LINEヤフーの技術カンファレンス「Tech-Verse 2026」の公式記事です。
こんにちは。AIエージェントで分析を「ひとつなぎ」にするプロジェクト「PJ One Piece」のプロダクトマネージャーの橋本とプロダクトオーナーの岡田です。
PJ One Pieceは、生成AIを活用して、事業の問いからデータ分析、示唆の整理、次のアクション検討までをつなぐ分析AIエージェントの取り組みです。先行展開では、従来は依頼から結果が返るまで平均で約2週間かかっていた分析が、約10分で実行できるようになり、事業部内では月数百回規模の分析が行われるようになりました。
この記事では、生成AIを使って、事業とデータ、分析プロセス、ドメイン間の分断をどのように「ひとつなぎ」にしようとしているのか、そしてその中でデータサイエンティストの役割がどのように変わりつつあるのかをご紹介します。
背景にあった3つの分断
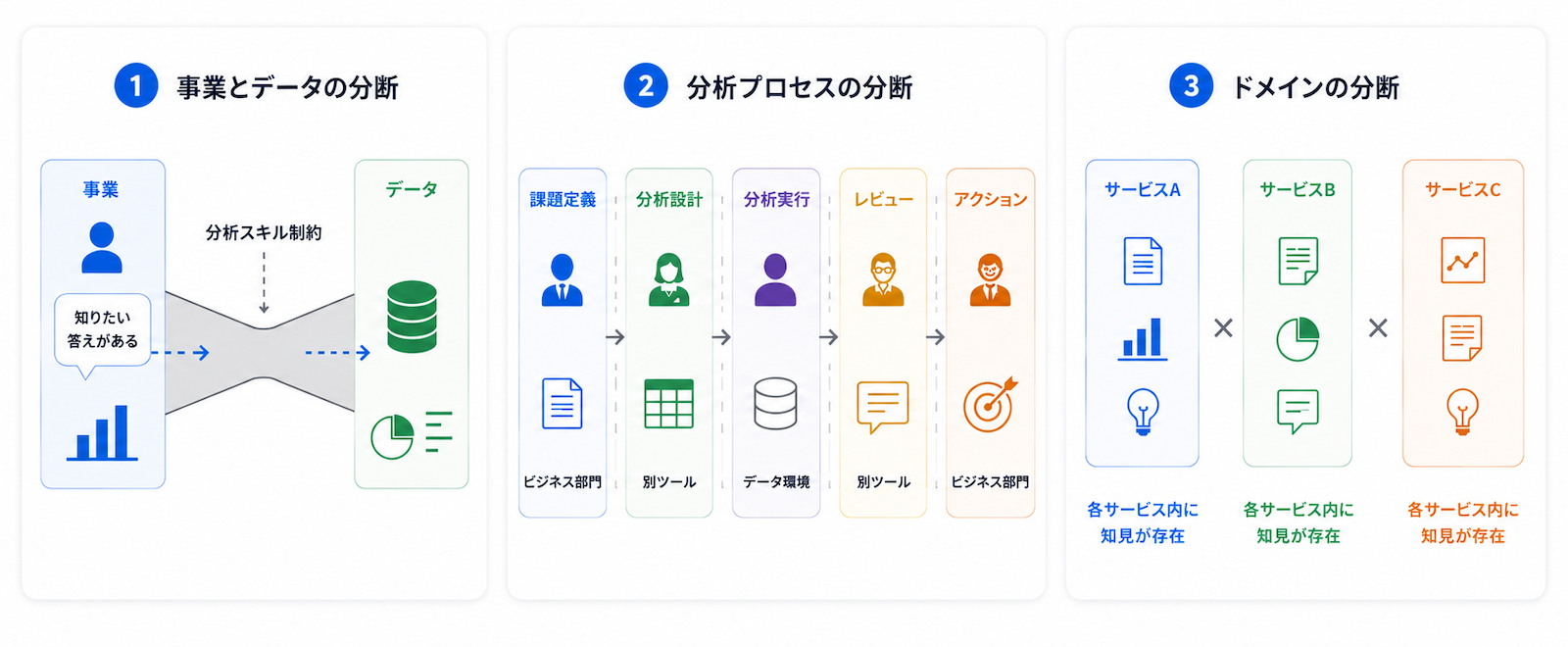
PJ One Pieceの出発点には、分析業務における3つの分断がありました。
- 事業とデータの分断
- 分析プロセスの分断
- ドメインの分断
つまり、事業の問いがデータに届かない、分析プロセスの途中で本来のゴールを見失い思わぬ方向に走ってしまう、ドメインごとの知見の再利用が困難、などの問題です。これら3つの分断の個々の深刻度合いは事業によってさまざまですが、それぞれが影響し合って、その事業におけるデータ活用のスピードと品質が決まっていると捉えることができます。
まず、「事業とデータの分断」です。DWHやBIが整備され、データはアクセスできる状態になったとしても、事業現場が必要なタイミングで必要な粒度の情報をデータから自力で得るには、まだ高いハードルがありました。SQLを書けるか、どのテーブル・列を使えばよいか、どの指標・定義で見るべきか、さまざまな変動の中から意味のある情報をどのように見つけるか、得られた数値をどう解釈して活用すればよいか。こうした判断が必要になるため、データ基盤を用意したとしても、データ活用のラストワンマイルが残ります。
次に、「分析プロセスの分断」です。これは、課題定義、分析設計、分析実行、レビュー、アクションまでの流れが、担当者やツール、実施タイミングが異なることで分断され、文脈が途切れやすい状態を指しています。依頼者の事業背景や意思決定の目的を明文化しきれず、あるいは分析設計の意図が実行やレビュー時に引き継がれないことで、認識のずれや手戻りが発生します。さらに工程の切れ目で待ち時間が生じ、実作業以上にリードタイムが伸びます。結果として、分析品質がばらつき、示唆がアクションにつながるまでのスピードが落ちる、という課題が発生していました。
最後に、「ドメインの分断」です。事業ドメインが変��わると分析担当者が変わり、サービスの前提、KPIの定義、見るべき比較軸、テーブル構造、施策やユーザー行動の文脈も変わります。そのため、あるドメインで優れた分析技術や分析パターンが生まれても、ドメインに閉じた再利用になりがちで、別ドメインでの活用は限定的でした。施策評価、ファネル分析、ユーザー理解、要因分析、効果測定など、似た構造を持つ分析は多くあります。それでも、ドメインごとの背景知識、テーブル契約、過去の判断理由、レビュー観点、結果から得た学びが個別に閉じると、分析資産は横断的に展開されにくくなります。
