1. はじめに
こんにちは、奈良先端科学技術大学院大学 修士1年の大中緋慧です。私は、LINEヤフーでの8週間のインターンシップとして�、音声条件付きの音素・韻律アノテーションモデルの改良に取り組みました。
本記事では、インターンシップ中に取り組んだ内容について報告します。
2. 背景
音声条件付きの音素・韻律アノテーションモデル
まず、今回取り組んだテーマに関連する先行研究である、音声条件付きの音素・韻律アノテーションモデル[1]について簡単に説明します。
近年、大量のラベルなし音声データを用いた自己教師ありモデルの研究[2,3]が盛んになってきています。これらの手法は、大量のラベルなし音声データから有用な特徴を抽出することで、後段タスクにおいて高い精度・品質を発揮できることが知られています。他方で、テキスト音声合成(text-to-speech: TTS)の枠組みで、自己教師あり学習の枠組みと同じように大量のラベルなし音声データを活用できるようにするには、大きな課題があります。それは、自己教師あり学習とは異なり、正確な音素と韻律のラベルが求められるという点です。そのため、大規模ラベルなし音声データを活用するために高品質なアノテーションが可能な手法が求められます。
自動アノテーションの最も一般的なアプローチは、以下の図([1]の Fig. 1 より引用)に示す自動音声認識(Automatic Speech Recognition: ASR)適用後に、自然言語処理(Natural language processing: NLP)ベースの音素(読み)変換(Grapheme-to-phoneme: G2P)やアクセント推定を適用する方法です。
![Fig. 1[1] (a) から引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/c12f873ae72543349b30e7ac6ccfd628.png?updatedAt=1739759481000)
この方法の欠点は、アクセントや読みの推定に音声情報を利用できないため、音声に対して適切なアノテーションができないサンプルの出現を回避できない点にあります。(例:「化学」を「かがく」「ばけがく」のどちらで読み上げているかは音声情報がないと決まらない)
そこで、この問題を解決するために下図([1]の Fig. 1 より引用)の音声条件付きの音素・アクセントアノテーションモデル[1]が提案されました。
![Fig. 1[1] (b) から引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/db3ebf89d6c148a2a8f0162c1e6d7908.png?updatedAt=1739759496000)
この方法は、既存の ASR モデルを活用し、限られた量の正確な音素・アクセントアノテーションデータを用いて ASR モデルを fine-tuning することで音声条件付きのアノテーションモデルを実現するというものです。実験では、このアノテーションモデルを用いたアノテーションデータを利用して学習された TTS モデルと、正解アノテーションデータを利用して学習された TTS モデルの合成音声品質が同等なことが確認され、アノテーションモデルの有効性が示されています。
音声条件付きの音素・韻律アノテーションモデルの課題
しかしながら、この方法にもいくつかの課題が残されています。
1. ベースとなる ASR モデルの速度や精度の問題
先行研究[1]で採用された ASR モデルとして Whisper[4]の small モデルが採用されていました。このモデルは Encoder-Decoder 型の自己回帰モデルであ��るため、精度が高くなる一方で推論が遅くなる傾向にあります。これは、大規模なラベルなし音声データセットへの応用を見据えた場合に、アノテーションモデルの推論速度が大きなボトルネックとなります。そのため、CTC[5]などの非自己回帰型モデル[6,7]の採用による速度改善を行うことが望ましいと言えます。
2. 書記素の書き起こし能力の欠落
アノテーションモデルでは音素アクセント系列に対して Decoder の fine-tuning を行うため、書記素を書き起こす能力は失われます。そのため、音素アクセントに対応する書記素も獲得したいような場面では、書記素のみ異なるモデルを別に推論に使用する必要があり、メモリや時間的なコストが増加します。前に述べた TTS への一般的な応用では音素アクセントさえ推定できれば十分ですが、アクセント推定タスク[8,9]におけるアノテーションモデルを用いたデータ拡張や言語条件付き[10]の音声復元モデル[11]によるデータクリーニングなどの応用では音素(+アクセント)に対応する書記素が必要となるため、音素アクセントに加えて書記素も同時に推論できるモデルへの拡張が求められます。
