LINEヤフー Advent Calendar 2023の1日目の記事です。
こんにちは。Yahoo!乗換案内でiOSアプリ開発を担当している江田です。
この度乗換案内アプリにて路線図改め公共交通マップをリリースしました。その機能であるトレインキャストにて、約4,000〜5,000台に及ぶ全国すべての鉄道を実時間に沿って、時刻表通り動かすという描画周りの限界に、ネイティブ言語を用いて挑み、そこで得られた知見を紹介します。
1. トレインキャストとは
トレインキャストとは鉄道路線の上を、時刻表データを元に実際の列車を模したアイコンが走行するものです。 列車アイコンをタップすると、列車の写真や発着時刻、列車番号などの情報を確認できます。対象となる列車は新幹線、有料列車、普通列車など、全国の鉄道路線をすべて採用しました。乗車中の列車や、通過列車の情報を確認したり、鉄道が好きなお子さまや鉄道ファンの方が見て楽しめる機能となっています。
2. 時刻表データから、列車の走行位置を現実時間に沿って可視化するには
トレインキャストは、時刻表をベースにした列車情報の可視化を目指して開発されています。しかし実際の列車の位置と、理論上の走行位置は、完全に一致するわけではありません。
なぜなら、現実の列車は加速・減速を行いますし、列車の発車遅延などの予測不能な事態が起こることもあるからです。トレインキャストは出発時刻になったら地図上に追加され、駅と駅との間を等速で移動しながら出発・停止を繰り返します。
そして、列車が目的地に到達する��と地図上から削除されます。ではこのようなメカニズムを、時刻表データからどのように実現できるのでしょうか。そのためには、一連の列車のライフサイクルを定義する必要と、ライフサイクルを処理できる形に時刻表データを再定義する必要があります。
列車のライフサイクルの定義
トレインキャストでは列車のライフサイクルを以下のように定義しています。
- 列車の生成
- 列車を地図上に追加
- 列車を移動開始
- 列車を一時停止
- 列車を目的地で停止
- 列車の削除
