こんにちは。LINE Plus(韓国にある、LINEヤフー株式会社の子会社)のRedisチームでDBA業務を担当しているJeonghoon Kimです。私たちのチームはその名の通り、代表的なキーバリューストア(key-value store)Redisを研究し、社内に導入しています。また、国や法人を問わずに独自で運営しているサービスを除く、LINE関連サービスで使用されるすべてのRedisに対して技術サポートを担当しています。
その間、新しいサービスが生まれ、既存のサービスも成長してRedisの規模も徐々に大きくなってきました。この記事では、2023年の1年間、大規模なRedisを運用してきた私たちのチームの経験についてお伝えしたいと思います。まず、私たちが運用しているRedisのおおよその規模と、HA(high availability)をどのように構成したかを簡単に説明し、クラウドリソースをより効率的に使うために行った「Low Usage Project」を紹介します。
Redisの運用規模としてはおそらくアジア最大級?
「大規模なRedis」という表現があまりピンと来ないかもしれません。以下は、昨年11月から今年2月までの使用量増加の推移を半月ごとに示したグラフです。
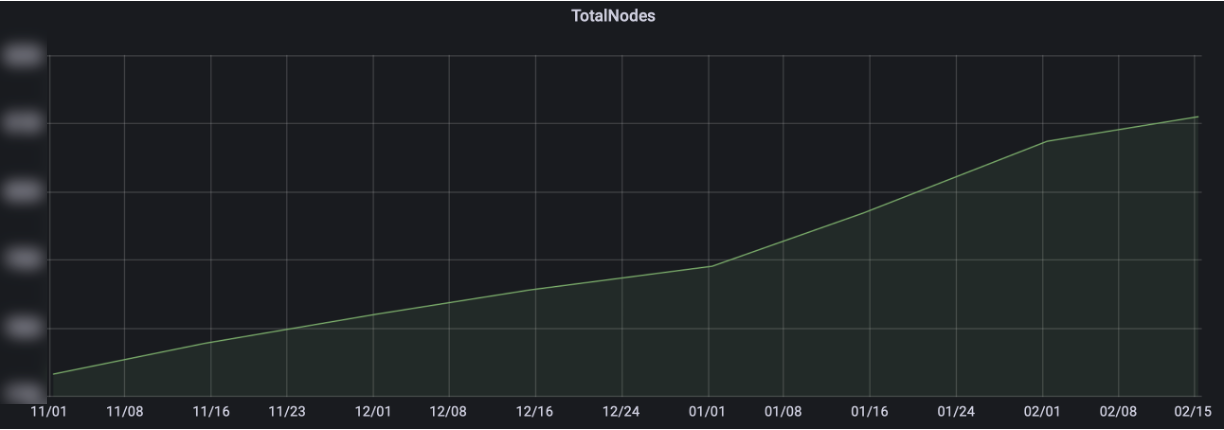
具体的な数字は公開できませんが、確かなことは、時間がたつにつれて社内で使用されるRedisの規模がどんどん大きくなっているということです。社内クラウドを通じて提供されるRedisもあり、一部のサービスはDBAの管理の下でVMやPMに直接インストールして運用することもあります。
従来もかなり大きな規模のRedisを運用していたため、もしかしたら「アジア最大規模」ではないかと思っていました。それが最近、Redis Enterpriseのエンジニアの方から、中国のある会社で膨大な規模のRedisを運用しているという話を聞き、その規模を知ることができました。驚くことに、私たちの規模はその規模を上回っています。そのため、私たちがおそらくアジア最大規模ではないかと推測しています。
障害はいつでも発生する可能性がある
入社当初、チームメンバーからよく言われ、今でも痛感していることがあります。それは、障害はいつでも発生する可能性があるということです。ソフトウェアであれば、開発能力の範囲内で直接トラブルシューティングが可能です。リソースを多く使う部分があれば、ロジックを改善して最適化するなどがその例になると思います。しかし、ハードウェアの場合は本当に恐ろしいです。ハードウェアを構成するさまざまな部品(CPU、RAMなど)のどれか一つでも問題が発生した場合、PMあるいはHV(hypervisor)にサービス中断を伴うメンテナンスが必要です。さらには、運用中に特定のベンダーの一部の部品全体から問題が発見され、長時間にわたってサービス中断を繰り返した経験もあります。
HA構成のおかげでおそらく安心できます!
