はじめに
こんにちは、LINEヤフーで音声AIの研究開発を担当している三宅純平と木下泰輝です。
私たちの所属組織「Speech and Acoustic AI部」では、音声認識(ASR)や音声合成(TTS�)を軸とした技術開発とサービス応用に取り組んでいます。
本記事では、2025年6月30日に開催されたTech-Verseで「LINEヤフーの音声AIがもたらす未来:ASR/TTSと対話技術の新たな可能性」というテーマで登壇した内容をもとに、LINEヤフーの音声AIの取り組みを紹介します。

発表スライドや発表動画は以下から視聴できます。
https://tech-verse.lycorp.co.jp/2025/ja/session/1226/
また、宣伝にはなりますが、直近の国内外会議での発表論文もご紹介します。
会議でお見かけの際は、ぜひお立ち寄りください。
-
日本音響学会第154回(2025年秋季)で5件発表
- 「音声からの音素・韻律ラベルの獲得とその応用」白旗 悠真、朴 炳宣、山本 龍一
- 「SLASH: 信号処理と自己教師あり学習を組み合わせた基本周波数推定法」寺島 涼、白旗 悠真、川村 真也
- 「映画音源分離のための非言語音声を含むデータセット」蓮実 拓也、藤田 雄介
- 「BitTTS: 1.58-bit 量子化と重みインデキシングによる軽量なテキスト音声合成」川村 真也、蓮実 拓也、白旗 悠真、山本 龍一
- 「音響情報に基づいた疑似言語特徴量による半教師あり音響言語対照学習」小松 達也、宗像 北斗、石川 裕地
音声認識・音声合成のプロダクト紹介
私たちは現在、ASRでは「YJVOICE(ワイジェーボイス)」、TTSでは「Achoris(アコリス)」というプロダクトを社内展開しています。
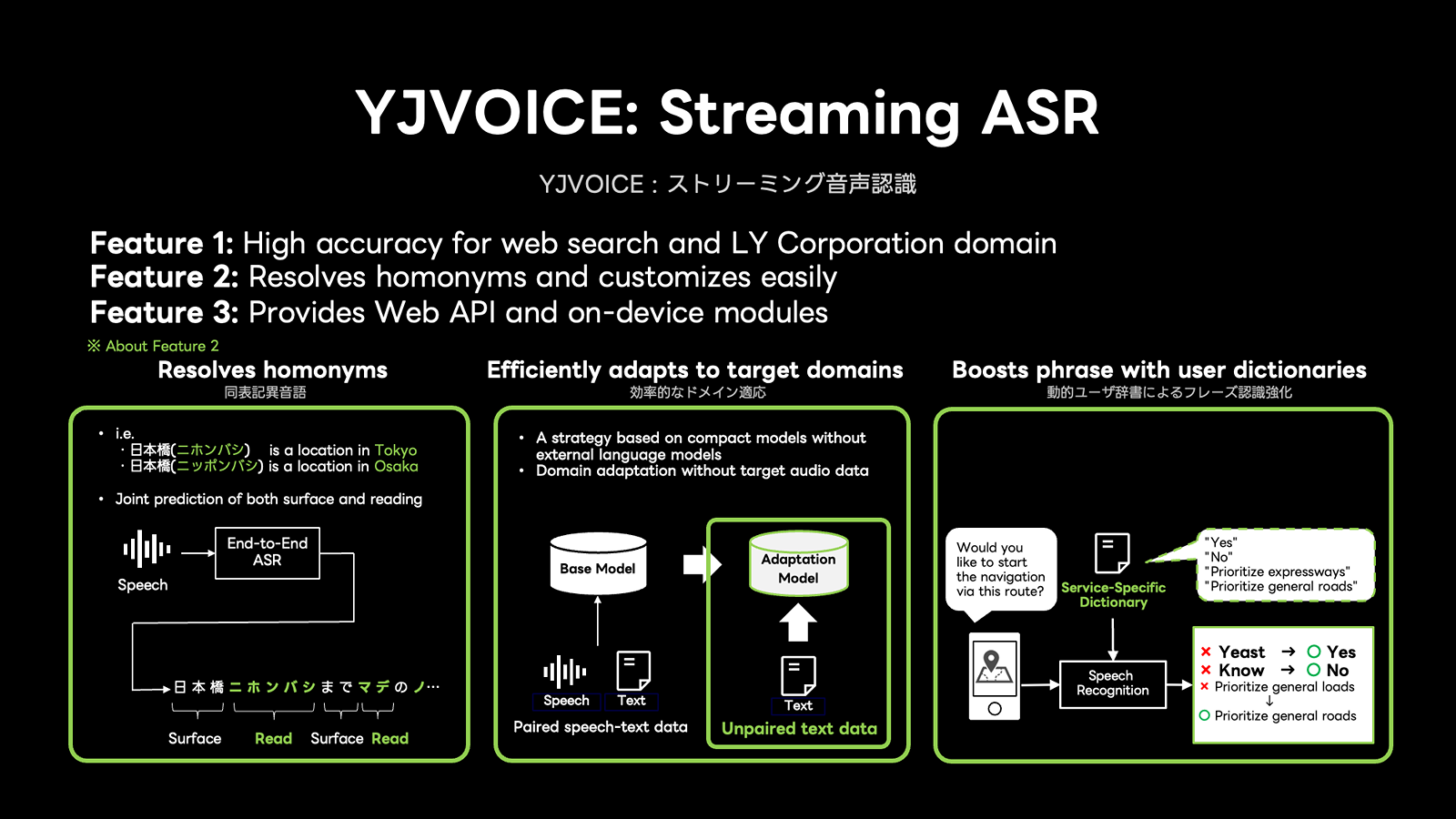
YJVOICEはウェブ検索や社内サービスでの用途に最適化されたストリーミング音声認識です。
主な特徴は「ドメイン特化の高精度」「同音異義語の解決」「柔軟なカスタマイズ性」です。
