概要
はじめに
東京大学情報理工学系研究科修士1年の山根那夢達です。普段はネットワークパケットの冗長化に関する研究を行っています。2024年8月19日から9月27日までの6週間、ネットワーク領域にて就業型インターンとして参加させていただきました。
今回参加させていただいたチームでは、LINEヤフーを支えるネットワークの運用やそれに関わる開発を行っています。私が今回のインターンシップに興味を持ったきっかけは、研究室でネットワークについての研究やサーバの管理をしていく中で、ネットワークに関連する開発に関心を抱いたからです。
業務内容
今回のインターンシップでは、LINEヤフーのネットワークトポロジーを描画するシステムの設計・開発を行う業務に取り組みました。
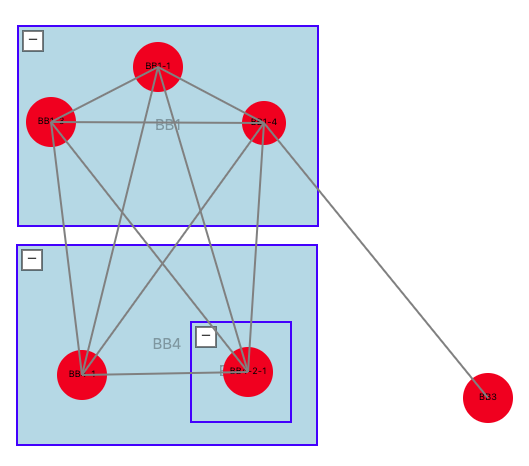
ネットワークトポロジーとは、図1 のように、多数のルータ・スイッチなどのネットワーク機器の間の繋がりのことをいいます。トポロジー図においては、ノード(ネットワーク機器)とエッジ(物理的なケーブル・物理リンク)からなるグラフとして表され、多数の機器からなるネットワークの機器間の繋がりを視覚的に示すことができます。一般的なトポロジー図は、機器名とリンクからなる一枚の絵に過ぎないのですが、もし各リンクを流れる通信量が一目で分かるようになれば、これはネットワーク機器の状態を即時に把握することに繋がり、とても有意義なことです。例えばネットワーク機器のマクロな状態、つまり外部との境界のルータからの通信しかできないような状態だとします。この場合、ある機器との通信ができなくなった時、それがどのリンク間での接続が落ちているからなのかがわかりません。また、各機器のメトリクスを取得していたら十分であるかといえば、そうではありません。可視化ができていなければ人間が一つ一つの機器に入って取得する必要があり、時間もかかる上全体像も把握しづらくなってしまいます。
こうした問題を解決するのが今回開発するネットワークトポロジーシステムというわけです。このシステムがあれば落ちていたり、逼迫(ひっぱく)していたりするインターフェースが一目でわかるなどの利点があります。また機器の情報を自社データベースに集約することで、他の用途への使用も期待できることから、ネットワーク管理には欠かせないシステムの1つとなっています。
本来こうしたシステムを外注した場合、複数人のチームで半年以上の長期的なスパンで開発を進めていくことが多いそうなのですが、今回は6週間という短い期間の中で、設計・技術選定からコア機能および一部重要な機能を作成して動かせる状態に持っていくところまでを目標に開発を行いました。
注力した部分
