들어가며
현재 일본과 대만, 태국에서는 LINE 앱에서 LINE VOOM이라는 서비스를 제공하고 있습니다. LINE VOOM은 LINE 앱 사용자를 위한 SNS로 사진과 텍스트, 비디오 등의 포스트를 업로드할 수 있는 공간입니다.
VOOM RecSys Platform 팀에서는 수많은 포스트 중 사용자들이 관심을 가질 만한 포스트를 추천해 주기 위해 모델 학습 파이프라인부터 사용자 화면에 결과를 전달하는 API에 이르기까지 전체 시스템을 설계하고 구현해 운영하고 있는데요. 이전에는 저희 팀에서 포스트를 추천하기 위해 하루에 한 번씩 모델을 학습하며 그날 추천에 나갈 포스트 후보군들을 추리는 방식으로 진행했습니다. 그러나 이 방식은 전날 데이터를 기반으로 학습하고 추천하기 때문에 월드컵이나 올림픽 같은 실시간 이벤트나 그날 새로 올라온 뉴스를 반영하는 데에는 한계가 있었습니다. 이에 이런 한계를 극복하고 사용자에게 보다 더 최신 포스트를 추천할 수 있도록 2023년의 시작과 함께 실시간 추천 시스템을 구축하기 시작해 2023년 11월 말에 실제 서비스에 적용했습니다.
이를 위해 실시간으로 이벤트를 수신해 검수, 임베딩 생성 등의 작업을 처리하는 ‘Retriever’ 시스템을 구축했습니다. Retriever의 사전적 의미는 '리트리버(사냥 때 총으로 쏜 새를 찾아 오는 데 이용하는 큰 개)'인데요. 요청 받은 이벤트를 검색해서 가져오는 시스템의 기능을 고려해 이름을 지었습니다.
Retriever 소개
사용자가 게시물 생성/수정/삭제와 같은 액션을 실행할 때마다 Kafka의 특정 토픽에 액션에 대한 이벤트가 쌓입니다. Retriever는 이렇게 토픽에 쌓인 포스트 이벤트를 소비(consume)해서 추천해도 되는 포스트인지 확인�하기 위한 다양한 검수를 진행합니다. 또한, 검수를 통과한 포스트를 추천에 활용할 수 있도록 비디오 길이나 해시 같은 메타 데이터를 추출한 뒤 모델 학습 및 예측을 위한 임베딩을 생성하고 저장하는 등의 처리 작업을 수행합니다.
Retriever의 구조를 설계할 때 다음과 같이 5가지 주요 원칙을 세웠습니다.
- 확장성: 특정 시기(예: 1월 1일)에 게시물 생성이 급증하는 경우에도 쉽게 대응할 수 있어야 합니다.
- 유연성: 게시물이 추천 시스템에 포함되기까지 다양한 단계를 거쳐야 하는데 이 과정에 필요한 사항이 추가되거나 삭제될 때 빠르게 대응할 수 있어야 합니다.
- 안정성: 시스템의 한 부분에 문제가 발생해도 이 문제가 다른 부분으로 확산되지 않아야 합니다.
- 쉬운 운영: 게시물 처리 과정을 쉽게 추적할 수 있어야 하고, 필요할 경우 쉽게 재처리할 수 있어야 합니다.
- 성능: 작업을 병렬로 처리할 수 있어야 합니다.
위 원칙을 지키기 위해 큐잉(queueing) 시스템을 채택했습니다. 큐잉 시스템이 위 원칙을 지키기에 적합한 이유는 다음과 같습니다.
- 확장성: 큐잉 시스템은 작업을 큐에 보관하며 부하에 따라 소비자(consumer)의 수를 동적으로 조절해 확장성을 보장합니다.
- 유연성: 처리 과정을 변경해야 할 때, 큐잉 시스템은 파이프라인의 단계를 유연하게 수정하거나 추가, 제거할 수 있는 구조를 제공합니다.
- 안정성: 시스템의 한 부분에 장애가 발생하더라도 큐에 저장된 작업은 안전하게 보호되며, 장애가 해결된 후에도 작업을 계속 처리할 수 있습니다.