一方、Achorisは感情表現が可能な音声合成エンジンで、現在は17種類以上の話者プリセットを提供しています。
特徴は「感情強度の制御」「人間に近い自然な音質」「用途に応じた提供形式(API/オンデバイス/編集ツール)」です。
カーナビ音声や案内システムなど、リアルタイム性が求められるユースケースでも活用されています。

音声認識・音声合成の応用事例
私たちのASR/TTS技術は、実際のLINEヤフーサービスでも広く活用されています。
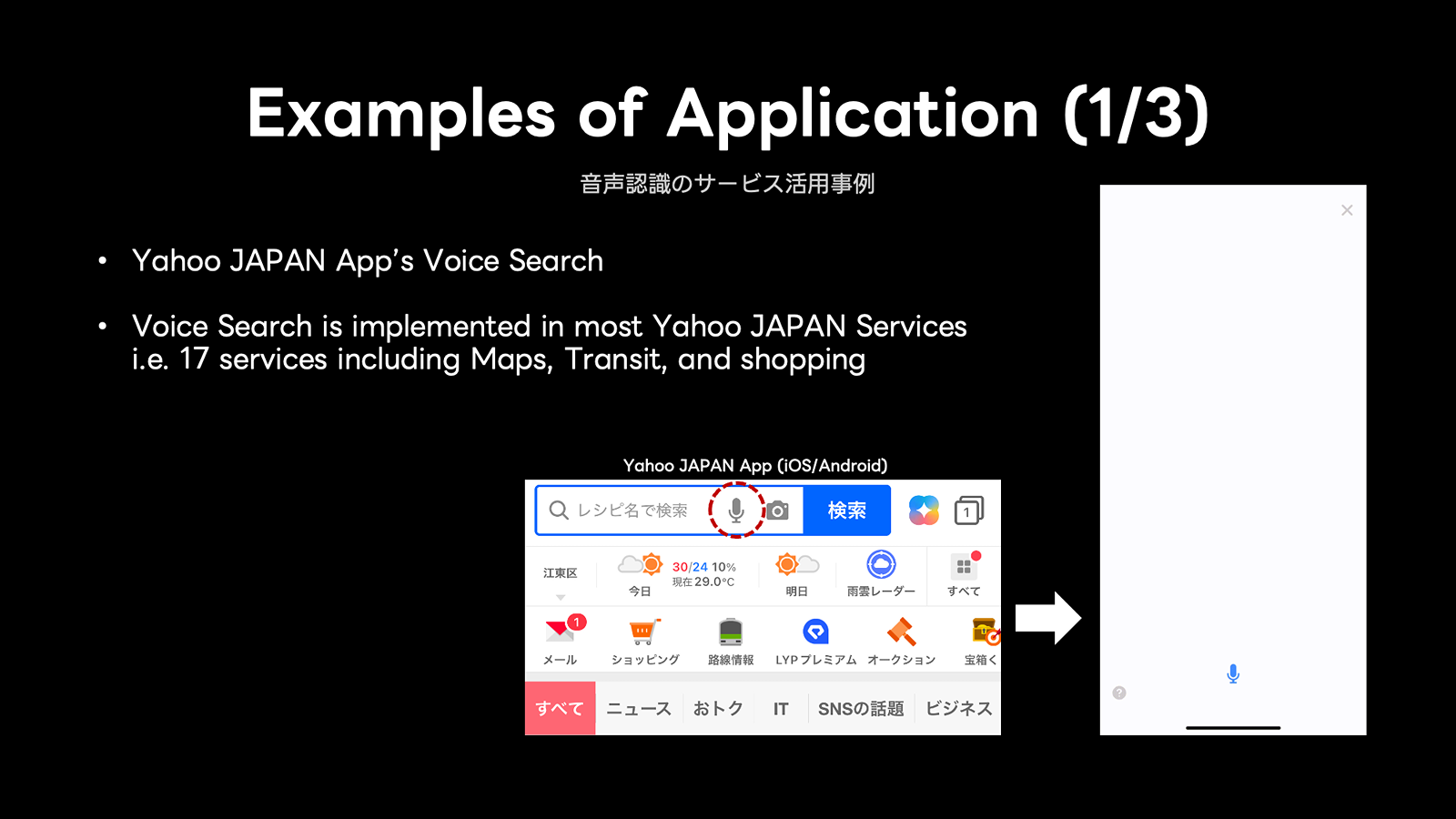
たとえば「Yahoo! JAPANアプリ」では、リアルタイム音声検索機能としてYJVOICEが利用されています。
地図検索、乗換案内、ショッピングなど、17以上のサービスに展開しています。
「Yahoo!カーナビ」では、Achoris Liteという軽量TTSエンジンをオンデバイスで動作させています。
約10秒の音声を0.2秒で生成するなど、RTF(Real-Time Factor)0.02という高速処理を実現しています。

