こんにちは、LINEヤフー株式会社でRedisチームに所属している加藤です。現在はLINEヤフーの社内向けのDatabase as a ServiceとしてRedis DBaaSの開発と運用を行っています。
Redis DBaaSは、ヤフー株式会社(現LINEヤフー株式会社)で提供開始し7年がたちます。運用しているRedisは10,000台を超え、合算で毎秒1,000万以上のリクエストを処理する大規模なRedis基盤となりました。この記事では、まずRedis DBaaSで作成できるRedisのHA(High Availability)構成を説明し、次にRedisプラットフォームの成長とともに増加した社内のユーザーへのサポートの中で、ユーザーに安心してRedisを利用してもらうために行っている取り組みについて紹介します。
Redis DBaaSのHA構成
Redisはインメモリ(in-memory)データベースであり、メモリ上のデータは揮発性のため、何らかの障害でサーバーがダウンした場合やRedisプロセスが終了した場合、データが消失する可能性があります。Redis DBaaSでは、データの消失防止とユーザーの要望に沿ったスケーリングのためにRedisクラスターを提供しています。
Redis DBaaSのプロダクション環境で提供しているRedisクラスターでは「1 Master - 2 Replica」構造のシャードを3つ用意した、計9台のRedisノードを1つのクラスターの最小構成として採用しています。
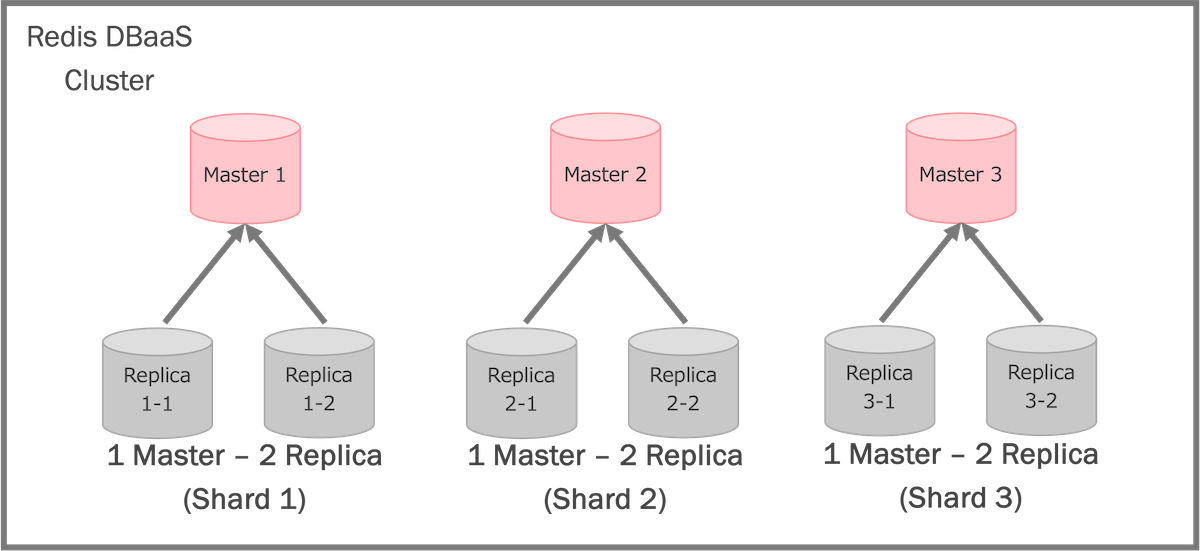
シャード構造のクラスターを採用するメリットの1つが高可用性(HA)です。Replicaノードを用意することで、Masterノードに問題が発生したときにフェイルオーバーが行われ、短いダウンタイムでリクエストの処理が可能になります。
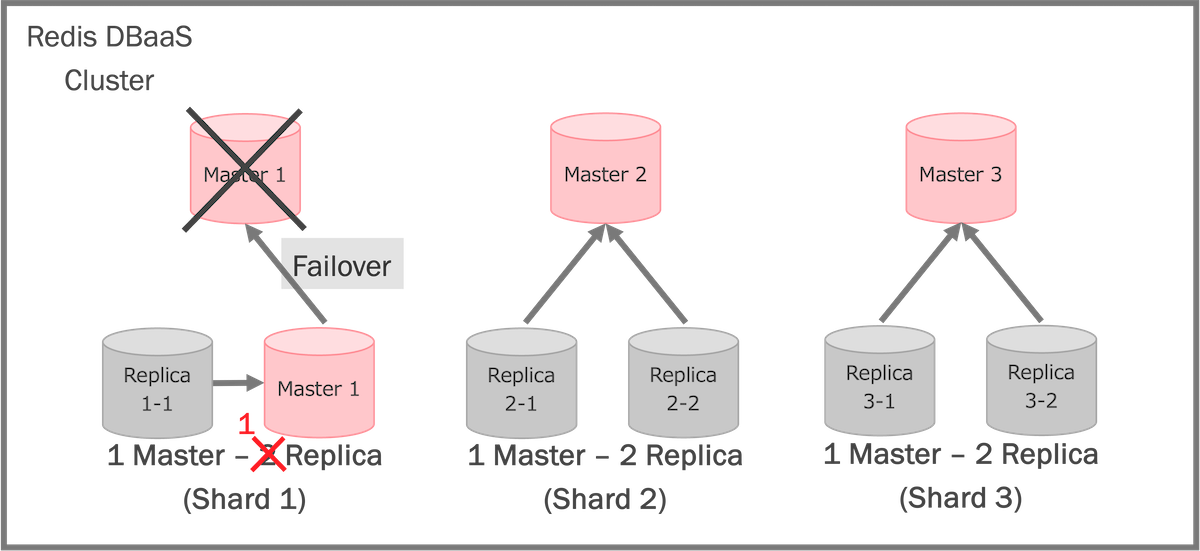
Masterノードの問題を考えれば、なぜ「1 Master - 1 Replica」構造ではなく「1 Master - 2 Replica」構造にしているのか疑問に思われるかもしれません。「1 Master - 2 Replica」構造にすることで、Redisサーバーを動かしているVM(Virtual Machine)の不調やメンテナンスの実行中など、1台のノードが停止されてもシャードごとに「1 Master - 1 Replica」構造で動作できる最低限の可用性を担保しています。
