こんにちは。エンジニアの中野です。前回は、私たちが開発している FractalDB: LINEヤフーのオンプレミス・マルチテナンシー型データベースシステムの紹介という記事を公��開しました。
今回は続いて、開発に至った背景とそれからどのようなサービス設計を行ったのか、少し具体的な話をさせていただきます。
課題(FractalDB開発の背景)
社内クラウドDBが欲しい
比較的昔から「パブリッククラウドの"クラウドDB"、例えばAWS DynamoDB(以下DynamoDB)やGCP Cloud Spanner、Microsoft Azure CosmosDBのようなデータベースが社内にも欲しいよね」という漠然とした話はありました。
例えば、DynamoDBを使ったアプリケーション作成は、通常のRDBMSを使ったアプリケーション開発と以下のような違いがあります。
| 普通のRDBMSを使ったアプリ | DynamoDBを使ったアプリ | |
|---|---|---|
| スケール |
|
|
| メンテナンス |
|
|
| 分析/集計処理 |
|
|
クエリ体系が別物なのでRDBMSを置き換えるものでは決してありませんが、DynamoDBを使ったアプリは一度作ってしまえばその後のメンテナンスは比較的楽になるのが特徴として挙げられます。
特にマイクロサービスのようにアプリケーションの責��任を小さく分割している場合は、DynamoDBのようなシンプルな操作で十分である場合が多くなるため、DynamoDBの弱点の影響をあまり受けず、メリットを享受できるため相性が良いです。
LINEヤフー社内にもKubernetes環境(ZCP)、 ZAPのようなアプリケーション実行基盤や、Function as aserviceの環境が整備が整ってきたこともあり、データベースプラットフォームとしてもそれらと相性の良い、すぐ使えて手間がかからず、スケールするDBMSがあるべきと考えていました。
社内運用の課題
LINEヤフーではMySQLやApache Cassandra(以下Cassandra)、RedisをDatabase as a Serviceとして既に社内に対して提供していて、社内のDB利用者は比較的簡単にDBを構築・運用・利用できる環境が既に整備されています。
これらはそれぞれのDBMSを構築して運用するものですので、どうしても解決が難しい課題がいくつか残っていました。
- 整合性とスケーラビリティを同時に実現するのは難しい
- これ自体を解決できるソフトウェアは比較的多く存在しますが、続く2つの課題やその他の基準と照らし合わせると選択肢が多くはない状態でした。
- 集約率の問題
- DBのインスタンスのすべてがフル稼働しているわけではありません。その余力を集めると全体として相当量のリソースの余剰がある状態でした。
- もし仮に1つのクラスターに全ユーザーを収容できるのであれば、80%を超えるコスト削減が試算によって見込まれていました
- 正直この試算がFractalDBが始まる決定打となりました
- DB利用者、DBAの運用�負荷が高い
- 現状でも自動化によって平時の運用負荷は十分低く抑えられていますが、構成を変える必要がある場合の負荷の低減が難しいという課題がありました。
- DBMSのバージョンアップ
- ハードウェアのライフサイクルによる移設
