はじめまして、データソリューション本部の小暮です。私はデータアナリストチームのマネージャーを担当しています。
弊社では、Yahoo! JAPANが持つ質の高�い大量のデータを活用し、データマーケティングソリューション(以下、DMS)の開発に取り組んでいます。
この記事では、改正個人情報保護法に準拠した管理システムを、非データエンジニアであるアナリスト組織の現場で開発した事例について、奥村・清水・雲崎と共にご紹介します。その中でもとくに、分析作業において頻繁に発生する「二次加工データ(分析用データマート、中間テーブルなど)」の取り扱いに焦点を当てます。
1.非データエンジニアによる改正個人情報保護法対応
個人情報保護法が改正され、個人情報の取扱いが厳密になりました。これにより、ユーザーは安心感を享受できますが、一方で分析担当者にはより高いデータ管理精度が求められます。とくに、二次加工データの扱いに関する課題が生じる可能性もあります。
(※LINEヤフー株式会社ではお客様のプライバシーの保護に細心の注意を払っています。詳しくはLINEヤフー プライバシーセンターをご覧ください。)
そんな中、われわれも改正された個人情報保護法の遵守を最優先とし、その解釈に善処しています。具体的な取組としては、「Apache Hudiを使ったレコード単位で削除可能なデータレイクの構築」の話におけるデータレイクレベルの削除請求への対応に加えて、分析用のデータも同様に扱うよう社内規定を設けています。
アナリストとして作業をする際、顧客ニーズに最大限応えるためにさまざま��な分析軸を用意する必要があります。そのため、データレイクから必要なデータを切り出し、分析用データマートを作成するという作業は一般的です。分析プロジェクトの性質によっては中長期にわたって複製データを保持する必要があり、現場において削除申請ユーザーのデータを除外する処理を行う必要があります。
弊社には多くのアナリストが従事しており、個別分析案件やソリューション開発のPoC案件に対応しています。そのため、案件ごとに削除処理を組み込むことは大変な作業であるため、対応アプローチの検討が必要でした。
ルール遵守のために最初に検討した選択肢は大きく次の2つです。
- 任意のユーザー識別子を含むテーブル・レコードを全体を中央の仕組みで定期削除。
- 定期的にパージや削除が行われなかったユーザー識別子の監視をし、案件担当者に削除依頼。
さまざまな検討の結果、誤って重要な分析データマートを削除するリスクを回避するため、2の検知・監視の仕組みを作ることにしました。
次章以降ではread系コマンドのみを使用した識別子の監視システム(以下、パトロールシステム)の作り方について、検討の過程をご紹介します。
2.システム実装までの流れ
2-1.調査対象ストレージの調査
パトロールシステムの設計要件を固める前に、まずはパトロール対象となるストレージの実態調査を行いました。
システム開発前のアプローチでは、ストレージからファイルをすべて実行環境に複製し、その中身を確認、検知すべき識別子が含まれているかを��判別する独自スクリプトを作成していました。しかしこの処理には多大な時間がかかり、要求されるパトロールの頻度に対応できない課題がありました。
2-2.アプローチ別要件適合度の調査
プロジェクト内での議論の結果、初めに以下の8点を必要要件として定義し、いくつかのアプローチを調査することにしました。

最初に独自スクリプトが要件と適合するかを整理し、次に独自スクリプトのリファクタリングとの比較検討を行いました。その後、ちょうどAmazon Macie(※1)のサービスについても知る機会があり、比較対象として含める方向で比較・検討を開始しました。Amazon Macieはストレージ(S3バケット)の機密データを定期的にパトロールしてくれるサービスで、運用までをひととおりGUI上で完結できるため、非エンジニアでも簡単にデータセキュリティ体制を強化できると考え、導入の検討を行いました。