ディスクストレージを使用する他のDBMSとは異なり、Redisはインメモリ(in-memory)データベースです。メモリは揮発性の媒体であるため、Redisプロセスが終了した場合、データが失われることを覚悟��しなければなりません。
それを防ぐため、私たちが運用しているRedisは基本的に「1 Primary - 1 Replica」構造を採用しています。「より多くのReplicaノードがあればもっと安全で便利ではないか」と思うかもしれませんが、各構造にはそれぞれメリットとデメリットがあります。下図は、「1 Primary - 1 Replica」構造と「1 Primary - 2 Replica」構造を表したものです。
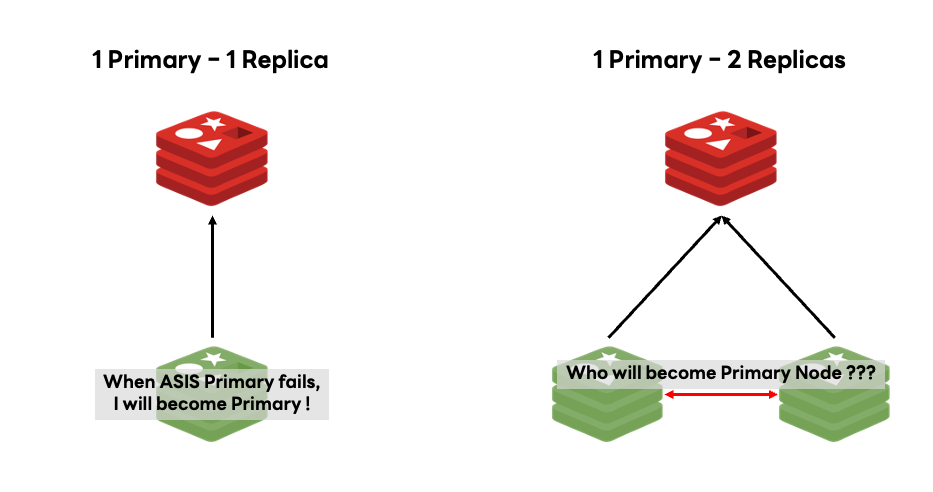
上の図のようにReplicaノードが2つある場合、Primaryノードに問題が発生したとき、どのReplicaノードがPrimaryノードになるかを決定する追加プロセスが必要です。もちろん、このデメリットが致命的なものではありませんが、Replicaノード間で発生する衝突の可能性も考慮し、「1 Primary - 1 Replica」構造で運用しています。意図したわけではありませんが、この構造はReplicaノードを最小化し、コスト面での最適化も実現できました。
この状態でPrimaryノードのハードウェアに問題が発生した場合、既存のReplicaノードがPrimaryノードに昇格され、問題なくサービスを運用できます。しかし、ハードウェアの問題が解決されるまでは、Primaryノードが1つだけ存在することになり、まだ少し危険な状態です。
Replicaを追加します(それはReplicaがないということですから)
Primaryノードだけが残っている場合、そのノードまでダウンするとデータ損失につながる可能性があるため、高可用性を維持するために「1 Primary」状態を放置することはできません。解決策は簡単です。Replicaノードをもう1つ追加すれば済みます。それに備えて、チームレベルで高スペックのサーバーを何台も用意しておき、必要に応じてサーバーを追加します。これらのサーバーはいつでもRedisを実行する準備ができており、サービス中断が発見されたらすぐにPrimaryノードだけが残っているサービスに一時的なReplicaノードを追加する作業を行います。
下図は、常に「1 Primary - 1 Replica」構造を保つように一時的なReplicaノードを追加する過程を示しています。

しかし、驚くことに私たちは現在、クラウド環境で管理されていないPMの場合、その作業を毎回手作業で行っています。そのような状況が頻繁に発生しなければいいのですが、実際には一週間に何度も何度も発生しています。障害はいつでも発生する可能性があるため、社内の各種サービスを問題なく運営するために、使命感を持ってあらゆるリスクに対応しています。では、クラウド環境ではどのように作業しているのでしょうか?
