Tổng quan
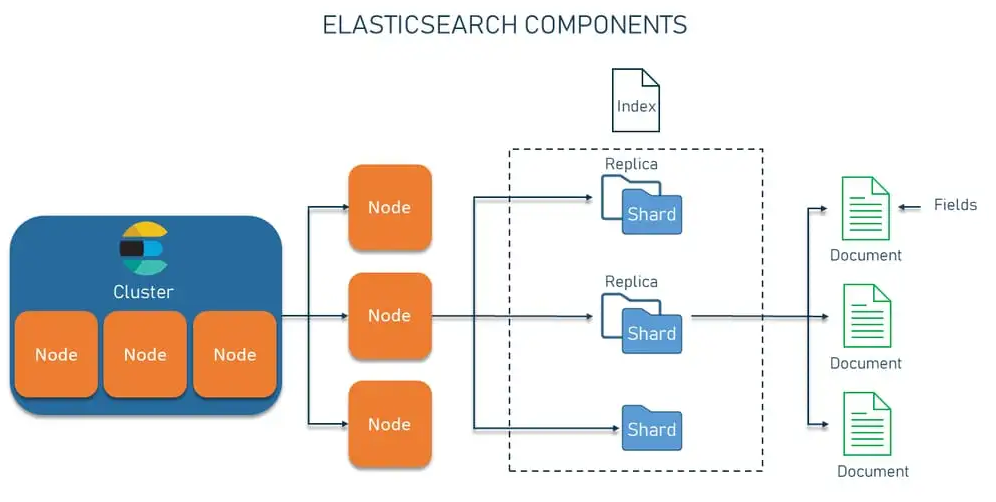
Dự án LINE NEWS là ứng dụng đọc báo cho smartphone lớn nhất Nhật Bản với 57 triệu MAU (tham khảo tại đây). Trong đó, ProofRead là hệ thống phục vụ việc hiệu đính các bài báo được xuất bản trên hệ thống LINE NEWS.
Trong một bài báo, có thể chứa đựng các lỗi sai chính tả, lỗi sai về số liệu hoặc có thể có những thông tin không chính xác, sai lệch. Nhiệm vụ của người hiệu đính là cần kiểm tra toàn bộ bài báo và chỉ ra các lỗi sai trên để tác giả bài báo sửa lại cho chính xác. Một bài báo chỉ có thể được xuất bản sau khi đã vượt qua được quá trình hiệu đính trên. Hiện tại, để phục vụ việc tìm kiếm các bài báo theo nội dung hoặc các comment mà người hiệu đính đã thực hiện (tìm kiếm theo free word), hệ thống ProofRead đang thực hiện lưu trữ các bài báo trên Elasticsearch.
Vậy Elasticsearch là gì?
Elasticsearch là công cụ tìm kiếm và phân tích phân tán được xây dựng trên Apache Lucene. Kể từ khi ra mắt năm 2010, Elasticsearch đã nhanh chóng trở thành công cụ tìm kiếm thông dụng nhất và được sử dụng rộng rãi cho các trường hợp sử dụng liên quan đến phân tích nhật ký, tìm kiếm toàn văn bản, thông tin bảo mật, ph�ân tích nghiệp vụ và thông tin vận hành. Elasticsearch có những đặc điểm sau:
- Elasticsearch là một search engine được kế thừa từ Lucene Apache.
- Elasticsearch hoạt động như một web server, có khả năng tìm kiếm nhanh chóng (near realtime) thông qua giao thức RESTful.
- Elasticsearch có khả năng phân tích và thống kê dữ liệu.
- Elasticsearch chạy trên server riêng và đồng thời giao tiếp thông qua RESTful, do vậy nên ES không phụ thuộc vào client viết bằng gì hay hệ thống hiện tại của bạn đang sử dụng ngôn ngữ gì. Nên việc tích hợp ES vào hệ thống của bạn là dễ dàng, bạn chỉ cần gửi request http lên là sẽ nhận được kết quả trả về.
