Introduction
Enterprise data analysis faces a fundamental challenge: the gap between business questions and executable SQL queries. While data-driven decision making is critical, the reality is that most teams don't have enough data analysts to serve all business needs. Analysts spend significant time writing SQL for repetitive queries, and business teams wait days for answers to simple questions.
We all know this problem — then how should we solve it? An easy answer emerged with the introduction of generative AI models, or more specifically, large language models (LLMs). "Why not connect an LLM directly to our database? Let AI handle the SQL generation".
After Anthropic introduced the model context protocol (MCP) to enable easy connection between LLMs and external tools, we were one of the first teams in LY Corporation to create an in-house database MCP server. We connected Claude to our AI Assistant service database and expected it to democratize data analysis across the organization.
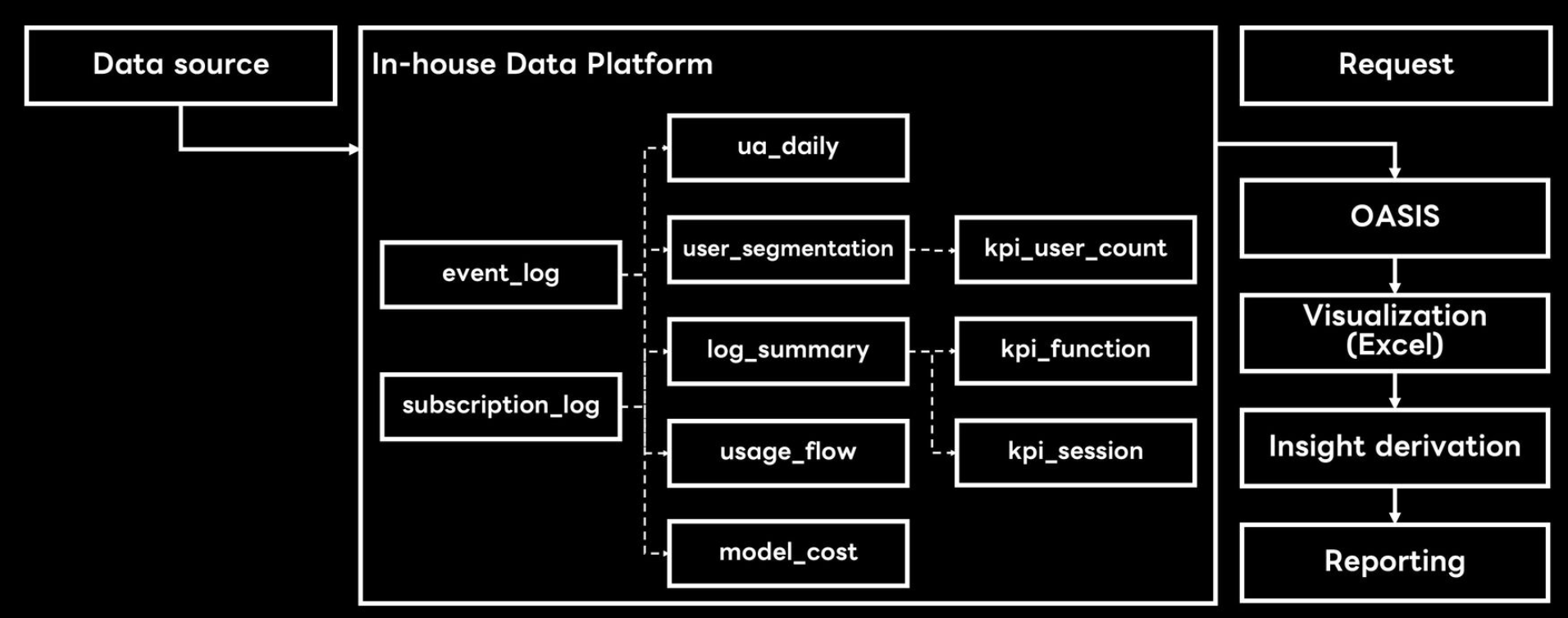
What our analysis workflow looked like
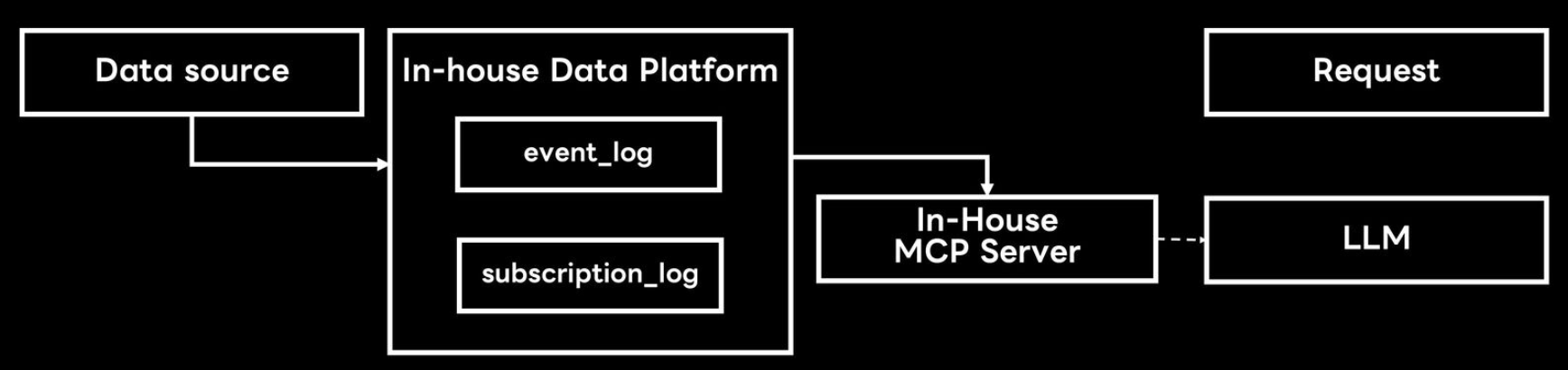
What we imagined our analysis workflow would look like after LLM implementation
It didn't work.
Why generic LLMs failed for enterprise analytics
Our initial experiment showed a possibility. LLMs were returning SQLs that seemingly looked good. Could this be the next innovation in data analysis?
Then, the more we actually looked into the generated SQLs and the more we tried asking complex and business-related questions, problems started showing up. It was revealed how little the LLM understood our business.
It didn’t understand our data.
When someone asked, “What’s this month’s DAU?”, it rummaged through dozens of tables containing “user” and confidently picked the wrong one. We realized syntax wasn’t our problem; semantics were.
It didn’t understand our business.
The model knew what “daily active users” meant in general, but not in our context where “active” only includes certain API endpoints. The LLM was fluent, not wise.
And then came the enterprise nightmares:
-
It tried to drop tables because it thought schema cleanup was “optimization”.
-
It failed with cryptic messages like “syntax error near line 42”.
-
It raised security flags the moment someone mentioned production data.
These limitations revealed a fundamental truth: generic LLMs lack the domain-specific knowledge, security policies, and organizational nuance.
The MCP server solution
