LINEヤフー株式会社で、出前館の SRE をしている岡田 将です。今回の記事では、Wide Events と Honeycomb を組み合わせて可観測性を高める手法、主に Unknown unknowns (未知の未知) に対応しやすくするアプローチを紹介します。
Wide Events
Wide Events は、一つのイベントにあらゆる関連情報をまとめて記録するアプローチです。ログ、メトリクス、トレースを分けて考えるのではなく、リクエストやジョブ単位で情報を広く詰め込むことで、後から自由に分析できるのが特長といえます。
このアプローチに興味を持つきっかけになったのは、A Practitioner’s Guide to Wide Events、 All you need is Wide Events, not “Metrics, Logs and Traces” というブログ記事を読んだことでした。業界ではよく、ログ、メトリクス、トレースという三つの柱が語られますが、一方で「そもそもトレースとログはどう違うのか」「どちらに何を記録すべきか」といった整理が難しく、人によって導入ハードルが高くなりがちです。こうした混乱を解消する方法の一つとして、Wide Events の考え方が提示されているのがとても新鮮でした。
特に興味深かったのは、Unknown unknowns に対処しやすいという点です。あらかじめログの形式やメトリクスの種類を厳密に決めても、障害やパフォーマンス低下の原因を事前にすべて予測するのは難しいものです。Unknown unknowns に直面すると、必要な情報が見当たらず後から後悔するケースも少なくありません。ところが Wide Events であれば、「とにかく広く情報を詰め込み、あとでさまざまな観点から分析する」というスタイルを自然に実行できるため、未知の角度から問題に切り込むヒントを逃しにくくなります。
出前館では、OpenTelemetry を使ってログ、メトリクス、トレースを整理しているものの、用語や運用方法が複雑になりがちで、可観測性を高める手段としてはややハードルが高いと感じることがありました。具体的には、メトリクスのカーディナリティ問題が頻繁に発生し、仕様上これを改善するのは難しい状況です。また、調査の際にログ、メトリクス、トレースを複数の画面で見比べる必要があり、原因特定に時間がかかってしまっていました。そんな中で Wide Events に出会い強く興味を抱きました。一つのイベントに多角的な情報を集約しておけば、後からの分析やトラブルシューティングで抜け漏れを防ぎやすくなり、別の視点や分析の切り口で深掘りすることも簡単になります。この手法と Observability Platform を掛け合わせることで、どれほど楽になるかを実際に試してみたいと思いました。
Honeycomb
この Wide Events の考え方を実際に試す際に注目した Observability Platform の一つが Honeycomb です。Wide Events を活かすためには、幅広いデータを取り込んで、あとから自在に分析できる仕組みが欠かせません。Honeycomb はまさにその要件を満たす機能を備えています。高次元・高カーディナリティのフィールドに対応している点、データサイズではなくイベント数に応じた料金体系を採用しているため、必要十分な情報を広く持たせられるのも大きな利点といえます。中でも BubbleUp の機能は、Wide Events の概念と非常に相性が良いと感じています。では、この Honeycomb が具体的に何をもたらしてくれるのか、簡単に紹介していきます。
BubbleUp を使った分析
BubbleUp は、問題のあ��るデータ群(たとえばエラーや遅延が多いリクエスト)を選ぶと、正常なデータとの違いを自動で比較し、「どのフィールドが原因に関わっていそうか」を一目で示してくれます。結果的に、複数のツールを行き来したりする手間を大幅に削減し、インシデント対応や原因特定のスピードアップに大きく貢献します。具体的にどんな操作フローで問題を突き止められるのかをイメージしていただくため、シンプルなウェブアプリを例にとり、特定パラメータでのみ応答時間が遅くなる仕組みを作ってみました。
以下では、この人工的な遅延ケースを Wide Events と組み合わせて Honeycomb に送り込み、BubbleUp を使って高速に原因を発見する例をお見せします。実案件と比べると非常に単純なものですが、Unknown unknowns に対応するうえで実践のヒントをつかんでいただけるのではないかと思います。
1. 概要
まずは、/products というエンドポイントを提供するシンプルなアプリを用意します。このアプリは、通常のリクエストでは遅延を起こさず、クエリパラメータ category に "special" が指定された場合にだけ、2秒の処理遅延を挿入するという仕組みにします。こうすることで、明確なエラーが起きていないにもかかわらず、"special" という特定パラメータを付けたリクエストだけ応答に時間がかかる不具合を再現できます。BubbleUp を使った原因究明の手順を示すには、このように原因が限られたパラメータだけ極端に遅いケースがあると、分析の効果がよりわかりやすくなります。
2. ソースコード例
import (
...
