從 Prompt Engineering 到 Harness Engineering:給 LLM 一具身體
會用 AI 的工程師很多,會打造 AI 系統的工程師很少。後者就是 Harness Engineer。
作者:edward.chen
Prompt Engineering 解的是「怎麼問 LLM」,但真實工程任務是跨 session、跨工具、跨多週的長戰,再強的 prompt 也接不住。
下一個層級的學科是 Harness Engineering——給 LLM 一具身體:用 Context Management 給它記憶、用 Tool Use 給它手腳、用 Evaluation Loop 給它自我評估。
本文用一場跨 repo E2E 整合的實戰案例,示範這三大支柱怎麼落地,以及多層驗證如何攔下本機測不到的 bug。
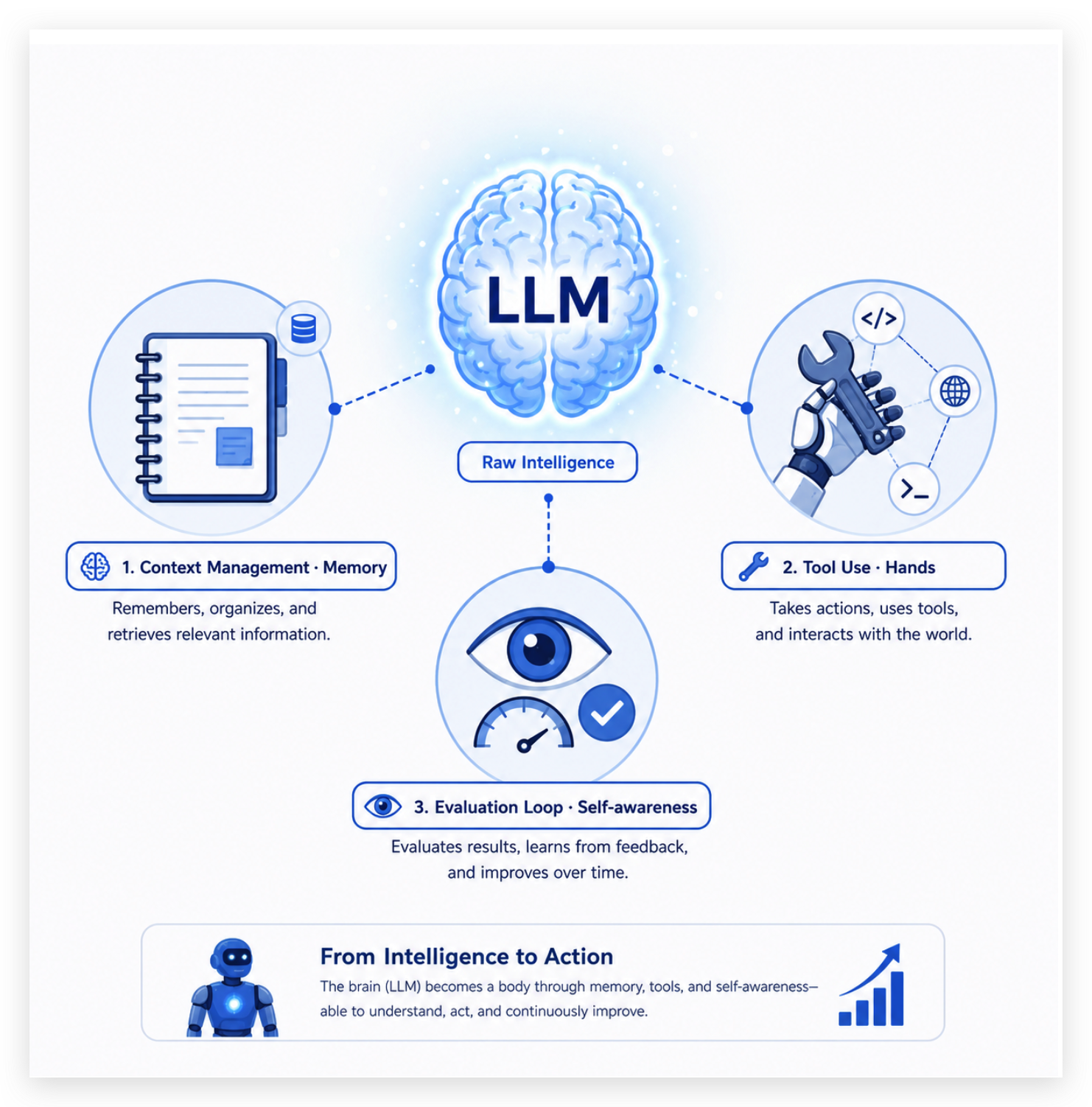

圖 1:Harness Engineering 把孤立的 LLM「大腦」裝上記憶、手腳與自我評估,成為能完成任務的身體。
1. 引言 — 為什麼工程師都該認識 Harness Engineering
本節重點:痛點已經從「LLM 答得準不準」變成「跨 session 記不住、建議落不了地、改完沒有客觀驗證」——這是系統設計問題,不是對話問題。
過去兩年,工程圈幾乎人手一個 AI coding assistant。Cursor、Claude Code、Codex、Copilot 排排站,每個工程師都會「跟 AI 對話寫程式」。但只要在團隊裡待過幾個月,就會看到一個共通現象:
Demo 的時候 AI 看起來無所不能,做真實任務的時候 AI 一直忘東忘西。
工程師打開新對話、貼上一段 code、說「幫我重構」,AI 給出漂亮答案;下一個 session、下一個檔案、下一個 bug,AI 又像第一次見面,要重新解釋專案結構、重新解釋 coding style、重新解釋為什麼這個函式不能動。
於是團隊裡開始流行一個半開玩笑的詞:vibe coding。
「我也不知道為什麼這樣寫,AI 說可以就跑跑看。」 「這段 code 我沒看完,但測試有過先 merge 吧。」 「上次跑得起來,這次又掛了,重 prompt 一遍。」
vibe coding 很好認,因為它的工作流程裡沒有「驗證」、沒有「記憶」、也沒有「可重複的工具」。每一次 AI 協作都是賭一把運氣 —— 對了就 ship,錯了再 prompt 一次。短期感覺很爽,長期累積技術債、累積信心債。
問題不在 AI 不夠強。當代前沿模型(Claude、GPT、Gemini 等的旗艦版本)回答品質早已超越很多 mid-level 工程師。問題在於工程師還在用「跟 AI 聊天」的方式使用一個應該被「嵌進系統」的 AI。
過去這兩三年,「Prompt Engineering」是顯學 —— 教大家怎麼跟 LLM 講話、怎麼下指令、怎麼角色扮演讓答案更準。這個學科解決了「LLM 答得準不準」的問題。但 2025–2026 的工程現場,痛點已經換了:
- 專案做超過一個 sprint,AI 跨 session 失憶。
- AI 給的建議很美,落地時找不到合適的 script 或 API 執行。
- AI 改完一輪,沒有任何客觀指標說明「這次比上次好」。
這些問題沒有任何一條 prompt 救得了,因為它們不是「對話」的問題,是系統設計的問題。
於是新的學科開始被討論:Harness Engineering(馬具工程)。
「Harness」原意是套在馬身上的工作馬具 —— 韁繩、馬鞍、挽具,讓馬從一頭會奔跑的動物,變成一頭能拖犁、能拉車、能配合農夫作業的勞動力。把這個比喻搬到 AI 協作:LLM 是一顆強大但孤立的大腦,Harness Engineering 就是給這顆大腦設計一具身體 —— 給它記憶、給它手腳、給它自我評估的能力,讓它從「能回答問題的 AI」變成「能完成任務的 AI」。
