This is the official article for Tech-Verse 2026, LY Corporation's technology conference.
Coding speed is not the biggest bottleneck anymore. It's the fragmentation of inputs and the cost of stitching them together.
Every feature requires us to jump across systems: Jira for requirements, Figma for design, Confluence for documentation, Slack for clarifications, Git for implementation. As Frontend developers, we sit at the point where every input converges - specs, designs, requirements, plans and our job is to assemble them into something the user can actually use.
For a long time, the burden of frontend work has relied heavily on our ability to absorb and synthesize information, reading tickets, inspecting design files, clarifying edge cases, and constantly syncing with product and backend teams, to ensure the final output meets expectations.
Much of this context switching and many of these manual operations can now be automated with the help of large language models. As LLMs take on more of the coding itself, frontend development is becoming less a coding problem and more a orchestration problem.
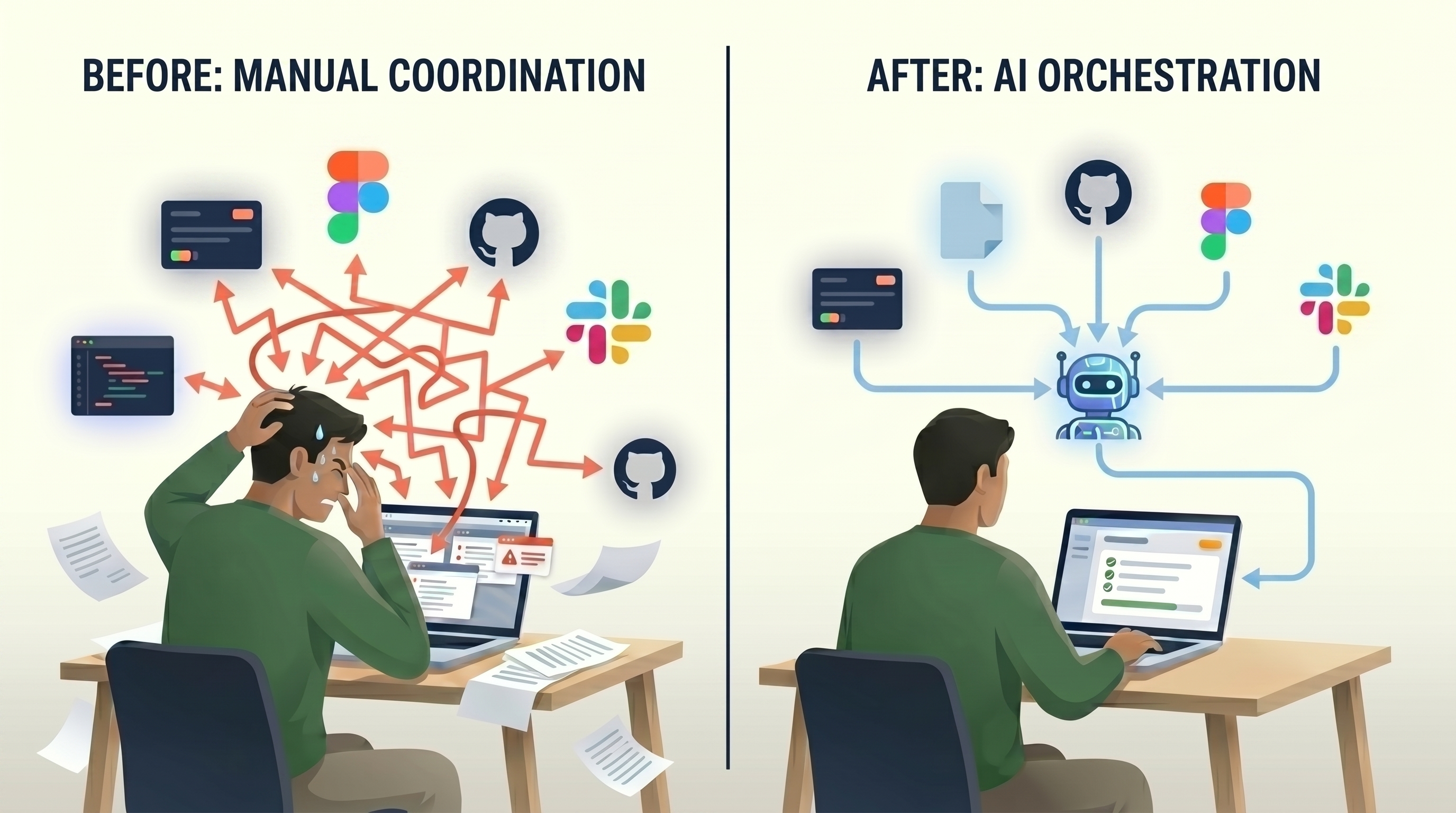
The shift: from prompting to workflows
The instinct with AI is to write a clever prompt and hope. That works once. It doesn't compound.