- Elasticsearch là một hệ thống phân tán có khả năng mở rộng tuyệt vời (horizontal scalability). Lắp thêm node là ES sẽ tự động mở rộng cho bạn.
- Elasticsearch là một open source được phát triển bằng Java.
Các vấn đề gặp phải
Trong quá trình sử dụng, hệ thống gặp vấn đề như sau: Khi người dùng thực hiện tìm kiếm các bài báo có chứa một từ ngữ hoặc một đoạn văn bản nào đó (free word search), kết quả tìm kiếm trả về rất chậm, thời gian Elastic Search xử lý mất tầm > 1 phút, thậm chí một số query không trả về kết quả (timeout). Điều này gây ra rất nhiều bất tiện cho người dùng, giảm hiệu suất khi thực hiện hiệu đính các bài báo. Đặc biệt là với các bài báo hot trend cần xuất bản trong thời gian nhanh nhất, điều này ảnh hưởng rất lớn.
Dưới đây là cấu hình Elasticsearch mà chúng tôi cần tối ưu:
"settings": {
"analysis": {
"char_filter": {
"cjk_space": {
"type": "mapping",
"mappings": [
" => \\u0020"
]
}
},
"analyzer": {
"lowercase_analyzer": {
"type": "custom",
"tokenizer": "keyword",
"char_filter": [
"cjk_space"
],
"filter": [
"cjk_width",
"lowercase"
]
}
}
}
}Cấu hình dynamic template (khi tìm kiếm theo free word) cần tối ưu như sau:
"dynamic_templates": [
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "text",
"fields": {
"lo": {
"type": "text",
"analyzer": "lowercase_analyzer"
}
}
}
}
}
]Nguyên nhân xảy ra
Qua quá trình điều tra, chúng tôi xác định việc query tìm kiếm trên Elasticsearch chậm do 2 nguyên nhân sau:
Khối lượng lưu trữ trên Elasticsearch khá lớn
Hiện tại, hệ thống đang lưu trữ tất cả bài báo: bao gồm cả phiên bản mới nhất (revision = 0) và các phiên bản lịch sử (revision > 0) của bài báo. Điều này dẫn tới số lượng cần lưu trữ lớn:
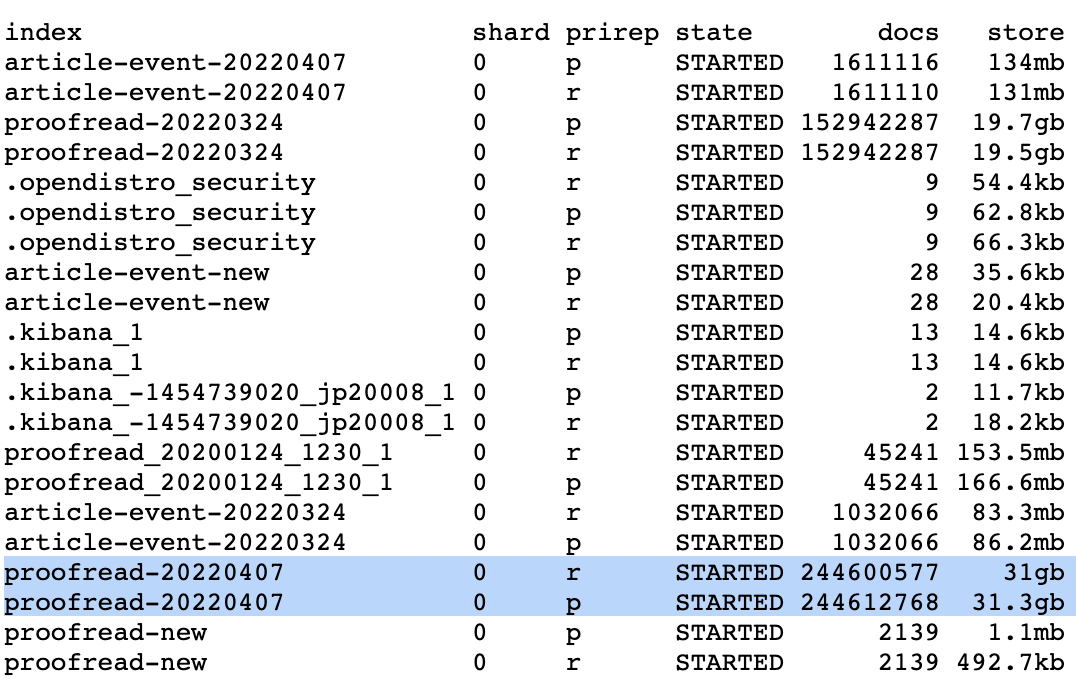
- Môi trường Elasticsearch có 3 node data, mỗi index được cấu hình sử dụng 1 shard, khối lượng shard tương đối lớn (32gb) cho index hiện tại (proofread-20220407)
- Số lượng documents được index lên tới 244.6 triệu docs.
