1 はじめに
こんにちは、京都大学大学院情報学研究科修士1年生の藤原智弘です。普段はメタ学習をメインに研究しています。今回貴重な機会をいただき、2025年8月18日から2025年10月10日までの8週間で、高度なセグメントと呼ばれる検索行動に基づいた広告ターゲティング機能の研究開発を担当しているチームでインターンに参加させていただきました。本記事では、インターン期間中に取り組んだ「高度なセグメントにおける機械学習モデルの改善」について紹介していこうと思います。
2 背景
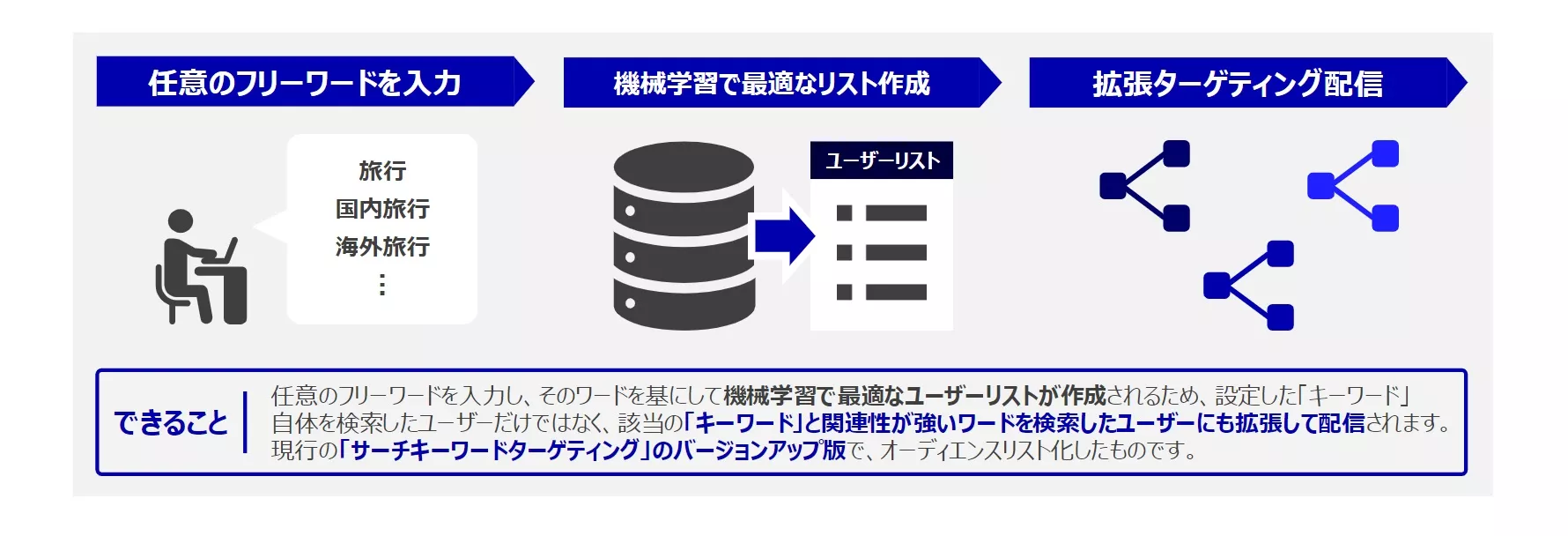
私たちのチームでは「高度なセグメント」と呼ばれる広告配信システムの研究開発を行っています。高度なセグメントでは、広告主が入力するフリーワードと各ユーザーの��検索履歴を基に、機械学習モデルを用いて最適な配信対象ユーザーをリスト化しています。
このモデルの精度が上がれば、広告主にとっては幅広いユーザーに広告を配信することができるようになり、ユーザーにとっては自分の関心・嗜好によりマッチした広告を閲覧することができるようになります。よって、モデル改善は広告主とユーザーの双方にとってメリットがあります。本インターンでは、この機械学習モデルの精度改善に取り組みました。
3 取り組んだ内容
私が提案した施策は以下の4つです。
- ライフイベントの推定結果を特徴量に追加
- 階層構造を明示したマルチタスク学習モデルの導入
- 予測確率の補正
- 配信サイズの動的変更
3.1 ライフイベントの推定結果を特徴量に追加
私はまず、検索履歴にはユーザーの短期的な関心がより強く反映されていると考え、より長期間のユーザー行動履歴を反映している特徴量を使うことで、ユーザーの長期的な関心・好みを捉えられるのではないか?と仮説を立てました。この仮説の下で、「ユーザーのライフイベントを推定するモデル※2」の推論結果を新規の特徴量として採用しました。例えば、結婚というライフイベントがあれば、同棲・同居のための家具の新調や引っ越し業者が必要になります。また、出産というライフイベントがあるなら、育児のためのミルク・オムツ・玩具など育児用品の購入が必要になります。このように、ライフイベントは生活全体の関心・好みの構造を変化させるので、ライフイベントは包括的な�ユーザーの関心・好みを表現していると期待できます。私の提案手法では、ユーザーの短期的な興味や好みだけでなく、より広く包括的なユーザーの興味を捉えられる可能性のあるライフイベント情報を特徴量に導入することで、モデルの精度が改善することを狙いました。
