들어가며
안��녕하세요. LINE Plus에서 Global E-Commerce Platform 개발을 맡고 있는 서종현입니다. 저희 팀은 작년에 주문 DB를 Oracle에서 MySQL로 이관하라는 미션을 받아서 성공적으로 완료했습니다. DB를 이관하면서 DB 모델도 변경해 읽기와 쓰기 양쪽 성능을 모두 향상시켰는데요. 이번 글에서는 그 과정을 공유드리고자 합니다.
이 글은 Spring MVC와 JPA를 알고 있다는 가정 하에 작성했습니다.
DB 이관 전 DB 모델 재정의
저희는 DB를 이관하기 전에 MySQL에서 사용할 DB 모델을 재정의했습니다. DB 이관과 함께 DB 모델을 변경한 이유는, 기존에 Oracle에서 사용하던 모델로는 조회 성능이 잘 나오지 않았기 때문입니다. 기존 모델로는 주문 데이터를 확인하기 위해 총 17개의 테이블을 조인해야 했습니다. 이로 인해 DB와 애플리케이션 서버 인스턴스 모두에 부하가 발생해, 하나의 주문에서 100개 정도의 상품을 구매한 경우 해당 주문을 조회하는 데 최대 5초 이상 소요됐습니다. 이 문제를 MySQL에도 가져갈 수는 없다고 판단해 DB 모델을 재정의했습니다.
신규 DB 모델을 정의할 때의 주 관심사는 '어떻게 하면 조인을 줄일 수 있을지'였습니다. 팀 내 논의 결과 조인을 줄일 수 있는 방법으로 두 가지 안이 나왔습니다. 첫 번째는 일부 테이블을 JSON 문자열로 저장해 역정규화하는 안이고, 두 번째는 정규화 테이블과 비정규화 테이블 두 쌍을 운용하는 안입니다.
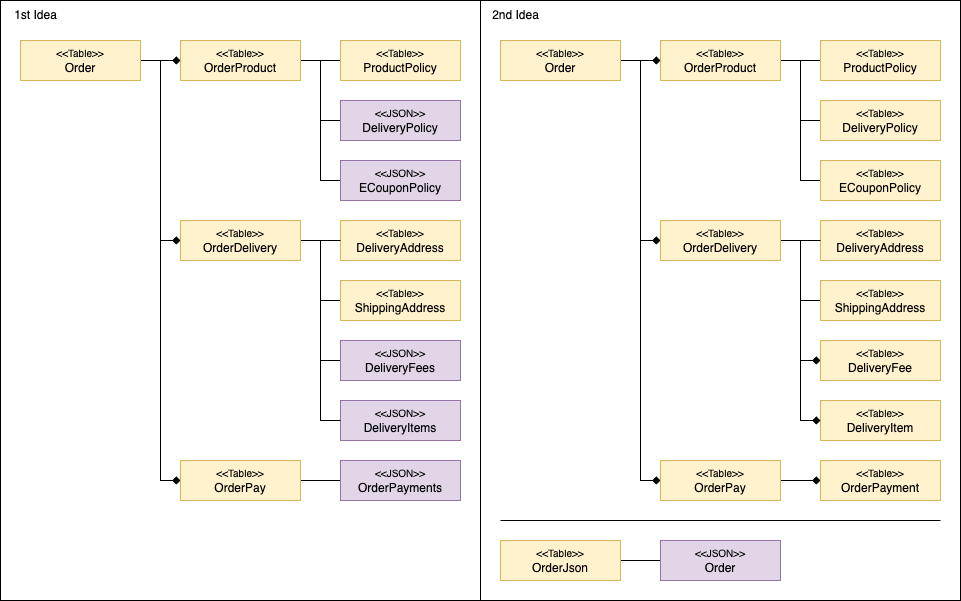
첫 번째 안은, 저희 테이블 간 관계에 One-to-Many 관계가 많았기 때문에 컬럼으로는 역정규화할 수 없어서 JSON Object 혹은 JSON Array로 역정규화하자는 아이디어에서 나온 안입니다. 이 안의 경우 JPA를 사용하고 있기 때문에 코드 작성에는 큰 어려움이 없지만, JSON 문자열로 저장한 필드로 검색해야 할 경우 테이블 구조를 다시 변경해야 할 수 있다는 위험이 있습니다.