PJ One Pieceでは、AIがある前提で業務・知識・データ・人の役割・組織構造を再設計し、この3つの分断を「ひとつなぎ」にすることを目指しました。中核に置いているのが、自律的に分析を行うAIエージェント、分析エージェントです。
分析エージェントで分析を「ひとつなぎ」にする
ここでいう分析エージェントは、データサイエンティストが普段行っている「問いを整理する」「必要なデータを探す」「集計・分析する」「結果を読み解く」「次のアクションにつなげる」という流れを、社内システムを活用しつつ進める仕組みです。ユーザーはチャット画面などの入口から自然言語で依頼し、エージェントが目的を解釈して分析計画を立て、ツールを駆使して情報を�集めつつ、結果をまとめます。
この分析エージェントで目指す「ひとつなぎ」とは、データ分析を取り巻く一連の活動や資産をつなぐということです。これは、背景にあった3つの分断に対応しています。
1つ目は、事業とデータをつなぐことです。事業担当者がデータサイエンティストに依頼して結果を待つだけでなく、自ら問いを立てて分析を行い、次の打ち手を考えるところまで進められる状態を目指します。たとえば「先週のキャンペーンは売上に効いたのか、次にどの導線を改善すべきか」と自然言語で聞くだけで、SQLやテーブル情報などの複雑な技術・仕組みを意識せずに分析を始められるようにします。
2つ目は、分析プロセスをつなぐことです。エージェントはSQLや集計結果のような部分的な結果を返すのではなく、ユーザーの目的や過程の文脈を保持したまま、意思決定に必要な論点を整理し、キャンペーン対象や比較期間を確認し、集計や専門分析を行い、結果を解釈し、可視化やレポートとしてまとめ、ユーザーの目的の解決を目指します。必要なら追加分析も提案し、ユーザーが次のアクションを考えられるところまで伴走します。
3つ目は、ドメイン間をつなぐことです。分析エージェントという形で分析を形式知化することで、分析知見そのものが再利用可能、かつ継続的に改善していけるものになります。問いの整理、要件定義、指標や比較軸の選び方、レビュー観点、追加分析の判断といった過程はログとして残り、どこで前提不足や手戻りが起きやすいかを把握し、分析プロセスの改善につなげられます。頻出する分析プロセスはSkillとして一般化し、別担当者や別ドメインでも再利用できるようにします。
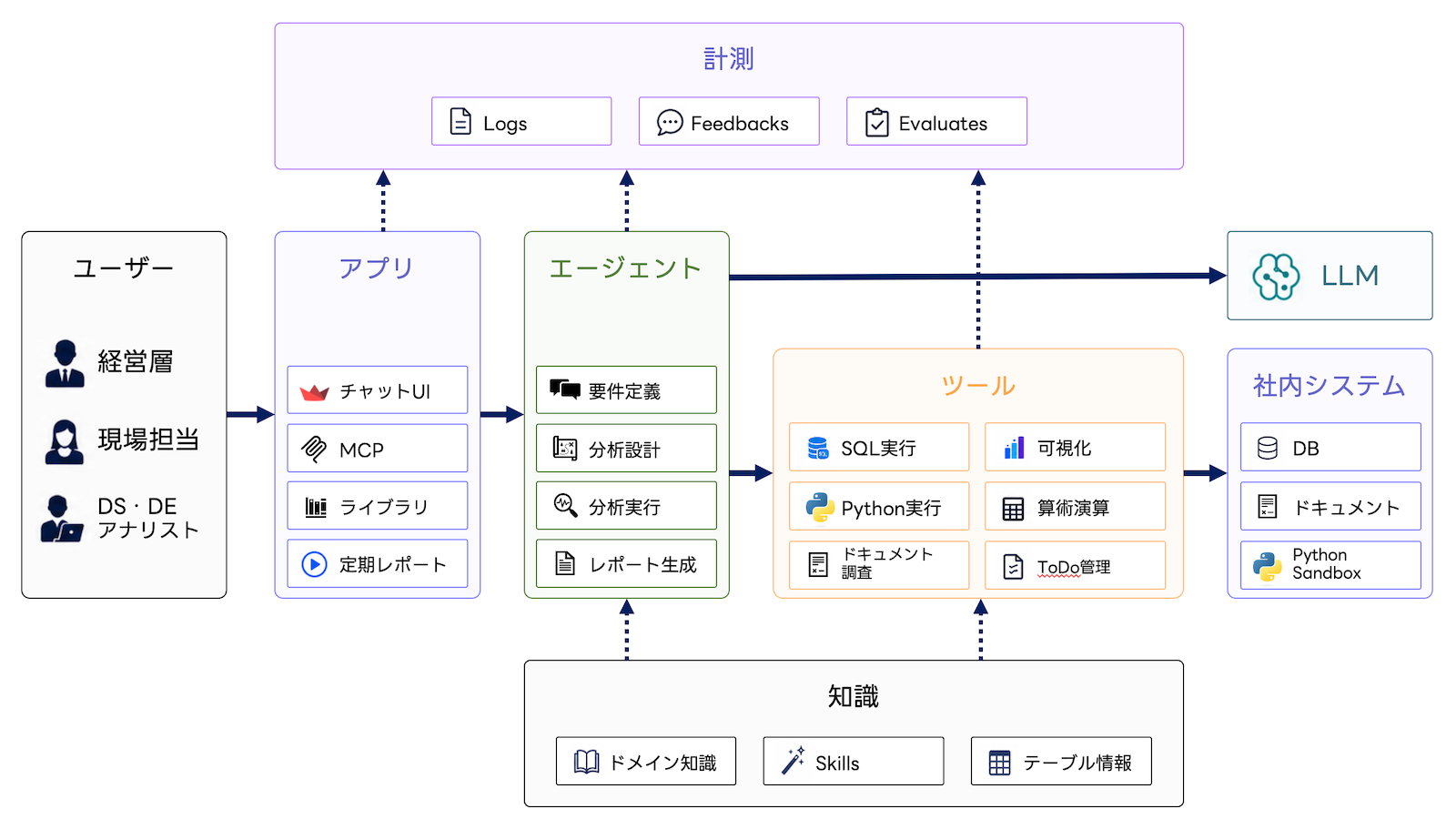
これらを支える全体構成は、大きく5つのコンポーネントに整理できます。
- ユーザーとの接点になるアプリ
- ユーザーの目的を達成するために、推論やツール利用を行うLLMベースのエージェント
- SQL実行、Python実行、社内ドキュメント調査、可視化などを担うツール
- ドメイン知識、Skill、テーブル情報などを提供する知識
- 分析エージェント全体のログ、ユーザーフィードバック、モニタリング、評価を担う計測
知識部分はプロダクトドメインごとに追加できるプラグイン構造にしており、実行ログやフィードバックも改善に活かすことで、使われるほど知識や分析パターンが蓄積される構成にしています。つまり、PJ One Pieceの分析エージェントは単体のLLMチャットアプリではなく、アプリ、エージェント、ツール、知識、計測を組み合わせた分析実行基盤として設計しています。