- 쉬운 운영: 큐에서 작업 상태를 쉽게 추적할 수 있으며, 처리 실패 시 재처리가 간편합니다. 작업 처리 완료 후 커�밋을 발행하는 방식으로 실패한 작업을 재처리할 수 있습니다.
- 성능: 큐 시스템은 병렬 처리를 용이하게 해 시스템 전체의 처리량을 높일 수 있습니다.
이런 이유로 Retriever의 전체 구조는 큐잉 시스템을 기반으로 구성했습니다.
초기 버전에서는 Go 언어의 채널을 메시지 큐의 역할과 유사하게 활용했습니다. 신속하게 개발해서 편리하게 사용할 수 있다는 장점 때문이었는데요. 사용하다 보니 다음과 같은 이유로 채널을 대신 할 메시지 큐 적용을 고려하게 됐습니다.
- 불안정성: Go 채널은 메모리를 기반으로 통신하기 때문에 프로그램 종료나 장애 발생 시 채널 내 메시지가 손실될 수 있습니다. 반면 Kafka나 일반적인 메시지 큐는 메시지를 디스크에 영구적으로 저장하기 때문에 시스템 장애가 발생해도 메시지를 보호할 수 있습니다.
- 확장성 제한: Go 채널은 프로그램 내에서만 작동하므로 시스템을 확장하거나 여러 인스턴스로 분산하는 데 제한이 있습니다. 반면 메시지 큐는 부하에 따라 유연하게 확장할 수 있는 기능을 제공합니다.
- 메시지 버퍼링 제한: Go 채널은 버퍼 크기가 고정돼 있어 버퍼가 가득 차면 메시지 전송이 블로킹될 수 있습니다. 대규모 시스템에서는 동적 메시지 버퍼링이 필요한데요. 이를 메시지 큐에서 제공하고 있습니다.
- 메시지 처리 보장 부재: Go 채널은 메시지 처리를 보장하는 내장 메커니즘이 없지만, 메시지 큐는 메시지가 안전하게 처리될 때까지 보관하는 등의 처리 보장 기능을 제공합니다.
- 모니터링 및 관리 도구 부재: Go 채널은 별다른 관리 도구를 제공하지 않아 대규모 시스템에서 운영 및 관리하기가 복잡합니다. 반면 Kafka나 메시지 큐의 경우 모니터�링과 경고, 로깅을 위한 풍부한 도구와 인터페이스를 제공합니다.
위와 같은 사항을 고려해 안정성과 확장성, 관리 용이성을 갖춘 메시지 큐로 전환하기로 결정했고, 여러 큐잉 시스템을 면밀히 검토한 후 Redis Streams를 새로운 큐잉 솔루션으로 선택했습니다. Redis Streams가 다른 메시지 큐와 비교해 어떤 장점이 있었는지 자세히 살펴보겠습니다.
메시지 큐로 Redis Streams를 선택한 이유
메시지 큐로 사용할 수 있는 기술 스택은 굉장히 다양합니다. 그 중 저희가 리트리버에 적합한 MQ를 선정할 때 고려한 조건은 다음과 같습니다.
- 쿠버네티스 환경의 여러 파드(pod)에서 브로드캐스트 방식이 아니라 중복 없이 처리 가능한가?
- 큐에 메시지가 발행됐을 때 해당 큐를 구독/소비하고 있는 소비자(파드)에게 모두 동일한 메시지가 전송(브로드캐스트)되느냐? 아니면 각 파드별로 서로 다른 메시지를 중복 없이 처리할 수 있는가?
- 처리 과정 중 실패한 메시지를 안전하게 재처리할 수 있는가?
- 사내 인프라를 활용할 수 있는가?