※1 ストレージ(S3バケット)の機密データを定期的にパトロールをしてくれるサービス。デフォルトでは、クレジットカード番号・住所などの個人情報を検知できる仕組みが提供されており、カスタム識別子(正規表現)を用いて、各企業独自の機密データも定義できるようになっている。 定期実行や、運用までひととおりGUI上で完結で�きるサービスとなっており、誰でも簡単にデータセキュリティ体制を強化できる至れり尽くせりのサービス。AWS公式ドキュメント:https://aws.amazon.com/jp/macie/
2-3.Amazon Macieの導入決定理由
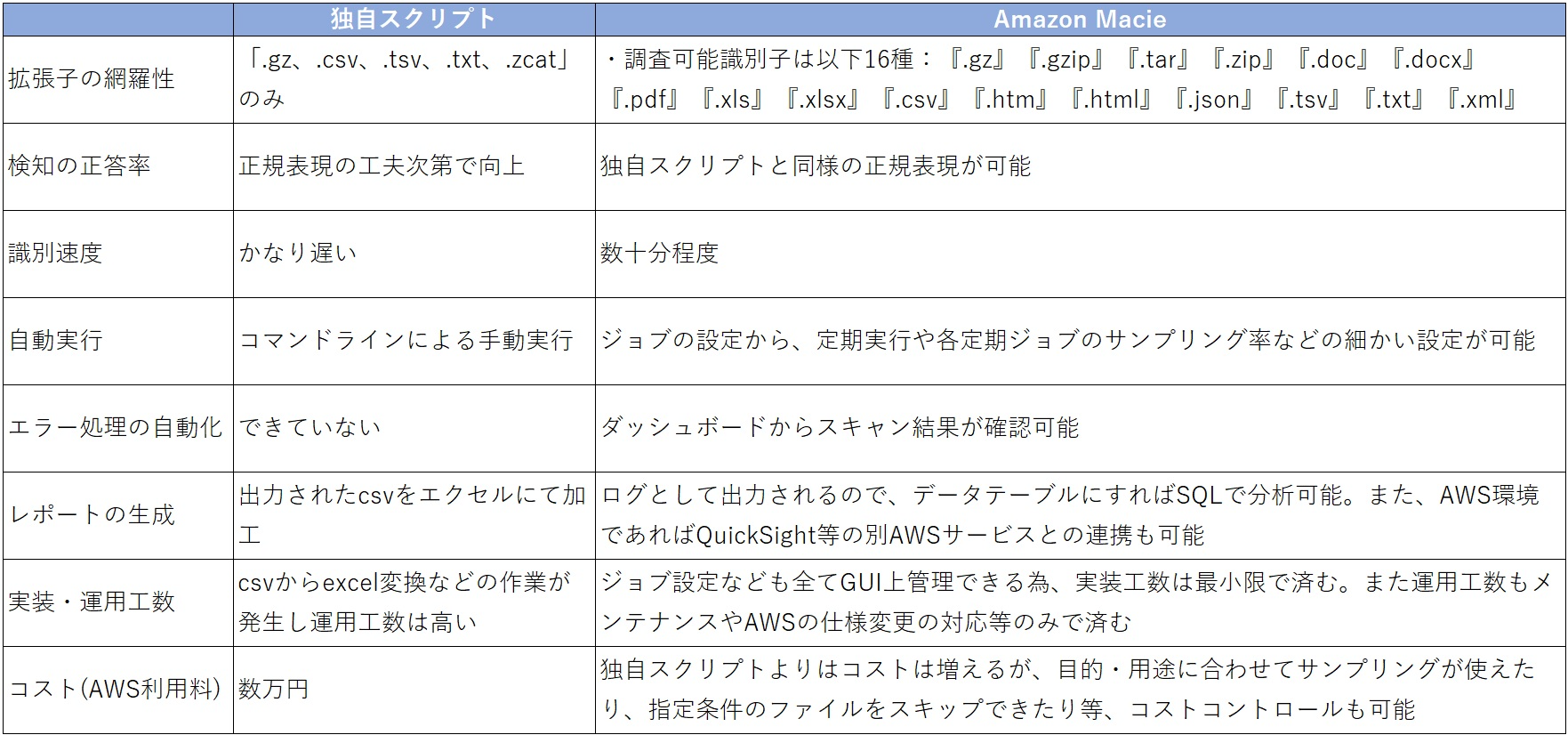
以下の要件適合度表で独自スクリプトとAmazon Macieのスペック差を比較しました。最終的に、プロジェクト内で独自のスクリプトを開発するよりもAmazon Macieを導入することが要件を網羅していることが判明し、Amazon Macieを本格的に導入することを決定しました。
採用理由としては、以下が大きな要素となりました。
- 一番の理由としては、独自スクリプトでは処理が遅すぎたこと。Amazon Macieの利用で高速化が可能であったこと。
- 非エンジニアが主に触るため、運用や結果確認などすべてGUIベースで効率的にAWSコンソールから設定できること。
- 識別子もカスタム設定ができ、今後検知対象が増えたときも正規表現の作成のみで追加可能であること。
この前提条件を基に、要件を定義し、最適な手法でパトロールが可能となるようプロジェクトチームでの調査が始まりました。(この時期、プロジェクト内では本当に達成できるのかという不安がありました…)
3.Amazon Macieを中心とした検出結果の可視化までの流れ
3-1.Macieの検出結果ロ�グをテーブル化することで分析と可視化を容易にする
要件を高い条件でクリアしたAmazon Macieでしたが、GUI上では簡易的な結果のみが表示されるため、ダッシュボード・レポート作成についてはMacieのみでは行えないという課題もありました。しかし、弊社の分析環境はAWSサービスを活用しており、Amazon Macieではパトロール対象となったファイルや検知結果などの詳細なログがS3に蓄積されるため、AWSのクエリエンジン、AthenaなどからSQLで抽出できる点は非常にありがたかったです。つまり、他のAWSサービスと組み合わせることで、ダッシュボード化を含めたシステム構築が実現できました。
3-2.Amazon Macieの事前設定
Amazon Macieを使用するためには、適切な権限(IAMロール)の設定が必要です。MacieはS3バケットをスキャンして機密データを検出するために、AWSServiceRoleForAmazonMacieという特別なサービスリンクロールを使用するので、システム実装を行う前にこの設定を済ませておく必要があります。(このロールはMacieが初めて有効化されたときに自動的に作成されます。Amazon Macieの開始方法はAWS公式ドキュメンテーションをご参照ください。)
3-3.Amazon Macieから出力されるログの確認
Macieから出力されるログは、指定したprefixの場所にjsonl.gz形式で出力されます。最上位のキーの構造は以下のようになっており、その中のseverity 、resourcesAffectedとclassificationDetailsがさらにネストされた構造になっています。