- これらはDBAとアプリケーション開発者の連携が必要で、双方にある程度の負荷がかかります。
- これが数百、数千と積み重なると非常に大きなコストとなります。
- 現状でも自動化によって平時の運用負荷は十分低く抑えられていますが、構成を変える必要がある場合の負荷の低減が難しいという課題がありました。
既存の解決策では解決出来ない課題
最初の目標を達成するだけなら選択肢はたくさんあります。"NewSQL"という単語で代表されるような、書き込みにスケーラビリティを持ちつつも、整合性、さらにはSQLが利用できるソフトウェアはパブリッククラウド上、製品、またはOSSにも存在します。
ただ、私たちのチームではプラットフォームとして会社全体に提供するのを目的にしています。そのため、社内の多くのアプリケーションから依存されても問題ない製品を選定する必要がありました。
- 費用がなるべく低いこと
- 長期的なメンテナンスが見込まれるもの、コミュニティが開かれていて活発なこと
- ライセンスや開発主体に対する懸念がないこと
これらは通常アプリケーションのDBMSを選定する際にはあまり問題にはなりません。LINEヤフーでもサービスが必要と判断すれば個別専用のクラスターとして準備する場合もあります。
ただ、プラットフォームとして社内に提供した場合、数百のインスタンスが作られ数百のアプリケーションから依存されます。その上で十年�単位で維持するためにこれらの要件を通常よりは考慮しました。
Cassandraの課題
これらに加えて、現在社内に提供しているCassandraにもいくつか課題がありました。
- 利便性
- セカンダリインデックスの課題
- 結果整合性によって問題となるケースがあること
- 拡張性
- 特定のKeyをSplitし、スケールアウトすることができない
- 運用面
- Compactionの処理の関係でディスク容量を活用できない
- Java GC 発生時に高負荷となる
- 大容量のクラスターではRepair処理をgc_grace_seconds以下で常に完了させることが運用負担となる
互換性の問題や、ある程度トレードオフになってしまう課題もあるため、社内利用者が純粋なCassandraか、FractalDBかを選択できるようになっています。FractalDBは主キーのスキャンができたりセカンダリインデックスが使える等、Cassandraに比べて"MySQLに近い使用感"なCassandra互換DBMSになっています。
実現可能性
DBMSのすべてを内製するのはチームの規模的にも現実的ではありませんでした。
そんな中、FoundationDBがLayered Architecture (参考:Document Layer)という概念を提唱しました。これはトランザクションが使えるスケーラブルなKVSであるFoundationDBを使って、その上でクエリ処理をFoundationDBユーザーが実装することを前提とした設計です。
実際、このような疎結合なDBMSの設計は近年よく見られるようになってきていて、それぞれレイヤーの分け方は違いますがGCP CloudSpannerやAmazon Aurora、TiDB等も1つのクエリを�処理するのに、役割の違う複数のサーバーが担当する設計になっていて、この設計が一般的となっていることも後押ししました。