開発を始めるに先立ち、今回のシステム開発にふくむべき機能をどのようにするかを把握したいと考えました。そこで、具体的な業務に即した形で使うのに欲しい機能をもれなくリストアップすることとしました。具体的には、以前社内で使用されていた類似のツールを参考にしたり、インターネット上で既存のネットワークトポロジーシステムなど��を調べたり、社員の方にヒアリングを行ったりしました。こうして今回のシステムに持たせるべき機能を明らかにしました。以下ではコア機能および、それに加え自分が注力した部分を説明していきます。
コア機能
今回作成するネットワークトポロジーシステムは、手動でネットワークトポロジー図を描画するマップ・ノード(機器)・エッジ(物理リンク(の集まり))を追加・削除する仕組みとしました。手動作成機能は一切持たせず、システム側で自動で表示対象を選ぶようにするという案も検討しましたが、見やすい配置の決定や、人間側が監視したい対象を過不足なく盛り込むなどの管理者側の細かいニーズに応えにくいという点が懸念されたため、手動の編集機能を追加する方針となりました。また自動作成機能自体はマップデータをクライアント側に渡すだけで後々実現ができるため、その点でもこの方針で問題ないと考えました。その上で、このようなコア機能を盛り込みたいと考えました。
- ネットワークトポロジー図の表示: JSON 形式のデータをもとに、クライアント側でマップを表示する機能
- ネットワークトポロジー図の編集: 機器を配置するマップを表示・選択・作成・削除できる機能
- 配置するノードの検索・追加・削除: 追加する機器を決定するための機能
- ノードの移動・サイズ変更: ドラッグによりノードを移動でき、またサイズの変更ができるようにする
ノードの追加について、以前使われていたシステムでは数百ノードの表示が限界でしたが、より多くのノードを表示したいという要望もあり、およそ3,000ノード程度は大��きな遅延なく表示できるようにシステムを構築したいと考えました。またクライアント側の描画用フレームワーク自体は、今後の改良を挟めばすべてのネットワーク機器・エッジを表示しても耐えうるようなものにしたいと考えました。
グループノード
概要
「+」ボタンで展開、「-」ボタンで縮小することのできるノードです。中にノードを内包できます。縮小されている間はグループの持っている全部の子ノードが非表示になり、その中のノードがまとめて1つのグループノードとして表現されることになります。展開されると、内部のノードが表示される仕組みになっています。これを追加することにより、大規模なネットワークトポロジーでもグループをまとめてわかりやすく図示することが可能となります。
入れ子構造
グループの中にグループを含めることができるようにします。この機能により3,000ノードのような、1層のグループ化ではノード数が多くなり過ぎてしまう規模のネットワークトポロジーを描画する場合における、ユーザ体験の向上が期待できます。多層構造により人間にわかりやすいような見た目にすることができ、かつ深掘りも可能となり、見やすさと情報の網羅の両方を達成できます。
