LINEヤフーで機械学習エンジニアとしてプロダクトの開発に携わる佐藤怜が、機械学習分野のトップカンファレンスであるNeurIPS 2024に現地で参加しました。本稿では、現地の様子や佐藤らが発表した論文、そして注目しているLLM関連の採択論文を紹介します。
NeurIPS 2024の概要
NeurIPSは毎年12月に開催される機械学習分野のトップカンファレンスです。2024年はカナダのバンクーバーで現地時間12月10日から15日にかけて開催されました。採択率は25.8%と例年通りの水準でしたが、投稿件数は年々増加しており、2024年は前年比+26.9%の15,671件の投稿がありました。
会議のトレンドをつかむために、論文内での頻出キーワードの上位5件を以下に示します(参考):
- Large Language Models
- Reinforcement Learning
- Diffusion Models
- Graph Neural Networks
- Transformer
トップは予想通りLLMで、会場内のあちこちでLLMに関する発表を見つけることができました。Diffusionは2023年に急上昇したキーワードであり、2024年のNeurIPSでも引き続き人気がありました。その他の3キーワードについても近年のトレンドを引き継いだものといえます。
会議のフォーマット自体は2年前に参加したNeurIPS 2022と大差ありませんでしたが、今年は3日間にわたる計6回のポスターセッションで4,000件を超える論文が発表されるとあって、ポスター会場を歩き回るのには苦労しました。1回のポスターセッションは3時間で、一見十分な時間に思えますが、全体を見て回るには決して長すぎるということはありませんでした。
会場の様子



現地参加の目的
佐藤が著者に名を連ねる論文: Stepwise Alignment for Constrained Language Model Policy Optimizationが本会議に採択されており、このポスター発表で他の参加者に研究を宣伝することが主な参加目的です。また、会場で共有される大量の情報に触れて、今後の業務に役立ちそうな情報を持ち帰ることも目標でした。
後者に関しては「オンラインで採択論文を眺めるだけでも達成できそうでは?」という声も聞こえそうですが、(1)一定期間他の業務から隔離された状態で、(2)視界に大量のポスターが目に入る会場で、(3)著者から説明を聞ける、という恩恵を生かすことで、未知の研究とのより質の高い出会いがあると感じました。実際に出会った研究については後の章で紹介します。
また、必ずしも今後の業務やキャリアに役立つとは限りませんが、有名研究者や企業の創業者と話す機会を得られるのも現地参加の魅力だと思います。
発表した論文: Stepwise Alignment for Constrained Language Model Policy Optimization
佐藤が共著に入っている論文: Stepwise Alignment for Constrained Language Model Policy Optimizationについて簡単に紹介します。
昨今隆盛を極めている対話型のLLMでは、ユーザーにとってどれだけ有益な情報を提供できるかの指標であるhelpfulnessに加え、どれだけ有害な情報の提供を防ぐかというharmlessnessも重要な指標です。この両方を最大化するようなLLMのpreference tuningは、harmlessnessを一定以上にする制約のもとでhelpfulnessを最大化する制約付き最適化問題として定式化できます。これまでSafe RLHFがこの設定に取り組んでいましたが、2つの指標を評価する関数を学習したのち、これを最大化するように強化学習でLLMを学習する従来のRLHFのフレームワークであり、最適化が不安定で煩雑であるという課題がありました。
われわれの提案手法では、はじめにLLMをhelpfulnessに対して最大化するpreference tuningを実施し、次にこの学習結果のLLMに対してharmlessnessを最大化する学習を実施します。これらの各ステップはDPOと呼ばれる、RLHFと等価でありながらより安定した教師あり学習手法を用いることができるので、Safe RLHFより簡便で安定した学習プロセスとなります。