DBMSの開発において、難しいポイントの1つであるデータの保存をFoundationDBにすべて任せてしまい、われわれが開発するのはデータを保存しない、ステートレスなAPIサーバーのみとできます。これによって、比較的小さいチーム規模で開発・運用できるめどが立ちました。

ここまでのまとめ
まとめると、FractalDB開発の契機となった主な理由は以下の通りです。
- きっかけとなった課題
- クラウドDBの実現
- 整合性とスケーラビリティの両立
- 集約率を向上
- 運用の負荷を軽減
- 現行のCassandraの課題
- 後押しした実現可能性
- FoundationDBを活用したLayered Architectureの可能性
アーキテクチャの詳細
これらの目標を達成する上で、まずFractalDBのアーキテクチャを FractalDB: LINEヤフーのオンプレミス・マルチテナンシー型データベースシステムの紹介より少し深掘って紹介します。

��アーキテクチャ: 全体的な動作
FractalDBはいわゆるAmazon AuroraやGCP Cloud Spannerでも採用されているものと似ている「Compute/Storage分離」を採用していて、それぞれ以下の機能を持っています。
- クエリクラスター: Compute層
- ユーザーからクエリを受け取って処理します
- クエリを処理し、ストレージへの操作へ変換します
- 例えば「INSERTクエリが来たら、PUTに変換する」、「SELECTクエリが来たら、GET/SCANに変換する」のような処理です
- ストレージクラスター: Storage層
- データの保存を行います
- APIとしては基本的にキーがバイナリー、値もバイナリーのシンプルなKey-Value Storeです
この2つの「複雑な操作をするが、ステートレスなCompute層」と「シンプルな操作しかできないが、ステートフルなStorage層」で構成されています。
Compute/Storage分離のメリット
FractalDBにおけるCompute/Storage分離を採用した理由は、以下のようなものがあります。
- ComputeとStorageを別々にスケールできる
- ワークロードの変化に柔軟に対応でき、データ容量だけ増やしていくことも簡単です。
- 運用をシンプルにできる
- Storageの運用影響をユーザーから隠すことができる
- Storage層がネットワーク的にクライアントから接続されていないので、例えばStorage層のノードが不意にシャットダウンしてもその影響をCompute層で隠蔽(いんぺい)できます。
アーキテクチャ: クエリクラスター
DBMSの内部を大まかに分類したとき、主にクエリパーサー、クエリエンジン、トランザクションエンジン、ログ、ストレージエンジンの5つで構成されているとします。MySQLやPostgreSQLはこれらが1つのプロセス内に収まっていて、Cassandraも複数ノードにまたがっていますが、それぞれのノードの1プロセスにこれらすべての機能が収まっています。
対してFractalDBでは複数プロセスにこれらが分離していて、クエリクラスターはこのうち、クエリパーサー、クエリエンジンの処理を行っていて、それ以外は後述するストレージクラスター(つまりFoundationDB)が行っています。