The workflow is different. It's a repeatable path from input to output: gather context across the systems where the work already lives (Jira, Confluence, Slack, code), summarize what's actually being asked for, surface what's unclear, then propose an implementation plan - and wait for a human to review it before touching code.
AI is the execution engine that runs the workflow.
At LY Corporation, we already have a strong internal ecosystem built by many incredible teams across the organization. Noah MCP is one example: by connecting tools such as Jira, Confluence, Slack, and GitHub, it turns the data we access every day from isolated places we visit one by one into connected inputs an AI agent can read, reason over, and act on. This means the AI is no longer limited to the context we manually paste into a prompt - it can work with the actual context that already exists in our daily workflow.
The same workflow runs on every ticket. The input changes; the pattern stays the same. That's what makes it scale.
What a workflow looks like end-to-end
To make this concrete, here's what usually happens. The ticket. A Jira ticket asks us to build a list page with search, filters, sorting, and role-based filter visibility.
Old way:
- Open the ticket, read it twice: Sort/filter/search are listed, but nothing about whether filter state should persist across refresh or be shareable.
- Open Figma: You find empty / loading / no-results states for the list, plus the filter panel.
- Search Confluence for the feature: Find a page on filter rules: which filters are visible to which roles.
- Search Slack (Slack could include a few hundred messages): Discovered a thread from last month where another team agreed or it was not finalized by the planner?
- Open the codebase: Notice
useTableFiltersanduseUrlStatehooks already exist in another feature. Should reuse, not reinvent. - Open a notes file and start pasting fragments from each source: Try to assemble a coherent plan.
- During development: Run the code and fight all the bugs, all the possible edge cases, solving typing and linting conventions, and so on.
- Ending the cycle: Submit a pull request (PR) to the repository.
New way:
Trigger a workflow.
- Read Jira ticket FE-1234.
- Find related Confluence docs on filter rules and role-based visibility.
- Search Slack for recent decisions on this list page or filter behavior.
- Look for similar list/filter implementations in the codebase.
Do not modify code yet.
Return: requirement summary, frontend impact, files involved,
implementation checklist, test checklist, open questions.A few minutes later, the agent returns this:
## Requirement summary
Build a list page for the <Feature> module with search, filter, and sort.
Integrates with the existing GET /api/<feature> endpoint (already paginated).
Filter set depends on the current user's role.
## Frontend impact
- New `<FeatureListPage />` route + container
- New `<FeatureList />` component reusing existing table primitives
- Search / filter / sort UI wired to the shared filter hook
- State sync: filter + sort + page must round-trip through the URL
## Files likely involved
- src/features/<feature>/FeatureListPage.tsx ← new route
- src/features/<feature>/FeatureList.tsx ← new
- src/hooks/useTableFilters.ts ← reuse
- src/hooks/useUrlState.ts ← reuse
- src/components/ui/SearchInput.tsx ← reuse
- src/components/ui/FilterPanel.tsx ← reuse
- src/api/<feature>.ts ← already exists
## Role-based filter visibility (from Confluence: "<Feature> Access Matrix", updated 2026-04)
- viewer → search, status filter, date range
- editor → + owner filter
- admin → + internal-only flags
## Implementation checklist
- [ ] Add route and page container
- [ ] Wire search / filter / sort to useTableFilters + useUrlState
- [ ] Gate admin-only filters behind useCurrentUserRole()
- [ ] Empty / loading / no-results states per Figma
## Test checklist
- [ ] Filters round-trip through URL params (reload preserves state)
- [ ] Shareable URL renders the same filtered view for another user
- [ ] Role-based filters are hidden for lower-privilege users
- [ ] No-results state renders correctly
## Open questions
1. Filter and sort state: store in URL params or localStorage? (Slack thread 2026-04-12 in #frontend-platform suggests URL params for shareability)
2. Should the empty state offer a "clear filters" CTA, or just "no results"? (Figma shows both variants without indicating which is final.)Above is what a Plan looks like. Three things stand out immediately:
- The Slack thread surfaced a hidden requirement: Filter state belongs in the URL, not localStorage. This is the single thing that would have caused a rewrite halfway through implementation if it surfaced only at PR review.