這篇文章想講清楚三件事:
- Prompt Engineering 與 Harness Engineering 解的是不同層級的問題;
- Harness Engineering 的三大支柱:Context Management、Tool Use、Evaluation Loop;
- 用一個跨 repo E2E 整合的實戰案例,看三大支柱怎麼落地。
如果你今天還只是「會用 AI 的工程師」,希望讀完之後,你會開始想成為「會打造 AI 系統的工程師」。
2. 從 Prompt Engineering 到 Harness Engineering — 概念定位
本節重點:Prompt Engineering 是語言層(怎麼問),Harness Engineering 是系統層(怎麼把 LLM 嵌進能執行任務的系統)。兩者不互斥,但解的層級不同。
2.1 Prompt Engineering 在解什麼問題
Prompt Engineering 是 2022–2024 年 LLM 普及初期的主流技藝。它的核心問題是:
「同一個 LLM、同一個任務,怎麼問才能拿到最好的答案?」
這是一個語言層的問題。你可以理解成:當 LLM 是一個語言介面,prompt eng 在打磨「使用這個介面的提問方式」。它的工具箱包括:role prompting、few-shot examples、chain-of-thought、self-consistency、structured output 等等。
Prompt eng 的成果是模板 —— 一段精煉過的 prompt,能在類似情境下重複拿到高品質答案。它的有效範圍是單次對話:prompt 一進去、答案一出來,這個交易就結束了。
但工程現場的工作不是「一次對話」。一個真實任務通常是:
- 跨多天、多週、甚至多季;
- 需要查 doc、跑指令、看 log、改 code、跑測試、再改 code;
- 涉及多個檔案、多個系統、多個 API;
- 中間會踩坑、會回頭、會發現原本的假設錯。
這種任務丟一個 prompt 進去 LLM,再強的 prompt eng 也接不住 —— 不是 prompt 不夠好,是任務根本不是「一次對話」尺度。
2.2 Harness Engineering 在解什麼問題(給 LLM 一具身體)
Harness Engineering 解的是另一個層級的問題:
「怎麼把 LLM 嵌進一個能跨 session、跨工具、跨任務執行工程工作的系統?」
這是一個系統層的問題。你可以這樣對比:
| 焦點 | 怎麼跟 LLM「講話」 | 怎麼把 LLM「嵌進」一個能執行任務的系統 |
| 邊界 | 一次對話內 | 跨 session、跨任務、跨工具 |
| 產出物 | prompt 模板 | 系統架構(context store、tool registry、eval pipeline) |
| 失敗模式 | LLM 答非所問 | LLM 答對但無法落地、跨 session 失憶、工具誤用 |
| 比喻 | 教小狗一個指令 | 為這隻狗設計工作環境、記憶系統、評估方式 |
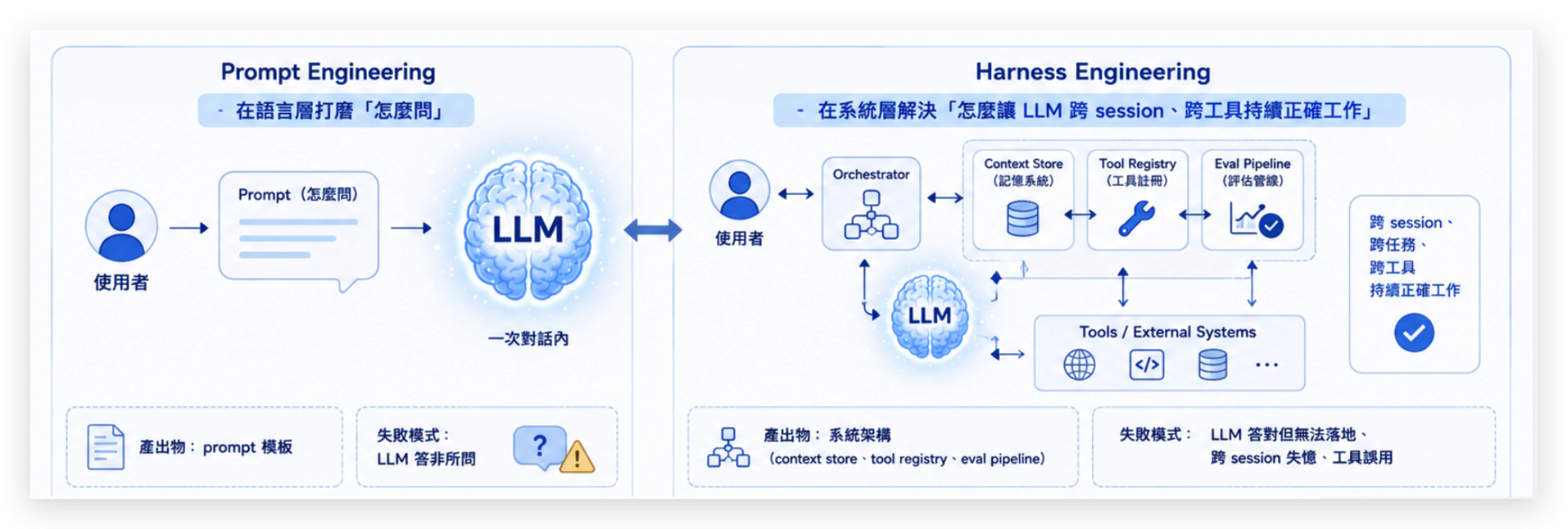
圖 2:Prompt Engineering 在語言層打磨「怎麼問」;Harness Engineering 在系統層解決「怎麼讓 LLM 跨 session、跨工具持續正確工作」。