['schemaVersion', 'id', 'accountId', 'partition', 'region', 'type',
'title', 'description', 'severity', 'createdAt', 'resourcesAffected',
'category', 'classificationDetails']resourcesAffectedの構造
s3Objectの中身を見ることで、スキャンされたオブジェクトの詳細を確認できます。また、圧縮されているオブジェクトに関してはさらにembeddedFileDetails で展開後の詳細を確認できます。
{
"s3Bucket": {
"arn": "arn:aws:s3:::s3bucket",
"name": "your-bucket",
"createdAt": "2023-09-04T00:00:00Z",
"owner": {
"displayName": "sample",
"id": "sample"
},
// 中略
},
"s3Object": {
"bucketArn": "arn:aws:s3:::your-bucket",
"key": "foo/your_file.gz",
"path": "your-bucket/foo/your_file.gz",
"extension": "gz",
"lastModified": "2022-10-06T08:51:51Z",
"eTag": "xxxxxxxxxxxxxxxxxxxxxx",
"versionId": "null",
"serverSideEncryption": {
"encryptionType": "NONE"
},
"size": "1916",
"storageClass": "STANDARD",
"tags": [],
"embeddedFileDetails": {
"filePath": "your_file",
"fileExtension": "",
"fileSize": "5634",
"fileLastModified": "2022-10-06T08:51:51Z"
},
"publicAccess": false
}
}classificationDetailsの構造
ここに検出した結果が格納されます。今回定義したカスタムデータ識別子での結果、何行目で存在が確認されたかがarray形式で記録されています。
{
"jobArn": "arn:aws:macie2:ap-northeast-1:account:classification-job/xxxxxxxx",
"result": {
"status": {
"code": "COMPLETE"
},
"sizeClassified": "5634",
"mimeType": "application/json",
"sensitiveData": [],
"customDataIdentifiers": {
"totalCount": "97",
"detections": [
{
"arn": "xxxx-xxxx",
"name": "UserID",
"count": "97",
"occurrences": {
"lineRanges": [],
"pages": [],
"records": [
{
"recordIndex": "0",
"jsonPath": "$.user_id"
},
],
"cells": []
}
}
]
}
},
// 略
}3-4.Glue Catalogに登録し、SQLで分析できる状態にする
