LINEヤフー Advent Calendar 2024の参加記事です。
こんにちは。LINEヤフー株式会社ビジネスPF開発本部で LINE DMP の開発を担当している yamaguchi です。
この記事は、Testcontainers を活用して Apache Kyuubi を用いたユニットテスト環境をどのように構築したかを紹介します。
はじめに
LINE DMP(Data Management Platform)は LINE 外部から同意を得てアップロードされた、あるいは LINE の内部で得られたデータをさまざまな形で ETL 処理をし、LINE広告やLINE公式アカウントのような B2B サービスで活用できるようにするためのプロダクトです。
膨大な累積データや非常に大きなトラフィックを扱うこともあり、リアルタイム処理から大規模バッチ処理までさまざまな LINE にまつわるデータ処理を行っています。
プロジェクトの背景
大規模データを取り扱うにあたり、HiveServer2 を利用して Hive テーブルにアクセスしたデータ処理をこれまで行っていましたが、全社でより効率的な処理を行うために Spark エンジンを利用した Apache Kyuubi への移行が必要になりました。
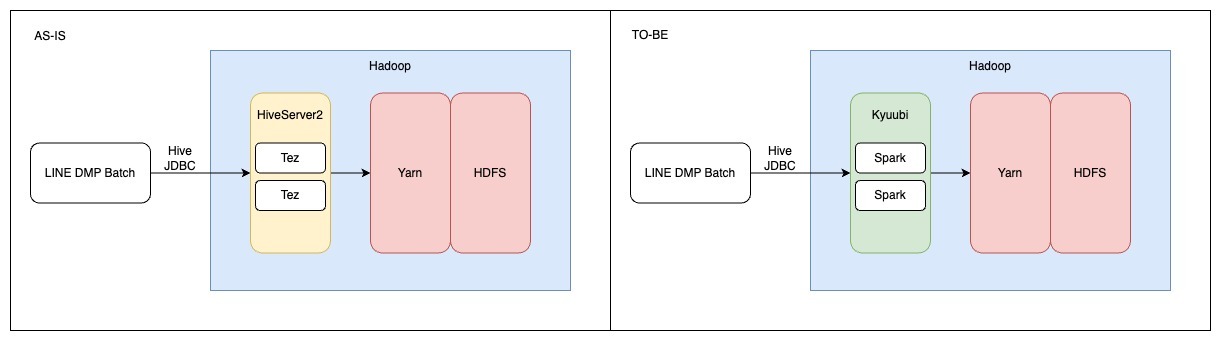
Apache Kyuubi とは
Apache Kyuubi とは、データウェアハウスやレイクハウス上でサーバーレス SQL を提供する、分散型かつマルチテナント対応のゲートウェイです。
Kyuubi は、Apache Spark などの最新のコンピューティングフレームワーク上に分散型 SQL クエリエンジンを構築し、さまざまなデータソースに分散された大量のデータセットを効率的にクエリします。
Apache Kyuubi のゲートウェイ構築は他のチームが担当しており��、LINE DMP としては HiveServer2 から Apache Kyuubi を介した Spark へのクエリ移行が主な要件となりました。
ユニットテスト環境構築の動機
LINE DMP では、HiveServer2 を利用しておよそ30個のバッチがデイリーやアワリーで動作しています。
Hive から Spark への移行は基本的には互換性があり、簡単なクエリであればそのまま動作しますが完全互換ではありません。
目指すのは、データ量やデータの質もさまざまなバッチを障害ゼロで移行することです。