두 번째 안은 첫 번째 안의 문제점을 해결하기 위해 검색용 모델과 조회용 모델을 분리해서 운용하자는 아이디어에서 나온 안입니다. 이 안의 경우 두 개의 모델을 관리하기 때문에 작성해야 하는 코드의 양과 DB에 저장되는 데이터의 양이 증가한다는 문제가 있지만, 검색이 유연하고 첫 번째 안보다 조회 성능이 뛰어나다는 장점이 있습니다.
성능 테스트 결과, 두 번째 안을 선택했습니다. 첫 번째 안이 두 번째 안에 비해 읽기와 쓰기 성능 모두 떨어지는 것을 확인했기 때문입니다. 첫 번째 안의 읽기 성능이 떨어지는 것은 이해할 수 있었지만 쓰기 성능이 떨어지는 것은 이해할 수 없었습니다. 성능을 테스트할 때 JPA의 Batch Insert를 사용했다고 하더라도 데이터가 더 많은 두 번째 안이 더 느릴 것으로 생각했기 때문입니다. 이에 Pinpoint 등을 이용해 원인을 분석했고, JPA의 변경 감지와 Jackson의 특성 때문인 것을 확인했습니다. 다음은 저희가 얻은 Pinpoint의 타임라인 그래프를 간소화한 그림입니다.
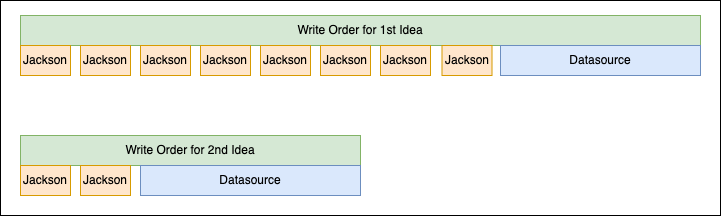
위 그림에서 먼저 주목해야 할 부분은 Jackson의 호출 횟수입니다. 첫 번째 안에서 사용하는 모델이 Jackson을 여러 번 호출하는 구조이긴 하지만, 예상보다 너무 많이 �호출해습니다. 이렇게 호출 횟수가 많았던 이유는 JPA가 AttributeConverter를 사용하고 있는 엔티티를 저장할 때 변경을 감지하기 위해 항상 직렬화와 역직렬화를 호출하기 때문이었습니다. 이로 인해 첫 번째 안에서 예상보다 두 배 더 많이 Jackson을 호출했고, 저장 성능에 영향을 끼쳤습니다.
두 번째로 주목해야 할 부분은 각 Jackson 호출 시의 소요 시간입니다. 저희는 직렬화하는 객체의 복잡도에 따라서 Jackson 성능에 영향이 있을 것으로 생각했지만, 실제로 첫 번째 안과 두 번째 안의 Jackson 호출 성능에는 거의 차이가 없었습니다. 이에 따라 큰 객체를 작은 객체로 나눠 여러 번 직렬화하는 첫 번째 안보다 큰 객체로 한 번만 직렬화하는 두 번째 안이 더 좋은 성능을 보여줬습니다.
이와 같이 Jackson 호출 횟수 및 수행 시간의 영향으로 두 번째 안이 첫 번째 안보다 좋은 성능을 보여줬기에, 정규화 테이블과 비정규화 테이블 두 쌍을 운용하는 두 번째 안을 선택했습니다.