問題は、このstepwiseな学習手順がはじめに定義した制約付き最適化と等価なのか、という点です。そして、理論的な解析によってこの問いにポジティブな答えを出しているのが、この研究の最大の貢献です。結果としてSafe RLHFと同様の問題に取り組みながらも、二指標のトレードオフが改善されることが実験で確認されました。
こ�の論文は現地時間12月11日の午前11時から午後2時にかけて3時間のポスター発表枠を与えられ、私を含む3人の著者で聴講者への対応を行いました。結果として、聴講者への説明や質問への回答、そこから発展する雑談などを、3人が個別に2時間半前後行っており、非常に盛況だったといえる状況でした。実際に言葉を交わした聴講者はほとんどがRLHFやDPO(NeurIPS 2023のBestPaper)などの前提知識を有しており、発表論文が土台とするLLMのアライメント分野への高い関心が伺えました。

他の参加者の発表
ここからは、実際に手を動かして試してみたくなる手法であったり、新たな研究や検証のベースラインとしてふさわしいと感じた、LLMに関連する採択論文をピックアップして紹介します。
Adaptable Logical Control for Large Language Models
- 著者: Honghua Zhang, Po-Nien Kung, Masahiro Yoshida, Guy Van den Broeck, Nanyun Peng
- URL: https://openreview.net/forum?id=58X9v92zRd
この論文では論理制約(e.g., 指定された長さの回答、特定のキーワードを含む回答)を満たすようなLLMの生成を目的としたCtrl-Gを提案します。
Ctrl-GではLLMの追加学習は行わず、tokenの生成時に生成確率を操作するアプローチを取ります。具体的には、位置までのtoken列を用いて、位置のtoken をから生成することを繰り返すことで論理制約を満たす文章を生成します。この生成確率はと変形できます。ここで、は通常通りLLMで位置のtoken生成を行う確率である一方、はこの問題設定に特有で計算方法は自明ではありません。
この手法の本質であるを計算する方法の概要だけを説明します。提案手法ではまずLLMをHMM(Hidden Markov Model)で近似します。HMMでは、はその時刻の隠れ状態にのみ依存し、は前の時刻の隠れ状態にのみ依存します。Decoder-onlyのTransformerを用いたLLMではこの性質は成り立ちませんが、HMMで近似することで、効率的にtoken列に関する同時確率を計算できるようになります。同時に、論理制約をDFA(Deterministic Finite Automaton)で表現します。これは実質、論理制約が正規表現を判定する形であることを要請しています。この二つの比較的小さな状態空間を持つ状態遷移グラフを組み合わせ、ある種総当たり的に確率を計算することで、現実的な時間でを計算するのがこの論文の提案の中心になります。
実験では、複数のキーワードを含むような文章や、指定された範囲の長さの文章を、100%の確率で生成できたことが報告されています。
On Softmax Direct Preference Optimization for Recommendation
- 著者: Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, Tat-Seng Chua
- URL: https://openreview.net/forum?id=qp5VbGTaM0
この論文ではLLMを用いた推薦システムにおいて、1つの正例に複数の負例が紐付くデータセットが得られる状況で利用できるS-DPOを提案します。
歴史的にはgenerativeなLLMを用いた推薦システムでは、ユーザーの行動系列を自然言語で表現したプロンプトと、そのユーザーが選好したアイテムのペアを用いて、に続いてを出力する確率を上げるsupervised fine-tuning(SFT)によるLLMの訓練が行われてきました。また、RLHFやDPOの開拓により、とに加え、より選好されないアイテムを用いて、に続いてが出力される確率を上げつつ、が出力される確率を下げるpreference tuningも利用できるようになりました。