3.2 階層構造を明示したマルチタスク学習モデルの導入
ユーザーは、配信された広告に対してクリックや動画視聴、コンバージョンなどさまざまな広告アクションを行います。しかし、一部の広告アクションは発生確率が極端に低く、陽性サンプルのパターンを学習することが困難です。そこで、ユーザーの多様な広告アクションとその行動遷移をモデルで捉え、陽性数が少ない広告アクションを学習させるために、2つの改善施策を検討し、以下の図のようなマルチタスク学習モデルを提案しました。DesiredActionが元のタスクの広告の詳細閲覧または商品購入にあたり、Action1~4が元のタスクと性質は近いものの、発生確率が高い補助タスクになっています。
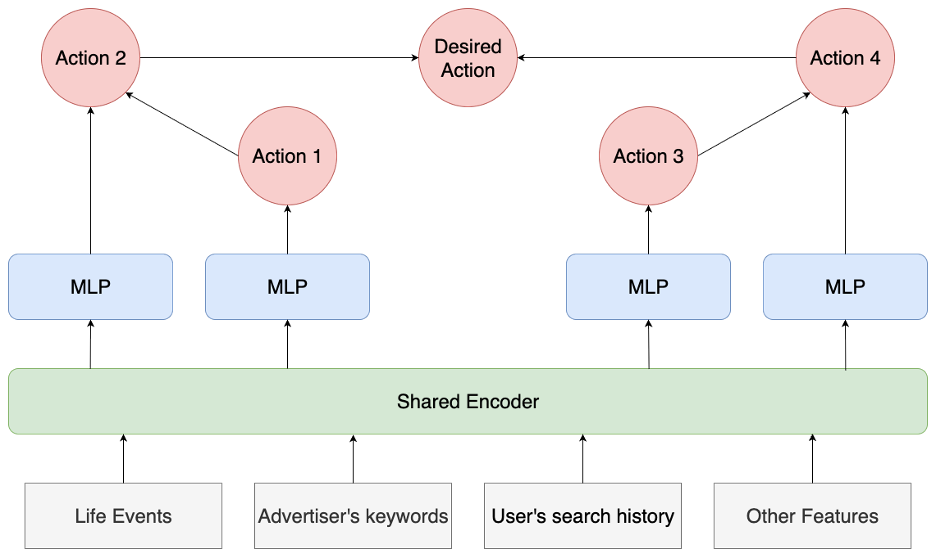
2つの改善施策についてそれぞれ説明していきます。
1つ目の改善施策はマルチタスク学習の導入です。ユーザーの多様な広告アクションのほとんどはユーザーが対象広告に興味を持った時に発生すると考えられます。よって、これらの多様なアクションを同時に学習することで、発生数が少ない目的のタスクに対する予測精度の向上が期待できると考えました。そこで、目的タスクである広告の詳細閲�覧または商品購入以外の広告アクションを補助タスクとして導入し、マルチタスク学習を行いました。
2つ目の改善施策は、広告アクションの遷移構造に基づく階層的ヘッドの導入です。マルチタスク学習では、通常各ヘッドで1つのタスクの予測を行いますが、発生数が少ないアクションの予測では過学習が懸念されます。そこで、各タスクを1つのヘッドで計算するのではなく、複数のヘッドで計算する方法を提案しました。ユーザーの広告アクションには、閲覧 →クリック → コンバージョンというような階層構造があると考えられます。この考えの下、上の図のような階層構造に従い、各ヘッドで広告アクションの遷移確率を予測し、複数のヘッドの出力を使って各タスクの発生確率を計算します。これにより、各ヘッドが複数の正解ラベルで学習されるので、発生数が少ないタスクに対して過学習することを抑制できると期待されます。
3.3 予測確率の補正
私が提案したモデルでは全リストの予測確率を1つのモデルで学習・予測しますので、リストごとに予測確率が極端な値を取ってしまいます。例えば、広告の詳細閲覧または商品購入を行ったユーザーが多かったリストでは、予測確率がほぼ1.0となってしまうということが考えられます。逆に広告の詳細閲覧または商品購入を行ったユーザーがほとんどいなかったリストでは、予測確率がほぼ0.0となってしまうことも考えられます。これにより、リスト間で予測確率の分布にズレが生じる可能性がありました。