퍼시스턴스 레이어 개발
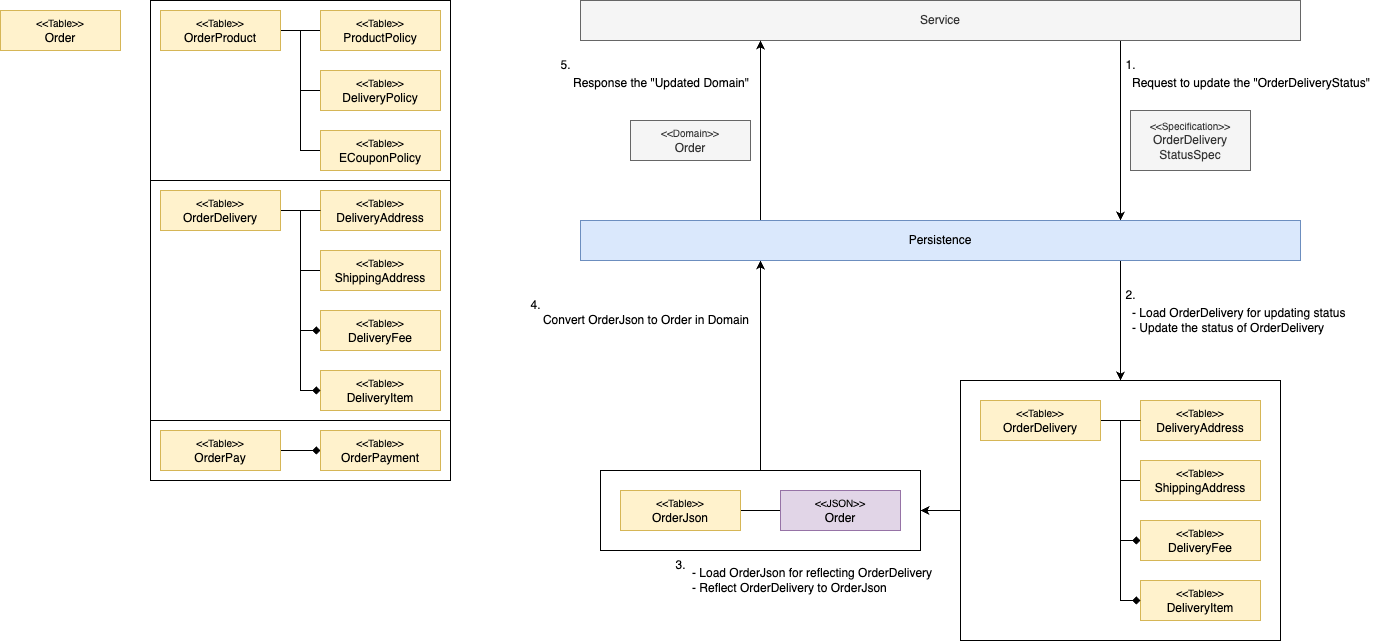
테이블 운용 방법을 결정한 뒤 어떻게 퍼시스턴스(persistence) 레이어를 개발할지 고민했습니다. 정규화 테이블과 비정규화 테이블을 이용한 개발은 크게 두 가지 문제가 있습니다. 첫 번째는 저희가 사용하고 있는 JPA는 데이터를 업데이트하려면 먼저 데이터를 읽어와야 한다는 것입니다. 이로 인해 정규화 테이블에 대량의 조인이 발생합니다. 두 번째는 개발자의 실수로 정규화 테이블과 비정규화 테이블 간의 일관성이 깨질 수 있다는 것입니다. 만약 깨진다면 잘못을 바로잡기 위해 DB 전체를 마이그레이션할 필요가 발생할 수 있습니다.
이 두 가지 문제를 해결하기 위해 세 가지 방책을 강구했�습니다.
