はじめに
東京大学大学院情報理工学系研究科修士1年の小濵晴天です。2024年8月17日から9月27日まで6週間、LINEヤフー株式会社のLINE�ギフトのSRE業務を担当するチームで就業型インターンシップに参加させていただきました。この記事では、インターンシップ期間中に私が取り組んだこととその成果についてご紹介します。
参加動機
私がインターンシップに参加した理由は、身近な大規模アプリケーションにおけるSRE業務を実際に体験してみたいという思いがあったからです。これまでサーバサイドのソフトウェアエンジニアとして、アプリケーションの機能仕様の決定から設計、実装まで一貫して携わってきました。しかし、これまでの経験は主に機能の開発や改善に重きを置いており、システムの運用、監視、パフォーマンス最適化といった分野にはあまり触れてきませんでした。
そんな中、LINEヤフー株式会社が運営するイベントISUCONに参加し、パフォーマンスチューニングの面白さに目覚めました。このコンテストはお題となるWebサービスを、限られたルールの中でどれだけ高速化できるかを競うものです。特に、限られたリソースの中でシステムをいかに効率よく動かすかという点に強く興味を惹かれ、より実務的な経験を積むためインターンシップに応募しました。
概要
LINEギフトは、LINEアプリを通じて友だち同士でさまざまなギフトを贈り合うことができるサービスです。累計ユーザ数は約3,500万人に達しており、非常に多くのユーザを持つ大規模なアプリケーションです。詳しいサービス内容については、LINEギフトの公式サイトをご覧ください。
図1:LINEギフトのトップページ
LINEアプリ内でLINEギフトのトップページに遷移する際、必ず最初にあるエンドポイントへリクエストを送信し、その後に他のエンドポイントへのリクエストを続ける仕様になっています。そのエンドポイントはユーザ自身の情報や後続の処理に必要なデータをレスポンスとして返すものであり、ここではこのエンドポイントを「/meエンドポイント」と呼びます。/meのレスポンスタイムが長いと、トップページの表示が全体として遅くなりユーザ体験への悪影響につながります。そのためこのAPIのパフォーマンス改善をすることは非常に重要であり、インターンシップ期間中のメインテーマとすることにしました。

図2:トップページへ遷移する際のAPIアクセスの順序
パフォーマンス改善のプロセス
既知のボトルネックの解消
まずは当時わかっていた /meの処理のうち改善の余地がある部分の修正をしました。
1点目として社内の別サービスに対して同種のリクエストを複数回送信していた処理を改善しました。社内の別サービスというのはIDをリクエストとして受け取って、処理を行った上でレスポンスを返すものです。このサービスに対して以前は、ID1つにつき1リクエストを送信していたため、リクエストごとにネットワーク遅延が発�生していました。これを一度に複数のIDをまとめて処理できるBulk APIを使用するように変更することで、ネットワークへのアクセス回数を減らし遅延を抑えるようにしました。
2点目としては外部サービスのメンテナンス情報をデータベースから毎回取得していた部分の改善をしました。メンテナンス情報は全ユーザにとって共通の情報であり、毎回データベースから取得する必要もないので、オンメモリでキャッシュすることにしました。/meはリクエスト数が非常に多く、多数のスレッドが同時にキャッシュへアクセスすることが想定されていたため、スレッドセーフなものを利用する必要があります。Javaにおけるオンメモリのキャッシュ実装は、標準ライブラリのConcurrentHashMapを使うものなどいくつか候補がありましたが、今回はGuavaのLoadingCacheを用いました。実装例は以下のとおりです。
@Service
public class ExternalMaintenanceService {
...
