北海道大学大学院情報科学院修士1年の山村尚也です。2024年9月9日から10月4日までの4週間、LINEアプリのトーク機能部分のバックエンドの開発を担当しているチームでインターンをさせていただきました。この記事ではインターンシップの内容について説明させていただきます。
背景
Operation log と Kafka
LINEトークのバックエンド(talk-server)では、Apache Kafkaという分散型のメッセージキューを利用しています。

LINEトークのアプリケーション上でユーザーがチャットで特定の操作を行うと、操作の内容を表すoperation logと呼ばれるデータがtalk-server上で生成されます。operation logはtalk-serverからKafkaに送られます。 一方、LINE MUSICやLINE VOOMなどの種々のサービスは、Kafkaからoperation logを取得して処理を行います。Kafkaでは前者のようにメッセージを生成する側をproducer、後者のようにメッセージを取得して処理する側をconsumerと呼びます。Kafkaがproducerとconsumerの間に介在することで、サービスの独立性や通信の効率などが向上します。
Dual Cluster
LINEではサービスの可用性を高めるため、operation logのような重要なtopicに対してdual-clusterを設定しています。

平常時にはKafkaのprimary clusterにメッセージがproduceされ、primary clusterの異常時にはsecondary clusterへメッセージがproduceされます。consumerはprimary clusterとsecondary clusterの双方からメッセージを取得する必要があります。二つのclusterからconsumeするのに必要な処理はアプリケーションによって異なるため、各consumerにおいてこの部分を適切に実装する必要があります。
過去の事例
LINEのKafka clusterは基本的に安定しており、障害が発生することは稀です。しかし過去にはprimary clusterに障害が発生し、secondary clusterへのfailover(primaryに障害が発生したときにsecondaryに切り替えること)を設定していなかったサービスに影響が発生した事例もあります。そのため、LINEのような高い可用性が求められるサービスではfailoverの機能が非常に重要です。
インターンシップのスケジュール
Week 1 (9/9 - 9/13)
- PCのセットアップ
- Kafkaのチュートリアル
- 社内のビデオ教材を利用した学習
Week 2 (9/17 - 9/20)
- Kafkaのシリアライザを利用したfailure injectionを設計(要件を満たせないことがわかったため、不採用)
Week 3 (9/24 - 9/27)
- 社内ライブラリを利用したfailure injectionの設計
- Tec Specの執筆
- 実装
Week 4 (9/30 - 10/4)
- レビューをうけて実装の修正
- beta環境でのテスト
- チーム内での成果発表
概要
operation log の producerには、secondary clusterへのfailoverが実装されています。具体的には、primary cluster対応するprimary producerと、secondary clusterに対応するsecondary producerという、2つのproducerを内部的に持っています。このインターンでは、primary producerがmessageをproduceする過程で例外を発生させ、failoverを引き起こしました。
failure injectionの際に検証したのは以下の2点です。
- producer側のfailoverが起こってい�るか
- consumer側はsecondary clusterをconsumeできるているか