グループ間移動
移動した時にそのノードが展開中のグループノードに含まれていれば、そのノードの属するグループを変更する機能です。ノードの属するグループが移動した時に、グループとノードを繋ぐエッジがどのように変化するかという部分をきちんと実装するのが難しい部分とな�ります。
物理リンクごとの流量の値・画像の表示
リアルタイム流量確認機能
リアルタイムに各エッジの持つ物理リンク(ケーブル)の流量を見られるようにすることで、問題の箇所を迅速に発見できるようにする仕組みです。エッジをクリックしたときに関連する流量を表示する機能や、一定間隔で流量を自動的に更新する機能が含まれます。
ホバー時の履歴画像表示機能
リンクをホバーした時にそのリンクの流量の履歴画像が表示されるような機能です。過去どうなっていたかを見ることで、通信が断絶している箇所を見た時に、それが突発的なものか継続しているものかといった問題の詳細を把握できるという利点があります。
クライアントライブラリの選定
今回作るシステムでは、最終的にLINEヤフーの全機器分のノードとリンク(エッジ)を表示する可能性があります。そこで、いくらサーバ側で計算量的に効率の良いシステムを作るとしても描画しきれなければ意味がないので、どれくらいのノードとエッジを表示できるかについて検証することにしました。現段階で使用する可能性のあるノード数として 50ノード、300ノード、3,000ノードの設定を考え、そして非常に大規模になった場合に備え負荷を与えるため 10万ノードの設定でも試しました。また、今回ノード・エッジだけでなく、ノードをまとめて表示するためのグループノードを作成することとしたため、この表示に耐えられるようなライブラリを選ぶこと�が必要となります。また資料の多さやライブラリのメンテナンスが継続しているかという面も、それぞれ開発速度・保守の可能性などの面で重要となります。また、今回のシステムは Web ブラウザ上で閲覧することを前提としているため、その点も考慮に入れます。それを踏まえて、以下の5種類を検討しました。
1. D3.js
カスタマイズ性が高い動的な可視化用 JavaScript ライブラリです。長年にわたって開発されており、参考資料が多いというメリットがあります。その代わり、ネットワークトポロジーの可視化に特化しているわけではないので、それに関連する処理は全部手動で作成する必要があります。
2. vis.js
現在も開発が続く汎用可視化用 JavaScript ライブラリです。ネットワークグラフ用のライブラリが豊富で、最初からUIがある程度実装されており、デフォルトでノードのドラッグやキャンバスの拡大が実装されており、ネットワークトポロジーの描画にも転用できるように見えました。
3. Sigma.js