分析を「ひとつなぎ」にするための設計と技術
この3つのつながりを実現するには、分析をただ自動化するだけでは足りません。データ分析を取り巻く一連の活動や資産を1つのシステムとして設計する必要があります。実装や運用を進める中で見えてきた技術的課題を、ここでは4つに整理して紹介します。
1. 事業の問いを、分析可能な文脈に変換する
最初の課題は、ユーザーの自然言語の問いを明確な分析要件へ変換することです。ここでは、ユーザーに詳細な分析要件を書かせるのではなく、エージェント側がドメイン知識やテーブル情報を参照し、足りない前提だけを確認する設計にしています。
「先週のキャンペーンは売上に効いたのか」という問いには、対象施策、期間、KPI、比較対象、見るべき粒度、除外条件など多くの前提が含まれます。この前提があいまいなままでは、事業とデータの分断は残ります。
ただし、ユーザーが毎回これらを漏れなくプロンプトに書くのは現実的ではありません。ユーザーが書くべきなのは「何を知りたいか」であって、データ構造や分析設計を熟知していることを前提にした詳細な指示ではありません。そこで、事業側の自然な問いを起点にしながら、問いの背景を補い、分析要件へ変換する仕組みが必要になります。
このため、サービス理解、KPI定義、集計時の注意点、施策情報の探し方、レビュー時に確認すべき前提を、毎回のプロンプトではなくドメインごとの知識として管理しています。あわせて、どのようなテーブル・カラムがあって、どのテーブルをどの場面で使うべきか、といったテーブル情報も整備します。
この設計により、ユーザーはSQLやテーブル構造を知らなくても、自分の問いから分析を始められます。一方でエージェント側は、事業背景とテーブル情報を参照しながら、確定できる項目と、あいまいなためユーザーに確認すべき項目を明らかにし、確認すべき項目のみをヒアリング�することで、少ないユーザー負荷で分析要件を固めることができます。これは、事業とデータをつなぐための土台です。
2. 必要なデータへ、安全かつ確実にたどり着く
次の課題は、分析に必要なデータへ安全かつ確実にたどり着けるようにすることです。エージェントがデータを正確に使えるようにするには詳細なテーブル情報を渡す必要があります。しかし、大規模なデータを持つドメインでは、分析で利用するテーブルやカラムが多くなり、それらの説明や利用時の注意点を網羅するとかなりの文量になります。これらをすべて最初からLLMの入力に含めると、コンテキストが肥大化し、必要な情報を見落としやすくなります。さらに、入力トークンが増えることでコストが膨らみ、応答速度や推論の安定性も悪化します。
そこで、テーブル一覧のような軽い情報と、テーブルごとの詳細情報を分け、段階的開示で必要な情報へたどり着けるようにしています。エージェントはまずテーブル一覧だけを参照して利用するテーブルを絞り、それから利用するテーブルの詳細な情報を確認し、SQLを書く前に必要な説明、カラム定義、サンプル、パーティション条件、利用上の注意点を把握します。すべてを最初から読ませるのではなく、必要になったタイミングで必要な知識へ移動できる構造です。