5の目的地に到着するまで3,4は繰り返されます。時刻表データを上記のライフサイクルに沿って再定義したデータに変換し、このライフサイクルを実現できるシステムを構築しました。
時刻表データの再定義
再定義したデータは以下のようになっています。
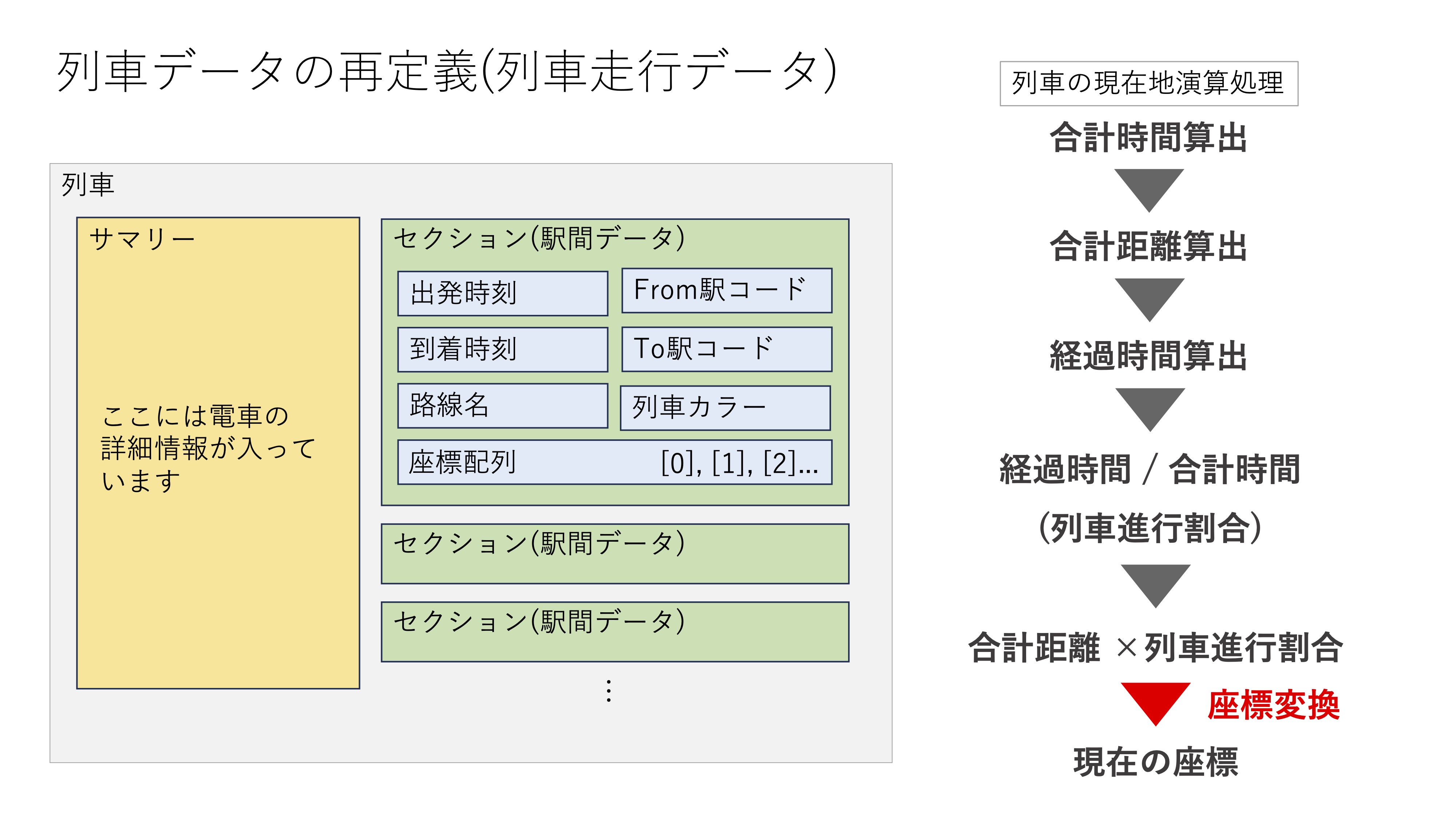
再定義したデータを元に列車を地図上に描画します。駅間の移動アニメーションは、高速で列車オブジェクトを再描画することによって、パラパラ漫画のようにつなぎ合わせ、動いているように見せています。というのも、今回採用した地図描画のライブラリには、地図上のオブジェクトを個別にアニメーションで動かす機能はなかったからです。
列車のライフサイクルを実現できるシステム
これで列車のライフサイクルに沿った時刻表データの再��定義が完了しました。これを列車のライフサイクルに当てはめたのが次の図です。
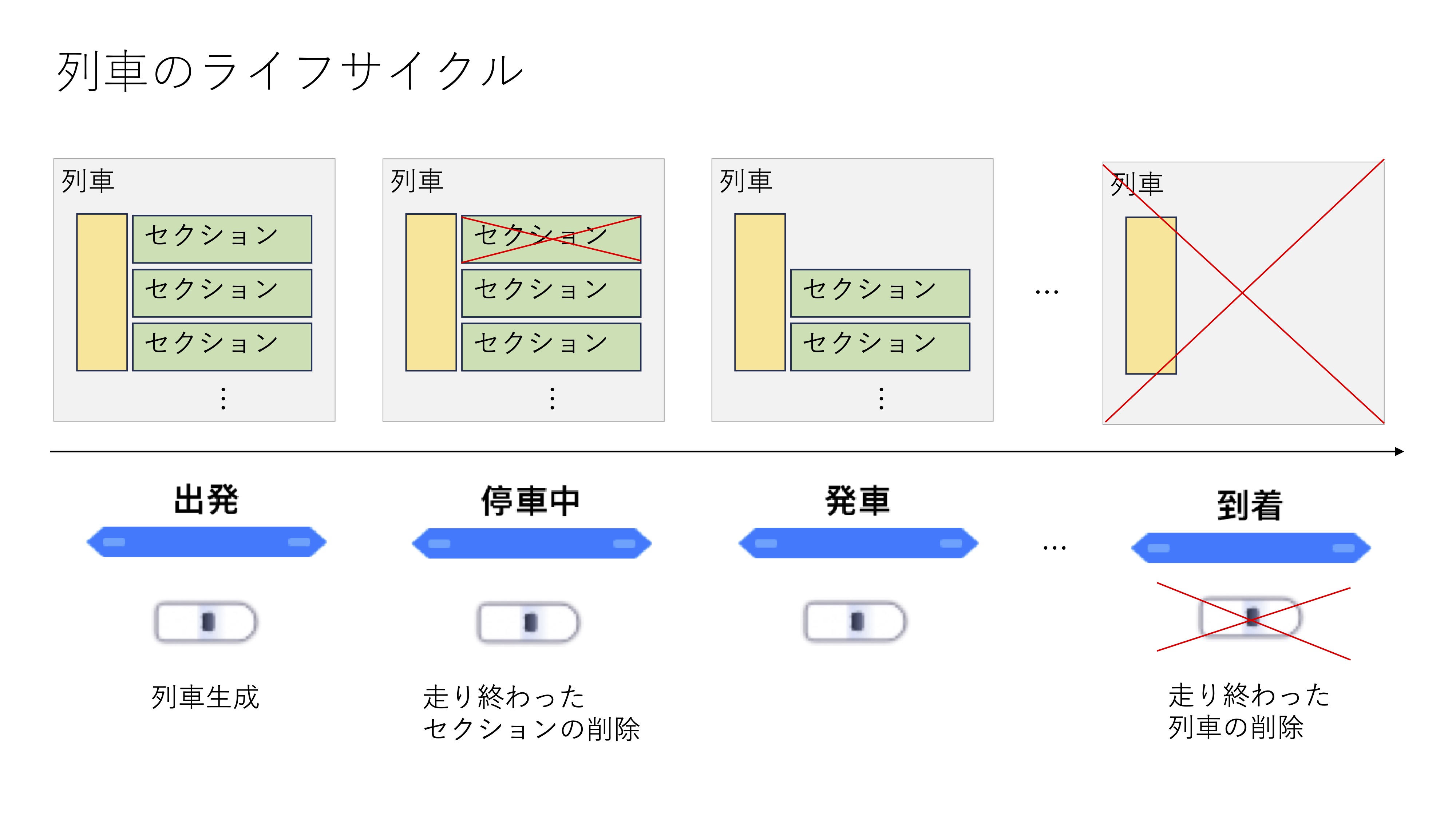
駅間をアニメーションさせつつ移動をさせ、移動が終われば区間データを格納した配列から当該区間を削除します。そして次の区間の発車時間になったら再び列車を移動させ、終わればその区間を配列から削除するという処理を繰り返し、区間情報の配列がすべてなくなった時点でマップ上からその列車オブジェクトを削除します。
このようにしてトレインキャストでは、時刻表データから列車の走行位置を現実時間に沿って可視化しています。
3. 列車のアニメーションクオリティーを上げるために
2章にてトレインキャストにおける移動アニメーションについて軽く触れました。パラパラ漫画のように、高速で列車オブジェクトの再描画を繰り返すことで、列車が動いているかのように見せています。このアニメーションの品質を上げるには、できるだけ再描画する回数を増やす必要がありました。
つまりフレームレート(FPS)を上げることです。FPSは高ければ高いほどなめらかな動画になり、低すぎるとカクカクした動画になってしまいます。FPSは一般的に30FPSあれば違和感なくみられ、60FPSで自然な動きの映像に見えるといわれています。