Dung lượng và số lượng documents được lưu trữ lớn như vậy đã làm tốc độ tìm kiếm document giảm xuống.
Câu lệnh query phức tạp
Khi thực hiện tìm kiếm nội dung bài báo trên Elasticsearch, chúng tôi đang kết hợp theo các điều kiện sau:
- Chỉ tìm kiếm theo phiên bản mới nhất của bài báo (revision = 0).
- Thời gian update bài báo trong vòng 1 tháng gần nhất.
- Tìm kiếm theo nội dung dùng wildcard query.
Chi tiết về câu lệnh query trên Elasticsearch các bạn có thể thấy như bên dưới:
{
"from": 0,
"size": 10000,
"query": {
"bool": {
"must": [
{
"term": {
"revision": {
"value": 0,
"boost": 1.0
}
}
},
{
"bool": {
"should": [
{
"nested": {
"query": {
"bool": {
"should": [
{
"wildcard": {
"reviews.comment.lo": {
"wildcard": "*4月5日*",
"boost": 1.0
}
}
},
{
"nested": {
"query": {
"bool": {
"should": [
{
"wildcard": {
"reviews.reviewer.userId.lo": {
"wildcard": "*4月5日*",
"boost": 1.0
}
}
},
{
"wildcard": {
"reviews.reviewer.userName.lo": {
"wildcard": "*4月5日*",
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"path": "reviews.reviewer",
"ignore_unmapped": false,
"score_mode": "avg",
"boost": 1.0
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"path": "reviews",
"ignore_unmapped": false,
"score_mode": "avg",
"boost": 1.0
}
},
{
"nested": {
"query": {
"wildcard": {
"items.value.lo": {
"wildcard": "*4月5日*",
"boost": 1.0
}
}
},
"path": "items",
"ignore_unmapped": false,
"score_mode": "avg",
"boost": 1.0
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
}
],
"filter": [
{
"range": {
"contentUpdatedAt": {
"from": "2023-03-19T10:39:10",
"to": null,
"include_lower": true,
"include_upper": true,
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
}
}Việc trong câu lệnh query có sử dụng wildcard sẽ làm cho hiệu năng giảm xuống rất nhiều. Đây là nguyên nhân chính gây nên tình trạng tìm kiếm chậm của hệ thống.
Giải pháp xử lý
Sau khi đã xác định được nguyên nhân, để giải quyết vấn đề tìm kiếm chậm của Elasticsearch, chúng tôi đã thực hiện 2 công việc sau đây:
- Giảm dung lượng lưu trữ của index trên Elasticsearch
- Giảm độ phức tạp trong truy vấn tìm kiếm trên Elasticsearch
Giảm dung lượng lưu trữ index
Hiện nay, khi lưu trữ các bài báo trên Elasticsearch, chúng tôi đang lưu trữ cả revision mới nhất và các revision cũ hơn. Tuy nhiên theo nghiệp vụ, khi tìm kiếm các bài báo trên Elasticsearch, chúng ta chỉ quan tâm tới phiên bản mới nhất. Do đó thay vì chỉ sử dụng duy nhất một index để lưu trữ các bài báo, chúng tôi đã tạo ra 2 index:
- Index thứ nhất để lưu trữ revision mới nhất (revision 0) của bài báo
- Index thứ hai để lưu trữ các revision cũ hơn.
