こんにちは。コミュニケーションアプリ「LINE」のモバイルクライアントを開発している石川です。
この記事は、毎週木曜の定期連載 "Weekly Report" 共有の第 44 回です。 LINEヤフー社内には、高い開発生産性を維持するための Review Committee という活動があります。ここで集まった知見を、Weekly Report と称して毎週社内に共有しており、その一部を本ブログ上でも公開しています。(Weekly Report の詳細については、過去の記事一覧を参照してください)
貧血の誤診
foo-module と bar-module の 2 つのモジュールがあり、それぞれのモジュール内にデータモデル FooModel と BarModel が定義されているとします。
// In `foo-module`
class FooModel(val fooValue: Int)
// In `bar-module`
class BarModel(val barValue: ULong)この FooModel と BarModel を相互に変換するロジックが必要になったと仮定しましょう。
この実装担当者は、貧血ドメインモデル を避けたいと考え、変換するロジックを FooModel と BarModel に含めるように実装しました。
// In `foo-module`
class FooModel(val fooValue: Int) {
fun toBarModel(): BarModel? =
if (fooValue > 0) BarModel(fooValue.toULong()) else null
}
// In `bar-module`
class BarModel(val barValue: ULong) {
fun toFooModel(): FooModel? =
if (barValue <= Int.MAX_VALUE.toULong()) FooModel(barValue.toInt()) else null
}しかし�このままでは、foo-module と bar-module で依存が循環してしまいます。そこで、依存の循環を解消するために、以下のようにインターフェースのモジュール *-api-module と実装のモジュール *-impl-module で分割しました。
// `foo-api-module`
interface FooModel {
val fooValue: Int
}
interface FooModelFactory {
fun create(fooValue: Int): FooModel
}
// `foo-impl-module`
class FooModelImpl(override val fooValue: Int): FooModel {
fun toBarModel(): BarModel? =
if (fooValue > 0) BAR_MODEL_FACTORY.create(fooValue.toULong()) else null
companion object {
private val BAR_MODEL_FACTORY: BarModelFactory =
... // Obtain a factory instance by service locator.
}
}
class FooModelFactoryImpl : FooModelFactory {
override fun create(fooValue: Int): FooModel = FooModelImpl(fooValue)
}
// `bar-api-module`
interface BarModel {
val barValue: ULong
}
interface BarModelFactory {
fun create(barValue: ULong): BarModel
}
// `bar-impl-module`
class BarModelImpl(override val barValue: ULong): BarModel {
fun toFooModel(): FooModel? =
if (barValue <= Int.MAX_VALUE.toULong()) FOO_MODEL_FACTORY.create(barValue.toInt()) else null
companion object {
private val FOO_MODEL_FACTORY: FooModelFactory =
... // Obtain a factory instance by service locator.
}
}
class BarModelFactoryImpl : BarModelFactory {
override fun create(barValue: ULong): BarModel = BarModelImpl(barValue)
}これにより、モジュールの循環依存は解消されました。モジュールの依存関係を図示すると次のようになります。
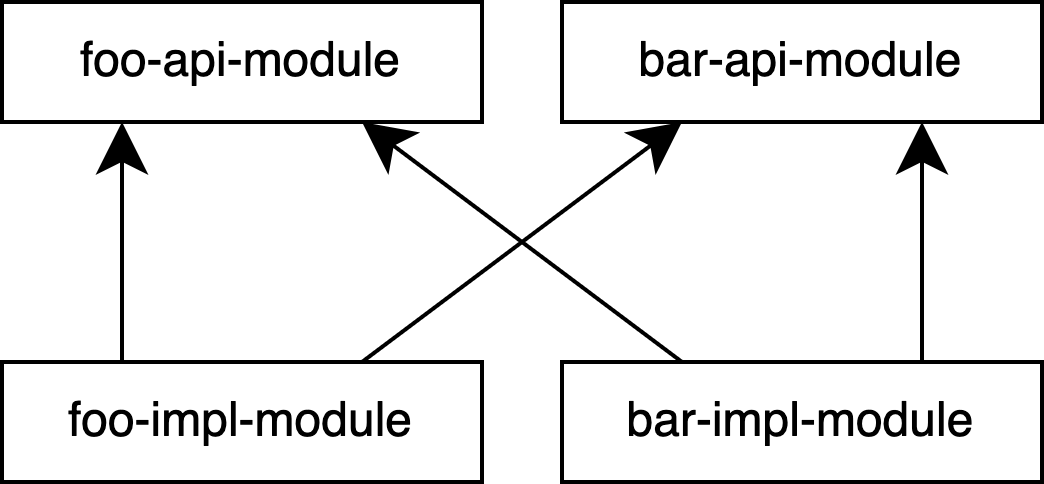
しかし、このコードとモジュール構成には、いくつか問題点があります。それは何でしょうか?