そこで、私の提案した運用方法ではリストごとに予測確率に対して、Min-Max正規化を行い予測確率を補正するこ��とで上記の問題を防いでいます。
以下の表は、補正前後での各性能指標のリフトになります。precisionとrecallは微増に留まっていますがROC-AUCは大幅に上がっているのが確認できます。
| precision | recall | ROC-AUC | |
|---|---|---|---|
| リフト(%) | +0.299 | +0.386 | +2.634 |
3.4 配信サイズの動的変更
広告の詳細閲覧または商品購入の見込みのあるユーザーが多くいるリストもあれば、見込みのあるユーザーがほぼいないリストも存在します。これらのリストに対し、同じ閾値ロジックを適用して配信サイズを静的に決定すると次のような問題が起こります。広告の詳細閲覧または商品購入の見込みのあるユーザーが多いリストでは、見込みのあるユーザーを取り逃がしてrecallが下がるおそれがあります。逆に見込みのあるユーザーがほぼいないリストでは見込みのないユーザーにも配信を行ってしまいprecisionが下がるおそれがあります。
そこで、各リストに対して適切な閾値を設定するために、過去の配信実績に応じて配信サイズを動的に変更する方法を提案しました。
具体的には、過去の実績から広告の詳細閲覧または商品購入の見込みのあるユーザーがより多くいると思われるリストに対しては配信サイズを拡大し、逆に広告の詳細閲覧または商品購入の見込みがないユーザーを多く含んでいると思われるリストは配信サイズを小さくしました。
これにより、より効率よく多くのユーザーに広告配信できることが期待できます。
4 オフライン検証
上述した私の提案モデルと現行のモデルで社内のオフライン性能評価を実施しました。
ある日付までのユーザーの行動データを用いて最適化モデルを学習し、その翌日に配信するユーザーリストを作成する形で検証を行いました。
結果として、提案モデルでユーザーリストを作成した際は全性能評価指標で現行モデルを上回っていました。
| precision | recall | ROC-AUC | |
|---|---|---|---|
| 現行モデルからのリフト(%) | +49.646 | +8.620 | +8.189 |
今回は時間が足りず、A/Bテストなどのオンライン検証はできませんでしたが、配信効率の改善は十分に見込める結果になったと思います!