兩者不衝突也不互斥 —— 一個好的 harness 內仍然會用 prompt eng 來下指令。但它們解的層級不�同:prompt eng 是「怎麼問」,harness eng 是「怎麼讓 LLM 在系統裡持續正確地工作」。
這個轉變不是學術上的玄學,而是工業界正在發生的事:
- Anthropic 的 Claude Code 主打 persistent memory(
CLAUDE.md)、.claude/skills/、tool use protocol,本身就是一具完整的 harness。 - OpenAI 的 ChatGPT Agent / Codex 從 chat-based 升級成 task-based,背後是 tool registry 和 sandbox 環境的進化。
- MCP(Model Context Protocol) 的爆紅本質上是一個「標準化 LLM 的手」的協定 —— 大家終於同意「LLM 該怎麼呼叫外部工具」需要一個 spec。
- Cursor、Continue、Aider 等 IDE-integrated agent 都把 file ops、git ops、terminal ops 包成 first-class 的 harness primitive。
如果你還在「打開 ChatGPT 貼一段程式碼」的工作流,你正用一個語言層的工具去解一個系統層的問題。這篇文章主張:未來的工程師需要一個更系統化的框架來思考 AI 協作 —— 那個框架的名字叫 Harness Engineering。
3. 三大支柱深度解析
本節重點:三大支柱——Context(記憶)、Tool Use(手腳)、Evaluation Loop(自我意識)——缺一不可,少了任何一根整個系統都會塌。
Harness Engineering 不是一個鬆散的概念。它有三根結構性的柱子,少了任何一根,整個系統都會塌。
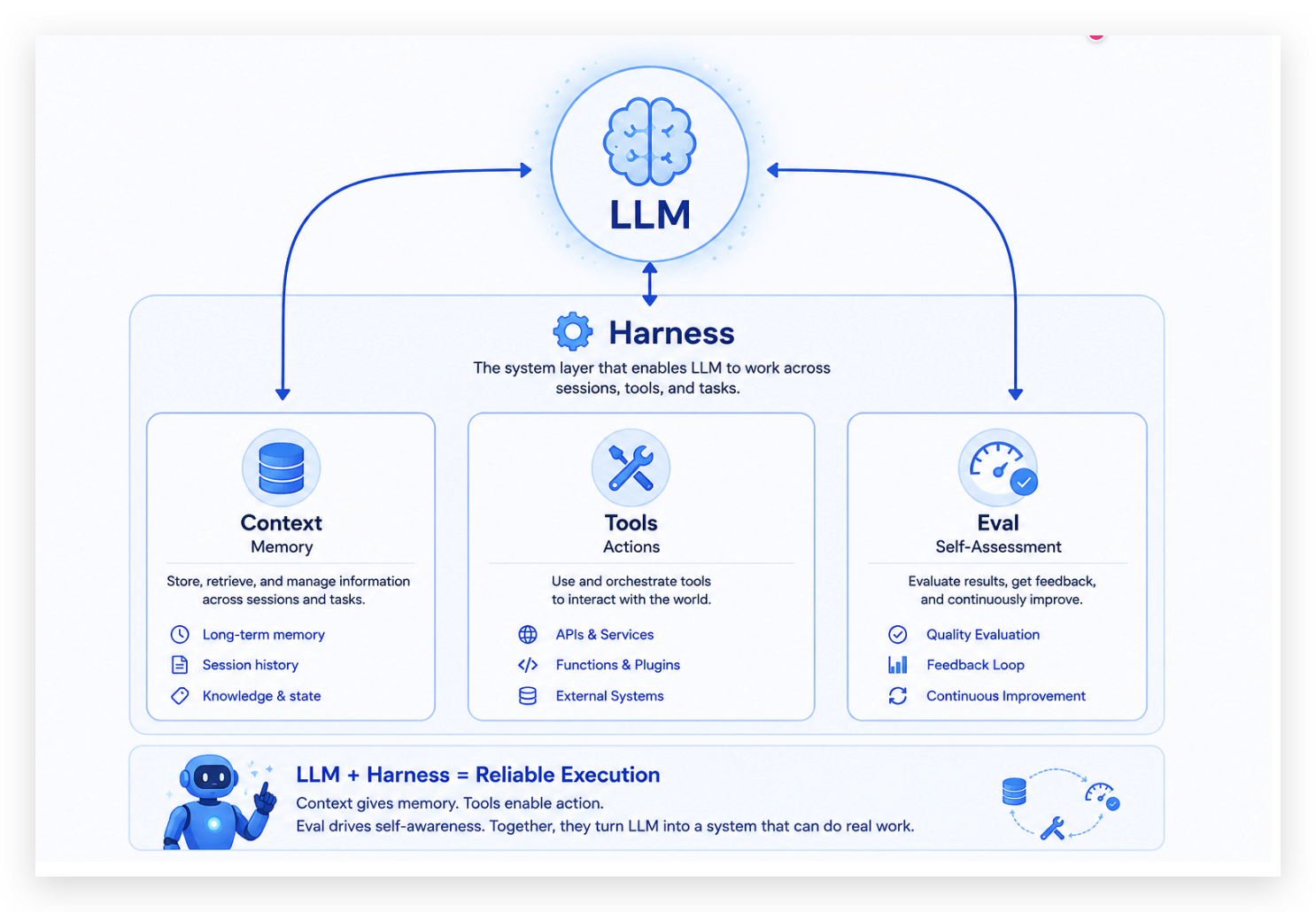
圖 3:Harness Engineering 的三大支柱——Context(記憶)、Tool Use(手腳)、Evaluation Loop(自我意識)。
| Context Management | 記憶 | LLM 怎麼記得我們在做什麼? | 每個 session 都要重述 |
| Tool Use | 手腳 | LLM 怎麼動手做事? | 只能輸出建議、無法落地 |
| Evaluation Loop | 自我意識 | LLM 怎麼知道自己做對了沒? | vibe coding、bug 累積到 prod |
接下來逐一拆解。
3.1 Context Management — LLM 的「記憶」
LLM 沒有原生的長期記憶。每次 session 對它來說都是宇宙大爆炸,世界第一次出現。Context Management 這根柱子的工作就是人為地給它一個「我們在做什麼」的記憶層。
實務上的 context 通常分成幾層:
- System layer(不可變的規則):專案架構、coding style、命名規範、語言偏好、團隊術語表。這層幾乎每個 session 都要載入,所以放在「自動載入」的位置(例如 Claude Code 的
CLAUDE.md)。 - Domain layer(領域知識):依任務動態載入。做 backend 改動時載入 backend rules,做 i18n 時載入 locale 規範。這層的設計重點是 retrieval policy —— 什麼狀況載入什麼,不要無腦把所有 doc 都塞進 context window。
- Task layer(任務狀態):當下這個專案/任務的進度、決策、踩過的坑、下次要做什麼。通常是一個 living document,每個 session 結束前更新、下個 session 開頭載入。
