Webアクセシビリティチーム中野です。
プロダクトとウェブサイトにおける、アクセシビリティの向上と啓発を行っています�。
今年の10月に社内イベントのTech Week 2024でアクセシビリティチームとしてブースを出展し、画面の情報を合成音声で読み上げる支援技術であるスクリーンリーダーのチートシートを作成して配布しました。
主にディスプレイで表示したり、印刷したりすることを想定して作ったPDFですが、スクリーンリーダーなどの支援技術でも閲覧できるようにしています。この記事ではPDFをアクセシブルにするための課題と理由について解説します。なお、今日から障害者週間(12/3-9)が始まりますので、この記事が障害者福祉の一環として考えるきっかけになればと思います。
そもそもPDFとは
「Portable Document Format」の略で、オブジェクトの2次元情報、カラープロファイル、フォント情報などを保持したフォーマットです。環境によらずレイアウトやフォントを保持して表示することを想定して作られたフォーマットで、印刷するときにも使えます。
PhotoshopやIllustratorでおなじみのAdobeが開発したフォーマットで、近年は冊子やカタログなどの印刷データをウェブで公開するときにもよく使われています。
アクセシブルなPDFとは
PDFにはいくつかバージョンがあります。最新は2.0です。1.7からは「タグ」という仕様が増えたことで、次のような事ができるようになりました。
- 見出し、リスト、リンクのようなメタ情報を付与して�文書を構造化できる
- 画像に代替テキストを付与できる
これにより、見えない場合でもスクリーンリーダーで見出しの強弱や文書の構造がわかるようになりました。また、構造化された情報をもとにビューアーのウィンドウ幅に応じて文書をリフロー表示(折り返し表示)できるようになりました。


このように、HTMLのように多様な使い方ができるPDFですが、ウェブでコンテンツを公開するときのフォーマットとしてはいくつか解決の難しい課題もあります。
課題1 日本語の文字が置き換わりやすい
PDFは、UTF-8などの文字に割り当てられた文字コードを使わずに、独自のコードである「グリフID」を文字に割り当てて管理しています。PDFからテキストを選択したりコピーするときに、グリフIDから文字コードに変換されます。
そのときに、フォントによっては日本語以外の文字に変換されたり、文字として認識できないコードで変換されます。これは、PDFの中で使��っているフォントによって起きる問題です。変換されたことにも気づかないくらい似ている文字もあり、見た目では区別がつきにくいこともあります。
その状態では、見えない方がスクリーンリーダーを使ってウェブページを読み上げるときに読み上げられなかったり、PDFからテキストをコピーすると見た目と異なる文字に変わっていたりします。
この問題は、ウェブアクセシビリティーに限った問題ではなく、情報アクセシビリティー全般に関わる課題です。
課題2 ビューアーによっては文書構造を正しく読み上げられない
Google Chrome、Mozilla Firefox、Microsoft Edgeなどのブラウザーでは、PDFビューアーがブラウザーの中に組み込まれています。そのため、PDFはシームレスにブラウザーで閲覧できます。
しかし、ブラウザーのビューアーで合成音声とキーボードでコンピューターを操作するスクリーンリーダーを使ってPDFを読み上げようとすると、見出しではない文言を見出しと読み上げたり、設定した順番と異なる順番で要素を読み上げたりするため、正しく情報を取得できません。スクリーンリーダーを使ってPDFを正しく読むためには、ダウンロードしてからAcrobat Readerなどを使って読み上げる必要があります。
課題3 PDFをオーサリングするツールの対応が不十分
MicrosoftのWordやPowerPointでは、PDFに変換するときにアクセシビリティーを向上させるオプションがあります。また、Adobe InDesignではスタイルにタグを設定することや、画像に代替テキストを付与できます。
しかし、現時点ではそれらの方法を使ったり、Acrobat Proを使って既存のPDFファイルを編集したりすることでアクセシビリティーを高めようとすると、一定水準まではできますが限界があります。
一例として、PDFには「PDF/UA-1」という、アクセシビリティーに関する要件を定めた規格がありますが、Acrobat Proではツールチェックで検出できても修正できない項目がいくつかあります。そのため、PDFのアクセシビリティーを高めるために規格に準拠することを目標にすると、達成不可能な状態に陥ることがあります。
