こんにちは。LINEヤフー株式会社でデータベースエンジニアをしている、松浦、中園、大塚、曽根、笠井です。
データベースはLINEヤフーのさまざま�なサービスを支える重要なソフトウエアですが、その安定的な運用やトラブルシューティングには、データベースに関する専門的な知識が必要です。
一方で、データベース部門に配属される新卒のエンジニアは、全員が学生時代にデータベースを専門的に勉強しているわけではありません。このような新卒エンジニアは、データベース部門へ配属後、OJTや実際のデータベースの運用業務に携わりながら、データベースに関する専門知識を深めていきます。
今回のブログ記事では、データベースエンジニアとしての専門性を高めるために、部門内で実施している専門書の輪読会、そして、MySQLを題材としたデータベースカーネルのモブプログラミング(以下、モブプロ)の取り組みについてご紹介します。
1. 輪読会とモブプロの概要
まずは、輪読会やモブプロを企画・開催するに至った経緯と、実際にそれらをどのように運営しているかをご紹介します。
データベースの運用業務は、非常に多岐に渡り、環境構築や監視、また、クエリチューニングやパラメータチューニングなどが例に挙げられます。
データベース部門に配属となった新卒のエンジニアは、先輩からのサポート、製品マニュアル、市販の書籍を頼りに、OJTという形で、業務を実際に行いながら、環境構築や監視、クエリやパラメータチューニングといった知識とスキルを磨いていきます。
一方で、頻度は少ないですが、データベース製品自身のトラブル発生時には、製品が出力するコアファイル(製品が異常終了した際のプロセスやメモリの状態を記録したファイル)を解析して��、トラブルの原因を推測したり、回避策を調査することもあります。
データベース製品のコアファイルを解析し、その内容を理解するためには、データベース管理者向けに市販されている書籍や製品マニュアルの理解のみでは不十分であり、データベースカーネル内部の理論的な知識も必要です。また、データベースカーネルに関する理論的な知識の獲得だけではなく、理論が、実際のデータベース製品にどのように実装されているか具体的に理解できている必要もあります。データベースカーネルの理論的な知識を体系的に理解でき、そしてコアファイルの迅速な解析が行え、より高いレベルでのデータベース運用業務ができるよう、データベース本部の先輩がメンターとなり、その専門書を新卒や若手エンジニアと輪読する取り組みを始めるに至りました。加えて、理論が製品として実際にどのように実装されているのかも理解するため、MySQLのサーバーレイヤーとInnoDBを題材として、2週間に一度、LINEヤフーのオフィスに集まり、データベース本部の先輩と新卒・若手エンジニアでモブプロを実施しています。
専門書の輪読会は、指定の書籍を題材に、週次で実施しています。輪読会では、毎週、発表担当を決め、その担当が読んできた専門書の内容を付箋ツールに要約しています。そして、それを、Zoomやオフライン開催時にはスクリーン投影で、参加者に説明し、参加者全員で書籍の理解を進めています。
モブプロは、2週間に一度、オフラインで皆が集まり、大きな画面にMySQLのソースコードを投影し、一緒にソースコードを見ながら、実装に対する理解を深めています。
では、次に、�専門書の輪読会とモブプロに参加している若手エンジニアから、輪読会で学習した内容とモブプロの内容の一部をご紹介させていただきます。

2. 輪読会について
LINEヤフーのデータベース本部でMySQLを運用するチームに所属している曽根です。MySQLの知識が何もないままMySQLを運用するチームに配属され、3年目になります。