リアルタイム音声対話技術の実現に向けた取り組み
私たちが現在注力している領域は、リアルタイム音声対話技術(Real-time Speech-to-Speech)の実現です。
これは、ユーザーの音声理解から応答生成、音声生成までをLLM基盤で統合した音声対話システムです。
このシステムの鍵は「低遅延」です。発話終了から応答までの総遅�延を1秒未満に抑えることが重要です。
Speech-to-Speechモデルの代表的な構造として、
下図のように音声の入出力をLLMに直接的に接続する手法が多く提案されています。
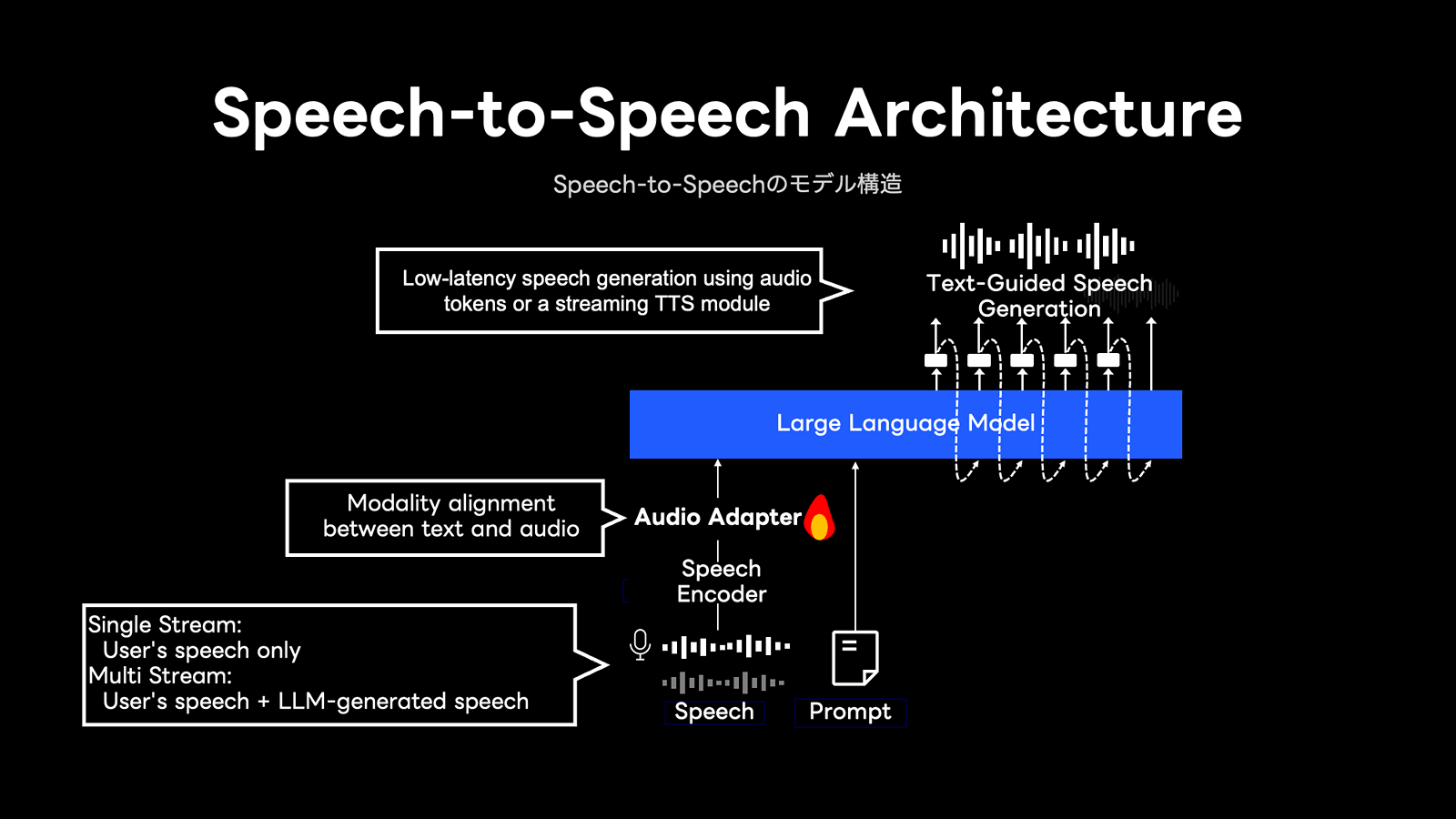
私たちも、音声とテキストという異なるモダリティを接続するための音声Adapterモジュールや、ストリーミング可能な音声生成モジュール(Acoustic Token/Streaming TTS)の重要性を強く認識しています。
現在は、遅延の最小化やクロスモダリティのアライメントを図りつつ、タスクの柔軟性を損なわないモデルの実現に取り組んでいます。