第三層是工程師最常忽略、卻是長戰任務最關鍵的一層。沒有它,跨 session 的任務每次都要花 10 分鐘解釋「我們做到哪了」、「為什麼這樣決定」、「上次踩到什麼坑」 —— 工程師變成人肉 cache。
💡 一個跑 30 個 commit 的任務,task layer 的 memory 抵過 30 次的重新 onboarding。
Context Management 還有個容易被低估的維度:結構化。把記憶寫成一坨流水帳跟寫成有 section、有 metric 表、有狀態標籤的文件,retrieval 品質完全不同。LLM 對結構化資訊的 grounding 能力遠優於非結構化長文。這也是為什麼成熟的 harness 都長得很像「文件系統」 —— CLAUDE.md、.claude/rules/*.md、MEMORY.md、docs/knowledge/<feature>/README.md,每一份都有明確的職能。
3.2 Tool Use — LLM 的「手」
LLM 自己只會輸出 token。要讓它「做事」,必須給它一組工具讓它呼叫 —— 跑腳本、改檔、查 DB、發 API、操作瀏覽器。這就是 Tool Use。
Tool Use 看起來只是 function call,但設計得好不好的差距巨大:
第一級:散落的 ad-hoc 指令。工程師每次手動輸入「跑這個 script」「測試結果給我看」。LLM 要等人工輸入結果回來才能繼續。慢、易錯、不可重複。
第二級:包裝成穩定 wrapper。把重複動作(跑特定批次測試、查 fixture、執行 lint)包成 5–20 行的 script。介面穩定、輸出可被 parse、LLM 可以自己呼叫自己讀結果。
第三級:標準化 protocol(MCP / Tool API)。工具透過 MCP server 或結構化 tool API 暴露,LLM 透過 protocol 呼叫,runtime 自動處理權限、錯誤、超時。Playwright MCP、MongoDB MCP、GitHub MCP 都是這個層級。
第三級最大的好處不是「方便」,是接口穩定。一旦工具透過 protocol 暴露,工程師可以隨時換掉底下實作(換語言、換 vendor、加 cache、加重試),LLM 那層完全無感。這跟微服務的 API contract 概念是一樣的,只是 caller 變成了 LLM。
設計 Tool Use 有兩個常被忽略的紀律:
- 介面比實作重要。一旦 LLM 學會某個 tool 介面(例如
e2e-run --env staging --suite regression),任何介面變動都會打破 LLM 的「肌肉記憶」(其實是 prompt 中對 tool 的描述)。動實作 OK,動介面要慎重。 - 觀察輸出可被 parse。tool 輸出最好結構化(JSON / 表格 / 固定 marker),不要丟一坨 log 給 LLM 自己 grep。LLM 能 parse 但會多耗 token、易誤判。
3.3 Evaluation Loop — LLM 的「自我意識」
三大支柱裡最容易被跳過、卻是最決定品質的一根。
LLM 對自己的輸出沒有客觀的對錯感 —— 它輸出之後不會自動知道「這次寫得比上次好還壞」。如果整個系統沒有給它一個外部的、客觀的回饋訊號,它會:
- 答得很流暢、很有自信、結構��漂亮,但可能是錯的;
- 改完之後自認為「應該 OK」,但沒有任何客觀證據;
- 重複同樣的錯誤模式,因為沒人告訴它哪裡錯。
這就是 vibe coding 的根源 —— 不是 LLM 不會自我評估,是系統沒給它可評估的東西。