MySQLとデータベースシステムに関する理解を深めることを目的に、部門内でデータベース理論の専門書を輪読しています。今回は、輪読会の雰囲気をお伝えできるよう、その本から学んだ内容を、抜粋してご紹介いたします。
輪読会では、Seppo Sippu, Eljas Soisalon-Soininen による Transaction Processing: Management of the Logical Database and Its Underlying Physical Structure [1] という書籍を扱っています。この書籍では、MySQLを含めたDiskベースのデータベースシステムがページと呼ばれる単位でI/Oを行うことを前提とし、トランザクション処理の理論や、障害時のリカバリ処理、インデックス操作などのアルゴリズムとその実装が説明されています。
輪読会で学んだ内容
輪読会で学んだ内容のうち、
- Steal, No-forceポリシー
- ARIES(Algorithm for Recovery and Isolation Exploiting Semantics)
について紹介します。
Steal, No-forceポリシー
前提
データベースをHDDやSSDといったストレージに保存するDiskベースのデータベース管理システム(DBMS)では、データレコードへのアクセスや更新を高速化するため、参照や更新対象のレコードを一時的にメモリ(データベースバッファ)にキャッシュし、更新されたレコードは、更新処理が行われたタイミングとは別のタイミングで、データベースバッファからDiskに書き出す、ということを行っています。これは、DiskへのI/O回数を減らす、データベースの性能最適化技法の1つです。データベースバッファ上のページのうち、そのページを最後に更新したトランザクションがアクティブであるものをDirtyページ、そうでないものをCleanページ、と呼びます。
また、データベースバッファは、メモリを使うため、そのサイズには限りがあります。そのため、更新や参照の対象となる全てのページをデータベースバッファに配置しておくことは現実的に不可能です。よって、有限なデータベースバッファをどのようにすれば、効率的に利用でき、また、DBMSの性能も担保できるか、という問題があります。その問題の解決方法を考える上で、Steal/No-steal, Force/No-forceという考え方があり、それを輪読会を通して学習しました。
Steal, No-steal
Stealは、データベースバッファ上のページに対して更新があり、その更新をしたトランザクションがアクティブである場合、そのページ(Dirtyなページ)をDiskにフラッシュしてもよい、とするポリシーです。
Stealポリシーを採用するシステムでは、DirtyなページでもDiskにフラッシュすることが許されます。つまり、アクティブ(未コミット)なトランザクションが書いたレコードがDisk上に永続化される、ということです。
一方、No-stealポリシーはこれ��を許しません。すなわち、No-stealポリシーに従うシステムでは、Disk上に存在するレコードは、それを書いたトランザクションは全てコミット済み、であることが言えます。これにより、障害復旧時にデータベースを一貫性のある状態に戻すための、トランザクションのロールバック処理が軽くできる利点があります。
