はじめに
こんにちは。筑波大学情報学群情報科学類3年の浅田睦葉と申します。
私は2024年9月に行われた8日間のサマーインターンシップ�で、内製分散データベースシステム FractalDB の開発業務に参加しました。この記事では、インターンシップ中の課題とその取り組みについて紹介します。
FractalDB
FractalDBとは、LINEヤフー内製で開発・運用されている分散データベースシステムです。現在、同じ分散データベースシステムであるApache Cassandraは、各サービス向けに独立にデータベースを構築し運用されています。
内部では分散型のキーバリューストアであるFoundationDBが使用されており、Cassandraクライアントから送信されるパケットをパースしてCQLを受け取り、FoundationDBへの操作に変換しています。したがって、これまでCassandraを利用していたサービスはほとんど変更を行うことなく、データベースのみをFractalDBに移行することができます。
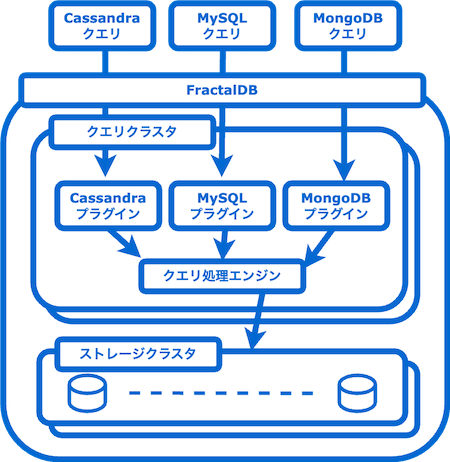
詳細な内容についてはメンターの今野さんが書かれたFractalDB: LINEヤフーのオンプレミス・マルチテナンシー型データベースシステムの紹介や、中野さんが書かれたFractalDBを内製するに至った背景とサービス設計概要をご覧ください。
背景
FractalDBはApache Cassandraを拡張し、制約の少ないグローバルかつマルチカラムなセカンダリインデックスをサポートしています。しかし、ユーザがクエリを実行する際、データベースがどのセカンダリインデックスを使用するかはルールベースによって決定していました。たとえば、次のようなテーブルとインデックスが存在する状況を考えます。
CREATE TABLE tb1 (
pk int,
col1 text,
col2 text,
PRIMARY KEY ((pk))
);
CREATE INDEX tbl_col1 ON tb1 (col1);
SELECT * FROM tb1 WHERE pk > 100 AND col1 = 'foobar';このテーブルに対して上のような検索を行うとき、主キーを利用した範囲検索を行うべきか、tbl_col1を利用した検索を行うべきかは、ルールベースで決まります。この方法では作成される実行計画が必ずしも最適化されたものにならないため、アクセスするべきデータ数が非常に大きいクエリなどでは性能が低下する可能性がありました。
一方で、多くのデータベースシステムは、クエリを実行可能な複数の実行計画に対してそれぞれコストの見積もりを行い、できるだけ安価な実行計画を選択する手法であるCardinality Estimationを採用しています。しかし、FractalDBのようにデータが複数のノードに分散された環境では、正確な推定を実行することは簡単ではなく、短期間での導入は現実的ではありません。そこで、効率的な実行計画作成機能が実装されるまでの対応策として、データベースが使用するセカンダリインデックスをユーザが明示的に指定できる仕組みを導入することが検討されていました。インターンシップでは、これを実現する構文の設計を行った�後、実装を行いました。
※1: テーブル内の主キー以外の列に対して作成されるインデックス。事前にセカンダリインデックスを作成すれば、主キーに依存しないクエリの実行性能を高めることができる。
設計
FractalDBに対して大きな機能追加を行う場合には、設計書を書いてチームの承認を得る必要があります。導入する構文やその実装方法について検討を行い、設計書を作成し、チームの方にレビューを頂きました。
調査
すでにインデックスヒント句を採用しているMySQL、Oracle、PostgreSQLなどの仕様を調査しました。
MySQL
MySQLではインデックスヒント句か、オプティマイザヒント句におけるインデックスヒントのいずれかを用いることでユーザが使用したいインデックスを明示できます。
インデックスヒント句は、クエリ処理において利用するインデックスを明示的に指定するための構文で、SELECT my_column USE INDEX (my_index) FROM my_tableのように記述できます。インデックス名には曖昧でなければ不完全な名前を与えることもできます。オプティマイザヒント句におけるインデックスヒントが追加されたため、将来的に非推奨になることがすでに決まっています。
オプティマイザヒント句は、データベースに対して最適化を明示的に指定する構文で、SELECT my_column /*+ JOIN_INDEX(my_index) */ FROM my_tableのように記述できます。SQL標準としてはコメント/* */に含まれますが、MySQLは最適化のために特別に解釈を行います。
Oracle
SELECT my_column /*+ hint */ FROM my_tableのような構文でオプティマイザ・ヒントをサポートしています。
PostgreSQL
