Giới thiệu
Trong bối cảnh phát triển ứng dụng iOS ngày càng thay đổi, đã xuất hiện vô số thư viện cơ sở dữ liệu, mỗi thư viện đều cung cấp các cách hiệu quả để lưu trữ và truy xuất dữ liệu. Trong số đó, SQLite, Realm và CoreData đã trở nên đặc biệt nổi bật. Mỗi thư viện đều có những ưu điểm độc đáo của riêng mình, nhưng CoreData nổi bật như một trong những khung cơ sở dữ liệu mạnh mẽ và phổ biến nhất trong phát triển ứng dụng iOS.
Tuy nhiên, CoreData không chỉ là một cơ sở dữ liệu thông thường hỗ trợ các hoạt động tạo, đọc, cập nhật, xóa (CRUD). Đây là một khung cơ sở dữ liệu toàn diện cung cấp một loạt các tính năng hấp dẫn như đồng thời (concurrency), lỗi khi truy xuất (fetch faulting), so sánh khi truy xuất (fetch diffing) và các mối quan hệ. Đặc biệt thú vị trong số đó là các mối quan hệ (relationships) trong CoreData. Chúng đi kèm với các API đơn giản, dễ dàng cấu hình và được tối ưu hóa cực kỳ cao về hiệu suất.
Tuy nhiên, để thực sự khai thác sức mạnh của các mối quan hệ trong CoreData, sự hiểu biết sâu rộng là cần thiết. Đó là lý do tại sao trong bài viết này, chúng ta sẽ đi sâu vào các mối quan hệ trong CoreData, khám phá mọi khía cạnh để giúp bạn hoàn toàn hiểu được tiềm năng của chúng và đạt được hiệu suất tốt nhất trong các ứng dụng iOS của bạn. Ta cùng bắt đầu nhé!
I. Tổng quan
Mối quan hệ trong CoreData cho phép bạn mô hình hóa các liên kết giữa các thực thể trong mô hình dữ liệu của bạn. Chúng là một phần không thể thiếu để tạo ra một đồ thị đối tượng liên kết và rõ ràng, và chúng phản ánh cách bạn tự nhiên nhìn nhận các kết nối giữa các loại đối tượng khác nhau trong thế giới thực.
Dưới đây là một số loại quan hệ phổ biến trong CoreData. Các lập trình viên làm việc với cơ sở dữ liệu ít nhất nên đã gặp chúng một lần, nhưng nếu bạn không biết về chúng thì cũng không cần phải lo lắng, chúng ta sẽ xem xét kỹ hơn về từng loại mối quan hệ trong Phần II.
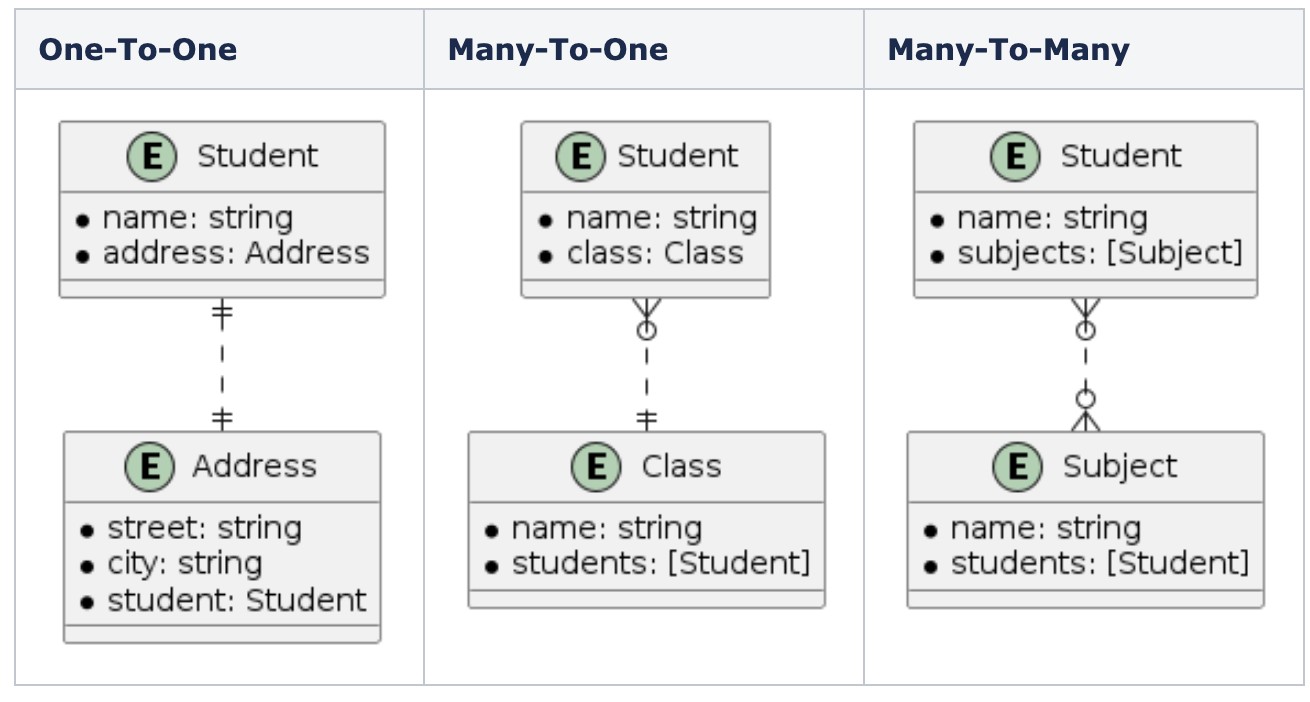 Hình 1. Các loại quan hệ (Nếu bạn không quen thuộc với cú pháp này hãy tham khảo PlantUML)
Hình 1. Các loại quan hệ (Nếu bạn không quen thuộc với cú pháp này hãy tham khảo PlantUML)Một mối quan hệ gồm những thuộc tính gì?
Mối quan hệ trong CoreData được triển khai tương tự như trong cơ sở dữ liệu quan hệ. Mỗi thực thể trong CoreData được biểu diễn bởi một bảng, và chúng ta có thể tạo mối quan hệ giữa các thực thể giống như chúng ta làm với các bảng. Tuy nhiên, đây không chỉ là những mối quan hệ cơ sở dữ liệu quan hệ thông thường. Apple cung cấp một loạt các tính năng thú vị cho mỗi mối quan hệ mà chúng ta sẽ khám phá ở phần sau. Còn theo tài liệu của Apple, đây là các thuộc tính cơ bản mà một mối quan hệ sẽ có.
 Hình 2.