Rather than abandoning AI-assisted SQL generation, we recognized that we needed a domain-specific system that understood our data and business context. That meant building a system that understood not only SQL syntax but our data, our business logic, and our guardrails. We set out to design a domain-specific NL-to-SQL MCP server to solve these challenges. The server worked as a bridge between natural language and the real-world constraints of enterprise data.
In the sections that follow, we’ll walk through how we built it:
-
Architecture: How a 7-step workflow and 4-layer design makes every query consistent and secure
-
Core components: How self-training, validation, and configuration keeps it improving over time
Our goal wasn’t just to make the model smarter, but rather to make it understandable, reliable, and teachable.
Understanding the system architecture
The NL-to-SQL MCP server transforms natural language queries into production-ready SQL through a structured pipeline. It acts like a translation system between business intent and data reality. To achieve this, we ended up with two complementary blueprints.
-
A 7-step workflow that defines how a query becomes SQL
-
A 4-layer architecture that defines where each step happens
Together, they turned what used to be a black box into a predictable, teachable process. We'll examine each perspective in detail, then show how key technical implementations enable this architecture to work in production.
The logical flow — how a question becomes a query
The 7-step workflow
Every query passes through seven mandatory checkpoints. It starts when a user asks a question in natural language, and ends when the system delivers validated, production-ready SQL or learns from the interaction to improve the next one. This structure is enforced by the system prompt and executed through MCP tool calls. The workflow ensures consistency, quality, and continuous improvement.

Step 0: User request
The user will start the process by asking a question in natural language - "What was last month’s retention?", "What was yesterday's DAU?". The system first detects the language, normalizes the phrasing, and translates it into a structured intent. This step ensures the AI truly hears the user before it starts thinking.
Step 1: Business context discovery
Before touching a database, the system looks up current business definitions and available metrics. Business context can be updated - KPIs can change, terms can be removed. This step makes sure the model never works with stale assumptions.