しかし、普通列車を含めた数千台の列車を再描画させるためにかかる、位置計算のコストは膨大です。開発当初は一桁程度のFPSしか出せず、繰�り返しの再描画処理を、いかにFPSを落とさずに行うかが課題でした。
この課題を解決するために大きく分けて3つのアプローチを試みました。
広域時の演算対象を限定
1つ目は広域時表示、つまりズームレベルが低い場合に再描画ループ実行の演算対象を絞ることです。広域時表示の場合は、ユーザーが見たいのは列車の全体的な分布などになるため、すべての列車のアニメーションはそれほど品質が求められないと考えたからです。
ただし、この対応をする上で難しかったのが、1回のループ処理でどこまで演算し終えたかという演算対象のインデックス管理です。なぜなら、列車の初回読み込み後、1分ごとに新しい列車を地図上に追加する機能と到着した列車を削除する機能があるため、列車のインデックスが動的に変化するからです。演算対象を絞ることにより、1回のループ処理の負荷を軽減することでき、FPS低下を防ぎました。
狭域時の演算対象を限定
2つ目は、狭域時表示つまりズームレベルが高い場合に、バウンディングボックスを用いることです。バウンディングボックスとは、画像や映像の中の物体を囲んだ部分領域のことで、領域内に存在する物体検出に用いられる技術です。
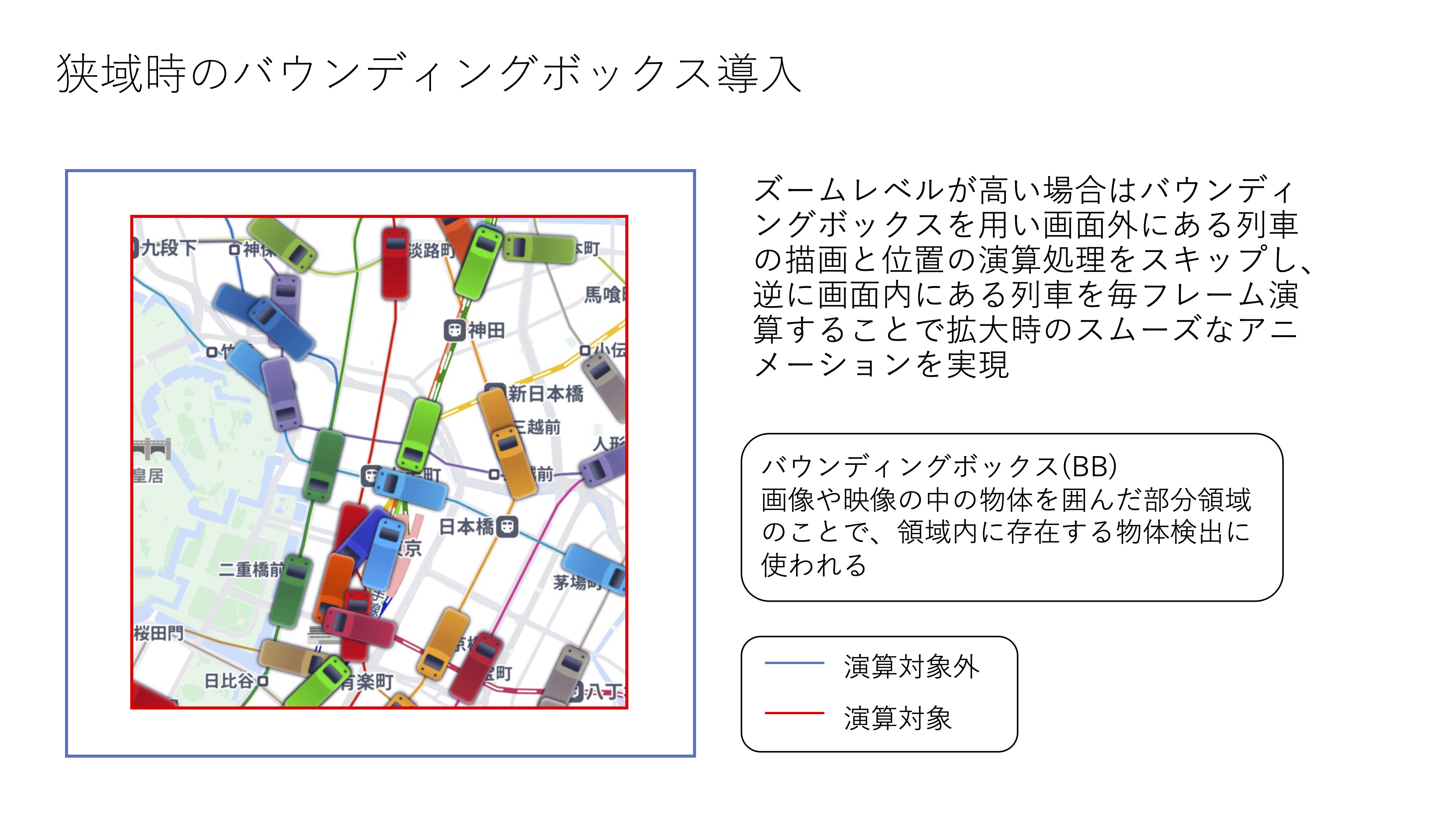
狭域時表示の場合は、ユーザーは興味のある列車を注視したいと考え、画面領域内に存在する列車のアニメーションは高品質で提供することを目指ししました。そこ��で、ズームレベルが高い場合はバウンディングボックスを用い、画面外にある列車の描画と位置の演算処理をスキップし、逆に画面内にある列車を再描画ループの際に毎回演算することで、拡大時のスムーズなアニメーションを実現しました。
CADisplayLinkの採用
3つ目は再描画の定期実行に、CADisplayLinkを採用したことです。定期的な繰り返し処理をさせるには、一般的にNSTimerを利用すると思います。しかしNSTimerを用いた場合、画面の更新タイミングに関係なく、固定された秒数でcallbackが呼ばれます。高頻度のcallback呼び出しが必要な場合、callback処理の負荷が高いと、その処理が終わるまで次のcallback処理が行われないため、画面更新が止まってしまい、いわゆるコマ落ちが生じてしまいます。
