こんにちは、音声認識技術の研究開発を担当している篠原です。
この記事では、音声認識モデルのドメイン適応のために最適なデータセットを抽出する技術について紹介し�ます。汎用データセットから目的ドメインのデータセットを擬似的に生成できるため、特定用途向けのカスタムモデルの構築(ドメイン適応)を低コストで実現できます。
なお本技術は、米国カーネギーメロン大学の渡部晋治准教授との共同研究を通して考案したものです。詳細については、国際会議 ASRU 2023(IEEE Automatic Speech Recognition and Understanding Workshop 2023)で発表していますので、興味がある方はぜひ論文 [1] もご覧ください。
はじめに
音声認識とは?
音声認識は入力された音声をテキストに変換する技術です。たとえば、スマートフォンでの音声によるウェブ検索などで使われています。ソフトウェアキーボードと比べて検索したい単語を素早く入力できるため、使ったことがある方も多いのではないでしょうか。他にも、動画共有サービスでの自動字幕付与、ミーティングの議事録作成、コンタクトセンターの自動化、音声で操作できるスマートデバイス、自動音声翻訳、音声対話アシスタントなど、さまざまな場面での応用が進んでいます。
近年、音声認識はニューラルネットを用いた「End-to-End 音声認識」と呼ばれる方式が主流になりつつあります。具体的には、入力系列を出力系列に変換するニューラルネット(たとえば Transformer)を用いて、音声系列を文字列に変換することで音声認識を行います。音声とテキスト(音声の内容を文字列として書き起こしたもの)のペアを大量に収集したデータセットで学習することで、音声を聞き取ってテキストに変換するニューラルネットを構築できま��す。
ドメイン適応とは?
音声認識モデルを特定のサービス向けに導入する場合には、汎用モデルをカスタマイズしたサービス特化モデルを構築することで、より高い認識精度が得られます。たとえば金融分野、医療分野、テクノロジー分野などに特化したモデルが考えられます。このような分野のことを「ドメイン」、汎用モデルを特定ドメイン向けにカスタマイズすることを「ドメイン適応」と呼びます。
従来のドメイン適応法
ドメイン適応の標準的な方法では、目的のドメインに特化したデータセットを構築して、このデータセットを用いてニューラルネットのパラメータを微調整(fine-tuning)します。
しかし目的のドメインに特化したデータセットの構築には多大なコストが掛かります。たとえば、スポーツ中継の音声認識に特化したモデルを構築する場合、さまざまなスポーツ中継の音声を収録し、その音声を人手で文字起こしすることで、そのドメインの音声とテキストのペアを収集します。数時間から多い場合は数百時間の音声とそのテキストが必要なため、多大な作業コストが発生します。
コストを抑えるため、テキストのみを用いたドメイン適応の方法も盛んに研究されています。音声とテキストのペアを収集する場合と比べて、テキストのみなら低コストで収集できるためです。とくに目的ドメインのテキストで構築した言語モデルを音声認識モデルに統合する方法が良く使われます(代表例:Shallow Fusion)。しかし言語モデルを統合すると推論演算量やストレージ使用量が増大するため、実用化は容易ではありません。