Hình 2. | Thuộc tính | Định nghhĩa |
| Transient |
Quan hệ tạm thời (Transient relationships) không được lưu vào cơ sở dữ liệu. Vì vậy, mối quan hệ tạm thời hữu ích để lưu trữ tạm thời các giá trị được tính toán hoặc suy ra. CoreData theo dõi các thay đổi đối với giá trị của thuộc tính tạm thời cho mục đích hoàn tác. |
| Optional |
Quan hệ không bắt buộc (Optional relationships) không yêu cầu phải có bất kỳ thực thể nào thuộc loại đích. Một mối quan hệ bắt buộc (Required relationship) phải chỉ đến một hoặc nhiều thực thể của loại đích. |
| Destination |
Mỗi quan hệ chỉ từ một thực thể nguồn (thực thể mà bạn đang chỉnh sửa mối quan hệ) đến một thực thể đích. Thực thể đích là một loại liên quan ảnh hưởng và bị ảnh hưởng bởi loại nguồn. Thiết lập cùng một loại nguồn và đích tạo ra một mối quan hệ phản xạ. Ví dụ, một nhân viên có thể quản lý nhân viên khác. |
| Inverse |
Quan hệ đảo ngược (Inverse relationship) cho phép Core Data áp dụng sự thay đổi theo cả hai hướng khi một thực thể của loại nguồn hoặc đích thay đổi. Mọi mối quan hệ đều phải có một mối quan hệ đảo ngược. Khi tạo mối quan hệ trong Graph editor, bạn thêm mối quan hệ đảo ngược giữa các thực thể trong một bước duy nhất. Khi tạo mối quan hệ trong Table editor, bạn thêm mối quan hệ đảo ngược cho từng thực thể một cách riêng lẻ. |
| Delete Rule |
Quy tắc xóa của một mối quan hệ: quy định cách thức của sự thay đổi lan truyền qua các mối quan hệ khi Core Data xóa một thực thể nguồn.
|
| Cardinality Type |
Chỉ ra một mối quan hệ là To-One hoặc To-Many, còn được biết đến như là yếu tố thể hiện mối quan hệ tương quan giữa các thực thể. Sử dụng mối quan hệ To-One để kết nối thực thể nguồn với một thực thể đích duy nhất. Sử dụng mối quan hệ To-Many để kết nối thực thể nguồn với một tập hợp có thể thay đổi của loại đích, và để tùy chọn xác định một cách sắp xếp và số lượng: |
| Index in Spotlight | Bao gồm trường dữ liệu vào chỉ mục Spotlight. Để biết thêm thông tin, xem Core Spotlight. |
Mặc dù không được mô tả chính thức trong tài liệu của Apple, nếu không thiết lập mối quan hệ đảo ngược (Inverse relationship), chúng ta sẽ kết thúc với hai loại mối quan hệ: One-To-Nil và Many-To-Nil. Những loại mối quan hệ này khá khác biệt so với mối quan hệ cơ sở dữ liệu quan hệ. Điều quan trọng là bất kỳ cập nhật nào trong những mối quan hệ này sẽ không phản ánh ở những nơi khác bởi vì chúng thiếu mối quan hệ đảo ngược. Một khía cạnh thú vị của mối quan hệ Many-To-Nil là nó có thể dẫn đến mất dữ liệu nếu không được hiểu rõ. Chúng ta sẽ thảo luận thêm về điều này khi chúng ta đi sâu vào từng loại mối quan hệ cụ thể hơn trong Phần II.B.
Chúng ta đã đề cập đến một số phần cơ bản về mối quan hệ trong CoreData, trong phần tiếp theo chúng ta sẽ xem xét sâu hơn vào từng loại mối quan hệ để hiểu cách sử dụng chúng và cách chúng được triển khai.
II. Mối Quan Hệ trong CoreData: Một Cái Nhìn Cận Cảnh
A. Quan Hệ To-One
Chúng ta thường sử dụng các loại mối quan hệ này để lưu trữ dữ liệu bổ sung cho một thực thể mà khó có thể biểu diễn bằng một thuộc tính đơn lẻ. Hãy xem xét ví dụ sau:
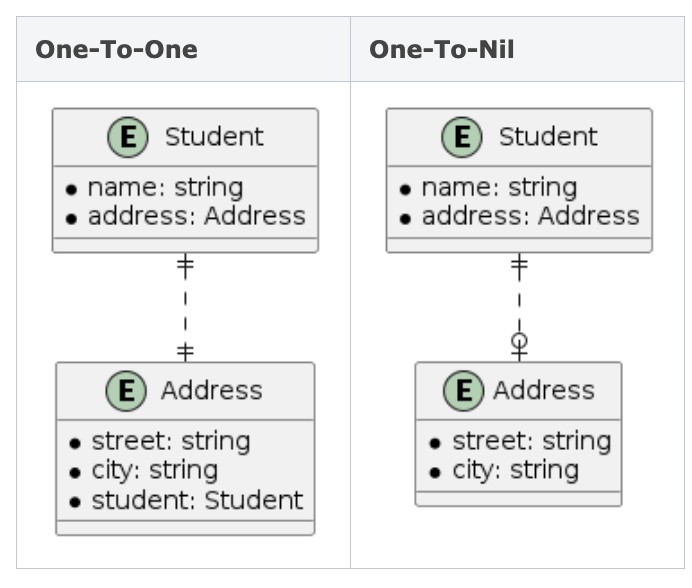
Hình 3. Các loại quan hệ To-One
Sự khác biệt giữa quan hệ One-To-One và quan hệ One-To-Nil là rõ ràng. Trong một mối quan hệ One-To-One, cả hai thực thể Student và Address đều có mối quan hệ To-One. Từ góc độ của CoreData, quan hệ One-To-One có mối quan hệ đảo ngược (Inverse relationship) cho cả thực thể Student và Address. Do đó, bất kỳ thay đổi nào trong mối quan hệ address từ thực thể Student cũng sẽ cập nhật mối quan hệ student trên thực thể Address. Tuy nhiên, trong một quan hệ One-To-Nil, thực thể Address không biết đến thực thể Student và không có cập nhật nào xảy ra.
Dưới đây là cách dữ liệu được lưu trữ trong cơ sở dữ liệu. Thông tin mối quan hệ được lưu trữ dưới dạng một thuộc tính trên bảng Student hoặc Address, làm cho việc hiểu cách CoreData lưu trữ dữ liệu trở nên dễ dàng.
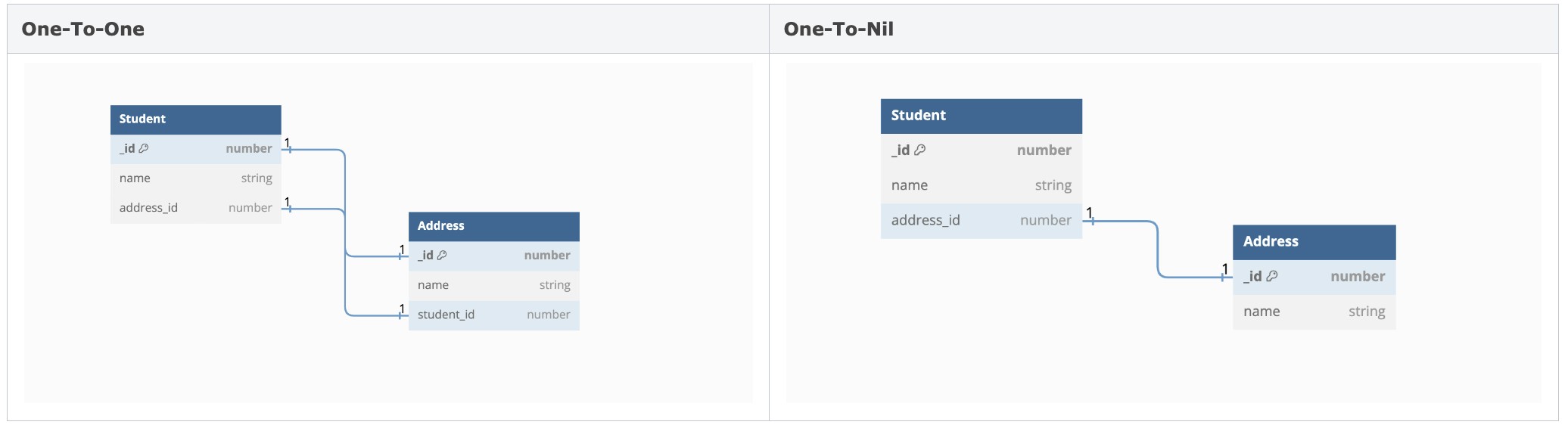
Hình 4. Sơ đồ mối quan hệ To-One (Các sơ đồ được tạo ra với DBDiagramIO)
Ví dụ
Làm thế nào để truy xuất mối quan hệ thông qua việc sử dụng yêu cầu truy xuất (fetch requests)? Hãy xem xét ví dụ sau:
let fetchRequest = NSFetchRequest<Student>(entityName: "Student")
fetchRequest.returnsObjectsAsFaults = false
guard let student = try context.fetch(fetchRequest).first else { return }
print(student.address.name)Ở dòng 3, chúng ta truy xuất các đối tượng Student và lấy phần tử đầu tiên. Tất cả các thuộc tính của Student sẽ được truy xuất trừ mối quan hệ address. Đây là cơ chế fault của CoreData. Thuộc tính address không được truy xuất cho đến khi chúng ta truy cập nó ở dòng 4. Tại thời điểm này, CoreData thực hiện một yêu cầu truy xuất khác để lấy đối tượng Address. Vì vậy, trong khối mã này, thực tế có hai lần truy xuất xảy ra.