モジュラーな設計
FractalDBは長期的な環境変化に対応するために、複数のクライアントプロトコル、複数のバックエンドストレージに対応できるように設計されています。
FractalDBのクエリ処理は大まかに3モジュールで構成されていて、フロントエンド、クエリエンジン、バックエンドの3つで構成されています。
- フロントエンド
- クライアントからクエリを受け取ってパース、クエリエンジンの中間表現に変換します
- 現在はCassandraプロトコル(CQL)に対応しています
- クエリエンジン
- 中間表現を受け取って、実際にストレージエンジンで行う処理(物理プラン)を決定します
- バックエンド
- 物理プランを実行します
フロントエンドとバックエンドは徐々に対応を増やすことができるように設計されていて、例えばフロントエンドは現在Cassandrav3が実装されていますが、この上にCassandra v4, v5を実装するだったり、バックエンドもFoundationDB以外も対応できるようになっています。

Cassandra(CQL)をターゲットにした理由
FractalDBの企画段階ではMySQLやMongoDB、GraphQL等もアクセス用APIとして候補に挙がっていました。その中でもLINEヤフーの社内一般に最も需要が高いのはMySQLです。ではなぜMySQLをターゲットにしなかったのかというと、十分な互換性を確保する難しさがあったからです。
まずそもそも、MySQLと十分に互換性の高いクエリエンジンを実装するのはとても大変ということがあります。そのほかにも性能面において、FoundationDBをストレージに採用するのであれば、OLAPに近いクエリでは性能それほど良くないことが予想されます。この結果、機能・性能がMySQLと乖離(かいり)してしまい互換性が低下した結果、FractalDB利用者の「がっかり」につながってしまう恐れがありました。
互換性が低ければ既存の利用者に「今使っているものの代わりにFractalDBを使って」と言うのが難しくなります。結果、利用を広げにくい他にも仕様の違いによる障害などの問題が発生する恐れがあり、初期にMySQLを実装することは見送られました。
代わりにCQLはある程度社内利用者がいる上、OSSとして各種ツールもそろっています。さらにFractalDBの性能特性と近いため互換性がある程度高いものが実現できる見通しでした。その後Cassandra独特の接続仕様に四苦八苦するのですが、それはまた別の話。
まずはCassandraを実装してFractalDBはどのようなものなのかを社内のユーザーに知ってもらった上で、そのほかのプロトコル、例えばMySQLやMongoDBといったものの対応を目指していきたいと思っています。
簡素なクエリエンジン
CQLであれば基本的なクエリのIO特性はFoundationDBの性能特性と非常に近いものとなっている上、クエリエンジンが簡素なもので良いというメリットがありました。
クエリエンジンは簡単なものは簡単ですが、作り込むとなるととても奥深いものです。MySQLのクエリエンジンは当然複雑で、初期に作るのは現実的ではないと考えられたからです。CQLであれば、FoundationDBのトランザクション機能とKVSの機能を活用できるので、それほど複雑なものは必要ありません。