しかし、No-stealのポリシーでは、トランザクションが更新したデータページが、データベースバッファに収まりきらない場合に、そこからページを退避できないため、その制約を受け、巨大な更新トランザクションの実行が難しい、というデメリットがあります。加えて、自由にDirtyなページをフラッシュすることができないために、それが許されるStealポリシーの場合と比べると、多くのトランザクションから高頻度で参照・更新がされるページは、恒常的にDirtyとなり、Diskへなかなかフラッシュされない、という現象が発生します。その結果、当該ページの古いデータが Disk 上に残ることになる、そして、障害復旧からのリカバリでは、そのページを最新の状態に戻すRedoの処理が多くなる、というデメリットもあります。
このようなNo-stealポリシーのデメリットから、MySQLを含む主要なDiskベースのDBMSは、Stealポリシーを広く採用していることを、輪読会で学びました。
Force, No-force
次にForce、No-forceについて説明をします。これはトランザクションがコミットする時に、そのトランザクションが更新した全てのページをDisk上にフラッシュするか否かに関するポリシーです。トランザクションがコミットする時に、そのトランザクションが更新した全てのページをDisk上にフラッシュするポリシーをForceと呼びます。反対に、このような制限がなく、トランザクションのコミットと同時にページをDiskへフラッシュしなくてもよいポリシーをNo-forceと呼びます。
Forceポリシーでは、障害復旧時のリカバリでのRedo処理が少なくなります。しかし、トランザクションがコミットされるたびに、そのトランザクションの更新をDiskにフラッシュすることが強制されるので、コミットのパフォーマンスが落ちる、というデメリットがあります。その上、複数のトランザクションが同じページを頻繁に更新する場合を想定すると、No-forceポリシーであれば、そのページのフラッシュ回数を減らせるところを、Forceポリシーでは、トランザクションのコミットの都度、そのページをフラッシュする必要がある、という無駄が生じます。
No-stealとForceのポリシーは、データベースの障害復旧時のリカバリを減らすことができる利点があります。一方で、StealとNo-forceのポリシーでは、トランザクションコミットのパフォーマンス、また、データベースバッファの利用効率がよい代わりに、リカバリが増えると考えられていました。
しかし、ARIES [2] というリカバリアルゴリズムが登場し、それ以前のリカバリアルゴリズムの問題点を指摘・改善するとともに、リカバリがStealやForceのポリシーとも関係なく動作することを示しました。ARIESの登場によって、No-stealとForceポリシーによるリカバリの処理量減少というメリットは薄れ、現代の多くのDBMSではStealとNo-forceのポリシーを採用しています。
ARIES
次にARIESについて説明をします。
ARIESは、Algorithm for Recovery and Isolation Exploiting Semanticsの略で、Do-Redo-Undo方式のリカバリアルゴリズムです。
Do-Redo-Undoとは、まず、Disk上から欠けている全ての更新を適用し(Redo)、その後コミットされなかったトランザクションによる更新を取り消していく(Undo)、というリカバリアルゴリズムです。
ARIESについて、その前提知識となる、LSNとWALの説明も交えて、もう少し詳しく説明します。
LSN, WAL
まずは、LSN(Log Sequence Number)についてです。データベースの更新は全てログに記録されますが、このログのレコードには単調増加の一意の番号がついています。これを、LSN(Log Sequence Number)、と呼びます。データベースのレコードを格納するページには、そのページを最後に更新したトランザクションが書いたログのLSNが記載されており、それは、ページの状態を知るのに役立てられます。これを、Page-LSNと呼びます。