Các bạn có thể tham khảo hình vẽ dưới đây để thấy sự khác biệt giữa 2 cách lưu trữ.
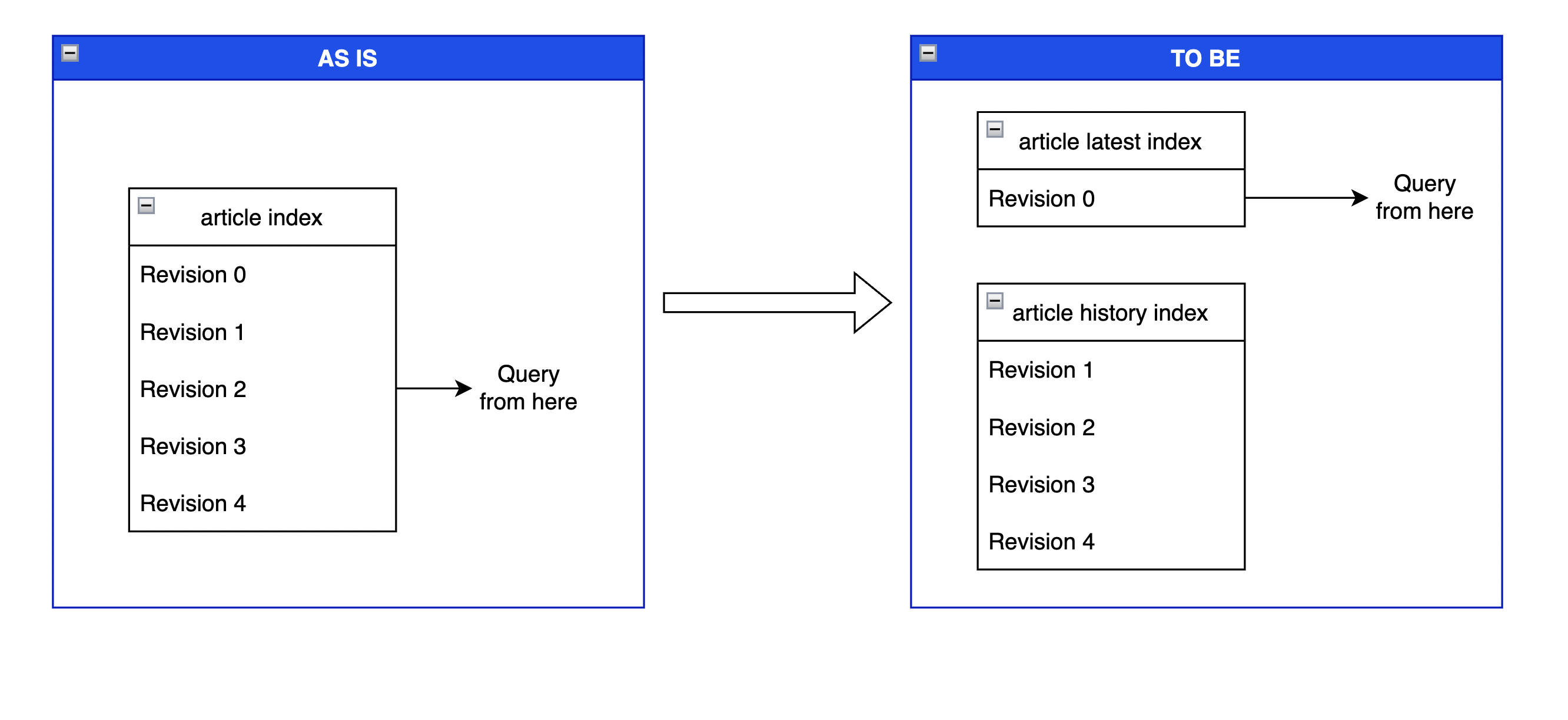
Việc chia thành 2 index như vậy sẽ có các lợi ích sau:
- Khi tìm kiếm bài báo, chúng tôi chỉ cần tìm kiếm trên index chứa bài báo mới nhất.
