In the realm of software development, managing complex states is an unavoidable challenge, particularly when a simple boolean flag or optional value isn't sufficient. Often, developers resort to adding multiple properties and using their combinations to represent various states. While this approach is easy and might work initially, it can quickly lead to software that's difficult to maintain and debug.
The iOS version of the LINE app is no different, as it also comes with the challenges of managing complex states. We were early adopters of Swift when we wrote the app, and as we migrate to Swift Concurrency, the way to handle states has also evolved.
This article introduces a pattern used in the LINE iOS app for implementing a robust state machine to handle complex states using modern Swift Concurrency. We will walk through the creation of a RequestScheduler for scheduling network requests with the following specifications:
- Sendable: The scheduler should conform to the
Sendableprotocol, ensuring safe access from different threads. - Send request: It should provide an asynchronous method for sending a request and returning the response.
- Automatic retry: If a request fails, the scheduler should automatically retry up to 10 times, with a specified interval between retries.
- Cancellation: The scheduler should respond to cancellations by stopping any pending retries and finalizing the operation.
Implementing RequestScheduler
Creating a skeleton for RequestScheduler
Let's begin by constructing the RequestScheduler. We'll utilize Swift Concurrency's actor to ensure that access to its state is isolated, thereby making it thread-safe.
- The details of making the actual request are not the concern of the scheduler.
- While the retry interval can incorporate a backoff strategy, for simplicity, we'll use a constant time interval.
final actor RequestScheduler<Response: Sendable> {
private let makeRequest: () async -> Result<Response, any Error> // (1)
private let retryInterval: ContinuousClock.Duration = .seconds(10) // (2)
init(makeRequest: @escaping () -> Result<Response, any Error>) {
self.makeRequest = makeRequest
}
}Next, let's create a public method for users of RequestScheduler.
- From the user's perspective, a method
func request() async throws -> Responseis all that's needed. Users can call this method to get a response. - Considering the possibility that the
request()method might be called multiple times, we need an internaltaskproperty to cache the request process and its result, ensuring that the request flow executes only once. - We use
withTaskCancellationHandlerto initiate the internal task, providing a cancellation action to cancel the entire scheduler if needed. - The internal task is initiated with a
continuation. Thiscontinuationwill be used by the internal scheduling logic to eventually resume with the appropriate result.
final actor RequestScheduler<Response: Sendable> {
private typealias TaskType = Task<Result<Response, any Error>, Never>
private var task: TaskType? // (2)
public func request() async throws -> Response { // (1)
try await withTaskCancellationHandler( // (3)
operation: {
try await getTask().value.get()
},
onCancel: {
Task {
await cancel()
}
}
)
}
private func getTask() -> TaskType {
if let task {
return task
} else {
let task: Task<Result<Response, any Error>, Never> = Task {
await withCheckedContinuation { continuation in
start(continuation: continuation) // (4)
}
}
self.task = task
return task
}
}
private func start(continuation: ContinuationType) {}
private func cancel() {}
}Modeling states
To effectively manage the states of the scheduler, we use an enum to model its possible states. Based on the requirements, we need four states: idle, sending, scheduledForRetry, and finished.
The state transitions can be illustrated as follows:
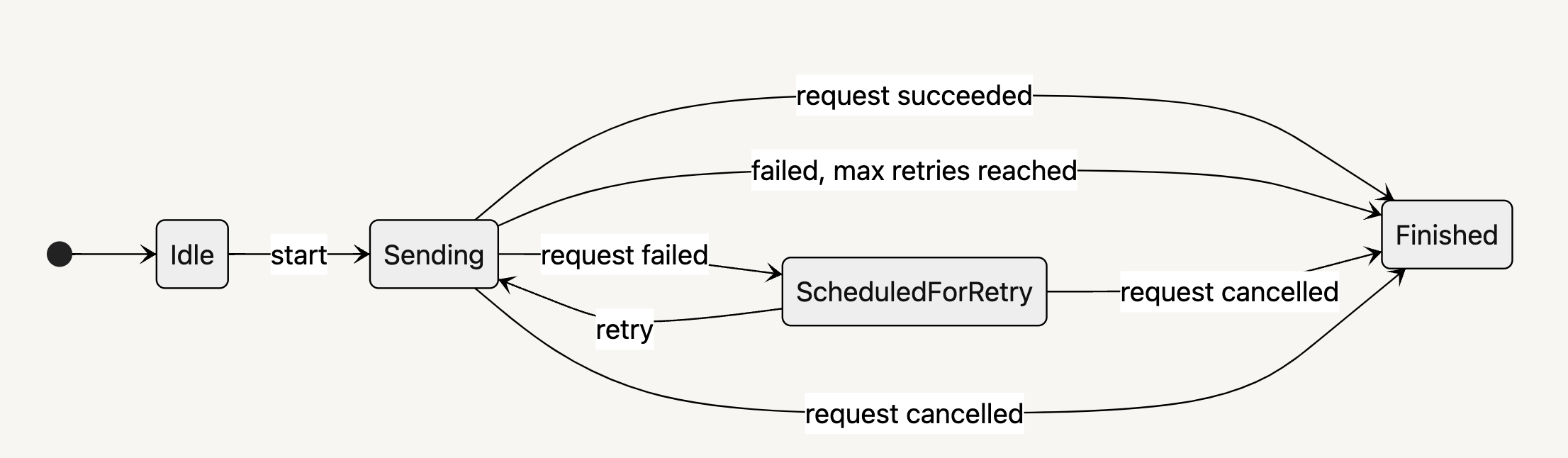
Let's implement the code for these states. Initially, we'll focus on the idle, sending, and finished states. In the sending state, sendingTask is a Task for sending the actual request.