次にWAL(Write-ahead Logging)についてです。WALは、データベースのI/O処理の最適化、また、トランザクションのアトミック性、および、永続性保証の一役を担っているアルゴリズムです。WALでは、データベースバッファ上のページ をフラッシュする前に、そのページ に含まれる 、Page-LSN以下のログレコードをDisk上にフラッシュしなければならない、というルールです。ログは常にログファイルの末尾に追記することになるため(シーケンシャルアクセス)、データベースファイル上の保存位置が不規則になるデータベースのページ(ランダムアクセス)よりも、効率よくDisk I/O が行え、トランザクションのアトミック性、および、永続性保証が可能です。
WALでは、システムがクラッシュした際に、あるログレコードが残っていれば、それより小さいLSNのログレコードも全てDisk上に残っていることが保証されます。これにより、DBMS がクラッシュした際は、ログのデータを正として、データベースのリカバリを行うことができます。
ARIESの前提となる、LSN、WALの説明を簡単にいたしました。
ARIESは、リカバリのアルゴリズムですが、ARIES以前には、Do-Undo-Redoの考え方に基づき、データベースのリカバリは実行されていました。ARIESの有用性が紹介できるよう、ARIES以前のリカバリアルゴリズムであるDo-Undo-Redoの問題点について説明します。
Do-Undo-Redoリカバリの問題
Do-Undo-Redoの第1の問題点は、必要なUndoを全て実行した後のRedoが同じページに対してできない可能性があるということです。これは、アクティブなトランザクションのみをUndoしていることが原因で、ページの状態が当時と異なる可能性があるためです。また別の問題点として、Redoが同じページにできない可能性があるということは、このRedoに対するUndoのためのログが必要になります。それによりPage-LSNが進み、Page-LSNを見るだけでは、そのページにどこまでの更新が入っているかわからなくなってしまいます。
ARIES では以下のような性質が成り立ち、前述の問題点を克服しています。
- 各ページ について Page-LSN () 以下の LSN をもつ更新は全て に含まれ、 Page-LSN ()より大きい LSN をもつ更新は全て に含まれていない
- Redoは全て同じページの同じ位置に対して実行できる
- Redoで追加のログレコードが必要ない
- Undoは常に実行可能である
ARIESの構成ステップ
ARIESは、Do-Redo-Undoの考え方に基づくリカバリですが、次の3つのステップから構成され、記載の順番でリカバリが実行されます。
- Analysis Pass
- Redo Pass
- Undo Pass
これら3つのステップの動作の概要を、以下の図に示す状態を例に、説明をします。
以下の例では、障�害発生前の直近で、データベースバッファ上のページとDisk上のページが同期するチェックポイント(Last Checkpoint)から障害発生時にかけて、3つトランザクション , , が実行されています。そして、 と は障害発生時には、コミット済みであり、 は未コミットです。

このような状況から、ARIESの各ステップでは次のような処理が実行され、データベースの状態が障害発生直前のものにリカバリされます。