次に、AthenaのDDLクエリにてMacieのログファイルに対してテーブルを作成します。作成したテーブルを用いて、検出結果をSQLで分析できます。
create external table tssl_807.macie_log_raw_dev (
schemaVersion string
, id string
, accountId string
, `partition` string
, region string
, `type` string
, title string
, description string
, severity struct<score:string,description:string>
, createdAt string
, resourcesAffected struct<
s3Bucket:struct<
arn:string,
name:string,
createdAt:string,
owner:struct<
displayName:string,
id:string
>,
tags:array<string>,
defaultServerSideEncryption:struct<
encryptionType:string
>,
publicAccess:struct<
permissionConfiguration:struct<
bucketLevelPermissions:struct<
accessControlList:struct<
allowsPublicReadAccess:boolean,
allowsPublicWriteAccess:boolean
>,
bucketPolicy:struct<
allowsPublicReadAccess:boolean,
allowsPublicWriteAccess:boolean
>,
blockPublicAccess:struct<
ignorePublicAcls:boolean,
restrictPublicBuckets:boolean,
blockPublicAcls:boolean,
blockPublicPolicy:boolean
>
>,
accountLevelPermissions:struct<
blockPublicAccess:struct<
ignorePublicAcls:boolean,
restrictPublicBuckets:boolean,
blockPublicAcls:boolean,
blockPublicPolicy:boolean
>
>
>,
effectivePermission:string
>
>,
s3Object:struct<
bucketArn:string,
key:string,
path:string,
extension:string,
lastModified:string,
etag:string,
verionId:string,
serverSideEncryption:struct<
encryptionType:string
>,
size:string,
strorageClass:string,
tags:array<string>,
embeddedFileDetails:struct<
filePath:string,
fileExtension:string,
fileSize:string,
fileLastModified:string
>,
publicAccess:boolean
>
>
, category string
, classificationDetails struct<
jobArn:string,
result:struct<
status:struct<
code:string
>,
sizeClassified:string,