音声LLMの性能評価と遅延評価
私たちはリアルタイム音声対話技術の事前検証として、構成要素であるSpeech-to-Text(Speech LLM)による質問応答(QA)と翻訳タスクの性能評価を行いました。
モデル学習にはSLAM-LLMを利用しました。
その結果、質問応答タスクでは音声認識を介した条件よりも大きく上回る高い結果が得られ、翻訳タスクでは音声認識を介した条件とほぼ同水準の性能を実現できることが確認できました。

次に、モデル推論速度の改善について紹介します。
モデル推論時にSLAM-LLMで利用されているTransformersライブラリを、LLM推論フレームワークとして広く用いられているvLLM上でも動作するように改修し��、両者の速度比較を行いました。
その結果、約3.2倍の高速化を確認しました。
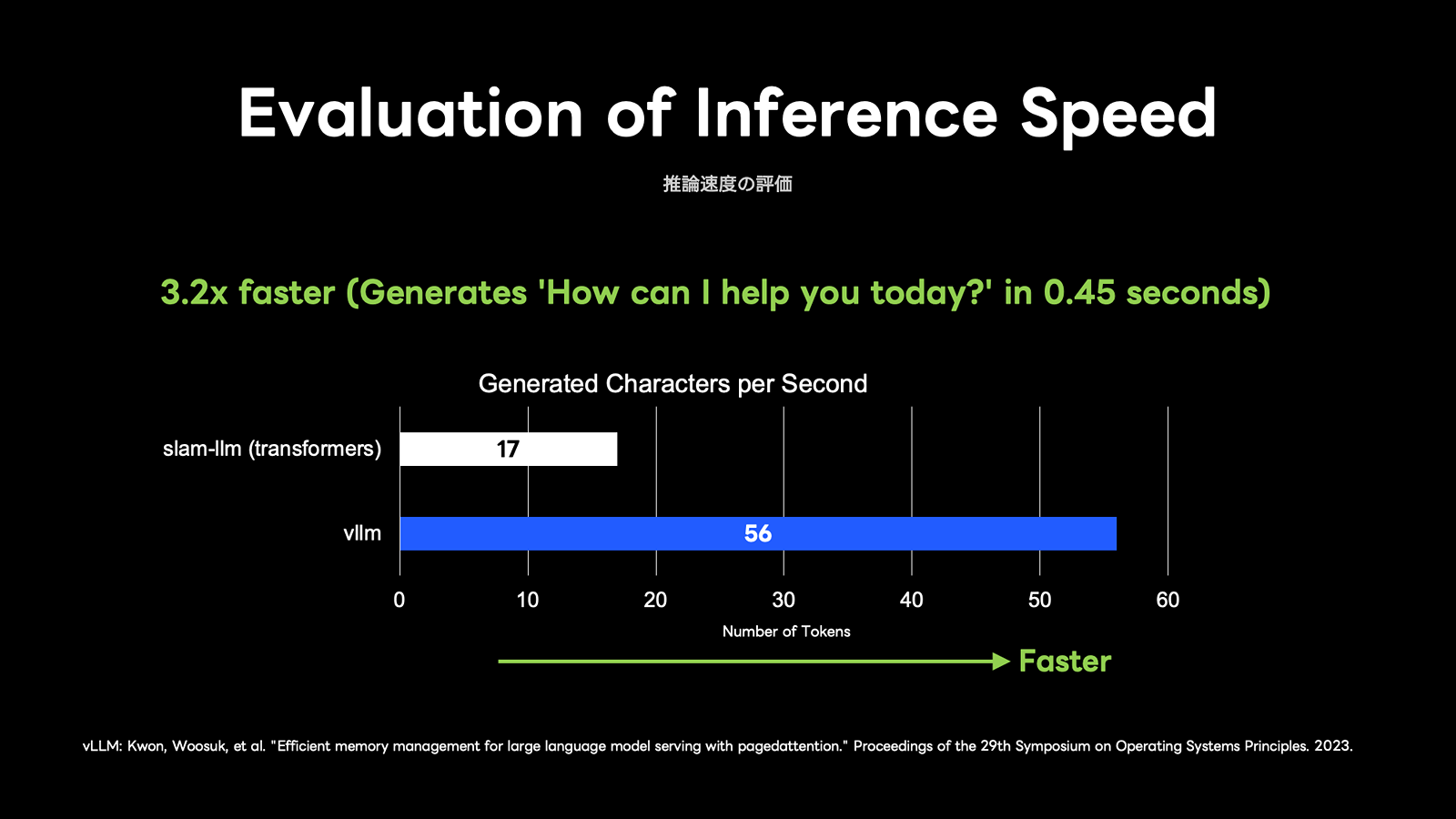