そこで、データセット構築のコストが掛からず、かつ推論演算量やストレージ容量も増大しない、新しいドメイン適応の方法を検討することにしました。
提案法:データセットの抽出によるドメイン適応法
私たちは、既存の汎用データセットから目的のドメインに合致したデータセットを抽出できれば、新たにデータセットを構築するコストが掛からず、低コストにドメイン適応を行えるのではと考えました。では、どのようにデータセットを抽出すれば良いのでしょう。
私たちの論文(“Domain Adaptation by Data Distribution Matching via Submodularity for Speech Recognition”)[1] では、目的ドメインのデータ分布と合致するようにデータセットを抽出することで、目的のドメインに特化したデータセットを擬似的に構築する方法を考案しました。また、「劣モジュラ最適化」と呼ばれるアルゴリズムを用いることで、このデータセット抽出処理を効率的に実行できることを示しました。
以下では、私たちが考案したデータセット抽出によるドメイン適応法について、詳しく説明します。
方法
私たちの論文で提案した、データセットの抽出によるドメイン適応法について説明します。
まず、提案するドメイン適応法のプロセス全体像を説明します。次に、どのような基準でデータセットを抽出するのか、またどのようなアルゴリズムで効率的にデータセットを抽出するのかについて、順に説明します。
ドメイン適応のプロセ�ス全体像
データセット抽出によるドメイン適応法のプロセス全体像を下図に示します。このプロセスは、ベースとなる汎用モデルおよび目的ドメインのテキストを入力として、目的のドメインに特化したモデルを出力します。
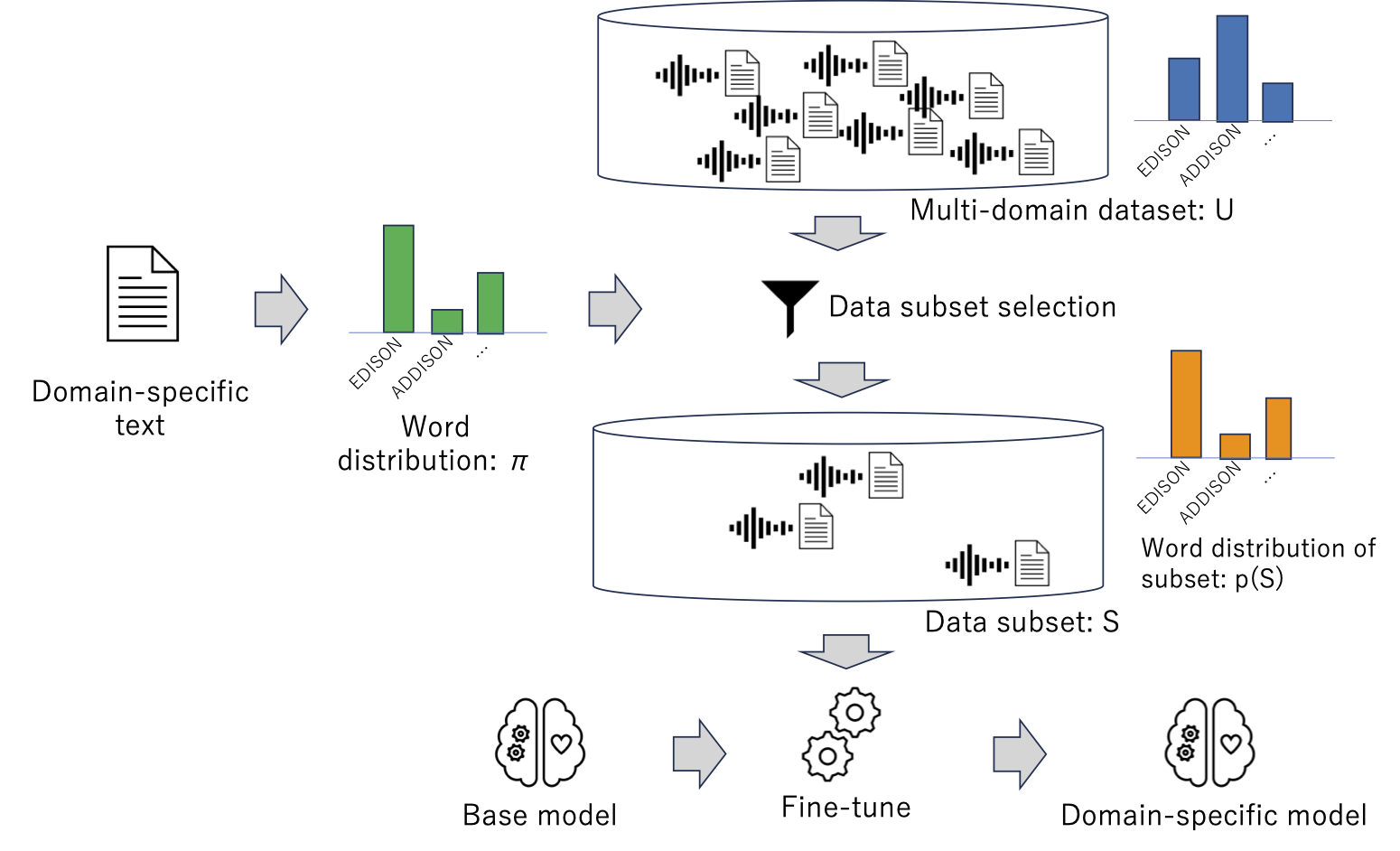 図 1. 目的ドメインのデータ分布に合致したデータセットの抽出によるドメイン適応のプロセス
図 1. 目的ドメインのデータ分布に合致したデータセットの抽出によるドメイン適応のプロセス
なお、このプロセスにおいて、既存の汎用データセット(音声とその書き起こしテキストのペアの集合)が利用できるものとします。目的ドメインに合致したデータが含まれる可能性を高めるため、この汎用データセットはさまざまなドメインを広くカバーしていることが望ましいです。
まず、与えられた目的ドメインのテキストから、目的ドメインにおけるデータ分布(具体的には単語分布)を推定します。次に、このデータ分布と合致するように、既存の汎用データセットからサブセットを抽出します。具体的には、目的ドメインのデータ分布との距離(Kullback-Leibler ダイバージェンス)を最小化するように、劣モジュラ最適化を用いてサブセットを選択します。このようにして抽出したデータセットは、目的のドメインに合致した特性を持つと期待されます。最後に、抽出したデータセットを用いて汎用モデルを微調整(fine-tuning)して、ドメイン特化モデルを構築します。
以下では、このドメイン適応プロセスの詳細について説明します。
どのような基準でデータセットを抽出するのか?
