こんにちは。LINEアプリ開発SBU AIディベロッパーエクスペリエンスチームの onevcat(王 巍)です。最近は、AI エージェントを開発・検証のループに組み込むためのツールづくりに取り組んでいます。
この記事�では、私たちが開発しオープンソースとして公開した sim-use というツールを題材に、モバイル開発で「エージェントによる検証」を成立させるための技術選定と、いくつかの設計上の工夫を紹介します。
ここ半年でエージェントを使ってコードを書いたことがあるなら、おそらくこのループを経験しているはずです。
プロンプトを書く → エージェントが成果物を出す → 自分でアプリを動かす
→ 検証 / スクリーンショット / エージェントに不満を伝える
→ エージェントが修正する → また動かす → またスクショを撮る …「コードを書く」という作業は、多くの部分をすでにエージェントが引き受けています。しかし、UI アプリにとって「検証」の正しさを確かめることは特に難しいのです。エージェントは数分でそれらしい Swift や Kotlin を大量に吐き出せますが、書き終えてもせいぜいユニットテストを走らせる程度で、そこで止まってしまいます。あなたが実行し、目で見て、どこが間違っているかを伝えるのを待ち、そのフィードバックをもとに修正するわけです。これはかなり非効率な開発のやり方です。
この記事で取り上げるのは、まさにこの問題に対して私たちが作ったツール sim-use です。これはクロスプラットフォームの CLI で、エージェントが iOS と Android の上で効率的かつ正確に「画面を見る・要素をタップする・結果を検証する」ことを可能にします。すでにオープンソースとして公開しています。
まずはなぜこれに取り�組む価値があるのかをお話しし、そのうえで 5 つの技術的な判断を通じて、内部の(少し面白いけれど自明ではない)設計や詳細について語っていきます。
1. 背景:エージェント時代における、コード生産と製品検証の乖離
業界には、あるざっくりとした、しかし無視できない見立てがあります。今後 5 年間で生み出されるコード量は、過去すべての年の合計を上回るというものです。この数字を信じるかどうかはともかく、方向性は明確です。エージェントはソフトウェア開発の「生産」側を急速に飲み込みつつあります。
しかし「生産」は開発ループの半分にすぎません。コードは検証を経て初めて製品になります。従来の検証のやり方(エンジニアが手で触って確かめる、CI で機能テストを走らせる、リリース前に QA チームがテストする)は、もともと開発プロセスの中で最もコストが高く、最も遅い部分でした。上流のコード生成が 10 倍に加速すれば、下流の検証のボトルネックは 10 倍に拡大されます。
さらに厄介なことに、モバイルアプリ開発においては、成熟したツールチェーンの不足に加え、モバイルプラットフォーム自体が Web より閉じているため、この問題はいっそう大きくなります。
1.1 フロントエンドエージェントの「ズル」とも言える優位性
Web をやっている方なら、エージェントがフロントエンドでは検証のループをそれなりにうまく閉じられると感じているでしょう。理由はとてもシンプ�ルです。
- エージェントは DOM を労せず直接手に入れられます。構造化され、走査可能で、それ自体が意味を持つ一本のツリーです。
- ブラウザには成熟した自動化ツール(Playwright、Puppeteer など)があり、セレクタが安定しています。
- コンソールログやネットワークリクエストなど、あらゆるシグナルがテキストとして読めます。
DOM はそれ自体がエージェントにとっての「天然のコーパス」です。<button id="login"> のようなものは視覚的な理解を必要としません。それはすでに構造化されたデータなのです。エージェントはコードを書いたら、自分で動かし、自分でクリックし、自分で確認できます。ループがとても短いのです。
1.2 モバイルの「ブラックボックス」という事情
モバイルに移ると、問題はたちまち様変わりします。
- iOS も Android も比較的閉じた環境で、外部に公開された「DOM 相当物」がありません。
- 現在、世の中で見かける 2 種類のアプローチには、それぞれ特徴や強みがありますが、まだ十分に応えきれていないニーズも存在します。
- スクリーンショット + マルチモーダルモデル:高価で遅く、ロングテールなコントロールの認識能力には限界があり、タップ座標をスクリーンショットから計算するため簡単にずれて不安定で、しかもマルチモーダルの呼び出しコストが大きく膨らみます。
- UI ツリーをダンプしてエージェントに見せる:UIAutomator / AccessibilityService / iOS の AX API は、生の出力がすぐに数十、ときには数百 KB の JSON になり、使い方を誤るとトークン消費が驚くほど膨らみ、しかもしばしば UI 要素が取得できません(この点は後で詳しく述べます)。
結果として、エージェントは画面がはっきり見えなければ自分で検証できず、自分で検証できなければ、開発者はあの「プロンプトを書き、成果物を待ち、人力でアプリを動かす」非効率なループに引き戻されてしまいます。
「エージェントに、アプリに対する視覚と操作の能力を、効率的・正確・確実・高速に持たせる」ことは、エージェントがどこまで検証を引き受けられるかをほぼ決定づけ、実際の開発における速度の上限をも決めます。私たちは、これがこれからのソフトウェア開発の時代において、最も取り組む価値のある課題の一つだと考えています。このループがいったん回り始めれば、エージェント開発がより本格的になります。
これが sim-use が解こうとしている問題です。
2. sim-use とは何か