- Số lượng document cần xử lý khi tìm kiếm giảm đi đáng kể (chỉ còn 1/5 so với trước đây): do trung bình 1 bài báo sẽ có 1 revision mới nhất và 5 revision cũ hơn
- Nếu nghiệp vụ thay đổi cần xử lý trên các revision cũ hơn, chúng ta cũng có thể đáp ứng được.
Giảm độ phức tạp khi truy vấn tìm kiếm
Để thay thế cho việc tìm kiếm theo wildcard, chúng tôi sử dụng N-Gram Tokenizers. Việc sử dụng N-Gram Tokenizers cũng cho kết quả tương tự như sử dụng wildcard, tuy nhiên tốc độ xử lý sẽ nhanh hơn rất nhiều do tận dụng được index search của Elasticsearch.
Vậy N-Gram Tokenizers là gì?
N-Gram là các chuỗi văn bản con nhỏ hơn có thể được lập chỉ mục và tìm kiếm hiệu quả hơn. Bằng cách lập chỉ mục n-gram, chúng ta có thể giảm nhu cầu truy vấn theo wildcard và cải thiện hiệu suất tìm kiếm. N-Gram Tokenizers phá vỡ văn bản thành các từ bất cứ khi nào nó chạm trán một trong những ký tự được chỉ định, sau đó nó phát ra N-gram của mỗi từ có độ dài quy định. N-Gram giống như một cửa sổ trượt di chuyển qua từ - một dãy liên tục các ký tự có đ��ộ dài quy định.
Để hiểu rõ về N-Gram, chúng ta hãy xem xét ví dụ dưới đây:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 2
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "関連リンク"
}Đầu ra nhận được là: [ 関連, 連リ, リン, ンク ]
Trong ví dụ bên trên, chúng ta đang đặt min_gram = max_gram. Thông thường, việc đặt min_gram và max_gram thành cùng một giá trị là hợp lý. Độ dài gram càng nhỏ càng có nhiều tài liệu trùng khớp nhưng chất lượng của các kết quả khớp càng thấp. Ngược lại, độ dài gram càng dài, các kết quả khớp càng cụ thể. Trong bài toán của chúng tôi, để phục vụ cho việc tìm kiếm được càng nhiều kết quả càng tốt, chúng tôi đã thiết lập min_gram và max_gram đều bằng 1.
Dưới đây là cấu hình index sau khi chúng tôi apply N-Gram Tokenizers:
{
"settings": {
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 1
}
},
"analyzer": {
"ngram_token_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer",
"filter": [
"lowercase",
"cjk_width"
]
}
}
},
"index.max_ngram_diff" : 10
}
}Ngoài ra khi sử dụng N-Gram Tokenizers, có một hạn chế đó là chúng ta không thể tìm kiếm theo các từ có độ dài lớn hơn max_gram.
Ví dụ trong trường hợp bên trên, khi chúng ta tìm kiếm các văn bản có chứa từ リンク, kết quả tìm kiếm sẽ không trả ra kết quả nào. Nguyên nhân vì khi thực hiện lưu trữ văn bản có nội dung "関連リンク", Elasticsearch đã thực hiện tạo chỉ mục theo các từ sau [ 関連, 連リ, リン, ンク ]. Rõ ràng là trong các từ được lập chỉ mục, không có chứa từ リンク.
Để giải quyết vấn đề đó, chúng ta cũng cần sử dụng N-Gram Tokenizers để phân tách keyword thành các cụm từ tương tự như khi chúng ta thực hiện lưu trữ văn bản bằng cách sử dụng search_analyzer trong dynamic_templates.
"dynamic_templates": [
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "text",
"fields": {
"lo": {
"type": "text",
"analyzer": "ngram_token_analyzer",
"search_analyzer": "ngram_token_analyzer"
}
}
}
}
}
]Khi đó nếu chúng ta search theo keyword là "リンク", keyword này sẽ được phân tách thành các cụm từ [リン, ンク], và các cụm từ này sẽ được mang đi để tìm kiếm trong các chỉ mục đã được tạo bên trên.