他のメリットとしては、データの分散が可能なことです。Redisクラスターへ保存されたデータは自動的に各Masterノードへ分散されるため、単一のRedisでは処理の仕切れないデータ量の格納と大量のリクエストを捌くことができます。また、MasterノードとReplicaノードをそれぞれでwrite/readを分けることでスループットの向上も可能です。
脅威は思いがけないところからやってくる
今まで運が良かったこともありますが、「1 Master - 2 Replica」のHA構造を採用しているため、長い間事故も起きず、メンテナンスも安全に作業を進めることができていました。
しかし事件は突然やってくるもので、短期間に2つの重大な問題が発覚しました。
1つは、社内のPaaS環境下でSpring Boot Actuatorを使用してRedisのヘルスチェックを行っている場合に、アプリケーションがクラッシュする報告が複数あったことです。Spring Boot Actuatorのヘルスチェックでは、Redisクラスター内のノードが1台でもダウンしている場合に異常として検知されていました。社内PaaSではヘルスチェックの結果を元にAppの管理を行っていたため、1台のRedisノードがダウンすると自動的にAppが再起動される状態でし��た。この問題は社内環境によるものであり、Redis DBaaS側でもダウン検知を行っていること、またクライアントライブラリ側の機能でRedisクラスターへ追従できることから、Spring Boot Actuator経由でのヘルスチェックを回避するように周知を行いました。
次に、JavaのRedisクライアントであるLettuceでcancelCommandsOnReconnectFailureが有効の場合、セッションごとのデータが競合するリスクがあることが判明しました。原因はRedisへのreconnection時のエラーに伴い、commandHandlerのresetが引き起こされることで、command stackが強制的にクリアされ、Redis Protocolの内容とCommandHandlerのコマンド処理順の対応関係が破壊されることです。その結果、リクエストとレスポンスがランダムに食い違った状態になる可能性があり、意図しない結果がクライアントに返ることで情報漏えいを引き起こす可能性もありました。このオプションは極めて危険と言えます。このオプションは既に廃止予定となっており、またデフォルトでは無効になっていたため、危険性と有効にしないよう周知を行いました。
Redis外の影響に立ち向かう
短期間に発覚した問題はどちらもRedisクライアントやフレームワークの取り扱いがきっかけであり、信頼していたHA構成では防ぐことはできません。非推奨なオプションと周知することは大切ですが、ユーザーが実際に理解しているかを追うことは容易ではありません。