今までも Hive クエリについてはユニットテストを行っていました。それを Spark クエリにも移植して、クエリの実行結果が同一であることを担保できれば移行を安全に進めることができます。また、Spark置き換え後のクエリの修正などの先の開発を考えると、ユニットテスト環境が必要になります。
そこで、HiveServer2 から Kyuubi へユニットテスト環境をどのように移行したのかを説明します。
Testcontainers とは
先に、ユニットテスト環境で利用している Testcontainers について簡単にご紹介します。
Testcontainers は、Docker コンテナを利用してテスト環境を簡単に構築・管理するためのライブラリです。
Testcontainers を利用するメリットは以下になります。
- 環境の再現性と一貫性
- モックやインメモリサービスを使用せずに、実際のデータベースと同様の環境でテストを書くことができる。
- テストごとに適切にクリーンナップすることで、テストの副作用を防ぐことができる。
- 簡単なセットアップと管理
- Testcontainers は、Java や他のプログラミング言�語から簡単に操作でき、テストコード内で直接コンテナのライフサイクルを管理できる。
- JDBC サポートなどの便利な機能により、データベースのセットアップをコード内で簡潔に行える。
この Testcontainers を、移行前と移行後でそれぞれどのように利用していたのかもあわせてご紹介いたします。
AS-IS ユニットテスト環境
AS-IS ユニットテストに必要な要件
AS-IS のユニットテスト環境からみていきましょう。求められる要件は以下の通りです。
- データベースとしての Hive の機能(Hive テーブル作成、テストデータの格納など)
- HDFS 環境へのファイル操作(データパイプラインを模倣するために HDFS に直接ファイル配置ができること)
- HiveServer2 へのアクセスと Hive クエリの実行(ユニットテストとして Hive クエリが動作すること)
AS-IS ユニットテスト環境の構成
移行前の AS-IS の Hive クエリのユニットテスト環境はこのようになっていました。
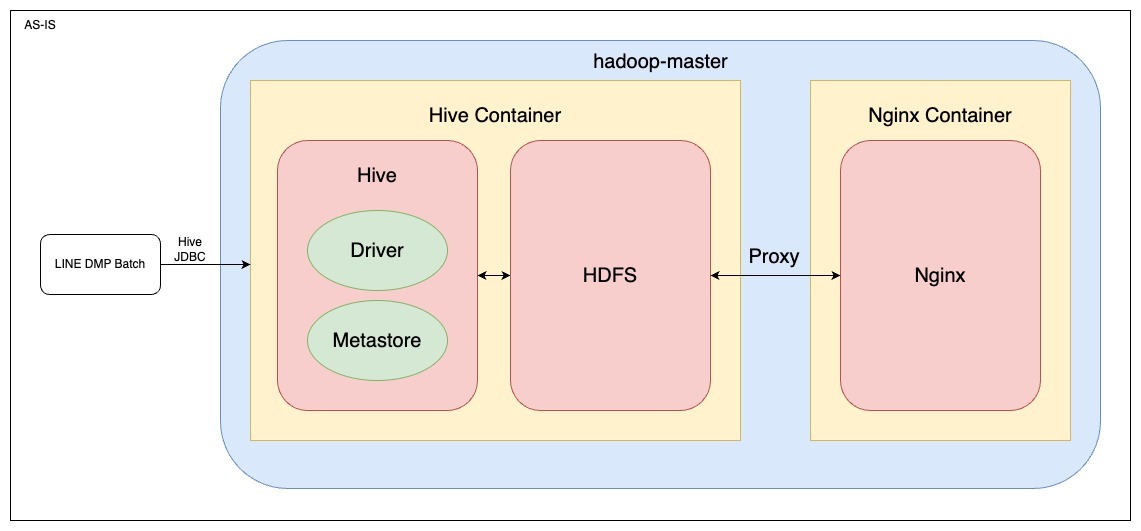
それぞれの役割は以下の通りです。
- Hive コンテナ
- Testcontainers を利用して Hive のコンテナを起動