SELECT my_column /*+ hint */ FROM my_tableのような構文でオプティマイザ・ヒントをサポートしています。特に、IndexOnlyScanヒントがインデックスヒントに対応しています。オプティマイザ・ヒントを有効にするには、別途pg_hint_planをインストールする必要があります。
構文
各DBMSにおけるインデックスヒントを基に、FractalDBに導入する構文を検討しました。
インデックスヒント句か、最適化ヒント句か
インデックスヒント句(MySQLに類似)または最適化ヒント句(MySQL・Oracle・PostgreSQLに類似)のどちらを採用するか検討しました。当初は、構文解析の変更が後者と比較して容易であると考えられることや、インデックスヒントはあくまで暫定的な措置であることを理由に、インデックスヒント句を採用し、USE・IGNOREキーワードを導入する予定でした。しかし、以下のような理由によって最適化ヒント句を採用することにしました。
- 現状ではインデックスヒント句を備える主要なDBMSはMySQLしか見つからず、そのMySQLも将来的にこの構文を廃止する方向性のため、すぐに構文的な互換性が維持できなくなること
- 加えて、標準SQLから逸脱した構文を採用することになるリスクも�ある
- ステートメントの実行時間制限である
MAX_EXECUTION_TIME(MySQL)、並列化の制御を行うPARALLEL(Oracle)など、FractalDBを利用する上で制御できるとユーザにとって便利なヒントは他にも考えられるが、それらを追加する際にキーワードを確保して構文を拡張するよりも、/*+ */スコープに閉じた範囲で拡張する方が、実装面でも構文面でも有利だから
ヒントを記述できる範囲の制限
MySQLのオプティマイザヒントは、SELECT文やUPDATE文、DELETE文に対して与えることができますが、まずは効用を実証するためにSELECT文に対してのみ拡張を行い、その後必要であれば他の文にも拡張することにしました。
JOIN_INDEXに対応する命名
MySQLのオプティマイザヒントは、JOIN_INDEXヒントによって使用するインデックスを明示することができますが、Cassandraをはじめとする多くのNOSQLデータベースにはJOIN操作が存在しません。混乱を招くことを防ぐために、FractalDBではインデックスヒントに対してUSE_INDEX、NO_USE_INDEXと命名することにしました。
異常系クエリに対する対応
MySQLやOracleのインデックスヒントに対して存在しないインデックス名を渡すと、そのヒントは無視されます。しかし、この仕様はユーザに不要なデバッグをさせる可能性があります。そこで、FractalDBではできるだけ安全側に倒した挙動を提供するためにエラーを発生させることにしました。
結果
以上の検討の結果、導入する構文を用いたクエリをいくつか例示します。
/*== 正常系 ==*/
/* index1という名前のインデックスを用いて、test_tableから検索する */
SELECT /*+ USE_INDEX(index1) */ foo FROM test_table;
/* index2以外のインデックスを用いて、test_tableから検索する */
SELECT /*+ NO_USE_INDEX(index2) */ foo FROM test_table;
/* index3、あるいはindex4を用いて、test_tableから検索する */
SELECT /*+ USE_INDEX(index3, index4) */ foo FROM test_table;
/* 最適化ヒントに複数のヒントを指定できる */
SELECT /*+ USE_INDEX(index5), USE_INDEX(index6) */ foo FROM test_table;
/* 主キーを利用して検索する */
SELECT /*+ USE_INDEX(PRIMARY_KEY) */ foo FROM test_table;
/*== 異常系 ==*/
/* `USE_INDEX` か `NO_USE_INDEX` で指定する必要がある */
SELECT /*+ JOIN_INDEX(index1) */ foo FROM test_table;
/* カンマが末尾に来ることは許されない */
SELECT /*+ USE_INDEX(index2, index3, ) */ foo FROM test_table;
/* この提案で拡張されるインデックスヒントはSELECT文でのみ利用できる */
UPDATE /*+ USE_INDEX(index4) */ test_table SET foo = 'bar';
/* 作成済みのインデックスのみを指定できる */
SELECT /*+ USE_INDEX(no_exists_index) */ foo FROM test_table;
/* 複数の最適化ヒントを含めることはできない */