mimeType: string,
sensitiveData:array<string>,
customDataIdentifiers:struct<
totalCount:string,
detections:array<
struct<
arn:string,
name:string,
count:string,
occurrences:struct<
lineRanges:array<string>,
pages:array<string>,
records:array<
struct<
recordIndex:string,
jsonPath:string
>
>,
cells:array<string>
>
>
>
>
>,
detailedResultsLocation:string,
jobId:string,
originType:string
>
)
row format serde 'org.openx.data.jsonserde.JsonSerDe'
location 's3://your-bucket/macie_prefix/AWSLogs/156828224272/Macie/ap-northeast-1/'3-5.AWS Athena/QuickSightでの集計・可視化
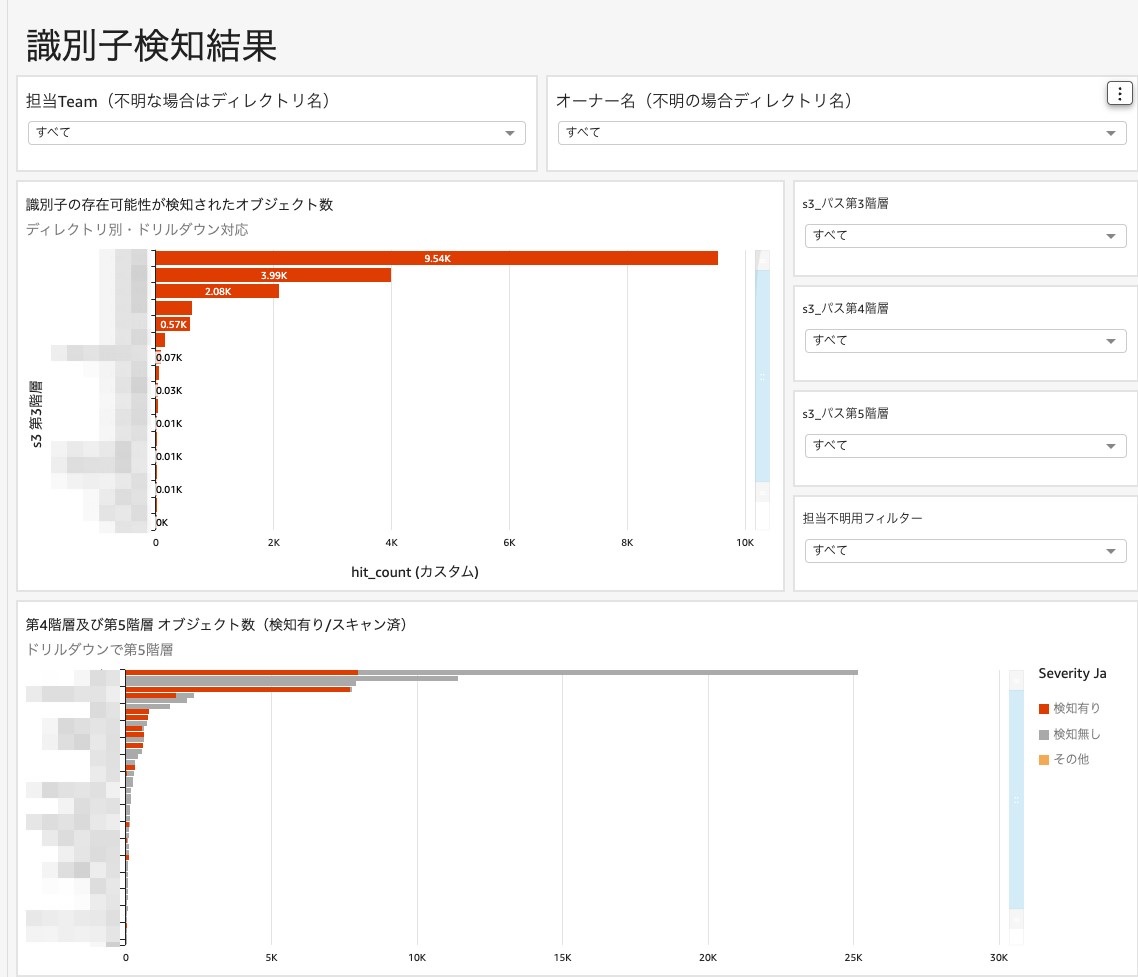
最後にQuickSightで必要な項目に絞ってテーブルからデータを抽出し、ダッシュボード化します。ここでは、読み込みデータの自動更新機能やメールによる定期通知機能があるため、最新のパトロール結果をユーザーに自動で伝えられます。
with t as (select distinct classificationdetails.jobId as jobId
, severity.description as severity
, from_iso8601_timestamp(createdAt) as createdAt
, resourcesaffected.s3Object.key as s3Object_key
, resourcesaffected.s3Object.extension as s3Object_extension
, from_iso8601_timestamp(resourcesaffected.s3Object.lastModified) as s3Object_lastModified
, resourcesaffected.s3Object.size as s3Object_size
, classificationdetails.result.status.code as result_status_code
, classificationdetails.result.sizeClassified as result_sizeClassified
, classificationdetails.result.customDataIdentifiers.totalCount as result_customDataIdentifiers_totalCount
, element_at(classificationdetails.result.customDataIdentifiers.detections,
1).count as result_customDataIdentifiers_detections_1st_row_count
, element_at(classificationdetails.result.customDataIdentifiers.detections,
1).name as result_customDataIdentifiers_detections_1st_row_name