Analysis Pass
Analysis Passでは、まずは、Disk上のログレコードを走査し、��障害発生直前のチェックポイント(Last Checkpoint)を特定します。また、チェックポイントでは、チェックポイントのログレコードと、データベース内でアクティブなトランザクション情報を管理する「Active Transaction Table」と、Diskにフラッシュしていないページ情報を管理する「Modified Page Table」の内容が合わせて書き出されます。Analysis Passでは、Last Checkpoint時に書き出されたこれらの情報を元に、Active Transaction TableとModified Page Tableを初期化します。
今回の例では、障害が発生した際にDiskにフラッシュされていたログはLSNが15までとしています。LSN=5,6,7のログからなるLast CheckpointのログからActive Transaction TableとModified Page Tableを復元し、15までのログを時系列順に走査して図のようなActive Transaction TableとModified Page Tableを出力します。すなわち、Analysis Passでは、Last Checkpoint以降に開始されたトランザクションがあり、それが、Active Transaction Tableに登録されていなければ、それを追加していきます。ログの走査を進めていき、そのトランザクションがコミット済みであれば、Active Transaction Tableから削除する、という処理をログの終端まで行います。(今回の例では、トランザクション と はコミット済みのため、Active Transaction Tableから削除)
また、Last Checkpoint以降のログを確認していき、あるページ に対する更新のログレコードが見つかり、 がModified Page Tableに含まれていなければModified Page Tableに を追加し、そのLSNを と一緒に登録します。このLSNのことをRec-LSNと言います。(厳密には、ページ に対する更新のLSNでチェックポイント以降の最も若いLSNをRec-LSNと言います)
Modified Page Tableの作成処理を終えると、Analysis Passの最後で、そこに登録されているRec-LSNの最小値をとります。この最小値のことをRedo LSNと呼び、これが、Analysis Pass以降で実行されるRedoステップの基準点となります。

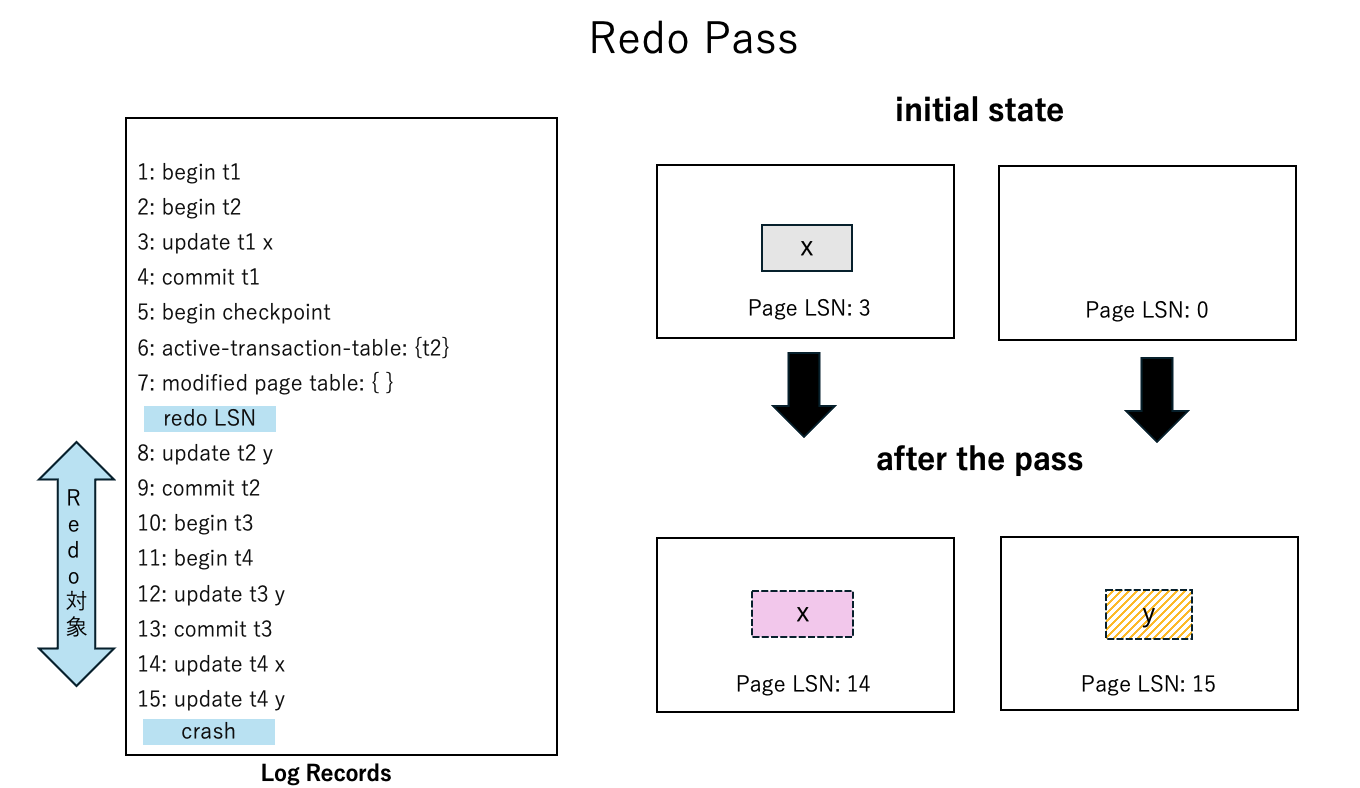
Redo Pass
Redo Passは、Redo LSNのLSNをもつログレコードからその処理が始まります。Redo LSN、もしくは、それ以降のログレコードをスキャンし、ページ に対する LSN= のログレコードが見つかれば、Disk上のページ の中に書かれているLSN (Page-LSN)と を比較し、 > Page-LSN であれば(すなわち LSN = の更新がページ に反映されていない)、その更新を適用し、そうでなければ適用しない、ということを順に行い、Redo処理を行います。Redo中のDiskに対する更新は、障害発生直前にメモリ上で適用された更新と全く同じページの同じ位置に行うことができるため、Do-Undo-Redoのリカバリアルゴリズムで起こる前述の第1の問題は発生しません。
今回の例では、Analysis Passで求めたRedo LSN(=8)から始め、ログを時系列順にたどりながら順に更新することで、Disk上に書かれていた各ページは、LSNが15までのログを全て適用した状態になります。