3. 取り組んだ内容
3.1 より高精度かつ高速なベースモデルの採用
まず、前述の1つ目の課題に対処するために、ベースモデルとして Whisper の代わりに OWSM-CTC[7] を採用しました。OWSM-CTC は、CTC に基づく Encoder-only の大規模音声基盤モデルです。モデル構成は下の図([7]の Fig. 2 より引用)の通りです。
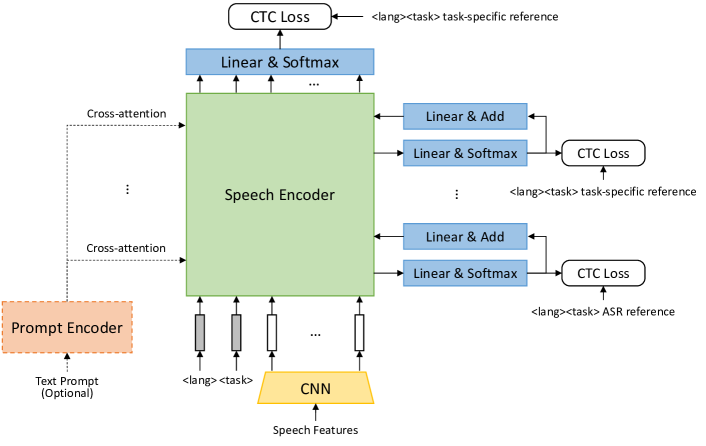
事前学習時には、各モジュールが中間層 CTC loss[12]&条件付け[16]と最終層 CTC loss により音声翻訳タスクと音声認識タスクで事前学習されています。評価実験では、[1] で採用された Whisper small モデルから約2.5倍の高速化を達成しつつ、単語誤り率も改善できることが示されています。さらに、日本語データセットである ReazonSpeech[13,14] に対しては、32.5→8.1% の大幅な改善が確認されています。
そこで、OWSM-CTC をベースモデルに採用することで処理速度・精度の改善を目指しました。
予備実験
OWSM-CTC を書記素・音素・アクセントを同時に予測するモデルに拡張するための方法としていくつかの方法が考えられます。インターン中にいくつかの方法を検討しましたが、ここでは以下の2つについて結果を述べます。
- Multitask: CTC モジュールをパラメータごと複製し、書記素と TTS label(音素アクセントの混合系列[1,15])をマルチタスク学習
- 利点:中間層 CTC & 条件付けを書記素/ TTS label の両方で行うため、学習時にモデルへリッチな情報を与えられる。
- Cascade: 共通の CTC モジュールを利用し、入力層から中間層までは TTS label 予測、その後の層では書記素予測を学習
- OWSM-CTC における音声翻訳(Speech Translation:ST)タスクでの事前学習では、浅い層では ASR タスクで、後段では ST タスクでの学習を適用することが最も良い結果であることが報告されている。それに倣い、前段では TTS label の予測を、後段では書記素の予測を行う方法を採用した。
- 今�回は、6,11,15層の中間層CTCをTTS label に対して学習し、推論時には15層目の中間層出力をTTS label の結果として取得するようにしました。
- 21,27層(最終層)では書記素に対して学習しました。
実験条件
- 学習データ
- パターン1:JSUT[21] 4410文 (+ 検証データ 248文), 1話者
- パターン2:Internal 150729文 (+ 検証データ 4220文), 13話者
- Iteration数:batch size 32 で 41000 step の反復を行いました。また、1000 step ごとに validation を行い、下に示す3つのエラー率の総和が小さいものを best model としました。
- 評価データ
- JSUT 248文
- Internal data 13904文。フィラーや感情表現を含む音声も含まれています。学習とは異なる話者4名の発話で構成されています。
- 評価指標
- Character Error rate (CER): 書記素の文字誤り率。「!?,.」などの音声に対応しないラベルは正規化により削除しています。
- Phoneme Error rate (PER): 音素の誤り率。「!?,」の音声に対応しないラベルは正規化により削除しています。
- Accent Error rate (AER): 音素長に合わせるようにパディングされたアクセント系列の誤り率
- Match rate: Mecab[22] を用いて、予測された書記素から読みを 5-best で推定し、いずれかと予測された音素がどの程度マッチするかを評価データセット単位で表した指標です。 書記素と音素の一貫性を示す指標なので、アクセント推定への応用の観点ではこの指標が高いことが重要になります。 ただし、読み推定自体が完全に考えられる読みパターンを網羅しているわけでないことに注意。
- その他の変更点
- Speech encoder 27 層のうち、5 層目ま��でのパラメータを固定しています。 これは、fine-tuning による話者依存などの過学習を抑制することが目的です。