クラウド環境へのオートヒーリングの導入
前述のように、現在運用しているRedisの規模が非常に大きいため、もしクラウド環境で管理しているRedisまで、各サーバーのすべてのメンテナンスに上記の対応を繰り返さなければならない状況だったら、体がいくつあっても足りません。毎回手作業で行うことは不可能ですし、かといって残りのサーバー1台だけを頼りにして放置しておくわけにもいきません。この問題を解決するために、社内クラウド環境にはオートヒーリングを導入しました。
下図は、クラウド環境に導入したオートヒーリングが動作するプロセスを示しています。

要するに、サーバーのメンテナンスが行われる際に、新しいサーバーを追加することです。違いといえば、新しく追加されたサーバーが返却されるのではなく、メンテナンス対象のサーバーが返却されることです。クラウド環境なので、PMとは異なって簡単にサーバーの追加や交換ができ、自動化することができました。
サービス中断が発生した場合には、Redisの状態を確認する必要があるため、夜中にも起きて確認する必要があることは変わりません。しかし、HA構成を維持するように自動化プロセスを構築しただけで、工数を大幅に減らすことができました。
ほう、使用量が増えていますね
良いサービスは時間がたつにつれ、使用するサーバーの規模がだんだん大きくなるものです。それに応じて、社内クラウドサービスにもさまざまな機能を追加して改善し、安定性を確保しています。クラウドサービスは開発者が使いやすいというメリットだけでなく、データベース管理者から見ても非常に多くのメリットがあります。その中で私たちが挙げたメリットは、以下のとおりです。
- データベース数が増えても、管理工数が必ずしも正比例で増加しない
- (拡張の場合、妥当なスペックかどうかを検討する過程はありますが)拡張や縮小が容易である
このような環境の下、開発者は簡単に「多数のデータベース」を提供され、私たちは簡単に「大規模なデータベース」を提供できます。そうして、まるで戦闘力が上がるように、より多くのデータベースを管理しているうちに、より多くの使用事例を発見し、トラブルシューティング事例を残して、より強固な技術力を身につけていました。そんなある日、クラウド環境でも極限まで負荷がかかる可能性があることに気づきました。
Low Usage Projectの企画と準備
クラウド環境では、その中ではさまざまな状況に柔軟に対応できますが、クラウド自体の物理的なリソースが不足している状況まで柔軟に対応するのは困難です。つまり、物理的サーバーが追加されない限り、容量の限界は決まっており、それ以上のサービスを提供することは難しくなります。
実は、前述の「極限まで負荷がかかる」という表現は少し大げさな表現です。サービス提供に無理はありませんでした。ただ、想像以上に使用量が多かったのは事実です。それに対処する方法は簡単です。使用量が多ければ、よく使わないリソースを一部返却するか、縮小すればいいのです。前述のように、クラウドサービスは拡張や縮小が容易なので、それを実行するのは難しくありません。
