こんにちは。LINE MUSICのサーバサイドエンジニアをしている森です。
LINE MUSICでは(主に他社の)音楽サービスのプレイリストの画像から曲を認識し、曲をプレイリストに取り込む機能があります。この機能は以前から導入されていましたが、認識率のさらなる向上が求められていました。この機能を改めて実装し直すことで、認識率の改善に成功しました。どうやって改善に成功したか、またその中で得られた学びについて紹介します。
プレイリスト認識機能について
プレイリスト認識機能では、以下のようにプレイリストの画像を認識し、LINE MUSICのプレイリストに取り込むことができます。
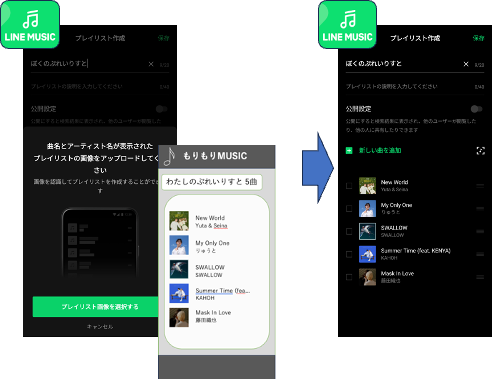
LINE MUSICの新規ユーザが、複数の曲をまとめてLINE MUSICに取り込みたいときに便利です。
この機能は以前から実装されていましたが、認識率のさらなる向上が求められていました。調査したところ、およそ8割の認識率であり、ユーザの利便性を踏まえると、さらに高い精度が必要です。
既存の構成と改善の方針
プレイリストの認識に必要な処理は、次の3つに分けられると考えられます。
- プレイリストの画像からの文字認識
- 認識された文字・位置から曲名・歌手名の抽出
- 曲名・歌手名から曲の検索
既存の構成を確認するとそれぞれの処理を担当するサーバも分かれていました。
入力となるプレイリストの画像は主にスクリーンショットを想定しています。そのため、1の処理の精度が問題になることは多くなさそうです。実際、もともと使われていた文字認識の処理を確認してみたところ、十分な精度で文字を認識できていることが確認��できました。つまり、1の処理のサーバは使い回してもよく、改善すべきは2と3の処理をするサーバであることがわかりました。
2と3の処理をするコードを確認したところ、調整の範疇で改善するのが困難そうだったため、2と3の処理をするサーバは一から作り直すことにしました。続く節で2と3の処理についてどういった工夫をしたかについて説明します。
認識された文字・位置から曲情報の抽出
曲情報の抽出は、以下を入出力とする処理です。
- 入力:プレイリストの画像中の文字列とその位置の組の列
- 出力:曲名・歌手名の組の列
曲情報の抽出はルールベースの方針で実装しました。機械学習を使って実装する方法も考えましたが、以下の理由から選択しませんでした。
- 機械学習はプレイリストのUIの変更に弱くなりやすい
- プレイリストのUIが変更された際にも対応できるよう、その状況を想定した学習が必要である
- 学習データを用意するために必要な工数が大きい
- ルールベースのほうが修正対応が楽
一方、ルールベースの場合を選択した場合も同様に、特定のUIを意識したルールを設定しないように注意する必要はあります。
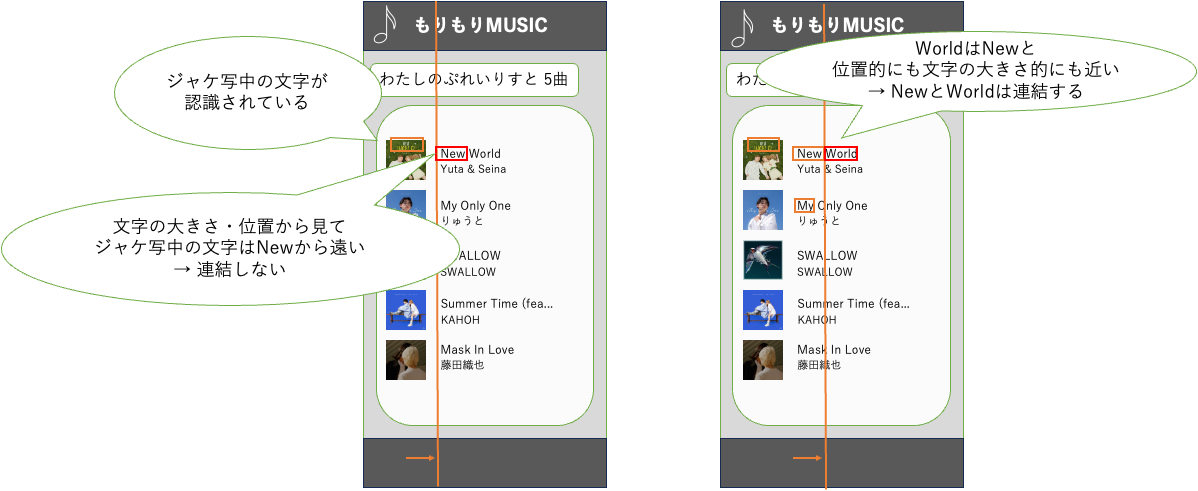
入力では本来つながっている曲名が複数に分かれていることがあります。そのため、どれが同じ曲名に含まれる文字列として連結すべきなのかを、判断する必要があります。これは文字の大きさを使って連結すべき位置関係を予測し、画像を左から走査して連結することで実現しました。
曲名・歌手名から曲の検索
曲の検索では検索エンジンとしてElasticsearchを用いています。曲の検索では曲名・歌手名を入力として、対応するLINE MUSICの曲を出力します。以下の手順で実施しています。
- 曲名・歌手名をトークンに分割する
- Elasticsearchから曲の候補を列挙する
- 曲の候補から最も「一致度」の高い曲を1つを選択する
それぞれについて、実施した工夫を説明します。
曲名・歌手名をトークンに分割する
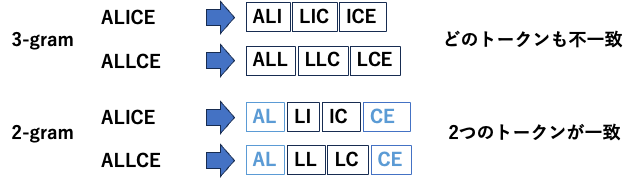
Elasticsearchでは文章(今回は曲名・歌手名)をトークンに分割して検索できます。トークンの分割にはN-gramを使いました。Elasticsearchではよく単語の単位でトークンへの分割をすることがありますが、曲名やアーティスト名の検索ではうまく機能しないことが多いです。造語や長い単語を含むため、正しく分割・検索をするのが難しいからです。このような場合はN-gramが有効です。N-gramではN文字ずつに文章を区切ります。たとえば「きらきら星」を3-gramで分割すると、「きらき」「らきら」「きら星」の3つのトークンに分割できます。
![]()