現在も開発が続くネットワークグラフの可視化用 JavaScript ライブラリです。vis.js と同じく、最初からネットワークトポロジー図にも使えるUIがある程度実装されているライブラリが豊富です。また、WebGL で実装されているので、大量描画時の処理が SVG 実装の D3.js よりも高速になるというメリットがあります。
4. inet-henge
D3.js を元に作成された、ネットワークトポロジーの可視化用 JavaScript ライブラリです。グループの描画やドラッグ、エッジの幅変更などを行える機能が組み込まれており、今回の目的に特化したシス��テムになっています。一方で個人プロジェクトであることから開発が活発でないことや、サンプルプログラムが自分の環境で起動しなかったため今回は断念しました。
5. Python を利用する(NetworkX)
Python のネットワークグラフを描画するためのプログラムです。Python の力を利用したかったのでこれが頭によぎりましたが、Webブラウザ上で動作させることが難しいことからこの選択肢は断念しました。
表示速度の検証
上記5つのうち JavaScript 上で動作が確認できた D3.js、vis.js、Sigma.js について、ノード数を増やした時の表示に要する時間のテストを行い、結果は以下のようになりました。
| ライブラリ | N=ノード数 | E=エッジ数 | 平均時間 (ms) | 備考 |
|---|---|---|---|---|
| D3.js | 50 | 150 | 1.84 | |
| D3.js | 300 | 900 | 7.29 | |
| D3.js | 3,000 | 9,000 | 45.84 | |
| D3.js | 100,000 | 300,000 | 1475.5 | 頻繁にクラッシュする。1,000,000で試すと確実にクラッシュ(メモリエラー)する。 |
| Sigma.js | 50 | 150 | 26.16 | |
| Sigma.js | 300 | 900 | 31.16 | |
| Sigma.js | 3,000 | 9,000 | 46.92 | |
| Sigma.js | 100,000 | 300,000 | 940.1 | 拡大すると Maximum call stack size exceeded エラーが発生する。ちょうど N>10000 から発生する。エッジ数関係なし。 |
| viz.js | 50 | 150 | 19.03 | |
| viz.js | 300 | 900 | 63.28 | |
| viz.js | 3,000 | 9,000 | 490.3 | |
| viz.js | 100,000 | 300,000 | 18047.9 |
表: ノード・エッジ数による表示速度の違い