- HDFS は分散ストレージとして機能し、データの保存とアクセスを提供
- Metastore で Hive のメタ情報を管理
- Nginx コンテナ
- Nginx はプロキシサーバーとして機能し、HDFS へのリクエストをルーティング
- HDFS に直接テスト用ファイルを put するケースなどで利用
- hadoop-master ネットワーク
- Docker のネットワークに hadoop-master という名前を指定することで、ネットワーク内での相互通信を簡単に行えるようにする
AS-IS Testcontainers の利用方法
Testcontainers の JDBC サポート機能を活用してセットアップしていました。
コンテナの起動
JDBC 接続 URL の jdbc: のあとに tc: を追加するだけで、データベースの新しいコンテナ化インスタンスを取得できます。
つまり、jdbc:tc:hive2:// のエンドポイントを設定することで、テスト起動時に Testcontainers が自動的にコンテナを起動してくれるので、コンテナ起動の実装は不要です。
また、ポート設定は Testcontainers が動的にマッピングしてくれるので、ここの手間も不要です。
ライフサイクル
TC_DAEMON=true を設定することで、コンテナは一度だけ起動しテスト全体を通して維持されます。
これにより起動時間を短縮し、パフォーマンスを向上させます。
コンテナは維持されますが、テストごとにデータベースを JUnit の afterEach でクリーンアップすることで、データの一貫性を保ちます。
TO-BE ユニットテスト環境
TO-BE ユニットテストに必要な要件
それでは、HiveServer2 から Kyuubi への移行はどのようにユニットテスト環境で実現すればよいでしょう。
求められる要��件は以下の通りです。
- データベースとしての Hive の機能(Hive テーブル作成、テストデータの格納など)
- HDFS 環境へのファイル操作(データパイプラインを模倣するために HDFS に直接ファイル配置ができること)
- Kyuubi サーバーへのアクセスと Spark クエリの実行(ユニットテストとして Spark エンジンでクエリが動作すること)
TO-BE ユニットテスト環境の構成
最終的にこのような構成になりました。
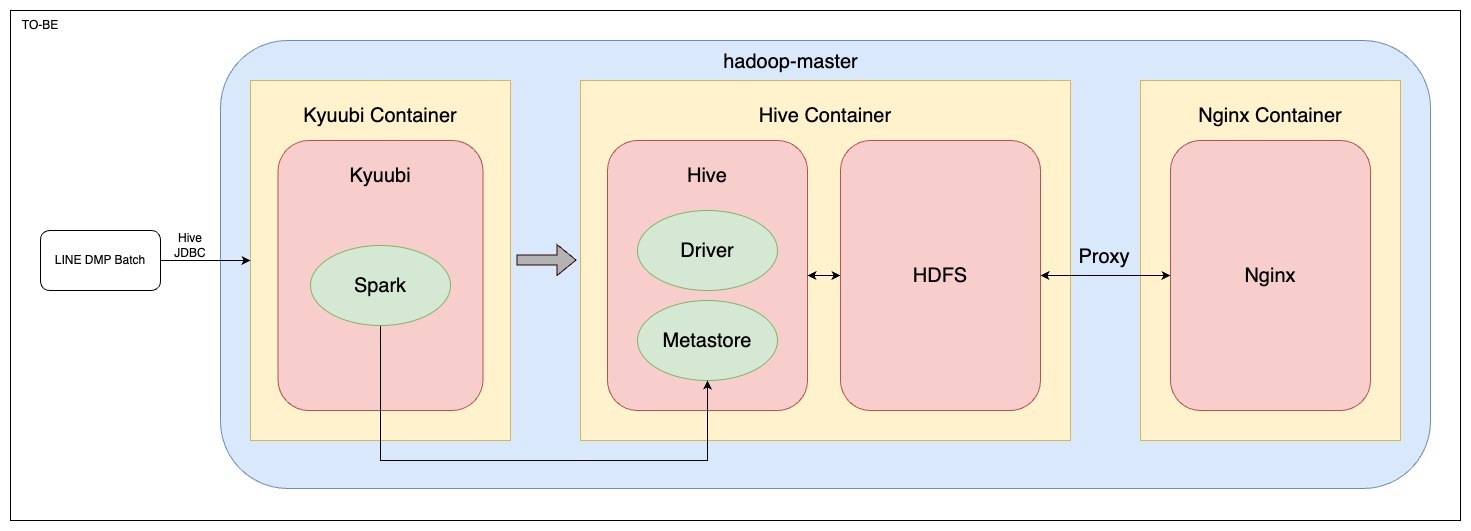
- Kyuubi コンテナ (New!!)