- 学習速度やメモリ使用量との兼ね合いで、音声の入力長を 30 s から 15 s へ変更しました。音声のトリミングが発生する少数のサンプルは本実験から除外しました。
- CNN module の最終層の Conv2d の時間方向の stride を 2 から 1 へ変更し、frame shift を 80 ms から 40 ms へ変更しました。 これは、比較的系列長の長い TTS label を正確に捉えられるようにするモチベーションがあります。
評価結果
上述した実験条件で、JSUT データセットを用いて学習後、評価を行った結果を以下の表に示します。
| Method/Metrics | CER%(JSUT,↓) | CER%(Internal,↓) | PER%(JSUT,↓) | PER%(Internal,↓) | AER%(JSUT,↓) | AER%(Internal,↓) | Match%(JSUT,↑) | Match%(Internal,↑) |
|---|---|---|---|---|---|---|---|---|
| Phoneme-accent-whisper[1] (Trained by JSUT,Baseline1) | - | - | 3.85 | 3.47 | 11.46 | 18.41 | - | - |
| OWSM-CTC[7] (w/o fine-tuning,Baseline2) | 10.18 | 10.35 | - | - | - | - | - | - |
| Multitask | 10.89 | 11.91 | 0.80 | 2.47 | 5.96 | 9.48 | 50.00 | 48.86 |
| Cascade | 11.52 | 12.10 | 1.07 | 2.91 | 5.73 | 9.87 | 46.77 | 45.09 |
まず、phoneme-accent-whisper[1]と比較して、今回の OWSM-CTC を採用した場合に全ての観点で精度が上回っていることが確認できました。また、本インターンでは同条件での定量的な推論速度評価は行っていませんが、速度面においても体感では倍近い速度での推論が可能であることがわかっています。これらの点から、先行研究の課題の一つである精度と速度の改良についてはおおむね達成できたと言えます。
次に、同時予測モデルの組み合わせでの比較について述べます。まず、Multitask と Cascade では Multitask の方が高精度であることがわかります。これは、Cascade の音素アクセント予測には Speech encoder の中間層までしか寄与しないこと、書記素に関しても中間層 CTC loss と中間層での条件付けを多く取ることが精度向上に寄与していることが理由だと考えられます。この結果を踏まえて、以降は Multitask モデルを採用して議論を進めていきます。
次に、Internal データセットを用いて学習した結果を以下の表に示します。
| Method/Metrics | CER%(JSUT,↓) | CER%(Internal,↓) | PER%(JSUT,↓) | PER%(Internal,↓) | AER%(JSUT,↓) | AER%(Internal,↓) | Match%(JSUT,↑) | Match%(Internal,↑) |
|---|---|---|---|---|---|---|---|---|
| Phoneme-accent-whisper[1] (Trained by Internal,Baseline1) | - | - | 1.49 | 0.64 | 14.06 | 1.21 | - | - |
| OWSM-CTC[7] (fine-tuning前,Baseline2) | 10.18 | 10.35 | - | - | - | - | - | - |
| Multitask | 16.10 | 0.88 | 1.09 | 0.29 | 11.68 | 0.89 | 37.10 | 91.82 |
より大きなデータサイズでの学習でも、音素アクセントについては同様の傾向が得られました。また、書記素に関しては in domain の internal に特化したような精度の変化になっており、fine-tuning の挙動として納得できる結果となりました。