ドメイン適応に「最適」なデータセットを抽出するためには、どのような基準を用いれば良いでしょうか?私たちは、目的ドメインのデータ分布(=単語分布)と合致するデータセットが最適であると考えました。
この基準を用いることにした背景について簡単に説明します。近年主流になっている End-to-End 方式の音声認識(音声系列を文字列に変換するニューラルネット)では、学習に用いたデータセットにおける出現頻度が高い単語ほど、テスト時に認識精度が高くなる性質があります。この性質を考慮すると、目的のドメインで頻出する単語ほど学習データセットでの出現頻度を高めることで、目的ドメインでの音声認識精度を全体的に底上げできると考えました。そこで、目的ドメインにおける単語分布と合致するようデータセットを抽出することにしました。
この基準によるデータセット抽出の問題は、以下のように定式化できます。
まず以下の記法を用いることにします。
- : 既存の汎用データセット。 個の文から構成される。各文は音声と(その内容を書き起こした)テキストのペアであり、テキストは単語の系列である。各文たとえば 5〜20単語くらいの長さ。
- : 抽出されたデータセット。すなわち を構成する 文から 文を選択したサブセット。
- : 目的ドメインのテキストにおける単語分布。すなわち、各単語 の相対頻度 の配列 ( は語彙数)
- : 抽出されたデータセット における単語分布。すなわち、各単語 の相対頻度 の配列
- : 各文 のコスト。今回は文 の長さ(単語数)をコスト とした。
- : データセット のサイズの上限。 が所定の単語数になるように制御する。
- : 2つの単語分布の間の距離(Kullback-Leibler ダイバージェンス)
この記法のもとで、最適なデータセット を抽出する問題は、次式によって定義されます。
- (1)
この式 (1) を言葉で説明すると、
- データセット の単語分布 が、目的ドメインの単語分布 と合致(距離が最小化)するように、 の最適なサブセット を抽出せよ。ただし、 のサイズ(総単語数) は所定の値 を上限とする。
となります。
では、式 (1) で定義される最小化問題を解くためには、どのようなアルゴリズムを使えば良いでしょうか?次の節では、この問題を効率的に解くアルゴリズムについて紹介します。
どのようなアルゴリズムで効率的にデータセットを抽出するか?
本節では、与えられたデータセットから、所望のデータ分布を持つサブセットを抽出する方法を紹介します。
なおこの方法は、私が 2014 年の論文 [2] で考案したものです。今回のドメイン適応の論文 [1] では少しだけ方法を拡張していますが、以下で紹介する基本的な考え方は変わっていません。
まず問題設定についてイメージを持っていただくために、簡単な練習問題を考えてみます。
- [問題]下図のように 6 個のバッグがあり、各バッグには色付きのボールが 1 個以上入っているとします。また、各ボールの色は赤・緑・青のいずれかだとします。いま、ボールの数が 赤30%、緑50%、青20% の比率になるように、2 個のバッグを選択したいとします。どの 2 個を選ぶのが良いでしょうか?