Undo Pass
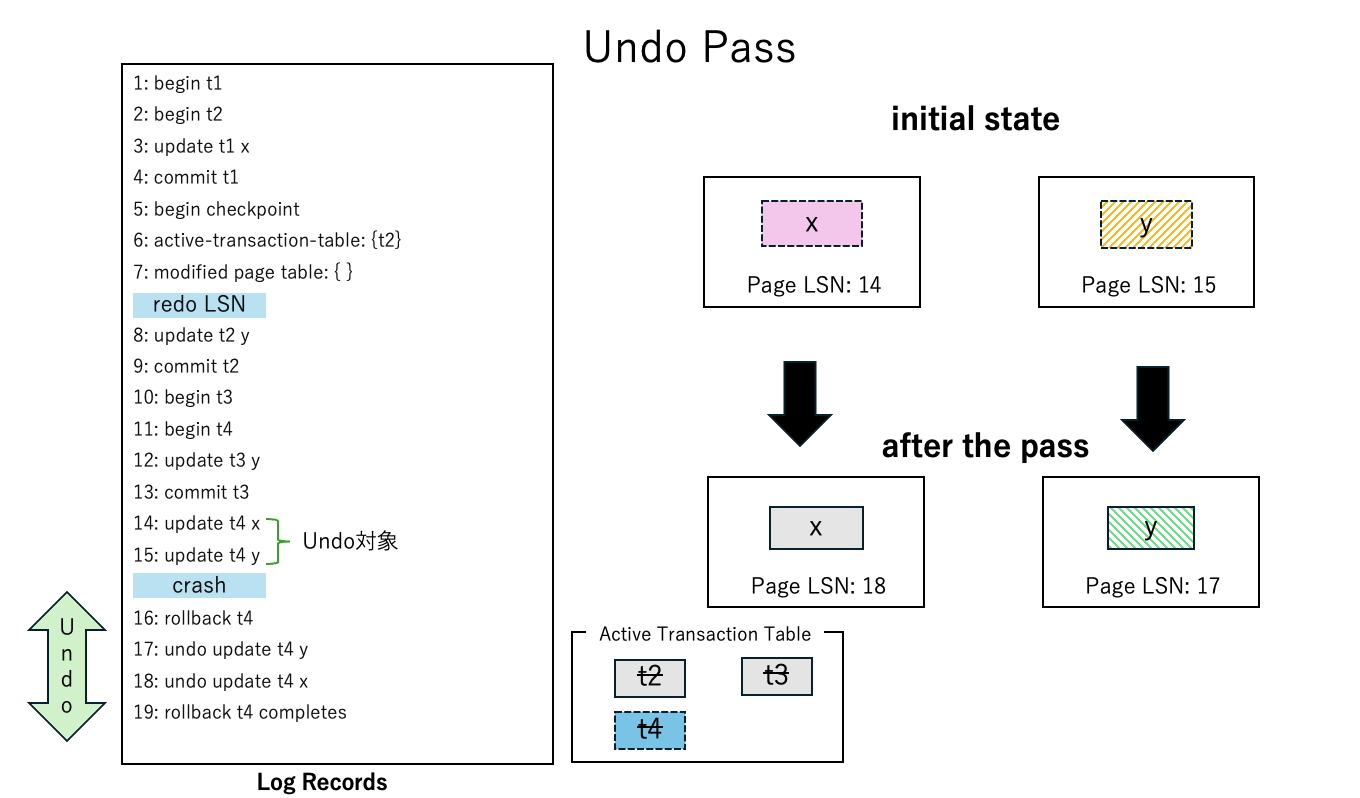
Undo Passでは、Analysis Passで作成したActive Transaction Tableを参照し、障害時にアクティブであったトランザクションのロールバック処理を行います。
今回の例を考えると、トランザクション が障害時にはアクティブのままです。その取り消しを行うため、Undo Passでは、まず、当該トランザクションのロールバックを開始するログレコードをLSN=16として書き出します。そして、そのトランザクションに含まれる更新操作(LSN=14,15)の取り消しをページ と に対して実施し、その取り消し操作もログレコードLSN=17,18として書き出します。そして、トランザクション のロールバック処理が完了したログレコード(LSN=19)を書き出し、Undo Passを終了します。
Undo Passの後は、下図のafter the passに示す状態となり、障害発生直前のデータベースの状態にリカバリができています。
Analysis PassでActive Transaction TableやModified Page Tableの作成とRedo LSN の設定、そして、Redo PassでトランザクションのRedo処理、Undo Passでアクティブトランザクションの取り消しをすることで、障害発生直前の状態にデータベースをリカバリできます。
以上が、輪読会を通して学んだ、Steal, No-forceポリシーや、ARIESについてのご紹介でした。
3. モブプロについて
はじめまして、LINEヤフーのデータベース本部の笠井です。昨年よりデータベース本部に配属され、現在はMySQLを運用するチームで業務をしています。
普段の運用業務に加えて、MySQLのソースコードを題材にしたモブプロにも参加しています。こちらのモブプロを行っているチームでは、MySQLのデータベースカーネル内部に手を加えて設計・開発を行っています。
今回のブログでは、輪読会のご紹介と合わせて、モブプロの様子もお伝えできればと思います。
モブプロ参加のモチベーション
モブプロとは3人以上で1つのプログラムを書く取り組みのことです(2人でやる場合はペアプロと呼ばれます)。モブプロでは、1人がコーディングを行い、その他の人はコーディングの様子を見て、議論したり指示を出したりする形式でプログラムを書いていきます。モブプロでは他のメンバーの作業の様子を直接見ることができるので、作業環境やプログラミングに関する知識を吸収できます。
私は入社して以来ずっとリモート&テキストベースで業務を行ってきたため、コミュニケーション不足になりがちでした。他の人の作業の様子を見る機会もほとんどないため、同じチームで業務をしていても他のメンバーの技術や知識を学ぶ機会は多くありませんでした。モブプロは他の人の技術と知識を学ぶチャンスだと思って参加しています。
どんなふうにやっているか?
モブプロの日はオフィスに出社をして、全員で巨大ディスプレーを見ながらプログラミングをしています。Zoomを利用してリモートでも可能ですが、やはりリアルタイムコミュニケーションは物理画面を共有して、対面で会話したほうが捗ります。

コーディングを行う人を毎回入れ替えながら、1時間の作業時間でプログラミングをしていきます。会話しながらの1時間なので大規模な変更を加えるのは難しいです。モブプロは知見と技術の共有を目的にしているため、比較的簡単なタスクをモブプロの題材としています。
実際に書いたプログラムは?