failure injectionの方法
社内の別のチームがKafka producerのラッパークラスとしてメッセージ送信のタイミングで意図的な例外を発生させることができるproducerを整備しており、今回のテーマに合致していたためそれを利用しました。また、Central Dogmaを利用してfailureの起こる確率を制御しました。Central Dogmaを利用することで、設定の変更をGitHubのプルリクエストで行えるようになり便利でした。
実装
レビューの過程で大幅に実装が変更されました。シンプルな実装方法やログの見やすさ、メモリリークの可能性などさまざまなことを指摘していただきました。自分の考えられていなかったところを指摘してもらえるのはありがたかったです。
テスト
betaという試験用の環境でテストを行いました。テストの設定は次のようにしました。
- operation logの1%がprimary clusterへのproduceに失敗する
- primary clusterへのproduceが失敗したものは全てsecondaryにproduceされることが期待される
結果
producer側でfailoverが起こっているか、consumerがsecondaryをconsumeしているか、をメトリックを用いて確認しました。
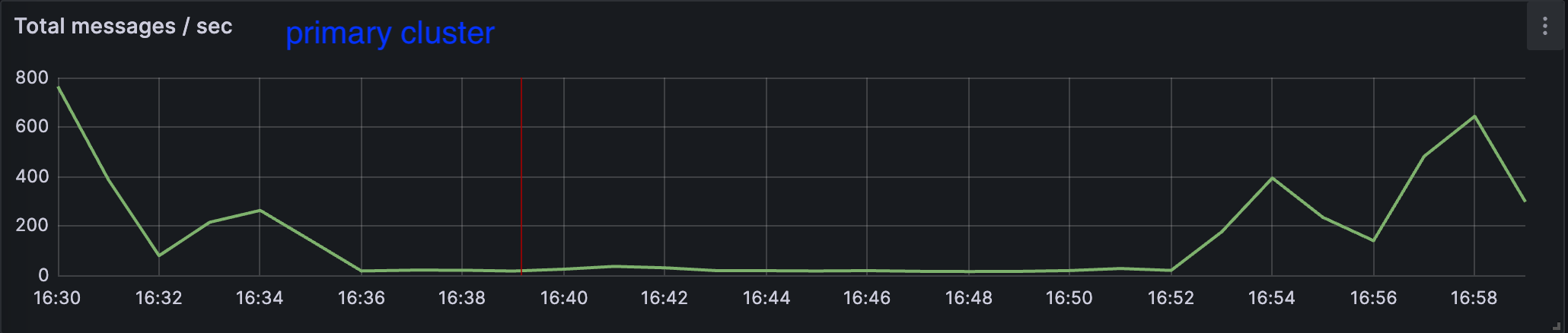
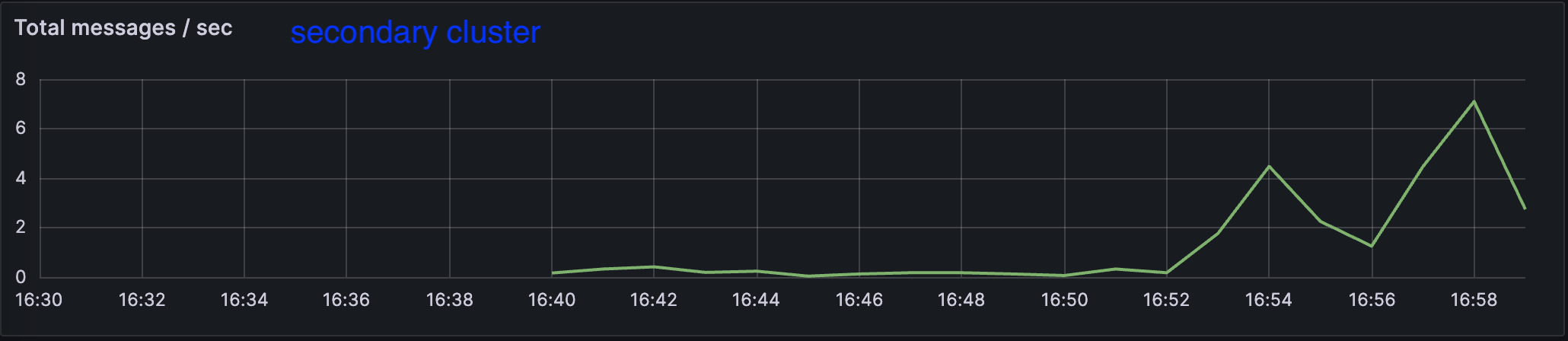
まずproducerについてです。 下の2つの図を比較すると、途中まで0だったsecondary clusterの秒間message数がある時間からprimary clusterの1%の値になっていることが確認できます。設定した通りにproducerにfailure injectionできていることと、期待通りfailoverしていることが確認できました。
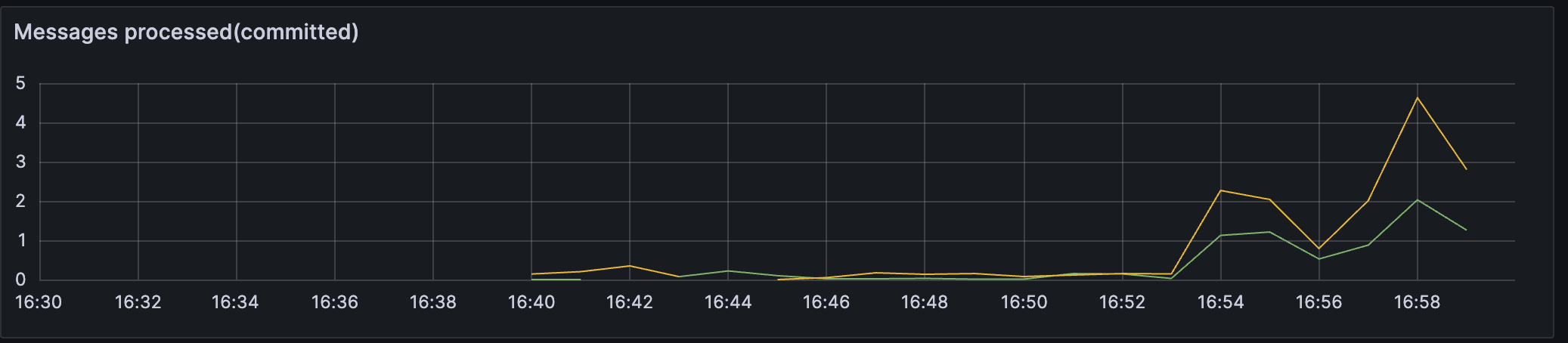
次にconsumerについてです。下図はあるconsumerのsecondary clusterに対応するメトリックです。先程のproducerとほぼ同じグラフになっています。このconsumerはsecondary clusterを正しくconsumeできていると言えそうです。
operation logを利用しているconsumerはいくつもあるので、他のconsumerについても同じように確認を行いました。その結果、複数のconsumerはsecondaryをconsumeしていないことが判明しました。インターンではここまでを確認したところで期間が終了していまいました。重要なサービスはsecondary clusterを利用するべきなので、今後はconsumerへの修正依頼等が発生するものと思われます。
まとめ・感想
今回のインターンでは、operation logのKafka producerへのfailure injectionを行い、failoverの機能を検証しました。その結果、一部のサービスでsecondaryへのfailoverが正しく設定されていないことが判明しました。この結果はLINEというサービスの信頼性の向上に役立つと考えられます。
今回のインターンで行ったことは上記のようにシンプルでしたが、インターン期間中はいろいろと大変なことがありました。環境構築で手間取ったり、failure injectionを行うための方法案がボツになって最初からやり直したり、社内のコードの不思議な実装(実はちゃんとした理由がある)に困惑したりと、各所でつまずいていました。また、レビューのプロセスも印象に残っています。時間はかかりましたが、自分が気にかけていなかった点を指摘してもらうことができました。
会社・チームの雰囲気はとてもよく、オンラインでしたが働きやすかったです。Slackでわからないことを聞いたりレビューのお願いをしたりすると、チームの方々がすぐに反応してくれました。エラーやソースコードを見せると数分で的確なアドバイスをいただけたことがあり、反応の速さとスキルの高さに驚きました。対面でのランチ会や懇親会等もあり、貴重な機会でした。
メンターのお二人をはじめとするMPEのみなさん、人事の方々、4週間ありがとうございました。