from tssl_807.macie_log_raw_dev)
-- 中略
select jobId
, severity
, s3Object_key
, s3Object_extension
, s3Object_lastModified
, result_status_code
, sum(cast(result_customDataIdentifiers_totalCount as bigint)) as sum_total_count
, sum(cast(result_sizeClassified as bigint)) as sum_result_sizeClassified -- 実際に巡回したサイズ(解凍後)
from t
group by 1, 2, 3, 4, 5, 6
4.識別子検知の自動化成功ファクターはストレージのディレクトリの設計
4までの手順でダッシュボードによる管理体制が出来上がりました。この仕組みで管理が成功した大きな要因は、ディレクトリの適切な設計を行っていたからです。
ディレクトリの設計は情報管理の効率とセキュリティを保つための重要なステップです。そのため、設計に際し以下のポイントを重視していました。
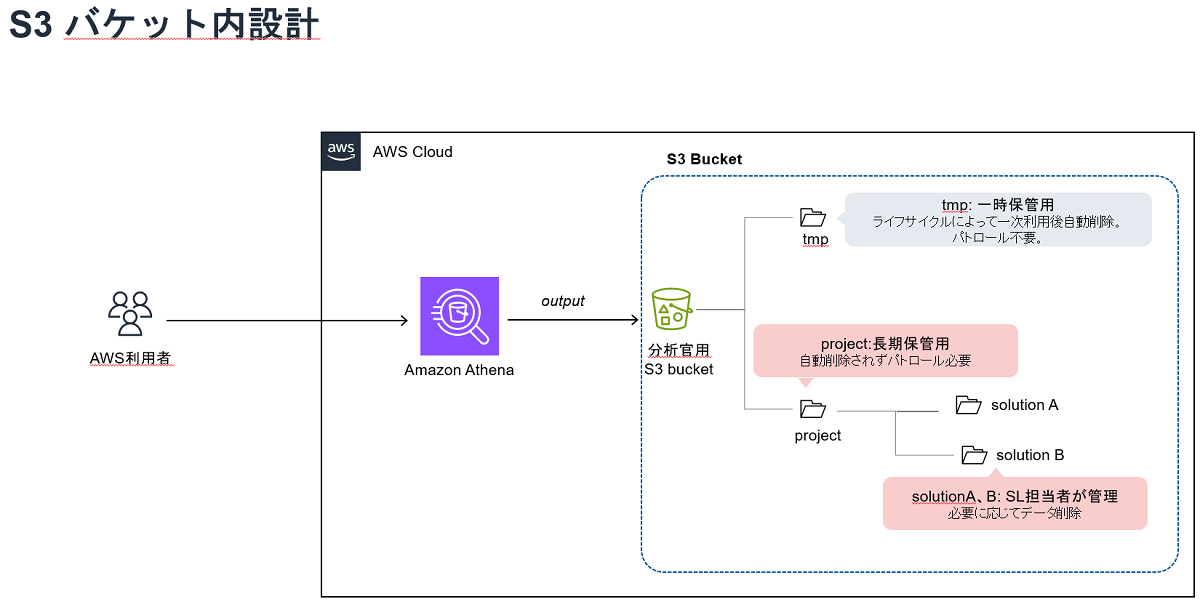
4-1.Point1 データの利用目的×種類でバケット分類し、アクセスポリシーを設定する
私たちの組織の場合、業務の主軸がDMS(データマーケティングソリューション)の開発・運用であったため、ディレクトリもマーケティングソリューション単位で分割していました。また、その配下の階層では識別子データを配置して良い領域も定義しています。このように設計を行うことで、個々のディレクトリに対して適切なアクセスポリシーを設定でき、意図しない識別子が他者によってうっかり配置されることがなくなります。また、パトロールで識別子を検知した場合でも確認先担当者が即座にわかるといったメリットがあります。
4-2.Point2 データの保存期間で分類し、ライフサイクルを設定する
また、データの保存期間もディレクトリの設計における重要な観点です。分析用途のデータなど、長期保管が必要なデータと一時的に保存するだけのデータを同じディレクトリに保存すると、データ管理が複雑になります。長期保存が必要なデータに対するアーカイブポリシーの設定や、一時的なデータの削除スケジュールの設定が、ディレクトリ単位で容易に行えるでしょう。さらに、ライフサイクル設定を使うことで、オブジェクトの寿命を自動的に管理することが可能になり、パトロールの効率化にも貢献します。
以上のディレクトリ設計は、日々増加するデータに向き合うアナリストとして、序盤に行うべき非常に重要な検討事項と言えるでしょう。
5.パトロール実行によって得られた成果とまとめ
これらのシステム実装・運用を行うことで、識別子管理精度の向上し、コストと時間のコントロールが可能になりました。結果として、アナリストが安心して本業に集中できる環境になりました。
アナリストが現場で独自に業務システムを構築する難易度は高いですが、AWSソリューションアーキテクト(SA)との連携により成功へとつながりました。アナリストだけではたどりつきにくいヒントもあり、AWSを活用したソリューション設計や運用におけるSAのサポート体制は非常に助けになりました。現システムには課題も見受けられますが、今後も持続的な運用と改善�を通じて、データ分析を行うすべての人がデータセキュリティ対策を恐れずに環境を維持していけるよう、努力を続けたいと考えています。
この記事が読者の理解を深め、より健全なデータ活用の浸透に役立つことを願っています。