다음은 여러 기술을 대상으로 위 세 가지 조건을 만족하는지 조사한 표입니다.
| 중복 없이 동시 처리 가능 여부 | 재처리 가능 여부 | 사내 인프라 활용 및 인프라에 대한 유지 보수 위탁 가능 여부 | |
|---|---|---|---|
| RabbitMQ | O | O | X |
| ActiveMQ | O | O | X |
| Redis Lists | X | X | O |
| Redis Pub-Sub | X | X | O |
| Redis Streams | O | O | O |
이에 '관리 포인트를 최소화할 수 있는 방법은 없을까?'를 고민한 끝에 Redis를 선택했습니다. 저희 회사에서는 개발자들이 AWS와 같은 다양한 서비스를 보다 쉽게 사용할 수 있도록 Verda라는 사내 프라이빗 클라우드 플랫폼을 제공합니다. Verda에서 제공하는 서비스를 활용하면 서버 구축 및 관리에 대한 부담을 줄일 수 있는데요. Redis의 경우 간편하게 서버를 발급 받을 수 있고, Grafana를 이용한 모니터링 설정도 완비돼 있으며, Verda Redis 팀에게 기본적인 운영 관련 도움도 받을 수 있습니다. 여러모로 저희 팀에게는 최적의 선택이었습니다.
단, Redis는 RabbitMQ나 ActiveMQ에 비해 메시지 큐로 사용된 역사가 상대적으로 짧고 사용 사례도 적었습니다. 따라서 Retriever에서 필요한 기능을 Redis에서 잘 제공하고 있는지 확인할 필요가 있었습니다.
Redis를 활용해 메시지 큐를 ��구현하는 방법은 크게 세 가지로 Lists, Pub/Sub, Streams입니다.
먼저 Lists 자료형은 링크드 리스트(linked list)로 구현돼 있으며, LPUSH 명령어로 새로운 데이터를 추가하고 RPOP 명령어로 가장 오래된 데이터를 꺼내오는 FIFO 방식을 통해 메시지 큐로 활용할 수 있습니다. 다만, 서버 재시작 같은 상황에서 데이터 처리에 실패하면 큐에서 데이터를 다시 가져와 재처리하는 것이 불가능해 메시지 유실의 위험이 있습니다.
다음으로 Pub/Sub은 데이터를 저장하는 토픽(topic)이라는 개념과 함께, 메시지를 발행하는 발행자(publisher)와 해당 토픽을 구독해 메시지를 수신하는 구독자( (subscriber)로 구성됩니다. 이 방식 역시 메시지 수신을 보장하지 않아 유실의 위험이 있습니다. 또한 구독자들에게 메시지를 일괄적으로 발행하기 때문에 채팅이나 푸시 알림과 같은 용도로는 적합하지만 Retriever와 같이 메시지를 중복 없이 동시에 처리해야 하는 경우에는 부적합합니다.
마지막으로 Streams 자료형은 5.0 버전에서 새로 도입된 자료형으로, 추가 전용(append-only) 로그 방식으로 작동하며 메시지를 발행하는 생산자(producer)와 메시지를 소비하는 소비자(consumer)로 구성됩니다. 일견 Pub/Sub과 유사한데요. 중요한 차이점은 소비자들을 소비자 그룹으로 묶을 수 있다는 것입니다. 이렇게 같은 그룹으로 묶인 소비자들에게는 동일한 메시지를 일괄적으로 발행하는 것이 아니라 각각 다른 메시지를 순차적으로 전달함으로써 중복 없이 동시 처리가 가능하게 만듭니다. 또한 XACK 명령어를 사용해 메시지 처리 여부를 확인할 수 있고, 일정 기간 동안 ACK를 받지 못한 메시지는 다른 소비자가 재처리할 수 있습니다.
이와 같은 장점을 고려해 비록 상대적으로 사용 사례가 적지만 Retriever의 요구 사항을 모두 충족하는 Redis Streams를 메시지 큐로 선택했습니다.
Redis Streams 적용 후 발생한 문제
Retreiver에 Redis Streams를 적용한 버전을 성공적으로 배포했지만, 4일 만에 다시 Go 언어 기반의 Channel로 교체해야 했습니다. Redis Cluster의 한 노드에서 메모리 경고가 발생했기 때문입니다. 사전에 계산했던 바에 따르면 한 달 이상의 메시지를 보관할 수 있을 만큼 충분한 메모리를 갖추고 있었는데 일주일도 채 안 되는 기간에 60% 이상을 사용한 것입니다.