- Two existing hooks to reuse: (
useTableFilters,useUrlState), no need to invent anything. - Two open questions worth resolving: Before writing a line of code.
Next, after checking the plan and confirming the open questions, the Code Agent can start implementing with high confidence. Resulting in a very high quality work result. However, don’t stop at just implementing the feature - the full workflow needs the follow-ups after coding too. A strong workflow needs a closed-loop development cycle.
After the Code Agent finishes the first implementation, the next step is to make the agent verify its own work against the plan. The same workflow continues. The agent can take the original plan and turn it into a verification loop:
Implementation is done.
Now verify the work against the original plan.
Run:
- typecheck
- lint
- related unit tests
- relevant smoke test or local verification flow
Then return:
- what passed
- what failed and was fixed
- what could not be verified automatically
- screenshots or notes for UI states
- remaining risks before PRThis is where LLMs are especially useful. A lot of frontend maintenance work is not conceptually difficult, but it is time-consuming and easy to skip when we are rushing: fixing TypeScript errors, adjusting test mocks, following lint rules, checking edge states, updating snapshots, or making sure the implementation follows the same conventions as the rest of the codebase.
The output should look like this:
## Verification summary
Typecheck: passed
Lint: passed
Unit tests: passed
Smoke test: partially verified locally
## Tests added / updated
- Added tests for URL state persistence when filters change
- Added tests for role-based filter visibility
- Updated no-results state test to match the Figma copy
## Smoke test result
Verified manually in local environment:
- Search updates the URL query params
- Refresh preserves search / filter / sort state
- Viewer role cannot see owner or internal-only filters
- Admin role can see all filters
- Empty state renders correctly when the API returns no rows
## Issues found and fixed
1. Filter state was reset when changing page number
Fixed by preserving existing URL params inside `useTableFilters`.
2. Admin-only filter was hidden on first render because user role loaded async
Fixed by rendering the filter panel only after role resolution.
3. No-results state used the generic empty text instead of the Figma-specific copy
Fixed by reusing the correct translation key.
## Could not verify automatically
- Shareable URL behavior for another user role requires a real account with different permissions.
- Final empty-state CTA decision still depends on PM / Design confirmation.
## Remaining risk before PR
The implementation follows the current Confluence access matrix, but if the role rules change before release, the filter visibility logic needs to be updated.This changes the agent from a code generator into a development partner that can complete the boring but important loop: implement, run, fail, fix, verify, and report.
And if you can give the Code Agent access to run the app, call real APIs in a safe environment, or execute Playwright smoke tests, the result becomes much more stable. The agent should not only write the code. It should be able to check the result by itself.
For example:
Run the local app and smoke test the feature.
Check:
- loading state
- empty state
- search
- filter
- sort
- pagination
- URL refresh behavior
- role-based visibility
Do not create a PR yet.
Return screenshots, failed cases, and suggested fixes.This is the real value of the workflow: the same context gathered during planning is reused during implementation, testing, debugging, and handoff. The agent does not need to rediscover the requirement at every step. It can keep comparing the work against the original plan.
Then, when the verification loop is clean enough, the final step is handoff. The agent already has the full context:
- What the ticket asked for
- Which files changed
- Which decisions came from Jira, Confluence, Slack, or Figma
- Which tests were added
- Which checks passed
- Which risks still need reviewer attention
So it can prepare the PR in the same team convention:
Prepare the PR.
Read the project PR template and recent merged PRs in this area.
Summarize the change using the team convention.
Link the Jira ticket.
Include test evidence.
Call out remaining risks or manual verification notes.
Do not hide unresolved questions.The PR description should not be generic. It should be the final summary of the whole workflow:
## Summary
Implemented `<Feature>` list page with search, filters, sorting, pagination, and role-based filter visibility.
## Key behavior
- Search / filter / sort state is synced to URL params
- Viewer, editor, and admin roles see different filter sets based on the access matrix
- Empty, loading, and no-results states follow Figma
- Existing `useTableFilters` and `useUrlState` hooks are reused
## Verification
- Typecheck: passed
- Lint: passed
- Unit tests: passed
- Local smoke test: completed
## Notes for reviewers
- URL state behavior follows the Slack decision from 2026-04-12
- Empty-state CTA still needs final Design confirmation
- Shareable URL behavior across different user roles requires staging verification
This is the closed-loop workflow. The context is carried through the entire development cycle. Planning prevents the wrong implementation. Testing prevents the fragile implementation. Smoke testing prevents the implementation that only works in theory. PR handoff prevents reviewers from having to reconstruct the entire story from scattered commits. That is what makes the workflow feel complete.