CADisplayLinkは、画面のリフレッシュレートに同期して、callbackを実行するためのクラスです。画面のリフレッシュレートに合わせて、callback処理の実行タイミングを自動調整でき、スムーズなアニメーションやリアルタイムの描画を実現を可能にするため、ゲームやグラフィックスアプリケーションなどでよく使用されます。
これを用いることで、フレーム間の処理が間に合わない場合でも、端末の負荷状況に応じてcallback呼び出しのタイミングを調整してくれます。これにより、端末負荷状況に応じて、最大限のアニメーションパフォーマンスを発揮することが可能になります。
さらにCADisplayLinkは、timestampとtargetTimestampという2種類のプロパティを取得できます。timestampは、今準備しているフレームの開始時刻を表すタイムスタンプで、targetTimestampは、今準備しているフレームが表示される時刻を表すタイムスタンプです。
列車の現在地を算出する際に、出発してからどれくらいの時間が経過し、どれくらいの距離を移動したのかを算出し、そこから現在の座標を求めます。どれくらいの時間が経過したかを算出する際に、実際に描画される時間をあらかじめ加算しておく必要があります。
しかし、高負荷で処理が間に合わない際にcallbackがスキップされることがあるので、 今のフレームのtargetTimestampが、次のフレームのtimestampに一致するとは限りません。正確な位置計算を行うためには、デルタにtargetTimestampを使うことが望ましいです。
func displayLinkCallback() {
progress += link.targetTimestamp - previousTargetTimestamp
previousTargetTimestamp = link.targetTimestamp
...