Retriever에 들어오는 데이터 하나의 크기는 약 10,388바이트로 하루 동안 하나의 Stream에 들어오는 데이터의 전체 크기는 대략 1.57GB입니다. Retriever에서 사용하는 Redis Cluster는 32GB 메모리를 가진 노드 6대로 구성돼 있으며, 이를 통해 사용할 수 있는 총 메모리는 192GB(32*6)의 절반인 96GB입니다. 단순 계산으로는 약 60일, 여유를 둬도 한 달 정도의 데이터는 모두 Stream에 유지해도 문제가 없다는 계산이 나오는데 무슨 이유로 4일 만에 메모리 경고가 발생한 것일까요?
이는 Redis Streams의 기능에만 초점을 맞춘 채 Redis Cluster의 기본적인 저장 및 작동 원리를 간과해서 벌어진 일이었습니다. Redis는 각 키(key)에 1:1로 대응하는 값(value)을 저장하며, 저장되는 값의 자료형은 Strings, Lists, Sets 등으로 다양합니다. Redis는 '하�나의 키는 반드시 하나의 노드에 저장한다'는 원칙을 따릅니다. Redis Cluster는 여러 대의 노드 및 샤드로 구성돼 있기 때문에 키를 저장할 샤드를 결정하는 샤딩(sharding) 기법이 필요합니다.
Redis가 키를 고르게 분산하기 위해 사용하는 샤딩 알고리즘은 다음과 같습니다.
HASH_SLOT = CRC16(key) mod 16384
Redis는 키를 저장하기 위해 총 16,384개의 해시 슬롯을 사용합니다. 이 16,384개의 슬롯에 키를 균등하게 분배하기 위해, CRC16 해시 함수를 사용해 각 키의 해시 값을 계산해서 16,384로 나눈 나머지를 이용해 각 키가 속할 해시 슬롯을 결정합니다. 이 16,384개의 해시 슬롯은 Redis 클러스터를 구성하는 여러 샤드에 할당됩니다. 예를 들어 클러스터를 세 개의 샤드로 구성한다면, 0번부터 5,460번 슬롯까지는 첫 번째 샤드에, 5,461번부터 10,922번 슬롯까지는 두 번째 샤드에, 10,923번부터 16,383번 슬롯까지는 세 번째 샤드에 할당됩니다.
Redis에서 Streams는 키-값 구조의 데이터 타입 중 하나입니다. 여기서 Stream 이름이 키 역할을 하고, Stream을 위한 데이터가 값으로 저장됩니다. 각 Stream은 하나의 해시 슬롯에 매핑되므로, Stream에 저장된 모든 데이터는 단일 샤드에 저장됩니다. 이는 Stream에 들어오는 데이터가 여러 샤드에 분산되지 않고 한 샤드에 집중돼 저장된다는 의미입니다. 따라서 실제로 하나의 Stream에 저장할 수 있는 데이터의 최대 양은 클러스터 전체의 용량이 아닌, 단일 샤드의 용량에 의해 제한됩니다. 예를 들어, 샤드의 최대 용량이 16GB라면, 하나의 Stream이 저장할 수 있는 데이터의 양도 16GB로 제한됩니다.
뿐만 아니라 하나의 키 크기가 커지는 것은 'Big Key Issue'(참고)라고 잘 알려진 위험한 상황을 초래할 수 있습니다. 읽기와 쓰기 작업에 바로 문제가 발생하지는 않을 수 있지만, 클러스터의 확장이나 축소 시 장애를 일으킬 수 있습니다. 또한 Redis는 싱글 스레드로 작동하기 때문에 큰 키를 처리하는 동안 다른 작업이 대기 상태에 놓이게 돼 Redis 서버가 일시적으로 다운될 수 있습니다. 이에 Verda Redis 팀에서는 각 키의 크기를 약 500KB 이하로 유지할 것을 권장하고, 1MB를 초과하는 키는 특별한 주의가 필요하다고 조언하고 있습니다.
위 문제를 해결하기 위해 처음에는 아래 두 가지 방법을 고려했습니다.