첫 번째는 서비스 레이어가 퍼시스턴스 레이어에 요청을 보낼 때 도메인 객체가 아닌 별도의 명세 객체를 만드는 것입니다. 서비스 레이어가 퍼시스턴스 레이어에 도메인 객체 저장을 요청할 수 있게 될 경우, 이 요청을 퍼시스턴스 레이어에서 구현하기 위해서는 정규화된 테이블 전체에 대한 변경 감지가 필요합니다. 이는 정규화 테이블 전체를 읽어와야 한다는 문제로 연결됩니다. 이에 저희는 두 레이어 간 통신에 명세 객체를 사용하도록 설계했습니다. 명세 객체는 업데이트에 필요한 정보만 갖고 있어서 퍼시스턴스 레이어가 정규화된 테이블 전체에 대해 변경 감지를 할 필요가 없습니다.
두 번째는 정규화 테이블에 대응하는 JPA 엔티티의 연관 관계를 데이터가 변경되는 단위로 쪼개서 애그리게이션(aggregation)을 만들어, 부분적으로 데이터를 읽어오고 업데이트할 수 있도록 만든 것입니다. JPA를 사용할 때 가장 위험한 부분은 레이지 로딩(lazy loading)으로 N+1 쿼리가 발생하는 것이라 생각합니다. 이 위험을 원천적으로 봉쇄하기 위해 JPA 엔티티 간 연관 관계를 최소화하기로 결정했고, 데이터가 변경되는 단위를 기준으로 애그리게이션을 만들어 항상 페치 조인(fetch join)으로 데이터를 읽어와 데이터 업데이트 시 전체 정규화 테이블을 조회하지 않고 부분만 조회하게 설계했습니다.
세 번째는 퍼시스턴스 레이어 안에서 명세의 반영은 정규화 테이블을 통해, 도메인 객체의 생성은 비정규화 테이블을 통해 진행하게 만든 것입니다. 퍼시스턴스 레이어는 명세를 받고 이 명세가 반영된 도메인 객체를 반환하는 인터페이스를 갖고 있습니다. 명세의 반영을 정규화 테이블을 통해서 하면 비정규화 테이블은 명세가 반영된 도메인 객체를 만들어야 하기 때문에 정규화 테이블의 상태를 어쩔 수 없기 계속 반영해야 합니다. 이와 같은 구조를 만들고 통합 테스트를 작성해 코드 머지 전 일관성이 깨지지 않았는지 검증하는 것으로 정규화 테이블과 비정규화 테이블 간의 일관성을 유지하도록 설계했습니다.
이 세 가지 방책을 통해 대량의 조인이 발생할 위험을 없앴고, 정규화 테이블의 스키마와 비정규화 테이블의 스키마 간에 일관성을 유지했습니다.
ID 채번
DB 모델도 정의하고 퍼시스턴스 레이어의 개발 방향도 결정했으니 드디어 개발을 시작할 수 있겠다고 생각했지만, 아직 해결하지 못한 커다란 문제가 하나 남아 있었습니다. MySQL의 Auto Increment(AI)는 ID를 생성하는 정말 좋은 방법이지만, JPA를 이용한 Batch Insert와는 호환되지 않는다는 것입니다. 원인은 JPA는 영속성 컨텍스트에 객체를 보관할 때 ID가 필요해서 ID를 얻기 위해 객체 하나당 삽입 쿼리가 하나씩 전송되기 때문입니다. 이 문제를 해결하기 위해 채번 테이블도 고려했지만 원했던 것만큼 성능이 나오지 않았고, 대신 ID 채번 방식으로 Snowflake 방식을 채용하기로 결정했습니다.
Snowflake 방식은 여러 서버 인스턴스에서 각자 ID를 생성하는 방식으로, 특정 시간에 특정 인스턴스가 생성한 시퀀스로 ID의 유일함을 보장합니다. 일반적으로는 타임스탬프 41bit와 서버 인스턴스 번호(InstanceId) 10bit, 시퀀스 12bit를 합쳐서 63bit에 1bit를 더해 4byte로 표현합니다. 하지만 저희는 하위 호환성 문��제로 이 패턴을 적용할 수 없었습니다. 이에 자체 패턴을 만들었는데요. 자체 패턴에 따른 ID는 다음 그림과 같이 파티셔닝을 위한 날짜 8자와 서버 인스턴스 번호 3자, 시퀀스 7자를 더해 총 18자의 숫자로 구성됩니다.
