高速かつ高精度な音声認識処理を目指して 〜潜在変数モデルの応用〜
こんにちは、LINEヤフーで音声認識エンジンの研究開発を担当している藤田です。今回のブログでは、LINEヤフーで取り組んでいる音声認識技術の研究開発の最新の取り組みの1つを紹介します。具体的には、高速かつ高精度な音声認識処理を実現するべく、機械翻訳の分野で提案された潜在変数を用いたモデルを音声認識に応用し、従来法に比べて良好な精度と速度を達成しました。なお、この内容は難関国際会議IEEE ASRU 2023にて発表を行っています。論文はこちらで公開されているので、詳細が気になる方はぜひご覧ください。
音声認識処理は、処理が高速かつ高い精度が求められる
音声認識処理は、音声からその発話内容のテキストを予測する技術です。スマートフォンからの検索ワード入力や動画の自動字幕付、コールセンター対応の補助などさまざまな応用先があります。すべての応用先に共通する望ましい挙動は、当たり前ですが、処理が高速で高い精度を得られることです。しかし一般的に、音声認識処理に限らず処理速度と精度はトレードオフの関係にあり、両方を実現することは困難です。
昨今では精度が高い大きなモデルでも、GPUなどを用いればある程度高速に推論できますが、GPUは高価ですし、例えば数十万時間の音声を毎日処理したい場合などでは、費用対効果が悪くなってしまいます。そのため、モデル側でなんらかの工夫を施すことで、推論処理を高速化することも必要です。
非自己回帰モデルによる高速化と課題
非自己回帰モデルとは?
モデル側での工夫の1つとして、非自己回帰モデルが知られています。これは、これまでの音声認識処理で主流だった、自己回帰モデルにおける逐次処理をなくす/緩和することで、高速な処理を実現するものです。詳細な説明は以前のブログに譲って、概要を説明します。
自己回帰モデルでは、例えば「明日の天気」という発話があった場合、まず「明」を予測したのち、それをモデルに再入力して次の文字「日」を予測します。この処理は逐次的に行う必要があり、並列計算ができません。
一方、非自己回帰モデルでは、すべての/複数の文字を同時に予測するため、並列計算が可能です。そのため、SIMDなどによる効率的な処理が可能となり、高速化が期待できます。
非自己回帰モデルの課題
課題は、自己回帰モデルに比べて精度が劣化する場合があることです。特に雑音環境や不明瞭な発話の場合に、劣化することが知られています。この原因の1つとして、非自己回帰モデルにおける条件付き独立の仮定が、音声認識処理に適していないと考えられています。条件付き独立というのは、文字間の依存関係を考慮しないことです。
自己回帰モデルは過去に予測した文字列に依存するため、例えば「明日の」まで予測した場合、先に続く文字は「天気」や「予定」が妥当そうで、「元気」や「ペンキ」などは妥当ではないことを、モデルが学習データから暗に学習していると考えられています。
一方、非自己回帰モデルでは、この��ような学習が不十分なために精度劣化が起きているのではないか、と考えられています。この条件付き独立の仮定を緩和する手法はいくつか提案されていますが、今回は、機械翻訳の分野で良好な結果が報告されている、潜在変数モデルを応用することにしました。
潜在変数モデルとは?
まず、ニューラルネットワークによる、End-to-End(E2E)音声認識モデルの一般的な定式化を説明します。E2E音声認識モデルは、音声の特徴量 が与えられた条件での文字列 の事後確率が、パラメータ を持つニューラルネットワークによりモデル化されています。
潜在変数モデルでは、この事後確率が、ある潜在変数 で周辺化されていると仮定します。
このモデルはこのままでは解けないため、ELBO(evidence lower bownd)という形式を導入し、これを最大化するように学習します(大量のデータを効率的に学習するアルゴリズム”reparameterization trick”が存在します)。
ここで、 はKLダイバージェンスです。そしてELBOの3つの項、つまり「デコーダ」「事後分布推定」「事前分布推定」をなんらかのニューラルネットワークでモデル化します。