"go.opentelemetry.io/otel/attribute"
"go.opentelemetry.io/otel/trace"
...
)
func handler(w http.ResponseWriter, r *http.Request) {
...
if category == "special" {
time.Sleep(2 * time.Second)
}
span := trace.SpanFromContext(r.Context())
span.SetAttributes(attribute.String("category", category))
defer span.End()
...
}上のように、クエリパラメータが "special" だった場合にだけ 2秒の遅延を挿入しています。また、OpenTelemetry のトレース機能を使って "category" という属性をスパンに付与しています。これで、後から Honeycomb 上で「どの category を処理していたときに遅延が発生したのか」という検証が容易になります。実際のアプリでは Honeycomb にデータを送る実装を行っていますが、ここでは詳細を割愛しています。
3. 可視化
このアプリをしばらく実行していろいろな category でアクセスすると、「通常は応答が速いが特定の場合だけ遅延する」イベントが Honeycomb に蓄積されます。まずは Query Builder を使って、下のように duration_ms のヒートマップを可視化します。
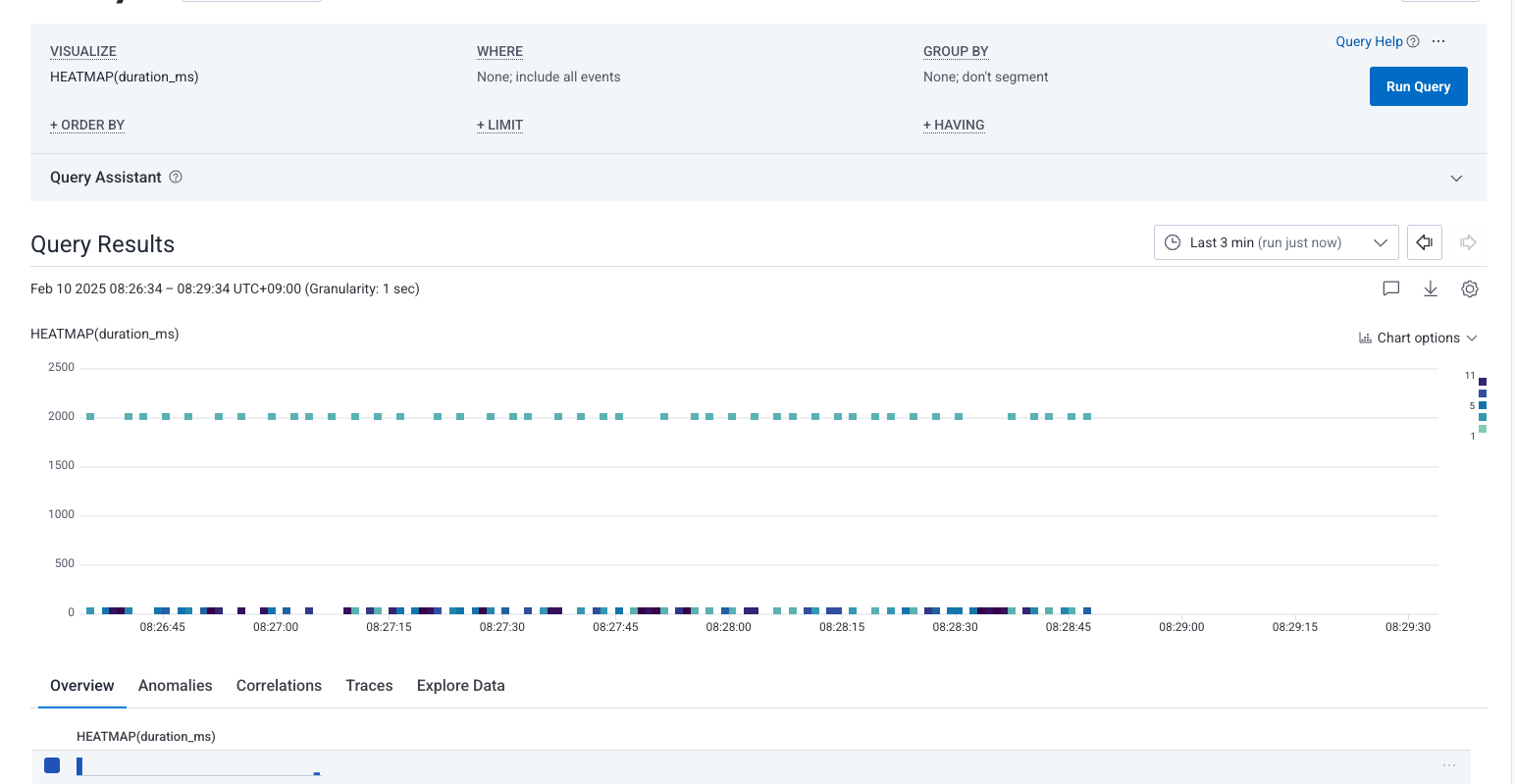
4. 原因調査
ヒートマップを眺めると、一部だけ明らかに応答時間が高い部分が見られます。下のスクリーンショットのように、その範囲をドラッグして選択します。
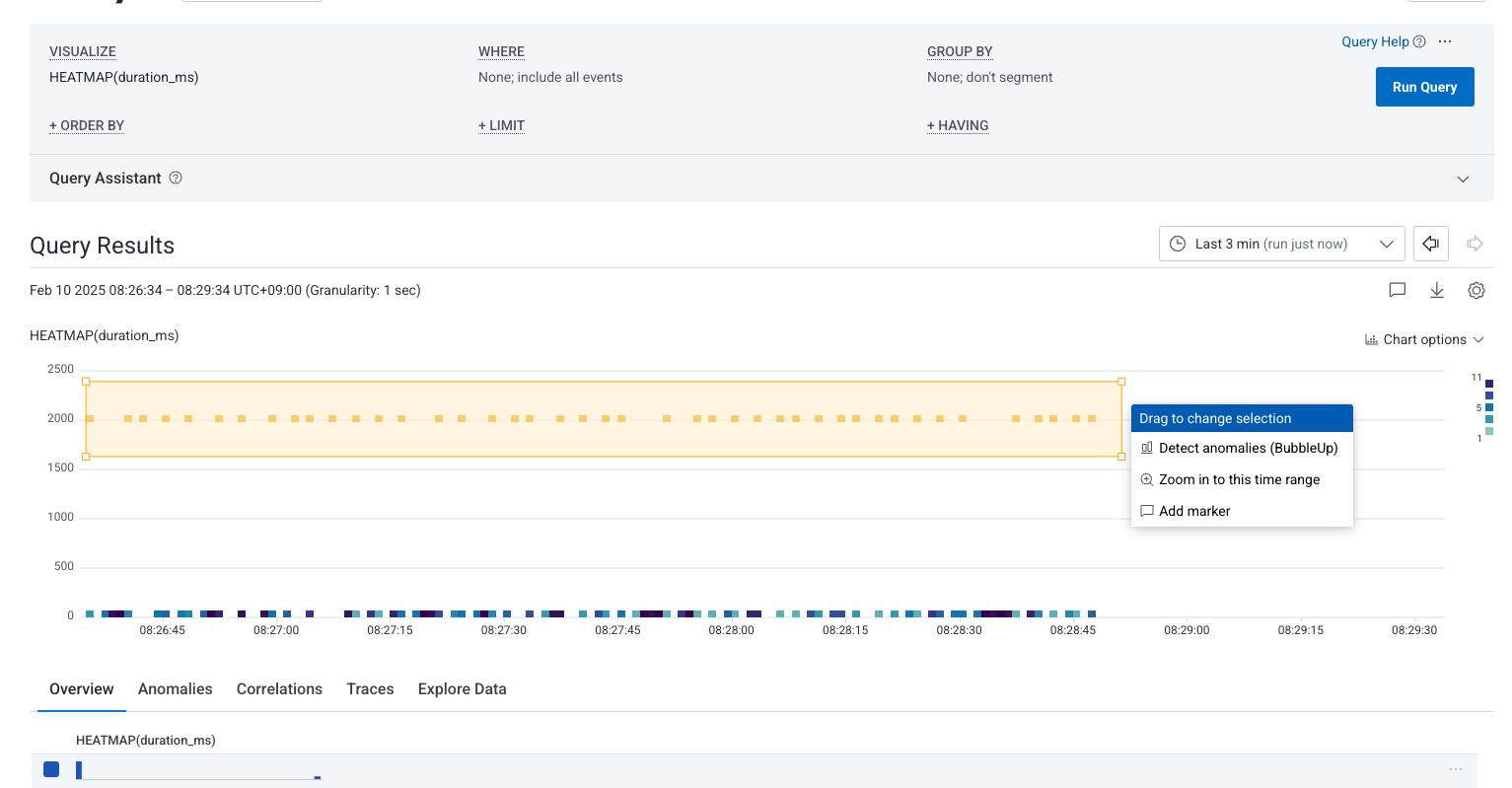
すると、Detect anomalies (BubbleUp) が表示されるため、これをクリック。比較結果の画面が表示されます。
BubbleUp は選択範囲(Selection)のデータと、その他(Baseline)のデータを自動で比較し、次のような画面を出力します。
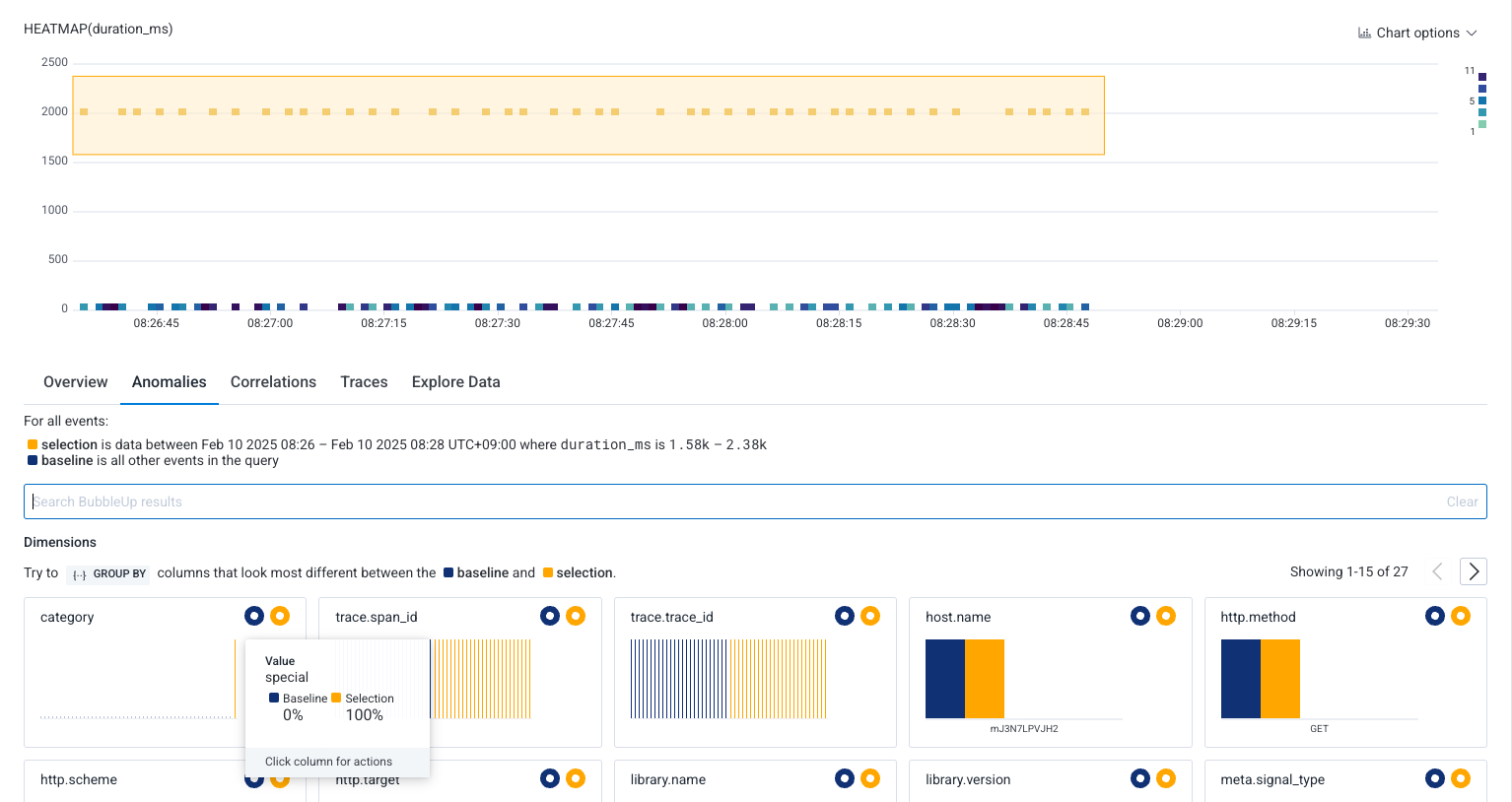