これは、おおよそ1文あたり0.45秒で文章を生成できることを意味し、既存のオンデバイス型音声合成Achoris Liteの生成時間とあわせても、応答全体の処理時間を1秒未満に抑えることが可能となりました。
現在は音声合成Achorisのストリーミング化も進めており、さらなる高速化が期待でき、より実用的な会話体験の実現に大きく近づいています。
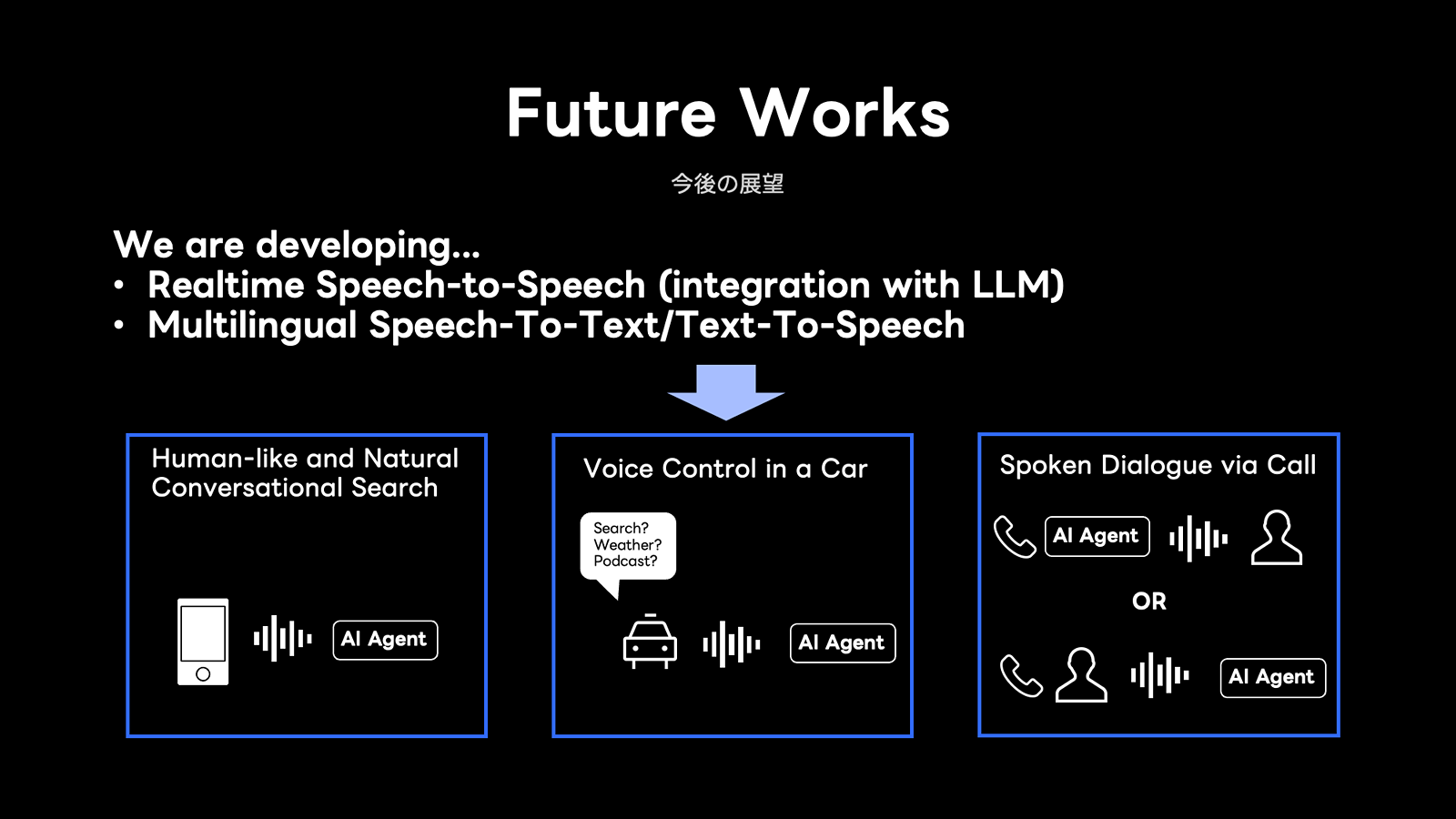
今後の展望と実用化に向けて
今回、リアルタイム音声対話AIの取り組みを紹介しましたが、LINEサービスの海外における事業展開に伴い、多言語対応にもさらに力を入れていきます。
カーナビの音声操作や電話応対の自動化、リアルタイム音声翻訳など、幅広いユースケースへの応用を視野に入れ、より高精度な音声理解、表現力豊かな音声生成、そして低遅延の実現により、LINEヤフーの利用者の皆さまに、より人間らしく自然な音声対話体験を提供することを目指しています。
本記事が、皆さまの技術的な参考やインスピレーションとなれば幸いです。
今後とも、LINEヤフーの音声AIにご期待ください。