N-gramのNの選択は、誤認識を1つまで可能な限り許容するように設計しました。「ALICE」の入力を例に考えてみましょう。3文字目は大文字のiですが、文字認識の段階で小文字のLと誤認識することがあります。この��ような誤認識をして「ALLCE」(わかりやすさのために3文字目を大文字にしています)のように認識した場合、3-gramで分割してしまうと、「ALL」「LLC」「LCE」のように、本来の入力では存在しないトークンだけで、構成されることになります。2-gramで分割すると、一部のトークンが一致します。今回は曲名とアーティスト名の両方で検索しているので、部分的に一致するだけでも絞りこめる可能性が上がります。
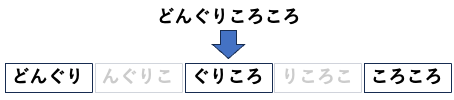
また、N-gramによる分割をそのまま採用せず、トークンをスキップする検索も実装しました。たとえば「どんぐりころころ」の入力では、そのまま4-gramに分割すると、「どんぐり」「んぐりこ」「ぐりころ」といった形になりますが、これらのトークンは大部分が重複しています。そのため、全てを検索するのは非効率です。これを「どんぐり」「ぐりころ」「ころころ」のように1つ飛ばしにすることで、大きな検索効率の改善ができます。
他にもさまざまな工夫をしています。
Elasticsearchから曲の候補を列挙する
事前に曲名・歌手名を分割方法に沿ってインデックスしておき、検索します。英語名の曲は日本語で表記されることもあるため、別名も事前に用意しておき検索対象に含めます。
曲の候補の列挙する際�のスコアリングについては、曲名・アーティスト名それぞれが反映されるように調整しました。Elasticsearchではスコアリングをカスタムもできるので、Elasticsearchから最も一致度が高い曲を選択するという設計も可能です。しかし、カスタムしたスコアリングをElasticsearchにそのまま適用すると、検索対象が多い場合に検索時間が非常に長くなってしまいます。そのため、Elasticsearchからは複数曲の候補を返させるだけにとどめて、アプリケーションの側で候補から最も一致度の高い曲を選択することで、効率と精度を両立できました。
曲の候補から最も一致度の高い曲を1つ選択する
Elasticsearchから返ってきた候補をもとに一致度の高い曲を選択します。この一致度の計算は編集距離をベースにして作成しました。編集距離は簡単には誤字・脱字の数を表す指標です。文字認識の誤りのパターンも多くは誤字・脱字とみなせるケースであり、一致度の表現として編集距離はぴったりです。
一致度は純粋な編集距離ではなく、前半が一致するほど高い一致度になるようにカスタムしました。これは曲名の表示のされ方によって、とくに後半に一致しない文字列がつくことがあるためです。代表例はフィーチャリングソングです。「(feat. xxx)」のような文字列が、曲名後半につく場合もあればつかないこともあります。後半の一致度が重要視されすぎると、フィーチャリングのアーティスト名部分が一致した、別の曲を抽出してしまう問題があります。文字列の前半の一致度が強く反映されるようにカスタムすることで、このような問題が解決されました��。
純粋な編集距離で一致度を評価するとうまくいかない例:
| 曲名 | 認識された曲名からの編集距離 | |
|---|---|---|
| 認識された曲名 | なつまつり(feat. もり) | |
| 検索結果としてふさわしくない曲 | ぶるどっく(feat. じゅん) | 8 |
| 本当に検索したかった曲 | なつまつり | 10 |
結果
合計400曲分のプレイリストの画像を複数の音楽サービスから作成して検証しました。
既存の認識率から大きく改善したことが確認できました。
| 既存の認識率 | 今回の手法の認識率 |
|---|---|
| 76% | 96% |
認識できなかった例として、以下のようなケースがありました。
- 曲名が韓国語で表記されているケース
- 該当の曲はLINE MUSICでは英語表記
- 空白が曲名に入っているが、画像から文字認識した時点で空白を認識できていないケース
- 4文字の曲名で2文字認識がうまくできていなかったケース
認識率をさらに向上させるためには、こういった個別のコーナーケースに対応していくことが鍵になりそうだとわかりました。
おわりに
それほど込み入ったことをせずとも、曲情報の抽出や検索を工夫することで、大きく認識率を改善できました。ぜひLINE MUSICのプレイリスト認識機能で遊んでみてください。