- Lần truy xuất đầu tiên được sử dụng cho đối tượng Student
- Lần truy xuất thứ hai được sử dụng cho đối tượng Address
Cơ chế này của CoreData được thiết kế để tối ưu hóa việc sử dụng bộ nhớ, nhưng nó có thể không cung cấp hiệu suất tối ưu trong một số tình huống. Chúng ta sẽ thảo luận thêm về điều này trong Phần III.B.
B. Quan hệ To-Many
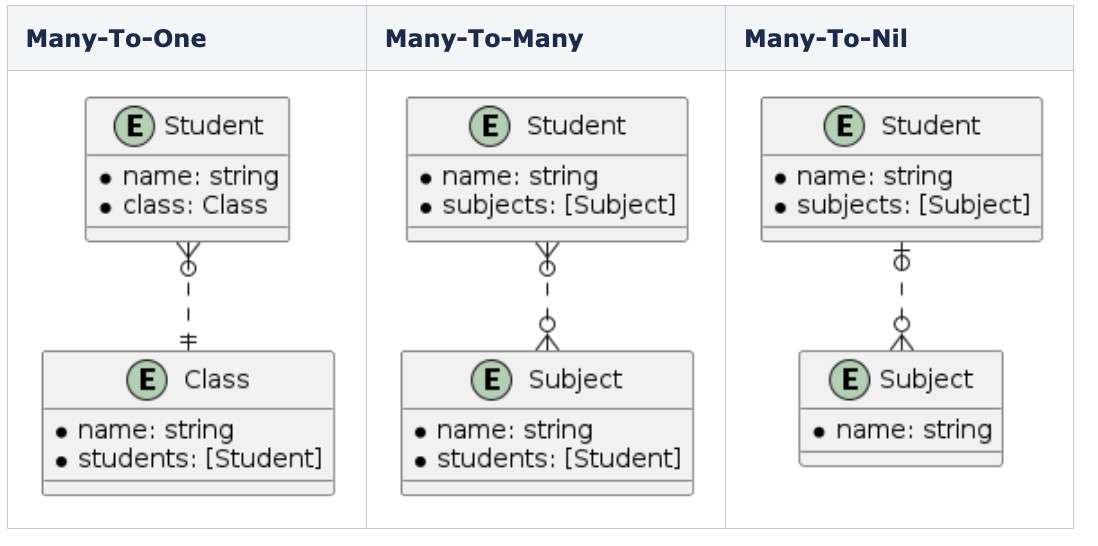
Hình 5. Các loại quan hệ To-Many
Để hiểu các loại quan hệ To-Many, hãy xem xét mối quan hệ giữa các thực thể Student, Class và Subject.
- Một Student sẽ thuộc về một Class và một Class sẽ có nhiều Student. Đây là loại
mốiquan hệ Many-To-One. - Một Student sẽ tham gia nhiều Subject và một Subject có thể có nhiều Student, vì vậy đây là loại quan hệ Many-To-Many. Trong trường hợp chúng ta không thực sự cần quản lý Student trong mỗi Subject, chúng ta có thể loại bỏ mối quan hệ student trên Subject và sau đó chúng ta có loại quan hệ Many-To-Nil (Loại
mốiquan hệ To-Many mà không có mối quan hệ đảo ngược (Inverse relationship)).
Ở cấp độ thực thể, mối quan hệ One-To-Many xuất hiện như một thuộc tính bình thường - đơn giản chỉ là một mảng các phần tử. Thông qua các API của CoreData, chúng ta có thể thực hiện các hoạt động CRUD giống như chúng ta làm với một mảng bình thường. Nhưng liệu nó có thực sự đơn giản như vậy không? Hãy xem xét cách thông tin được lưu trữ dưới cơ sở dữ liệu.
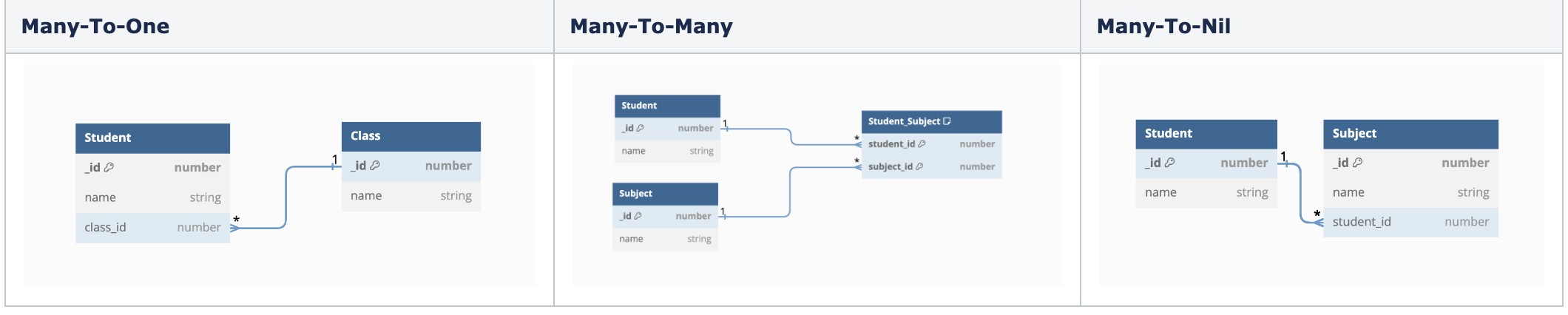
Hình 6. Sơ đồ mối quan hệ To-Many (Chúng tôi không đề cập đến thông tin thứ tự (order) ở đây để đơn giản hóa)
Trong hình trên, chúng ta thấy rằng quan hệ Many-To-One và quan hệ Many-To-Nil có thiết kế rất tương đồng để lưu trữ dữ liệu mối quan hệ. Cả hai đều lưu trữ dữ liệu này trên thực thể đích (destination) của mối quan hệ To-Many. Đối với loại quan hệ Many-To-Many, dữ liệu mối quan hệ được lưu trữ trong một bảng riêng biệt, trong trường hợp này là bảng student_subject. Khi chúng ta lắp đầy dữ liệu mối quan hệ To-Many, chúng ta sẽ tra cứu trong bảng này.
