問題背景
LINE Travel 提供了多個線上訂房平台(OTA, Online Travel Agency)的飯店資訊,讓使用者可以直接透過單一介面來同時搜尋想要的飯店並直接在上面比價。
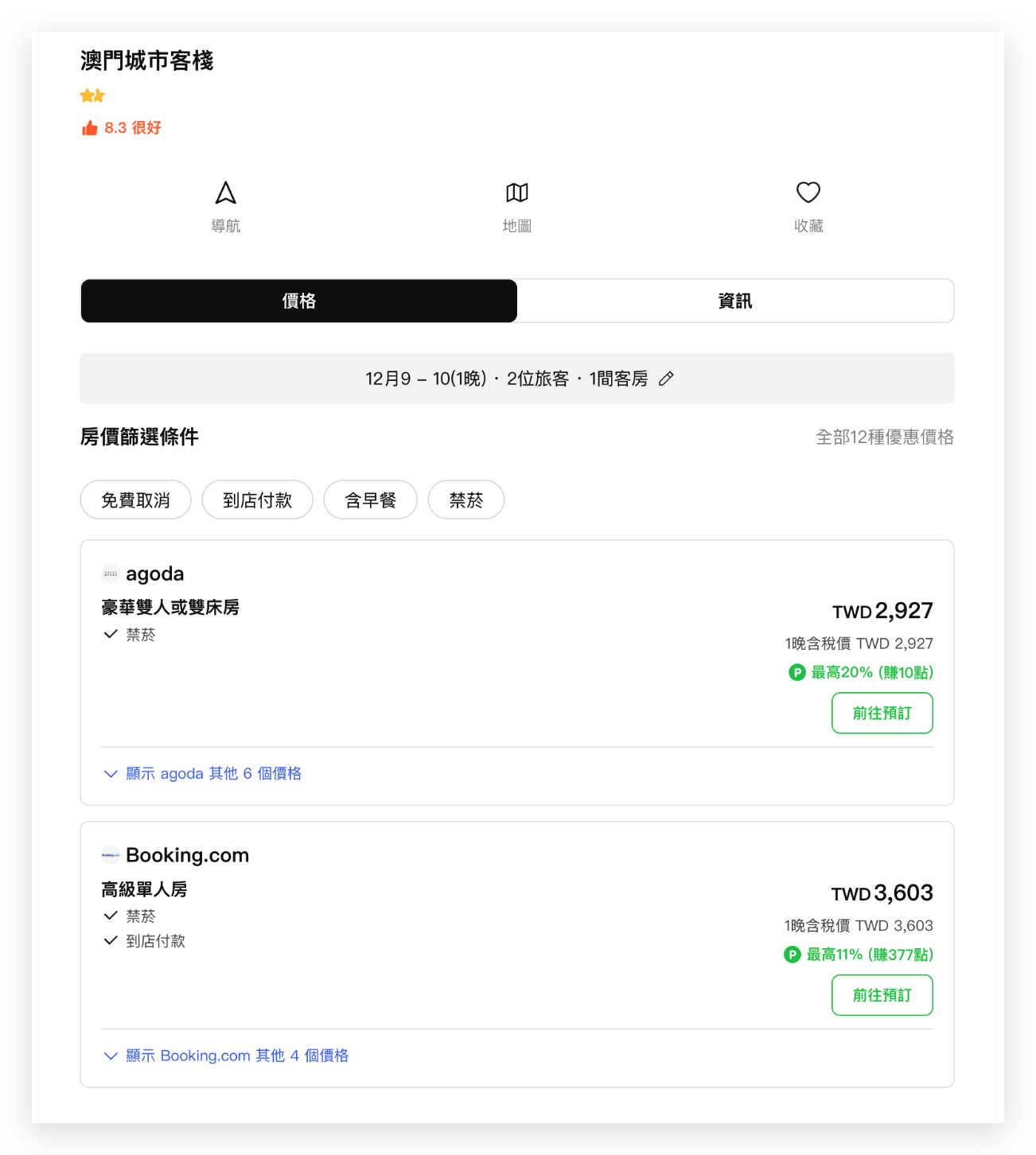
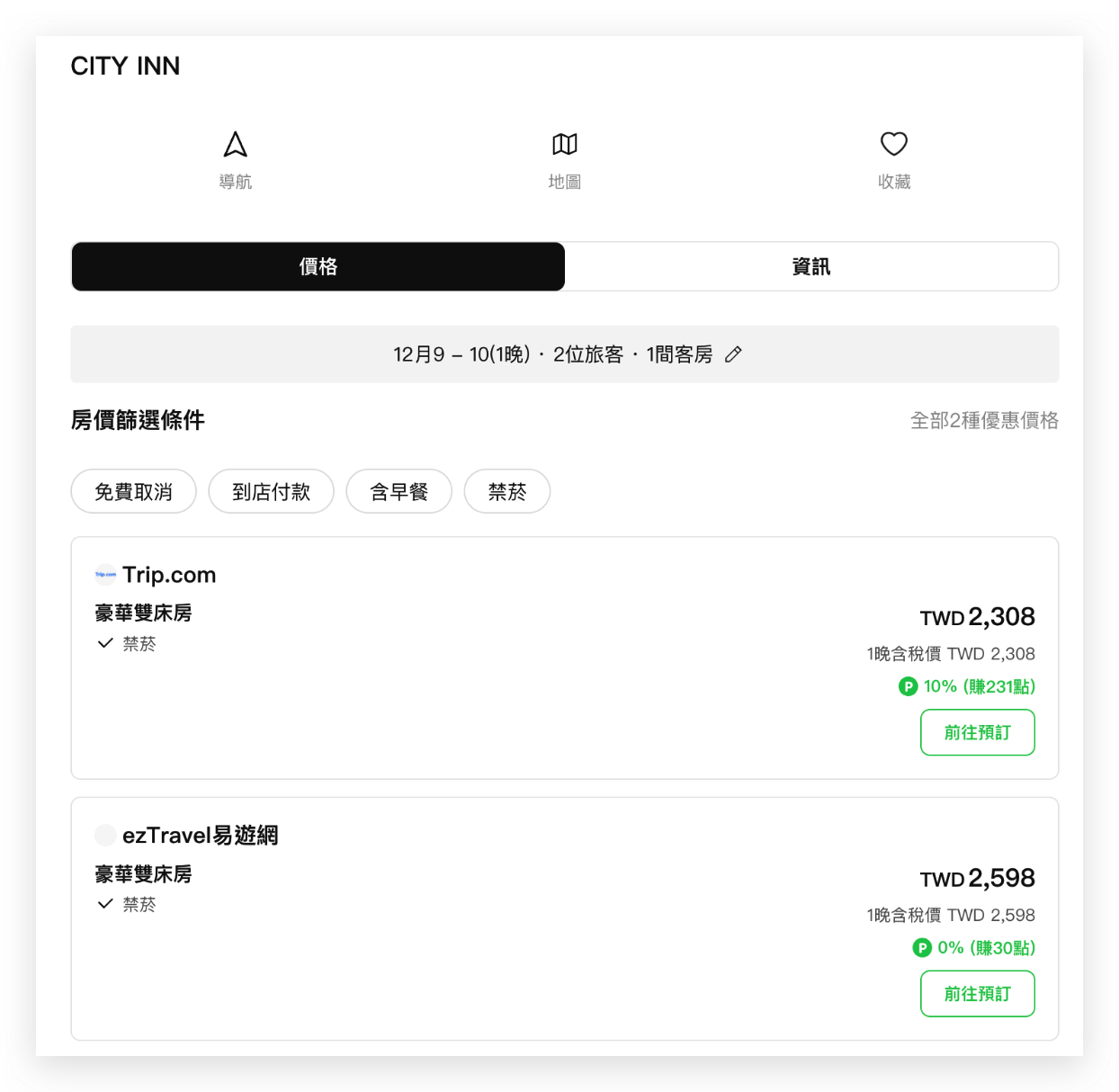
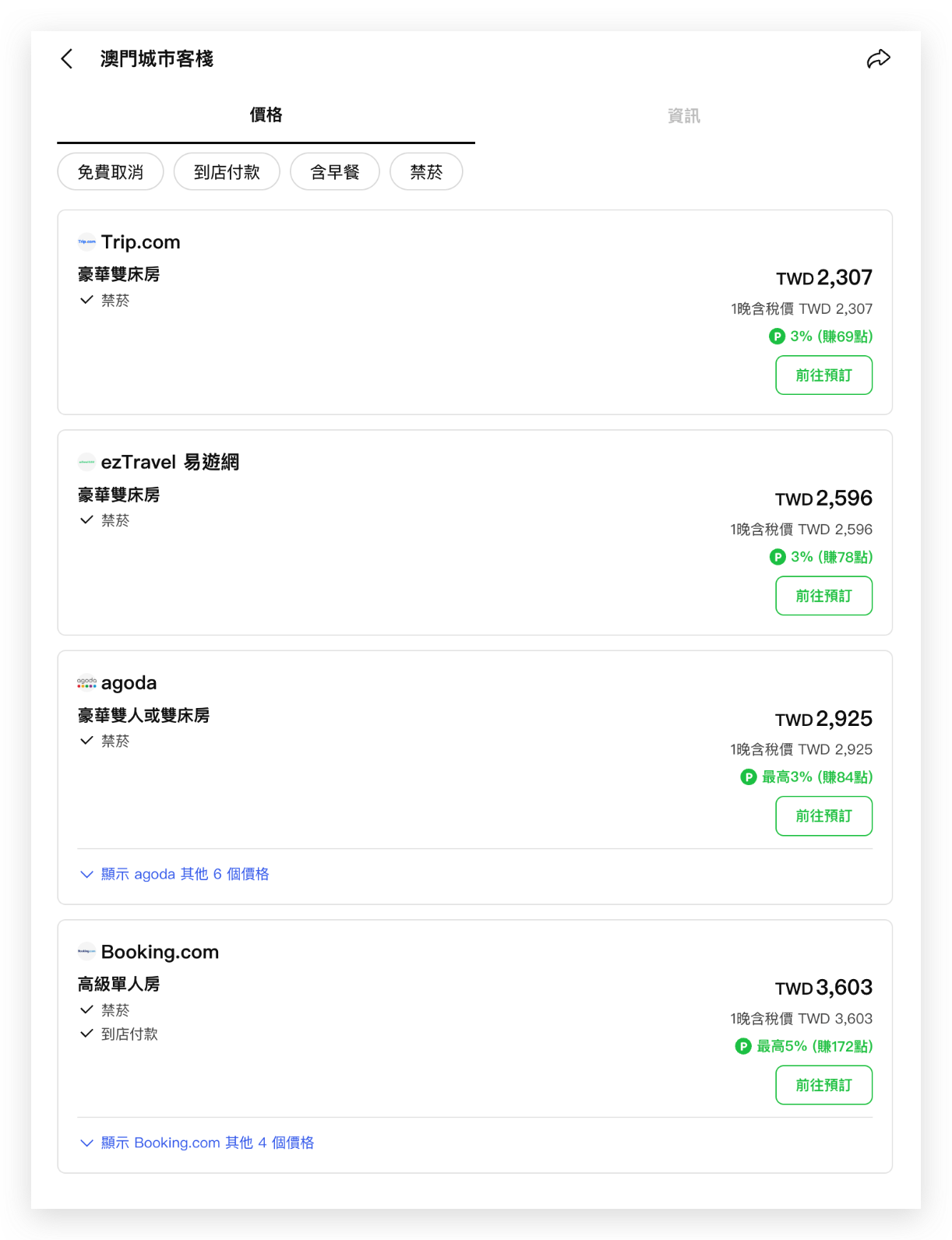
然而,同一間飯店通常會同時在多個線上訂房平台(OTA, Online Travel Agency)上架,例如 Agoda、Booking.com、Trip.com 等。以下圖的澳門城市客棧為例,它在 LINE Travel 系統中被視為兩家不同的飯店:一家有 Agoda 和 Booking 的價格,另一家則包含 Trip.com 和 EzTravel 的資訊。這種資料分散的情況,讓使用者在搜尋比價時需要分別查看多筆飯店資料,造成使用上的不便。LINE Travel 先前沒有有效的方式將他們合併,過去只能依賴人工介入,不但時間成本高,也無法面對新 OTA 的加入或是飯店資料的頻繁變動。
| AS IS | TO BE |
|---|---|
|
飯店 1
飯店 2
|
希望合併成這樣
|
解決方向
為了改善這個問題,利用 LLM 的自然語言理解能力,我們希望能夠讓 LLM 取代人工判斷,透過系統化的方式來建構整個飯店合併流程,解決這個資料品質問題。因此,LINE Travel 建立了一套基於 LLM 的飯店配對與合併流程,能夠將散落在各平台的同一間飯店整合在一起,讓使用者可以在單一頁面查看完整的價格與資訊,提升整體的使用者體驗和搜尋效率。
兩階段處理
我們設計了一套自動化的兩階段處理流程,後面的章節將會一一介紹兩個階段的內容。
第一階段:LLM Hotel Mapping
- 針對飯店資料庫建立飯店配對
- 使用 LLM 進行旅館配對比較
- 產生每對旅館的相似度機率 (0-1)
第二階段:Union-Find 飯店分群
- 使用 Union-Find 演算法將相似旅館群組化
- 按規則選擇最佳合併飯店群組
LLM 飯店比對階段
流程設計