Gather context
→ Return plan
→ Resolve open questions
→ Implement
→ Run checks
→ Fix failures
→ Smoke test
→ Summarize verification
→ Prepare PRHow to achieve this magic?
You don't need a workflow library to start. You need good prompting discipline and a verified MCP setup.
1. Verify your agent can reach the tools (one-time):
First, run the following command once to confirm that the agent can access the required tools.
claude mcp list
# or
codex mcp listBelow is a list of our expected services:
jira
confluence
slack
github
figmaRecommended to explore (optional):
design.md
playwrightIf anything is missing, the setup guides are linked in wiki, docs here:
- Claude Code MCP setup
- Codex CLI MCP setup
- Design.md for describing a visual identity to coding agents
2. What each tool contributes
At our company, each tool serves the following purpose.
| Tool | What the agent reads | What the agent can do |
|---|---|---|
| Jira | Ticket scope, acceptance criteria, linked issues, sub-tasks, comments, custom fields. | Create tickets from a planning doc using the team's standard description format. Comment with progress updates, transition status, link to epics |
| Confluence | Long-lived business rules: permissions, status definitions, edge cases, access matrices, design specs. | Search across spaces, extract specific sections from long pages, summarize multi-page docs into the relevant business rules for the current ticket |
| Slack | Recent decisions and clarifications that never made it back to the ticket, design pings, API limit changes, PM confirmations. | Search threads by keyword, surface confirmed decisions vs still-open questions, cite messages with channel + date so you can verify |
| GitHub | Prior PRs in the same area, branch history, the project's commit convention, the PR template, CI status. | Run lint and apply auto-fixes, group changes into commits following the convention, draft PR descriptions from the team's template, open a draft PR linked to the ticket |
| Figma | Component specs and variants, design tokens, layout details, screen states (empty / loading / error / hover / focus), accessibility annotations. | Generate component scaffolds from a frame, extract design tokens into code, map Figma components to existing code components via Code Connect, surface design states the ticket forgot to mention. |