final actor RequestScheduler<Response> {
private enum State {
case idle
case sending(
tryCount: UInt,
sendingTask: Task<Void, Never>,
continuation: ContinuationType
)
// scheduledForRetry will be added later
case finished(result: Result<Response, any Error>)
}
private var state = State.idle
private typealias ContinuationType = CheckedContinuation<Result<Response, any Error>, Never>
}
State transition
Implementing a basic skeleton for handling state transition
Let's set up the basic framework for handling state transitions.
- Introduce an
Eventenum to represent possible events that trigger state transitions. - The core of the state machine is the
reducemethod, which examines the current state and event, performs necessary operations, and returns the next state. - Create a method to send an event, updating the state to the new one returned by the
reducemethod.
final actor RequestScheduler<Response: Sendable> {
// ...
// (1)
private enum Event {
}
private func send(event: Event) {
state = reduce(state: state, event: event) // (3)
}
// (2)
private func reduce(
state: State,
event: Event
) -> State {
}
}
Start and finish request
Now, let's implement the state transitions for the start and finish events.
- (1): Add
startandreceivedResultto theEventenum. These represent events when the request is started and when a result is received. - (2): Handle events based on the current state in the
reducemethod. When the current state isidleand the event isstart, initiate the request and return thesendingstate.- (3): Start a request by creating a
Task, which triggers the eventreceivedResultupon completion ((4)).
- (3): Start a request by creating a
- (5): When the state is
sendingand a result is received, finish the request. ThefinishAndReturnFinishedStatemethod is used to unconditionally finish the scheduler with a result, as it will be reused for other events. - (6): In the finish method, first cancel all ongoing tasks ((7)), then finish the continuation with the provided result.
- Cancelling an already finished request in the
sendingstate is unnecessary but harmless. ThecancelSubTasks()method is designed to cancel any ongoing async operations for any state.
- Cancelling an already finished request in the
final actor RequestScheduler<Response: Sendable> {
// ...
// (1)
private enum Event {
case start(ContinuationType)
case receivedResult(Result<Response, any Error>)
}
private func reduce(
state: State,
event: Event
) -> State {
switch (state, event) {
case let (.idle, .start(continuation)):
return .sending(tryCount: 1, sendingTask: makeRequestTask(), continuation: continuation) // (2)
case let (.sending, .receivedResult(result)):
return finishAndReturnFinishedState(result) // (5)
default:
return state
}
}
// (3)
private func makeRequestTask() -> Task<Void, Never> {
Task {
let result = await makeRequest()
if !Task.isCancelled {
send(event: .receivedResult(result)) // (4)
}
}
}
// (6)
private func finishAndReturnFinishedState(_ result: Result<Response, any Error>) -> State {
cancelSubTasks()
switch state {
case let .sending(_, _, continuation):
continuation.resume(returning: result)
case .idle, .finished:
break
}
return .finished(result: result)
}
// (7)
func cancelSubTasks() {
switch state {
case let .sending(_, sendingTask, _):
sendingTask.cancel()
case .idle, .finished:
break
}
}
}
Cancellation
Let's implement the cancellation feature for the scheduler.
- (1): Add a new event
cancelled. - (2): In the
cancel()method, simply send thecancelledevent. - (3): In the
reducemethod, handle thecancelledevent for any state by reusing thefinishAndReturnFinishedStatemethod to clear ongoing operations and finish with aURLError(.cancelled)error.
final actor RequestScheduler<Response: Sendable> {
// ...
private enum Event {
// ...
case cancelled // (1)
}
private func cancel() {
send(event: .cancelled) // (2)
}
private func reduce(
state: State,
event: Event
) -> State {
switch (state, event) {
// ...
case (_, .cancelled):
return finishAndReturnFinishedState(.failure(URLError(.cancelled))) // (3)
// ...
}
}
}
Automatic retry
Now, let's implement the feature to retry the request up to 10 times if it fails.