- Hive へのゲートウェイとして起動
- Spark を立ち上げて Kyuubi へのリクエストを Spark で処理し、Hive テーブルに書き込みや読み込みを行う
- Hive コンテナ
- Testcontainers を利用して Hive のコンテナを起動
- HDFS は分散ストレージとして機能し、データの保存とアクセスを提供
- Metastore で Hive のメタ情報を管理
- Nginx コンテナ
- Nginx はプロキシサーバーとして機能し、HDFS へのリクエストをルーティング
- HDFS に直接テスト用ファイルを put するケースなどで利用
- hadoop-master ネットワーク
- Docker のネットワークに hadoop-master という名前を指定することで、ネットワーク内での相互通信を簡単に行えるようにする
Kyuubi コンテナが追加された以外は、全体の構成には変更はありません。
AS−IS の LINE DMP Batch と Hive コンテナの間に Kyuubi のコンテナを立てて、Kyuubi がゲートウェイのようになる構成です。
TO-BE Testcontainers の変更点
AS-IS では直接 Hive に JDBC 接続してクエリを実行するので、Testcontainers の便利な JDBC 機能を活用できました。
しかし TO-BE では Kyuubi を介して Spark クエリを実行するので、Testcontainers の使用方法をカスタマイズする必要があります。
コンテナの起動
Kyuubi がエンドポイントになるため、JDBC 接続 URL を jdbc:hive2://localhost:10010/default; に変更します。
そうすると、JDBC サポートの便利機能が使えなくなるので、JUnit の beforeAll でコンテナを起動する必要がありますので、適切に実装しましょう。
また、AS-IS だとポートは動的にマッピングしてくれていましたが、ポートが固定になるので Kyuubi コンテナ側でポートを適切にマッピングする必要があります。
ライフサイクル
こちらも TC_DAEMON=true のような機能は使えませんが、コンテナの起動は手動で行っているので起動は一度だけです。
なので、起動時間を短縮したままテスト実行が可能です。
こちらも同様に、テストごとにデータベースを JUnit の afterEach でクリーンアップすることで、データの一貫性を保ちます。
Testcontainers を利用することで、常にクリーンな状態のデータベースを使用することができます。これにより、実機の環境共有時にありがちなゴミデータによる問題を回避でき、テストの信頼性が向上します。
多少カスタマイズの手間は増えますが、Testcontainers のメリット(安定・信頼できるモックに頼らないユニットテスト)を享受できる構成ができました。
設定ファイル
それでは次に、実際に使った設定ファイルを紹介します。
...
├── Dockerfile-hive
├── Dockerfile-kyuubi-customresources
├── core-site.xml
├── hive-site.xml
├── init.sql
├── mybatis-config-test-for-spark.xml
├── nginx-proxy.conf
└── spark-defaults.conf簡単に各ファイルの役割をみていきましょう。
| File | Who needs it? | Description |
|---|---|---|
| Dockerfile-hive | hive | Hive イメージ作成用の Dockerfile。(version: Hive 3.1, HDP 3.1) |
| Dockerfile-kyuubi-custom | kyuubi | Kyuubi イメージ作成用の Dockerfile。(version: Kyuubi 1.7.1)後述するが、カスタマイズしている。 |
| core-site.xml | hive/kyuubi | Hadoop のファイルシステム、ネットワークに関する情報。このファイルを Kyuubi に渡すことで、Kyuubi から Hive へのアクセスを可能にする。 |
| hive-site.xml | hive/kyuubi | Hive のメタデータを保存する Metastore の接続情報。 |
| init.sql | hive/kyuubi | kyuubi から接続するための user / password を設定する。 Metastore に新しい DB を作成しようとすると、外部キー制約でエラーが発生するので DBS テーブルに default 値を追加する。(既知の issue で 4.0.0 で解消) |
| mybatis-config-test-for-spark.xml | hive/kyuubi | Testcontainers で利用する JDBC のコネクションに関する情報が記載。 Unit Test が接続する Kyuubi のエンドポイントとなる jdbc:hive2 の URL を設定する��。 |
| nginx-proxy.conf | hive | HiveContainer とともに起動する Nginx の情報が記載。HDFS へアクセスするためのプロキシの役割を担う。 |
| spark-defaults.conf | kyuubi | Kyuubi で起動する Spark の設定を記載。(version: Spark 3.4 カスタム) |
いくつかピックアップして、ファイルの中もみてみましょう。
Dockerfile-kyuubi-custom
Kyuubi 用の Dockerfile は下記のようにカスタマイズを行っています。
FROM apache/kyuubi:1.7.1
USER root
RUN apt-get update && \
apt-get install -y zip curl && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# install customize spark
RUN curl ...