public ExternalMaintenanceService(ExternalMaintenanceService externalMaintenanceMapper, Clock clock, Ticker ticker) {
this.externalMaintenanceMapper = externalMaintenanceMapper;
this.externalMaintenanceCache = CacheBuilder.newBuilder()
.ticker(ticker)
.expireAfterWrite(CACHE_DURATION_SEC, TimeUnit.SECONDS)
.build(new CacheLoader<>() {
@Override
public List<ExternalMaintenance> load(Long key) {
return externalMaintenanceMapper.findMaintenanceByTime(key);
}
})
}
}コード1:オンメモリキャッシュの実装例
GuavaのLoadingCacheを使ってオンメモリキャッシュを実装するメリットの1つは、expireAfterWriteで指定した期間が過ぎるとエントリが自動的に削除される点です。そのため、エントリ管理に関して追加の実装をする必要がありません。またtickerを用いるとテストの際に時間の経過を仮想的に制御できるため、キャッシュの期限切れに関するシナリオを簡単に検証できるという利点もあります。
修正の効果の計測(1回目)
修正1点目の社内の別サービスへのBulkリクエストは2024年9月3日に、修正2点目のメンテナンス情報のオンメモリキャッシュは2024年9月17日に、それぞれリリースされました。それぞれのリリース後に修正の効果を検証するため、nginxのログから得られるレスポンスタイムがどう変化したかを確かめました。2回のリリース前後でのレスポンスタイムの変化を表すグラフは以下の図3の通りです。図3から見てわかる通りレスポンスタイムはほとんど変化しませんでした。平均するとむしろ3ms程度悪化する結果となりました。修正内容から考えるとレスポンスタイムが全く改善しないというのは想定外のことでした。