SELECT /*+ USE_INDEX(index5) */ /*+ USE_INDEX(index6) */ foo FROM test_table;
/* 最適化ヒント句はSELECTの直後でのみ認められる */
SELECT foo /*+ USE_INDEX(index7) */ FROM test_table;ただし、最適化ヒント句/*+ */はCassandraでは単なるコメントとして扱われます。開発時に利用するライブラリやツール(ORMなど)が最適化などを目的に除去しないかどうかを検証する必要があります。もしORMが最適化ヒント句を除去する可能性が高い場合には、異なる字句により実現することにします。
実装
最適化ヒント句の実装は、主に3つの作業に分割できます。
- CQLクエリパーサを変更する
- FractalDB内部で使用される、クエリエンジンの中間表現であるQIC(Query Intermediate Code)に、最適化ヒント句に対応するオペランドを追加する
- QICによる実行計画作成のロジックを変更する
それぞれについて説明します。なお、本記事で示すソースコードはすべて疑似コードであり、実際のFractalDBのソースコードではありません。
CQLクエリパーサの変更
まず、現状のクエリパーサによってパースすると、最適化ヒント句はコメントとして扱われるためにヒント情報は捨てられるはずです。そこで、最適化ヒント句を含むSELECT文を解釈できるようにする必要があります。FractalDBではLL構文解析を行うパーサジェネレータである、ANTLRを用いています。ANTLRに対して文法定義ファイルを与えることで、Lexer(字句解析器)とParser(構文解析器)を生成することができます。
selection
: kwSelect optimizerHints? (distinctSpec |) selectClause fromSpec whereSpec? orderSpec? perPartitionLimitSpec? limitSpec?
allowFilteringSpec?
;
optimizerHints
: optimizerHintsStart optimizerHint (syntaxComma optimizerHint)* commentEnd
;
optimizerHint
: IDENT optimizerHintArgs?
;
optimizerHintArgs
: syntaxBracketLr IDENT (syntaxComma IDENT)* syntaxBracketRr
;ANTLRのドキュメントによれば、文法定義ファイルに記述されたルールは上から下に解釈されます。しかし、それに従ってルールを記述しても、最適化ヒント句/+* */の解釈よりもコメント/* */の解釈が優先されてしまう問題に当たりました。残念ながら根本的な原因を発見することはできませんでしたが、コメントの解釈を('/*' ~'+' .*? '*/') | '/**/'のように変更することで別々の字句要素として扱われるように対応しました。今回は最適化ヒント句に対してインデックスヒントのみを実装しましたが、将来的には異なる種類のヒントが追加されていく可能性があります。USE_INDEXヒントをはじめとしたヒント名は字句要素として解釈するのではなく、意味解析時にサポートされたヒント名であるかどうかをチェックすることで、予約語を増やさないようにしました。
QICへのヒントオペランドの追加
FractalDBに渡されたいかなるクエリも、QICと呼ばれる中間表現に変換されてから実行計画が作成されます。したがって、先ほど変更したCQLクエリパーサがパースした最適化ヒント句をQICに変換できるようにする必要があります。
type OptimizerHint struct {
hintName String
hintArguments Array
}
type OptimizerHints struct {
*Array
}QIC表現として、最適化ヒントとその配列を定義します。静的に最適化ヒントを作成するだけではなく、バイト列とQIC表現を相互変換することが�できます。インタフェースによりQICのオペランドが抽象化されており、CassandraのクエリからQICを出力するコンパイラの変更を簡単に実装できました。
case *SelectQuery:
if err := validateRestrictions(queryType.Restrictions()); err != nil {
return nil, err
}
expandedRestrictions, err := expandRestrictions(queryType.Restrictions())
if err != nil {
return nil, err
}
for _, restriction := range expandedRestrictions {
operation := createSelectOperation(queryType.AllowFiltering())