Redisチームでは、Redis DBaaSの開発運用だけでなく、ユーザーのアプリケーションが安定稼働できるようサポートも行っています。そこで、この問題を解決するために、Redisクライアント起因の事故を削減するプロジェクトを開始し、Redis DBaaS用のコード検査ツールを開発しました。
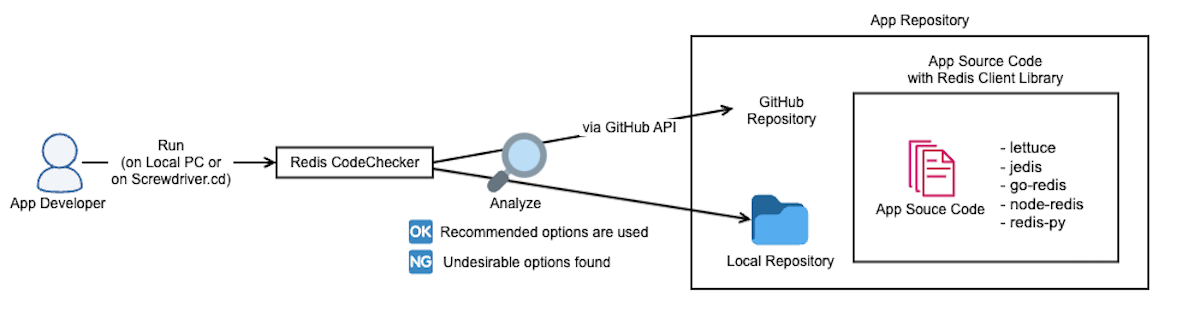
機能としては、ユーザーが実装したソースコードを解析し、Redis関連の非推奨オプションの使用有無をチェックするものです。コマンドラインツールとして提供されており、使い方は対象のリポジトリを指定してツールを実行するだけです。リポジトリ内のRedisクライアントの種類とバージョンを判定し、対応するクライアントの注意項目をチェックします。現在は5つのRedisクライアント(Jedis、Lettuce、redis-py、go-redis、node-redis)に対応しています。
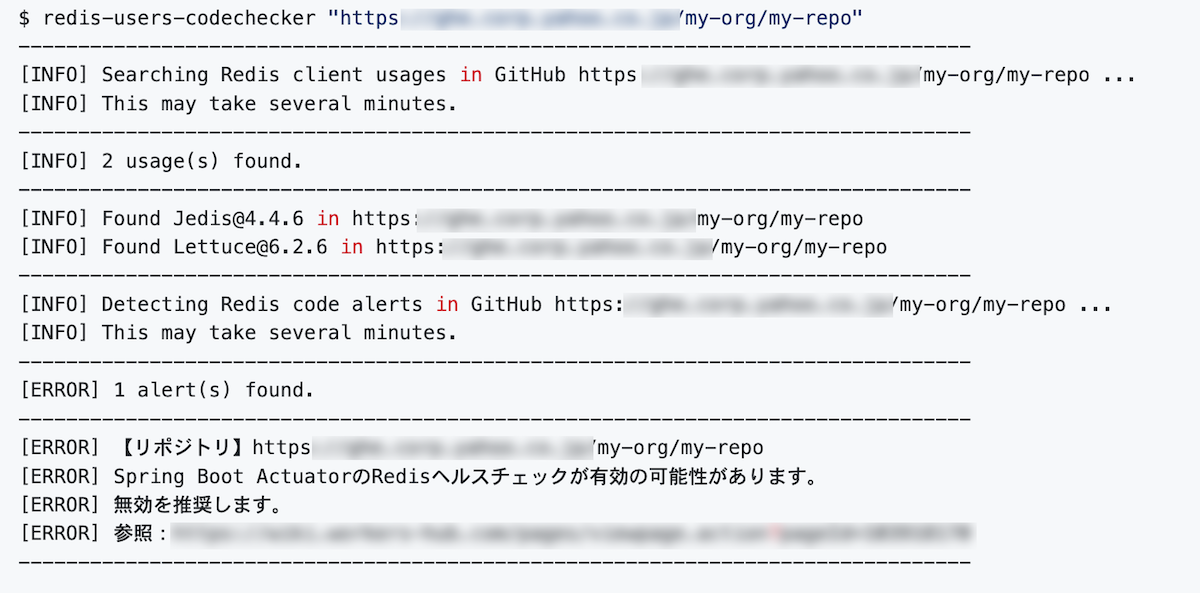
以下の実行例ではJedis, Lettuceのクライアントが見つかったため、Spring Boot Actuatorでヘルスチェックを行っている設定を検知しています。
当初の運用では、管理者側でパブリックリポジトリに対する一括チェックを毎週実行し、非推奨オプションが検知された場合はユーザー個別に連絡して修正を依頼していました。これまでに検知されたリポジトリは300件以上! 私たちの想像よりも多くのアプリケーションが危険な状態にあったのです。
この取り組みが未然に事故を防いだことに一役買っていたことは間違いありませんでしたが、この運用を続け�ていくうちにいくつかの不安も出てきました。
プライベートリポジトリに対するチェックができないこと、チェックを行う前に稼働してしまっているアプリケーションでは事故のリスクが残っていることです。そこで、ユーザー自身でチェックを行えるように既存のツールを拡張し、アプリケーションの開発時にローカル環境でのチェックやCI/CDツール上に組み込むことで、非推奨オプションの使用による事故を未然に防ぐことができるようにしています。
事前に事故を見つけるために
コード検査ツールを利用することで、既知のオプションや設定由来の事故は未然に防ぐことができるようになりました。しかし、コード検査ツールではアプリケーションの実装まではチェックできないため、適切なオプションを利用していたとしてもエラーハンドリングの不備が事故を引き起こすかもしれません。
ではユーザーは、実際にRedisクラスターに障害が発生したときのアプリケーションの挙動をどうやって確かめればいいでしょうか?