5 学んだこと
5.1 PySparkによる大規模データのETL
これまでのKaggleや研究における機械学習モデルの開発では、学習データセットはあらかじめ整備されたものを使うことが多く、サイズも1GB以下でした。しかし今回のタスクでは、ユーザーの広告アクションに関するデータのみが存在し、モデル仕様に合わせて自分でSQLを書いてデータセットを構築する必要がありました。 さらにデータ量が非常に大きいため分散ファイルシステム(DFS)上での管理が必要で、DFSに対してSQLを実行するためにPySparkを使用する必要もありました。学習コストの高いPySparkを使って、大規模データのETLを本格的に学ぶ貴重な機会だったと思います。
5.2 「意味のある施策」を意識する
8週間という長期インターンでしたが、それでもA/Bテストなど本格的な検証まで行うには、時間が足��りませんでした。既存モデルの性能検証を十分に行わないまま、自分の仮説に基づく新モデルの構築に時間をかけてしまったことが反省点です。 自由な発想も大事ですが、既存モデルの理解・分析を深めること、そして「自分の今の施策には本当に意味があるのか」を常に考えることの大切さを学びました。
6 感想
今回のインターンで取り組んだ領域は広告に関するデータサイエンスであり、これまでの大学での研究テーマと関わりが皆無で、ドメイン知識も完全に0でした。しかし、研究で培った論文のサーベイ力・個人開発で養った人のコードを読んで理解する力・Kaggleで磨いたモデル改善力、など私がこれまでの経験で身につけた能力を総動員して、8週間でかなりの成果を絞り出すことができたと思います。またメンターの山口さんを中心に、社員の方々の作業時間をいただいて、使い慣れていないTensorFlowやPySparkのエラー対応やモデルの改善施策へのアイディア出しなどをしていただきました。そのおかげで、インターンシップ8週間の成果を最大化することができました。本当にありがとうございます。
サーベイした論文やメンターの方からいただいたアイディアをモデルに落とし込み、その結果に対するメンターの方からフィードバックや自分なりの考察を基に新たな改善策を模索する、という業務がインターン中のほとんどの時間を占めていました。一見、個人開発や大学の研究でもできそうな内容に聞こえるかもしれません。しかし、実際には、大規模な学習データや本番と同等の広告の配信リストをPySparkで作成して、モデルの性能を検証するといった業務も行っており、大変貴重な経験でした。非常に勉強になりました。
インターンシップ期間中は、社員の方々とモデル改善を黙々と進めていくだけでなく、別のチームや部署で働いているインターン生同士の交流も盛んに行われています。お昼休みの時間に定期的に開催されたオンライン交流会や、多くのインターン生が参加したオフラインでの懇親会などがありました。この機会を通じて他のチーム・部署では何をやっているのか、チームの雰囲気はどんな感じか、などの話を聞くことができました。インターン生同士の交流を通じて、私は良い意味での危機感を持つこともできました。
最後になりましたが、私をインターンシップに参加させていただいたLINEヤフー株式会社と、お世話になった高度なセグメントのチームの皆様、そして毎日1on1を設けていただきモデル改善以外のさまざまな相談にも対応していただいたメンターの山口さんには非常に感謝しております。今回のインターンシップでは非常に密度の高い環境で多くのことを学ぶことができました!
7 メンターからの一言
この度、藤原さんのインターンシップのメンターを務めさせていただきました山口寛人です。
今回のインターンシップでは、実際のサービス運用で発生していた課題を共有し、その解決策の立案から実装・検証までを藤原さんに一貫して取り組んでいただきました。インターン開始当初、藤原さんは高度なセグメントに関する知識が浅かったにも関わらず、短期間で必要な知識をキャッチアップし、スピード感を持って課題解決に臨む姿勢が非常に印象的でした。
改善案の検討においても、論文や既存手法の�調査にとどまらず、高度なセグメント特有の課題やサービスの仕様などを考慮した上で改善案を提案していただき、非常に高いレベルで業務に取り組まれていたと思います。結果としても、オフライン検証において既存モデルを大きく上回る成果を出していただき、期待以上の成果を得ることができました。
また、業務の成果だけでなく積極的に他のインターン生や社員とコミュニケーションを取る姿勢も非常に印象的でした。インターン期間中に開催された部内のポスターセッションでも、自ら他のチームの取り組みに関心を持ち、交流を深めている様子にも非常に素晴らしいと感じました。
この度は弊社のインターンにご参加いただきありがとうございました。メンターの私としても非常にいい刺激を受けた8週間でした。
藤原さんの今後のご活躍を期待するとともに、またお会いできることを楽しみにしています!
※1: 2025年11月現在サーチキーワードターゲティングはサービス終了しています。
※2: ユーザーのライフイベントを推定するモデルは匿名化/集計化・利用目的・社内ガイドラインに準拠しています