3. Use plan mode to run the workflow on a real ticket.
If you're using Claude Code: turn on plan mode (/plan) before running. Plan mode is the structural enforcement of do not modify code yet. The agent can search, read, and plan, but can't write to files until you explicitly approve. It turns the boundary from a prose instruction into a guarantee. It should be the same as the plan mode of other coding agent tools.
4. Review the output before touching code.
Especially the Open questions section. If the agent surfaces one good question you would have missed, the workflow has already paid for itself.
5. Prepare your close-loop development.
In your code base, set up Code conventions where LLMs can read and follow. SKILL.md or Custom Slash Commands is the best place to manage them. And always pair any work with test suites.
6. Final review work and ready to Handoff.
A hand-off condition should be all satisfied in the plan and combined with any convention of the team in the PR or Git management. A well defined convention and templates are what matter here.
Why this works: understand before you execute
The reason the workflow above produces useful output isn't the prompt, it's the order. The agent gathers context, summarizes, and asks questions before it's allowed to change code. That ordering is what separates a workflow from novice prompting.
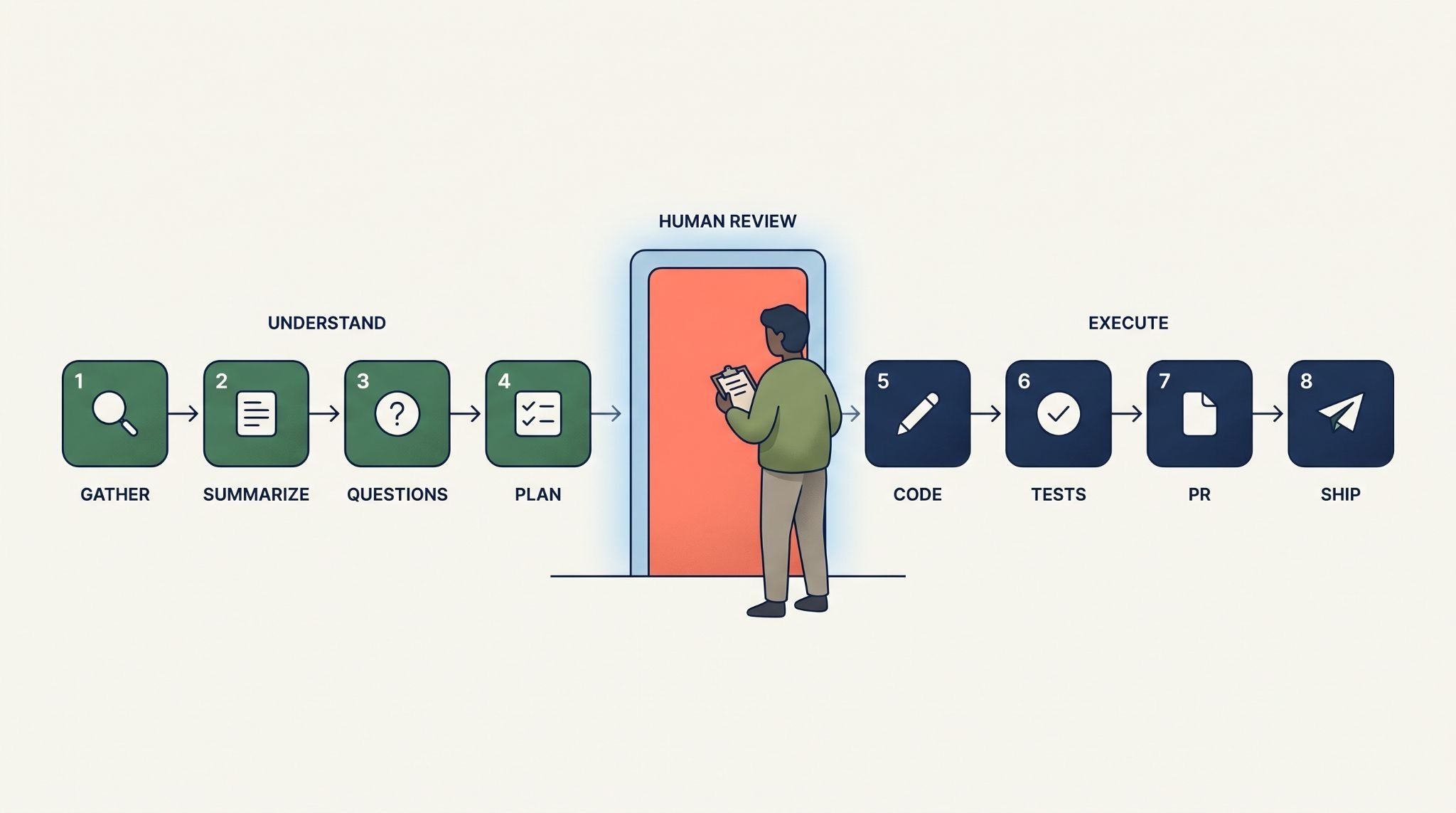
Three things make this hold up:
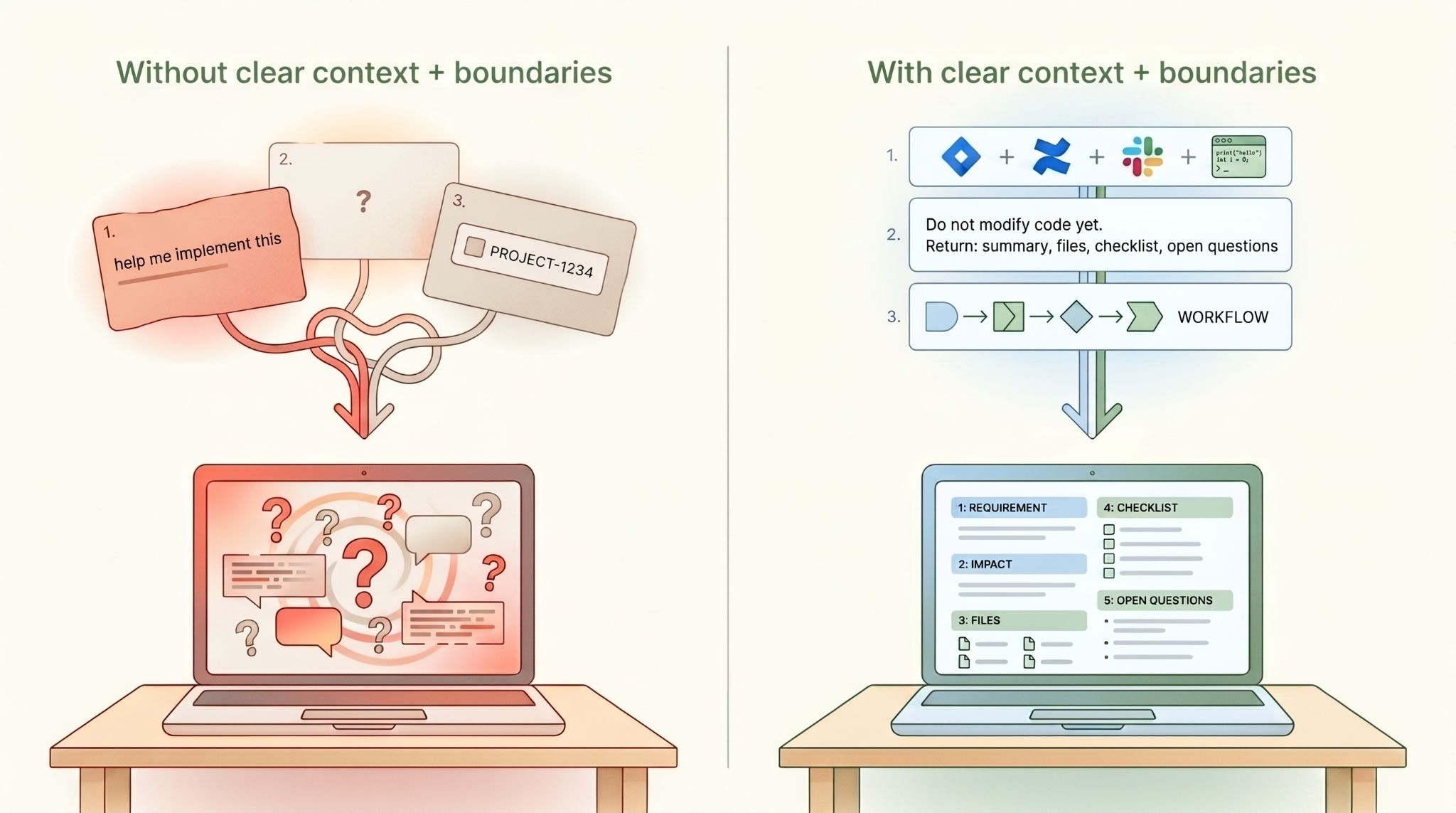
- Clear context. The agent knows where to look (Jira, Confluence, Slack, code) and what to return (the six headings in the prompt above). Vague instructions produce vague output.
- Boundaries. Do not modify code yet is one line that prevents most "the AI did too much" failures. In Claude Code, plan mode makes this enforcement structural, the agent literally can't write to files until you approve. The agent should know what it is allowed to change and what it should only inspect.
- Structured output. A fixed pattern makes the result easy to review. Summary, files, checklist, tests, and open questions should appear in the same order every time. This lets you scan the output quickly, catch missing context, and compare the plan against the actual requirement before approving the next step.