最後に、match rate に関して述べます。この観点では、書記素/音素の推論精度が match rate の改善にもつながることが JSUT における Multitask vs. Cascade の結果や、Internal での Multitask の結果から読み取れます。
3.2 データ拡張によるモデルの改善
前述の実験から、 match rate と推論精度が対応していることが明らかになりました。match rate はアクセント推定に利用できる推論結果の割合とほぼ同等であるため、この指標を高めることが重要です。
Internal data での学習した結果の評価では、in domain の Internal テストセットに対して書記素精度が改善していることから、学習データの書記素ドメインを拡張できればより多様なデータに対して書記素精度、match rate を改善できると考えられる。そこで TTS を用いたテキストドメインの拡張について検討しました。
また、ラベルなし音声の実データにはノイズが含まれていることが多いため、実応用を見据えた際には noisy な音声に対しても頑健に動作することが望ましいと言えます。この観点から、雑音・残響に関するデータ拡張についても検討しました。
TTS を用いたテキストドメインの拡張
先行研究[1]では、正確な音素アクセント情報付きのデータセットが少ない問題を解決するために、以下の手順による TTS データ拡張を使用していました。
- テキストのみのデータセットを用意
- テキストをNLPベースで音素�アクセント系列に変換
- 音素アクセント系列から TTS を使って音声を合成する。この音素アクセントと合成音声を1ペアデータとする。
この方法では、NLPベースの処理で読み誤りが発生しても、音素アクセントと合成音声の間では対応が取れること(テキストと合成音声間にはエラーが含まれうる)が利点となっています。今回は、テキストに対しても音声と対応が取れてほしいところですが、ひとまず上述の方法と同様のフローで TTS データ拡張を行い、学習と評価を行いました。
ノイズの多い音声に対応するためのデータ拡張
初めにすでに学習済みの Multitask (Trained by Internal) モデルがどの程度ノイズに頑健であるか簡単に検証を行いました。
まず、雑音データセットとして DEMAND[17,18]、Room Inpulse Response (RIR) データセットとして ACE challenge[19] を用いて、Signal-to-Noise ratio (SNR) が -5, 0, 5, 10, 15, 20 [dB] の際の各指標の推移を確認しました。
その結果が以下の図になります。(前述までの誤り率のコードが若干異なるため、スコアのレンジが変化しています)
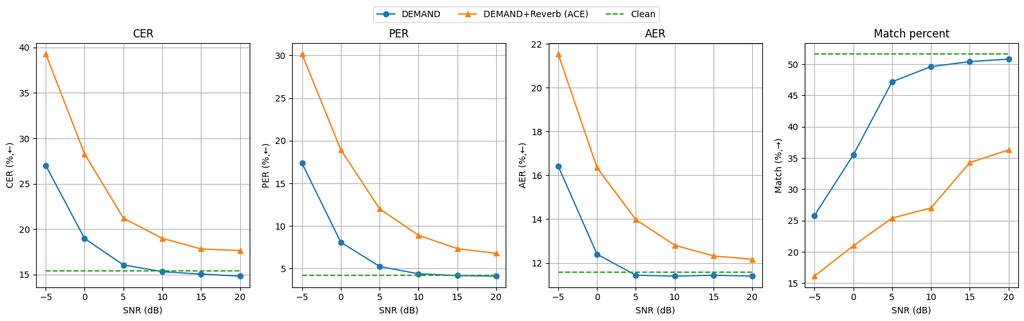
この結果からいくつかの傾向が読み取れます。まず、Noise に対してはすでに頑健であるという点です。残響がない場合には SNR 5 [dB] の低~中SNR下においてもそこまで精度が悪化しないことがわかります。一方で、残響が絡んでくると精度が大きく悪化することがわかります。それ以外に、ローパスハイパスによる劣化や発話の混合時の match rate の変化について観察しましたが、雑音・残響による劣化が最も大きかったため、雑音・残響に対処するための noisy 音声のデータ拡張を適用し、評価を行いました。
実験条件
- 学習データ
- パターン1:JSUT 4410文 (+ 検証データ 248文)
- TTS:TTSデータ拡張 (Internal の学習データのテキスト約15万文 + Wikipedia テキスト約40万文)
- Noisy:Noisy音声データ拡張。雑音はDEMAND, 残響は ACE challenge とし、雑音は0--10[dB]でランダムに決定、残響を80%の確率で適用しました。
- TTS+Noisy (合計約114万発話)
- パターン2:Internal 150729文 (+ 検証データ 4220文)
- TTS:TTSデータ拡張 (Wikipedia テキスト約40万文)
- Noisy
- TTS+Noisy(合計約112万発話)
- パターン1:JSUT 4410文 (+ 検証データ 248文)
- 評価データ
- JSUT, Internal に加えて、Noisy な実環境データセットとして ReazonSpeech tiny 5322 発話を用いて match rate を評価しました。
評価結果