対して推薦システムでは、正解データは「複数のアイテム候補から1つを選択した」というように、1つの正例に複数の負例が紐付く形式であるケースがあります。このような形式からサンプリングして1対1のデータに変形することはできますが、直接1対Nのデータを扱える手法を考えることで学習が改善される、というのが著者ら主張です。
手法の概要をもう少しだけ詳しく説明します。DPOではがを優越する確率、つまり2つの候補を選考度合いに従って並べたランキングが生成される確率をBradley-Terryモデルで表現します。S-DPOでは候補の数をNに一般化して考え、Plackett-Luceモデルでランキングの生成確率を表現します。このようなモデリングでもDPOに類似の勾配が導出できるのですが、DPOと比較して (1)正例に対して負例の選好度合いが健闘している場合に、正例の生成確率を上げる勾配と負例の生成確率を下げる勾配が大きくなり、(2)ある負例の選好度合いが他の負例に対して劣っている場合に、の生成確率を下げる勾配を小さくするといった重みが出現しており、これがより効率的な学習を達成すると解釈されています。
実験では推薦タスクにおける評価で、SFTやDPOに対してより高い推薦性能を獲得したことが示されています。
Customizing Language Models with Instance-wise LoRA for Sequential Recommendation
- 著者: Xiaoyu Kong, Jiancan Wu, An Zhang, Leheng Sheng, Hui Lin, Xiang Wang, Xiangnan He
- URL: https://openreview.net/forum?id=isZ8XRe3De
この論文ではLLMを用いた推薦において、ユーザークラスタにつき異なるLoRAを1つ学習することで推薦精度を改善するiLoRAを提案しています。
この手法が扱う問題設定では、ユーザーが時刻までにインタラクションしたアイテム列を記述したテキストを入力し、時刻でインタラクションしたアイテムの記述を出力させるinstruction tuningを実施します。学習済みのLLMをfine-tuningする際には、LoRAを用いることで計算コストを削減できます。iLoRAではLoRAで学習する行列をユーザークラスタの数に分割することで異なる行動傾向のあるユーザークラスタが混じり合う場合でも効率的な学習を実現しています。手法は以下のように構成されます: (1)ユーザーの行動系列をより小規模でシンプルな推薦モデルに入力しvector を抽出し (2)を計算します(は学習可能なパラメータで、はLoRAの分割数と一致する次元を持つattentionベクトルです) (3)分割されたLoRAのそれぞれの出力をで重み付けて最終的な結果を計算します。
実験では、有効な出力が得られる確率: ValidRatioと、正解と関連する出力が得られる確率: HitRatioを確認しており、ValidRatioが1.0かつHitRatioが向上したことを報告しています。
Optimal Design for Human Preference Elicitation
- 著者: Subhojyoti Mukherjee, Anusha Lalitha, Kousha Kalantari, Aniket Anand Deshmukh, Ge Liu, Yifei Ma, Branislav Kveton
- URL: https://openreview.net/forum?id=cCGWj61Ael
この論文では、少ないアノテーションコストでより高い精度で報酬関数を推定するためのアノテーション戦略について議論しています。