sim-use はクロスプラットフォームの CLI で、エージェントが人間と同じように iOS シミュレータや Android エミュレータ / 実機を操作できるようにするものです。
主に 4 つのことを行います。
- 見る:アプリの現在の画面を、コンパクトでエージェントにやさしいテキスト形式(私たちは
outlineと呼んでいます)に翻訳します。 - タップする:outline 内の
@N、#idといった短いセレクタを通じて、エージェント(と人間)の双方が要素を簡単に選択し、インタラクションを発火で��きます。 - 文字入力 / ジェスチャー / スクリーンショット / 画面録画 / マルチタッチ / キーイベント……あらゆる操作と証拠の保全をカバーする一通りのコマンドを提供し、エージェントの監査や他システムへの接続のためのインターフェースも用意しています。
- クロスプラットフォーム:iOS と Android で同じコマンド、同じセレクタ、同じ JSON 出力形式を使うので、同じ検証を複数のプラットフォームで再利用できます。
ツールの全体構成は、処理を高速化する常駐 daemon を備えた Swift 製の macOS 向け CLI を中心に、2 つのプラットフォームをそれぞれ次のように駆動します。iOS 側は Facebook の idb(FBSimulatorControl)経由でシミュレータに接続し、UI の観測は CoreSimulator の AccessibilityPlatformTranslation から accessibility tree を取得し、入力は HID イベントの注入で行います。Android 側は、デバイス上で AccessibilityService を走らせて adb forward 経由で HTTP API を公開する bridge APK を通じて操作します。
実際の使用イメージは以下の通りです。
sim-use ui --device <iOS-UDID-or-Android-emulator># 出力
App: LINE Dev 402x874
[Top y<120]
@6 Button "Keep memo" #keepButton
@7 Button "Notifications" #notificationButton
…
[Content y=120..754]
@10 Button "Sato's profile"
@12 Image "Profile image" #profileView
…
[Bottom y>=754]
@39 RadioButton "Home" #homeTab selected
@40 RadioButton "Chats, 22 new items" #chatTab
@41 RadioButton "Shopping" #commerceTab
@42 RadioButton "News" #newsTab
@43 RadioButton "MINI" #miniTab多くの場合、1 つの画面はわずか数百トークンに圧縮されるため、エージェントは一瞬で画面構成を把握できます。テキストで UI を把握し、操作を実行します。
sim-use tap "@10"
sim-use type "hello world"
sim-use swipe --from-x 200 --from-y 800 --to-x 200 --to-y 400
sim-use record-video --output ./demo.mp4最後に、もう一度 ui コマンドで新しい画面の状態を取得し、アサーションと次の操作を行います。目的を達成するか、必要な検証の証拠を得るまで、これを繰り返します。
この記事では、sim-use の使い方を浅く紹介するつもりはありません。その裏側にある、私たちが共有する価値があると考えた「技術的な意思決定」と「実装の詳細」について、深く掘り下げていきたいと思います。
3. 技術の舞台裏(その一):Outline —— エージェントのために用意した「方言」
エージェントがまず必要とするのは「画面を見る」ことです。最も直感的なやり方は、accessibility tree をまるごと JSON にダンプして渡すことです。構造は明快で、内容も完全、パースも簡単です。私たちも最初はそうしていました。LINEニュースのページで初めて試すまでは。返ってきたのは 24 KB、pretty-print で 1,600 行あまりの JSON でした。
24 KB は普通のエンジニアリングでは何でもありませんが、エージェントにとっては厄介です。一度の検証ループの中で sim-use ui は何十回も呼ばれ、その出力が毎回コンテキストに混ぜ込まれます。2、3 ス�テップも進めば、コンテキストは UI ツリーで膨れ上がり、そのノイズによってエージェントはそれまでの会話を忘れ始めます。賢いエージェントなら、何度かこういう目に遭ったあとで head を通したりスクリプトを書いてデータを整形したりするかもしれませんが、それも特定のコンテキスト構造(あらかじめ定義された skill など)やエージェントの自己修正に依存します。エージェントに快適な作業環境を用意することこそ、効率的に問題を処理させるための鍵なのです。
そこで私たちは CLI レイヤーで、outline と呼ぶコンパクトなテキスト DSL の出力を作りました。同じ LINEニュースのページが、ダンプすると 1.2 KB、30 行足らずになり、トークン消費は元の 1/20 に抑えられます。実際の出力イメージは以下の通りです。
[Top y<120]
@1 Button "Back" (24,60 88x44)
@2 StaticText "News" (152,68 96x28)