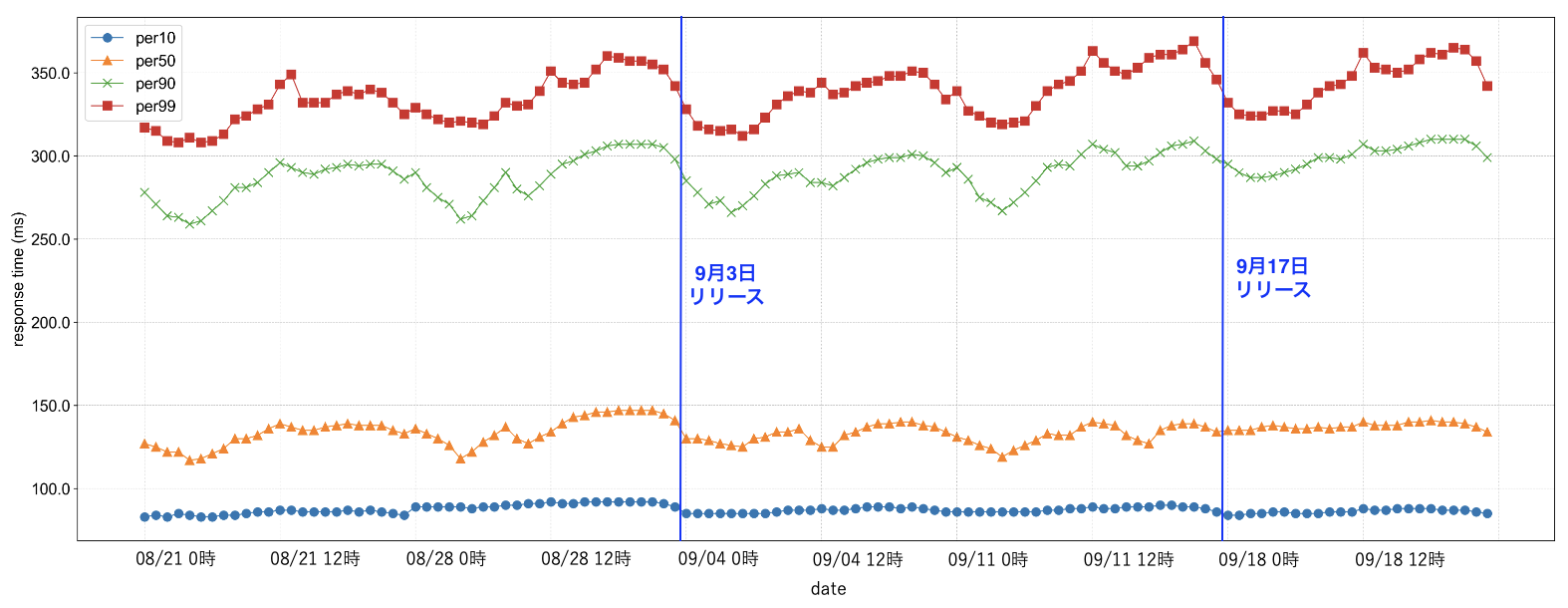
図3:2回のリリース前後でのレスポンスタイムの変化
Pyroscopeの導入
もともと部署内でContinuous Profiling Toolを導入したいというニーズがありました。��さらに、/meのレスポンスタイムが改善しなかった理由も明らかになるのではということで、次にPyroscopeを導入することにしました。
Continuous Profiling Toolは、アプリケーションのプロファイルデータを継続的に収集し、CPUやメモリがプログラム中のどの部分で多く消費されているかを分析するツールです。PyroscopeはContinuous Profiling Toolの1つで、Grafana Labsが管理するOSSです。
Pyroscopeは「Pyroscope Agent」と「Pyroscope Server」という2つの主要なコンポーネントにより、プロファイルデータの収集と分析を実現しています。Pyroscope Agentを各アプリケーションに導入し、定期的にプロファイルデータをPyroscope Serverに送信します。Pyroscope Serverでは受信したプロファイルデータの保存、UI上でのプロファイリング結果の表示、統計クエリの処理を行います。
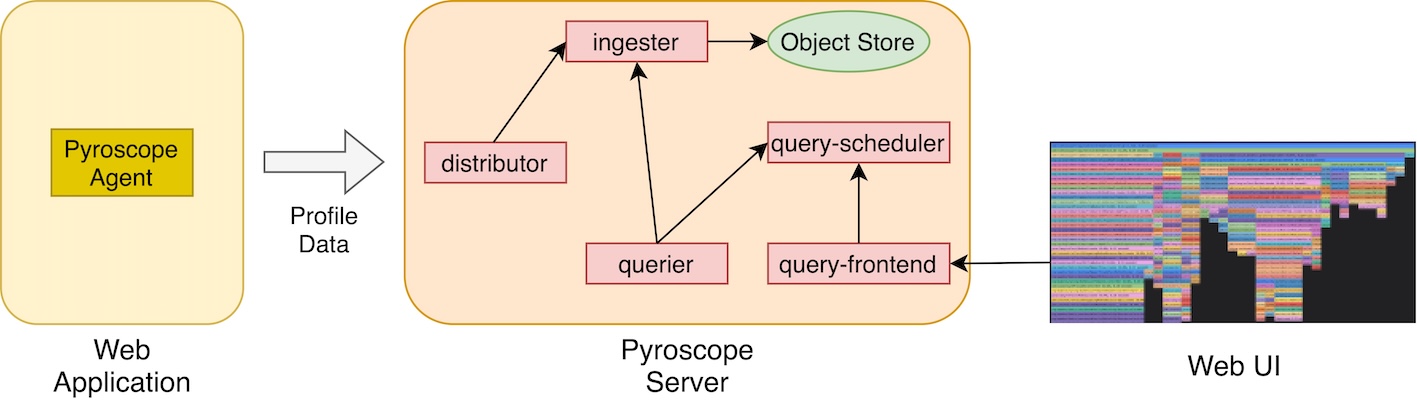
図4:Pyroscopeの構成図(一部を省略)
Pyroscope Serverのデプロイにはさまざまな方法がありますが、今回はKubernetes上にデプロイする方法を選択しました。具体的にはVKS(Verda Kubernetes Service、社内のKubernetes実行基盤)上でPyroscope Serverをホストしました。Kubernetesがほぼ初めてであり、罠もいくつかあったため苦戦しました。罠というのは、
- Podがスケジュールされるために必要な最小リソース量であるrequestsの合計値がデフォルトではかなり多めに設定されており、ノードのリソースが少ない場合正常に起動できないPodが存在すること
- Dockerによりデプロイしたときと、Kubernetesによりデプロイしたときでダッシュボードにアクセスする方法が違うこと
でした。
