 속도 12배 향상에 실질적인 비밀
이 글의 제목이기도 한 '12배 속도 향상'은 기존에 1시간(60분) 주기로 돌던 데이터 반영 작업을 5분으로 �단축하면서 얻어낸 결과입니다. Flink를 도입해 체크포인트 생성 주기를 5분으로 설정했고, 체크포인트가 성공적으로 완료되는 시점에 메타데이터를 Iceberg 테이블에 커밋해 데이터가 즉각 반영되게 구성했습니다.
어쩌면 이 성과가 단순히 스트리밍 처리 엔진인 Flink를 적용했기 때문이라고 생각하실 수도 있습니다. 하지만 진정한 '12배 향상의 비밀'은 주기를 줄인 것 그 자체보다 '짧은 주기로 데이터를 계속 밀어 넣어도 시스템이 무너지지 않는 환경'을 구축했다는 데 있습니다.
아무리 데이터를 빠르게 반영하더라도 정합성이 깨지거나 읽기 지연이 발생한다면 실제 서비스 환경에서는 결코 사용할 수 없습니다. 5분이라는 촘촘한 간격으로 커밋이 발생해 파일들이 생성되는 열악한 상황에서도 데이터 정합성을 완벽하게 유지하고 읽기 성능에 전혀 문제가 없다는 것을 파티션 아키텍처와 치열한 트러블슈팅을 통해 완벽히 검증해냈기에 비로소 달성할 수 있었던 수치입니다.
마치며
Hbase 스냅숏과 Hive를 사용한 ETL의 한계를 마주하며 시작된 고민이 Iceberg와 Flink 도입으로 이어졌고, OOM 타임아웃, HDFS 부하 등 수많은 한계를 극복하며 마침내 안정적이고 빠른 파티션 아키텍처를 완성할 수 있었습니다. 이제 통합 커머스에서는 수시로 발생하는 상품 업데이트를 훨씬 더 실시간에 가깝게 처리할 수 있게 되었고, 과거 데이터 지연 때문에 발생하던 비즈니스 위험도 크게 낮출 수 있었습니다.
대규모 상품 데이터를 다루며 '실시간'과 '데이터 정합성'이라는 두 마리 토끼 사이에서 고민하고 계실 많은 데이터/서버 엔지니어분들에게, 저희 팀의 이번 Iceberg 도입 여정이 조금이나마 도움이 되기를 바라며 이만 마치겠습니다. 긴 글 읽어주셔서 감사합니다.