Step 2: Query analysis & SQL generation
This is where the core natural language processing happens. The system searches its knowledge base for similar queries. If it finds one, it adapts the existing SQL. If not, it synthesizes a new one from templates and learned patterns.
Step 3: SQL enhancement & validation
This stage acts as the quality gate: checking syntax, flagging slow or dangerous operations, and blocking any attempt to modify data. Rather than blindly trusting the generated SQL, it goes through a full validation report. When issues are detected in this step, the system goes back to Step 2 and tries to generate a validated SQL based on the issue report.
Step 4: SQL formatting & optimization
The final SQL may run, but it can be difficult to read to the human eye. Here, the query is formatted, indexed, and rewritten for clarity and performance. It ensures that the user can actually read and understand the SQL that is used.
Step 5: SQL delivery and guidance
At this point, the user sees their query and result. They get the retrieved business context, execution guide, validation report, and how to interpret the data.
Something else happens in the background: the system evaluates whether this interaction is worth remembering. Was it novel? High-confidence? Correct? Every response is a learning opportunity waiting to be confirmed.
Step 6: Interactive learning dialog
If the query meets the criteria, the system opens a dialogue: "This looks like a valuable example!" It explains why this example will help improve the system, and suggests adding it to the dataset. When the user agrees, that moment of success becomes a new golden example.
Step 7: Auto-expansion & training update
Finally, the system takes that one golden example and expands it, generating new variations across phrasing, parameters, and complexity. One query becomes many. It’s how the AI evolves from rule-following to intuition.
Benefits of enforcing a workflow
This structured approach provides three critical advantages:
- Consistency: Same query always follows same process, producing reliable results
- Quality gates: Multiple validation steps catch errors before SQL reaches users
- Self-improvement: Every successful query is an opportunity to enhance the system
The enforcement mechanism is simple but effective: the system prompt explicitly instructs LLMs to execute these steps in order, and each step is implemented as a dedicated MCP tool that must be called.
The physical structure - under the hood
Separating concerns
While the 7-step workflow describes the sequence of operations, the 4-layer architecture defines where each operation happens and how components interact. This separation enables independent development, testing, and maintenance of each layer.
The 4-layer architecture
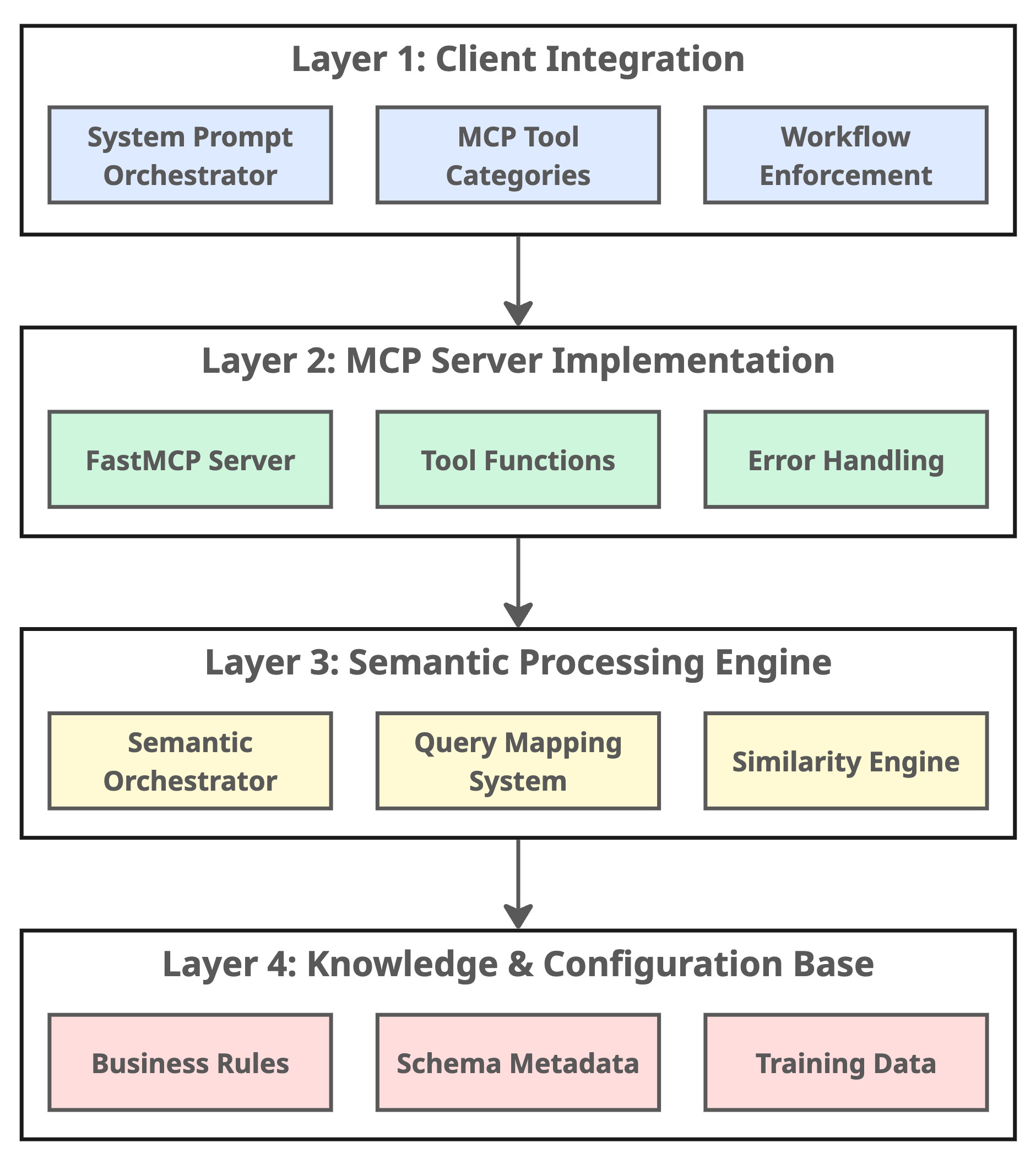
Layer 1: Client integration
This is where the behavior is defined and the 7-step workflow is enforced. It ensures that every request enters through the same disciplined 7-step process, resulting in consistent, high-quality processing for every query.
Layer 2: MCP server implementation
This layer provides a structured interface between the LLM and semantic engine. Whether it’s SQL generation, validation, or self-training, each operation runs through standardized APIs with error handling baked in. It enforces structure without stifling flexibility.