実際にモブプロの題材として書いたプログラムを1つご紹介します。
独自グローバル変数に対して巨大な数値を設定した際のバグ修正
モブプロを実施しているチームではMySQLのソースコードを独自に改変して機能追加を行っています。そして、追加機能の挙動を調整できるよう、独自にMySQLのグローバル変数(仮称 org_size_of_buffering)を追加していました。しかし、この変数に対して、上限値を超過する値を設定すると、その挙動が仕様を満たさない、というバグがありました。
SET GLOBAL org_size_of_buffering=4294967300;モブプロの題材として、このバグ修正に取り組みました。
MySQLでは、グローバル変数は sql/sys_vars.cc で、たとえば、以下のように定義されています。
static Sys_var_ulong Sys_org_size_of_buffering(
"org_size_of_buffering", "buffer size",
HINT_UPDATEABLE GLOBAL_VAR(org_size_of_buffering),
CMD_LINE(REQUIRED_ARG), VALID_RANGE(1, UINT_MAX32), DEFAULT(1024),
BLOCK_SIZE(1), NO_MUTEX_GUARD, NOT_IN_BINLOG, ON_CHECK(nullptr),
ON_UPDATE(Org::Org_Repl_sys::on_update_size_of_buffering));上記では、VALID_RANGE(1, UINT_MAX32) によって、独自のグローバル変数 org_size_of_buffering の最大値はUINT_MAX32と定義されています。最大値を超過する値を指定した場合、エラーメッセージを出力し、変数値変更の操作をエラーとする仕様でした。しかし、最大値を超過する値を設定した際の実際の挙動は、警告が出力され、最大値にTruncateされる、というものでした。デバッガであるgdbを利用して、こちらの挙動を解析することも、モブプログラミングで実施しました。独自グローバル変数の仕様は、最大値を超過する値を設定した場合、指定されたエラーメッセージを出すというものですので、そのエラーメッセージ出力と上限値CheckのValidation処理を行う独自メソッド(Org::Org_sys::on_check_size_of_buffering)を、モブプログラミングで実装しました。そして、以下のようにそのValidation処理のメソッドをグローバル変数定義のマクロ中のON_CHECK()に指定することで、独自のエラーメッセージ出力処理と上限値のValidation処理を実行し、仕様を実現できました。
static Sys_var_ulong Sys_org_size_of_buffering(
"org_size_of_buffering", "buffer size",
HINT_UPDATEABLE GLOBAL_VAR(org_size_of_buffering),
CMD_LINE(REQUIRED_ARG), VALID_RANGE(1, UINT_MAX32), DEFAULT(1024),
BLOCK_SIZE(1), NO_MUTEX_GUARD, NOT_IN_BINLOG, ON_CHECK(Org::Org_sys::on_check_size_of_buffering),
ON_UPDATE(Org::Org_Repl_sys::on_update_size_of_buffering));このようなバグ修正や仕様を満たす実装を通して、他メンバーの作業環境や、デバッガの利用方法、MySQLのソースコードに対する知見などを共有できました。
モブプロで得た知見・成果
モブプロに参加することによって得られた知見や成果をご紹介します。
- コア開発メンバーの暗黙知の吸収とフィードバック
- 生産性向上のためのTips
コア開発メンバーの暗黙知の吸収とフィードバック
モブプロに参加することによって得られたものとしてコア開発者の暗黙知があります。
こちらのモブプログラミングを行っているチームは、普段私が所属している運用チームとは異なり、MySQLのデータベースカーネル内部に手を加えて設計・開発を行うチームです。このチームのメンバーの間では暗黙のうちに常識になっている知見があります。たとえばMySQLのソースコード構成についての理解があります。膨大なファイル群の中から適切な修正対象のファイルを見つけるのは難しいですが、モブプロに参加することによってコア開発メンバーの方から「ディレクトリ構成の意味」や「よく修正するファイル・ディレクトリ」といった知識を吸収できました。
加えてコア開発者の間では、開発環境の構築方法も暗黙知として扱われていました。しかし、モブプロで新たに開発に加わった私はその暗黙知を知らず、コア開発者が想定していなかった手順で開発環境を構築してしまいました。その結果、開発環境がうまく動作しないという事態に遭遇しました。このことを通して、開発環境がうまく動かない原因がすぐにわかるように「〇〇の場合にはエラーメッセージを出したほうがよい」という改善案がモブプロメンバー内で生まれました。
生産性向上のためのTips
ソフトウエア開発での生産性を高めるため、私を含めたモブプロメンバーは、各々、統合開発環境をカスタマイズしたり、さまざまな便利なプラグインを利用したりしています。ここでは具体的な製品名を出すことはしませんが、私が使ったことのない統合開発環境やプラグインを他の方が使っていて、それらの機能について学習ができたり、また、便利なキーバインドについてお互いに知識交換することもできました。また、ソフトウエアのBuild時間を短縮するため、ハイスペックなマシン上で96並列の力業でBuildしているメンバーもいました。
モブプロの成果まとめ
モブプロに参加したことにより、上記のような知見を得ることができました。リモートワークとテキストチャットがメインの場合、どうしてもコミュニケーション不足になりがちです。業務上必要なことであっても、「質問する文章を書くの面倒だからちょっと先に調べてみるか...」などとなりがちです。業務上必要ではない作業環境や細かなTips等に至っては共有する機会がほとんどなくなってしまいます。そういった場合にモブプロに参加することにより、細かい知見まで自然に共有できました。
たとえ新しい知見がないような場合であってもモブプロに参加するメリットはあります。それは自分の作業環境や知識セットが他のメンバーとそろっていることを確認できる点です。新規メンバーが既存メンバーと同じ作業環境を利用できているのであれば効率的な作業環境であることを再確認できますし、知識セットがそろっていてツーカーで会話できるのであれば開発を進める上での認識に大きなズレがないことを確認できます。
またここまではメリットを強調してきましたが、他のメンバーと一緒に会話しながらプログラミングができるのはシンプルに楽しいです!