}以上のようにさまざまなテクニックを駆使し、端末の性能に依存するところではありますが、常時30〜60FPSを保てました。
4. 全国の車両情報を高速生成するために工夫したこと
トレインキャストでは、各列車のボタンを押した際にサーバーから該当種別の列車情報をダウンロードして、キャッシュしています。ダウンロードしてきたデータはzip形式で圧縮されており、それらの解凍およびパースをアプリ側で行っています。
この際、1日分の列車データをダウンロードしているため、すべての車両種別を合計すると約10万台のデータがあります。このうち9割ほどが普通列車のデータとなっています。2章で触れましたが、このダウンロードしてきたデータから、列車のライフサイクルを実現するためのデータを作り直さなければいけません。
有料列車や新幹線ではさほど問題はなかったのですが、普通列車に関しては、列車のライフサイクルを実現できるデータに変換するまでのすべての処理時間を合計すると、約20分かかっていました。この課題を解決するために、大きく2つのアプローチを行いました。
サーバーから取得するデータの最適化
まず行ったのが、サーバーからもらうデータをアプリ側で扱いやすい形式に変更することです。あらかじめサーバー側でデータを生成する際に、列車のライフサイクルにできるだけ近づけた形のデータを生成し、負荷を分散しました。これにより、サーバーからもらったデータをアプリ側でほとんどそのままパースすれば、必要な形式のデータが生成できました。
さらに普通列車に限っては、zipファイルを細かい単位で分割して、サーバーに配置するようにしました。これにより、zipのダウンロード処理と解凍からパースまでの処理を、並行で行えるようになり、データ生成の効率化が行えました。
データ生成処理の並行化
次に行ったのが、データ生成処理の各フェーズを、できうる限り並行で実施することです。ただし、並行処理の弊害として端末の発熱問題がありました。並行処理による処理速度向上と端末の発熱量はトレードオフだったので、CPUの処理能力をどれだけ並行処理に割り当てるのかは、最後まで微調整を行いました。
また、今回並行処理にはSwift Concurrencyを使っていますが、並行処理を中断された際に、適切にタスクキャンセルをしてあげないとインスタンスが解放されず、循環参照を引き起こしてしまいました。
他にも同時書き込みによる、データ競合の不具合などにも遭遇しました。これらの経験からSwift Concurrencyは便利な反面、使い方に非常に注意が必要だと感じました。
他にもXcodeのTimeProfilerを使って、ひたすら実行中のプロセスから時間のかかる処理に関して、さらに効率的な処理方法がないか検討し、トライアンドエラーを繰り返しました。
以上の取り組みにより、最初20分ほどかかっていた列車データの生成時間は、最終的に20秒ほどまで改善できました。
おわりに
今回トレインキャストを開発するにあたり、普段あまり触れないさまざまな技術領域に触れられました。どちらかというとゲームに近い思考の開発だったのかなと思います。ファーストリリースではユーザーに!(びっくり)な体験を届けることを目標としており、ありがたいことにSNSなどでも非常に大きな反響を呼びました。
今後は!な体験を届けるとともに、普段使いで役に立つ機能も追加していく予定です。まだまだ成長途中のプロダクトではありますが、変化を楽しみながら開発をしていきたいと思います。