[Content y=120..H-120]
@3 #1 Cell "Top story headline …" (0,120 393x180)
@4 #2 Cell "Second story …" (0,308 393x180)
…
[Bottom y≥H-120]
@9 Button "Tab Home" (0,790 98x44)
3.1 単なる圧縮ではない —— Outline の設計原則
Outline は単なる圧縮ではありません。「JSON を小さくする」という目的ももちろんありますが、より重要なのはエージェントが読みやすくするためです。この位置づけが、いくつかの具体的な設計上の選択につながっていて、そのどれもが地雷を踏んだ末に残ったものです。
その一つ目であり、最もシンプルで根本的な工夫がバイトレベルの安定性です。座標はすべて Int(rounded()) で丸め、要素は (center-y, x) で決定的にソートされるので、同じ画面を二度ダンプすれば必ずバイト単位で一致します。これはつまり、エージェントが二つのダンプを直接テキスト diff にかけられるということです。「タップ前」と「タップ後」で何が変わったかが一目でわかり、処理するデータ量も少なくて済むので、高速な推論にとって非常に重要です。
二つ目はセレクタの設計です。すでにお気づきかもしれませんが、ui の出力では 3 種類の省略記法を提供しています。@N は現在のスナップショット内の N 番目の要素、#N は「ページの主要リストの N 番目の cell」でリスト型 UI に対応し、#<id> は accessibility tree が自前で持つ安定した ID を直接参照し、ダンプをまたいで再利用できます。この DSL のそもそもの狙いはエージェントのタイプ量を減らすことでした。sim-use tap "@5" は sim-use tap --label "Login Button" --container "MainView" よりずっと簡潔です。ところが意外なことに、エージェントだけでなく人間も好んで使います。失敗したケースを手作業でデバッグするとき、出力を見ながら tap @10 と打つほうが、長いセレクタ文字列を組み立てるよりずっと速いのです。さらに、人と人、人とエージェントのやり取りにおいても、この outline は問題を説明する難しさを大きく下げてくれます。
三つ目は抑制です。Outline は accessibility tree がすでに宣言しているものだけを厳密に書き、意味を発明しません。ボタンの一群はあくまで「Button × 5」であって、勝手に「NavBar」や「CategoryTabs」と名付けたりはしません。この規律は一つの判断から来ています。エージェントは「最下部に位置し、横方向に並び、role がすべて RadioButton」と見れば、それが tab bar だと自分で推論します。しかしツールが代わりに名前を付けてしまうと、いったん推測を誤った場合(たとえば一群の RadioButton を SegmentedControl とラベル付けしたが、実際の挙動は異なる、など)、エージェントはそれに引きずられて間違えます。これは固定化されたツールと LLM の知性とのあいだの繊細なバランスの一つの表れです。私たちはツールに推測させるのではなく、エージェント自身に画面の意図を推論し理解させるのです。
唯一の例外は、出力の一番上にある [Top y<120] / [Content] / [Bottom y≥H-120] という 3 つの帯への区分けです。これらは唯一の「意味的なヒント」ですが、入れているのは、この 3 つの帯がモバイル UI 上で十分に安定しているからです(status bar、コンテンツ領域、tab bar)。ほぼ間違えようのない、低コストなヒントに属します。
最後はクロスプラットフォームで無理に揃えないことです。iOS では要素を (center-y, x) でソートします。一列に��並んだボタンは高さが違っても中央揃えが常態なので、中心線でのソートが最も安定します。しかし Android の AccessibilityNodeInfo.bounds はコンテナの padding まで含めてしまうため、中心線でソートするとかえって親ノードが子ノードのあいだに入り込んでしまいます。そこで Android 側では (top-y, x) に変えました。小さな工夫ですが、これによって outline はより理にかなった並びになり、UI が画面上で持つ正しい順序を反映できます。クロスプラットフォームとは「片側の設計をもう片側に無理やり持ち込むこと」ではなく、プラットフォーム特性の相違に余地を残すことなのです。
3.2 見るだけでなく、指し示せること —— リスト検出
#N というセレクタは一見シンプルですが、その裏には自明でない問題が隠れています。実行時に、ページの「主要リスト」をどうやって識別するのか?
最も素直なやり方は、ユーザーにコンテナを指定してもらうことです。「これがチャットリスト」「これがニュースフィード」と。しかしそれでは「エージェントは構造を知る必要がない」という前提に反します。そこで私たちはヒューリスティックな自動検出を作りました。ページをひと舐めして、「リストっぽく見える」要素のクラスタをすべて見つけ出し、確からしさでランク付けし、最上位のものが #N がデフォルトで指すグループになります。