- 일정 주기마다 Stream을 새로 생성하기
- 미리 N개의 Stream을 만들어 사용하기
첫 번째 방법에서는, 아래 그림과 같이 매시간 새로운 이름(예: streamA:240225T10:00)으로 Stream을 생성해 사용함으로써 데이터가 전체 샤드에 균등하게 분배될 것으로 기대했습니다. 하지만 매시간 새로운 Stream이 생성된다면 읽어야 할 Stream 목록이 계속해서 변하게 되므로, 오차 없이 관리하기가 어려웠습니다. 예를 들어, ‘streamA:240225T10:00’이 존재할 때 한 시간 후 ‘streamA:240225T11:00’을 생성하고 이전 스트림과 교체하는 시스템을 상정해 보면, ‘streamA:240225T10:00’에 남은 데이터가 완전히 처리됐는지 확인하는 것이 중요합니다. 특히 1월 1일과 같이 트래픽이 집중되는 날에는 ‘streamA:240225T09:00’의 데이터를 한 시간 내에 처리하지 못할 가능성이 있으며, 이 경우 11시에 ‘streamA:240225T09:00’ 또는 그 이전의 Stream의 데이터 상태를 다시 확인해야 합니다.
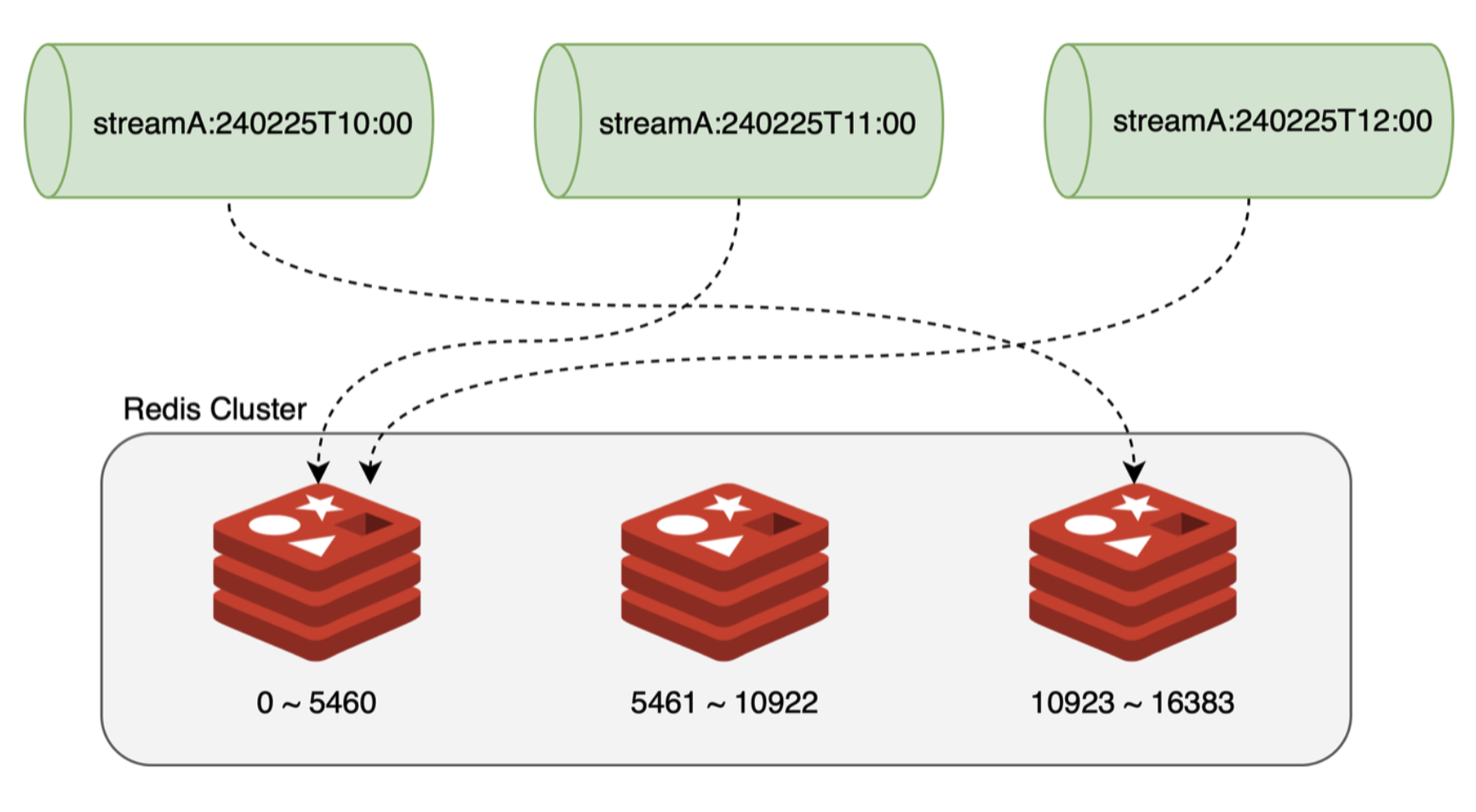