私たちはそれをプロジェクト化し、「Low Usage Project」という未使用または低使用のRedisを返却するキャンペーンを展開しました。この記事を読んでいる方の中には、学生時代にAWSなどからサーバーを借りて利用した経験がある方も多いと思いますが、借りたサーバーを期限内に返却せず、保有クレジット以上の費��用が請求された経験がある方もいるでしょう。社内クラウドも同様です。使用していないのに放置しているのであれば、リソースを無駄にしていることになります。それに着目し、大規模なインフラ運用の宿題のような「無駄なコストとリソースの浪費を減らす」という目標を掲げ、キャンペーンを準備しました。
キャンペーンを準備するにあたり、未使用または低使用を判断する基準を設けたり、スケールインまたはスケールダウンの際にサービスに影響はないかを判断するなど、考慮すべき点が想像以上に多くありました。以下は、そのような悩みの軌跡です。

その中で最も重要なのは「ユーザーが望むかどうか」でした。では、各悩みをどのように解決していったのか、簡単に説明します。振り返って文章を書いている今となっては大したことないように話していますが、当時は非常に苦しい悩みであり、試行錯誤も経験しました。
シュレーディンガーのRedis:使用することも、使用しないことも
Low Usage Projectを実行して真っ先にぶつかった問題は、「本当にこのRedisは使われているのか」を判断することでした。それはRedisで一番重視するメモリ使用量だけでは判断できない問題です。もちろん、エクスポーターを使って各種指標を収集していたので、以下のようにコマンドの発行回数など、さまざまな指標を確認することはできました。
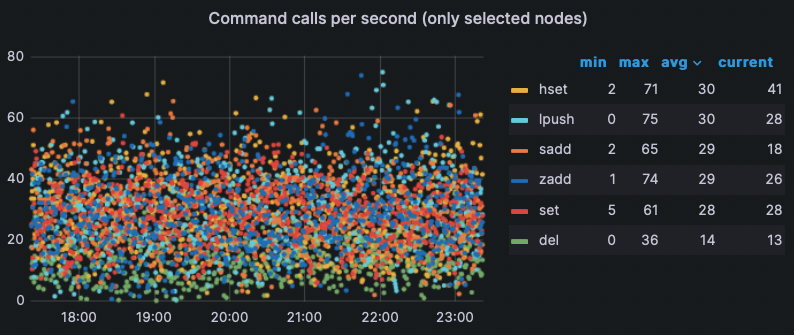
問題は、指標だけ十分だったということです。コマンドの発行履歴は比較的重要度が低く、別途後処理していない状態でした。つまり、指標のデータベースを開いてみても使用量を識別することはできませんでした。ただ、生(raw)データしか存在しませんでした。
しかし、データが存在すること自体に感謝し、簡単に使用量を判断できるように後処理を行いました。最終的に、各サービスについて最近のコマンドの発行回数やシステム使用量を基に、内部で低使用の判断基準を設けました。その後は、今後同じことを繰り返さないように体系化し、メモリ以外にも各種指標を追跡・管理できるようにしました。
あれ? それって、そういうことじゃないんだけど
未使用のRedisは簡単に整理できます。使用中のリソースを返却するだけで済みます。しかし、低使用のRedisなら話は少し変わってきます。以下は、例としてRedisをインストールした後、使わずに放置してみた様子です。
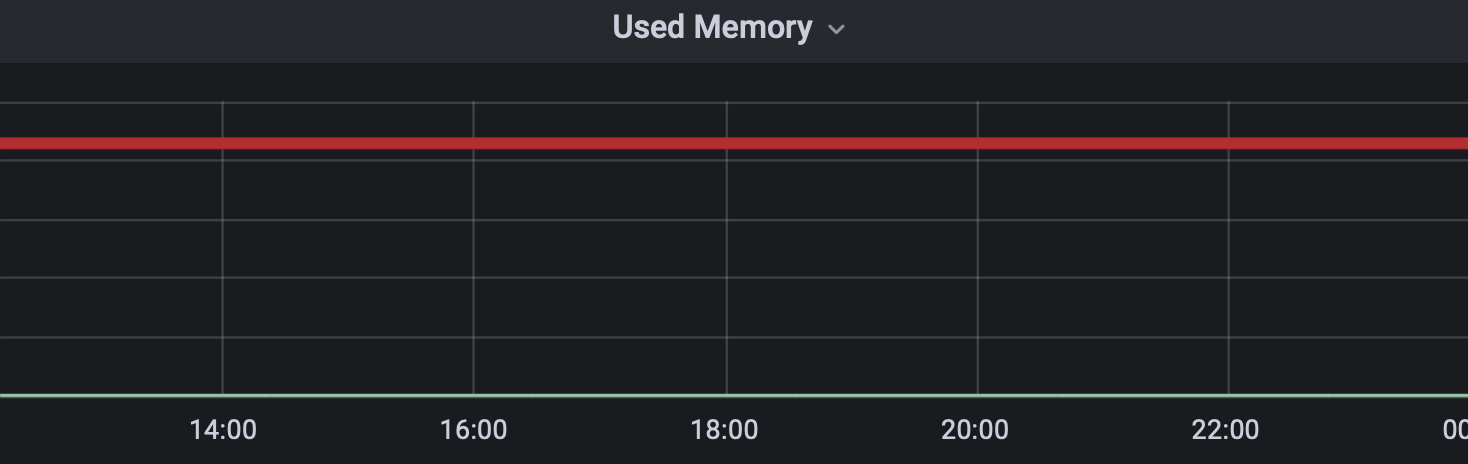
上の例はやや極端なケースになりますが、それと同�じようにサーバーのスペックに比べて使用するメモリの量が著しく低いサービスが存在しました。その場合、以下の2つの方法のいずれかまたは両方を使って縮小しました。
- スケールイン:Redisクラスタを構成するシャード数を減らします。