| Method/Metrics | CER%(JSUT,↓) | CER%(Internal,↓) | PER%(JSUT,↓) | PER%(Internal,↓) | AER%(JSUT,↓) | AER%(Internal,↓) | Match%(JSUT,↑) | Match%(Internal,↑) | Match%(Reazon,↑) |
|---|---|---|---|---|---|---|---|---|---|
| JSUT | 10.89 | 11.91 | 0.80 | 2.47 | 5.96 | 9.48 | 50.00 | 48.86 | 10.09 |
| JSUT(TTS) | 9.90 | 6.76 | 0.74 | 2.94 | 6.15 | 6.03 | 65.32 | 61.33 | 15.35 |
| JSUT(Noisy) | 12.23 | 13.18 | 0.79 | 2.30 | 6.10 | 9.55 | 46.37 | 47.78 | 13.13 |
| JSUT(TTS+Noisy) | 10.74 | 6.72 | 0.84 | 2.95 | 6.28 | 5.68 | 64.11 | 60.82 | 17.30 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Internal | 16.10 | 0.88 | 1.09 | 0.29 | 11.68 | 0.89 | 37.10 | 91.82 | 18.99 |
| Internal(TTS) | 11.34 | 4.72 | 0.79 | 0.63 | 11.45 | 1.82 | 54.84 | 79.52 | 21.68 |
| Internal(Noisy) | 15.30 | 0.98 | 1.07 | 0.27 | 11.47 | 0.97 | 43.55 | 91.14 | 21.89 |
| Internal(TTS+Noisy) | 10.50 | 5.16 | 0.84 | 0.69 | 10.40 | 2.03 | 61.69 | 80.34 | 23.82 |
まず、元のデータ量が少ない JSUT の場合について述べます。この場合、TTS によるテキストドメインの拡張が書記素とアクセント、 match rate の改善に非常に有効なことがわかります。一方で、Noisy音声のデータ拡張は ReazonSpeech での match rate を改善する一方で、綺麗な音声で構成される JSUT, Internal テストセットでの精度を落とす結果となりました。しかし、これら2つのデータ拡張を組み合わせた場合には TTS データ拡張による改善を維持したまま、Reazonspeech に対する match rate をさらに改善できることが確認できました。
次に、中程度のデータがもともと存在する Internal の場合について述べます。こちらの場合、in domain の Internal テストセットでの精度は Internal を使った方が良くなるものの、�それ以外の評価ではおおむね JSUT と同様の傾向が確認できました。
一方で、依然として綺麗な音声データに対して20~40%、Reazonspeechで80%程度のミスマッチが発生しているという課題があります。定性的な分析としてミスマッチパターンを観察したところ、完全に破綻したような出力は少なく、部分的な誤りが原因でミスマッチを引き起こしていることが確認できました。
- sample1: バーミアンツ、オンエア獲得も疑惑浮上。|バ1ーミアンズ、4ホ1ンエ2アー3カ1クトクモ3ギ1ワク3フ1ジョー
- sample2: 彼、点作業のほうもやるんで、成ル瀬さんにご挨拶だけでもと思って。|カ2レ、4テ1ンジサ2ギヨーノ3ホ2ーモ3ヤ1ル2ンデ、4ナ2ルゼサンニ34ゴ1ア2イサツダケ2デモト3オ1モ2ッテ
この結果を踏まえて、もう少し強い制約として推論フローやデコード時の変更を用いて match rate を向上させる方法について検討します。以降の3.3, 3.4 ではその方針で検証した2つの手法についてそれぞれ説明します。
3.3 Prompt Encoder を用いた誤り修正
また、ベースモデルの OWSM-CTC のモジュールを有効活用する方向性での match rate 改善についても検討しました。今回は、音素推定において、一度推論結果が確定した後に後処理として子音誤りの修正を行う Transformer を適用する手法[20]から着想を得て、PromptEncoder をエラー修正に利用する手法を提案します。
手順について、ステップに分けて説明します。
- 正解の書記素系列、音素系列に対して置換・挿入・削除のエラーを付与し、擬似エラーを含む系列を生成します。