# install mysql connector for metastore
RUN curl -o /opt/spark/jars/mysql-connector-java-5.1.49.jar \
https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.49/mysql-connector-java-5.1.49.jar
USER kyuubiLINE ではカスタマイズされた Spark があるので、ここでインストールして適切に配置しています。
また、Hive の Metastore である MariaDB にアクセスするためにここで mysql-connector をダウンロードして配置しています。
hive-site.xml
Hive コンテナ内で起動している MariaDB の Metastore に接続するための設定ファイルです。
<?xml version="1.0"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop-master/metastore</value>
<description>the URL of the MySQL database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>userName</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
</configuration>この設定がないと Kyuubi が起動する際に、Kyuubi 内で Metastore 用 DB をローカルで起動してそちらに接続してしまいます。
mybatis-config-test-for-spark.xml
MyBatis の設定ファイルです。
AS-IS では、エンドポイントをこのように記述していました。
<property name="url" value="jdbc:tc:hive2:///?TC_DAEMON=true" />TO-BE では Kyuubi のエンドポイントを記載する必要があります。
<?xml version="1.0" encoding="UTF-8"?>
<!-- For testing -->
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="mapUnderscoreToCamelCase" value="true" />
</settings>
<environments default="test">
<environment id="test">
<transactionManager type="JDBC" />
<dataSource type="POOLED">
<property name="driver" value="org.testcontainers.jdbc.ContainerDatabaseDriver" />
<property name="url" value="jdbc:hive2://localhost:10010/default;" />
<property name="driver.encoding" value="UTF8" />
</dataSource>
</environment>
</environments>
</configuration>このように、それぞれのコンテナやネットワーク、コンフィグを適切に設定することで、一見複雑な構成の実環境をローカルのユニットテスト環境として構築することができました。
ユニットテストのおかげで解決できたポイント
Hive クエリから Spark クエリに移行するにあたり、基本的には互換性があるためクエリを変えることなく動作してくれました。
ユニットテストがあることで「問題がなく動作する」ことを確認できるため、安心材料としての効果も大きいですね。
その一方で、クエリエンジンによる違いがいくつかありましたので簡単に紹介します。
型の厳密性
Spark は Hive よりも型に厳密です。
Spark 側の設定により SQL のポリシーを ANSI, legacy, strict から選択できます。
legacy は Spark2.x の設定で、Hive 互換であり型に対して厳密ではありません。一方、現在はデフォルトが ANSI で、ANSI SQL 仕様に従って型変換が行われます。
この場合、文字列を int に変換するような不適切な型変換は許可されずにエラーが発生します。(Hive ではこのような変換も許可されていました)
移行前のクエリでは Hive 側の型変換に任せていた実装がいくつかあり、ユニットテストで事前に問題が発見できたため修正が容易でした。
詳しくは Spark のドキュメント(ANSI Compliance)をご参照ください。
書き方の違い
簡単な関数は Hive と Spark で同様の動作をしますが、一部の関数は書き方が違ったり、異なる結��果を返すことがあります。この点には注意が必要です。