面對同一間飯店可能在不同訂房平台上以不同名稱和資訊呈現的問題,我們採用 LLM 作為判斷工具。我們首先透過 MongoDB 地理空間查詢功能來尋找附近的飯店,對每間飯店篩選出與其距離 100 公尺內的飯店,藉此並產生多個飯店配對。
const nearbyHotels = await this.hotelsCollection
.find({
_id: { $ne: hotel._id },
location: {
$near: {
$geometry: {
type: "Point",
coordinates: hotel.location,
},
$maxDistance: maxDistance,
},
},
})為了讓 LLM 能準確判斷兩筆飯店資料是否代表同一間實體飯店,我們設計了包含飯店名稱、地址、描述等關鍵資訊的結構化 prompt,給予 LLM 詳細的合併規則,並要求模型回傳 0-1 之間的相似度機率值以及詳細的判斷理由。回傳機率可以讓 LLM 比較彈性的去回答每組配對的相似程度,在之後我們也會試圖找到一個最適合的機率閾值來決定是否配對中的兩間飯店真的相同。以下是一個 Prompt 的範例:
請仔細比較以下兩筆旅館資料紀錄,判斷它們是否代表同一個旅館。
請依照以下規則判斷兩間飯店是否相同,以下是規則重要性排序:
1. **名稱相似性**:
- 忽略名稱中的地名後,品牌名稱是否高度相似(考慮翻譯差異、縮寫形式)。
- 若其中一間旅館僅稱僅有地名或描述性文字,不包含識別性高的名稱,請將此配對視為不相似。
2. **地理位置一致性**:
- 地址可以有效對應到同一具體地點。
- 地址若不完整或有輕微差異,但整體非常相似。
- 若地址非常不完整,請依據其他資訊進行判斷。
3. **描述與重要資訊相似性**:
- 因為描述內容可能較為主觀且變動性高,請做為輔助判斷依據。
4. **其他佐證**:
- 名稱、地址與描述高度相似,僅房號不同。像是同一旅館被拆成兩個房號上傳,其本質屬於不同旅館。
- 忽略名稱中的地名後的名稱差異非常大,但地址完全相同,可能是不同業者在同一建物內經營的旅館,請視為不同旅館。
請提供:
- probability:可以是 0.0, 0.5, 1.0 三個值之一,分別表示「不同旅館」、「不確定」和「同一旅館」。
- reason:具體的判斷理由,每個理由需說明比較依據和結論
<hotelA>