検出は 2 つの経路を並行して走らせます。一方は高さを見ます。高さの揃った兄弟ノードの一群(友だちリストやテーブルの cell が典型的な形態)を探します。もう一方は間隔を見ます。「行間隔がだいたい一定」のノードの一群(ニュースフィードやチャットリストのような、cell の高さは不揃いでもリズムは一定のレイアウト)を探します。そして素朴な掛け算でスコアを付けます。cellCount × consistency × roleBonus × widthBonus。学習も重み調整も不要で、最高スコアのクラスタが勝ちます。複数のリストが共存する場合(たとえば LINE の転送先選択ページには「友だちリスト」と「グループリスト」が同時にあります)、2 番目に高いリストも識別され、#N@2 というセレクタが与えられます。
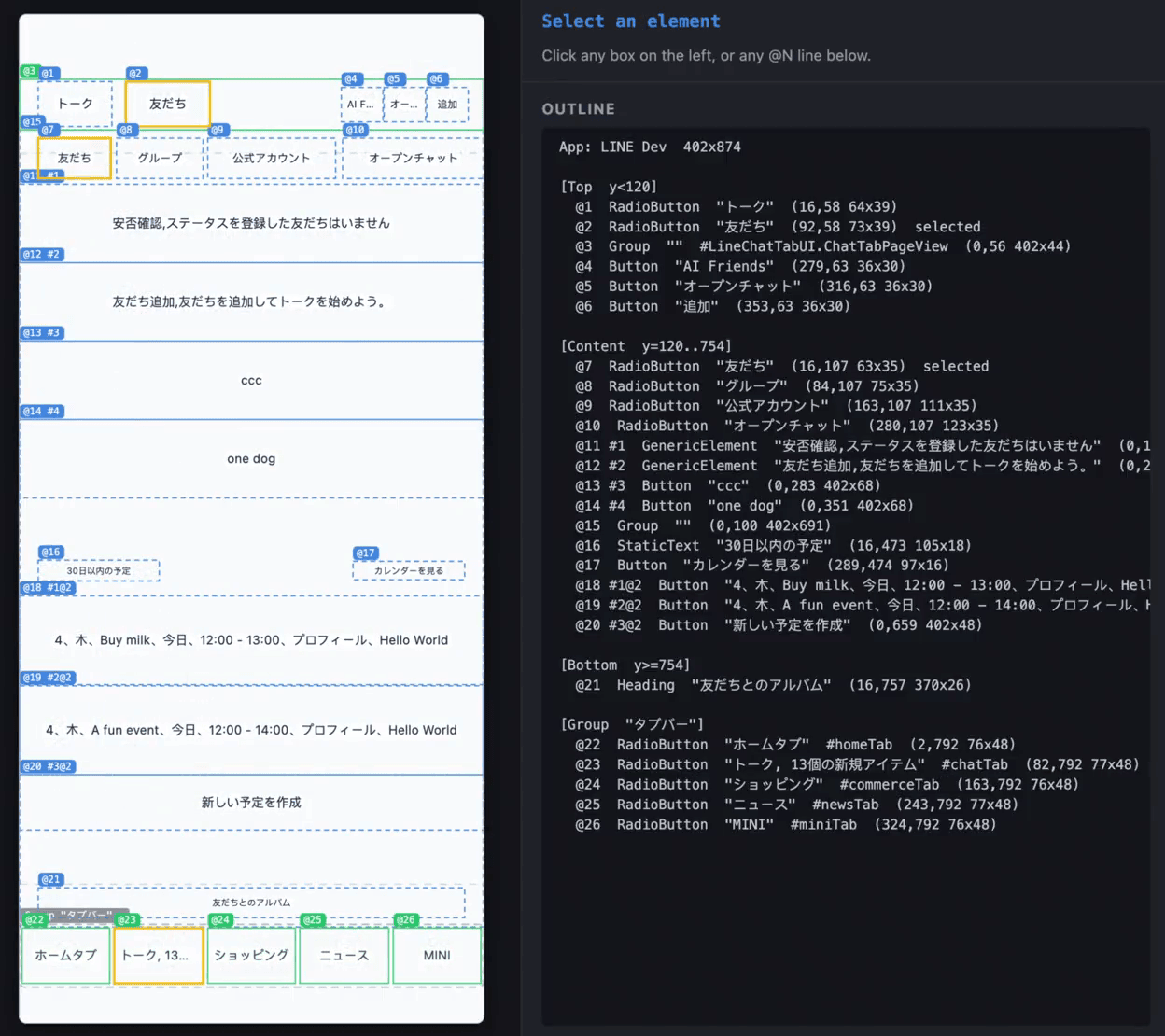
#N を獲得し、グループリストは自動的に #N@2 に落ちる。デモ動画:複数のリストが共存するときの #N と #N@2 セレクタの実際の現れ方
エージェントにとってこれは、「チャットリストの 3 行目をタップする」といった自然言語が、いまや視覚認識・推論・計算といった中間処理を一切挟まずに、そのまま tap #3 に対応するということを意味します。検証スクリプトも、ハードコードされた座標(デバイスによってずれる)や特定の label(多言語によってずれる)に縛られなくなります。適応する対象は「ページが実行時に提示する主要リスト」であって、そのリストが今日 5 個の cell を持つか 20 個持つかは問わず、cell の具体的な label が何かも気にしません。この種のセレクタのもとでは、E2E テストははるかに安定します。
4. 技術の舞台裏(その二):見えない要素を「出現」させる —— Quadtree プローブ
iOS の自動化には頭の痛い現象があります。一部のノードの内容が AccessibilityPlatformTranslation フレームワークのもとでは取得できないのです。たとえば UITabBar が返してくる accessibilityChildren は空です。画面の下部に明らかに 4 つの tab ボタンがあるのに、accessibility tree を走査しても、その AXGroup の下には何もありません。WebView も同様で、iOS 26 の「Liquid Glass」デザインや、各種のカスタムオーバーレイ、SwiftUI で組まれた非標準コントロールも、しばしばこの問題を起こします。
さらに奇妙なのは、これは API が完全に壊れているわけではないということです。同じ要素でも、accessibilityChildren の走査では辿り着けないのに、objectAtPoint: ではヒットします。iOS に座標を一つ与えれば、そこに何があるかは教えてくれます。ところが、あるコンテナにどんな子要素があるかを列挙させようとすると、無視するのです。これは長く知られてきた挙動で、多くの開発者が付き合ってきたものです。
私たちが欲しいのは完全な accessibility tree です。だから問題はこう変わります。hit-test を使って、通常の走査では到達しづらい要素をどうやって検出するか?
最も素朴な発想は密にサンプリングすることです。コンテナの frame 全体をキャンバスと見なし、小さな間隔(たとえば 10pt)で探測点を撒き、各点で一度 hit-test し、ヒットした要素をすべて回収して重複を除く。論理的には問題ありませんが、コストが耐えられません。objectAtPoint: は一回ごとに XPC のプロセス間往復で、sim-use プロセスからシミュレータプロセスへ、そして戻ってくるまで、一回あたり数ミリ秒かかります。400×800 のキャンバスを 10pt で撒けば 3,200 回の hit-test となり、数十秒規模の処理時間となるため、実用的な応答性能を満たすことができません。
ui はループの中で最も重要な一環なので、「いかに賢く打点するか」が重要です。私たちが使った解法は、自己適応的な四分木(quadtree)です。
四分木(quadtree)は計算幾何学の古い手法です。核心となる発想は、二次元の領域をトップダウンで再帰的に 4 分割し、ある条件が満たされたら止める、というものです。ゲームでは衝突判定の枝刈りに、地図のレンダリングではタイルの整理に使われます。私たちが使うのはその一種の変種で、「漏れた要素の回収」のために特別に適応させたものです。まずコンテナの frame に 160×80 の粗いマス目を一層撒き、各マスの中心で一度 objectAtPoint: を行います。ヒットした要素は記録し、その bounding rect を「カバー済み」と印を付けます。ヒットしなかったマスは、本当に空白か、いくつかの小さな要素のあいだの隙間をまたいでいるかのどちらかなので、4 分割してさらに探ります。この細分には打ち切りがあります。一つの粗いマスは最大 16 回(Phase 1)または 6 回(Phase 2)まで分割され、最小サイズは --min-cell-size(デフォルト 14pt)を下回りません。本当の空白の上で延々と粘らないためです。
ここに誤解しやすい点があります。seed cell が小さな要素にヒットしたあと、cell の残りの部分は最大 4 つの矩形(ヒットの上下 2 本と左右 2 本)に切り分けられ、再び探測キューに push されて処理が続きます。言い換えると、ヒットが押さえるのは seed cell 全体ではなく、ヒット自身の bounding rect だけです。その周りの、漏れているかもしれない兄弟要素は、なお探測されるチャンスが残ります。このステップはコード中で "opportunistic remainder subdivide" と呼ばれています。
全体の形は粗から細への一本の木です。要素が密なところでは木が深く、空白のところでは浅くなります。accessibility tree がすでに列挙したものは「既知」として直接スキップされ、漏れた要素がありそうな領域だけが深く探測されます。言い換えれば、高価な XPC hit-test を要所に使い、キャンバス全体に均等に撒かないのです。