Ví dụ
Để hiểu rõ hơn về cách thức quan hệ One-To-Many hoạt động trong CoreData, hãy xem ví dụ sau:
let fetchRequest = NSFetchRequest<Student>(entityName: "Student")]
fetchRequest.returnsObjectsAsFaults = false
guard let student = try context.fetch(fetchRequest).first else { return }
print(student.subjects.first?.name)Tương tự như ví dụ trước trong Phần II.A, chúng ta truy xuất một đối tượng Student ở dòng 3 và sau đó truy cập mối quan hệ subject ở dòng 4. Dưới đây là những gì xảy ra từ góc độ của CoreData:
- Truy xuất đối tượng Student và lấy phần tử đầu tiên ở dòng 3.
- Truy xuất mối quan hệ subject ở dòng 4. Một số người có thể nghĩ rằng chỉ có một lần truy xuất ở đây nhưng thực tế có hai lần truy xuất.
- Truy xuất các ID đối tượng NSManagedObject của subject để lắp đầy mối quan hệ To-Many (subjects).
- Truy xuất thông tin đầy đủ cho phần tử subject đầu tiên.
Vì vậy, chúng ta có tổng cộng ba lần truy xuất trong khối mã này. Mặc dù điều này hoạt động tốt, nhưng nó không được tối ưu hóa về hiệu suất. Chúng ta có một số phương pháp để giảm số lượng lần truy xuất, mà chúng ta sẽ thảo luận trong Phần III.C.
Một Điểm Khá Thú Vị Về Mối Quan Hệ Many-To-Nil

Đối với quan hệ Many-To-Nil, khi chúng ta có các mục trùng lặp trong quan hệ To-Many, việc lưu dữ liệu vào cơ sở dữ liệu có thể dẫn đến mất dữ liệu. Xcode sẽ hiển thị một cảnh báo cho vấn đề này, nhưng nếu chúng ta không nhận thức được nó, nó có thể gây ra vấn đề lớn cho tính nhất quán của dữ liệu của chúng ta. Hãy xem xét đoạn mã mẫu này:
let subject1 = Subject(context: context, name: "Subject1")
let subject2 = Subject(context: context, name: "Subject2")
let student1 = Student(context: context, name: "Student1", subjects: [subject1])
let student2 = Student(context: context, name: "Student2", subjects: [subject1, subject2])
try? context.save()
print(student1.subjects) // [] <= Mất dữ liệu
print(student2.subjects) // [subject1, subject2]Trong trư��ờng hợp này, chúng ta có thể thấy rằng sau khi lưu, student1 không có bất kỳ subject nào, mặc dù nó nên có subject1. Nếu bạn xem xét lại thiết kế sơ đồ của mối quan hệ Many-To-Nil (Hình 6), bạn có thể xác định nguyên nhân gốc rễ của vấn đề này. Vì vậy, trong hầu hết các trường hợp, chúng ta nên tránh sử dụng quan hệ Many-To-Nil để ngăn chặn mất dữ liệu. Nếu cần thiết, chúng ta có thể xem xét sử dụng quan hệ Many-To-One như một sự thay thế, vì nó có thiết kế tương tự.
Trong một nghiên cứu riêng biệt, chúng tôi đã điều tra hiệu suất của quan hệ Many-To-Nil và Many-To-One. Chúng tôi đã thử nghiệm với các bộ dữ liệu khác nhau và đo thời gian mất cho việc chèn và truy vấn. Kết quả thử nghiệm được mô tả trong hình dưới đây.
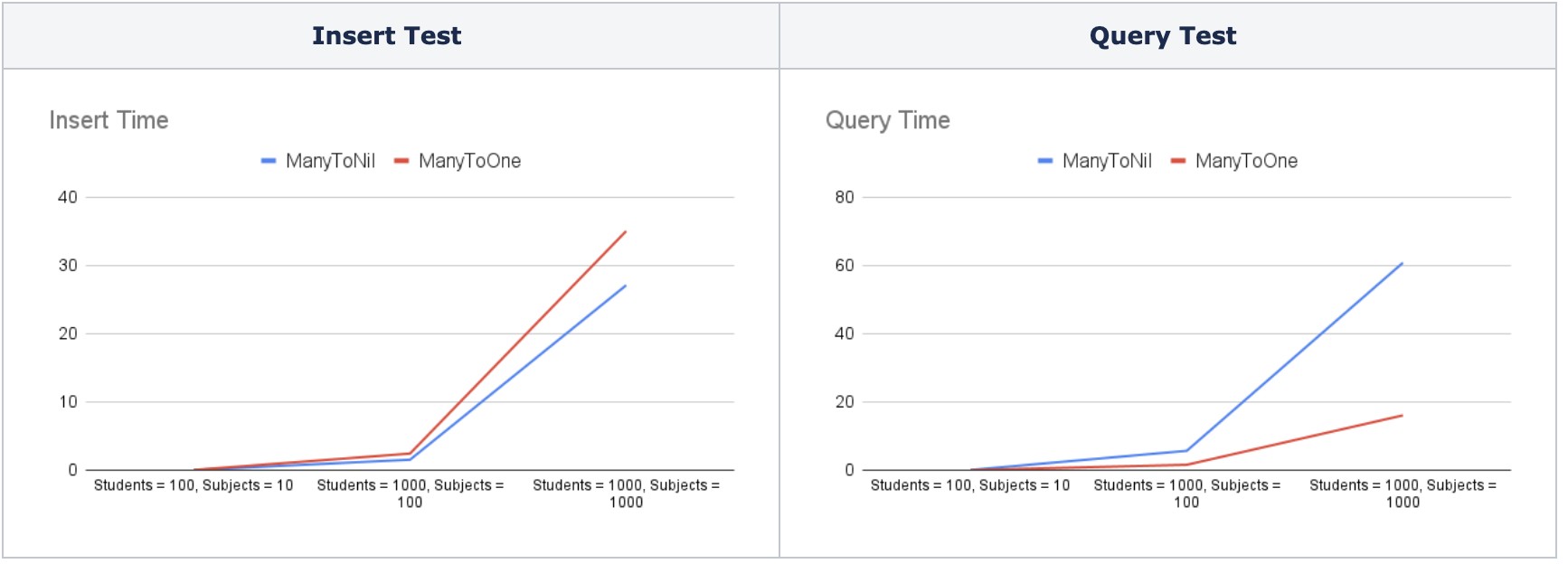
Hình 7. Các bài kiểm tra hiệu suất của mối quan hệ Many-To-Nil và Many-To-One
Chúng tôi nhận thấy rằng không có nhiều sự khác biệt về thời gian insert giữa các mối quan hệ này, với quan hệ Many-To-Nil kết quả tốt hơn một chút. Về thời gian query, quan hệ Many-To-One hoạt động tốt hơn Many-To-Nil, đặc biệt là với các bộ dữ liệu lớn hơn. Tuy nhiên, một điều cần xem xét đối với mối quan hệ Many-To-One là các mối quan hệ đảo ngược (Inverse relationship). Khi chúng ta cập nhật một bên của mối quan hệ, bên đảo ngược cũng được cập nhật. Điều này có thể gây ra vấn đề về bộ nhớ nếu chúng ta đang xử lý một bộ dữ liệu rất lớn.