Chú ý: Như các bạn đã thấy cấu hình index của chúng tôi đã sử dụng 2 loại filter lowercase và cjk_width. Hai loại filter này đã được sử dụng trong cấu hình index cũ trước đây, và để đảm bảo kết quả tìm kiếm được chính xác nhất, chúng tôi vẫn giữ nguyên 2 loại filter này trong cấu hình index mới. Ý nghĩa của 2 loại filter này như sau:
Lowercase filter: Thay đổi văn bản mã thông báo thành chữ thường. Ví dụ: bạn có thể sử dụng bộ lọc chữ thường để thay đổi "THE Lazy DoG" thành "the lazy dog". Điều này hỗ trợ việc tìm kiếm trong bài báo mà không phân biệt chữ hoa và chữ thường.
CJK width filter: Chuẩn hóa sự khác biệt về độ rộng trong các ký tự CJK (tiếng Trung, tiếng Nhật và tiếng Hàn)
- Chuyển các ký tự ASCII có độ rộng đầy đủ thành các ký tự Latinh cơ bản tương đương
- Chuyển các ký tự Katakana nửa chiều rộng thành các ký tự Kana tương đương: ví dụ "シーサイドライナー" được chuyển thành "シーサイドライナー"
Do các văn bản của chúng tôi đa phần được viết bằng ngôn ngữ tiếng Nhật nên việc sử dụng CJK with filter đặc biệt hữu ích để đảm bảo có thể tìm đúng và đủ các bài báo khi thực hiện query trên Elasticsearch.
Kết quả đạt được
Sau khi thực hiện giải pháp tối ưu cấu trúc index và giảm độ phức tạp khi truy vấn tìm kiếm trên Elasticsearch, chúng tôi đã đạt được các thành quả sau:
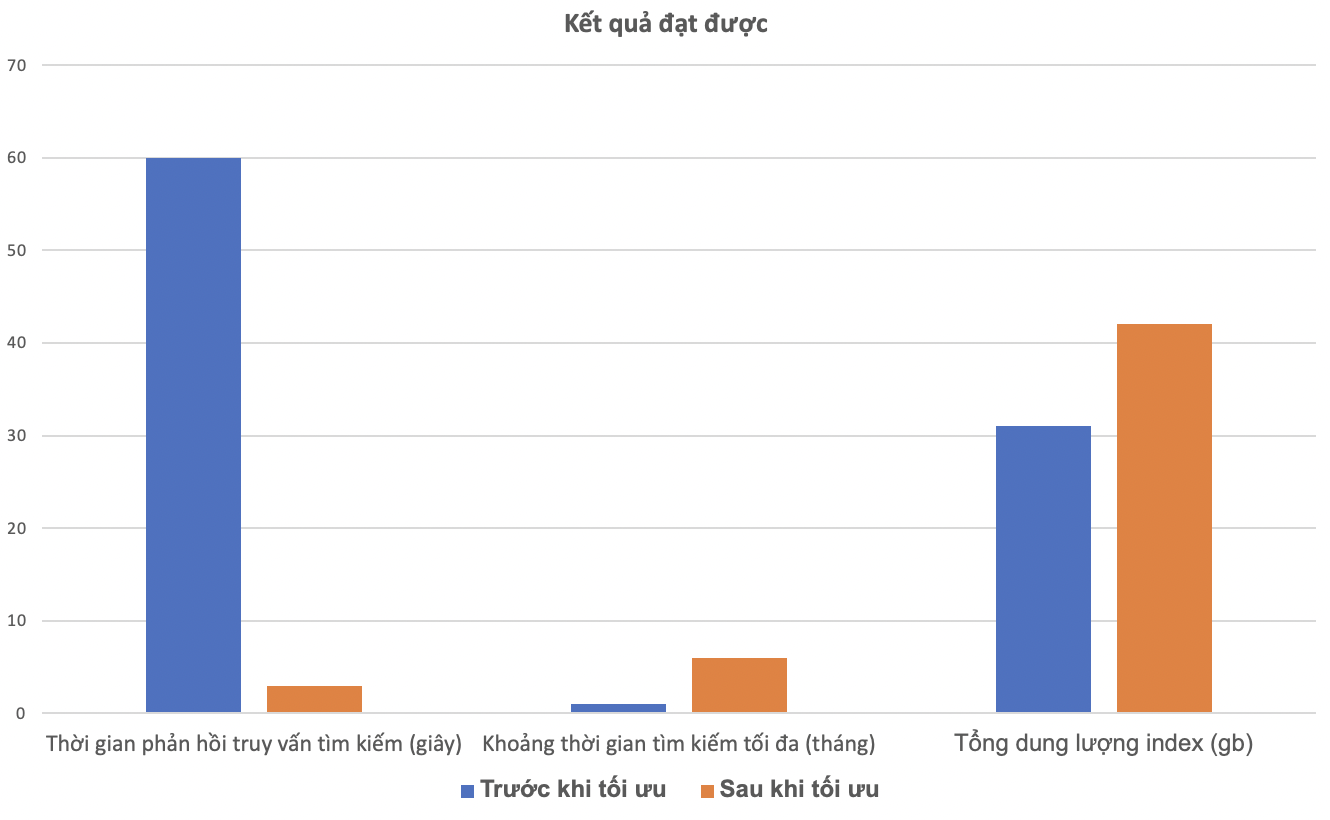
- Thời gian truy vấn tìm kiếm trên Elasticsearch theo free word giảm xuống còn chỉ 3s (so với > 1 phút lúc chưa tối ưu)