KLダイバージェンスが小さくなるように学習が進むので、文字列 を観測した上での事後確率分布と、音響特徴量 しか観測できない状態での事前分布が近くなることを期待します。つまり、事前分布推定のNNが文字列 をある程度考慮した分布を出力するようになり、条件付き独立が緩和されることを期待しています。
CTCと潜在変数モデルを組み合わせた音声認識モデル
では、具体的にどのようなニューラルネットワーク(NN)で音声認識モデルを作るのかについて、説明していきます。
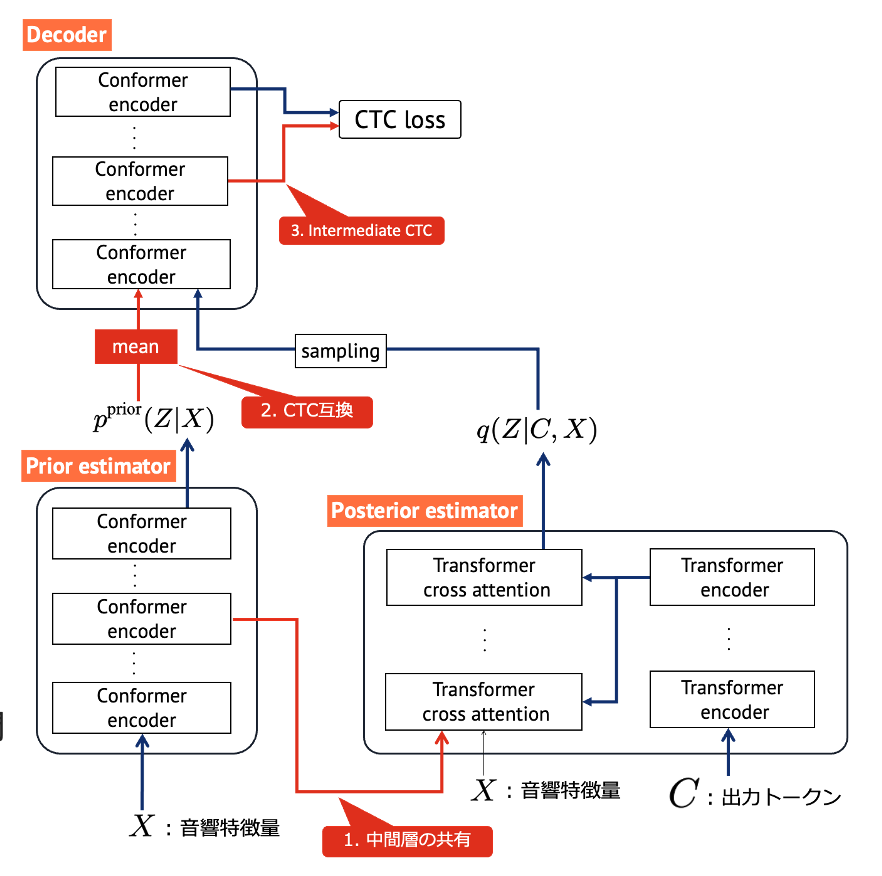
基本的には、Transformerと、Transformerをconvolution blockで補強したConformerと呼ばれる構造を採用しました。事後分布推定NNは音響特徴量 とトークン系列 の双方が入力されるため、Transformerのcross-attentionを用いています。そして、デコーダの出力にはconnectionist temporal classification(CTC)ロスを用いました。いずれも、非自己回帰��モデルによる音声認識ではよく用いられる構成です。
潜在変数モデルの定義に従うならば、この構成で十分なはずなのですが、従来法に比べて精度が向上しませんでした。そこで、次に示す3つの工夫を導入しました。
-
中間層の共有
事前分布推定NNの中間層出力を、事後分布推定NNに入力することにしました。事後分布推定NNの内部で、音響特徴量と出力トークンの間のcross attentionを計算しているのですが、それぞれの特徴が大きくことなるため、うまく計算できていないのでは、と推測しました。そこで、事前分布推定NNの中間出力であれば、この特徴の違いがある程度緩和されていると期待しました。
-
CTC互換
事前分布推定NNの出力の平均値をデコーダに入力することにしました。これにより、事前分布推定NNとデコーダが従来のCTCと非常に似た構成となるため、少なくとも従来のCTCの精度が担保されることを期待しました。
-
Intermediate CTC
デコーダの中間層にもCTCロスを適用しました。 これは、CTCを用いた音声認識でよく用いられるテクニックで、精度改善を期待しました。
NNの詳細な構造は以下の図を参照ください。
実験で効果検証
この構造のモデルを、英語のパブリックコーパスLibriSpeechのサブセット(100時間)で学習し、評価しました。評価セットは2つで、cleanという比較的認識が容易なものと、otherという比較的難しいものです。比較する従来のモデルは、RNN-Transducerという�自己回帰モデルと、従来のCTCです。評価指標は単語誤り率(Word Error Rate, WER)と、処理時間を処理する音声の長さで割ったRTF(Real Time Factor)という値を用います。いずれも低い方が良いものです。
結果は以下の通りでした。
| モデル | RTF | WER (clean) | WER (other) |
|---|---|---|---|
| 自己回帰 | 0.291 | 6.2 | 16.8 |
| CTC | 0.044 | 6.9 | 19.8 |
| 提案手法 | 0.086 | 6.1 | 17.1 |
潜在変数モデルを用いない従来のCTCに比べると、処理時間は倍になるものの、大きく精度が改善しています。また、自己回帰モデルに比べてもotherにおいて多少の精度劣化がありますが、3倍近い高速な処理が実現できています。以上から、提案手法は処理速度と精度のバランスがある程度よく取れているのでは、と考えられます。
まとめ
このブログでは、高速・高精度な音声認識処理を実現するために、潜在変数モデルとCTCを用いた非自己回帰型モデルを提案しました。さまざまな工夫を加えることで、従来法に比べて処理速度と精度のバランスが良いモデルが実現できたと考えています。今後は、日本語での評価実験を行い効果を確認し、プロダクトに導入していきたいと考えています。