モブプロはどちらかと言えば新規メンバーにとって参加するメリットが大きいものです。
新規メンバーとなった方は機会があれば積極的に参加していきましょう!
既存メンバーの方も余力があればモブプロの導入を検討してみてください。
4. メンターとして感じたこと
LINEヤフーのデータベース部門に所属している大塚です。本記事で曽根さん、笠井さんに紹介いただいたモブプログラミング、輪読会に微力ながらメンターとして参加させていただきました。
特にモブプログラミングにおいては、チーム内の暗黙知、開発・動作検証におけるTips、そして開発環境やツールの使い方を含めたデバッグの進め方を実践的に共有できたと思います。個々の項目については、笠井さんが本記事中で紹介してくれています。
私は今回のモブプログラミングの取り組みを経て、細かい要素技術や作業環境ごとのTipsの共有だけでなく、データベース開発における勘所を共有できることが最も重要な点だと感じました。これはデータベースに限ったことではありませんが、長年の開発で機能が増え、抽象化のためにレイヤやコンポーネントが逐次的に追加されたソフトウエアはそれなりに複雑です。膨大なソースコードと機能ごとに抽象化されたドキュメントがあったとしても、いざ、バグの状況やスタックトレースを頼りにソースコードを見ても、どこから手をつけたらよいか、どのレイヤで修正するのが適切か、判断が難しいことがよくあります。
これまで実践したモブプログラミングでは、バグ修正を題材として、要因の特定、解決策の模索、プロトタイプによる検証、既存機能との整合性の確認、修正方法の相談、PR作成といった流れを通して、どの粒度で問題を切り分け、どのように検証してチーム内でコンセンサスをとっているのかを直接に見せることができました。ここで体感した手法は1つの例に過ぎませんが、ドキュメントや手順書で伝えられるものではないので、今後の取り組みの参考になることを期待しています。
偉そうに書きましたが、正直、これらを含め私が教わったことのほうが多かったかもしれません。各自の対応方法が非常に参考になったことはもちろん、リアルタイムにコメントをもらえることで、経験則で間違った仮定を前提に作業を進めていたり、曖昧な理解のまま解決策を検討していたりすることに気づくことができました。今後もチームの力を借りながらよりよいプロダクトを開発し、ユーザーにさらなる価値を提供できるように取り組んでいきたいと思います。
LINEヤフーのデータベース部門に所属し、今回のモブプログラミング、輪読会にメンターとして参加した中園です。データベースの開発には理論と実装の両面の理解が求められます。コードを読む時は、ただ1つの何気ないmutexに対しても「これはロックなのかラッチなのか」などといったことを考える必要がありますし、コードを書く際には実装の裏にあるプロトコルやアルゴリズムを明示的に読者に伝えていかないといけません。理論と実践、演繹と帰納でコンテクストスイッチが大量に発生して、専門用語も多いので、経験のないメンバーには心理的なハードルも高い分野です。その心理的ハードルを取り除くには,モブプログラミングと輪読をセットで行うのは非常に有用です。
私自身も、データベース分野未経験の新卒として社会人になり、メンターにモブプログラミングと輪読を通じて指導・育成していただいたことが今の自分に強く影響しています。社会人になってから毎�年かかさず、いろんな人とこれを行ってきましたが、常に成長を実感できるよい取り組みだと感じています。引き続き、この取り組みを通じて自分とチームの能力を底上げして、よりよいサービスを社会に高速に提供できるよう取り組んでいきたいと思います。
輪読会・モブプロ参加メンバーで記念に集合写真(左から:松浦、インターン生 山口さん、笠井、大塚、中園、曽根)

5. 参考文献
[1]: Seppo Sippu, Eljas Soisalon-Soininen:Transaction Processing - Management of the Logical Database and its Underlying Physical Structure. Data-Centric Systems and Applications, Springer 2014, ISBN 978-3-319-12291-5, pp. 1-369
[2]: C. Mohan, Don Haderle, Bruce G. Lindsay, Hamid Pirahesh, Peter M. Schwarz:ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging. ACM Trans. Database Syst. 17(1): 94-162 (1992)