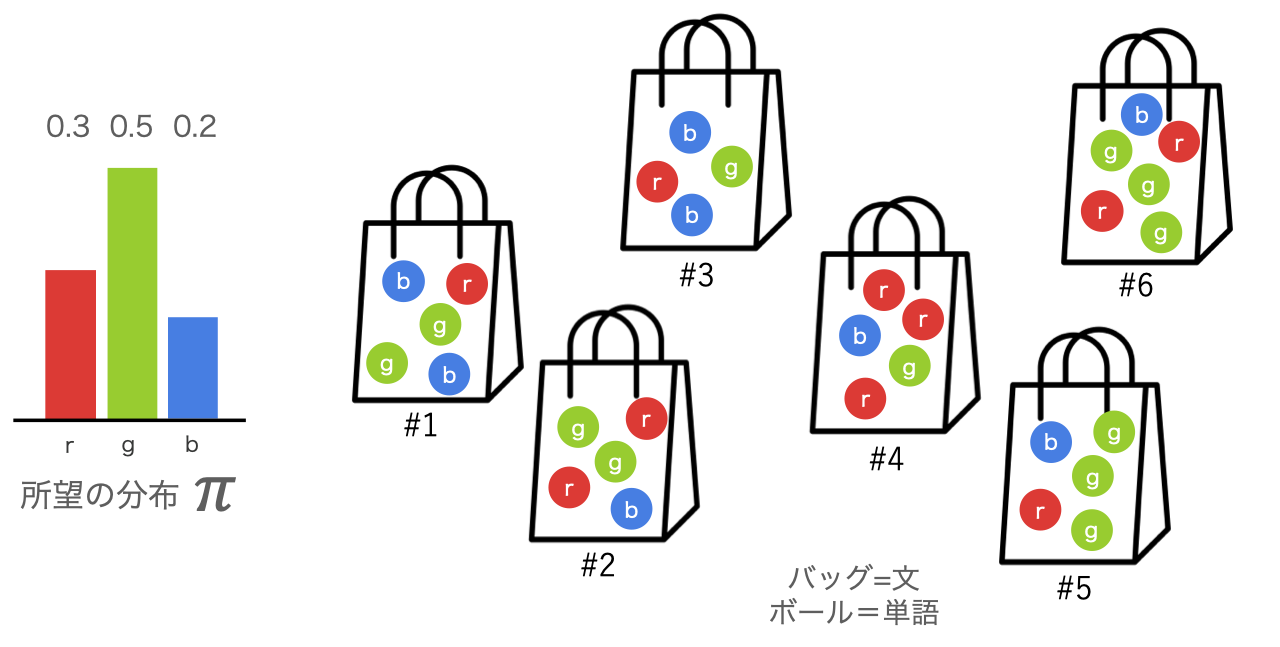 図 2. 6個のバッグから2個を選んで所望の色分布にするには?
図 2. 6個のバッグから2個を選んで所望の色分布にするには?
- [答え]6 個のバッグから 2 個を選択する組み合わせは 通りあります。この 15 通りの組み合わせの各々について、赤・緑・青のボールの数を数えて所望の分布(赤30%、青50%、緑20%)との距離を計算します。すべての組み合わせのうち、この距離が最小になる組み合わせが答えです。(#2 と #5 のバッグを選ぶと、赤3個、緑5個、青2個にできます)
しかし、この総当たりで厳密解を探す方法では、問題が大規模(たとえば 100 万個のバッグから 5 万個を選択)になると、組み合わせの数が膨大になり太刀打ちできません。そこで何らかの効率的なアルゴリズムで近似解を求める方法が必要になります。
ここで、バッグを文、ボールを単語と読み替えると、ちょうどわれわれの問題(式 (1))と同じ問題であることが分かります。つまり、たくさんの文があって、各文は 1 個または複数の単語から構成されるとき、所望の単語分布になるように所定の量の文を選択するには、どうすれば良いか? という問題です。したがって、所望の色分布を持つバッグの組み合わせを選択する問題が解ければ、所望の単語分布を持つデータセット(文の集合)を選択する問題も解けることになります。
私の 2014 年の論文 [2] では、劣モジュラ最適化を使うことによって、この問題の近似解を効率的に求められることを示しました。具体的には、われわれの目的関数(所望のデータ分布とのカルバック・ライブラー・ダイバージェンス)を、劣モジュラ性を持つ別の関数で近似することを提案しました。劣モジュラ性を持つ関数の最適化に対しては強力なアルゴリズム(劣モジュラ最適化)が知られており、このアルゴリズムを用いることで効率的に近似解を�求められます。
ちなみに、[2] のアルゴリズムは、機械学習においてデータセットのバランスを整えるさまざまな問題に対して適用されています。たとえば、推薦システムにおいて推薦のバランスを整える問題 [3] や、大規模な半教師付き学習でラベルのバランスを整える問題 [4] などに適用されています。ご興味がある方は、[2] のほか、AAAI 2015 のチュートリアル [5] や、推薦システムの論文 [3] でも分かりやすく紹介されてるので、ぜひご覧ください。
実験
英語音声認識のデータセット「LibriSpeech」を用いて、提案するドメイン適応法の有効性を検証しました。
「LibriSpeech」は、小説などの本をナレータが読み上げたオーディオブックのコレクションです。本は 1 冊ごとに扱っているトピック(ドメイン)が異なるため、各オーディオブックを 1 つのドメインとみなし、ドメイン適応の実験を行いました。
ドメイン適応の実験手順は次のとおりです。各オーディオブック(たとえばエジソンの伝記 “Edison, His Life and Inventions”)について、その本の 1 つの章を評価用、残りの全章を適応用とし、適応用の章のテキスト全文を用いて音声認識モデルをドメイン適応します。このドメイン適応したモデル(たとえばエジソンの伝記に特化したモデル)を用いて、評価用の章の音声をどれだけ正確に文字起こしできるかを評価しました。たとえばエジソンの伝記であれば、「エジソン」、「電気」、「発明」といった、この本(ドメイン)で頻出する、つまり重要な単語の認識精度が改善すると期待されます。
実験では以下の 3 つのモデルの音声認識精度を比較しました。
- ベースモデル:LibriSpeech の学習セット全体(約960時間)を用いて学習した汎用モデル
- 適応モデル(Shallow Fusion):適応用テキストを用いて構築した言語モデルを統合(Shallow Fusion)したモデル
- 適応モデル(提案法):適応用テキストを用いて抽出したデータセットで微調整(fine-tuning)したモデル
なお、抽出元となるデータセット には、LibriSpeech の学習セット(約960時間)を用いました。ベースモデルの学習データと同一ですが、別個のデータセットでも問題ありません。
4つの評価セット(dev-clean, dev-other, test-clean, test-other)について、それぞれ 10 冊(合計 40 冊)のオーディオブックを実験に用いました。各オーディオブックについて前述の手順で適応・評価を行い、10 冊平均の単語誤り率を求めました。