Chúng tôi không chắc chắn tại sao Apple lại chọn triển khai mối quan hệ Many-To-Nil theo cách này. Tuy nhiên, nếu họ sửa đổi thiết kế bảng tương tự thiết kế của quan hệ Many-To-Many, nó có thể giải quyết vấn đề. Đây chỉ là những suy đoán của chúng tôi, nhưng chúng tôi tin rằng họ đã lựa chọn như vậy vì những lý do sau:
- Tái sử dụng triển khai của
mốiquan hệ Many-To-One khi triển khai CoreData. - Khuyến khích không sử dụng
mốiquan hệ Many-To-Nil. Trong quá trình phát triển, chúng ta nên xem xét sử dụng quan hệ Many-To-One hoặc Many-To-Many để thay thế.
Trong phần này, chúng ta đã thảo luận về từng loại quan hệ và cách chúng được triển khai. Chúng tôi cũng đã chỉ ra một vấn đề tiềm ẩn có thể xảy ra nếu những khái niệm này không được hiểu rõ. Trong phần tiếp theo, chúng ta sẽ đi sâu vào các trường hợp cụ thể và thảo luận về các phương pháp hay nhất. Những điều này không chỉ liên quan đến mối quan hệ mà còn đến các trường hợp sử dụng CoreData phổ biến.
III. Những Lỗi Thường Gặp Và Các Làm Tốt Nhất
A. Bỏ Qua Quan Hệ Đảo Ngược (Inverse Relationship)
Quan hệ đảo ngược trong CoreData là mối quan hệ từ một thực thể trở lại một thực thể khác. Ví dụ, nếu một thực thể Class có mối quan hệ với một thực thể Student (một Student trong một Class), thì nên có một mối quan hệ đảo ngược từ Student trở lại Class (một Class được tham gia bởi một Student).
Bỏ qua mối quan hệ đảo ngược là một lỗi phổ biến mà các nhà phát triển thường mắc phải khi làm việc với CoreData, và nó có thể dẫn đến sự không nhất quán và hành vi không mong đợi trong mô hình dữ liệu của bạn.
Tại sao quan hệ đảo ngược lại quan trọng? Dưới đây là một số lý do:
Tính Toàn Vẹn Dữ Liệu: Quan hệ đảo ngược giúp duy trì tính toàn vẹn dữ liệu bằng cách đảm bảo rằng những thay đổi được thực hiện trên một bên của mối quan hệ được phản ánh trên bên kia. Ví dụ, nếu bạn xóa một đối tượng Class mà có chứa một đối tượng Student, mối quan hệ đảo ngược đảm bảo rằng thuộc tính class của đối tượng Student sẽ được thiết lập thành nil.
Hiệu Suất: CoreData sử dụng mối quan hệ đảo ngược để duy trì sự nhất quán của đồ thị, điều này có thể cải thiện hiệu suất. Khi bạn thiết lập một bên của mối quan hệ, CoreData tự động thiết lập mối quan hệ đảo ngược cho bạn, có thể giúp bạn tiết kiệm thời gian từ việc phải cập nhật thủ công bên đảo ngược.
Kiểm Định: CoreData sử dụng mối quan hệ đảo ngược để thực hiện kiểm định mối quan hệ. Nếu bạn không thiết lập mối quan hệ đảo ngược, CoreData có thể không thể kiểm định dữ liệu của bạn một cách chính xác.
Yêu Cầu Truy Xuất: Quan hệ đảo ngược có thể làm cho yêu cầu truy xuất dữ liệu hiệu quả hơn. Ví dụ, nếu bạn muốn tìm tất cả Student thuộc một Class cụ thể, việc có mối quan hệ đảo ngược từ Class đến Student có thể làm cho nhiệm vụ này dễ dàng và hiệu quả hơn.
Cách Làm Tốt Nhất
Duy trì sử dụng quan hệ đảo ngược trong CoreData là điều rất quan trọng để nhằm đảm bảo tính toàn vẹn dữ liệu, tối ưu hóa hiệu suất và thực hiện các yêu cầu truy xuất dữ liệu một cách hiệu quả. Dưới đây là một số phương pháp hay nhất cho việc quản lý mối quan hệ đảo ngược:
Định nghĩa mối quan hệ đảo ngược: Khi định nghĩa quan hệ trong CoreData, thông thường được khuyến nghị cũng định nghĩa mối quan hệ đảo ngược. Phương pháp này giúp CoreData duy trì tính toàn vẹn và nhất quán trong đồ thị đối tượng của bạn. Tuy nhiên, điều quan trọng cần lưu ý là không phải lúc nào cũng cần thiết phải tạo thêm mối quan hệ chỉ để định nghĩa mối quan hệ đảo ngược, đặc biệt nếu mối quan hệ chỉ tồn tại trên một bên của thực thể.
Lấy ví dụ, mối quan hệ giữa một Student và thực thể Address. Một học sinh có thể có một address, do đó thiết lập mối quan hệ To-One với thực thể Address. Trong trường hợp này, nếu không cần truy cập student từ thực thể Address (nói cách khác, Address không cần biết nó thuộc về Student nào), không có yêu cầu nghiêm ngặt nào để định nghĩa mối quan hệ này và thiết lập mối quan hệ đảo ngược.
Sử dụng quy tắc xóa đúng đắn: Tùy thuộc vào bản chất của mối mỗi loại quan hệ, hãy thiết lập quy tắc xóa phù hợp. Ví dụ, đối với mối quan hệ One-To-One, bạn có thể muốn chọn Nullify để khi đối tượng nguồn bị xóa, tham chiếu đến đối tượng đích được thiết lập thành nil. Đối với mối quan hệ One-To-Many, Cascade có thể phù hợp hơn, nó xóa tất cả các đối tượng đích khi đối tượng nguồn bị xóa.
Cập nhật cả hai bên của mối quan hệ: Khi bạn chỉnh sửa một bên của mối quan hệ, hãy đảm bảo rằng bên đảo ngược cũng được cập nhật. Mặc dù CoreData tự động duy trì mối quan hệ đảo ngược khi bạn chỉnh sửa một bên, nhưng việc cập nhật thủ công cả hai bên là một phương pháp hay để làm cho ý định của bạn rõ ràng trong mã lệnh.
Tận dụng quan hệ đảo ngược trong yêu cầu truy xuất: Sử dụng mối quan hệ đảo ngược để làm cho yêu cầu truy xuất của bạn hiệu quả hơn. Ví dụ, nếu bạn có một thực thể Class và một thực thể Student với mối quan hệ đảo ngược được định nghĩa, bạn có thể dễ dàng truy xuất tất cả Student thuộc về một Class hoặc tìm Class của một Student cụ thể.
Kiểm định mối quan hệ: Đảm bảo rằng mối quan hệ (và mối quan hệ đảo ngược) của bạn hợp lệ khi lưu xuống context. CoreData có thể báo lỗi nếu mối quan hệ của bạn không hợp lệ, vì vậy việc kiểm định dữ liệu trước khi lưu là quan trọng. Ví dụ, nếu một mối quan hệ được đánh dấu là Non-Optional (nói cách khác, nó là bắt buộc), nhưng mối quan hệ đó là null, CoreData sẽ coi đây là không hợp lệ.