- Khoảng thời gian cho phép tìm kiếm được tăng từ 1 tháng lên 6 tháng: hiện tại thời gian có thể tăng thêm nữa nhưng nghiệp vụ chỉ yêu cầu trong vòng 6 tháng gần nhất.
- Người dùng rất đánh giá rất cao kết quả đạt được do họ không còn phải chờ đợi lâu như trước.
Ngoài ra, sau khi tối ưu, tổng dung lượng 2 index lưu trữ bài báo có tăng 40% so với dung lượng lưu trữ index cũ (31gb → 42gb) do cần lưu trữ thêm chỉ mục cho giải thuật N-Gram, tuy nhiên chúng tôi đánh giá việc tăng dung lượng lưu trữ này có thể chấp nhận được vì dung lượng tăng thêm không đáng kể so với kết quả đạt được bên trên.
Tổng kết
Qua quá trình thực hiện tối ưu và kết quả đạt được, chúng tôi đã rút ra một số kết luận sau:
- Khi thực hiện lưu trữ dữ liệu lên Elasticsearch, chúng ta cố gắng lưu trữ ở mức tối thiểu nhất, không nên lưu trữ dư thừa quá nhiều dẫn đến việc tốn thêm dung lượng không cần thiết. Đồng thời sẽ làm cho việc tìm kiếm trở nên chậm chạp hơn do cần xử lý nhiều document hơn.
- Khi truy vấn tìm kiếm trên Elasticsearch, chúng ta không nên sử dụng wildcard query, mặc dù nó có thể linh hoạt trong tìm kiếm nhưng bạn sẽ phải đánh đổi về tốc độ tìm kiếm. Nếu cần tìm kiếm theo wildcard, các bạn có thể cân nhắc sử dụng một trong các biện pháp sau (tham khảo thêm ở đây):
- Sử dụng N-Gram Tokenizers hoặc N-Gram Token Filter tùy theo từng bài toán.
- Sử dụng prefix queries cho suffix wildcards.
- Tối ưu index settings sử dụng max_expansions.
- Cần cân nhắc cấu trúc index trước khi thực hiện lưu trữ. Nếu có thể, chúng ta cần benchmark performance của từng giải pháp trước khi sử dụng thực tế.