また、業務システムやDWH上のテーブルは、分析目的に対してそのまま使いやすい形とは限らず、目的の集計にたどり着くまでに複数の抽出条件やJOINが必要になると、SQL生成の複雑度が一気に上がります。そのため、DBにあるテーブルをそのまま触�らせないようにしています。分析用途に最適化した大福帳テーブル(トランザクションデータに各種属性を結合した横長テーブル)を論理的なビュー、あるいは実際のテーブルとして作成し、それをエージェントへの公開面としています。そうするとエージェントは簡単な抽出条件や集約だけで多くの集計を実行できるようになるので、SQL生成の複雑度が低下し、ミスを最小限に抑えることができます。
さらに、SQLは実行前後に必ずシステム側でチェックします。SELECT限定、公開されたテーブル契約との照合、パーティション条件、機微情報や個人情報の制限、結果行数の制御などをシステムで担保することで、誤ったSQLや過剰なデータ取得のリスクを下げます。こうしたガードレールがあることで、安全な環境の中で、エージェントに比較的自由に分析を行わせることができます。
3. 分析設計から実行・解釈まで、コンテキストを保ち続ける
3つ目の課題は、分析設計、集計、可視化、解釈、レビューの文脈を途切れさせないことです。SQLだけを生成できても分析プロセスはひとつなぎになりません。どの対象同士を比較するとよいのか、どの軸・粒度で見ると重要な示唆が得られるのか、この結果でユーザーの目的は達成できるのか、この分析では何が分からなかったのか(どの追加分析をすべきなのか)、まで扱う必要があります。
そこで、分析エージェントでは、ユーザーとのやり取りを担いつつ全体の文脈を管理するエージェントが分析計画を立て、必要に応じてコンテキストを分離したサブエージェントへ依頼する、スーパーバイザー型のマルチエージェント構成を採用しています。メインエージェントは依頼内容、分析目的、分かったこと、次に判断すべき論点を持ち続け、統計検定、時系列分析、クラスタリング、レビューのような専門タスクは役割を限定したサブエージェントに切り出します。
これにより、全体文脈はメインエージェント側で保ちつつ、コンテキストを圧迫してしまうような試行錯誤が必要な作業、専門的な知識を要する作業、独立視点を要する作業を、知識やコンテキストをサブエージェント側に閉じ込めて実行できます。全体設計と専門作業を分けることで、文脈をつなぎながら深い分析や独立したレビューへ接続できます。
また、分析エージェントのタスクは単発のチャット応答より長く動くことがあります。調査で分かったこと、分析設計、使えるデータと使えないデータ、途中で見えた制約などを進捗として適宜共有することで、ユーザーは途中で方針や見るべき観点を軌道修正できます。
4. 分析エージェントを共通資産にして、組織全体で継続的に育てる
最後の課題は、分析エージェントを個別業務の支援ツールで終わらせず、組織として継続的に育てられる分析能力にすることです。重要なのは、そこで生まれたドメイン知識、分析技術、レビュー観点、結果の読み解き方、改善の学びを、次の分析や別ドメインでも使える形に変換することです。