Bằng cách tuân thủ những phương pháp hay này, bạn có thể duy trì mối quan hệ đảo ngược một cách hiệu quả, đảm bảo tính toàn vẹn dữ liệu, cải thiện hiệu suất và làm cho yêu cầu truy xuất dữ liệu hiệu quả hơn trong việc sử dụng CoreData của bạn.
Một Trường Hợp Sử Dụng Thực Tế
Trong cơ sở dữ liệu LINE, chúng tôi có các thực thể Chat và Message. Một cuộc trò chuyện (chat) sẽ có nhiều tin nhắn (messages) và một tin nhắn sẽ thuộc về một cuộc trò chuyện. Trong trường hợp này, nếu chúng ta nhìn từ thực thể Chat, chúng ta sẽ có loại mối quan hệ One-To-Many. Mối quan hệ giữa chúng có thể được mô tả trong sơ đồ dưới đây.
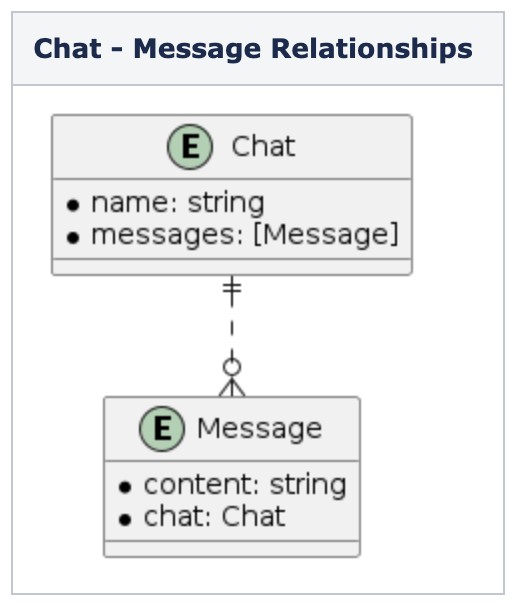 Thông thường, khi chúng ta muốn xóa một cuộc trò chuyện (chat), chúng ta cần thực hiện thêm các thao tác xóa trên các tin nhắn (messages), đúng không? Thay vì làm điều đó một cách thủ công, chúng ta sử dụng các Quy tắc Xóa phù hợp và thiết lập Mối Quan Hệ Đảo Ngược cho mỗi quan hệ. Mối quan hệ messages trên thực thể chat và mối quan hệ chat trên thực thể message sẽ có các Quy tắc Xóa Cascade và Nullify tương ứng. Vì vậy, khi chúng ta xóa một cuộc trò chuyện, CoreData sẽ thực hiện xóa các tin nhắn theo và chúng ta không cần phải thực hiện bất kỳ công việc phụ trội nào.
Thông thường, khi chúng ta muốn xóa một cuộc trò chuyện (chat), chúng ta cần thực hiện thêm các thao tác xóa trên các tin nhắn (messages), đúng không? Thay vì làm điều đó một cách thủ công, chúng ta sử dụng các Quy tắc Xóa phù hợp và thiết lập Mối Quan Hệ Đảo Ngược cho mỗi quan hệ. Mối quan hệ messages trên thực thể chat và mối quan hệ chat trên thực thể message sẽ có các Quy tắc Xóa Cascade và Nullify tương ứng. Vì vậy, khi chúng ta xóa một cuộc trò chuyện, CoreData sẽ thực hiện xóa các tin nhắn theo và chúng ta không cần phải thực hiện bất kỳ công việc phụ trội nào.
B. Không Tận Dụng Faulting
Faulting là một cơ chế của CoreData giúp quản lý việc sử dụng bộ nhớ bằng cách chỉ tải các đối tượng vào bộ nhớ khi cần thiết. Không tận dụng cơ chế này là một sai lầm phổ biến có thể dẫn đến các vấn đề quản lý bộ nhớ.
Ví dụ, nếu bạn truy xuất một số lượng lớn đối tượng mà không sử dụng faulting, tất cả các đối tượng này và thuộc tính của chúng sẽ được tải vào bộ nhớ, có thể dẫn đến việc sử dụng bộ nhớ cao và các sự cố liên quan đến bộ nhớ tiềm ẩn.
Cách Làm Tốt Nhất
Tận dụng faulting là một phương pháp hay khi làm việc với CoreData. Dưới đây là cách bạn có thể thực hiện:
Batch fetching (Truy xuất theo lô): Thay vì truy xuất tất cả các đối tượng cùng một lúc, hãy truy xuất chúng theo từng lô. Điều này cho phép CoreData 'fault out' các đối tượng không nằm trong lô hiện tại, giảm việc s�ử dụng bộ nhớ.
Prefetching: Nếu bạn dự đoán sẽ truy cập các mối quan hệ của một đối tượng, hãy truy xuất trước những mối quan hệ đó trong lúc thực hiện yêu cầu truy xuất. Điều này có thể ngăn chặn việc một số lượng lớn fault được kích hoạt cùng lúc, từ đó cải thiện hiệu suất. Từ iOS 13 trở đi, Apple đã thêm một tính năng mới vào CoreData gọi là derived attributes, cung cấp một cách vô cùng hữu ích và hiệu quả để truy xuất trước số lượng các mối quan hệ To-Many.
Faulting và uniquing: Hiểu cách faulting và uniquing làm việc cùng nhau. CoreData đảm bảo rằng, cho bất kỳ bối cảnh đối tượng được quản lý nào, không bao giờ có nhiều hơn một đối tượng được quản lý đại diện cho một bản ghi cụ thể. Điều này có thể giúp giảm việc sử dụng bộ nhớ. Để biết thêm thông tin, vui lòng kiểm tra tài liệu từ Apple.
Bằng cách tận dụng faulting, bạn có thể quản lý việc sử dụng bộ nhớ một cách hiệu quả hơn và cải thiện hiệu suất của các hoạt động CoreData. Hiểu cách và khi nào sử dụng faulting là một kỹ năng quan trọng khi làm việc với CoreData.
Một Trường Hợp Sử Dụng Thực Tế
Trên màn hình Danh sách Trò chuyện (Chat List) của ứng dụng LINE, khi truy xuất các mục trò chuyện, chúng ta thực hiện một yêu cầu truy xuất để lấy tất cả các mục trò chuyện và hiển thị chúng lên một UITableView. Nếu không sử dụng Batching Fetching, CoreData sẽ di chuyển tất cả các mục trò chuyện vào bộ nhớ cache. Điều này không chỉ chiếm dụng bộ nhớ, mà còn mất thời gian và tiêu tốn năng lượng. Vì vậy, trong trường hợp này, chúng tôi sử dụng Batching Fetching để đạt được hiệu suất tốt nhất. Dưới đây là một đoạn mã giả của yêu cầu truy xuất:
let fetchRequest: NSFetchRequest<Chat> = NSFetchRequest<Chat>(entityName: "Chat")
fetchRequest.fetchBatchSize = <appropriate size>
fetchRequest.returnsObjectsAsFaults = falseXin lưu ý rằng khi chúng ta sử dụng phương pháp lấy Batching Fetching, chúng ta nên đặt `returnsObjectsAsFaults` thành `false`. Nếu không, các đối tượng sẽ là faults; dữ liệu chỉ được kéo vào bộ nhớ đệm dòng, và sau đó mới được kéo vào bối cảnh khi truy cập các thuộc tính của từng đối tượng.