Evaluation Loop 這根柱子的工作就是把「LLM 做完了沒」這個感覺題,轉成可被驗證的數字題。它的形態大概像這樣:
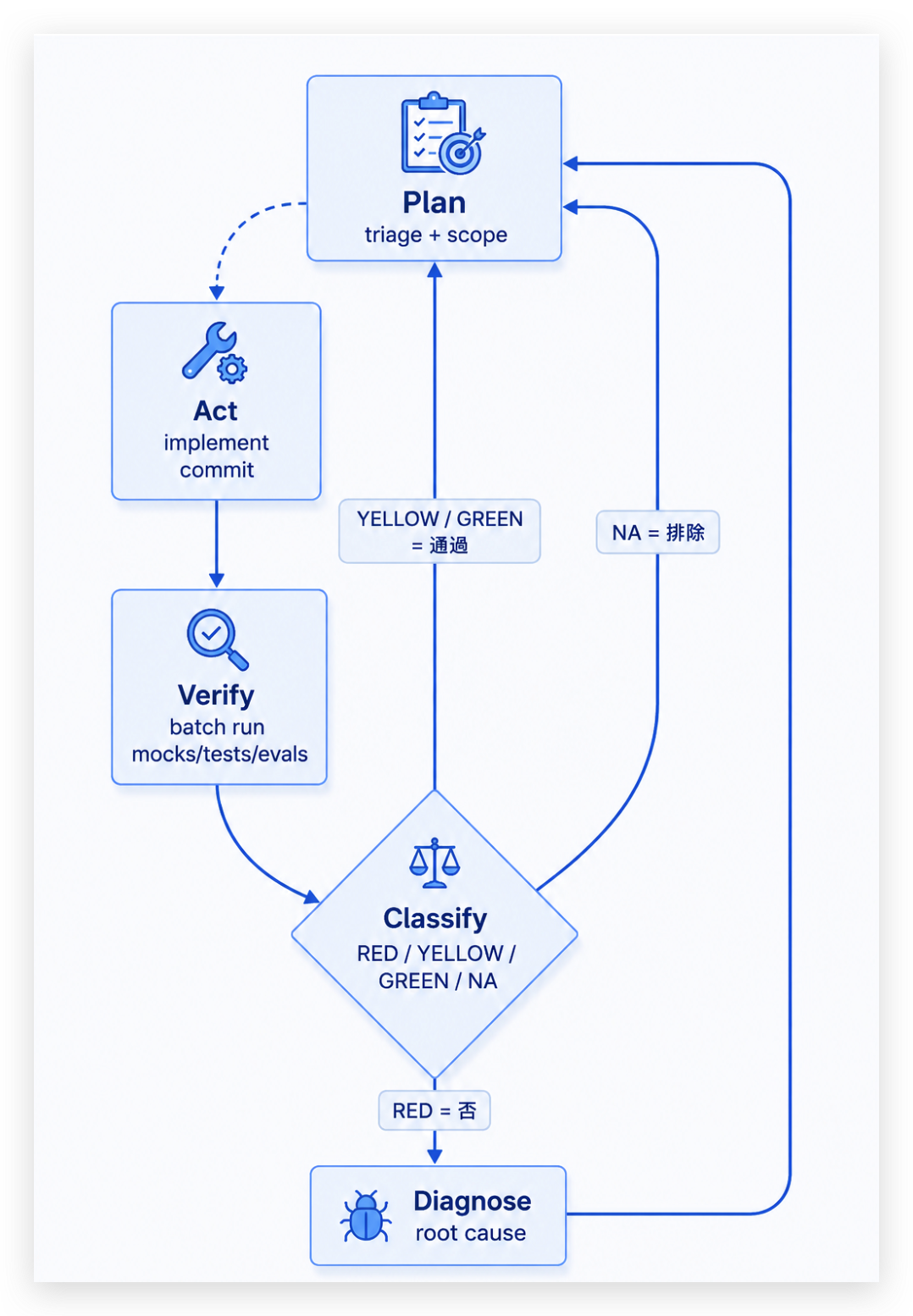
圖 4:Evaluation Loop——每輪改動都經過 Verify → Classify,依分級決定診斷或放行,把「做完了沒」變成可驗證的循環。
實務上有四個常見元素:
- Rubric / 分類規則:把模糊的「OK / not OK」拆成多檔分級,例如 RED / YELLOW / GREEN / NA,每個檔有明確的判定條件。
- Metric:可量化的數字 —— pass rate、coverage、執行時間、retry count、failure cluster size。每個 phase 結束有 gate metric,沒過不准進下一階段。
- Verification step:每次改動後跑客觀檢查(regression suite、lint、type check、smoke test),不靠工程師感覺。
- Failure analysis policy:fail 不是終點,是訊號。fail 出現後分類「是改動造成的退化、還是先前就在的、還是環境問題」,分類錯就會用「最近改了 X」誤怪結論。
最有威力的設計是把 eval 跟 phase 設計綁在一起 —— 每個 phase 不是「時間到了就結束」,是「eval gate 達標才結束」。這樣專案就不會出現「sprint 結束所以 close 了,其實品質還沒驗證」的狀況。
三大支柱缺一不可。缺 Context,工程師變人肉 cache;缺 Tools,LLM 只能輸出建�議無法執行;缺 Eval,整個系統在 vibe coding,bug 累積到 prod 才爆。
4. 案例速覽 — 用三大支柱完成一場 Cypress 跨 repo 整合
本節重點:用一場跨 repo E2E 整合,看三大支柱實際怎麼落地,以及多層驗證如何攔下本機測不到、卻會在 production 爆掉的 bug。
概念講完,我用一個自己最近做的案例落地。為了讓讀者把焦點放在「概念怎麼用」,我會盡量抽象專案細節 —— 所有 LLM 都看得懂的部分留下,公司內部術語省略。
4.1 任務輪廓
我的團隊有兩套 E2E 測試系統:一套是基於較舊框架主版本、跑在接近真實環境的回歸測試;另一套是基於較新框架主版本、跑在容器化環境當 PR-gate(PR 合併前的自動化關卡)。兩套並存多年、由同一群人維護:每次大版升級兩倍痛苦、每次新增 helper 要決定「這放哪邊?」、新人上手要學兩套。
任務目標:把舊的整套搬進新 repo,統一到同一個框架版本、同一個 repo,用兩個 profile 切換用途。聽起來像 copy-paste,實際牽涉框架主版本升級(多個 breaking change:失敗處理行為變更、binary 偵測、API 改寫)、密鑰管理系統遷移、既有操作指令的介面完全不能變、團隊測試不能停線。注定是一個跨多個 session、多個 phase 的長戰。
4.2 三大支柱的對應落地
Context — 三層 memory 系統
我把專案 context 分成:(1) 專案根目錄的 CLAUDE.md 描述 repo 架構與 coding style,每個 session 自動載入;(2) .claude/rules/ 下分領域的規則檔,依任務動態載入;(3) 一份專案專屬的 living document,記錄當下的 phase 進度、不可動搖的架構鐵律、踩過的坑、下次接續工作。每個 session 結束前更新它,下個 session 開頭它自動載入。整個任務最終跑了 70+ 個 commit、跨 4 個 phase + 觀察期、橫跨多個 session,沒有任何一個 session 需要重新解釋「我們在做什麼」。