ステートレス
クエリクラスターはステートレスに設計できていて、以下のメリットが生まれています。
- Kubernetes上で運用しやすい
- StatefulSetやOperatorを使うことなく、通常のDeploymentとして動作させられるので、運用が容易です。
- 開発の難易度が難しくならない
- クエリクラスターはクエリを受け取ってFoundationDBを操作するのが主な動作なので、これは結局「HTTPリクエストを受け取ってDBを操作する」通常のWebアプリケーションとHTTPがCQLに変わっただけで大きく変わりません
- Goで一般的なWeb APIサーバーが開発できれば、FractalDBの開発に参加できるように設計しています
アーキテクチャ: ストレージクラスター
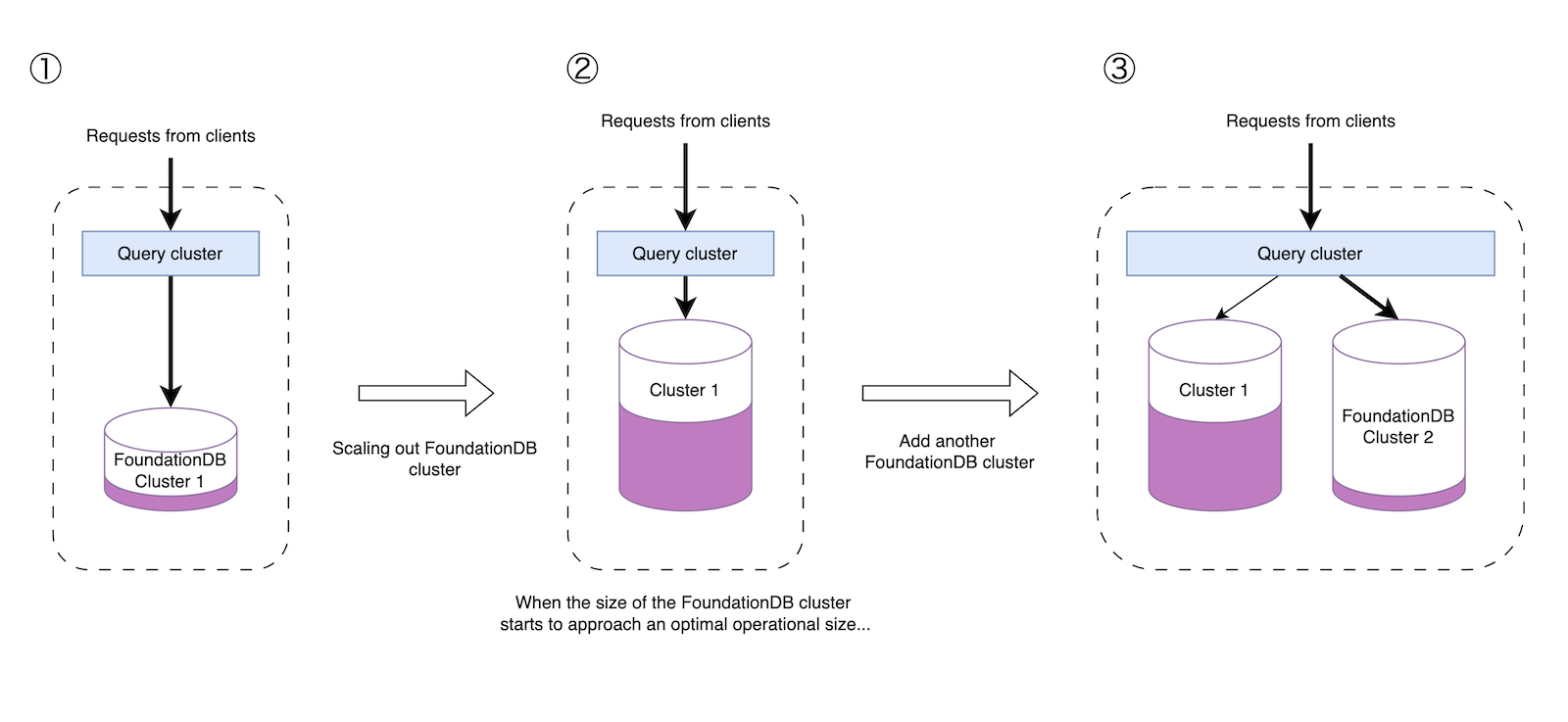
ストレージクラスターは実際にデータを保存するサーバー群です。現状FoundationDBやBadgerDBを実装していますが、実際に運用しているのはFoundationDBのみです。
FoundationDBは数百台規模までスケールするスケーラブルなKey-ValueStoreですが、FractalDBはそのFoundationDBクラスターを自由な数持てるようになっています。(上図で"Storage clusters"が複数あるように表現されているのはそのためです)
ユーザーのデータが増えた場合はまずFoundationDBクラスターをスケールアウトしますが、ある程度のサイズになったらさらにFoundationDBのクラスター自体を増やすことで、システム全体としては非常に大きなスケール性能を持てるようになっています。
余談: FoundationDB vs TiKV
FractalDBのバックエンドとして最終的な候補に残っていたのがFoundationDBとTiKVです。以下の3つの理由で最終的にはFoundationDBが採用されました
- ソフトウェアとしての設計思想
- FoundationDBはFractalDBのようなレイヤーを追加することを前提とした設計がされています。今後FoundationDBへ機能の要望を挙げる場合にも、彼らの目標とわれわれの目的が一致する可能性が高いです。
- 書き込みレイテンシの安定性
- TiKVでは複数シャードにまたがる書き込みはRaft+2PCで行われるため、1シャードの場合と比べレイテンシにばらつきが出ます。対してFoundationDBは書き込みは内容によらず同じ方法で行われるので、どんなトランザクションもある程度一定のレイテンシで捌けることが期待されます。
- レイテンシの絶対値としてはTiKVが低いケースもありましたが、どんなクエリでも安定したレイテンシが期待できる方を優先しました。
- TiKVでは複数シャードにまたがる書き込みはRaft+2PCで行われるため、1シャードの場合と比べレイテンシにばらつきが出ます。対してFoundationDBは書き込みは内容によらず同じ方法で行われるので、どんなトランザクションもある程度一定のレイテンシで捌けることが期待されます。
- FoundationDBのスケール上限が問題にならない見込みだった