またPyroscope AgentをJavaアプリケーションに導入しました。Agentに対して設定するApplicationNameを環境ごとに変えることで、環境それぞれでのプロファイルデータをわかりやすく管理し、比較もできるようにしました。
真のボトルネックの発見
Pyroscopeを導入し、アプリケーションのフレームグラフを観察した結果、/meエンドポイントのメソッド処理時間の大半を占める特定の処理を突き止めることができました。/meのレスポンスにはユーザに対して実施するA/Bテストの一覧を持つフィールドがあります。このA/Bテストの一覧をRedisから取得する部分が図5の赤色の矢印で示している部分です。この部分が全体のおよそ65%を占めていました。

図5:Pyroscopeから得られたアプリケーションのフレームグラフ
さらに5月からの/meの平均レスポンスタイムをnginxのログから算出しました。すると、レスポンスタイムが5月から緩やかに増加し、9月中旬にかけて60ms(約55%)増加していたことがわかりました。(図6)
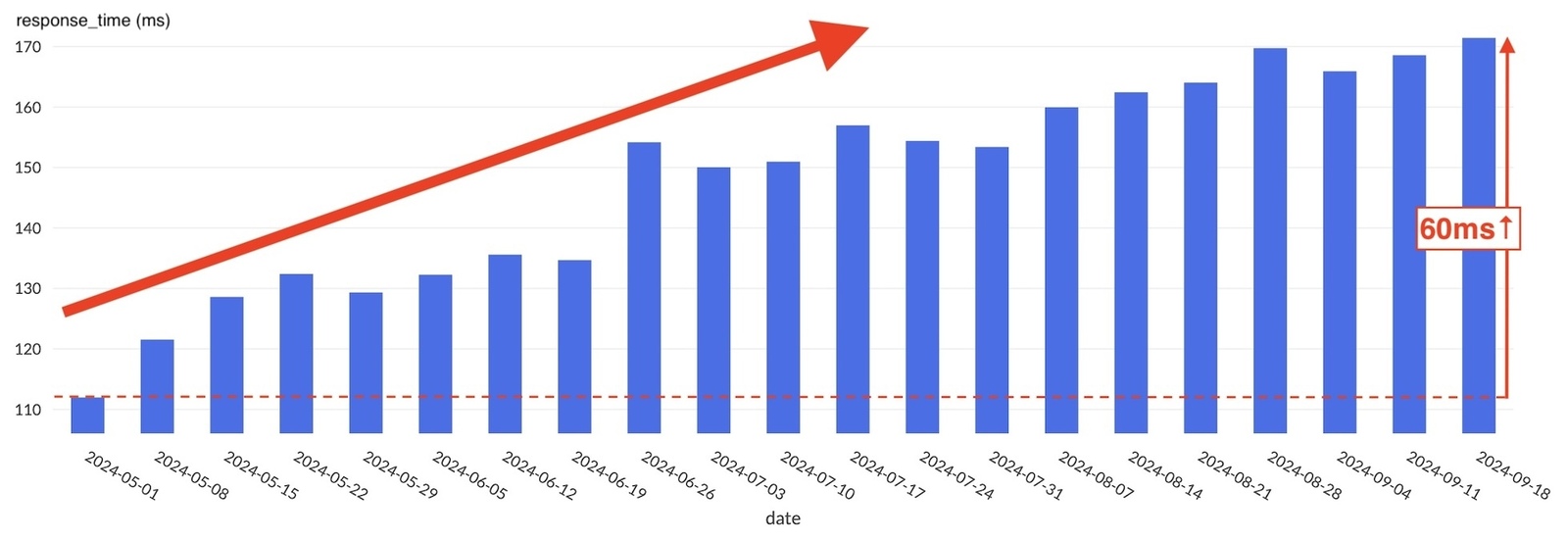
図6:5月ごろからの平均レスポンスタイムの増加の様子
後述しますが、A/Bテストの一覧をRedisから取得する処理にかかる時間は、Redis内のA/Bテストの数が増加�するにつれて増えるようになっています。Redis内のA/Bテストの数を推測すると以下の図7のようになり、これも4月ごろから急激に増加していることから、
A/Bテストの数の増加 → A/Bテストの一覧をRedisから取得する処理にかかる時間の増加 → 全体としての平均レスポンスタイムの増加
という構図になっており、真のボトルネックがA/Bテストの一覧をRedisから取得する部分にあるであろうことが明らかになりました。そしてこのA/Bテスト数の増加に伴う処理時間の増加が、社内の別サービスへのBulkリクエストやメンテナンス情報のオンメモリキャッシュといった、最初の修正の効果を打ち消していたという仮説が立てられました。
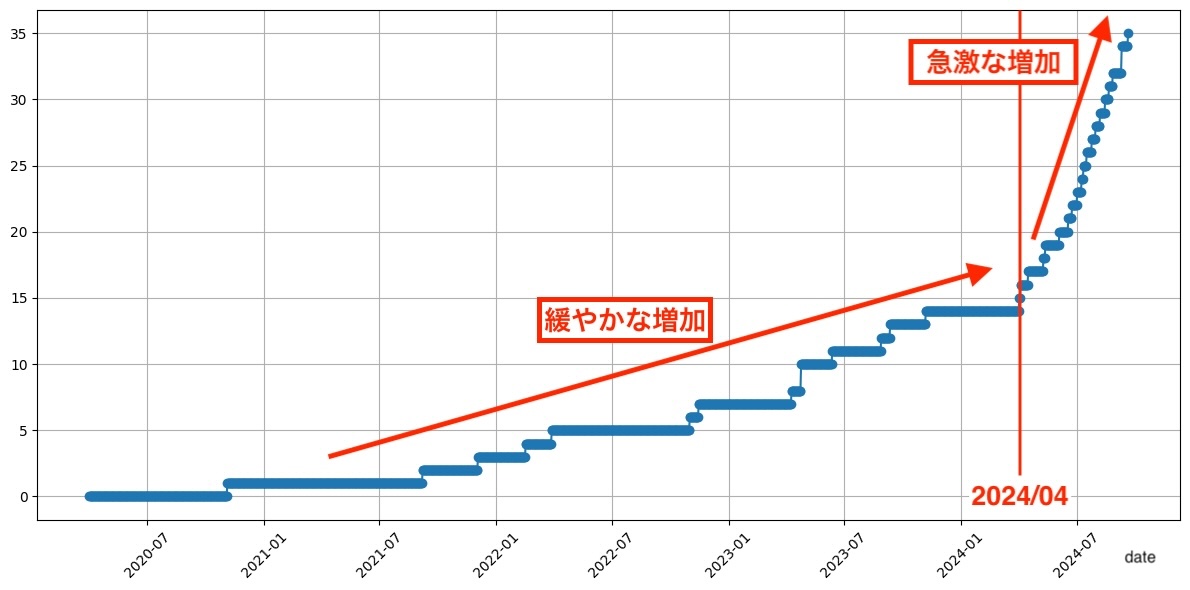
図7:Redis内のA/Bテスト数の変化
この真のボトルネックは一見すると、最初から見つけられていても不思議ではないように思えますが、