複数のフィールドがリストアップされ、そのうち category フィールドの "special" が際立って多いことがグラフでわかります。ほんの数クリックで「遅いリクエストは category が special の場合である」ことを特定できました。
今回はごく簡単な例ですが、実際のマイクロサービス環境などでは、問題の原因が多様な要素と絡み合うことがしばしばあります。Wide Events と BubbleUp を組み合わせれば、こうした Unknown unknowns でも素早く突き止められる可能性が高まり、デバッグやインシデント対応の効率を大きく向上させると考えています。
たとえば、以下のような属性をイベントに含めておくと、さまざまな視点から問題を追跡しやすくなります。
- アプリのバージョン
- バージョン差によるパフォーマンスの変化をすぐに把握できます。
- リージョン、アベイラビリティゾーン
- 特定のリージョンやアベイラビリティゾーンだけ遅延していないかなど、インフラ由来の問題をすぐに把握できます。
- ユーザー ID、組織 ID
- 特定のユーザーや組織だけに発生している問題なのか、全員に広がっているのかを切り分けやすくなります。
まとめ
このように、とにかく関連しそうな情報をひとまとまりのイベントに押し込むことで、後から BubbleUp を利用して、問題の原因を高速に突き止めることができるようになります。Unknown unknowns に対しても、まずはイベントに情報を充実させておけば、どのような切り口の分析でも必要なデータがそろっている、というのが大きな強みです。データが足りない状態だと問題を見つけるのに一苦労ですが、Wide Events の方針を採用していれば、あらゆる要因を後から自由に突き止められる可能性が高まります。
Honeycomb については、上で紹介した BubbleUp を活用して Unknown unknowns にも対応しやすいといった運用面の特長に加え、データサイズではなくイベント数に基づく課金体系を採用し、ユーザー数に応じた追加コストが発生しないなど、コスト面でも大きな利点があります。現在はまだ小規模な環境での検証にとどまっていますが、今後はより複雑なシステムでも導入を試み、既存のツールとの比較や使い分けを検討していく予定です。