昨今のLLMのpreference tuningでは、あるプロンプトに対して二つの回答のどちらが好ましいかを人間にアノテーションさせたデータを利用します。このアノテーション作業を一般化すると、1度のアノテーションにつき、(1)L個のアイテムリスト(各アイテムリストのサイズはK)から1つを提示され (2-a)K個のアイテムに対して絶対スコアを与える (2-b)あるいは、K個のアイテムを評価順に並び替える作業だといえます。最終的に、L個のリストの各K個のアイテムを全て正しい順序に並び替えるのが目標です。
このアノテーション作業は一見、L個のリストを順番に提示すれば終わる作業に思えますが、アイテムの順序を決定する真の報酬が、アイテムの特徴ベクトルと重みを使って、という線形な報酬関数で表現できる場合にはどうでしょうか。この場合、を推定することでアイテムの順序を決定できるため、より少ないアノテーション回数で高い精度でを推定することが重要になります。この論文では、高速に解ける凸最適化を各アノテーションステップで実施することで、上記を達成するために最適なリストを選択するエージェントを提案しています。このアルゴリズムには近似誤差の上界が理論的に保証されているというメリットがあります。
BAdam: A Memory Efficient Full Parameter Optimization Method for Large Language Models
- 著者: Qijun Luo, Hengxu Yu, Xiao Li
- URL: https://openreview.net/forum?id=0uXtFk5KNJ
この論文ではメモリ消費の少ないLLMのfine-tuning方法を提案しています。
通常、パラメータ数がMのLLM全体をAdamでfine-tuningするのに必要なGPUメモリは18Mバイト(パラメータが16bitで2Mバイト、Optimizerの勾配と1次・2次のモメンタムがそれぞれ32bitで16Mバイト)とされています。一方、LoRAを用いたfine-tuningではメモリ消費を抑えられますが、学習後のモデル性能が十分でない可能性があります。
本稿で提案されるBAdamは、メモリ消費を抑えつつモデルパラメータ全体のfine-tuningを可能にします。
BAdamではモデル全体をD個のブロック(例えばTransformerのブロック単位)に分割し、あるイテレーションではこのうち1ブロック分のパラメータだけをAdamで更新します。メモリ消費はAdamのOptimizerが保管するモメンタム等が多くを占めるので、Optimizerが同時に管理する対象パラメータを1ブロックに削減することでメモリ消費を抑えるのが根本のアイデアです。また、更新対象のブロックより入力側までbackwardを計算する必要がないため、1イテレーションあたりのbackwardコストはAdamに対して1/2程度になります(ただし、1イテレーションで更新できるパラメータは1ブロックに限られます)。
BAdamのメモリ消費は2M+16M/Dで、Adamの18Mから大きく削減されています。収束性に関する理論補償を提供している点も大きな貢献です。
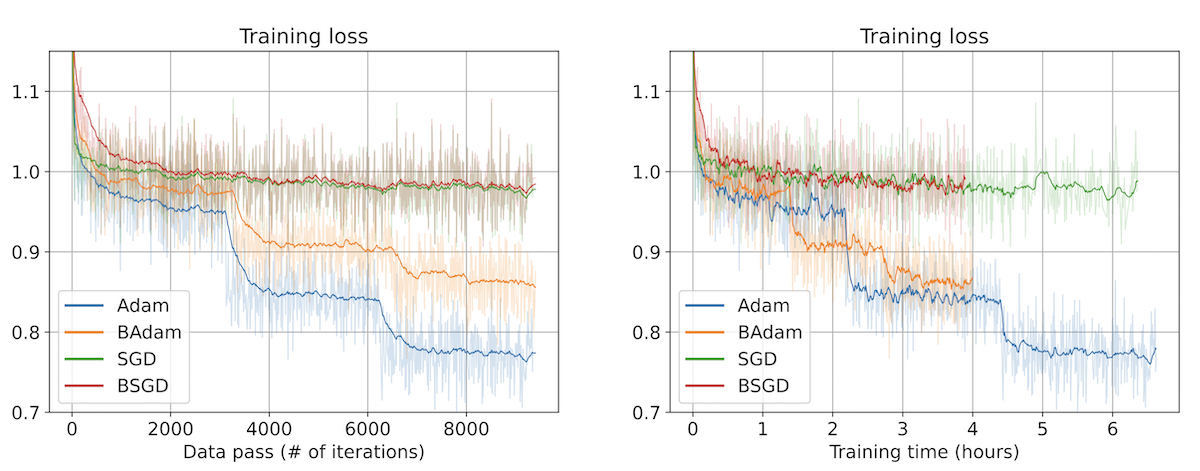
上図はBAdam��の実験結果で、左のグラフでは同イテレーションで比較した場合にBAdamがAdamに対してlossの減少ペースが劣っていることが示されています。これは、BAdamが1イテレーションで更新できるパラメータが1ブロック分に限られていることに起因します。一方で、右のグラフで同計算時間で比較した場合には、Adamに近いペースでlossが減少していることがわかります。これはBAdamの1回のbackwardにかかる時間がAdamの1/2程度であることに起因します。
ちなみに、NeurIPS 2024ではLISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuningという論文が発表されています。この論文でも一部のパラメータをフリーズしながらモデル全体を学習することでメモリ消費を削減するLLMのfine-tuning手法を提案しており、BAdamによく似た提案だといえます。
Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
- 著者: Wenyu Du, Tongxu Luo, Zihan Qiu, Zeyu Huang, Yikang Shen, Reynold Cheng, Yike Guo, Jie Fu