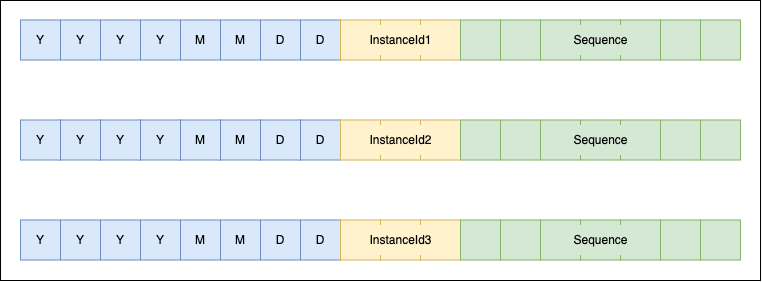
Snowflake 방식에서 가장 고민되는 요소는 서버 인스턴스 번호를 얻는 부분이라고 생각합니다. 저희는 MySQL을 이용해 각 서버 인스턴스가 경쟁해서 서버 인스턴스 번호를 선점하는 방향을 선택했습니다. 서버 인스턴스가 부팅될 때 MySQL을 통해 서버 인스턴스 번호가 저장된 테이블에 테이블 레벨 락을 걸어 동시성을 해소하고, 선점한 시간을 남겨 다음 날 다른 서버 인스턴스가 다시 해당 서버 인스턴스 번호를 선점할 수 있게 구성했습니다. 또한 현재 날짜로 발행할 수 있는 시퀀스가 얼마 남지 않으면 새로운 서버 인스턴스 번호를 비동기적으로 얻어 오버플로에 대응했습니다.
| 서버 인스턴스 번호 | 호스트 이름 | 선점 시작 시각 | 선점 종료 시각 |
|---|---|---|---|
| 1 | api-64b48b6f87-cjr22 | 2023-05-31 09:23:18 | 2023-06-01 21:10:18 |
| 2 | api-6d6b56fd57-bmxdk | 2023-05-31 09:23:18 | 2023-06-01 21:10:18 |
| ... | ... | ... | ... |
| 999 | api-77ffbf76f5-f878z | 2023-05-31 09:23:18 | null |
이처럼 ID 하위 호환성을 유지하기 위해 자체 패턴을 만들고, MySQL을 활용해 서버 인스턴스 번호를 경쟁하는 것으로 추가 인프라 없이 Snowflake 방식의 ID 채번을 구현했습니다. 처음 구상할 때에는 오버 엔지니어링이지 않을까 걱정했는데요. 지금까지 쭉 사용해 보니, ID를 신규로 채번할지 여부를 결정할 때 성능에 대한 걱정이 사라져 비즈니스 요구 사항만 고려해서 의사결정을 할 수 있게 돼 만들기 잘했다고 생각합니다.
동시성 이슈
DB 관련 문제를 모두 해결하고 기쁜 마음으로 개발을 진행하던 중 베타 환경에서 간헐적으로 데이터 정합성이 안 맞는 문제가 발생했습니다. 총 두 개의 상품이 배송 준비가 완료됐다고 각각 콜백을 받아 그 상태를 DB에 반영했는데, 이 중 한 개의 상품만 배송 준비가 완료됐다고 저장된 것입니다. 더 특이한 점은 정규화 테이블에는 정상적으로 저장돼 있고 비정규화 테이블에만 잘못 저장돼 있었습니다.
로그를 분석한 결과, 주문(order) 전체를 JSON 문자열로 저장하면서 발생한 동시성 이슈였습니다. 저희의 주문 프로세스는 각 상품마다 독립적, 순차적으로 진행됩니다. 이때 정규화 테이블은 부분적으로 업데이트가 가능해서 다른 상품 데이터에 영향을 주는 일이 없었습니다. 하지만 주문 전체를 비정규화 테이블에 JSON 문자열로 저장할 때에는 새로운 문자열로 치환하기 때문에 동시에 저장되면 서로의 변경 사항을 인식하지 못하면서 한쪽 데이터를 잃어버렸습니다.