そのために重要な役割を持つのが利用ログとフィードバックです。ログを見ることで、どのような入力に対してどのような出力を返したのか、��実行中にエージェントがどのような動作をして、どのように前提確認をして、どのような分析設計を作成したのか、どのようなSQLを書いたのか、どの分析でエラーが起きているのかなどを把握できます。ユーザーや分析者からのフィードバックを組み合わせることで、プロンプト、ツール、データ、Skillのどこを直すべきかを改善バックログにできます。
繰り返し登場する分析はSkillとして再利用可能な形にします。時系列分析やクラスタリング分析のように複数ドメインで使える汎用Skillもあれば、特定サービス向けの月報作成や施策モニタリングのようにドメイン特化のSkillもあります。どちらも確認すべき前提、比較軸、注意点、結果の読み解き方まで含めて明文化します。
こうしたSkillや改善バックログを積み上げることで、ドメインごとに閉じていた知識や分析パターンを、組織全体で使える分析能力へ変換できます。分析エージェントを単体のアプリではなく、複数の入口から同じデータ契約、Skill、レビュー観点を使える実行基盤として扱うことで、使われるほど知識と分析資産が蓄積され、対応できる分析領域や品質も広がります。
分析1案件の工数は2週間から10分へ: 先行展開で見えた事業価値
PJ One Pieceの分析エージェントは一部のサービス事業部で先行展開を行い、プロダクトオーナーから現場の方々まで広く利用していただいています。先行展開で大きなインパクトがあったのは、事業部内のデータ活用そのものを大きく加速できたことです。今では、事業部内の半数以上が利用する分析基盤に成長していま�す。データサイエンティストだけが使うツールではなく、ユーザーが日常業務の中で「まず聞いてみる」ための入口になっています。
わかりやすく変わったのは分析のリードタイムです。人が対応していたときは依頼から結果が返るまで平均で約2週間かかっていましたが、分析エージェントでは約10分で結果を得られます。前日実績の詳細な分析結果を、翌日午前の会議や施策検討にも十分に間に合わせられるようになりました。
事業部内の分析件数も大きく変わりました。分析チームで対応していたときは、月10回程度が現実的な上限でした。現在は、事業部内で数百回規模の分析が行われています。分析件数が増えたこと自体も重要ですが、それ以上に、これまで「分析依頼として出すほどではない」「順番待ちになるので後回しにする」と判断されていた問いが、実際に分析できるようになったことに意味があります。
- 施策期間中の売上や注文数はどう動いたか
- 今どのような商品がどのようなユーザーに人気なのか
- どの導線やセグメントで数値が動いているのか
こうした問いは、1つひとつを見ると必ずしも高度な分析ではありません。しかし、事業の意思決定では頻度が高く、タイミングも重要です。ここが分析組織のリソースに依存していると、すべての分析を実行するのは難しく、実行できたとしても待ち時間が発生して鮮度が落ちます。分析エージェントによって、このデータ活用のボトルネックを大きく解消できました。
データサイエンティストの役割はどう変わるのか
分析エージェントの�展開によって起きたもう1つの大きな変化は、データサイエンティストの価値と生産性を引き上げたことです。事業側が自分たちで分析を進められるようになると、データサイエンティストの仕事が減るのではなく、担うべき仕事の質が変わります。