- Prompt Encoder の入力として、na (入力がないことを示す特殊ラベル)・正解系列・擬似エラー系列からランダムに選択しながら fine-tuning
- <na> を Prompt Encoder の入力として、トレーニングセットに対して推論を行い、実際のエラーパターンを含む系列を取得する。
- 実際のエラーパターンを含む系列 と <na> からランダムに選択しながら再 fine-tuning を行う。
- 推論時には、1) <na> 入力で推論結果を取得 2) その推論結果を条件付けとして再度推論を行い、最終的な出力を獲得する。
音声入力を取り入れつつ、反復的な推論によって書記素と TTS label のミスマッチを解消することが期待されます。
実験条件
3.2 節の TTS + Noisy のモデルをベースとして次の条件を追加しました。
- エラー修正関連のパラメータ
- ステップ 2 の fine-tuning
- 書記素・音素系列の両方で <na> を選択する確率 50 %、
- 正解あるいは擬似エラーを含む系列のいずれかを書記素・音素系列で選択する確率 50 %
- 正解系列 25%
- 擬似エラーを含む系列 25%
- ステップ 4 の fine-tuning
- 書記素・音素系列の両方で <na> を選択する確率 50 %
- 書記素・音素系列の両方で実際のエラーパターンを含む系列を選択する確率 50 %
- ステップ 2 の fine-tuning
- インターンの時間の都合上、モデルの frame shift を 80 ms としました。
評価結果
| Method/Metrics | CER%(JSUT,↓) | CER%(Internal,↓) | PER%(JSUT,↓) | PER%(Internal,↓) | AER%(JSUT,↓) | AER%(Internal,↓) | Match%(JSUT,↑) | Match%(Internal,↑) | Match%(Reazon,↑) |
|---|---|---|---|---|---|---|---|---|---|
| JSUT(TTS+Noisy,Baseline) | 10.91 | 7.89 | 1.40 | 2.73 | 7.00 | 5.74 | 52.02 | 59.71 | 18.52 |
| w/ Error correction | 11.60 | 6.70 | 0.84 | 3.53 | 6.09 | 6.25 | 58.87 | 63.86 | 19.74 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Internal(TTS+Noisy,Baseline) | 11.17 | 5.75 | 1.07 | 0.85 | 10.56 | 2.34 | 52.82 | 74.47 | 23.54 |
| w/ Error correction | 11.39 | 3.00 | 0.85 | 0.55 | 10.41 | 1.48 | 59.27 | 85.72 | 34.75 |
エラー修正を導入することによって、CER・PER を同等以上の精度に保ったまま、match rateを更に改善できることが確認できました。
3.4 推論時のフロー変更による match rate の改善
データ拡張により、精度や ReazonSpeech での match rate を押し上げられることを確認できましたが、Internal の JSUT に対する match rate (37.10%) や ReazonSpeech に対する match rate は十分とは言えません。
読みの辞書を用いて枝刈りを行うビームサーチ推論
より強い制約を用いて、書記素と音素のマッチを保証するための推論方法として読みの辞書を用いて枝刈りを行うビームサーチ推論について検討しました。
まず、単語に対する考えられる読みの集合が保持された以下のような辞書を用意します。今回は教師なし学習で統計的に学習された内製の読み辞書を用いました。
{ ...
"ズレ": [
"ズレ"
],
"揚げ": [
"アゲ"
],
"一旗揚": [
"ヒトハタアゲ"
],
"一皮": [
"ヒトカワ"
],
"剥": [
"ハ",
"ム",
"ハゲ",
"ハギ",
"ムケ",
"パガ",
"ヘズ",
"ハク",
"ムキ",
"ハガ",
"ムク"
],
"一": [
"イチ",
"カズ",
"イッ",
"ーチ",
"ヒト",
"イツ",
"イ",
"ハジメ",
...