2번 방법의 경우 Stream의 이름이 동적으로 변경되는 것이 아니기 때문에 관리하기는 훨씬 수월할 것으로 판단했지만, 문제는 몇 개의 Stream을 생성했을 때 샤드에 균등하게 분배가 될 수 있는가를 계산하는 것이었습니다.
앞서 말씀드렸듯 일반적으로 16,384개의 해시 슬롯은 각 샤드에 연속적으로 할당됩니다. 따라서 Redis에서 키를 저장할 때 사용하는 해시 슬롯 결정 알고리즘을 활용한다면, 샤드의 수만큼 Stream을 생성하는 것만으로도 충분히 균등하게 분배할 수 있습니다.
그러나 Verda에서 제공하는 Redis의 경우에는 16,384개의 해시 슬롯이 샤드에 무작위로 분배돼 있다는 점에서 상황이 달랐습니다. 예를 들어 아래와 같이 0번, 5번, 7번, 29번 슬롯이 첫 번째 샤드에 할당되고, 3번, 4번, 30번 슬롯이 두 번째 샤드에 할당되는 식으로 슬롯이 연속적으로 할당돼지 않았으며 할당된 샤드 자체도 변동될 수 있었습니다.
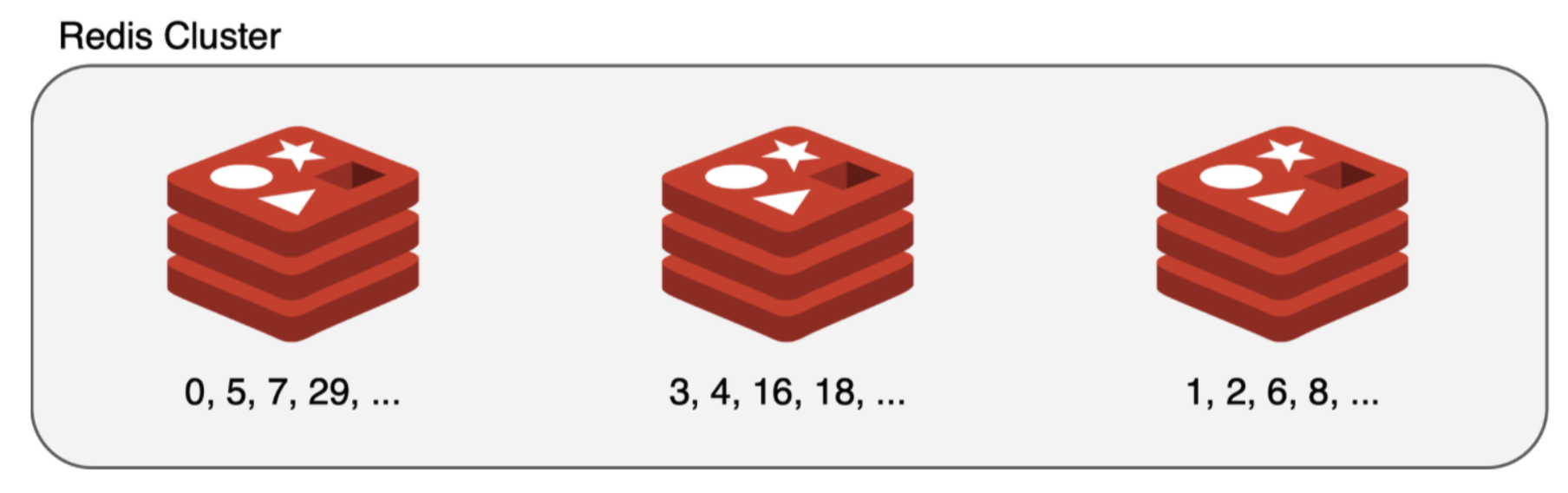
따라서 해시 슬롯을 결정하는 알고리즘을 사용해 특정 샤드에 일관되게 매핑되는 키를 생성하는 것은 사실상 불가능했습니다.