- FoundationDBはTiKV程のス�ケーラビリティがないことが想定されています。ただしFractalDBは複数のFoundationDBを内部に持てるように設計されているので、1つのFoundationDBですべてのFractalDBのデータを処理できる必要はありません。
- それにあまりに大きなクラスターは運用が大変です。運用しやすい"ちょうどいい"サイズのクラスターを考えたときに、FoundationDBのスケール性能は十分でした。
- FoundationDBはTiKV程のス�ケーラビリティがないことが想定されています。ただしFractalDBは複数のFoundationDBを内部に持てるように設計されているので、1つのFoundationDBですべてのFractalDBのデータを処理できる必要はありません。
ただし、FractalDBは複数のストレージエンジンに対応できるように設計しています。なので、将来的にTiKVも同時に動作できるようにする可能性は十分あります。TiKVのFoundationDBを超えるスケーラビリティは魅力的で、そのようなワークロードが必要になったら採用する予定です。
FoundationDBの機能の活用
FractalDBはDBMSとして基本的な機能をFoundationDBを使って実現しています。例えば以下のようなものがあります
- トランザクション機能
- データの永続化・冗長化
- データのリバランス
- ノード障害時の対応
- マルチリージョン対応
- バックアップ
これらの機能はFractalDBで実装しているわけではなく、FoundationDBの機能を使って実現しています。
FractalDBの設計目標の達成
このアーキテクチャを使って、どのように設計目標を達成するか説明します。
| 目標 | 解決する課題 | 具体的な目標 | FractalDBの解決方法 |
|---|---|---|---|
| 安全性 | 整合性とスケーラビリティの両立 | スケーラブルでかつ、整合性を備えるDBを実現する | FoundationDBの特性 + FoundationDB自体を増��やせるように設計。 |
| 拡張性 | クラウドDBの実現 | すぐに使えて、使っただけのコストがかかるDBを実現する | Cassandraのクラスターをソフトウェアとして実装 |
| 効率性 | 運用コスト | 利用者の運用作業(DBやOSのバージョンアップ等)を不要にする | Compute/Storage分離 + 共通クエリエンジン |
| 効率性 | 集約率 | リソースの集約率を高める | マルチテナントの採用 |
| 互換性 | 移行のしやすさ | 既存のCassandraと高い互換性と移行性を実現する | Cassandra互換プロトコルの実装 |
スケーラブルでかつ、整合性を備えるDBを実現する
これはほぼFoundationDBの採用によって達成されています。FoundationDBはスケーラブルかつ整合性のあるデータベースですので、その機能をそのまま使用しています。
さらにその上先述の通り、FoundationDBを複数持てるようにすることで、システム全体としてはとても大きなスケーラビリティを確保しています。
すぐに使えて、使っただけのコストがかかるDBを実現する
