香川大学大学院創発科学研究科修士1年の芝昌隆です。私は2025年夏季インターンシップで6週間��、LINEヤフーのCloud Infrastructure本部に所属し、プライベートクラウドで提供しているソフトウェアロードバランサの追加機能開発に取り組みました。
LINEヤフーにおけるソフトウェアロードバランサ
LINEヤフーでは、Linux XDP(eXpress Data Path)をベースにLayer-4で動作する独自のソフトウェアロードバランサを開発し、社内クラウド基盤から利用できるようになっています。
インターンではこのSoftware L4LB(Layer 4 Load Balancer)に対して、バックエンドサーバに転送するリクエスト量の比率を設定可能にする「Weighted Load Balancing」の機能開発に取り組みました。また、この重みをバックエンドサーバの負荷状況に応じて動的に調整する「Dynamic Weighted Load Balancing」に発展させました。それぞれ記事の前半と後半で紹介します。
Weighted Load Balancing
Static Weighted Load Balancing
現在運用しているL4LBは、セッションを考慮しつつ、正常なバックエンドサーバに均等にリクエストを振り分けています。しかし、サーバごとにリクエストの割合を変えたいこともあります。例えばサーバの交換や、サーバ内で稼働するソフトウェアのバージョンアップ時に、リクエスト量を最初は少量から徐々に増加させたいような場合です。また、異なる性能のバックエンドサーバを持つヘテロジニアスな構成の場合、リクエスト量を均等ではなく性能比に応じて調整する必要があります。
これらを解決するために、L4LBに固定の比率でトラフィック量を調整できるようにする、「Static Weighted Load Balancing」機能を実装しま��した。
Maglev Lookup Table
Software L4LBはどのようにしてトラフィックの振り分け先サーバを決定しているのでしょうか。LINEヤフーのSoftware L4LBは、Maglevをベースに実装されています。
Maglevの詳細はここでは説明しませんが、各LB(Load Balancer)ノードが転送先のバックエンドサーバの情報を格納したMaglev Lookup Tableを持ちます。例えば正常なバックエンドサーバが2つのとき、それぞれのサーバを0,1と表現すると以下のように0と1がおおよそ均等に現れるテーブルになります。
Lookup Table:[0,0,1,0,1,1,0,1,0,1,...]
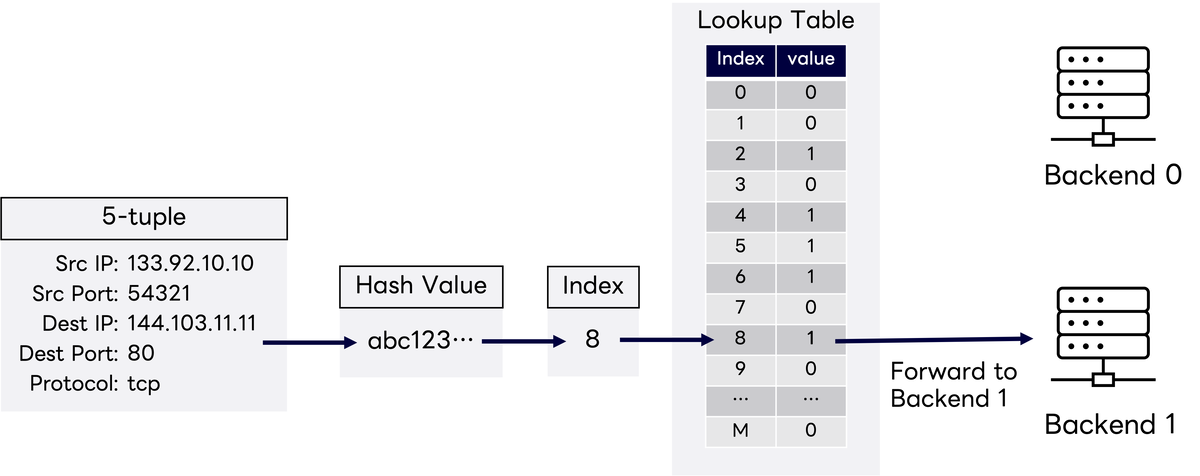
各LBノードは、到達したパケットに対して5-tuple(送信元IPアドレス、送信元ポート番号、宛先IPアドレス、宛先ポート番号、L4プロトコル)のハッシュ値をLookup Tableサイズで割った余りをインデックスとし、その位置に格納されているバックエンドサーバにリクエストを転送します。このMaglev Lookup Tableはバックエンドサーバの集合が同一であれば一意に決まるため、LBノードでLookup Tableが共通になります。これに��より、冗長構成のため複数デプロイされたどのLBノードにパケットが到達しても、転送先として同じバックエンドサーバが選択されるためセッション断が起こりません。
Maglev Lookup Tableの重み付け
このLookup Tableに格納するバックエンドサーバの出現頻度を変えることで、サーバごとの選択されやすさ(すなわち重み)を調整することを考えました。既存の実装では、このLookup Tableを生成する関数はバックエンドサーバの集合を引数に取り、Lookup Tableを計算し、各バックエンドサーバが均等に現れるようにテーブルを作成していました。
そこでバックエンドサーバの集合として{0,1}ではなく、{0a, 0b, 1a, 1b, 1c}を入力し、得られたTableを0a, 0b → 0, 1a, 1b, 1c → 1として変換します。すると0と1が以下のようにおおよそ2:3の割合で現れるテーブルが生成されます。
Lookup Table:[1,0,1,1,1,0,1,1,0,0,...]