下表に実験結果を示します。従来法(Shallow Fusion)による適応モデルは、4つの評価セットのすべてでベースモデルを上回る認識精度を達成しました。しかし、言語モデル(パラメータ数 87.6M)を統合したため、モデルのパラメータ数が 176.3M まで増大します。このためストレージ使用量の増加が(とくにスマートフォンで)課題となります。また、ここには数値は示していませんが、推論時の演算量も同様に�増加するため、電力使用量やサーバ運用コストの増大などの課題が発生します。
一方、提案法による適応モデルでは、4つの評価セットすべてで従来法(Shallow Fusion)とほぼ同等の認識精度を達成しました。ここで注目していただきたいのが、言語モデルを用いていないため、モデルのパラメータ数および推論演算量が一切増えない点です。このため、従来法とは異なり、ストレージ使用量や電力使用量、サーバ運用コストなどを一切増大させずに、ドメイン適応の効果を得ることができます。
表1: ドメイン適応前(Base)およびドメイン適応後(Shallow Fusion、提案法)の単語誤り率(%)
| Method | #Params | dev-clean | dev-other | test-clean | test-other |
|---|---|---|---|---|---|
| Base | 88.7M | 2.6 | 8.7 | 3.1 | 12.7 |
| Shallow Fusion | 176.3M | 2.5 | 7.7 | 2.9 | 11.1 |
| Proposed | 88.7M | 2.4 | 7.6 | 2.8 | 11.2 |
おわりに
音声認識モデルのドメイン適応のために最適なデータセットを抽出する方法を紹介しました。具体的には、目的ドメインのデータ分布との Kullback-Leibler ダイバージェンスを最小化するデータセットを、劣モジュラ最適化を用いて効率的に抽出するアプローチについて説明しました。新たにデータセットを構築するコストを掛けずに、かつモデルサイズや推論演算量を一切増やさずに、目的のドメインに特化したモデルを構築できます。多様なドメインで展開される多様なプロダクトに向けて��、低コストでのカスタムモデル構築が実現できると期待されます。
参考文献
- [1] Yusuke Shinohara and Shinji Watanabe, “Domain Adaptation by Data Distribution Matching via Submodularity for Speech Recognition,” in Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2023.
- [2] Yusuke Shinohara, “A Submodular Optimization Approach to Sentence Set Selection,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2014.
- [3] Harald Steck, “Calibrated Recommendations,” in Proceedings of the 12th ACM Conference on Recommender Systems (RecSys), 2018, pp. 154-162.
- [4] Daniel S. Park, Yu Zhang, Ye Jia, Wei Han, Chung-Cheng Chiu, Bo Li, Yonghui Wu, and Quoc V. Le, “Improved noisy student training for automatic speech recognition,” in Proc. Interspeech, 2020.
- [5] Jeff Bilmes, “Submodularity in Machine Learning Applications,” Twenty-Ninth Conference on Artificial Intelligence, AAAI-15 Tutorial Forum, January 2015.