이는 NoSQL과 같은 비정형 데이터를 사용하는 곳에서는 익숙한 이슈이지만, 저희 팀은 이전까지 비정형 구조를 사용한 적이 없기에 처음 겪어보는 것이었습니다.
이 이슈를 해결하기 위해 Redis를 이용한 분산 락을 사용하기로 결정했습니다. 낙관적 락이 아니라 분산 락을 통한 비관적 락을 선택한 이유는, 분산 락은 이미 재고 차감 로직 등을 위한 구현체가 있었기에 이를 이용해 빠르게 개발할 수 있겠다고 생각했기 때문입니다. 하지만 분산 락을 적용하고나니 또 다른 문제가 발견됐습니다. 마이그레이션을 위해 사용한 코드 구조와 분산 락의 구현이 잘 어울리지 않았다는 것입니다.
저희는 마이그레이션을 위해 Oracle을 사용하는 서비스와 MySQL을 사용하는 서비스, 둘 사이를 조율하는 프록시 서비스까지 총 세 개의 서비스 클래스를 사용했습니다. 프록시 서비스가 있지만 API에 따라 Oracle 서비스와 MySQL 서비스를 직접 호출하는 경우도 있었습니다. 따라서 동시성을 제어하기 위해 세 곳 모두 AOP(Aspect Oriented Programming)를 이용해 분산 락을 걸었는데요. 분산 락 구현체가 재진입을 �허용하지 않아 프로세스가 실행되지 못했습니다. 이 문제를 해결하기 위해 Spring이 제공하는 Transactional과 동일한 인터페이스를 락에 적용해서 재진입을 허용하는 분산락을 구현했습니다(참고로 이 구현 내용도 나중에 블로그를 통해 공유해 보면 좋을 것 같습니다).
결국 간단할 것으로 생각하고 비관적 락을 적용했지만 재진입 이슈 때문에 새로운 분산 락 구현체를 만들어야 했기에 문제를 간단하게 해결하지는 못했는데요. 이렇게 재진입 가능한 락을 만들어 둔 덕에 추후 비슷한 문제가 발생한 다른 케이스에 쉽게 적용할 수 있었고, 결과적으로는 만들기 잘했다는 생각이 들었습니다.
배포
이 외에도 'Transaction marked as rollbackOnly' 이슈와 '마이그레이션 프로세스와 비즈니스 프로세스 간의 경합' 이슈, 'MySQL Timezone' 이슈 등 여러 이슈가 발생했지만 모두 잘 해결해서 QA 테스트를 통과하고 배포할 수 있게 됐습니다. 저희는 아래와 같이 총 다섯 가지 배포 단계를 거쳐 MySQL 전환을 완료했습니다.

첫 번째 단계는 신규 모델이 문제없는지 검증하기 위해 비동기로 MySQL에 데이터를 적재하고 검증하는 단계입니다. 쓰기와 수정 이벤트를 Kafka를 통해 발행해 비동기 방식으로 Oracle 데이터를 MySQL에 적재하는 마이그레이션을 수행합니다. 그리고 미리 작성된 코드와 쿼리를 이용해 데이터 정합성을 비교합니다.
두 번째 단계는 이중 쓰기(dual write) 단계입니다. 쓰기와 수정 모두 동기 방식으로 Oracle과 MySQL에 데이터를 적�재합니다. 이때 비동기 마이그레이션과 데이터 수정에서 충돌이 발생할 수 있어서 마이그레이션 프로세스와 비즈니스 프로세스는 동시에 실행되지 않도록 처리했습니다. 비즈니스가 마이그레이션 때문에 지연되면 안 되기 때문에 비즈니스 프로세스가 진행되면 마이그레이션 프로세스를 중단할 수 있도록 코드를 작성해서 비즈니스 프로세스가 지연되는 것을 최소화했습니다.