これでバックエンドサーバの重みが2:3となるMaglev Lookup Tableを生成することができました。
重みを指定するために、LBにバックエンドを登録・更新するAPIに、「weight」という項目を追加しました。APIで指定された重みに基づいてバックエンドサーバを複製したスライスを組み立て、Lookup Tableを生成します。
例えばバックエンド0に対してバックエンド1が1.5倍の量のトラフィックを扱う場合、ユーザーは以下のようにAPIを通して重みを設定することができます。これによってWeighted Load Balancingが実現できるようになりました。
{
"backends": [
{ // バックエンド0
"address": "192.168.0.1",
"weight": 2,
// その他��の項目(省略)
},
{ // バックエンド1
"address": "192.168.0.2",
"weight": 3,
// その他の項目(省略)
}
]
}Dynamic Weighted Load Balancing
前半で紹介した重み付け機能により、バックエンドの性能に応じた重みをAPIで設定できるようになりました。しかし、サーバが処理できるリクエストの件数は、必ずしもあらかじめ決まっているわけではありません。リクエストの内容によって処理に必要なリソースは異なるため、重い処理を要求するリクエストが届くと、リクエストの件数が少なくても過負荷になってしまうかもしれません。また、バッチ処理によってサービスが利用できるリソースが制限される可能性もあります。そのため、静的に重みを設定するだけでは十分ではありません。バックエンドサーバの負荷をリアルタイムで監視し、負荷に応じて動的に重みを設定できれば、バックエンドの負荷が均等になりリソースを効率的に利用できるほか、ユーザーが手動で重みを設定する手間も削減できます。
バックエンドサーバの負荷を監視する方法には、クラウドに統合されたサーバ監視システムからメトリクスを取得する方法が考えられます。監視システムからメトリクスをAPIで取得するのは容易に思えますが、メトリクスの更新頻度が監視システムのメトリクス収集周期に依存してしまうという問題や、データフォーマットの変化に常に追従する必要があるなど手軽さはありません。また膨大な数のサーバのメトリクスを全てLBシステムが取得することはスケーラビリティの観点からも課題があります。
ヘルスチェックを利用した負荷取得
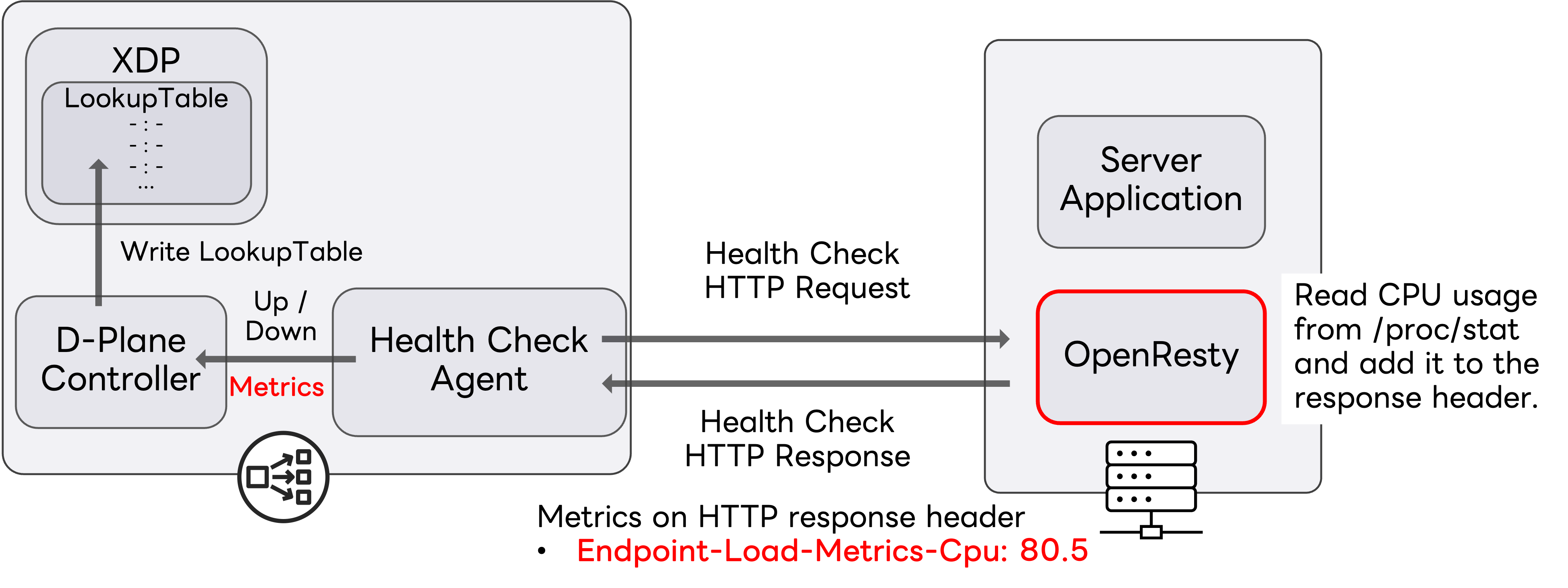
私たちのLBシステムではバックエンドサーバがリクエストを受け付けられる状態かを確認するために、LBノードから各バックエンドサーバに定期的な死活監視(ヘルスチェック)を行っています。具体的には、ICMP、TCP、HTTP(S)の3種類のヘルスチェックリクエストを送信し、その応答に基づいてバックエンドの状態を判定しています。今回はLBシステムだけで完結する手軽さから、LBノードからのHTTPヘルスチェックを拡張してバックエンドサーバのメトリクスを収集し、その値に基づいて重みを設定するように実装しました。