FractalDBはCassandra互換のDBMSですが、Cassandraクラスターは論理的に実現されています。つまり、クラスター作成時に物理的なリソース(VM等)を作成するのではなく、クラスターの情報をメタデータに書き込むだけで�論理的なクラスターが作成されます。
これによって、以下の特性を実現しています。
- 1秒未満でクラスター作成ができる
- 数qpsの小さなクラスターから、数万qpsのクラスターまで無駄なく実現できる
利用者の運用作業(DBやOSのバージョンアップ等)を不要にする
FractalDBの社内利用者が接続するのはクエリクラスターで、ストレージクラスターの運用状態は隠蔽(いんぺい)されます。例えば、物理的な位置を移動させる場合や、OSや各種ソフトウェアのバージョンアップを行う場合でも、それらの影響はクエリクラスターによって吸収されるので、ユーザー側への影響を最小限に抑えることが可能です。つまり、OSやDBMSのバージョンアップ作業があったとしても、FractalDBの利用者はそのことに気づくことがないようになっています。
リソースの集約率を高める
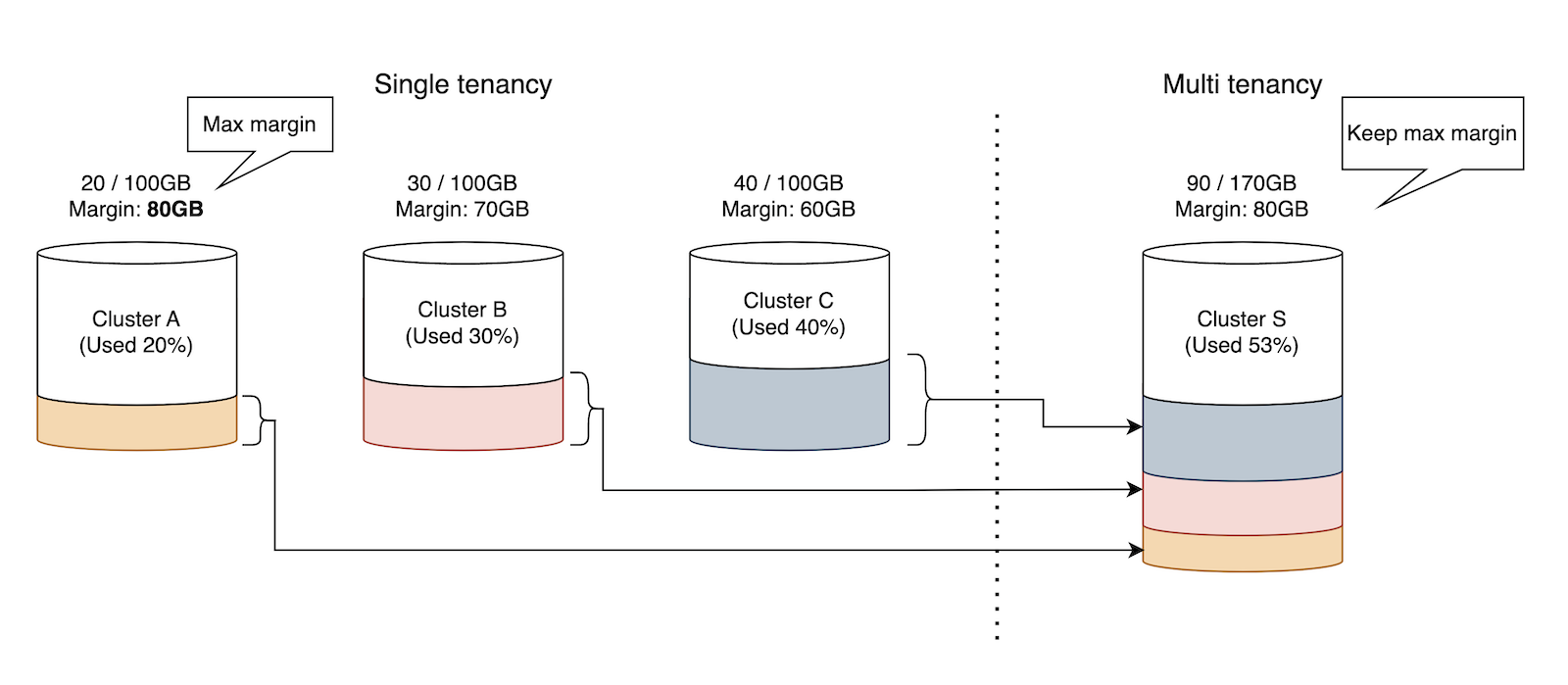
FractalDBはマルチテナントを採用しています 。FractalDBでは各データベースインスタンスはソフトウェアによって実装されていて、物理的なリソースは共有されています。
Cassandraで個別にクラスターを立てる場合、各クラスターに"余裕"を持たせる必要がありますが、マルチテナントであるFractalDBでは持つべき"余裕(マージン)"をFractalDBの利用者間で共有させることによって全体最適化を行える見込みでした。事前の試算では80%を超えるコストの圧縮効果が期待できることがわかっていました。
ノイジーネイバーの問題が発生する可能性がありますが、ソフトウェア的に互いが影響が出��ないような仕組みを実装するとともに、どうしてもソフトウェア的に影響を分離できない場合にハードウェア的に分離する方法も用意してあります。
例えば以下の図では、3つのクラスターを1つのクラスターに集約する例を表現しています。すべてのデータを収めつつ、マージンは既存のクラスターのうち最大のものを確保すると結果システム全体としては効率化を目指せます。この例では3クラスターの集約ですが、数十、数百のクラスターを集約すれば数に応じてこの効果はさらに増加します。
既存のCassandraと高い互換性と移行性を実現する
互換性についてはFractalDBはテストオラクルを用いたテストを始め、fuzzing等たくさんの方法でテストを行っていますが、テストについては今回は割愛させていただきます。
また、移行性についてもオンラインで既存のApache Cassandraクラスターを移行させることができる機能を実装し、管理WebUIに組み込んで提供していますが、こちらも今回は割愛させていただきます。
これらの話題については次回以降のLINEヤフー Tech Blog記事で紹介できればと考えています。
おわりに
FractalDBプロジェクトがなぜ始まり、どのような設計となっているのか大まかに説明させていただきました。今後もFractalDBチームではDBMSの課題を少しずつ解決するべく、開発を続けていきたいと思っています。
最後に一言、FoundationDBは��いいぞ。