그렇다면 최소한 각 샤드에 하나 이상의 Stream이 분배되기 위해서는 어떻게 해야 할까요? 이 문제를 해결하기 위해 '쿠폰 수집가 문제(Coupon Collector's Problem)'로 알려진 알고리즘을 적용해 보기로 했습니다.
해결 방안 - 쿠폰 수집가의 문��제
몇 년 전 캐릭터 스티커가 동봉된 빵이 큰 인기를 끌었었죠. 저도 좋아하는 캐릭터의 스티커를 얻기 위해 여러 번 빵을 구매했던 기억이 납니다. 당시 스티커는 총 275 종류의 캐릭터로 구성돼 있었는데요. 여기서 수집가라면 당연히 다음과 같은 의문을 품게 됩니다. 모든 종류의 캐릭터 스티커를 모으려면 과연 몇 개의 빵을 사야 할까요? 만약 운이 정말 좋다면 275 개의 빵만 사도 모든 스티커를 모을 수 있겠지만, 그 확률은 극히 낮습니다. 그렇다면 모든 캐릭터 스티커는 동일한 숫자로 배포되고 있으며, 빵을 구매할 때 어떤 스티커가 들어있을지 기대할 수 있는 확률은 275종류 모두 동일하다고 가정할 때, 평균적으로 모든 스티커를 모으기 위해 필요한 빵의 개수는 몇 개일까요?
이 질문에 대한 답은 쿠폰 수집가의 문제(coupon collector's problem)에서 찾을 수 있습니다. 쿠폰 수집가의 문제는 확률론과 통계학에서 다루는 유명한 문제로 다음과 같이 요약할 수 있습니다.
"어떤 제품을 구매할 때마다 다양한 종류의 쿠폰 중 하나를 무작위로 받는다고 할 때, 모든 종류의 쿠폰을 적어도 한 번씩 받으려면 평균적으로 얼마나 많은 제품을 구매해야 하는가?"
캐릭터 스티커 수집에 쿠폰 수집가의 문제 적용하기
쿠폰 수집가의 문제는 캐릭터 스티커를 수집하는 상황에도 적용할 수 있습니다. 수집가는 모든 종류의 스티커를 모으고자 합니다. 그러나 스티커는 무작위로 제공되므로 어떤 스티커는 반복해서 받을 수 있고, 어떤 스티커는 빵을 몇 개를 구입해도 하나도 받지 못할 수도 있습니다.
수학적으로 쿠폰 수집가의 문제는, n 종류의 쿠폰이 �있을 때 모든 종류의 쿠폰을 적어도 한 번씩 얻기 위해 필요한 평균 시도 횟수를 계산하는 것입니다. 평균 시도 횟수는 다음과 같이 계산됩니다.
여기서 H_n은 n 번째 조화수(harmonic number)이며, 이라는 것은 잘 알려진 사실입니다. 따라서 n 개의 쿠폰을 모두 모으기 위해서 필요한 제품 개수의 기대값은 으로 근사할 수 있습니다.
즉, 275개의 캐릭터 스티커를 모두 얻으려면 대략 개의 빵을 사야 합니다. 이는 약 1,544.612이며, 즉 평균적으로 약 1,545개의 빵을 구입하면 275종류의 캐릭터 스티커를 모두 받을 수 있습니다.