このように、ウェブコンテンツとして使うにはいくつかの課題があるPDFですが、そうであってもアクセシブルにすることには理由があります。
PDFをアクセシブルにする理由
技術的な観点だけでいうと、HTMLを使ったほうが確実にアクセシビリティーを担保できます。それでもPDFを使う場面があり、PDFをアクセシブルにする理由があると考えています。3点あります。
ウェブのメディア特性に合わせるため
ウェブはユーザーが情報の受け取り方を自由に選べるメディアです。そのため、HTMLのような中間言語をユーザーエージェントが解釈してレンダリングする場合はもちろんのこと、PDFや動画のように情報が確定したファイルにおいてもアクセシブルにする必要があります。
動画の場合は、音声であればキャプション、動画であれば音声ガイドといった代替コンテンツで多様な受け取り方に対応します。PDFはタグなどの仕様を使って、PDFの文章に文書構造と代替テキストを付与することで、スクリーンリーダーなどの支援技術が情報を受け取れるようにします。
PDF以外の提供手段を取れない場合
プレスリリースやニュースをPDFファイルで行うことはよくあります。Wordファイルなどを使って組織内外の確認を行い、体裁を含めて内容を確定させることもありえます。そのときは、最終的なアウトプットがPDFになると思われます。
また、会議やイベントで使ったプレゼン資料を公開するときも、PDFファイルで公開することがよくあります。スライドはレイアウトを使って情報を伝えていることも多いです。
さらに、パンフレットやマニュアルといった、印刷物で提供しているコンテンツをウェブで公開する場合もあります。
どの場合も、HTMLなどを使ってウェブページにすることは技術的にはできますが、工数と時間がかかったり、業務プロセスを変えなければいけない可能性があったりするため、すぐに対応できない場合もあります。
そのため、暫定的な対応として、少しの手間でPDFファイルのアクセシビリティーを向上させることが有用であると考えます。不完全でもPDFでも情報取得できる方法を増やしていくことは大事です。
技術的な可能性として
ウェブアクセシビリティーの規格であるJIS X 8314-3:2016やWCAG 2.0において、ウェブアクセシビリティーを向上させる媒体の指定はありません。対象にはPDFも含まれます。
しかし、さまざまなサイトのウェブアクセシビリティーの試験結果を見ると、PDFは試験の対象外にされていることが多いです。また、ウェブアクセシビリティ�ーを向上させることを書いた文書や書籍ではPDFについては「できるだけHTMLにするように」と書かれていることが多く、PDF自体をアクセシブルにすることについて書かれた文書や書籍は見つけにくい状況です。
そのため、私はPDFをどこまでアクセシブルにできるのか、スクリーンリーダーでどこまで読めるPDFを作れるか、という興味から始めました。今は少しだけわかったことが増えたので、今後は通常のPDFを作成する作業の中で効率よくアクセシブルにするための作業を盛り込めるかを模索しています。
まとめ
普段はHTMLやCSSといった、アクセシブルなコンテンツを作れる技術を使ってウェブアクセシビリティーの改善を行っているため気にしていませんでしたが、PDFのように、後からアクセシブルにするための仕様が追加された場合は、技術仕様、閲覧環境、オーサリングツールそれぞれの足並みがそろわないとコンテンツをアクセシブルにすることが難しいことを実感しました。
これは、W3Cが公開している Essential Components of Web Accessibility で示されているcontent、users、developersの三者を取り巻く状況が、PDFにおいてはまだ万全ではない状態であるともいえます。
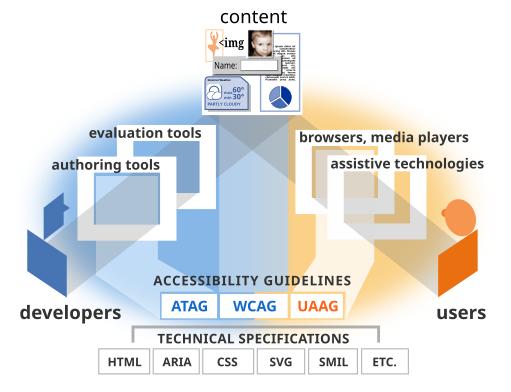
出典: Essential Components of Web Accessibility | Web Accessibility Initiative (WAI) | W3C
しかし、万全ではないこと��は不可能ということではなく、可能と不可能の間はグラデーションです。よって、コンテンツ提供者としては、少しでもアクセシブルにできるよう努めるべきです。そして、インターネットというメディア特性に合わせることが重要で、HTMLでは代替しにくい場合があり、アクセシブルにするための実装方法があるのであれば、PDFをアクセシブルにすることには一定の価値があると考えています。
努力目標のようなまとめになりますが、これからもPDFをアクセシブルにするための方法を模索していこうと思います。