+ hints, exists := queryType.GetOptimizerHints()
+ if exists {
+ optHints := &OptimizerHints{}
+ for _, hint := range hints {
+ hintObj, err := createOptimizerHint(hint.hintName, hint.hintArguments)
+ if err != nil {
+ return nil, fmt.Errorf("invalid optimizer hint: %v", err)
+ }
+ optHints.Hints = append(optHints.Hints, hintObj)
+ }
+ operation.AddHints(optHints)
+ }
collectionOperands := createCollectionOperands(restriction)
operation.AddCollectionOperands(collectionOperands)
condition, err := compileCondition(restriction)
if err != nil {
return nil, fmt.Errorf("invalid condition: %v", err)
}
if condition != nil {
operation.AddCondition(condition)
}
query.AddOperation(operation)
}QICによる実行計画作成のロジック変更
データベースにより使用されるセカンダリインデックスは、基本的に条件列に含まれるフィールド数(スコア)が多い順に採用されます。もし同数の場合には、インデックスの名前順にしたがってより若い方が採用されます。追加した最適化ヒントであるUSE_INDEX、NO_USE_INDEXがセカンダリインデックスの採用優先度に影響を与えるように、実行計画作成のロジックを変更しました。USE_INDEXヒントを与えた場合には、明示されたインデックスのうち、スコアが高い順に選ばれます。また、NO_USE_INDEXヒントを与えた場合には、インデックス全体から明示されたインデックスが除かれ、スコアが高い順に選ばれます。
func filterIndexesByHints(indexes []Index, includeHints []string, excludeHints []string) ([]Index, error) {
var filteredIndexes []Index
if len(includeHints) > 0 {
var missingHints []string
for _, hint := range includeHints {
found := false
for _, index := range indexes {
if index.Name == hint {
filteredIndexes = append(filteredIndexes, index)
found = true
break
}
}
if !found {
missingHints = append(missingHints, hint)
}
}
if len(missingHints) > 0 {
return nil, fmt.Errorf("indexes not found: %v", missingHints)
}
return filteredIndexes, nil
}
if len(excludeHints) > 0 {
remainingHints := excludeHints
for _, index := range indexes {
exclude := false
for i, hint := range excludeHints {
if index.Name == hint {
remainingHints[i] = ""
exclude = true
break
}
}
if !exclude {
filteredIndexes = append(filteredIndexes, index)
}
}
var missingHints []string
for _, hint := range remainingHints {
if hint != "" {
missingHints = append(missingHints, hint)
}
}
if len(missingHints) > 0 {
return nil, fmt.Errorf("indexes not found: %v", missingHints)
}
}
return filteredIndexes, nil
}このように、インデックスを選択する前に最適化ヒントに基づいてインデックスをフィルタするように変更しました。また、存在しないインデックスが渡された場合にはエラーを返すようにしました。
その他の課題について