- ローカルで実行するときにはRedisにA/Bテストを格納するバッチ処理が走らない → Redis内のテスト件数が0件となる → RedisからA/Bテストを取得する処理の時間が0秒だった
- PyroscopeなどのContinuous Profiling Toolがインターン開始時に未導入であり、実際にデプロイされた環境でのアプリケーションの処理の様子について知る手段がなかった
ことが原因で見つけられなかったと考えています。
真のボトルネックの解消
図5からもわかるとおり、A/Bテストの一覧をRedisから取得する処理のうち大きな割合を占めているのが、
- Redisから�値をとるためのキーを生成するために
String.format()を実行している部分 - テストを取得するためにRedisに対するhgetコマンドを実行している部分
です。A/BテストをRedisから取得する際、A/BテストのIDの一覧をあらかじめ取得しています。そして、for文の中でA/Bテストの数だけ以下のようなfindExperienceByIdメソッドを実行することで、1つずつA/Bテストを取得していました。
public Experience findExperienceById(String experienceId, String userId) {
final String a = redisService.hget(Cache.EXPERIENCE.key(experienceId), "a");
final String b = redisService.hget(Cache.EXPERIENCE.key(experienceId), "b");
final String c = redisService.hget(Cache.EXPERIENCE.key(experienceId), userId);
final String d = redisService.hget(Cache.EXPERIENCE.key(experienceId), "d");
final String hoge = getHoge(userId, d);
final String e = redisService.hget(Cache.EXPERIENCE.key(experienceId), hoge);
...