名稱:東京東陽町站大酒店
地址:Koto-ku Toyo 2-3-12 東京 日本
描述:Hotel Route-Inn Tokyo Toyocho 經濟型飯店距離東陽町站(Toyocho Subway Station)只有 2 分鐘的步行路程 ⋯⋯
</hotelA>
<hotelB>
名稱:Route Inn飯店 - Grand東京東陽町
地址:2-3-12, Toyo, Koto-ku Tokyo Japan
描述:在Route Inn飯店 - Grand東京東陽町體驗豐富的頂級設施和服務⋯⋯
</hotelB>在實作上,我們使用 TypeScript 結合 Zod Schema 來確保 LLM 回應格式的正確性和一致性。每當 LLM 返回判斷結果時,系統會自動驗證回應格式,確保包含必要的機率值和理由說明。
import { z } from "zod";
const HotelComparisonSchema = z.object({
probability: z.number().min(0).max(1).describe("兩個旅館資料為同一個旅館的機率"),
reason: z.string().describe("判斷理由的詳細說明")
});在執行 LLM Mapping 時,我們還必須面對 API 的呼叫限制。由於在公司內和 OpenAI API 都有呼叫 API 的速率限制,我們以 p-queue 套件為基底設計了一個 Queue 來做到發送速率的管控和達上限後的自動重試。這樣能夠做到精確控制 API 請求的頻率和併發數量。在開發階段,我們設定每秒最多處理一個請求來避免觸發限制,而在正式環境中則可以根據實際的 API 配額調整這些參數。
this.queue = new PQueue({
concurrency: 1000,
interval: 1000,
intervalCap: 100,
carryoverConcurrencyCount: false,
});在自動恢復機制方面,當遇到 429 錯誤(Too Many Requests)時,系統會自動讀取 OpenAI 回應中的 Retry-After Header,動態調整等待時間,並暫停所有進行中的請求。一旦限制解除,所有暫停的請求會自動恢復執行。這種設計讓我們能夠在大規模處理時保持系統的穩定性,即使面對數百萬筆飯店資料也能可靠地完成比對任務。以下用簡化的方式來大概呈現此設計。