ユーザーがアプリケーションに使っているRedisを実際にダウンさせることができれば良さそうです。しかし、DBの運用に慣れていないユーザーはどのRedisノードをダウンさせればいいのか、必要なテストを網羅できているか不安になってしまいます。そこで私たちは最小単位のダウン(Redisノード1台の停止)からクラスター内の全ノードダウンまでのテストケースを用意し、アプリケーションのリリースを行う前に障害時のRedisノードの挙動を試験できる機能を提供しています。実際に用意したテストケースは以下のとおりです��。
| No. | テストケース | 想定状況 |
|---|---|---|
| 1 | 1台の Replica 停止 | 通常時のメンテナンスが行われている状況 |
| 2 | 1台の Master 停止 | フェイルオーバーが発生する状況 |
| 3 | 1シャード内の全 Replica 停止 | 1シャードのreadリクエストが失敗する状況 |
| 4 | 過半数の Master 停止 | 過半数のMasterへのリクエストが瞬断する状況 |
| 5 | 全 Master 停止 | 全Masterへのリクエストが瞬断される状況 |
| 6 | 1シャード停止 | 1シャードのwrite/readが失敗する状況 |
| 7 | 全ノード停止 | Redisへのアクセスが失敗する状況 |
補足になりますが、クラスター内の過半数のMasterがダウンした場合、クラスターダウンと判定されリクエストの処理が継続できなくなります。
以下はユーザー向けのクラスター管理画面の一部です。クラスター内のノード情報欄に障害試験の項目を追加し、ユーザーの好きなタイミングでテストを実施できるようにしました。
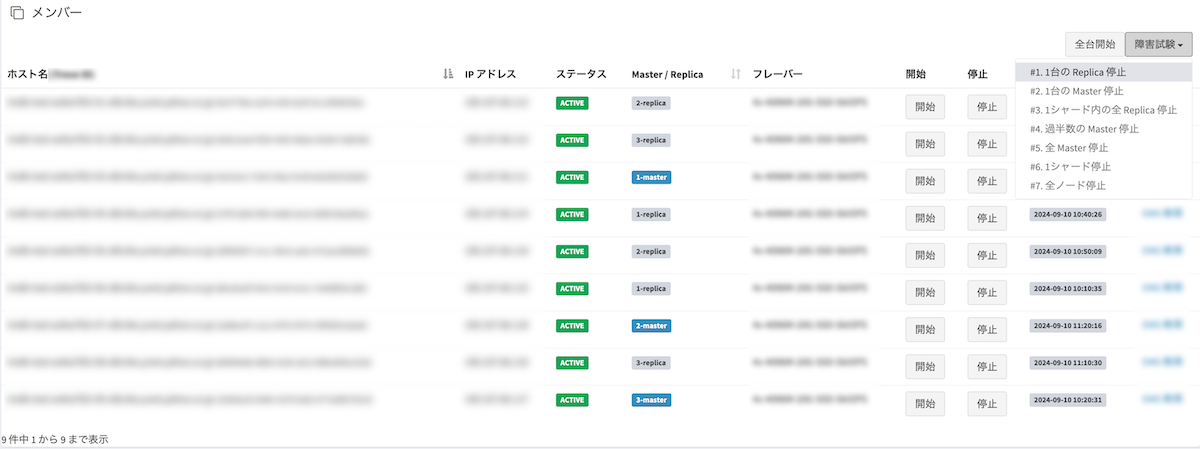
それぞれのノードがMaster, Replicaのどちらかをリアルタイムに取得し、ユーザーがテストに必要な情報を把握できるようにしています。また、先に用意したテストケースごとにノードを選出する機能を備えることで、ユーザーが必要なテストケースを実行するだけで障害時の挙動を再現できる仕組みを整えています。
おわりに
LINEヤフーとなり今ま�で以上に多くのサービスが生まれ、より多くのアプリケーションが開発されても、これらのツールが安全なRedisの利用を実現しています。
今回の記事では、LINEヤフーで運用されているRedis運用のほんの一部しか紹介できていません。管理者向けの運用ツールやRedis監視の方法など、安定した大規模Redis環境の運用の経験や使われているツールなどが多くあります。しかし、プラットフォームはユーザーに利用してもらえてこそ輝くシステムです。そのため、今回はRedisプラットフォームを利用しているユーザーを支える取り組みについて取り上げました。今回紹介できなかった仕組みや取り組みについても、今後の技術ブログで発信していく予定です。
今回の記事を、プラットフォーム運用のヒントにしていただければ幸いです。