Layer 3: Semantic processing engine
This is where the core intelligence resides. It’s responsible for understanding intent, finding similar patterns, and generating SQL using both learned examples and fallback templates. It is implemented through the semantic orchestrator, the 'brain' of the system.
Layer 4: Knowledge & configuration base
All of the system’s institutional knowledge lives here in YAML and CSV files that describe metrics, queries, and business rules. Because it’s human-readable, domain experts can edit it directly. This layer keeps the system current, transparent, and explainable.
Benefits of this architecture
Together, these four layers create a modular foundation. We can improve one layer without breaking the others, replace the knowledge base to adapt to new business domains, or even connect multiple MCP servers to form larger, cross-domain analytics networks. It also enables the 7-step workflow by providing clean separation between "what to do" (workflow), "how to communicate" (MCP tools), "how to process" (semantic engine), and "what to know" (knowledge base).
Key components and implementations
Having understood the architecture, let's examine what makes this system significantly more effective than generic LLM-based solutions for enterprise data analysis. We identified six core innovations that set our MCP server apart.
| Issue | Generic LLMs | Our NL-to-SQL MCP Server |
| Domain knowledge | One-size-fits-all approach | Business knowledge externalized in human-editable YAML/CSV files |
| Learning capability | Static, never improves | Self-training with automatic variation generation from user interactions |
| Consistency | Unpredictable behavior | Mandatory 7-step workflow enforced by system prompt |
| Language support | English-only | Multi-language semantic understanding (Korean/English/Japanese) with business term mapping |
| Security & validation | Basic SQL generation | Three-layer validation pipeline (syntax, security, performance) |
| SQL generation | Black box process | Confidence-aware generation with similarity scoring and intelligent fallback patterns |
All six work together, but two form the beating heart of the system - Domain-specific configurability (teaching the AI what to know) and self-training architecture (teaching it how to grow). This post focuses on these two innovations in detail. If you're interested in the detailed implementation of other supporting innovations, feel free to reach out.
Innovation 1: Domain-specific configurability
Generic LLMs don't know what "DAU" means in our service. They don't know which tables are authoritative. They can't distinguish between test data and production metrics. Domain configurability solves this by externalizing business knowledge into human-readable configuration files.
How business knowledge becomes system intelligence
Our system separates business logic from technical implementation by moving all the business logic out of code and into human-readable files. We now define metrics, SQL templates, and segmentation rules directly in YAML.
- business_terms.yaml: What metrics mean in your business
- queries.yaml: How to calculate those metrics
- user_segmentation.yaml: Business rules and logic
We can edit these files directly without developer involvement, and changes take effect immediately without code deployment.