const processHotelPair = async (hotel1, hotel2, attempt = 1) => {
try {
await waitForRateLimit(); // 檢查是否需要等待
const pairingResult = await callLLMAndCompareHotelPairs(hotel1, hotel2);
return pairingResult;
} catch (error) {
if (error.status === 429 && attempt < MAX_RETRIES) {
// 讀取 Retry-After header 並設定全域等待時間
const retryAfter = error.headers.get("Retry-After");
setGlobalRateLimit(retryAfter * 1000);
// 重新加入佇列等待處理
return queue.add(() => processHotelPair(hotel1, hotel2, attempt + 1));
}
throw error; // 超過重試次數或其他錯誤
}
};
挑選模型、Prompt 和 Decision Threshold
在前面提到我們使用 LLM 搭配結構化的 Prompt 使 LLM 回傳飯店配對的相似機率,而為了找出最適合飯店比對任務的模型配置、Prompt 和 Decision Threshold,我們進行了大規模的實驗。我們首先以人工方式標註了 500 筆飯店配對資料來獲得每筆配對的正確答案,再透過 5-fold Cross-Validation 方法來來評估不同組合的表現。我們測試了多種 GPT 模型(包括 gpt-4o、gpt-4.1-mini、gpt-4.1-nano、gpt-4o-mini、gpt-5-mini、gpt-5-nano 等)搭配多種 prompt 設計的組合效果。
在這個任務上,錯誤地將不同飯店合併會導致用戶體驗問題,我們希望 LLM 盡可能地避免將明明不同的飯店視為相同。因此在挑選模型、prompt 和閾值的組合時,我們的策略是在最大化精確度(precision)的狀況下,取得最高的召回率(recall)。換句話說,在不錯誤將飯店視為相同的前提下,盡可能地合併真正相同的飯店。