これらの結果から、3,000ノード程度であれば、単に表示するだけの D3.js が一番速くなることが示されました。一方、10万ノード以上ある状況では、 Sigma.js の方が早くなるという��結果となりました。そこで D3.js と Sigma.js において、グループノードの実装に取り掛かることとしました。Sigma.js において実装を試みた結果、WebGL のシェーダーを自分でカスタマイズする必要があるようだとわかりました。その上で展開・縮小のできるボタンを作ることは、ライブラリの範囲内では難しそうだという結論に達しました。一方 D3.js では SVG を直接操作することにより所望の操作を実現することができました。また、現状10万ノード以上表示した場合固まるといった問題もありましたが、Sigma.js でも拡大時にエラーが発生するのは同様であり、またこの規模のノードを表示することは視認性の観点から少ないだろうという見立てから、このクラッシュが問題となることはないだろうと考え、D3.js を用いることに決定しました。
その他機能
期間内の実装は見送ったものの、重要だと考えた機能です。
ノードからそれを含む他のマップに移動できるようにする
ノードをクリックするとそれが含まれているマップを表示・移動することのできるようにする機能です。全てを1枚の図として表示するとややこしくて見づらく、一方で図の分割を行った場合、図の繋がりが見えづらく全体のネットワークの様子をすることができないため、その解決案としてこちらを提案しました。
ノードの自動表示
手作業でノードを配置するだけでなく、一定の条件を持ったネットワーク機器のみを抽出して、階層ごとに配置するような機能を作成したいと考えていました。大規模なネットワークトポロジーを手動で作成する手間を省ける場合があると考えたからです。
アーキテクチャ
アーキテクチャ図
上記の点を踏まえて今回作成したシステムのアーキテクチャがこちらになります。基本に忠実なオーソドックスなものを利用し、のちに保守を容易にするという意図が含まれています。緑で塗りつぶされた部分が今回設定と開発を行った部分です。
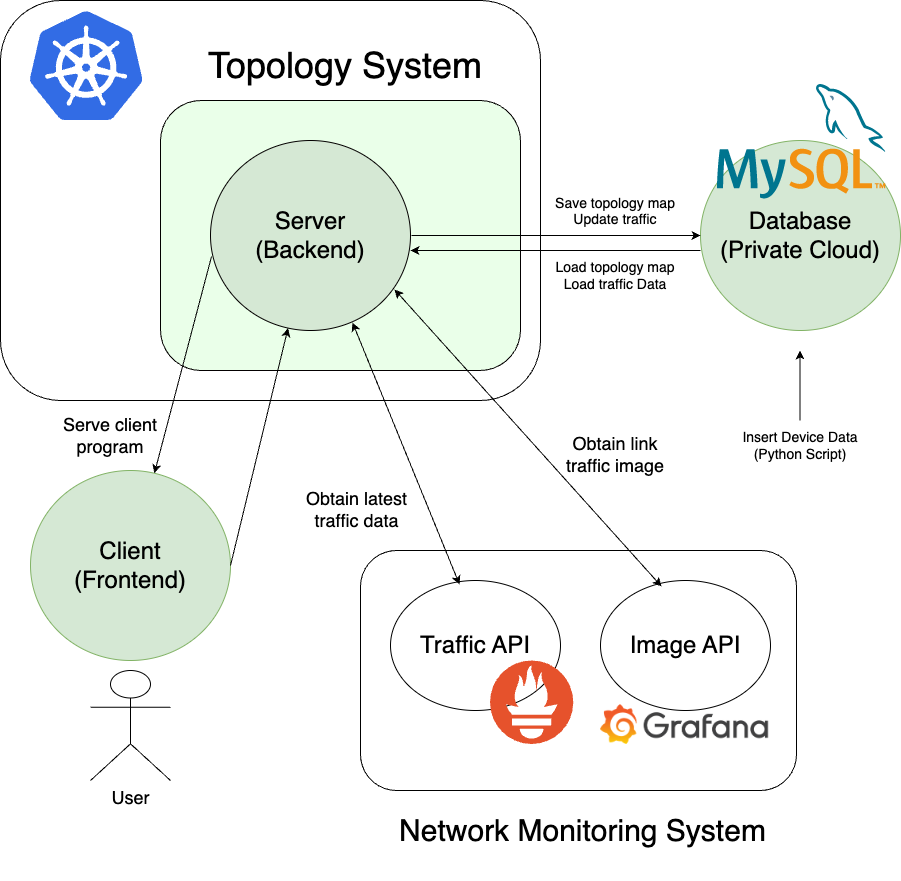
クライアント側は先述の通り D3.js を用いて JavaScript で実装しました。サーバサイドは FastAPI を使用しています。チーム内で管理されている他のシステムに倣うことで保守性を上げるという側面が大きいのと、Python で動くため、後々の改良(監視項目・機器更新機能の追加)がしやすいという面があったためです。データベースでは、機器や各マップの情報を保存しています。プライベートクラウド上の DBaaS(MySQL)を利用しました。機器の情報は外部スクリプトによりデータベースに直接 SQL 文で一括挿入される仕組みとなっています。そして構築したサーバ用のアプリケーションは Docker コンテナとし、それをチーム内で管理されている Kubernetes の基盤にデプロイする形で行いました。