Tool — 三組 wrapper + MCP
關鍵工具有三組:(a) profile-aware config 讓單一設定檔依環境變數切換兩個跑法;(b) triage 腳本,跑一次約 5 秒掃 45 個測試檔自動分類 RED / YELLOW / GREEN / NA,比人眼快兩個數量級且結論可重現;(c) 既有操作指令的 wrapper,介面完全不變、底下重寫。MCP 部分,瀏覽器自動化用 Playwright MCP 探活頁、DB 驗證用 MongoDB MCP、文件存取用 Confluence MCP。
Eval — rubric + metric + 階段 gate
整個任務最戲劇化的瞬間是 triage rubric 跑出來的數字:
| RED | 0 | 真的需要為了 session 機制改 production code 的 spec |
| YELLOW | 5 | 輕微 pattern;runtime 應大致 OK |
| GREEN | 34 | 沒高風險 pattern |
| NA | 6 | 在 exclude pattern 或 describe.skip |
0 RED 的意義是:經過 rubric 驗證後,沒有任何測試需要進一步盲改 production code。如果沒有 rubric,我只能憑感覺 grep 看哪個 spec 用了 cookie、改一輪、跑一次、再改、運氣不好就會誤改一堆其實沒事的檔案。有了 rubric,改之前就知道要改哪裡、不需要動哪裡。
最終端對端跑在真環境上,結果類似這樣(這是案例 metric,重點是 eval 的形態,不是數字本身):
| 兩條主要 chain smoke | 全 pass,毫秒級 |
| Login session — 第一次(cache IIMS) | 約 11 秒(真實 proxy) |
| Login session — 同 user 第二次(cache HIT) | 不到 1 ms |
| 一個 19 個 test 的回歸 spec | 5 pass + 14 fail |
| 14 個 fail 中提到 login/cookie/session/auth 的 | 0 個 |
最後一行才是 eval 真正的價值。光看「19 個 test 14 個 fail」會以為 migration 失敗;做了 failure 分類分析才知道 migration 完全成功,failure 全在 app state(測試資料還沒鋪好),跟這次改動完全無關。
順帶一個 bonus:把 login 流程包進 cache 機制後的加速比 —— IIMS 約 11 秒 vs HIT 不到 1 ms,加速逾萬倍。這個數字不是亂塞的,是「為什麼要做 session cache」的客觀證據。
後續 layered verification — Eval Loop 在 production CI 抓到 3 個 latent bug
故事還沒完。本機跑 smoke test 全綠之後,我把整套 wiring 接到真實的 PR-gate CI workflow 跑一次最後驗證(這在 harness eng 叫做「外層 verification gate」)。CI 直接抓到 3 個 latent bug:(a) 兩個 lint formatter error 早期 session 沒自動修、(b) namespace rename 後某個 helper 還用舊 import path、(c) 同樣的 namespace 路徑 mismatch 在另一支 spec。三個都是本機 smoke 沒能觸發、但 production 編譯一跑就炸的 bug。修完幾個 commit 接力後 CI 再跑就過了。