具体的にはHTTPヘルスチェックのレスポンスヘッダにバックエンドサーバのCPU使用率を表すヘッダが入っていた場合、各LBノードはそのヘッダをヘルスチェック対象のバックエンドサーバのCPU使用率として解釈し、その使用量に応じて動的に重みを変化させます。この計算した重みをもとに先程のWeighted Maglev Lookup Tableを更新します。
例えばあるバックエンドのCPU使用率が80.5%の場合、X-Endpoint-Load-Metrics-Cpu:80.5 というヘッダをレスポンスヘッダに含めて応答します。このヘッダ形式は、Envoyコミュニティが提案するOpen Request Cost Aggregationを参考にしました。今回は検証を簡単にするためにCPU使用率のみを対象としましたが、メモリやネットワーク使用量にも拡張可能です。
CPU使用率は指数移動平均��をとって平滑化します。これは瞬間的なスパイクの影響を抑えるためです。 は時刻 に観測されたCPU使用率、 は平滑化後の使用率です。
次に、算出したCPU使用率からCPUの空き率(1 - CPU使用率)を計算します。これはどれだけ追加のリクエストを処理できるかを表しています。さらに、空き率を1〜10の整数値に量子化したものをWeightとします。重みを1%単位などで細かく変動させると振動が大きくなるため、粒度を粗くして安定性を確保します。例えば、CPU使用率が40%の場合、空き率は60%、Weightは6となります。
この方式は、CPUに余裕があるバックエンドほど重みが大きくなり、多数のリクエストが振り分けられるようになるため、一見合理的なように思えます。しかし、実際には重みが振動してしまう恐れがあります。例えば2つのバックエンドの実キャパシティが3:1である場合、重みを3:1にすると両方のCPU使用率が同程度になり、次の重み計算では重みが1:1に戻ってしまいます。結果として、均衡状態と偏った状態の間で重みが振動することになります。
このように動的重み付けのための適切な関数とパラメータは実際のサービスや負荷特性に合わせて調整が必要と考えています。
動作検証
検証環境に今回の追加機能をデプロイし、クライアント用 VM(Virtual Machine)1台、バックエンドサーバ用 VM 2台を用意してDynamic Weighted Load Balancing機能の動作検証を行いました。
バックエンドサーバ上ではヘルスチェックに応答しメトリクスを取得してヘルスチェックレスポンスに載せるサイドカーとしてOpenRestyを動作させました。OpenResty上でLuaスクリプトを動かし、サーバのCPU使用率を取得してその値をHTTPヘルスチェックのレスポンスヘッダに含めます。今回の検証ではOpenRestyをサイドカー��として動作させましたが、社内クラウド基盤に展開する場合は、社内で使われているアプリケーションフレームワークのプラグインとして提供し、組み込むだけでヘルスチェック時のレスポンスヘッダにCPU利用率のようなメトリクスが含まれるようになるものを提供することもできるでしょう。