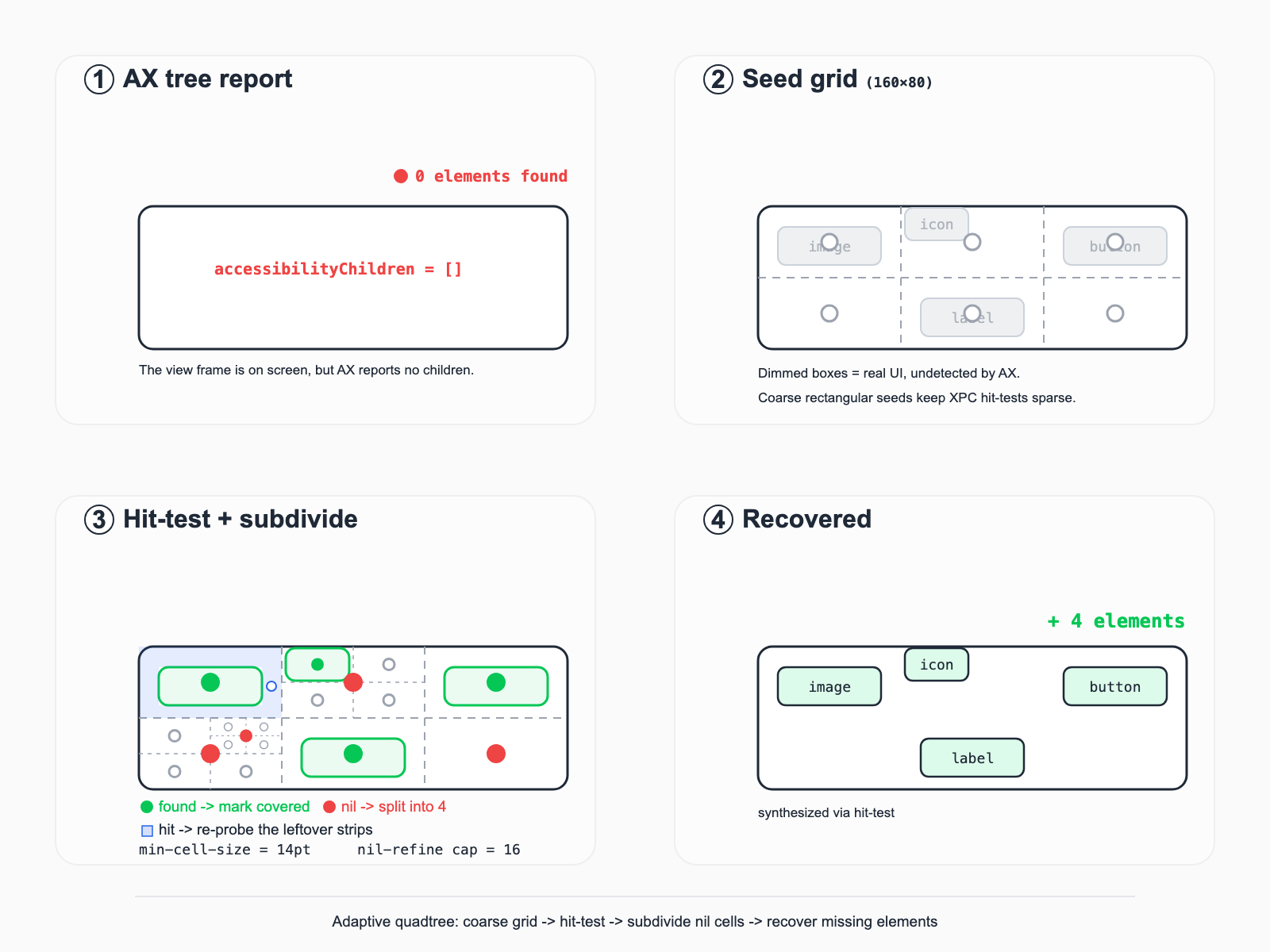
accessibilityChildren は空だが、quadtree プローブは粗い seed グリッド、ヒットすればカバー済みと印を付け(ヒット部分以外の残り帯はキューに戻して再びプローブする)、nil なら 4 分割して細分する、という流れで、最終的に 4 つの tab ボタンをすべて探し出す。実際のケースでは、要素が漏れるパターンは大きく 2 つに分かれ、それぞれ異なるフェーズ(Phase)で処理します。Phase 1 は空コンテナの復元です。親ノードの children が空なのに視覚的には明らかに空でない(UITabBar の典型的な症状)場合、frame 全体をそのまま quadtree に渡します。Phase 2 は死角のスキャンです。親ノードに children はあるが一部しかカバーしていない場合です。たとえば nav bar が左上の back button は返すのに、右上の menu button が見当たらない、などです。私たちはコンテナの frame から既知の要素がカバーする部分をすべて引き、残った「死角の矩形」(サイズが 60×60 以上かつ面積が 10,000 pt² 以上のものだけを対象とする)をもう一度 quadtree にかけます。Phase 2 はちょっとした幾何学的な工夫(水平ストリップの切り分け + 矩形の減算)を使っており、汎用的な多角形の減算よりずっと書きやすく、しかも「要素はほぼすべて矩形で、おおむね水平に並ぶ」というモバイル UI の入力分布にも非常に適しています。
この抽象的なアルゴリズムを「実際に動く」ものにするために、いくつかの素朴なエンジニアリング上の最適化をしました。最も重要なのはシードに正方形ではなく長方形を使うことです。モバイル UI の要素はほぼすべて縦よ��り横に長いのです。nav link、記事のタイトル、リストの行、テキストラベルは、どれも横長の帯です。初期には単純に正方形の seed を使っていて効率が悪かったのですが、初期 seed を 160×80 に変えたところ、同じ機能カバレッジのもとで LINEニュースのプローブ回数と wall time が 20% 下がり、seed cell は 45 から 27 に減りました。同じ面積の正方形 seed と比べて、同等の探測可能率を保ったうえで、典型的な複雑ページ一回あたりの総所要時間を 30% ほど短縮できます。
もう一つは XPC 呼び出し前の「既知エリアの事前スキップ(枝刈り)」です。XPC が最も高価な部分である以上、accessibility tree がすでに知っているマスは二度と問い合わせるべきではありません。私たちは CoveredSet を保持していて、ある seed cell の中心点がすでに既知の要素の範囲(2pt の遊びつき)に入っていれば、そのまま飛ばします。さらに、一見どうでもよさそうで実は影響の大きいパラメータがあります。--min-cell-size です。私たちはこれを 20 から 14 に下げ、status bar 上の SSID アイコン、tab bar 上の小さな badge、設定ページの右側にある小さな矢印などがすべて認識されるようにしました。代償はレイテンシの中央値が 470ms から 520ms に上がること(+11%、約 50ms)ですが、エージェントはこうした小さなアイコンを頻繁にタップする必要があるので、この 50ms は払う価値があります。
最後のポイントは重複除去です。初期の sim-use ui は、「チャット詳細の上部 nav」のような位置で、ときおり重複した合成要素を返していました。原因は、UIKit が同じコンテナを複数の兄弟 AXGroup の中に隠�していて、それぞれの AXGroup からプローブを下ろすと同じ実要素の一群にヒットするからです。最初期の重複除去ロジックは単一のプローブ呼び出しの範囲でしか効かず、これを走査全体のグローバルなスコープに引き上げる必要がありました。SeenIdentitySet を walk 全体に通し、要素にヒットするたびに identity を記録し、再び衝突したらスキップする、というものです。最終的にはわずか 8 行の変更でしたが、その裏には、実地での検証と試行錯誤を繰り返して初めて見えてくる状況がありました。
5. 技術の舞台裏(その三):200ms を消し去る —— Daemon アーキテクチャ
sim-use は CLI です。CLI は使い方が直感的ですが、目立たないコストが一つあります。呼び出すたびに新しいプロセスになり、すべての「重い」初期化をやり直さなければならないのです。
iOS にとって、この「重さ」はシミュレータフレームワークの初期化に accessibility サブシステムの初期化を加えたもので、二つ合わせて安定して 200ms ほどを食います。Android にとっては、BridgeClient の起動、auth token のキャッシュ、adb forward のポート準備で、一式合わせて 150ms ほどです。単体では目立ちませんが、エージェントは一度の検証ループで sim-use を何十回も呼ぶので、コールドスタートのオーバーヘッドはたちまち支配的なコストになります。
私たちの解法は、デバイスごとに常駐プロセスを一つ立てることです。host 上で Unix ドメインソケットの daemon サービスを走らせ��、クライアントがコマンドを実行するときはソケットを直接通します。最初の呼び出しで daemon を fork-exec し、ソケットが立ち上がるのを待ち(5s タイムアウト)、それ以降のコマンドはすべて hot path を通ります。すべての重い初期化のコストは一度だけ払えばよいのです。アイドル 600s で自動的に終了し、ゴミを残しません。