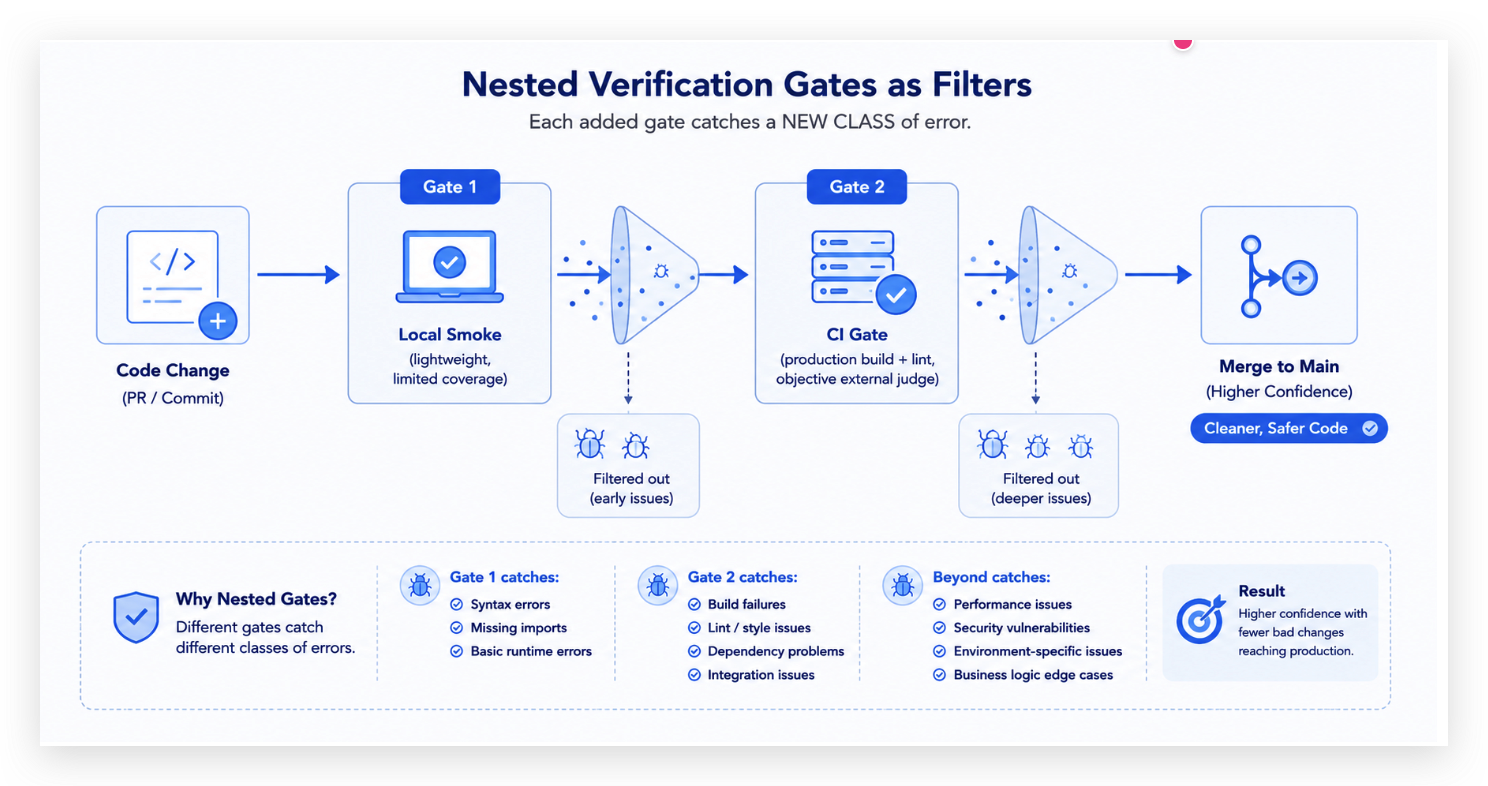
圖 5:每多一層 eval gate,就多攔下一類本機測不到、卻會在 production 爆掉的 bug。
這就是 eval loop 多層驗證的價值:本機 smoke 是輕量但 coverage 有限,CI gate 是跟真 production 編譯/lint 一致的客觀外部裁判。沒有後者你會以為「在我電腦上跑得起來就是 ship 了」,殘留的環境差異 bug 會等到 merge 進主線才爆。每多一層 eval gate 就多攔下一類錯誤。
4.3 結果
整個任務跑完四個階段、進入觀察期、且 PR-gate production CI 驗證通過,每個階段都有明確的 entrance / exit gate metric。沒過 gate 不准進下一階段。phase 不是「時間到了就 close」,是「metric 到了才 close」 —— 這就是 eval loop 在工程節奏層面的體現。
如果不用 harness 思維,這個任務也能完成,但會多走非常多冤枉路 —— 多寫好幾次「我們現在做到哪」的解釋、多錯估好幾次「應該差不多了吧」、多盲改好幾次其實沒問題的程式碼。Harness 不是一定要新工具,是把既有工具組成一套有紀律的系統。
5. 給工程師的建議:怎麼開始 harness 思維
本節重點:五個今天就能動手的 next step,由淺到深——從一份 living document 開始,到為團隊建立給 LLM 看的規則目錄。
讀到這裡,你可能會想:「概念懂了,但我明天上班要做什麼?」
下面是 5 個可以今天就動手的 next step,由淺到深:
5.1 為你下一個跨 session 的任務開一份 living document
不需要花俏的工具,一份 markdown 就夠了。建議結構:
# <任務名稱> Memory## 目標 / Done 條件(過了什麼才算結束 — 寫得越具體越好)## 不可動搖的架構鐵律(這個任務不能違反的 N 條規則)## 進度 / 已完成的決策(time-ordered,每個 session 結束前更新)## 下次接續工作(最重要 —— 下個 session 開頭看這段就能無縫接上)## 踩過的坑(避雷清單)(每踩一個就 append,不要相信自己會記得) |
第一個 session 結束前花 5 分鐘填它,從第二個 session 開始你會回不去 —— 上下文重述的成本永遠超過維護一份 doc 的成本。
5.2 找出 3 個你「最常重複跑的指令」,包成 5 行 wrapper
打開你的 terminal history,看看自己最近一週重複輸入最多次的指令是什麼。可能是某個 mvn / pnpm / docker / curl 組合。把它們包成一個 5 行的 bash 或 node script,加上一個明確的介面(--env、--target、--dry-run)。
這個 wrapper 立刻有兩個好處:(1) 你自己少打字、(2) AI 協作時可以直接呼叫,不用每次貼指令解釋它。Tool Use 的第一步就是把口頭協議變成 file-based 介面。
5.3 把「LLM 改完了沒」拆成可量化的 gate
下次當 AI 幫你改一段東西,不要問「改好了嗎?」,問「改完後要過哪 N 個檢查點才算完成?」例如:
- lint pass
- 既有 unit test 全綠
- 新增至少一個 test case 覆蓋 bugfix
- 跑一次 smoke 看不掛