}次に、書記素、音素のいずれかの仮説をビームサーチを用いて先に確定させます。この時、パラメータ N として N-best 分の仮説を保持しておきます。そして、残った側の系列の推論を行います。この時に、仮説の部分系列が事前に保持している N-best 分の仮説に合う場合はそのまま残し、そうでない場合はその仮説は破棄するという処理を行います。最終的に、残った仮説の中で best score のものを最終結果とします。これにより、書記素、音素の読みが辞書を介して一致することが保証される形で推論を行うことができます。辞書に要求される精度についても、極端に誤った読みのペアはアノテーションモデルにより弾くことができるため適合率さえ高ければ十分であり、辞書の構築難易度は高くないと言えます。
実験条件
- 適用モデル:Multitask (Internal)
- 評価データ:JSUT 248文
- ビームサーチのパラメータ
- 前段の推論:ビームサイズ2、N=5
- 後段の推論:ビームサイズ4, 10, 20 (仮説の枝刈りが走るため大きめに取っている)
- 書記素が先、TTS label が後 (G2P)、TTS labelが先、書記素が後(P2G)の両者について検証しました。読み一致の検証時にはアクセントラベルと読点などは除外されています。
- 評価指標
- match rate と、3つの誤り率をマッチしたもののみで計算
評価結果
推論結果を以下の表に示します。ここで、誤り率は誤った前段の系列に無理やり読みをそろえに行くような挙動となるため、参考程度として解釈してください。
| Method/Metrics | CER%(JSUT,↓) | PER%(JSUT,↓) | AER%(JSUT,↓) | Match%(JSUT,↑) |
|---|---|---|---|---|
| Internal | 12.67 | 0.46 | 11.28 | 37.10 |
| g2p (beam_size=4) | 14.08 | 1.79 | 11.86 | 58.06 |
| g2p (beam_size=10) | 14.18 | 2.04 | 12.04 | 61.29 |
| g2p (beam_size=20) | 14.42 | 2.27 | 12.23 | 62.90 |
| p2g (beam_size=4) | 12.45 | 0.20 | 11.85 | 17.34 |
| p2g (beam_size=10) | 13.85 | 0.61 | 12.56 | 35.08 |
| p2g (beam_size=20) | 14.79 | 0.66 | 11.76 | 49.19 |
g2p では読みの制約を入れた際に学習時の変更なしで倍近く match rate を改善できました。また、p2g でもビームサイズを大きく取った場合には match rate が改善することを確認できました。以下に、それぞれが効果的に機能しているサンプルの例を示します。
- sample1
- Internal:道端に咲いている花に目を向けると生命の異ぶを感じることができる|ミチバタニサイテイルハナニメオムケルトセーメーノイブキオカンジルコトガデキル
- p2g (beam_size=20): 道端に咲いている花に目を向けると生命の異ぶきを感じることができる|ミチバタニサイテイルハナニメオムケルトセーメーノイブキオカンジルコトガデキル
- sample2
- Internal:今年も白夜の季節がやってきた|コトシモピャクヤノキセツガヤッテキタ
- g2p (beam_size=20): 今年も白夜の季節がやってきた。|コトシモビャクヤノキセツガヤッテキタ
p2g でビームサイズが小さい場合の match rate の悪化については、仮説の topk が全て読みにマッチせず探索途中で仮説数が0に落ちてしまうことが原因であることがわかっています。今回は、この方法に取り掛かるタイミングが遅かったため、ここに対処するための実装までできませんでしたが適切に対処し仮説数が0に落ちることを回避すれば、ビームサイズが小さい場合でも match rate が改善すると考えられます。
4. まとめと今後の課題
今回のインターンでは、先行研究の音素アクセントアノテーションモデルの改良・拡張を目指しました。まず、モデルの推論速度向上、精度改善を目指してベースモデルに OWSM-CTC を採用し実験を行いました。その結果、推論速度を向上しつつ、音素アクセントの推論精度についても改善を達成することができました。この点における今後の展望としては、今回のような認識タスクによる評価だけでなく、実際の後段タスクである TTS における検証が挙げられます。
次に、書記素と音素の match rate 改善とさらなる精度改善を目指して、データ拡張とデコード時の読み一致制約、Prompt Encoder ベースのエラー修正についての実験評価を行いました。その結果、データ拡張、デコード時の読み一致制約、Prompt Encoder ベースのエラー修正のそれぞれの有効性を確認することができました。今後の展望としては、より CTC と相性の良い読み一致保証手法の提案が挙げられます。今回はビームサーチに読み一致の制約を組み込みましたが、これにより CTC の高速なデコードが可能という利点が損なわれています。そのため、CTC の高速な推論という性質を活かしたまま読��み一致の制約を入れる手法を検討していくことが重要だと考えています。また、Prompt Encoder ベースのエラー修正を用いた手法の、実際のアクセント推定や音声復元における評価ができると良いと考えています。
5. 最後に
今回のインターンでは、今まで経験のなかったタスクでの研究を行うことができ、自身の知見や視野を広げることができたように感じています。また、全ての実験を ESPNet を用いて行ったため、今までに経験のなかったツールキットを使った実装や実験に関する知見が得られました。いろいろと不慣れな中での8週間でしたが、メンターの白旗さん、そして山本さんに毎日議論や実装に関するアドバイスをしていただいたおかげで、非常に有意義な時間を過ごせたように感じています。また、川村さん、朴さん、藤田さん、小松さんには随所で的確なアドバイスやサポートをいただきました。おかげで、研究を円滑に進めることができました。本当にありがとうございました。この経験を今後の研究にも活かしていきたいです。
参考文献
[1] Y. Shirahata, et al., "Audio-conditioned phonemic and prosodic annotation for building text-to-speech models from unlabeled speech data," Proc. of Interspeech, 2024.