위 수식은 평균적으로, 즉 1,545개의 빵을 구입하면 50%의 확률로 모든 종류의 캐릭터 스티커를 받을 수 있다는 것인데요. 만약 모든 쿠폰을 수집할 확률을 높이고 싶다면 어떻게 해야 할까요? 이에 대해서는 다음과 같은 근사 공식이 제시돼 있습니다(주제와 벗어난 내용이기에 이 글에서 이 공식 자체를 깊이 다루지는 않겠습니다.).
샤드 분배 문제와 쿠폰 수집가 문제의 유사성
앞서 언급한 샤드 분배 문제는 쿠폰 수집가 문제의 변형으로 볼 수 있습니다. 이 관계를 다음과 같이 설명할 수 있습니다.
- 쿠폰: 샤드
- 수집해야 할 쿠폰의 종류: 샤드의 개수(여기서는 6개)
- 제품 구매: 키 할당
위 관계를 이용해 샤드 분배 문제를 다시 정의하면 아래와 같습니다.
"모든 샤드에 적어도 하나의 키가 배정되기 위해 필요한 평균적인 Stream 키의 개수는 얼마인가?"
6개의 샤드가 있다고 할 때, 각 샤드에 적어도 한 번씩 키를 배정받기 위해 필요한 평균 키의 개수는 6 * ln(6)으로 계산되며, 이는 평균적으로 약 10.75개의 키가 필요하다는 것을 의미합니다. 여기서 저희는 모든 샤드에 키가 95% 이상의 확률로 배정되기를 원했기 때문에, 위 근사 공식을 사용해 아래와 같이 계산한 결과 약 17.34개가 필요하다는 것을 알 수 있었습니다.
이 계산에 따라 실제로 18개의 키를 생성해 보니, 키들이 샤드에 균등하게 배분되는 것을 확인할 수 있었습니다.
적용 후 얻은 운영 노하우 소개
마지막으로, 저희 팀이 Redis Streams을 보다 원활하게 운영하기 위해 적용한 몇 가지 노하우를 공유하고자 합니다.
Redis Streams 온/오프 스위치 개발
Redis Streams를 실제 환경에 처음 도입할 때 베타 환경에서 충분한 테스트를 거쳤더라도 예상치 못한 문제가 발생할 수 있기 때문에 이에 어떻게 대응할지 준비해 놓는 것이 중요했습니다. 이를 위해 Redis Streams 사용 여부를 배포 없이 온/오프할 수 있도록, Central Dogma 환경을 이용해 제어할 수 있는 스위치 기능을 구현해 뒀습니다. 이 기능 덕분에 초기 Redis Streams 도입 시 로직에서 버그를 발견하거나 메모리 경고를 받았을 때 즉시 Redis Streams를 비활성화하고 Go 언어 채널로 원활하게 전환할 수 있어서 문제에 대응하는 데 큰 도움이 됐습니다.
모니터링 API 개발
팀원들이 Redis Streams를 쉽게 모니터링할 수 있도록 전용 API를 개발했습니다. Redis Streams는 구체적으로 모니터링하려면 직접 명령어를 사용해야 하는 번거로움이 있었는데요. 이를 해결하기 위해 현재 저장된 메시지 수와 각 Stream이 사용하는 메모리 양 등을 확인할 수 있는 API를 구축해 운영에 활용했습니다.
마치며
이번 글에서는 VOOM 서비스의 추천 시스템을 배치에서 실시간으로 전환하는 과정에서 큐잉 시스템이 필요해, Go 언어의 채널에서 Redis Streams로 전환하는 과정을 공유해��보았습니다. Redis Streams는 상대적으로 레퍼런스가 부족해 도입 과정에서 많은 어려움을 겪었는데요. 이 글이 저희와 비슷한 어려움을 겪고 계신 분들께 조금이나마 도움이 되길 바랍니다.
마지막으로 이 자리를 빌려 Retriever의 여정을 함께 해 주신 모든 팀원들에게 감사 인사를 전합니다. 긴 글 읽어주셔서 감사합니다.