鉄中毒を避ける
このコードとモジュール構成の問題点としては、以下のようなものが挙げられます。
- 信頼できる唯一の情報源 (single source of truth) の欠如: データモデルの変換ロジックが
foo-impl-moduleとbar-impl-moduleに分散している。変換ロジックの仕様が変わったとき、一方の変換ロジックは更新しつつ、反対側のロジックの更新を見落とすというバグが生じかねない。 - 呼び出し元の
*-impl-moduleへの依存: モデルの変換toFooModel/toBarModelを使いたい場合、*-api-moduleではなく*-impl-moduleに依存する必要がある。単にFooModelのインスタンスを作成するためだけでも、FooModelFactoryの実装が必要になる。 - 安全でないダウンキャストの原因:
FooModelインターフェース自身はtoBarModelを持たないため、変換する場合はダウンキャストが必要となる。ただし、他のモジュールで別のFooModel実装がないことは保証できない。
これらの問題を解決するために、いくつかの選択肢が考えられます。
Option 1: ロジックをどちらかのモジュールに寄せる
変換ロジックを foo-module か bar-module のどちらか一方に集めることで、循環の依存を解決するという方法があります。以下の実装では、foo-module が bar-module へ依存するようにし、foo-module に変換ロジックをまとめています。
// `foo-module`
class FooModel(val fooValue: Int) {
fun toBarModel(): BarModel? =
if (fooValue > 0) BarModel(fooValue.toULong()) else null
companion object {
fun fromBarModel(barModel: BarModel): FooModel? =
if (barModel.barValue <= Int.MAX_VALUE.toULong()) {
FooModel(barModel.barValue.toInt())
} else {
null
}
}
}
// `bar-module`
class BarModel(val barValue: ULong)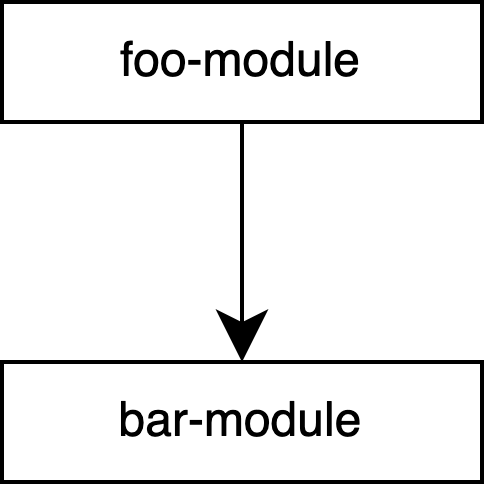
この方法は、「foo-module に依存するモジュールは、すべて bar-module にも依存してよい」という状況下で適用できます。FooModel と比べ、BarModel がよりプリミティブな型である場合が当てはまります。しかし当然ながら、FooModel と BarModel の複雑さが同程度の場合、この方法は不適当でしょう。
Option 2: 変換用の中間モデルを作る
変換を中継するモデル IntermediateModel を作成し、FooModel と BarModel 内で変換ロジックを実装するという方法があります。IntermediateModel は、foo-module と bar-module の双方から独立したモジュール intermediate-module に定義することで、循環の依存を回避できます。
// `intermediate-module`
class IntermediateModel(...)
// `foo-module`
class FooModel(val fooValue: Int) {
fun toIntermediateModel(): IntermediateModel? = ...
companion object {
fun fromIntermediateModel(model: IntermediateModel): FooModel? =
...
}
}
// `bar-module`
class BarModel(val barValue: ULong) {
fun toIntermediateModel(): IntermediateModel? = ...
companion object {
fun fromIntermediateModel(model: IntermediateModel): BarModel? =
...