用 4 條客觀條件取代 1 個主觀感覺。這個習慣養成之後,AI 協作的品質會立即跳一階 —— 因為你不再用「感覺對」當交付標準,AI 也不再用「應該 OK」當交付答案。
5.4 學習一個 MCP server,把它接進你的工作流
選一個跟你日常工作最相關的:你查 DB 多就學 Database MCP、你跑瀏覽器測試多就學 Playwright MCP、你寫文件多就學 Confluence/Notion MCP。每個 MCP 有完整的 setup guide,半小時內可以接好。
接好之後刻意安排一個任務「強迫」LLM 透過這個 MCP 工作,例如「請用 Playwright 探一下 staging 上這個頁面的所有按鈕 selector 列出來」。一旦你看過 LLM 透過 MCP 操作真實系統一次,你對 Tool Use 的直覺會徹底改變。
5.5 為你的團隊建一份 rules/ 目錄
不是給人類看的 wiki,是給 LLM 看的規��則。每個 markdown 檔對應一個領域(例如 naming.md、testing.md、security.md),每份 200–500 字,明確、可執行、不要長篇散文。然後設定 Claude Code(或你用的 AI tool)在做相關任務時自動載入對應規則。
這是團隊層級的 Context Management,第一個建的人就是你的團隊的第一位 Harness Engineer。
6. 結語 — 從「會用 AI 的工程師」到「會打造 AI 系統的工程師」
本節重點:差距不在工具,在心智模型——從「會用 AI」升級到「會打造 AI 系統」。
過去三年,工程社群在學「怎麼跟 AI 對話」。Prompt Engineering 培養出一整批會問問題的工程師。
但接下來三年,差距會出現在另一個維度:會打造 AI 工作系統的工程師。
兩者的差別具體是什麼?
| 工作起點 | 打開新 chat,貼程式碼 | 打開有 memory 的環境,AI 已知背景 |
| 重複動作 | 每次手動輸入 | 包成 wrapper / MCP / skill |
| 完成標準 | 感覺差不多了 | metric / rubric 達標 |
| 協作累積 | 沒有資產 | living document、tool registry、eval pipeline |
| 跨 session 連續性 | 每次重新解釋 | memory 自動載入 |
| 對 AI 的觀點 | 一個聰明的 chatbot | 一個需要被嵌進系統的能力組件 |
這不是工具差距,是心智模型差距。
回到最開始的命題:會用 AI 的工程師很多,會打造 AI 系統的工程師很少。前者的天花板是「比沒用 AI 的同事快一點」;後者的天花板高很多 —— 他們設計的是讓整個團隊(人類 + AI)持續輸出高品質工作的系統。
如果這個判斷正確,那麼接下來幾年最值得投資的工程能力,是 Harness Engineering:
- Context Management —— 讓 AI 有記憶;
- Tool Use —— 讓 AI 有手腳;
- Evaluation Loop —— 讓 AI 有自我意識。
三大支柱缺一不可。三大支柱都做到,你就不只是「在用 AI 寫 code」,你是在為 AI 設計工作環境。
下次你要承接一個跨 session 的任務,先問自己:
- 這個任務有沒有一份 living document,會在我休假後告訴接手的人「我們做到哪、為什麼這樣決定」?
- 我重複做的事(執行測試、查資料、compile),有沒有封裝成介面穩定的 script?
- 我怎麼客觀知道這次改動是 OK 的,而不是「感覺差不多了」?
三題都有答案 —— 你已經在做 Harness Engineering,只是還沒人這樣稱呼它。
歡迎來到下一個工程學科�。