In Frontend work, most mistakes are not syntax mistakes, they are context mistakes. The component compiles. The UI renders. The test passes. But the behavior is wrong because the agent missed a business rule, ignored a design constraint, or misunderstood the user flow. Forcing understanding before execution is how you catch those at the effective possible moment.
This is why getting a deep understanding of how to construct your is the next important skill of frontend development. A single prompt helps you in a single task. A workflow helps you grab the full context of what needs to be done.
What can go wrong?
AI workflows give you real leverage. But they can also become messy if we are not careful. Common mistakes when we not yet fully understand how to apply it are:
Over-trusting confident output.
Even when the agent has access to the right tools, it can still misunderstand the requirement, miss an edge case, or make the wrong assumption. This is especially risky when the output looks confident. A clean implementation does not always mean a correct implementation. The developer always needs to be in the driver seat, don’t build up your comprehension debt too big.
Trying to automate everything at once
It is tempting to build one large workflow that reads the ticket, searches every system, modifies code, writes tests, creates a PR, and posts an update to Slack. But large workflows are harder to control. When something goes wrong, it becomes harder to understand which step failed. The rule of thumb is to separate the READ and WRITE operations. Do PLANNING first then EXECUTE after.
Forgetting that AI works best with constraints.
Without constraints, the agent may change too much, use the wrong pattern, or create code that does not match the existing architecture. The more specific the boundary, the safer the execution. The most effective workflows are not the most automated ones. They are the ones that are repeatable, reviewable, and aligned with how the team already works.
Workflow adoption and scaling: Real-world case studies
From plan to PR
Now, let’s use the workflow to generate everything from a Jira ticket to a pull request. The following is an example prompt for running the workflow.
- Read Jira ticket EXP-4513.
- Find related Confluence docs on filter rules and role-based visibility.
- Search Slack for recent decisions on this list page or filter behavior.
- Look for similar list/filter implementations in the codebase.
Do not modify code yet.