Example: Defining business terms
When someone asks "What's the DAU?", the system needs to know your specific definition. Here's how you configure it:
business_terms:
DAU:
term: "DAU"
full_name: "Daily Active Users"
definition: "Users with event logs during measurement period, excluding blocked and unsubscribed"
calculation_logic: "COUNT(DISTINCT user_id) WHERE has_events AND NOT blocked"
data_sources: ["user_event_history", "user_status_history"]
related_terms: ["MAU", "engagement", "retention"]That small decision changes everything. It ensures that every query about DAU uses the same business logic, regardless of who asks or how they phrase the question.
Innovation 2: Self-training architecture
We didn’t want a static system. We wanted something that gets better with use. Every time a user asks a question and confirms the answer, the system adds it to its training set and automatically generates eight new variations (different phrasing, parameters, or levels of complexity).

The learning loop: from query to knowledge
Here's how the system learns.

-
The system evaluates whether the query is worth learning from, based on confidence, novelty, and validation results.
-
If approved, it asks the user for consent: “Should I learn this?”
-
Once confirmed, the query is stored in a CSV-based dataset that any analyst can review or edit. We chose CSV files over vector databases or complex ML pipelines for transparency and maintainability.
-
From there, the system automatically generates variations through reworded queries, different date ranges, and complexity levels. This effectively multiplies its training set.
Smart learning assessment
The system doesn't learn from every query. It automatically evaluates whether a successful query-SQL pair should be added to training data.
Learning opportunity criteria:
- High confidence score
- SQL passed all validation checks
- Novel pattern (not too similar to existing examples)
- Business-critical category (KPIs, revenue, user metrics)
- User confirmed accuracy
This ensures the training dataset contains only proven, high-quality examples.
Automatic variation generation: the 1→8 multiplication effect
When one golden example is added, the system automatically generates variations using four strategies.
Original entry:
User: "What's the MAU for October 2024?"
SQL: SELECT COUNT(DISTINCT user_id) FROM users WHERE month = '2024-10'Automatically generated variations (8+):
1. Language variations:
- "2024년 10월 MAU는?" (Korean informal)
- "Show me October 2024 monthly active users" (English verbose)
2. Parameter variations:
- "What's the MAU for September 2024?" (different month)
- "What's the MAU for Q4 2024?" (different time range)
3. Complexity variations:
- Simplified: Basic COUNT query
- Enhanced: Including user segmentation breakdown
4. Term substitutions:
- "monthly active users" ↔ "MAU" ↔ "30-day active users"
This way, one user confirmation creates 8+ training examples, exponentially growing the system's knowledge base.
Conclusion
Somewhere between the first failed LLM query and the final version of our MCP server, we learned an important lesson. Enterprise data analysis doesn't need smarter LLMs, it needs structured systems that externalize business knowledge and learn from production use. This post demonstrated how to build a domain-specific NL-to-SQL system that solves the fundamental limitations of generic LLM approaches through architectural patterns rather than model training.
By reimagining how AI interacts with data, we turned chaotic SQL generation into a repeatable craft. The 7-step workflow gave us reliability, the 4-layer architecture gave us clarity, and the combination of domain configurability and self-training gave the system its ability to grow. Together, they transformed our AI from a clever assistant into a consistent collaborator.
A closing thought
We started on this path in order to replace our own jobs with AI. What we built proved something better. AI doesn’t replace analysts, it amplifies them. It takes the everyday questions that slow us down and turns them into opportunities for learning, clarity, and speed. And in that process, it doesn’t just analyze data. It changes how organizations think.
The next chapter: A2A architecture
Building the MCP server taught us one defining lesson: structure unlocks intelligence. Then what if multiple structured systems could work together? That question became the seed for our next project: the agent-to-agent (A2A) architecture.
Right now, we’re developing a multi-agent analysis framework that carries forward everything we learned while building the MCP server and amplifying it. Each agent specializes in a specific role, from SQL generation to data validation to visualization, and they collaborate through well-defined protocols. Instead of one AI analyst, imagine a small, coordinated team that is fast, reliable, and self-improving.
We’ll be sharing that story soon. Not as a theoretical concept, but as the next practical step in our journey toward scalable, collaborative AI for enterprise analytics. So stay tuned; this is where the real transformation begins.
👉 New to MCP servers and data pipelines? Check out my 2025 Tech-Verse presentation on MCP servers here: Replacing Data Analysts with AI
👉 Want to know how to create AI Agents for Analysis? Look forward to our next article in this series on NL-to-SQL agents based on the A2A structure!