LINE DMP の場合、Hive(INPUT__FILE__NAME) -> Spark(input_file_name()) のような細かい関数名の違いで対応できたのは幸いでした。
詳しくは Spark のドキュメント(Compatibility with Apache Hive)をご参照ください。
また、HiveQL から Spark SQL への移行に関しては、LINE 時代の Tech Blog にもとても参考になる記事があるのでぜひご参照ください。
実際に移行してみて
ユニットテストによって、Spark でのクエリ実行に問題がないことが無事確認できました。
しかし、これでめでたしめでたし...とは残念ながらいきません。少々蛇足ではありますが、せっかくなので移行段階でハマったポイントを紹介させていただきます。
SORT BY の挙動の違い
HDFS にファイルを書き出すにあたり、下記のような要件が必要なケースがありました。
- 同じキーを持つデータは、同じパーティション(ファイル)に出力したい
- 各パーティション内では、指定したキーに基づいてソートしたい
これを実現する Hive のクエリが下記のような形でした(実際のクエリではなく簡略化しています)。
INSERT OVERWRITE TABLE ${outputTable} PARTITION (date=#{date}, is_active)
SELECT
user_id,
friend_id,
is_active -- true or false
FROM ${inputTable}
WHERE date=#{date}
DISTRIBUTE BY user_id
SORT BY user_id, friend_idHive ではこれは期待通り動作していたのですが、Spark では動作してくれません。
クエリの結果を確認すると、 user_id でパーティションが分かれていたので DISTRIBUTE BY は機能しているようでしたが、ファイル内で SORT BY が期待通り動作していませんでした。
原因としては、INSERT OVERWRITE の書き込み先パーティションが is_active という複数のパーティションになっていたからでした。
対応として、is_active を true と false の値を指定して書き込むことで問題は解消されました。
あとから Spark のドキュメント(SORT BY Clause)を確認すると、以下のように記載されていました。
When there is more than one partition SORT BY may return result that is partially ordered.
ドキュメントをしっかりと確認するのはとても大事ですね。
なお、ユニットテストではファイルを分散するほどのデータ量でテストしていなかったため、パーティションに分かれることがなく検知できませんでした。
型の厳密性
再び登場しました。ユニットテストの段階でクリアしていたはずの型問題です。
INSERT OVERWRITE TABLE ${outputTable} PARTITION (date=#{date})
SELECT
user_id,
friend_id
FROM ${inputTable}
WHERE date=#{date}こんなクエリで書き込みを行ったところ、次のようなエラーが発生しました。
Caused by: MetaException(message:Number of partitions scanned (=40004) on table 'XXXXX' exceeds limit (=40000).動的なパーティ��ションを指定した書き込みでフルスキャンが走るのは既知の事象だったのですが、このケースでは静的パーティションを指定しています。
それにもかかわらずフルスキャンが走ってしまいました。いったいなぜでしょう。
答えはシンプルで、指定しているテーブル側のパーティション date は String 型であるのに対し、SQL 内での date は Integer 型で指定していたのが原因でした。
その結果、フルスキャンが走り大量のパーティションを読み込んでしまい exceeds limit エラーが発生しました。
ユニットテストでは少量のデータでフルスキャンしても特に問題がなかったのですが、本番環境は巨大なデータなため発生したエラーでした。
他にもユニットテストだけでは確認できなかったエラーはありましたが、幸いにも社内のヘルプチームがとても親身になってサポートしてくださり、無事すべてのバッチを移行することができました。この場を借りて、感謝申し上げます。
おわりに
Testcontainers を用いることで、モックではなく実際の構成に近い環境を再現することができました。
これにより、ユニットテストでコードの品質を担保できるというのは大きな利点です。
この記事が、テスト環境と本番環境の差異でお悩みの方や、テスト環境の構築方法にお困りの方に少しでも参考になれば幸いです。