Return: requirement summary, frontend impact, files involved,
implementation checklist, test checklist, open questions.Output:
EXP-4513: Improve 'Live schedule' item - Requirements Analysis (Final)
1. Requirement Summary
Goal: Clarify the "Live schedule" field purpose based on live type to reduce user confusion.
Key Changes:
1. Create/Edit Live Video Form:
- Live stream: Hide the "Live schedule" field entirely
- Pre-recorded video: Show "Live schedule" with updated description text
- Update description: "Schedule a time for your pre-recorded video. It will start automatically at the scheduled time and can also be started manually".
2. Live Board Page:
- Live stream: Hide "Scheduled date" label and date in "Release" section for scheduled status
- Pre-recorded video: Show "Release" tab with scheduled date
- Only display scheduled date for pre-recorded videos; live stream shows live date only after going on-air
3. Live Videos List Page:
- Rename column from "Live date" to "Live status & Live date"
- Add info icon tooltip with explanations:
- Title: "Live date"
- Scheduled: "Scheduled time (Pre-recorded only)"
- On-air: "Actual live start time ~"
- Finished: "Actual live start time ~ end time"
- Hide scheduled dates for live stream broadcasts in Scheduled status
Frontend Impact
Behavior Changes:
- Conditional rendering based on broadcastType
- Scheduled date visibility rules differ by broadcast type and status
- UI text updates across 3 main areas
Data Requirements:
- broadcastType field must be available in all contexts
- scheduledLiveStartTime field
- broadcastStatus field
- No new backend fields required
UX Improvements:
- Clearer distinction between live stream and pre-recorded behavior
- Reduced confusion about when scheduled dates apply
- Better information architecture with tooltip guidance
Files Involved
Components to Modify:
1. Create/Edit Live Video Form:
- <project-root>/src/components/createEditLiveVideo/form/basicInformation/BasicInformationForm.tsx
- Conditional rendering of Live schedule field
2. Live Board Page:
- <project-root>/src/components/liveBoard/LiveBoardInformation/LiveBoardInformation.tsx
- Release section rendering logic
- Schedule date rendering function
...
...
...
Implementation Checklist
Phase 1: Pull Latest Translations
- Run the project translation sync command
- Verify required translation keys are available in message files
- If keys are missing, coordinate with design/PM team
Phase 2: Basic Information Form
- Add conditional rendering for Live schedule field based on broadcastType
- Show Live schedule only for pre-recorded videos
...
...
...
Unit Tests
Create/Edit form shows or hides schedule field based on broadcastType
Date display logic returns empty string for Live stream + Scheduled
Date display logic returns scheduledLiveStartTime for Pre-recorded + Scheduled
Tooltip content renders with correct translation keys
Integration Tests
Scenario 1: Create Live Stream
Live schedule field is not visible
Can create without setting schedule
Validation for schedule is skipped
Live Board Release section shows no scheduled date when status is Scheduled
List view shows blank date cell when status is Scheduled
After going On-air, date appears as actual live start time
Scenario 2: Create Pre-recorded Video
...
...
...
Browser/Device Tests
Chrome desktop
Firefox desktop
Safari desktop
Mobile responsive layout
Tooltip positioning correct on all screen sizes
Table column width adjusts properly with new header
Accessibility Tests
Tooltip accessible via keyboard
Screen reader announces column header text
Info icon has proper aria-label
Blank date cells do not cause screen reader issues
Open Questions
Existing Scheduled Live Streams:What happens to live stream broadcasts that already have scheduledLiveStartTime in the database?
Recommended approach: hide the date per new spec
Alternative: show with a deprecation notice
API Validation:Does the backend still accept scheduledLiveStartTime for live stream broadcasts?
If yes: add frontend validation to prevent it
If no: rely on backend validation
...
...
...After implementation is complete, you can create a PR using the same workflow.
From the code changes,
- reads the project's commit convention and PR template
- groups them into commits
- opens a draft PR linked back to the ticket
Here is an example output.
⏺ Bash(git add . && git commit -m "EXP-4513: Improve 'Live schedule' item ")
⎿ > example @1.2.0 pre-commit
Searched for 1 pattern, called github (ctrl+o to expand)
...
⏺ PR created: https://githum.com/org-example/example-project/pull/900
- Committed as EXP-4513: Improve 'Live schedule' item .
- Opened PR #900 against release/v1.2.0.
From Slack thread to plan
Once the basic loop of gathering context, returning a plan, reviewing it, and writing code reliably works, you can scale the workflow pattern. For example, the single source of truth for a feature may not be a Jira ticket or a Confluence page. Instead, it could be a Slack thread spanning two weeks with over 150 messages involving PMs, designers, backend engineers, QA, and other stakeholders. In those cases, when a ticket is assigned to you, no one can easily remember which decision was final, which proposal was discarded, or which questions remain unanswered.