機能実装の詳細
次に、実装面について特筆すべきところを説明します。
機器情報の保��管方法
あらかじめ全ネットワーク機器の情報を持つテーブルをデータベース上に作成しています。この情報は機器名や機器の種類(バックボーン、外部用ルータ)など個々のマップとは関係ない情報を保存するためのテーブルです。そのほか物理ケーブルやインターフェース(流量など)を保存するデータベースもあります。それとは別にどのマップに何の機器を表示するかの情報を持つテーブルが存在します。具体的には位置・サイズや表示名などが保存されています。なお、グループノードの情報はここだけに保存されています。実際の機器ではないので全ネットワークの情報を持つテーブルに保存する必要がないからです。マップを読み込む際は、まず表示に関するテーブルを読み、そこから機器自体や物理リンクの情報を持ったテーブルを読みに行くような構成になっています。このようにして、1つの機器を複数のマップにまたがって表示することや、グループノードを保存することを可能としています。
機器ごとのメトリクスの取得
各ノードの流量値の表示は、チーム内で運用されている Grafana の API にアクセスして情報を取得することで行いました。流量値については、定期的にクライアントからサーバにデータベースを更新するリクエストと、データベースから値を取得するリクエストを投げることで、ページを表示しながらリアルタイムに更新される仕組みを実装しました。最新値の取得は、社内の流量取得 API(Prometheus)経由で行いました。一方で画像については、エッジをホバーした際に社内の画像 API(Grafana)経由で取得したインターフェー�スの流量履歴を表示する、クライアントおよびサーバサイドの仕組みを作成しました。どのインターフェースを指定するかという部分の実装に苦労しました。
その他実装
マップに表示するノードを検索する機能の実装には、autoComplete.js を用いました。これは依存ライブラリなしで導入できるオートコンプリーション機能で、サンプルコードをコピーするだけで簡単に利用することができました。
動作デモ
今回作成したシステムが動作する様子を示します。
マップ選択
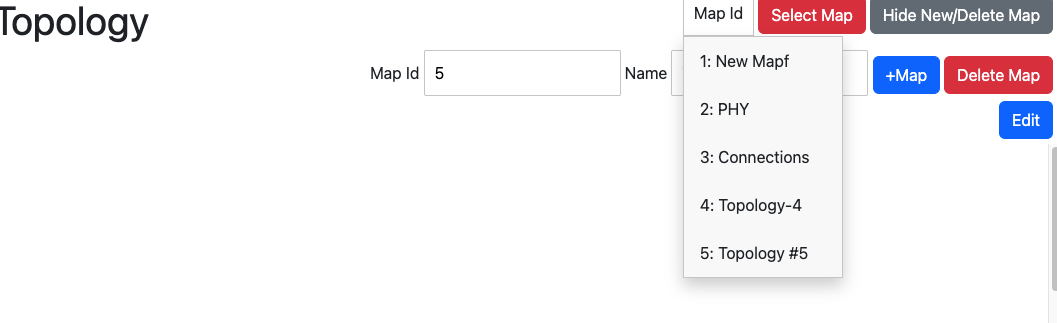
表示したいマップを右上から選択できます。マップの作成・削除も可能です。表示されるとマップに登録された機器(ノード)と、DB上に登録されたエッジが表示されます。
メトリクスの取得・表示
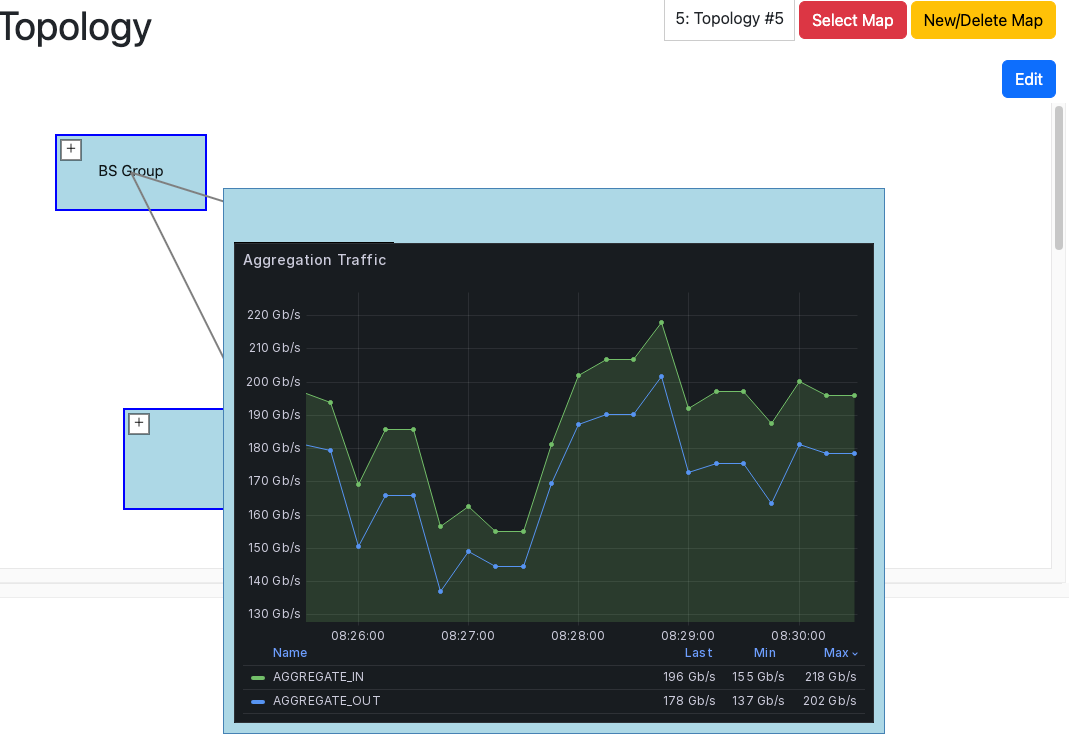
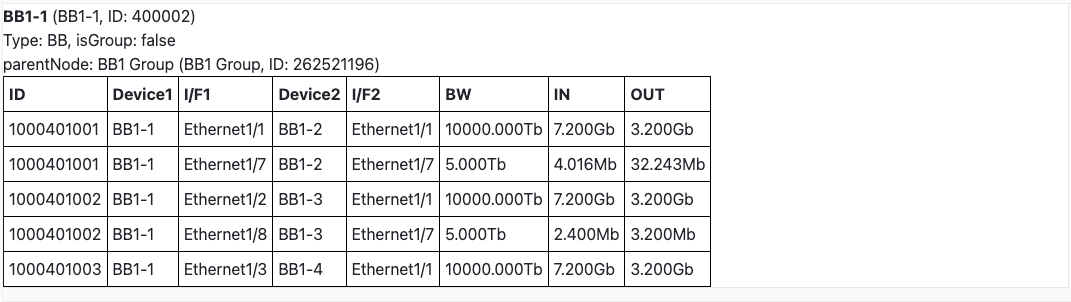