インターンシップ期間中、この課題を含めて3つのチケットを担当しました。残りの2つについても最後に簡単に紹介します。
QueryQuotaの切り上げ計算の修正
FractalDBには、安定稼働のためにQueryQuotaと呼ばれるトランザクションやIOの制限機能が実装されています。 トランザクションの回数やIOを行ったデータサイズに対して、あらかじめ定めたトークンが消費され、残トークンが0になるとエラーを返します。QueryQuotaの消費トークンを計算するロジックとして次のような実装がされていました。
readToken = readBytes / readTokenUnitizer + 1この実装には、読み出したバイト数が消費トークンの基準値(readTokenUnitizer)の倍数の場合に、トークンが1多く消費されてしまうという問題があります。インターンシップの最初の課題として、このコードを修正し、テストを実装し、チームの方にレビューを頂きました。
整数A、Bの切り上げ除算は(A + B - 1) / Bで計算できます。また、 writeToken の計算についても同様の問題が含まれていたため、修正しました。実装は次の通りです。
readToken = (readBytes + readTokenUnitizer - 1) / readTokenUnitizer
writeToken = (writeBytes + writeTokenUnitizer - 1) / writeTokenUnitizer読み書きを行ったデータのバイト数が��基準値(*TokenUnitizer)の倍数の場合の単体テストを追加し、堅牢性を高めました。
プロトコル圧縮を有効にして接続するとアラートが出る問題の修正
FractalDBはCassandraのAPIプロトコルをサポートしており、datastax/python-driverなどのCassandraクライアントを利用して接続できます。しかしdatastax/python-driverを利用して接続すると、[FRACTAL-RESTRICTION] COMPRESSION is not supported in STARTUPというエラーを返して接続が拒否されます。これはpython-driverがプロトコル圧縮をデフォルトで有効にしているのが原因で、FractalDBのCassandraのプロトコルを実装した内部パッケージがそれをサポートしていないため、接続が拒否されること自体は想定された挙動です。ただし、サーバ側で以下のようなエラーログを出力することが問題です。
2024-09-12T14:49:14.738+0900 ERROR UnhandledError {"error": {"error": "[Server Error] Code=0 Message=\" [FRACTAL-RESTRICTION] COMPRESSION is not supported in STARTUP\""}}FractalDBは本番環境で出力されたErrorログを架電対象にしており、仮に深夜にプロトコル圧縮を有効にした接続が飛んできた場合、誰かがそれを対応しなければなりません。このチケットでは、ErrorログではなくInfoログを出力することで対応しました。
調査
まず、人によってdatastax/python-driver(3.29.2)を利用して接続できる場合もあったため、この問題の再現に取り組みました。
from cassandra.cluster import Cluster
cluster = Cluster(['127.0.0.1'], protocol_version=4, compression=True)
session = cluster.connect()
print(session.execute("SELECT release_version FROM system.local").one())上のようなコードを用いてFractalDBへの接続を試みると、エラーが出力されることなく接続できました。 そこで、原因を探るためにWiresharkを用いてpython-driverがどのようなパケットを送信しているかを調べました。CQL BINARY PROTOCOL v4を確認したところ、プロトコル圧縮がかけられたパケットのヘッダには圧縮済みフラグ(0x01)が立てられていることがわかりました。
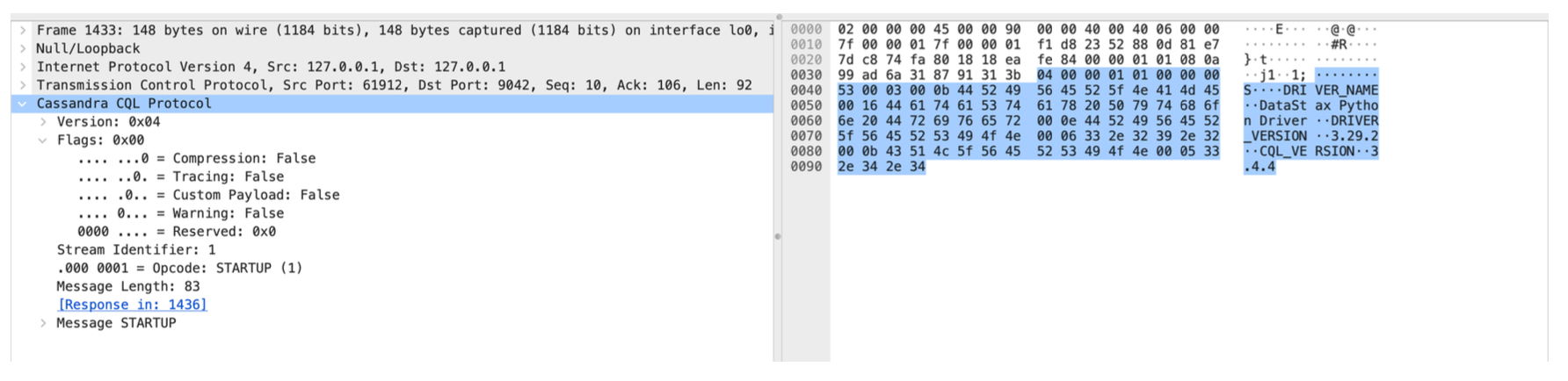
Wiresharkを用いてパケットを確認すると、Compressionフラグが立っていませんでした。すなわち、パケット全体にプロトコル圧縮がかけられていないために接続に成功するようでした。調べると、python-driverはlz4、python-snappy のいずれかのソフトウェアが利用でき、かつプロトコル圧縮が有効になっている場合のみ圧縮をかけることがわかりました。lz4、python-snappyのいずれかを環境に入れて再度接続を試みると接続が拒否され、サーバがエラーログを出力するようになりました。