為了實現這個目標,在 CV 的過程中,對每個訓練集,系統會先搜索能將 precision 最大化的機率閾值,然後再從中選出能最大化 recall 的閾值,並評估此閾值在對應驗證集中的表現。最終以所有 fold 驗證��集表現的平均值作為該模型組合的 CV 分數。在整個 CV 流程完成後,我們可以得到所有 model x prompt x threshold 在 5 個驗證集的平均 precision、recall、f1 score、accuracy 等指標。
實驗的結果顯示 GPT-5-nano 搭配我們寫的某個讓 LLM 輸出 0, 0.5, 1 三種結果的 prompt 以及 threshold = 0.51 (只有在回答為 1 時視為相同)時的組合表現最佳。這個組合在驗證集的平均 precision 為 100% 且 recall 為 77.8%,可以平衡配對系統的可靠性以及實用性。在所有 prompt 中,我們也試過回答 0-1 但間隔為 0.1 和完全不限制間隔,最後發現限制在越離散的輸出,在表現上是最好的。這個結果也和其他文章或論文提到的結果類似,也就是二元或類別式的判斷更為穩定,也跟人工標註的對應度更高 [1][2]。
用 Union Find 進行飯店分群
經過 LLM 階段的處理,我們現在有了大量的飯店配對結果,每一對都有一個 0-1 之間的相似度機率。看起來問題已經解決了,但實際上新的問題也出現了。
想像這樣的情況,LLM 告訴我們「東京君悅酒店」和「東京君悅大飯店」是同一間飯店,同時也判斷「Grand Hyatt Tokyo」和「東京君悅大飯店」是同一間。按照邏輯,這三間飯店都應該是同一間才對。隨著資料量增加,這種多層關係也會變得更複雜。一個飯店群組可能包含更多筆飯店記錄,彼此透過不同的路徑連結,因此我們需要一個系統性的演算法來處理這個問題。
Union-Find 演算法介紹
面對這個問題,我們需要一種能夠有效處理「分組」和「連通性」的演算法。Union-Find 演算法正是為此而生的,他可以維護一群「元素分成很多集合」的狀態,讓我們可以快速回答:兩個元素是不是在同一個集合?