You can handle this with the same workflow. Instead of scrolling back for 30 minutes yourself, assign the thread to the agent, set the same boundary ('do not modify code yet'), and ask it to return a structured plan.
<!-- this is just simple example, you should create commands or skill for those task also as a workflow -->
- Read Slack thread <link> in #live-platform from 2026-05-01 onwards (~180 messages, 9 participants).
- Cross-reference with Jira ticket GLPEX-4720 and any Figma frames linked in the thread.
- Look for similar implementations in the codebase.
Do not modify code yet.
Return: thread summary, confirmed decisions (with message timestamps),
rejected proposals, open questions, files likely involved, suggested implementation plan.
Here is an example output.
## Thread summary
Slack #example-project, 2026-05-01 → 2026-05-14, 184 messages, 9 participants.
Topic: rollout of "scheduled go-live reminders" for the Live module.
Started as a PM proposal, expanded into design / backend / frontend negotiation.
## Confirmed decisions (with message timestamps so you can verify)
- 2026-05-03 @taro.pm Reminders fire at 10 / 5 / 1 min before scheduled start.
Reconfirmed 2026-05-09.
- 2026-05-06 @yuki.design Use the existing toast component, not a modal. Figma frame linked.
- 2026-05-08 @minho.be Backend exposes `scheduledLiveStartTime` on /live/upcoming.
No new endpoint.
- 2026-05-12 @taro.pm Pre-recorded videos only. Live streams excluded from v1.
## Rejected proposals (kept here so they don't resurface in review)
- Push notifications via APNs rejected 2026-05-04 - out of scope for v1
- Separate "Reminders" tab in nav rejected 2026-05-07 - duplicates schedule view
## Open questions still unresolved in the thread
1. Timezone: viewer's local tz vs broadcaster's tz?
Last touched 2026-05-10 by @yuki.design as a question, never answered.
2. Dismiss behavior: does dismissing the 10-min reminder also suppress the 5-min and 1-min?
Mentioned twice, no decision recorded.
3. Reload behavior: should a dismissed reminder come back after page refresh?
## Files likely involved
- src/features/live/hooks/useUpcomingLiveReminders.ts ← new
- src/features/live/components/LiveReminderToast.tsx ← new
- src/components/ui/ToastStack.tsx ← reuse
- src/api/live.ts ← extend with /live/upcoming
## Suggested implementation plan (gated on the 3 open questions above)
- [ ] `useUpcomingLiveReminders(broadcastId)` hook subscribes to /live/upcoming on mount
- [ ] Schedule the 10 / 5 / 1 min reminders client-side, reuse <ToastStack />
- [ ] Dismiss state in sessionStorage (until Q3 is resolved)
- [ ] Gate the feature behind `broadcastType === 'pre-recorded'`
## Recommended next action
Don't start coding yet. Post the 3 open questions back into the thread, tag @taro.pm and
@yuki.design, and wait for explicit answers. The thread does not contain them - re-reading
won't help.The method works well despite the noisy 184-message input for two reasons:
- It separates confirmed decisions from items still under discussion. Threads become so long that someone new can't easily re-read everything. The agent organizes them once and cites timestamps so any line can be verified within 10 seconds.
- It doesn't make up answers. Unresolved parts of the thread are presented as-is and returned to people; don't invent plausible guesses that turn into bugs weeks later.
This pattern is the same as the "From plan to PR" pattern discussed earlier: read first, then structure and reveal missing items, but don't change code yet. The input source has merely shifted from a single ticket to a long Slack thread with many stakeholders; the core workflow remains the same.
Conclusion
Frontend development is where product intent, design decisions, business rules, backend contracts, user feedback, and code all meet. This is where AI can elevate our role.
The skill that will become important for frontend engineers is not just writing prompts but context engineering: knowing what information matters, where to find it, how to structure it, and how to guide AI safely.
Therefore, the goal is not to automate judgment. The goal is to build workflows that make judgment easier to understand and apply.
With AI, a frontend engineer who handles context well will do more than just work faster — they will make the whole system work better.

Tech-Verse 2026 to Be Held on June 29

This article has been published as the official article for the event.
Tech-Verse 2026 is a technology conference hosted by LY Corporation.
Explore cutting-edge challenges and real-world insights.
Be sure to watch the event live on YouTube LIVE.
https://tech-verse.lycorp.co.jp/2026/en/