Ngoài ra, trên màn hình danh sách trò chuyện, trước đây chúng tôi không áp dụng phương pháp prefetching cho các mối quan hệ, điều này dẫn đến nhiều lần lấy dữ liệu gây ảnh hưởng đến hiệu suất trong quá trình lấy các thực thể Chat.
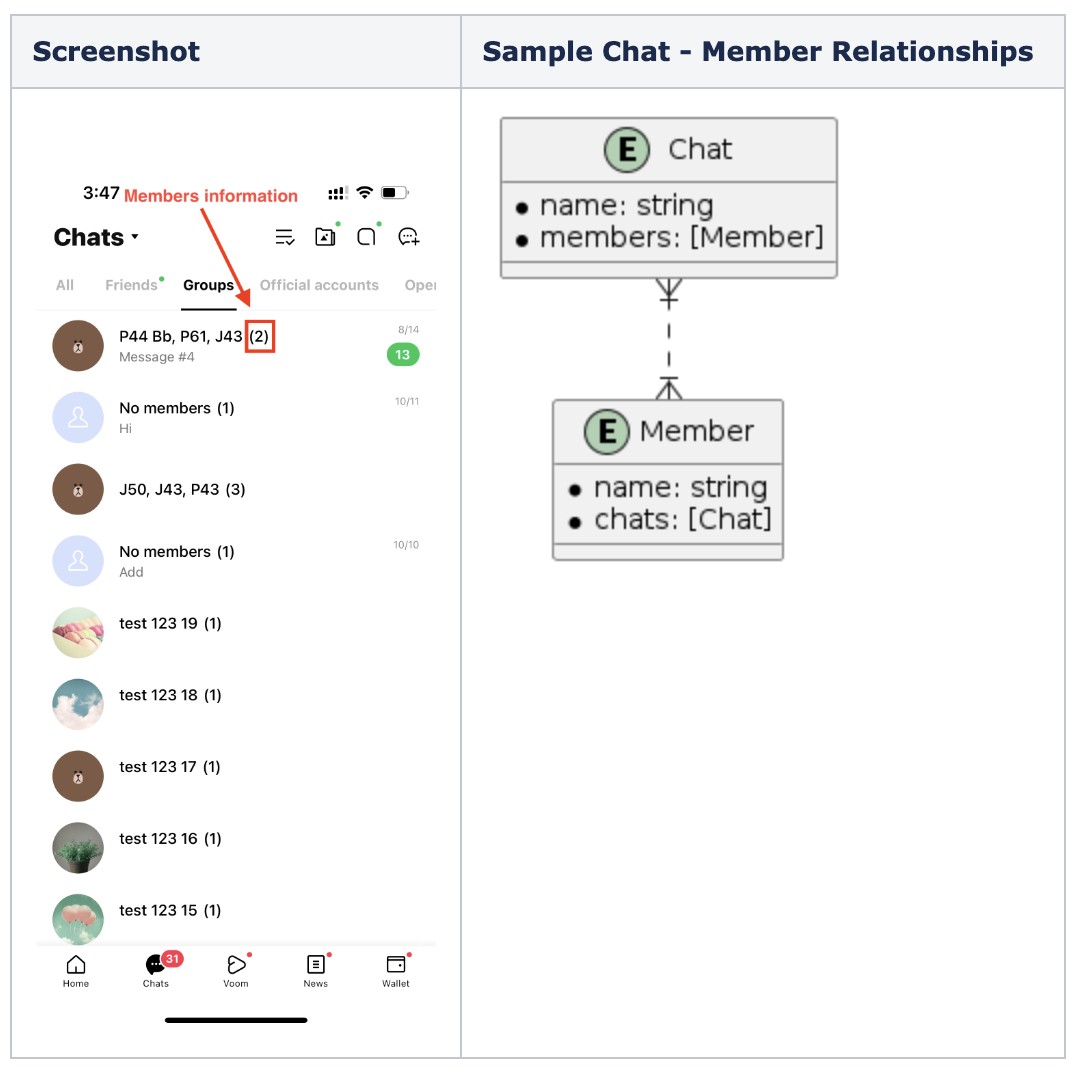
Trong trường hợp này, chúng ta có thực thể Chat và Member (một Chat có nhiều Member). Khi hiển thị một Chat, chúng ta muốn hiển thị số lượng Member, vì vậy chúng ta sử dụng mối quan hệ members trên thực thể Chat. Điều này gây ra fetch faults cho tất cả Member của một Chat và làm tăng đáng kể thời gian lấy dữ liệu.
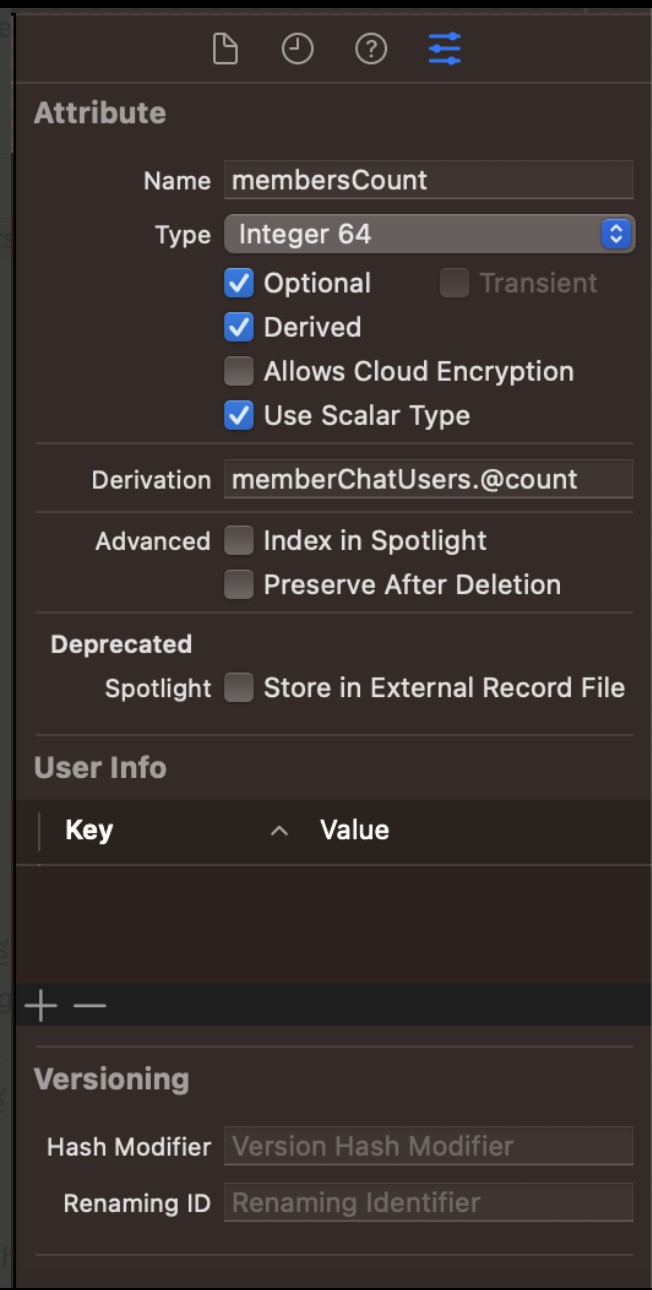
Để giảm số lượng fetch faults, chúng ta có thể áp dụng kỹ thuật prefetching ở đây bằng cách tạo một derived attribute có tên là membersCount trên thực thể Chat. Điều này cho phép CoreData lấy số lượng Member khi lấy một Chat, giúp chúng ta tiết kiệm một lượng thời gian lấy dữ liệu đáng kể. Dưới đây là cách chúng ta thực hiện:
- Mở xcdatamodel
- Chọn thực thể Chat
- Tạo thuộc tính membersCount và đặt kiểu là Integer 64
- Mở kiểm tra thuộc tính membersCount
- Đặt Derived ở trạng thái bật và Derivation = memberChatUsers.@count, nơi memberChatUsers là mối quan hệ To-Many
C. Làm phức tạp quá mức các yêu cầu lấy dữ liệu
Yêu cầu lấy dữ liệu (fetch requests) được sử dụng trong CoreData để truy xuất dữ liệu phù hợp với các điều kiện nhất định. Một sai lầm phổ biến là làm cho những yêu cầu lấy dữ liệu này trở nên quá phức tạp, có thể ảnh hưởng đến hiệu suất và làm cho mã nguồn khó hiểu và bảo trì hơn.