効果は、iOS では sim-use ui のたびに約 200ms を節約し(基本的にコールドスタートが一度で済む)、Android では一回ごとの呼び出しをおよそ 150ms から 10ms に圧縮します。Android 側の改善幅がこれほど大きいのは、BridgeClient 周りの処理が通常の adb コマンドよりも重いため、常駐化による恩恵をより強く受けられるからです。
そしてこれは、保守上のコストももたらします。たとえば daemon が招くいくつかの正しさの問題です。
一つ目の問題は、バイナリのアップグレードと、なお古いロジックで動き続ける daemon です。ユーザーが新しいバージョンを brew upgrade したばかりなのに、次の呼び出しが古いコードを走らせ続けている daemon に当たってしまうのです。挙動が合わず、バグも再現せず、人は自分を疑い始めます。私たちの解法は、クライアントが各呼び出しの前にまず _ping を送り、daemon が報告する simUseVersion と現在のバイナリのバージョンを突き合わせ、不一致なら shutdown して invoke に再 spawn させる、というものです。Ping 自体は 0.4ms ほどで、約 280ms の sim-use ui と比較すると無視できる値です。
二つ目の問題は、daemon が知らないうちにシミュレータが落とされてい�ることです。xcrun simctl shutdown、ユーザーが直接 Simulator.app を quit する。daemon はまだ FBSimulator ハンドルを握ったままで、次のコマンドでクラッシュします。私たちは daemon 自身にシミュレータの状態を検出させ、落ちていると分かったら自発的に終了し、staleSimulator エラーを返すようにしました。ここにあまり目立たない工夫があります。iOS は状態によって異なる低レベルのエラー文字列を吐き出します(シャットダウン、未起動、起動中で、それぞれ言い回しが違う)。私たちは生の NSError の説明をそのままユーザーに投げ返すのではなく、これらをすべて認識して、統一された回復可能なエラーに包み、エージェントがエラーを受け取ったときに次に何をすべきか(たとえば自動的にシミュレータの再起動を試みるなど)を判断するのに十分な情報を持てるようにしました。
三つ目の問題は、stdin 入力と、daemon の仕様との衝突です。sim-use ios type --stdin のようなコマンドはユーザーの端末から入力を読む必要がありますが、daemon の stdin は /dev/null を指していて入力を読めません。直し方は簡単です。コマンドに daemonBypass フラグを宣言できるようにし、daemon を介さず直接 in-process で実行させるようにしました。これは daemon が招く新しい種類の厄介事です。すべてのコマンドが daemon を通すのに向いているわけではなく、いくつかは脱出路を残しておかなければなりません。
Daemon が扱う問題は、前のいくつかの節とはだいぶ違います。Outline と Quadtree が解くのはどちらも「いかにエージェントにはっきり見せるか」で、製品の判断に近いものでした。Daemon は純粋に性能の問題ですが、これもまた非常によくあるエンジニアリングのリズムを示しています。高速化は簡単で、高速化したあとのシステムを、あらゆる境界条件のもとでなお正しく保つことこそが、手間のかかる部分なのです。
6. 技術の舞台裏(その四):同じコマンド、二つの世界 —— クロスプラットフォーム設計
sim-use は当初 iOS シミュレータしかサポートしていませんでした。この設計が iOS の上で安定して回るようになって初めて、私たちは Android バックエンドの追加に取りかかりました。iOS は FBSimulatorControl を、Android は bridge APK + adb forward を通り、両者は土台がまったく異なります。しかし LINE にとって、iOS と Android のエンジニアが協力して開発するのは日常的な状態なので、最初からの目標は、両側のコマンド面が一つのツールに見えるものを作ることでした。そうすればエージェントはプラットフォームごとに 2 つの API を学ぶ必要がなく、最終的なアプリ開発に向けた多くのプラクティスを共有し、蓄積していけます。
最も重要な設計上の判断は、実はとてもシンプルです。コマンド自身にデバイスの種類を判定させ、ユーザーもエージェントもデフォルトでは --platform のような引数を必要としないようにすることです。デバイスを自律的に識別するのが一番簡単な部分です。PlatformRouter は 3 つのルールでデバイス識別子を判定します。iOS シミュレータは 8-4-4-4-12 の標準的な UUID 形式、Android エミュレータは emulator- で始まり、Android 実機は ASCII の serial(4〜32 文字で、必ず数字を含む)です。
