こんにちは。LINEヤフーのFoundation Models研究開発チームです。われわれのチームでは、画像と言語のマルチモーダル基盤モデルの研究開発を行っています。
この記事ではわれ�われが開発した日本語マルチモーダル基盤モデル「clip-japanese-base-v2」について紹介します。弊チームでは以前「clip-japanese-base」を公開しましたが、今回は学習データと学習方法の改善によって高性能化したモデルを公開します。商用利用可能なApache-2.0 ライセンスで公開していますので、ぜひ気軽にご利用ください。
公開するリソース:clip-japanese-base-v2
はじめに
CLIPは画像と言語の代表的なマルチモーダル基盤モデルで、インターネットから収集した大規模データで学習することでゼロショットでの分類や検索が可能となりました。高い汎用性と拡張性をもつCLIPは研究・実応用問わずさまざまな場面で使われており、われわれのチームでは「clip-japanese-base」公開後も日本語に特化したCLIPの研究開発を継続してきました。今回は「clip-japanese-base-v2」での改善点について学習データ・学習方法の観点から概要を紹介したいと思います。また、LINEヤフーでのCLIPの活用事例に興味のある方は以下の記事も読んでいただけると幸いです。
LINEヤフーでの利用例
学習データ
clip-japanese-base-v2では、Common Crawlから収集した日本語の画像��・テキストペアデータを主に使用しています。前回バージョンからの主な改善点は以下の2点です。
データ件数の増加
Common Crawlの2020年から2025年の6年分(全39スナップショット)を対象に画像URLの抽出処理を行い、フィルタリング前の画像サンプル数が18億件増加しました(10億件 → 28億件)。
画像テキスト一致度によるフィルタリングの改善
画像とテキストが無関係なデータを除去するために、従来のCLIP-scoreに代わりnegCLIPLossという新しい指標を採用しました。
CLIP-scoreはCLIPによって計算される画像とテキストの特徴量の類似度であり、画像とテキストの関連度を表す指標とみなすことができます。一方でCLIP-scoreには画像やテキストの性質によるバイアスが存在します。例えばシンプルな画像やテキストは類似度が高くなりやすい傾向がある、といったものです。negCLIPLossは、このようなバイアスを排除するために提案された指標で、CLIP-scoreをベースに「そのサンプル自身が類似度が高くなりやすい性質を持っているか」を考慮した正規化項を含んでいます。
さらに、フィルタリング用のCLIPモデルも自前で用意しました。Data Filtering Networksという研究では、フィルタリング用CLIPの学習には「大規模ノイジーデータ」よりも「小規模クリーンデータ」が適していることが示されています。われわれの内部実験においても同様の傾向が確認され、ダウンストリームタスクの精度が高いモデルがデータフィルタリングに適したモ�デルではないこともわかりました。この知見に基づき、人間が付けたキャプションを持つ画像などのクリーンなデータのみでCLIPを学習し、フィルタリングに適したモデルを構築しました。
内部的な実験の結果、これらのフィルタリング手法の採用がダウンストリームタスクの平均精度の向上に大きく寄与することが確認できました。
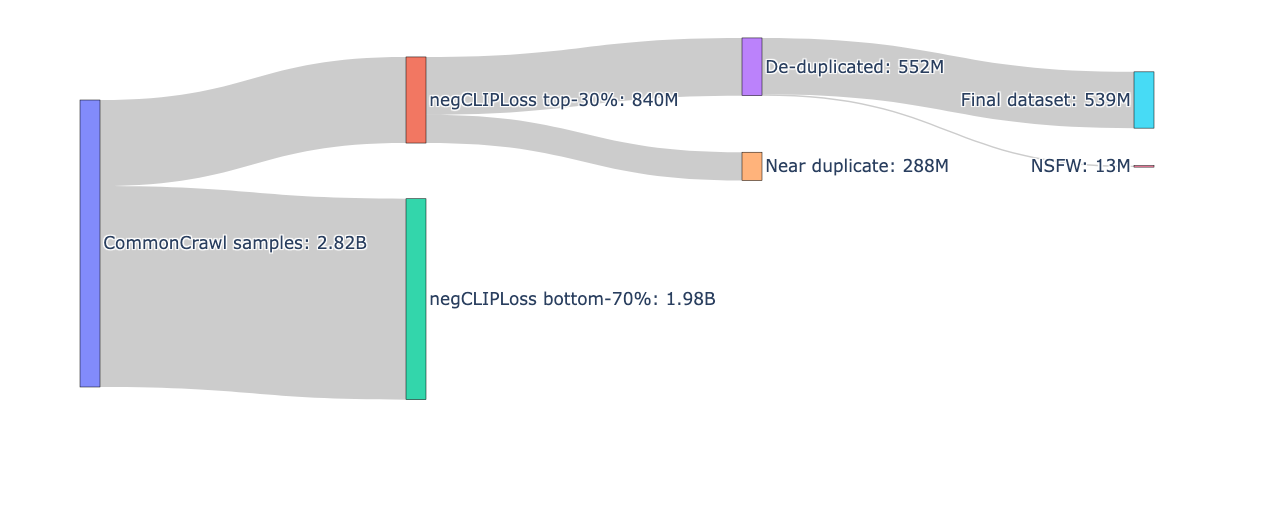
データ処理の全体像
最終的に5.4億件の高品質な画像・テキストペアを学習データとして使用しています。データ処理の全体像は以下の通りです。
学習方法
clip-japanese-base-v2では学習データの更新に加えて、知識蒸留による高精度化にも取り組みました。ここでは、高精度化の過程で参考にした先行研究:CLIP-KDを紹介します。
知識蒸留とは、大規模で高精度なモデル(教師)がもつ知識を、小さく軽量なモデル(生徒)に受け渡すことで、小さいモデルで高い性能を発揮できるようにする手法です。分類モデルのような通常のケースでは、教師モデルと生徒モデルの出力(ロジットや確率分布)を直接一致させる方法が一般的です。しかしCLIPは画像とテキストの2つのエンコーダをもつため、蒸留の設計がより柔軟になります。CLIP-KDでは、CLIP特有の構造を活かすためにさまざまな蒸留用の損失関数が提案されていますが、われわれの実験ではInteractive Contrastive Learning (ICL)と Contrastive Relational Distillation (CRD)の組み合わせが最も有効でした。ICLは、教師モデルと生徒モデルの特徴量を用いた対照学習によって生徒側の表現を強化する手法です(下図左)。一方で、CRDは教師モデルと生徒モデルで計算した画像とテキストの類似度を一致させるように学習させます(下図右)。