Ví dụ, việc sử dụng các điều kiện phức tạp (complex predicates), lấy quá nhiều dữ liệu cùng một lúc, hoặc không tận dụng các tính năng của CoreData như batching và sắp x��ếp (sorting) có thể dẫn đến các yêu cầu lấy dữ liệu không hiệu quả. Điều này có thể dẫn đến hiệu suất chậm và sử dụng bộ nhớ cao hơn, nhất là khi xử lý một lượng lớn dữ liệu.
Cách Làm Tốt Nhất
Việc đơn giản hóa các yêu cầu lấy dữ liệu là một phương pháp hay nhất khi làm việc với CoreData. Dưới đây là cách bạn có thể thực hiện:
Sử dụng Điều kiện Đơn Giản: Hãy giữ cho các điều kiện (predicates) của bạn càng đơn giản càng tốt. Càng phức tạp các điều kiện của bạn, CoreData phải làm việc càng nhiều để lấy dữ liệu.
Chỉ Lấy Dữ Liệu Cần Thiết: Thay vì lấy tất cả các đối tượng, chỉ lấy dữ liệu bạn cần. Bạn có thể làm điều này bằng cách đặt giới hạn cho yêu cầu lấy dữ liệu của bạn, hoặc sử dụng các điều kiện để lọc dữ liệu.
Sử dụng Batching: Nếu bạn đang xử lý nhiều dữ liệu, hãy sử dụng phân lô để lấy dữ liệu theo số lượng nhỏ. Điều này có thể giúp quản lý việc sử dụng bộ nhớ và cải thiện hiệu suất.
Sử dụng Sắp Xếp: Nếu bạn cần dữ liệu theo một thứ tự cụ thể, hãy sử dụng các mô tả sắp xếp trong yêu cầu lấy dữ liệu của bạn. CoreData thường có thể sắp xếp dữ liệu hiệu quả hơn là thực hiện nó trong bộ nhớ sau khi lấy dữ liệu.
Bằng cách đơn giản hóa các yêu cầu lấy dữ liệu của bạn, bạn có thể cải thiện hiệu suất, giảm việc sử dụng bộ nhớ và làm cho mã nguồn CoreData của bạn dễ hiểu và bảo trì hơn.
Ví dụ
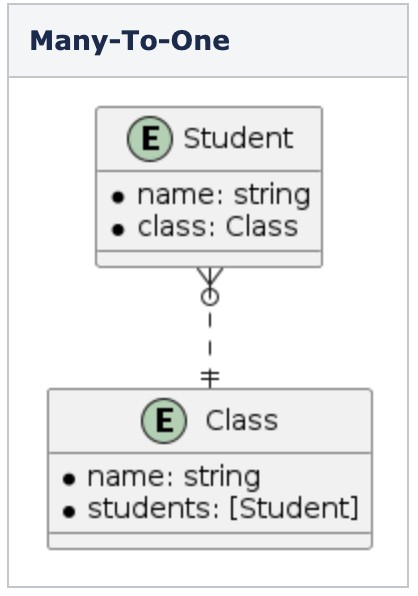
Hãy quay lại quan hệ Many-To-One của thực thể student và class (Hình 5). Nếu chúng ta muốn tìm một student trong một class với một tên cụ thể, chúng ta sẽ có hai lựa chọn:
| Lựa chọn 1: Sử dụng thuộc tính students trên đối tượng Class | Lựa chọn 2: Thực hiện một yêu cầu lấy dữ liệu trên thực thể Student | |
| Mã giả |
|
|
| Luồng lấy dữ liệu | 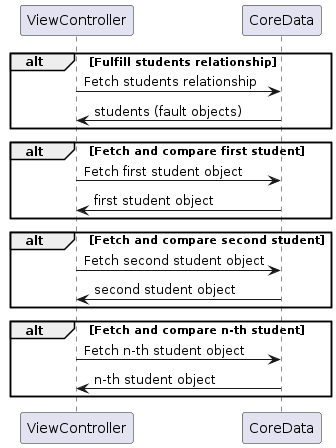 | 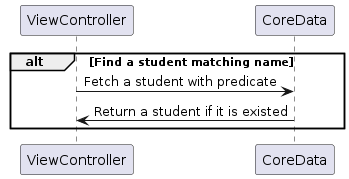 |
Lựa chọn 1 sẽ kích hoạt hai cấp độ lấy dữ liệu để thực hiện các faults. Cấp độ lấy dữ liệu đầu tiên sẽ thực hiện mối quan hệ students, điều này sẽ trả về một mảng các đối tượng Student dạng fault. Cấp độ lấy dữ liệu thứ hai sẽ thực hiện cho từng đối tượng Student khi chúng ta lặp qua chúng và so sánh với tên mục tiêu. Vì những lần lấy dữ liệu này, nó sẽ tốn khá nhiều thời gian đi lại giữa ViewController và CoreData, điều này sẽ dẫn đến thời gian lấy dữ liệu lâu hơn. Nếu so sánh với Lựa chọn 2, sẽ chỉ có một lần lấy dữ liệu, vì vậy nói chung, Lựa chọn 2 sẽ tốt hơn cho trường hợp này.
IV. Kết Luận
Kết luận, CoreData là một thư viện cơ sở dữ liệu mạnh mẽ và toàn diện, cung cấp nhiều hơn là chỉ những thao tác CRUD cơ bản. Các tính năng nâng cao của nó, đặc biệt là các mối quan hệ, cung cấp cho các nhà phát triển iOS những công cụ mạnh mẽ để xử lý cấu trúc dữ liệu phức tạp một cách hiệu quả. Tuy nhiên, để thực sự tận dụng những khả năng này, việc hiểu sâu về mối quan hệ trong CoreData là rất quan trọng.
Trong quá trình khám phá này, chúng ta đã đi sâu vào những chi tiết của mối quan hệ trong CoreData, từ các khái niệm cơ bản đến các chủ đề nâng cao, những lỗi thường gặp và các cách làm hay nhất. Chúng ta đã học được tầm quan trọng của việc duy trì mối quan hệ đảo ngược, hiểu và áp dụng các quy tắc xóa, tận dụng faulting để quản lý bộ nhớ, và đơn giản hóa các yêu cầu lấy dữ liệu để tối ưu hóa hiệu suất. Chúng tôi hy vọng rằng những hiểu biết này cũng sẽ có giá trị với bạn.
Happy coding!