最初の 2 つは自然ですが、3 つ目の「必ず数字を含む」は防御的なものです。--device foo のようなタイプミスをした際、Android のパスに入ってしまうと、adb -s foo が 5 秒間タイムアウトするまでエラーが返ってきません。しかし、iOS のパスに流せば、その場で即座にわかりやすいエラーを返すことができます。この「エラーがどれだけ早く人に気づかせるか」という配慮は、ルールを書くときに私たちがよく行う小さな判断の 1 つです。エージェントは人とは違い、一度の曖昧なエラーを処理するコストが人よりはるかに高いのです。失敗したツール呼び出し一回が、そのまま完全な LLM 推論を一度発火させ、数千トークンのコンテキストを消費しかねません。エラーをできるだけ早く、できるだけ具体的に露出させることは、エージェント向け CLI の設計において貫く価値が大いにある原則です。
Android バックエンドが iOS のコマンド面と 1:1 で揃ったあと、私たちはあまり一般的でないことをしました。トップレベルのコマンド面から、iOS 専用のコマンドを 5 つ意図的に削除したのです。key、key-combo、key-sequence、stream-video、batch がそれです。これらは依然として存在しますが、sim-use ios <verb> を通じてしか呼び出せず、トップレベルの --help にはもう現れません。古いコマンドは互換性のために残しますが、exit 64(EX_USAGE)で、一行の移行ヒント�を添えます。
理由はシンプルです。sim-use --help が並べるものは、すべて本当に両方のプラットフォームで使えるものであるべきです。ユーザーが tap、type、swipe を読んだら、「ああ、これは実は iOS にしかない」と心配することなく、安心してクロスプラットフォームのスクリプトを書けるべきなのです。
これは少し直感に反する判断です。多くのプロジェクトは「後方互換性」を第一の価値とし、コマンド面をじわじわ膨張させていきます。足すのは簡単で、削るのは難しいからです。従来の、人間のユーザーに向けて開発・運用するという文脈では、これは正しいことでした。しかし時代は変わり、いまのソフトウェア開発の在り方の中でツールを設計するなら、agent friendly であることがますます重要になります。エージェントのために作るツールにとっては、「コマンド面が誠実であること」のほうが「コマンド面が安定していること」より重要です。 エージェントは歴史的な命名への郷愁を抱いてツールを使ったりはしません。それはただ、「できそうに見えるのに、実際にはできない」コマンドに引っかかるだけです。そうしたコマンドの一つひとつが、余分なエラー処理一回、余分な fallback プロンプト一回、避けられたはずのトークン消費一回になるのです。
7. 技術の舞台裏(その五):指を増やす —— マルチタッチの技術検証
私たちは sim-use に「二本指のピンチ」というコマンドを加えたいと思っていました。さほど大きな要件には見えま��せん(pinch、rotate、二本指の long-press)。けれども、その開発過程は私にとって最も忘れがたい一段でした。理由は単純です。それは真面目なエンジニアリングの匂いがあまりせず、むしろ「リバースエンジニアリング + 実験 + 一行のひらめき」に近かったのです。
ことの起点は facebook/idb#514 という issue でした。2020 年に立てられ、タイトルはおおよそ「idb はいつ二本指ジェスチャーをサポートするのか」。私たちが手をつける前に、それはすでに6 年間放置されていました。誰もやりたがらなかったわけではありません。Meta 自身も試していて、彼らは「5 引数の呼び出し + パケットのバイトを手作業でパッチする」という路線を採りました。動きはしますが脆く、SimulatorKit のバイナリが一度でも変われば、あのハードコードされたオフセットが無効になりかねません。私たちはもっと安定した入り口を探したかったのです。
転機は SimulatorKit.framework の中の IndigoHIDMessageForMouseNSEvent という private シンボルから訪れました。idb の上流はその 5 引数の呼び出し形式を使っていて、一本指なら十分です。しかし同じシンボルを 9 引数の形式で呼ぶと:
IndigoHIDMessageForMouseNSEvent(p0, p1, target, eventType, direction,
1.0, 1.0, widthPoints, heightPoints)それはまったく構造の異なるパケット、すなわち本物の two-payload Indigo packet を生成し、二つの finger slot の state bits が正しく初期化されます。5 引数版がマルチタッチをできないわけではなく、第二の finger slot をそもそも初期化し��ないので、iOS 側には一本の指しか見えないのです。しかしいったん 9 引数版に切り替えると、SimulatorKit 自身が正しいパケット構造を生成してくれて、ハードコードされたバイトオフセットは一切要りません。同じパッチが iOS 18.6 でも iOS 26.2 でも、そのまま動きました。
けれども面白い部分は、このプリミティブをトップレベルのコマンドにつないでから始まりました。技術検証の段階では、最も難しいのは「iOS に二本の指を認識させること」だと思っていました。ところが本当に難しかったのは「iOS に正しいジェスチャーを認識させること」だったのです。
一つ目の発見は、iOS はイベントを数えないということでした。Down と Up のあいだに Move をたくさん詰め込まないと連続したジェスチャーとして認識されないだろうと思っていたのですが、steps=1(Down 一回、Move 一回、Up 一回)でも、iOS はちゃんと完全なドラッグとして扱いました。ジェスチャー認識器が見ているのは finger identifier の連続性であって、イベントの数ではありません。このことはトップレベルの API を直接シンプルにしました。私たちはジェスチャーごとに異なる複雑さのイベントストリームを構築する必要はなく、一つのプリミティブで十分なのです。