我們可以把一個元素以一個節點來表示,一個集合以一個 Tree 來表示,這個資料結構有兩個操作:
- Find(查找):查詢某個元素所處的集合、查詢某個節點的所屬 Tree 的根節點
- Union(合併):將兩個元素合併為同一集合、將兩個元素所屬的 Tree 接在一起
我們先以一個簡單的例子來了解這兩個操作,並介紹這與飯店分群的關聯。
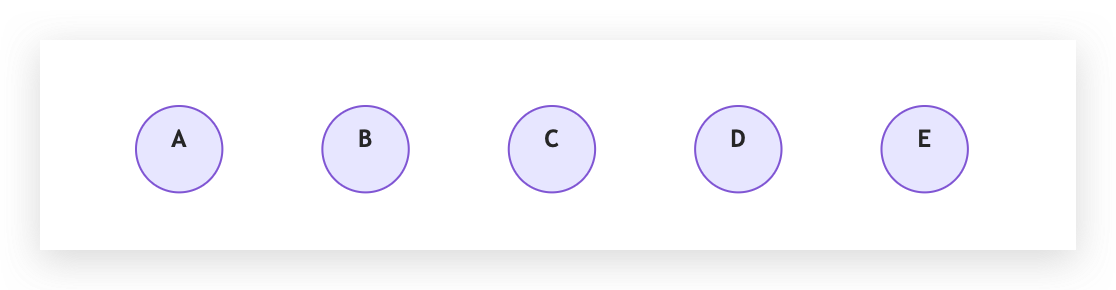
假設我們有 5 間飯店,我們可以用 5 個彼此沒有連接的節點來表示初始狀態。他們也各自是一棵 Tree,自己就是自己的根節點。
在利用地理位置建立配對後,我們可能產生了以下這幾個 pair,接著我們拿已經挑選好的 LLM x prompt x 閾值來標記每組配對是相同飯店還是不同飯店。
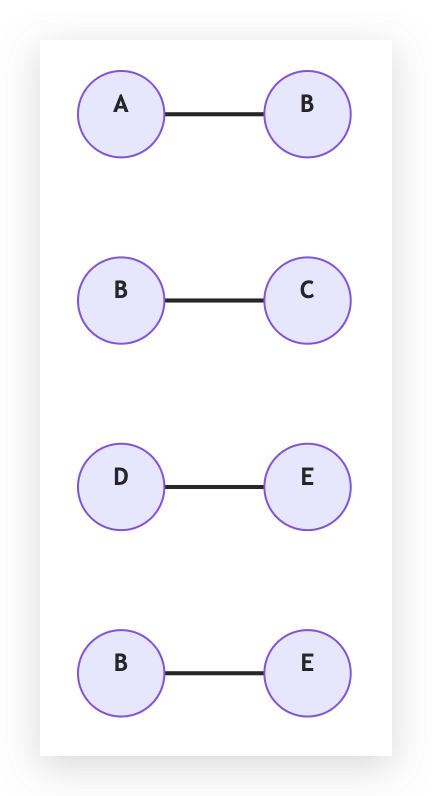
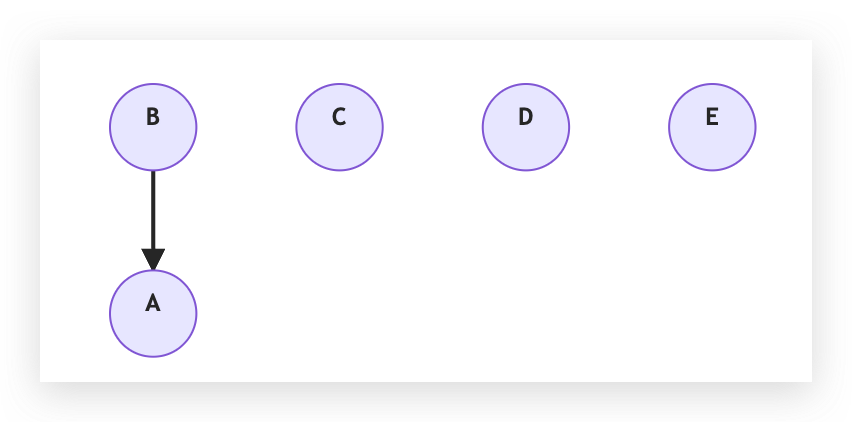
我們給 LLM 判斷 (A - B) 這個配對,LLM 認為是相同的飯店。此時我們可以做 Union(A, B) 這個操作。Union(A, B) 包含以下的步驟
- 找兩邊的 root:ra = Find(A), rb = Find(B)
- 如果 rootA == rootB,已經同集合,什麼都不做
- 否則把其中一個 root 接到另一個 root 下面,讓矮的那棵樹掛到高的那棵樹底下,否則就隨意挑一個。
假設現在 LLM 又判斷 (B - C) 也是相同的,那 Union(B, C) 後會變成:
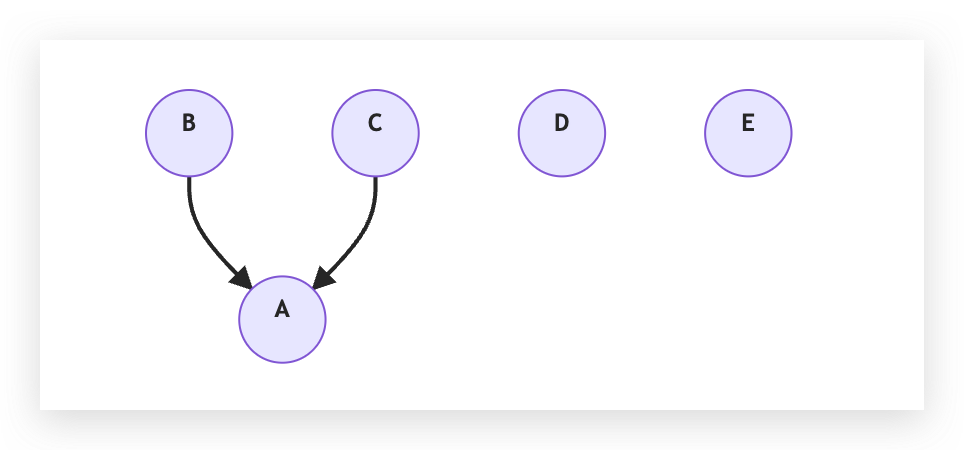
注意這時候 C 不是接在 B 上面,因為我們要連接的是 B 和 C 的根節點,在這個例子裡面,B 的根節點已經變成 A 了。
我們現在分別做 Union(D, E) 和 Union (E, B),資料結構先變成:
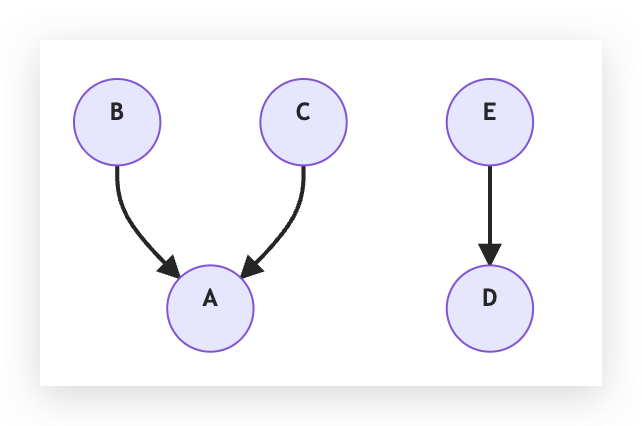
再變成:
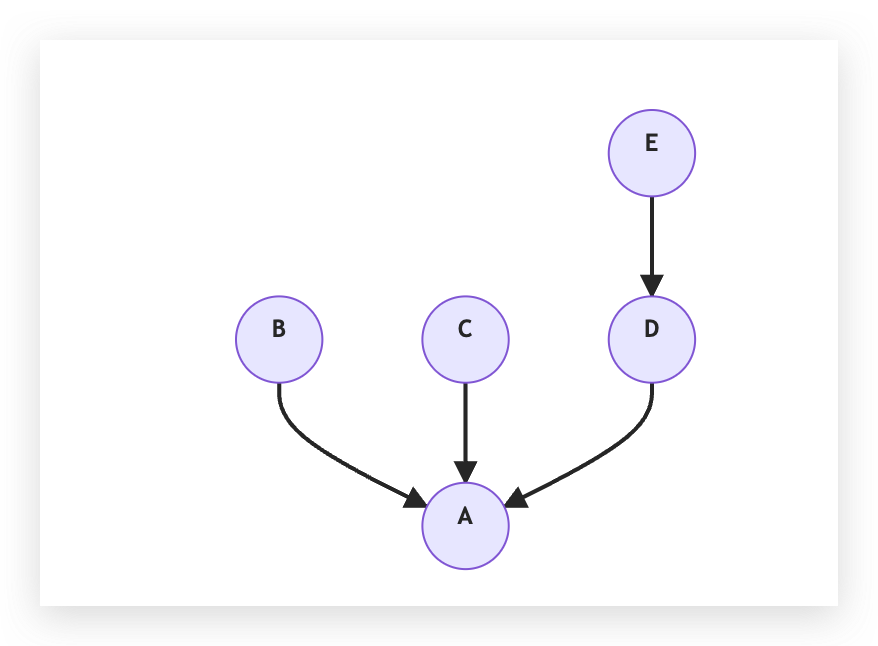
得到四個相同飯店的配對再透過四個 Union 操作,我們成功把 5 間飯店都接到同棵樹下面了。我們接下來就只要對所有的相同飯店配對都做一樣的事情,就可以得到非常多棵樹。在合併時,我們只要把這些樹挑出來,若樹裡面有 4 間飯店,我們就知道這四間飯店是一樣的,可以把這四間合併。這讓使用者搜尋這間飯店的時候不會挑出四個結果,而是呈現一間飯店,但裡面有四間 OTA 的價格資訊。
處理衝突
雖然一切看起來都沒問題了,但在上面的例子我們都只有考慮相同飯店的配對,完全忽略了被 LLM 視為不同的飯店配對。回到最一開始的君悅飯店例子。LLM 告訴我們「東京君悅酒店」和「東京君悅大飯店」是同一間飯店、「Grand Hyatt Tokyo」和「東京君悅大飯店」是同一間。假設 LLM 比較「東京君悅酒店」和「Grand Hyatt Tokyo」的時候,因為某些敘述或差異而給出代表不確定的機率 0.5,使得我們設定的閾值判斷他們為不同飯店,這時候該怎麼辦?