つまり、分析エージェントはデータサイエンティストの仕事を置き換えるものではなく、依頼分析を中心とする役割に閉じてしまいがちな専門性を、事業課題の発見や分析能力の仕組み化へ広げていくものです。
従来は、分析依頼に対して、要件を確認し、SQLを書き、集計し、可視化し、示唆をまとめる案件が多くを占めていました。この能力は今後も重要です。一方で、分析エージェントが分析実行を担えるようになると、データサイエンティストがすべての分析依頼の解決を担う必要がなくなります。
現在は、事業の上流の戦略立案や企画プロセスに参加しながら、重要な課題を自ら発見・提案し、解決するような活動が増えてきています。つまり、顕在化している課題解決から、潜在的な事業課題を定義して解決する方向へと役割がシフトしています。
加えて、データサイエンティストの生産性も大きく向上しました。分析案件の生産性は分析エージェント導入前に比べて約2倍になりました。個々の案件にかかる工数を下げながら、より多くの案件を扱えるようになりました。
こうした役割シフトや生産性向上によって、分析エージェントのような再利用可能な分析資産を整備する活動にも工数を割けるようになりました。これは短期的な案件処理とは別の、分析ケイパビリティを継続的に高めるための投資です。汎用Skill、ドメイン特化Skill、分析用テーブル、レポートフォーマットを整備することで、次の分析はさらに速く、安定して実行できるようになります。
つまり、事業側は自分たちで分析を進められるようになり、データサイエンティストは依頼分析に使っていた工数を、より重要な課題解決や、分析エージェント自体を育てる活動に振り向けられるようになりました。
ここに、生成AI時代の分析組織の新しい価値があると考えています。重要なのは、どこをAIに任せ、どこを人が担うべきかを設計することです。
AIが力を発揮するのは、行いたいことが明確で、必要な情報にAI自身がアクセスでき、あとは情報収集しながら考えて実行できる領域です。一方で人が担うべきなのは、本当に解くべき重要な問いを見極め、多少の困難があっても望ましい解決を目指して進めることであると考えています。
おわりに
PJ One Pieceという名前には、分析を「ひとつなぎ」にしたいという意思を込めています。生成AIによって分析の進め方は大きく変わり始めていますが、本当に重要なのは、AIでどこまで自動化できるかではなく、事業の問い、データ、分析プロセス、ドメイン知識をどうつなぎ、そこから得た知見を次の意思決定と次の分析にどうつなげていけるかです。
生成AI時代の分析組織に求められるのは、AIに分析を任せることそのものではなく、AIが力を発揮できる業務、知識、データ、人の役割を設計することだと考えています。
私たちはこれからも、分析を一度きりの作業で終わらせず、組織に知識と実行力が積み上がる仕組みとして育てることで、データ活用を一部の専門家のも��のではなく、事業を動かす多くの人の力に変えていきます。
Tech-Verse 2026 を開催します(6月29日)

この記事は、イベントの公式記事として公開されました。
Tech-Verse 2026は、LINEヤフーが開催する技術カンファレンスです。
最先端の挑戦や積み重ねてきた知識を共有します。
YouTube LIVEでの配信をぜひご覧ください。
https://tech-verse.lycorp.co.jp/2026/ja/