二つ目の発見はもっと面白いものでした。start と end を同じ点に設定すると、no-op ではなく、一度の二本指タップになるのです。Maps は実際にこれを受けて一段階ズームアウトします。これはつまり、pinch、rotate、二本指タップ、二本指 long-press というこの 4 つのコマンドが、本質的には同じ multi-touch プリミティブを、異なる duration と endpoint の幾何のもとで特殊化したものだということです。私たちは最終的に CLI の中でもこのように構成しました。一つの低レベルなプリミティブと、いくつかの preset です。
三つ目の発見は、私たちを二日間足止めしました。直線補間の rotate は、90° まで回すと二本指の中点間距離が 71% まで縮み、180° まで回すと一気に 0 まで縮みます。UIRotationGestureRecognizer は中点間距離が継続的に変化するのを見て、それを混入した pinch ジェスチャーだと誤認します。だから正しく rotate するには、ジェスチャーは円弧に沿って補間されなければなりません。幾何学的には一見どうでもよさそうな単純化(直線か円弧か)が、認識器の前では二者択一の問題になるのです。
ここまでで技術検証はほぼ終わり、pinch と rotate は iOS 18 / iOS 26 の双方で安定して zoom in/out と回転ができるようになりました。しかしこれをプロダクトに組み込む過程で、私たちはさらに二度、認識器に鍛えられました。
一度目は rotate の速度でした。デフォルトの 270°/0.5s で走らせると、iOS はおよそ 360° まで追従し(UIRotationGestureRecognizer には慣性が組み込まれている)、Android は逆に 210° ほどまでしか追従しません(dispatchGesture がフレームレートに制限される)。どちらも正確ではありませんが、巧いことに両者の「心地よい速度」はほぼ重なります。およそ 180°/s です。私たちは最終的に rotate のデフォルト duration を、回転角度に応じて自己適応する値に変え、角速度をこの範囲で一定に保つことで、両側の認識器がきれいに追従するようにしました。
二度目は --radius でした。デフォルト値の 80 は iOS シミュレータでは画面幅の 20% で、ちゃんと動いていました。ところが 1080+ px の Android エミュレータに切り替えると画面幅の 7% になり、一般的なデバイスの rotate しきい値を下回って、静かに失敗します。何のエラーメッセージもなく、ただ反応がないように見えるだけです。直すのは一行です。max(80, min(w, h) * 0.15)。けれどもこれは、二台の異なるデバイスでそれぞれ走らせてみないとなかなか気づけない類のバグです。単一プラットフォームの開発者は、もう片方のプラットフォームで「動いているように見えて実は動いていない」ツールを、まるごと出荷してしまうことが十分にあり得ます。
これも前のいくつかの点とは違います。Outline DSL はエージェントのための製品判断、Quadtree プローブは API の制限を回避するためのエンジニアリングの受け皿、Daemon は性能の問題です。どれも「計画されて出てきたもの」でした。Multi-touch のこの件は、どちらかといえばエンジニアリングの実践の中での改善であり、開発の最前線に密着するという前提のもとで進めなければならないものでした。
8. 最後に:なぜオープンソースにしたのか
sim-use は新しいアイデアではありませんが、モバイル開発におけるエージェントのループの検証という部分を前に進め、解決していくうえで、きっと助けになると私たちは信じています。Cameron Cooke の AXe がその出発点で、業界には Appium、idb、Maestro などもあります。私たちは先人の肩の上に立って、いくつ��かの具体的なことを行いました。
- 「スクリプトが動くこと」ではなく、「エージェントに UI を効率的に消化させる」ことを第一の目標に据えた。Outline DSL はこのことの直接の結果です。
- iOS / Android の accessibility API はどちらも取りこぼしがあることを認め、具体的な幾何 / hit-test のアルゴリズムでその欠けを埋めた。
- クロスプラットフォームを「片側の設計をもう片側にコピーすること」とは捉えず、統一されたコマンド面 + プラットフォーム固有の実装 + 「surface honesty」の規律によって、エージェントが本当にクロスプラットフォームのスクリプトを書けることを目指した。
- 十分に軽量で、とても始めやすい。7MB のバイナリのインストールに、数百行の SKILL.md を加えるだけで、エージェント開発の最後の一片のピースが埋まり、人間の開発者を解放して、ほかのもっと意味のある思考へと向かわせる。
sim-use は GitHub で公開しています。この記事が、その内部にある設計上のトレードオフについて、いくらか直感的な理解を与えられたなら幸いです。あなたももしモバイル + AI に取り組んでいるなら、ぜひ issue や PR を寄せてください。
エージェントがコードを書く速度は、本質的に、自分が書いたコードをどれだけ速く検証できるかによって制限されます。モバイルにおいては、この制限は少なくとも今日なお、現実に存在しています。
私たちは sim-use が、この制限を少しでも小さくできることを願っています。