- スケールダウン:Redisを構成するサーバーのスペックを下げます。
上記の作業で最優先に考慮すべきことは「サービス中断がないこと」です。さまざまなサービスを提供するためにリソースを確保するための作業でサービス中断が発生したら、それこそ主客転倒になるからです。
もちろん、それに対する解決策も用意されていました。前述のHA構成の説明で話したように、拡張と縮小の際にいつでもRedisサーバーを1つずつ追加できるように設計しました。これにより、作業中にいずれかの物理サーバーに問題が発生しても、Redisは問題なく稼働できます。
ただし、これはすべてクライアントが適切に設定されている場合にのみ可能な解決策です。DNSベースのエンドポイント設定や、Redisクラスタの構成情報が変更された場合、それを正常に識別できるようにするRedisクラスタのトポロジーのオプション設定など、クラウド環境で安全に使用するためには、社内クラウド設定ガイドのベストプラクティスに従う必要があります。
従来も主に使用されるクライアントライブラリの詳細設定については、単純な調査以上に、それまでのトラブルシューティ��ング事例を基にガイドを提供していました。それに加え、キャンペーンを準備しながらより多様な設定に関するガイドを追加し、より読みやすく整えました。上記のオートヒーリングの動作もクライアントの設定に依存するため、キャンペーンを通じて今後発生する可能性のある障害も事前に予防できました。
「Users Rule」、そして「Perfect the Details」
さて、最後の悩みであり、最も重要な悩みが1つ残っています。それは、「ユーザーが望むかどうか」です。Redisを運用しながら過去に何度かキャンペーンを実施しましたが、社内メールで以下のようなフィードバックを受けたことがあります。
各ユーザーにカスタマイズしたメールを送信できるシステムであれば、詳細情報を確認できるダイレクトURLも十分に添付できます。世界的な企業であるだけに、社内向けの告知であっても細かい部分まで気を配って、よりレベルの高い結果を導いていただきたいと思います。
このフィードバックを受けて、それまで何か見落としたことはないかと反省しました。キャンペーンを実施する上で何よりも重要なのはユーザーの参加なのに、以前のキャンペーンで私たちはやや大雑把な情報しか提供せず、もしかしたらそれが参加率の低さにつながったのかもしれません。それまでコミュニケーションしたことのないユーザーでしたが、そのメールは私に気づきを与え、その後ずっと私の重要なメールボックスに残っています。
このフィードバックをもう一度振り返りながら、改めて心に刻み、細かい部分までユーザーのために尽くすこと�を決心しました。フィードバックの通りにURLを提供することにとどまらず、それを超えてユーザーごとにカスタマイズされたダッシュボードを作成することにしました。その作成で特に考慮したことは、以下のとおりです。
- なぜ行うべきか
- 何を行うべきか
- どのように行うべきか
- 一目で直感的に確認できるか
そして、これはすでに前述ですべて取り上げている内容です。そうです。すべてがビルドアップでした!