ノードやエッジをクリックすると、それに紐づいた物理リンク一覧と、その帯域やリアルタイムの流量が表示される仕組みになっています。これによって明らかに流量の少ないリンクを発見できます。またエッジをホバーすると、そのエッジに紐づいた物理リンクの帯域・流量の合計が即座に表示されるとともに、そのエッジの流量の時間変化も知ることができます。またしばらくホバーし続けると、流量変化の画像が表示される仕組みになっています。
編集モード
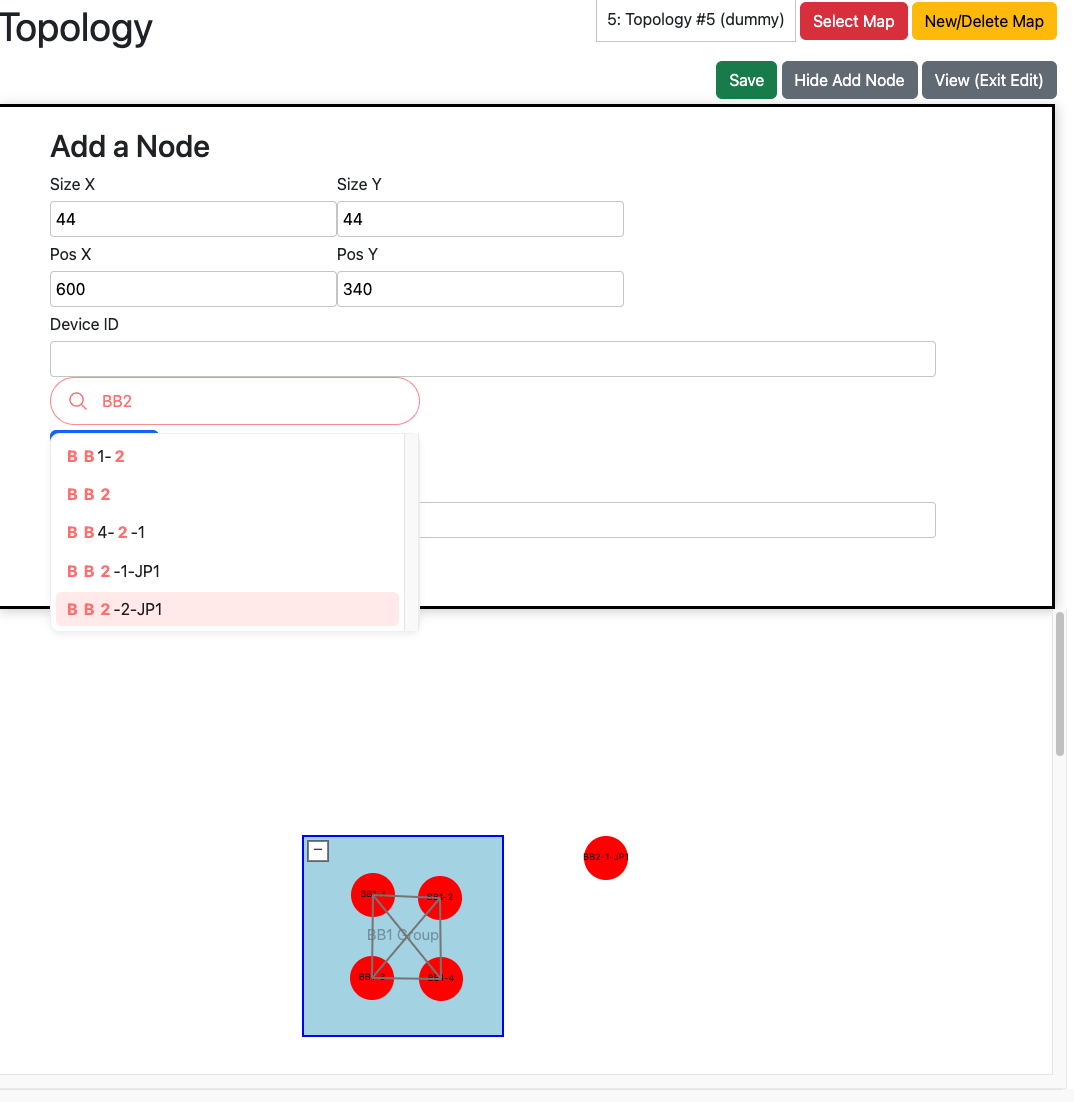
画面右上の「Edit」を押すと編集画面に入ります。DBに登録された機器や、グループの追加・削除やノードの移動やサイズ変更を行うことができます。変更が完了したら、右上の「Save」ボタンを押すことで変更がデータベースに反映されます。
学んだこと
開発経験
実際の環境を用いて開発する経験を積むことができました。自分は実務開発経験がなかったため、システムを新しく作る工程、Pull Request の書き方など多くのことを体験しつつ、エンジニアとしての開発工程を学ぶことができました。具体的な技術面では、サーバサイドの開発では型チェックに専用のフレームワークを用いるのが良いなどの重要な知見も学ぶことができました。また、これまでも JavaScript を使ったシステム開発を実務で行ってみたいという気持ちがあったため、今回その目的を達成することができました。自動追加やUI改善、データベースに登録された機器情報をどうやって定期更新していくかなど、まだ最終的な完成までには機能を残すこととなりましたが、期間内にコア機能やその他追加したい機能の多くを搭載したシステムを作成することができ、非常にためになる経験になったと考えています。
Jira (タスク管理)
タスク管理には Jira と呼ばれるツールを用いました。これはタスクをチケットと呼ばれる単位に分割し現状の課題を明らかにするものです。2週間のはじめに、今あるチケットの中からその期にやる内容を宣言し、期限内にやるように調整します。自分はチケットをいくつか作成し取り組みましたが、想定された時間の何倍もかかるようなタスクがある一方、すぐ終わってしまうものもあるなど、想定時間の予測が今回の課題となりました。より正確に予測するためにはチケットの調整が必要だと思いました。特に、コードをこれだけの量まとまって記述するという経験が少なく、軽く実装できるだろうと思っていた部分でかなりつまずいてしまったことがありました。具体的には、グループノードの追加・削除後のエッジの自動反映のアルゴリズムの作成に時間がかかっていました。こうした所要時間が読めない処理がある場合は、実行計画にバッファを持たせておくと良いと思いました。
デプロイ
実際に開発したものを商用規模の Kubernetes クラスタに載せるという貴重な体験をすることができました。その中で大量のリソースファイルや、社内プライベートクラウド上での設定なども体験させていただき、国内最大級のネットワークインフラに手を触れることができて、とても記憶に残る機会になりました。そしてサイトにアクセスしたときにページが表示された時はシンプルに感動しました。