這就是所謂的衝突問題:A = B、B = C,理論上 A = C,但 LLM 卻告訴我們 A ≠ C。以保守的角度來說,我們可能會傾向完全不把 A、B、C 三間飯店合併,雖然可能錯過一些可被合併的飯店,但我們更不希望錯誤的合併產生。
為了解決這個問題,我們新增了一個衝突檢測到飯店合併流程中。我們首先利用 Union Find 演算法來對所有的相同飯店配對來分群。我們接著可以遍歷所有被 LLM 視為不同飯店的配對,看這個配對中的兩間飯店在 Union-Find 資料結構中是不是有一樣的根節點。如果有一樣的根節點,就代表衝突發生了。回到 5 間飯店的例子,若有一組配對是 C ≠ E,我們發現 Find© = Find(E) = A,這就是一個衝突。
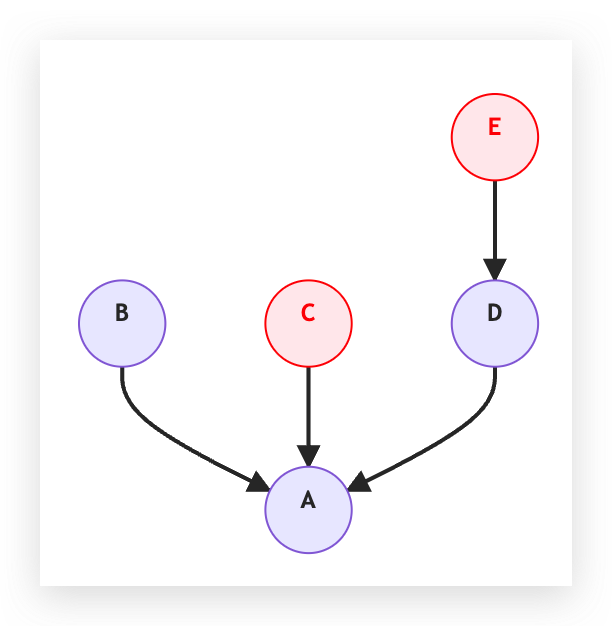
對於衝突的發生,我們會將這棵樹標記為衝突的樹,也就是衝突的群組,後續合併就會忽略這棵樹,以避免真的合併錯誤發生。這些衝突的樹,很多都因為 LLM 過於保守而使得無法合併,未來可以考慮以人工方式把這些衝突的樹解決,可以提供更多合�併機會。
成果總結
到這個階段,我們已經將資料庫中飯店都分群完,也標記可合併的飯店群組了。雖然實際執行合併時還有許多細節需要處理,但主要的辨識與分群流程已經完整建立。在成果方面,以日本的飯店資料為例,在我們執行完整個流程後,我們成功減少約 20000 間飯店,約佔全部日本飯店的 1/6。未來會繼續將此流程套用在更多國家上面,讓使用者在搜尋飯店時能夠更有效率。
心得
在處理這個問題時,一開始好像是個直觀的問題,但在建立整套流程時其實會遇到很多實務問題,包括資料前處理、流程功能實作方式都需要考慮現有的限制和環境。例如很多飯店早就已經關閉需要過濾、或是有些飯店是以房間為單位上傳這些問題。過程中也需要與團隊反覆討論各種規則的合理性,以及如何讓合併後的飯店資料能夠正常的被現有系統使用,也包含 OpenAI token 成本的計算等等。在技術方面上,例如前面提到呼叫 OpenAI 時實作的 Queue、因為需要處理大量資料執行時導致的記憶體不足問題,也都需要被一一解決。
這個任務最大的收穫不僅是技術實作,將問題拆解的過程讓我累積了將模糊需求轉化為可執行方案的經驗,也更清楚在解決真實世界問題時會需要面對的各種限制,而在這些限制底下嘗試找到一條路是一個很棒的經驗。
References
[1] Huang, F., Kwak, H., Park, K., & An, J. (2024). ChatGPT rates natural language explanation quality like humans: But on which scales?. arXiv preprint arXiv:2403.17368
[2] https://arize.com/blog/testing-binary-vs-score-llm-evals-on-the-latest-models/