[2] A. Baevski, et al., "wav2vec 2.0: A framework for self-supervised learning of speech representations," Advances in neural information processing systems, vol. 33, pp. 12449–12460, 2020.
[3] W.-N. Hsu, et al., "HuBERT: Self-supervised speech representation learning by masked prediction of hidden units," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021.
[4] A. Radford, et al., "Robust speech recognition via large-scale weak supervision," Proc. ICML, 2023.
[5] A. Graves, et al., "Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks," Proc. of ICML, 2006.
[6] S. Kriman, et al., "Quartznet: Deep automatic speech recognition with 1d time-channel separable convolutions," Proc. of ICASSP, 2020.
[7] Y. Peng, et al., "OWSM-CTC: An open encoder-only speech foundation model for speech recognition, translation, and language identification," Proc. of ACL (main), 2024.
[8] H. Tachibana, et al., "Accent Estimation of Japanese Words from Their Surfaces and Romanizations for Building Large Vocabulary Accent Dictionaries," Proc. of ICASSP, 2020.
[9] B. Park, et al., "A Unified Accent Estimation Method Based on Multi-Task Learning for Japanese Text-to-Speech," Proc. of Interspeech, 2022.
[10] Y. Jia, et al., "PnG BERT: Augmented BERT on Phonemes and Graphemes for Neural TTS," Proc. of Interspeech, 2021.
[11] Y. Koizumi et al., "Miipher: A Robust Speech Restoration Model Integrating Self-Supervised Speech and Text Representations," Proc. of WASPAA, 2023.
[12] J. Lee et al., "Intermediate Loss Regularization for CTC-based Speech Recognition," Proc. of ICASSP, 2021.
[13] Y. Yin et al., "ReazonSpeech: A Free and Massive Corpus for Japanese ASR," 言語処理学会第29回年次大会 発表論文集, pp. 1134-1139, 2023.
[14] https://huggingface.co/datasets/reazon-research/reazonspeech
[15] M. Omachi, et al., "End-to-end ASR to jointly predict transcriptions and linguistic annotations," Proc. of NAACL, 2021.
[16] J. Nozaki, et al., "Relaxing the Conditional Independence Assumption of CTC-based ASR by Conditioning on Intermediate Predictions," Proc. of Interspeech, 2021.
[17] T. Joachim, et al., "The diverse environments multi-channel acoustic noise database (demand): A database of multichannel environmental noise recordings," Proc. of Meetings on Acoust., 2013.
[18] https://zenodo.org/records/1227121
[19] J. Eaton, et al., "Data Corpus for the IEEE-AASP Challenge on the Acoustic Characterization of Environments (ACE)," doi: 10.5281/zenodo.6257551.
[20] K. Kurihara, et al., "Low-Resourced Phonetic and Prosodic Feature Estimation With Self-Supervised-Learning-based Acoustic Modeling," Proc. of ICASSP SASB Workshop, 2024.
[21] R. Sonobe, et al., "JSUT corpus: free large-scale Japanese speech corpus for end-to-end speech synthesis," arXiv preprint(1711.00354), 2017.
[22] https://taku910.github.io/mecab/