- (1): Add a new state
scheduledForRetry. This represents the scheduler waiting for the retry interval. TheretryTaskis aTaskthat sleeps for this interval. - (2): Add a
retryRequestevent, which occurs after the retry interval, prompting the scheduler to resend the request. - (3): In the
reducemethod, modify the logic when receiving a result in thesendingstate:- (4): If the result is a failure and
tryCountis less than 10, transition toscheduledForRetry. Carry overtryCountandcontinuationfrom thesendingstate for subsequent operations. InretryTask, after sleeping, send theretryRequestevent. - (5): Otherwise, finish the scheduler as before.
- (4): If the result is a failure and
- (6): When the
retryRequestevent occurs in thescheduledForRetrystate, resend the request, transitioning tosendingwithtryCountincremented andcontinuationcarried over. - (7): In
finishAndReturnFinishedState, ensure the scheduler finishes with a result in thescheduledForRetrystate as well. - (8): Handle the
scheduledForRetrystate in thecancelSubTasks()method.
final actor RequestScheduler<Response: Sendable> {
private enum State {
// ...
case scheduledForRetry( // (1)
tryCount: UInt,
retryTask: Task<Void, Never>,
continuation: ContinuationType
)
// ...
}
private enum Event {
// ...
case retryRequest // (2)
}
private func reduce(
state: State,
event: Event
) -> State {
switch (state, event) {
// ...
// (3)
case let (.sending(tryCount, _, continuation), .receivedResult(result)):
guard tryCount < 10, case .failure = result else {
return finishAndReturnFinishedState(result) // (5)
}
// (4)
return .scheduledForRetry(
tryCount: tryCount,
retryTask: Task {
try? await Task.sleep(for: retryInterval)
if !Task.isCancelled {
send(event: .retryRequest)
}
},
continuation: continuation
)
// (6)
case let (.scheduledForRetry(tryCount, _, continuation), .retryRequest):
return .sending(tryCount: tryCount + 1, sendingTask: makeRequestTask(), continuation: continuation)
// ...
}
}
private func finishAndReturnFinishedState(_ result: Result<Response, any Error>) -> State {
switch state {
// ...
case let .scheduledForRetry(_, _, continuation):
continuation.resume(returning: result) // (7)
}
// ...
}
func cancelSubTasks() {
switch state {
// ...
case let .scheduledForRetry(_, retryTask, _):
retryTask.cancel() // (8)
// ...
}
}
}
Discussions
We've successfully implemented a robust state machine for our RequestScheduler using Swift Concurrency. Let's delve into some detailed aspects of the implementation and discuss the benefits and considerations of using this pattern.
Compiler safety when handling states
When handling states, it's advisable not to use a default case in switch statements. This ensures that whenever a new state is added, the compiler will emit errors for any unhandled states, prompting you to address them.
Additionally, using associated values to store state-specific information is preferable to creating a dedicated structure:
// Preferred
case sending(
tryCount: UInt,
sendingTask: Task<Void, Never>,
continuation: ContinuationType
)
// Less preferred
case sending(SendingStateProperties)
This approach enhances compiler safety. If you add or remove a state-specific property, the compiler will flag all places where the state's properties are used, requiring you to consider the changes:
case let (.sending(tryCount, sendingTask, continuation), .receivedResult(result)): // × Missing argument for parameter 'newProperty' in call
// Use tryCount, sendingTask, continuation...
This behavior isn't present if you use a structure to hold a state’s properties:
case let (.sending(sendingProperties), .receivedResult(result)):
// Access sendingProperties.tryCount, sendingProperties.continuation...
Structured concurrency and actor reentrancy
Structured concurrency can be simply described as "not using Tasks". If all async code is directly called using await, the entire async operation benefits from structured concurrency, including cancellation propagation.
However, it's advisable to avoid introducing structured concurrency into the state machine's state transition logic. In our RequestScheduler implementation, only the public request() method is marked with async. Internal asynchronous operations are managed by unstructured concurrency - standalone Tasks like sendingTask and retryTask, while the rest of the state transition logic remains non-async.
This approach relates to actor reentrancy—actor-isolated functions are reentrant. This means that if a method is async and contains await code, it can be executed again while being suspended in the middle, waiting for an await statement. This leads to interleaved executions that might cause unexpected and invalid states. Therefore, it's crucial to ensure that methods for state transition logic are not marked with async.
Conclusion
In this article, we introduced a pattern for implementing a state machine:
- Use an enum to represent the state.
- Use another enum to represent possible events.
- Use associated values on the state enum to carry state-specific information (the same applies to the event enum).
- Centralize state transition logic in a
reducemethod, which handles events based on the current state and transitions to the next state. - Instead of directly modifying the state, send an event and let the
reducemethod manage the state transition.
While the implementation might seem straightforward, real-world scenarios often require additional considerations:
- If the scheduler is waiting for a retry and receives a connectivity-restored update, it might be beneficial to initiate the retry immediately.
- Implementing a "timeout" for the scheduler that works across multiple retries could be desirable.
As the requirements for RequestScheduler get more complicated, using a state machine to manage states becomes even more helpful. If you face situations with complex state management, I hope this article will come in handy as a useful resource.