세 번째 단계는 MySQL로 읽기를 전환하는 단계입니다. 이전 단계를 거치며 MySQL에도 실시간으로 최신 데이터가 저장되기 때문에 이제는 MySQL를 이용해 데이터를 읽어도 괜찮습니다. 또한 이중 쓰기로 비동기 마이그레이션 로직은 불필요해졌기 때문에 제거합니다.
네 번째 단계는 수정에서 Oracle를 제거하는 것입니다. MySQL로 데이터를 읽더라도 바로 쓰기와 수정에서 Oracle를 제거할 수는 없습니다. 배포 호환성을 보장하기 위해서 입니다. 저희가 사용하는 배포 모델은 신규 형상과 구 형상이 한 번에 스위칭되지 않기 때문에 쓰기와 수정에서 Oracle이 제거된 형상을 배포하면 하나의 주문에 대해 쓰기는 신규 API를 통해 수행되고 수정은 구 API를 통해 수행되는 경우가 발생할 수 있습니다. 그럴 경우 구 API에서는 Oracle에 데이터가 없어서 에러가 발생합니다. 이런 케이스를 막기 위해 저희는 수정부터 Oracle를 제거했습니다.
마지막 단계는 쓰기에서도 Oracle를 제거하는 것입니다. 이로서 Oracle 의존성을 모두 제거하고 MySQL로만 운용할 수 있게 됐습니다.
되돌아보며
마지막으로 MySQL로 전환하면서 성능이 얼마나 향상됐는지 보여드리겠습니다. 다음 표는 실제 서비스 환경에서 전환 전후 성능을 측정해 평균을 낸 결과입니다.
참고로 아래 표의 'Oracle(평균)' 칼럼의 경우 약 90~100ms 정도 발생하는 한국과 일본 사이의 지연 시간(latency)이 포함돼 있습니다. 이는 저희가 Oracle을 MySQL 전환하게 된 계기이기도 한데요. 대략적인 지연 시간을 뺀 값이 'Oracle(평균, 지연 시간 제외)' 칼럼입니다. 아래 표를 보실 때 이 점을 감안해서 보시면 좋을 것 같습니다.
| API | Oracle(평균) | Oracle(평균, 지연 시간 제외) | MySQL(평균) |
|---|---|---|---|
| 단일 조회 | 158ms | 약 60ms | 4ms |
| 나의 주문 목록 | 255ms | 약 150ms | 51ms |
| 주문 검색 | 405ms | 약 300ms | 60ms |
| 주문 생성 | 2,476ms | 약 2,200ms | 1,424ms |
| 주문 수정 | 496ms | 약 400ms | 17ms |
단일 조회는 약 60ms에서 4ms로, 목록 조회는 약 150ms에서 50ms로 확 줄어들었습니다. MySQL로 전환하면서 모델을 변경한 효과입니다. 주문 생성도 약 2,300ms에서 1,420ms로 거의 800ms 가량 줄어들었습니다. 이는 모델을 변경한 효과도 있지만, 기존에 사용하던 Oracle 시퀀스에서 Snowflake로 전환한 효과가 크다고 생각합니다.
처음에는 엄청난 작업 분량에 정말 잘 전환할 수 있을까 많이 걱정했습니다. 이 걱정을 혼자서 끌어안고 고민했다면 아마 전환은 실패했을 것이라고 생각합니다. 이 걱정을 팀원들과 나누고 모두 같은 목표를 바라보며 한 팀으로 작업했기에 MySQL로 전환하는 작업을 성공적으로 마쳤다고 생각합니다. 또한 바쁜 일정 속에서도 코드를 좋은 구조로 만들기 위해 끊임없이 의논하고 서로를 독려하며 노력했기에 Snowflake나 분산 락을 MySQL 전환 당시에만 사용하는 것이 아니라 그 이후로도 여러 작업에 유용하게 사용할 수 있었다고 생각합니다.