return experience;
}コード2:改善前のfindExperienceByIdの実装例
findExperienceByIdメソッドの中では、
- 内部で
String.format()を使用しているCache.EXPERIENCE.key()によりRedis用のキーを生成し、 - hgetコマンドをRedisに対して発行する
ということを5回ずつ行っています。for文の中でこれが毎回実行されるので、A/Bテストの個数×5回だけString.format()とRedisへのhgetコマンドが走り、いわばRedisに対するN+1のような状態になっていました。Redisに格納されていたA/Bテストの個数は40件程度であり、つまり1リクエストにつき40件 × 5回 = 200回のhgetコマンドとString.format()が実行されていました。
ユーザに��配信されるA/Bテストは数件程度なので、Redis内のテスト数は過剰だと言えます。格納されているA/Bテストを精査したところ、期限切れのテストもRedisに格納されていることが判明しました。Redis内のA/Bテストは、10分ごとにバッチ処理が実行されて更新されます。このbatch処理のロジックを変更し、期限切れのテストをそもそもRedisに格納しないことで、Redis内のA/Bテストの数を減らしました。
さらに、A/Bテスト1つにつき5回hgetコマンドを実行するという、Redisに対するN+1状態も解消しました。Redisには同一のキーのハッシュから複数のフィールドの値を取り出すhmgetコマンドがあります。これを用いて5回のhgetコマンドを1回のhmgetコマンドと1回のhgetコマンドに置き換えることで、ネットワークレイテンシを軽減できます。findExperienceByIdメソッドを以下のコード3のように変更しました。
public Experience findExperienceById(String experienceId, String userId) {
final CacheKey<String> cacheKey = Cache.EXPERIENCE.key(experienceId);
final List<String> fields = List.of("a", "b", userId, "d");
final Map<String, String> result = redisService.hmget(cacheKey, fields);
final String hoge = getHoge(userId, result.get("d"));
final String e = redisService.hget(Cache.EXPERIENCE.key(experienceId), hoge);
...
return experience;
}コード3:改善後のfindExperienceByIdの実装例
修正の効果の計測(2回目)
これらの改善によりレスポンスタイムがどのように変化したのかを再び計測しました。nginxログから得られる平均レスポンスタイムの変化を表すグラフを図8に示します。修正により結果として、70ms(約40%)レスポンスタイムを軽減できました。つまり、RedisからA/Bテストを取得する処理に関連して行った一連の改善は、レスポンスタイムに対して非常に大きな軽減効果があったことを意味します。
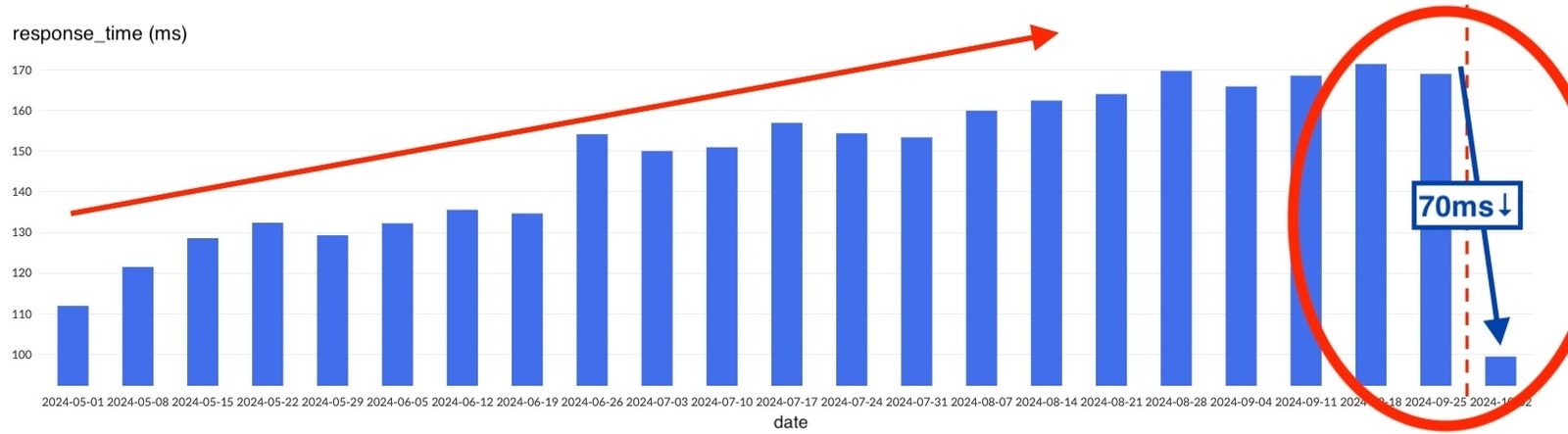