| なぜ? | 後処理した指標に基づき、あなたのRedisが未使用または低使用と判断されました。 |
|---|---|
| 何を? | 未使用の場合は返却を、低使用の場合は縮小をお願いいたします。 |
| どのように? | ガイドを参照し、設定を完了した後、クラウドUIを使って作業を行ってください。 |
以下のように、できるだけ簡潔に単一ページですべてを解決できるように構成し、ユーザーだけでなく私たちも使用量を追跡・管理するために、管理者ダッシュボードも構成しました。
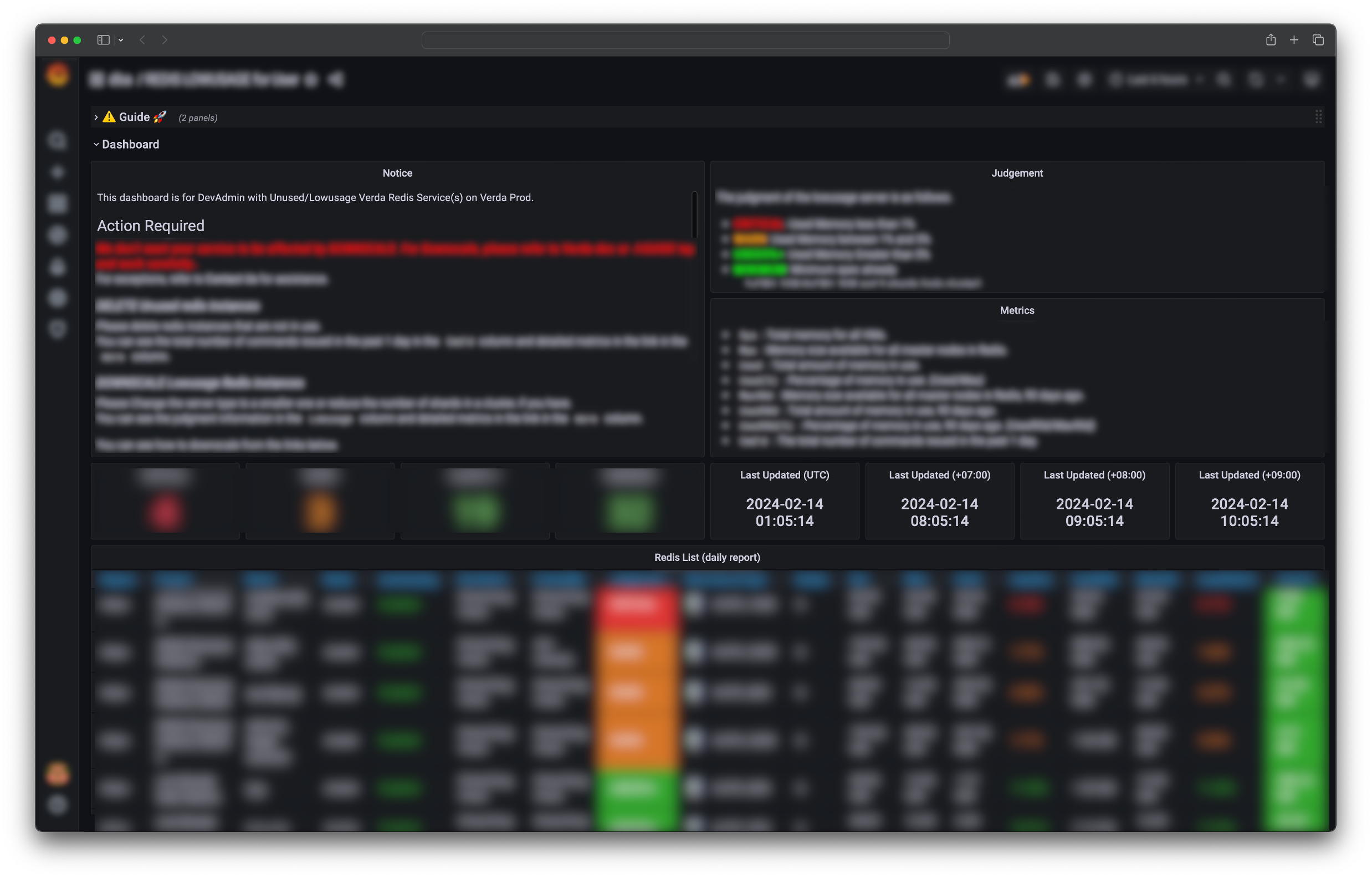
今回のキャンペーンは大規模なRedisが対象で、リリース時期や開発関連の特定イベントを避けるなど、開発者のスケジュールも考慮しながら実施したため��、長期間にわたって展開しました。深く考えて準備したためか、多くの開発者がキャンペーンに参加し、おかげさまで成功裏に終えることができました。以下は、2023年の1年間、Redisが使用していたリソースの変化を示したグラフです(サービス数ではありません!)。
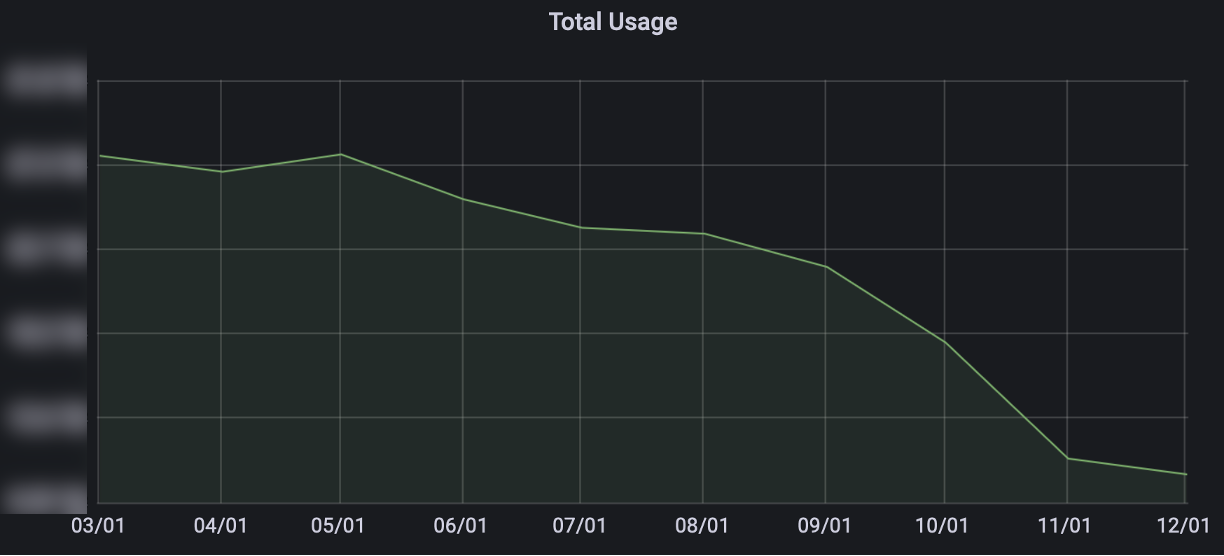
ここで重要なのは、サービス数にはほとんど変化がなかったということです。むしろ、終了するサービス数が開始するサービス数に追いつくことができませんでした。それでも、上のグラフのようにリソースの使用量が着実に低下することを確認し、キャンペーン結果は成功でした。また、公式キャンペーンが終了した今でも、リソースを効率的に使用し、より多くのRedisサービスを提供するために、継続的に追跡して管理しています。