終わりに
今回のインターンシップでは、出社イベントやランチ会に参加して、チーム外のインターン生や社員の方と交流して他のチームの内容を知り、とても刺激になりました。話を聞いていると、一部機能の追加などにとどまらず、新しいシステムの設計やライブラリの選定・検証から開発・デプロイまでの一連の流れを期間内に行うことができたことは、非常に貴重な期間だったのだと実感しました。また、チームの社員の方々からはネットワーク機器の分類や Kubernetes がどのように運用されているか、またデータセンタでの見学などの実環境のネットワークについての知識を教えていただいたほか、今回の開発に合わせ監視システム内部の API などの機能を作成していただきました。誰もが圧倒的な技術力を持っていて、この6週間の間は学ぶことばかりでした。大変お世話になりました。自分の今後の人生においてこの経験を積極的に生かしていきたいと思います。最後まで読んでいただきありがとうございました。
メンターからの一言
こんにちは。今回、山根さんのインターンシップのメンターを務めさせていただきました三好陵太です。
ここでは、彼が注力し達成した具体的な成果と、それがどのように私たちの仕事に貢献したかを述べたいと思います。
大量の表示が可能な�クライアントライブラリの選定により、ネットワーク全体の詳細な情報を一枚の図で表現できるようになりました。これにより大量の機器からなるネットワークの可視化が実現しました。加えて柔軟で入れ子構造をうまく表現できるグループノード機能の開発により、その大量の情報を整理することが可能になりました。一つのクラスタ、一つのサーバールーム、一つのアベイラビリティゾーン、一つのデータセンタ、一つのリージョンといった階層構造を表現しつつ、必要に応じて情報を展開して詳細にも確認できます。つまり抽象度を自由自在に調整できるようにすることでわかりやすさと情報の網羅性を両立に成功しました。
さらに、監視システムとの連携によって、トラフィックの全体像を簡単に把握できるようになりました。通常時のトラフィックの様子がわかりやすくなるだけでなく、作業や障害時のトラフィックの移動を簡単かつ正確に確認できるようになりました。
また成果だけでなく、取り組み方も非常に素晴らしいものでした。周りのメンバーの意見を上手に取り入れながらも、当事者意識を持ってさまざまな決定は山根さん自ら下すことができました。全体の進め方、成果の決定、要件定義、技術選定といった重要な決断でさえ、メンバーと相談しながらも決定自体は自らの手でしっかりと行っていた点は特筆に値します。
成果にもその取り組み方にも感服するばかりでした。山根さんの今後に期待しています。ありがとうございました。