図8:2回目のリリース後の平均レスポンスタイムの計測結果
その他のタスク
/meの改善と並行して、SREの普段の業務を体験できました。インターン期間中に取り組んでいたタスクを以下で紹介します。
- 乱数生成器の変更
- データベースの負荷対応(CPU使用率が非常に高いクエリの実行先をPrimary DBからReplica DBに変更する)
- イベント告知のタイミングでCPU使用率が異常に高くなったことに関する調査
学んだこと・成長できたこと
Java+Spring、Kubernetesといった技術を用いた実務が初めてではありましたが、 キャッチアップして何とか成果を残すことができました。他の言語で開発していた経験を十分に活かすことができた結果であると感じています。
「推測するな、計測せよ」という言葉がありますが、改めて計測することの重要性を実感しました。Pyroscopeを導入しなければ、/meエンドポイントのボトルネックがA/Bテストを取得する部分にあることはわかりませんでした。また、/meのレスポンスタイムの変化を時系列で比較しなければ、最初の修正でレスポンスタイムが改善しなかった原因もわかりませんでした。さらにPyroscopeの導��入が、特にユーザ体験の向上に大きく貢献することも体感しました。LINEギフトでは、もともとPrometheusを利用して、各種メトリクスをGrafanaのダッシュボード上で確認できるようになっていました。そこにPyroscopeなどのツールも併せて導入することで、特定のAPIのパフォーマンスを改善する際に、より詳細なボトルネックを特定できるようになります。
今回初めてSREとしての本格的な業務に挑戦しましたが、SREという業務は良い意味で泥臭いものだと感じました。LINEギフトは何年も開発が続けられ、今も稼働している大きくて複雑なシステムです。もちろん、ISUCONのような単純化された環境とは違い、簡単に問題を一掃できる手段があるわけではありませんし、それをすぐに本番環境へ反映できるわけでもありません。だからこそ、日々の小さな改善の積み重ねが本当に重要だと感じました。自分の引き出しが少ないがために詰まることがあり経験もかなり大事だと感じたので、これからもエンジニアとしていろいろな経験を積んでいきたいです。
おわりに
6週間のインターンシップでは、/meのボトルネックの発見・改善、Pyroscopeの導入などさまざまなタスクに取り組み、多くの貴重な経験を積むことができました。しかし、常に順調に業務を進められたわけではなく、未経験の技術や社内独自のインフラに触れる中で、行き詰まることもありました。そんなときに、Slackで質問に答えてくださったり、デイリーミーティングで相談に乗ってくださったりしたメンターの宇井さんのおかげで、無事に多くの課題を乗り越えることができました。また、技術的なサポートだけでなく裏側でさ��まざまな調整もしてくださった上長の木本さん、コードレビューなど技術的にアドバイスをくださったSREチームの方々のサポートも大変心強く、充実した6週間を過ごせました。
SREチームの方々だけでなく、開発チームの方々とも交流する機会があり、オフィスツアーや食事会に連れて行っていただきました。同年代のエンジニアの方々との交流は非常に刺激的で、将来のキャリアに対するモチベーションが一層高まりました。インターンシップ期間中お世話になった皆様へ心から感謝申し上げます。
インターンシップで得た貴重な経験を糧に、今後もエンジニアとしてさらに成長できるよう引き続き学びと挑戦を続けていきます。