合併してLINEヤフーになってから、運用中のRedisの規模は全体的にさらに大きくなっています。規模が大きくなるにつれて、今後解決すべき課題の数も増えています。今後もさまざまな挑戦を経て、より安定的かつ効率的なサービスを提供する予定です。この場をお借りして、社内のみなさんの関心に繋げたいです。これからもRedisサービスをよろしくお願いいたします。
おわりに
あまりにも膨大な規模のRedisを扱うことは、どこでも経験できないことだと思います。その経験について初めて文章にすることになり、本当にいろいろと書きたかったのですが、短い紙面ですべてを説明することは難しく、最も重要だと思ったHA構成と愛着のあるプロジェ��クト「Low Usage Project」を主なテーマとして取り上げました。プロジェクトの場合、単にリソースを効率的に使うだけでなく、管理者の立場からさまざまな改善を適用することもできたので、大きな意味がありました。今回の記事ではやむを得ず除外した内容や、技術的にもう少し深く掘り下げたい内容については、今後、時間があるたびに書いていく予定ですのでご期待ください。
一つだけお伝えしたいのは、この記事で紹介した内容のすべてを私一人で 行ったわけではないということです。この場をお借りして、一緒に意思決定を行い、共同作業を通じて良い結果を生み出したチームメンバーに心から感謝申し上げます。
最後に、Redisを大事にしてください。この記事が、Redisに愛着を持っている方や、運用業務を担当しているすべての方に役に立つことを願っています。Love yourself, Love your Redis.