}
}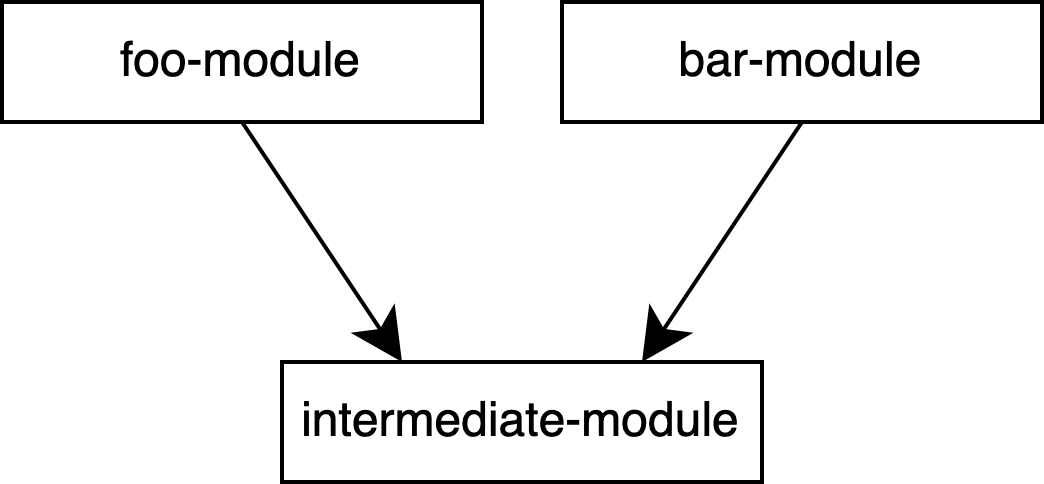
この方法は、相互変換が必要なデータモデルが多いときに有効です。ただし、FooModel と BarModel の 2 しかデータモデルがない場合、中継するモデルを作ることはオーバーエンジニアリングになるでしょう。
Option 3: 変換ロジックを独立させる
根本的には、先述の問題は「無理にロジックをデータモデルに含めようとした」ことによって引き起こされています。 ロジックをデータモデルに含めるのは、詳細を隠蔽する手段であって、それ自体を目的としてはなりません。 基本的に、ロジックやアルゴリズムはデータモデルに依存しますが、その逆になることは稀です。ロジックとデータをまとめることよりも、ロジックとデータの依存の方向を守る方が良い ことが多いです。
今回の場合、データモデルと変換ロジックの依存の関係は以下のようになっています。

この依存関係をそのままコードとして表現すると、以下のようになります。
// `foo-bar-converter-module`
object FooBarConverter {
fun createFooModel(barModel: BarModel): FooModel? =
if (barModel.barValue <= Int.MAX_VALUE.toULong()) FooModel(barModel.barValue.toInt()) else null
fun createBarModel(fooModel: FooModel): BarModel? =
if (fooModel.fooValue > 0) BarModel(fooModel.fooValue.toULong()) else null
}
// `foo-module`
class FooModel(val fooValue: Int)
// `bar-module`
class BarModel(val barValue: ULong)この構造の利点は、あるモジュールが FooModel や BarModel のどちらか一方だけを必要とする場合、もう一方のデータモデルや変換ロジックに依存しなくてよい点にあります。Option 1 や 2 と異なり、FooModel のために foo-module に依存した時に、bar-module や foo-bar-converter-module に依存する必要はありません。
どの処方箋が良いか
先述の説明の通り、Option 1 や Option 2 が適切な状況は限定的です。
Option 1: 一方のデータモデルを使うと、他方も常に必要になる状況で適用できる。一方が他方を概念的、構造的に含んでいる場合であり得る。
Option 2: データモデルの変換元/先が、データモデルのモジュールより広いスコープで使われている状況で適用できる。典型例としては、変換元/先が Protocol Buffers などのインターフェース記述言語で定義されている場合が挙げられる。
それ以外の場合は、Option 3 のように、データモデルと変換ロジックを分離することが適切な場合が多いです。更に言うと、Option 1 や 2 が使える状況でも Option 3 が好ましいこともあります。
データとロジックをオブジェクトに統合することは、オブジェクト指向プログラミングの基本概念です。しかし、それを手段でなく目的にしてしまうと、データとロジックの依存関係の分析を放棄することにつながってしまいます。データにしろロジックにしろ、まずは依存の方向を整理してから、次に何の要素をどこに含めるかを考えると、順調に設計ができることがあります。
一言まとめ
ロジックとデータをまとめることを目的化せず、依存の方向を守る。
キーワード: dependency direction, data model, anemic domain model