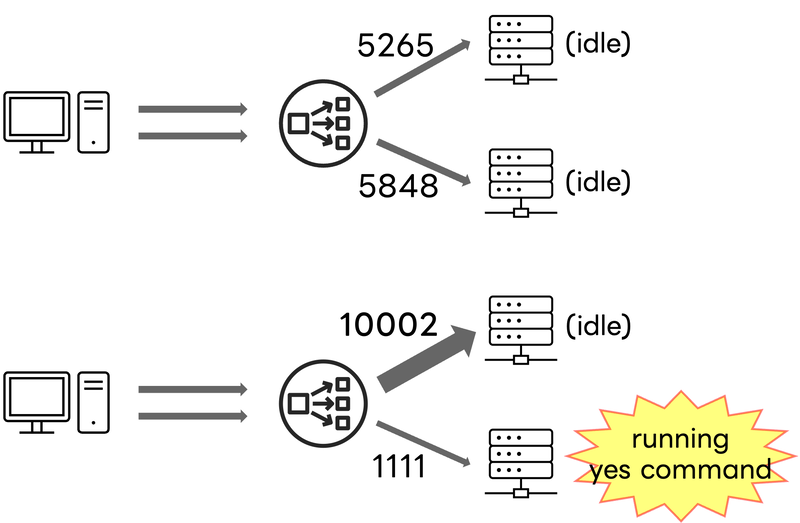
無負荷時の2台のバックエンドサーバのCPU使用率は約1%で、このときLookup Table上でのバックエンドサーバの比は5265:5848とほぼ同等でした。(Maglev Lookup Tableのサイズ:11113)その後、server2でyesコマンドを実行して負荷を与えたところ、Table上でのバックエンドサーバの比は10002:1111となり、約10:1の割合でリクエストが分散されるようになりました。これにより、片方のバックエンドサーバのCPU負荷の増加に伴い、もう片方のCPU負荷の低いバックエンドサーバに優先的にリクエストが振り分けられることを確認できました。
まとめ
今回のインターンシップでは、Software L4LBに「Weighted Load Balancing」を実装し、バックエンドサーバの性能に応じてリクエストの比率を静的に指定できるようにしました。さらに既存のヘルスチェックを拡張してバックエンドサーバのCPU使用率を取得し、その値をもとに動的に重みを調整できるようにしました。これにより、静的・動的の両面でリクエスト分配を制御する仕組みを検証でき、Software L4LBの柔軟性と将来的な拡張の可能性を示すことができました。
終わりに
インターンシップを通じて、大規模ネットワークのアーキテクチャやXDP、制御理論など、多くの技術に触れることができました。懇親会やLT会にも参加し、他チームの方々とも1on1で交流する機会をいただき、非常に充実した6週間でした。トラブルに直面した際にはすぐにサポートいただき、大変心強かったです。
また、チームや部の会議に出席することで、セキュリティやユーザビリティ、コスト、優先順位づけなど、日常業務で考慮すべき視点を学ぶことができました。研究室や授業では得られない実務の意思決定プロセスを体感できたことは、大きな学びとなりました。
今回得られた経験を、今後の研究やキャリア形成に活かしていきたいと考えています。最後になりましたが、温かく迎えてくださり、丁寧にご指導くださった皆さまに心より感謝申し上げます。
メンターからの一言
本インターンシップで芝さんのメンターを務めました石崎です。
芝さんは実装力が申し分ないのはもちろんのこと、6週間という非常にタイトなスケジュールにもかかわらず、方針を自ら定義し、そのための準備を進め、必要な知識を能動的に得て、成果としてまとめ上げていました。その過程から総合的なエンジニアリング能力の高さを感じました。まだ学生であることを忘れてしまいそうになるほどです。
社内特有の環境や、普段触れない領域の知識も多かったと思いますが、それらをめきめきと習得する姿勢と高い適応力に驚かされるとともに、メンターとしても、非常に感慨深いものでした。
このいきいきとインターンシップに取り組む様子は私自身にとっても大��きな刺激となりました。
今後のさらなる活躍が非常に楽しみです! お疲れさまでした!