package main
import "github.com/gocql/gocql"
func main() {
cluster := gocql.NewCluster("localhost")
cluster.Compressor = &gocql.SnappyCompressor{}
session, err := cluster.CreateSession()
if err != nil {
panic(err)
}
defer session.Close()
}Go言語のドライバであるgocql(v1.6.0)でも同様にプロトコル圧縮を有効にすると接続できず、エラーログが出力されることがわかりました。
実装
以下のように、Server Errorではなく不正入力を主張するエラーであるInvalid Errorを返すように変更しました。また、FractalDBがまだサポートしていない、不正な接続オプションを与えた場合にServer ErrorではなくInvalid Errorを返しているかどうかをチェックするテストを追加しました。
- return errors.Server("[FRACTAL-RESTRICTION] " + option + " is not supported in STARTUP") + errMsg := "[FRACTAL-RESTRICTION] " + option + " is not supported in STARTUP"
+ flog.Info(errMsg)
+ return errors.Invalid(errMsg)感想
これまでインフラエンジニアとして働いたことはなく、自分が知らない世界を見たいと思いインターンシップに応募しました。実際に参加して、パケットを調べたり、プロトコルの仕様を調査したり、設計書を書いたりするような、やったことのない仕事に取り組むことができました。FractalDBは規模が大きなソフトウェアで、実体が完全に見えなくても、命名や実装、ドキュメント、コミットメッセージ、過去にマージされたPRなど、少しずつ散らばっているヒントを元に理解していく必要がありました。大変でしたが、とても面白い体験でした。データベースは大学の講義で学んだことで実装に興味を持ちました。また、インデックスヒントの実装はお昼ご飯中にチームの方と雑談で言語処理系の話をしていた際に、それに関係する課題として提案していただきました。思わぬところで繋がることがあり、事前に情報科学を広く学んでおくことの重要性を実感しました。
まとめ
FractalDBに最適化ヒント句を追加し、インデックスヒントによるインデックスの優先度制御を実装しました。この機能によりユーザが使用したいインデックスを明示することで非効率な実行計画の実行を回避することができるようになりますが、実行コストを事前に見積もるCardinality Estimationと比較して現実的な時間で実装することができました。事前に最適化ヒント句の設計書を作成し、チームレビューを受けてから実装を行いました。実装はCQLクエリパーサを変更すること、QICにオペランドを追加すること、QICによる実行計画作成のロジックを変更することの主に3つに分けられました。インターンシップ期間では社内で利用されているORMが最適化ヒント句をFractalDBに渡す前に破棄しないかどうかの調査を行うことができませんでした。また、SELECT文以外の文に対する最適化ヒントの実装も行わなかったため、併せてチームの方に引き継ぎを行いました。メンターの今野さんをはじめとしてチームの方や人事の方にたくさんサポートしていただき、楽しく取り組むことができました。本当にありがとうございました。
インターンシップ担当メンターより
今回のインターンシップで浅田さんを担当した今野です。浅田さん、このインターンシップでのご活躍、本当にお疲れさまでした。
チームとしては、インターンシップ期間が短い中で、設計の必要のない、簡単なタスクだけを担当してインターンが終了してしまうのではないかという懸念がありましたが、最終的にはインデックスヒントの拡張という大きなタスクを実行できたことは、喜ばしい成果です。
インデックスヒントの拡張においては、先行するMySQLやOracle、PostgreSQLなどの既存のデータベースシステムを詳細に調査し、それをFractalDBに適用するための独自のアプローチを考案したことは素晴らしい成果です。
また、QueryQuotaやプロトコル圧縮に関する問題解決においても、積極的に問題を特定し、解決策を実装する姿勢に感心しました。インフラエンジニアとしての経験がない中で、未知の領域に果敢に挑戦し、多くの学びを得たことは、今後の浅田さんのキャリアにとって大きな財産となることでしょう。
チームとのコミュニケーションを通じて、浅田さんの情報科学の広範な知識が実際の業務にどのように活かされるかを体感できたことも、非常に貴重な経験だったと思います。これからもその好奇心と探求心を大切にし、さらなる成長を遂げてください。
本当にお疲れさまでした。そして、これからのご活躍を心より応援しています。