- URL: https://openreview.net/forum?id=FXJDcriMYH
この論文では、大規模LLMの事前学習の高速化を目的としたmodel growthの検証結果を報告しています。Model growthは学習中にレイヤを段階的に追加し徐々にモデルを大きくしていく手法です。検証では、(A)レイヤをそのまま複製して追加する (B)HyperNetworkで生成したレイヤを追加する (C)重みをゼロ初期化したレイヤを追加する (D)重みを乱数で初期化したレイヤを追加する の4パターンを検証しています。また、パラメータを水平方向に追加する(既存のレイヤに追加する)と垂直方向に追加する(新しいレイヤとして追加する)も検証しています。実験では、400MのLLMを10B token学習してからmodel growthを一度適用して1.1Bのモデルに拡張し、追加で97.5B token学習します。垂直方向のレイヤの追加は、モデル(例えば2層のモデル: L1 - L2)をレイヤ単位で繰り返す(L1 - L1 - L2 - L2)のではなく、モデル全体を繰り返す(L1 - L2 - L1 - L2)方法で行います。
下図に実験結果を抜粋して示します。
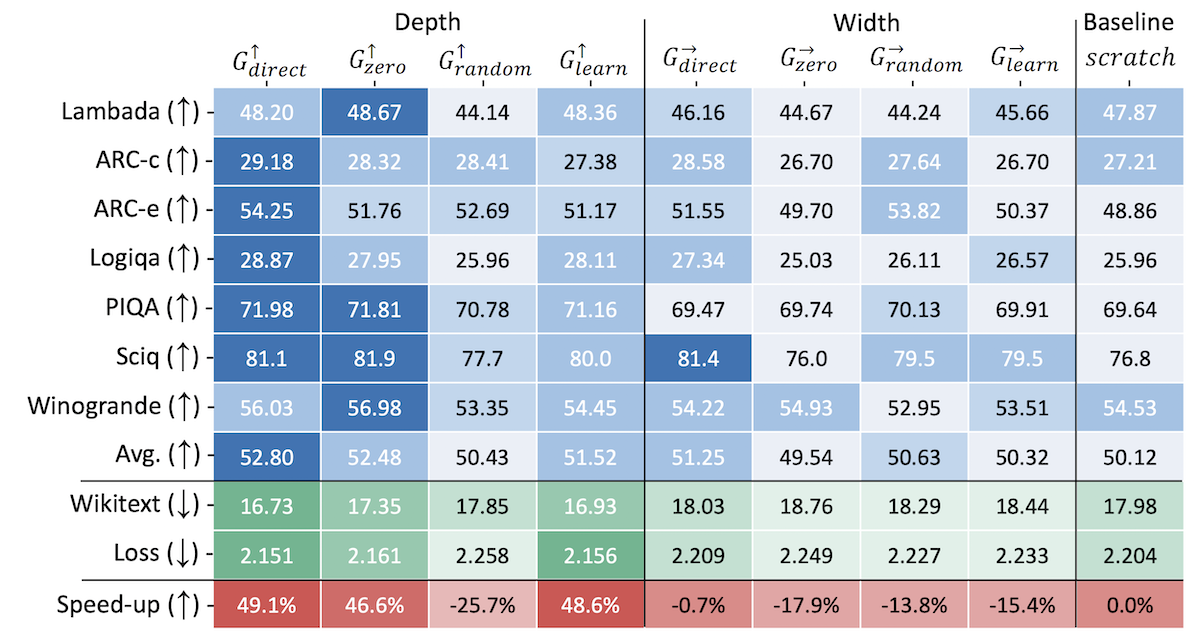
結果として、レイヤを垂直方向に複製する場合(最左列)に、モデル全体をfrom scratchで学習する場合(最右列)と比較して、同じlossを達成するまでの速度が49.1%上昇(Speed-up行)したうえ、同程度のFLOPsで学習した際の最終的な精度も改善されました。
Not All Tokens Are What You Need for Pretraining
- 著者: Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, yelong shen, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, Weizhu Chen
- URL: https://openreview.net/forum?id=0NMzBwqaAJ
昨年のBestPaperであるDPOが今年大流行していたこともあり、今後のトレンドになる可能性がある今年のBestPaperのRunner-up(ベスト4)に選ばれた論文を紹介します。
この論文では、LLMの大規模な事前学習において、学習の進捗を妨げるtokenを特定し除外することで、学習コストと学習済みLLMの精度のトレードオフが改善することを明らかにしました。
提案手法では質の高い小規模なコーパスと、質の低いtokenを含む大規模なコーパスの存在を仮定します。前者を用いてreference modelと呼ばれるLLMを学習します。このLLMを用いて大規模なコーパスの全てのtokenに対する交差エントロピー誤差を計算します。
続いて大規模なコーパスを用いたLLMの学習を行います。ここで、一定の間隔ごとに、あるtokenの現在学習中のモデルにおける誤差と、reference modelにおける誤差の差分を計算します。これが大きいtokenは質の高いコーパスで学習したLLMに対して誤差が悪化したことになりますので、ノイジーなtokenであると見なし、該当するtokenの誤差を0に修正し学習から除外します。
シンプルな手法ですが、実験では同じ学習コストでより高いdownstream task性能を獲得したことが示されました。
おわりに
本稿では、機械学習分野のトップカンファレンスであるNeurIPS 2024で得られた知見を共有しました。2025年1月23日に開催されたNeurIPS 2024 論文読み会でも参加報告を行っており、佐藤の発表スライドを公開しておりますので、ぜひご覧ください。
LINEヤフーでは、最先端技術の業務への応用を積極的に実施しており、今後もこうした知見のキャッチアップを継続していきます。また、LINEヤフーからは佐藤らが発表した論文に加え、3件の論文がNeurIPS 2024に採択されており、最先端技術の発信にも�引き続き注力していきます。