基本的にCLIPは画像とテキストの類似度の計算に利用されるため、特にCRDは実際のユースケースに即した方法となっています。われわれのチームでは、CRDに対して独自の改良を加えることで大幅な精度改善に成功しました。
性能評価
ゼロショット画像分類と画像・テキスト検索で性能を評価した結果を示します。評価データセットには以下の4つを利用しました。
評価指標は、画像・テキスト検索タスクであるSTAIR CaptionsではI2T_R@1とT2I_R@1の平均値とし、その他の画像分類タスクではacc@1とします。また、画像分類タスクのテンプレートはImageNet-1kで一般的に利用されるものを日本語訳して利用し、テンプレートあり・なしの評価で��性能が高い方を報告します。
まず、clip-japanese-base-v2の性能を既存の公開モデルと比較した結果を示します。今回比較対象としたモデルは以下の4つです。
- clip-japanese-base:以前われわれが公開した日本語CLIPモデル
- waon-siglip2-base-patch16-256:LLM-jpによる日本語CLIPモデル
- siglip2-base-patch16-224:GoogleによるマルチリンガルなSigLIPモデル
- siglip2-so400m-patch14-224:GoogleによるマルチリンガルなSigLIPモデル(大規模サイズ)
clip-japanese-base-v2はモデルパラメータが最も少なく、他の日本語特化やマルチリンガルモデルより高い性能を示します。
| モデル | パラメータ数 | 平均性能 | ImageNet-1k | Recruit | WAON-Bench | STAIR Captions |
|---|---|---|---|---|---|---|
| clip-japanese-base-v2 (Ours) | 196M | 0.708 | 0.666 | 0.913 | 0.975 | 0.277 |
| clip-japanese-base | 196M | 0.673 | 0.580 | 0.884 | 0.934 | 0.293 |
| waon-siglip2-base-patch16-256 | 375M | 0.664 | 0.555 | 0.872 | 0.951 | 0.276 |
| siglip2-base-patch16-224 | 375M | 0.579 | 0.517 | 0.802 | 0.871 | 0.126 |
| siglip2-so400m-patch14-224 | 1135M | 0.642 | 0.643 | 0.837 | 0.925 | 0.163 |
次に、学習データの更新と知識蒸留による精度改善の効果を示します。知識蒸留の教師モデルでは、vision encoderにsiglip2-so400m-patch14-224を採用し、われわれの日本語データでCLIPを学習しました。STAIR Captionsの性能は特徴量次元を512から256に減らした影響でclip-japanese-baseより悪化していますが、その他のタスクでは学習データと知識蒸留のそれぞれで精度改善を確認できました。
| モデル | 平均性能 | ImageNet-1k | Recruit | WAON-Bench | STAIR Captions |
|---|---|---|---|---|---|
| clip-japanese-base | 0.673 | 0.580 | 0.884 | 0.934 | 0.293 |
| + 学習データ更新 | 0.680 | 0.611 | 0.905 | 0.970 | 0.232 |
| + 知識蒸留 (clip-japanese-base-v2) | 0.708 | 0.666 | 0.913 | 0.975 | 0.277 |
おわりに
今回公開した「clip-japanese-base-v2」を皆様に広くご利用いただき、ご意見やご感想をお寄せいただけますと幸いです。
LINEヤフーは今後も構築したモデルの一部を継続的に公開しますので、今後の展開にもぜひご期待ください。


